- Ubuntu txt windows отображаются криво
- Решаем проблему с кодировкой текстового редактора Gedit в Ubuntu 14.04 — 12.04
- Кодировка в Gedit
- Содержание
- Описание проблемы
- Настройка Gedit на автоопределение кодировки
- Смена кодировки открытого файла
- Кое-что о проблемах с кодировками в убунту.
- Кодировка при копировании из windows в linux
- Смена кодировки файлов в Ubuntu, а так же iconv и большие файлы
- iconv и большие файлы
Ubuntu txt windows отображаются криво
| Главная |
|---|
|
| ИТ — специалист |
|---|
|
| Программы |
|---|
|

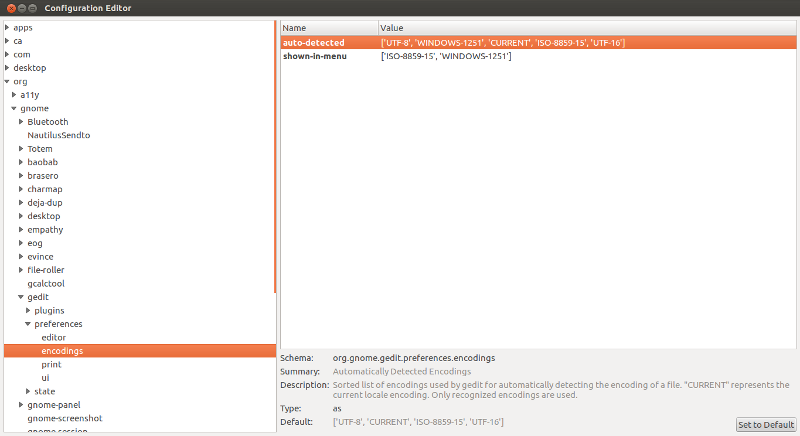
Решаем проблему с кодировкой текстового редактора Gedit в Ubuntu 14.04 — 12.04Все пользователи Ubuntu встречаются с проблемой, когда открывают в редакторе Gedit текстовые файлы, созданные в блокноте Windows и видят, что вместо текста отображаются нечитаемые «крокозябры». В данной статье расскажу, как легко и быстро решить эту проблему. Многие встречались с такой проблемой , когда Вы пытаетесь открыть txt файл от пользователя Windows стандартным текстовым редактором Gedit, а вместо вменяемого текста видите вот такие «крокозябры»: Но в данной статье хочу предложить более простой способ. По умолчанию, в Ubuntu в текстовых файлах, да и вообще в системе, использует кодировку UTF-8. А в майкрософтовских продуктах используется кривая и устаревшая кодировка Windows 1251(cp1251), когда сохраняете файлы стандартным блокнотом, но помимо её еще есть кодировка koi8-r. Чтобы корректно отображались текстовые файлы с кодировкой CP-1251 (Win1251), нам нужно в редакторе Gedit установить приоритет кодировке CP-1251 (Windows1251). gsettings set org.gnome.gedit.preferences.encodings auto-detected «[‘UTF-8’, ‘WINDOWS-1251’, ‘CURRENT’, ‘ISO-8859-15’, ‘UTF-16’]» Теперь пробуем открыть TXT файл снова. Кодировка в GeditСодержаниеОписание проблемыUbuntu по умолчанию использует кодировку текстовых файлов UTF-8, однако некоторые операционные системы используют другие кодировки (например, русская версия Microsoft Windows использует CP-1251). Из-за разницы в кодировках могут возникнуть проблемы при открытии текстовых файлов в редакторе Gedit — они будут нечитаемыми. Данная статья предлагает несколько простых способов решения этой проблемы. Настройка Gedit на автоопределение кодировкиGedit может автоматически определить нужную кодировку. Для этого его нужно немного настроить. Есть 3 варианта: Вариант 1. Запускаем dconf-editor и переходим в
Редактируем ключ auto_detected 3) , вписывая нужную нам кодировку Вариант 2. Выполните в терминале команду: Откроется Редактор Конфигурации GNOME. В нем откройте для редактирования ключ auto_detected 4) . Вариант 3. Выполните в терминале команду: Для Ubuntu 16.04: Для Ubuntu Mate 16.04: Данный способ является самым быстрым. Теперь, если вы откроете файл с кодировкой WINDOWS-1251 — он будет правильно отображаться в Gedit. Смена кодировки открытого файлаС помощью системы плагинов можно добавить возможность выбора кодировки уже открытого файла. /.local/share/gedit/plugins (если такой папки нет, то её нужно создать) После этого в главном меню Файл появляется пункт «Encoding», который позволяет менять кодировку в уже открытом документе. Кое-что о проблемах с кодировками в убунту.Я не ставил себе цель решить все проблемы, но хотел написать решения, о которых не писалось на хабре. Итак начнем с IM. Хорошая хозяйка может взять на заметку несколько следующих фактов. Миранда прекрасно ладит как с utf так и с 1251. qip принимает только 1251 и не желает работать с utf. Pidgin настроеный на utf не принимает 1251. Pidgin настроенный на 1251 принимает utf но отсылает в ответ все равно 1251. У вас было такое, что вы вставляете нормальный диск а кириллические названия выглядят примерно так: «. «. И немного про субтитры в mplayer. Тут немного о кодироваках в аудиофойлах и проигрывателях. Собственно пока все. Если вы считаете что какую-либо проблему надо решать по-другому либо знаете как решить другую — пишите. Поправки тоже принимаются. Кодировка при копировании из windows в linuxБыло несколько файлов созданных в windows (в стандартном блокноте, скорей всего там было windows 1251) с русским текстом. Потом человек из двух файлов хотел сделать один, но уже из под линукса. Скопировал содержимое одного файла, вставил в другой файл, сохранил. Но русский текст стал весь отображаться как . Можно ли это исправить как то?
Самый простой виндовый способ notepad++
да ты же болен, это самый неэффективный и малоприменимый способ
Огласил свой диагноз доктор onanymous.
Вряд ли 🙂 Склейте в блокноте из-под вайна.
Перестать страдать хернёй. для склейки файлов ему следовало использовать cat чтоб потом отобразить, выше команду iconv написали, чтоб поправить кривые досовские переносы: Боюсь печаль, беда уже. Блокнот тоже вопросики отображает. Там походу не просто криво отображается кодировка, а именно сохранение произошло.
На линуксе софт и пользователь с кодировкой не разобрались, а виновата винда 🤣
Не знаю, у меня и там и там vim с kate, всё норм. При чём тут венда? Можно («руками и головой» точно). «Исходники» конечно же утрачены? Для начала сделать копию этого текстового файла и далее «восстанавливать читаемость» текста из этой копии. Редактор умеет открывать тексты в разных кодировках? Текстовый файл как опознаётся командой file? * вполне возможно всё это из-за одного лишнего или потерянного символа (байта). Смена кодировки файлов в Ubuntu, а так же iconv и большие файлыДавно в категории «Ubuntu» у меня не было материалов. Сегодня я исправлюсь и выпущу сразу две статьи. Итак, начнём. вам приходилось менять кодировку текстовых файлов в linux’e? А что если объем такого файла больше 10 Gb?! Что бы изменить кодировку файла нужно использовать замечательную утилиту iconv. В параметрах необходимо указывать исходную кодировку, а в этом нам поможет команда: Ну а далее вот такие действия:
Остальные ключики как обычно в man iconv. iconv и большие файлыДля быстрого выполнения процесса кодировки, iconv загружает файл в оперативную память и в swap. Но это работает только для небольших файлов. Если файл уж совсем большой, а ОЗУ не особо, то вы прост получите ошибку, мол «слишком большой файл», звиняйте хлопцы. Где взять такой файл? К примеру это может быть выборка из БД ( игры для ipad, PC, PSP или другие данные) Вот здесь предлагают различные решения данного вопроса: и скриптами, и разбивка на части, вывод в потоки, а потом обратно сборка в файл. Лично мне понравилось весьма простое решение: команда split — она позволяет разбить текстовый файл на более мелкие, а дальше с ними работать как угодно можно. В простом варианте чтобы разбить файл на куски объёмом по 1Gb выполнить: Это самые просты решения, эти команды можно использовать в различных скриптах и получить от этого много кайфов. Надеюсь эта заметка вам чем-то помогла. |
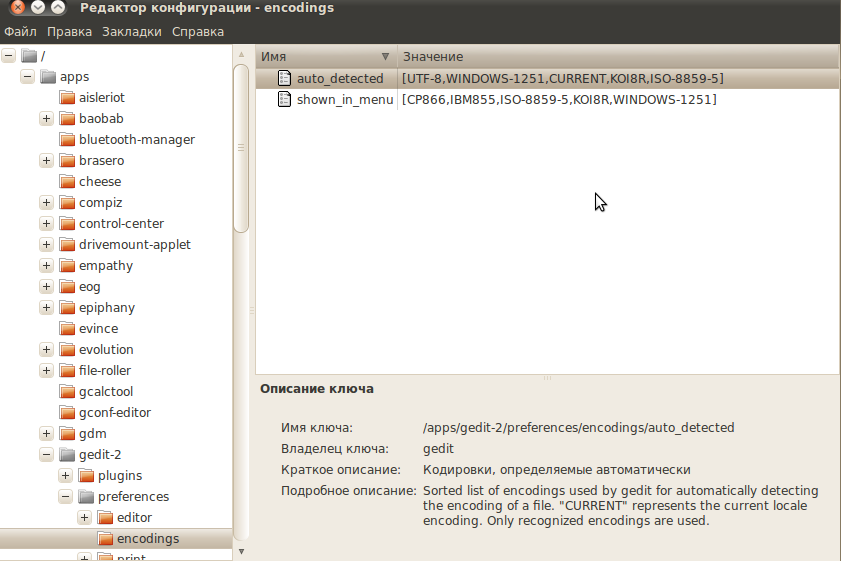 В появившемся окне редактирования переместите нужную вам кодировку вверх, так, чтобы она находилась сразу после UTF-8. Нажмите OK и закройте редактор.
В появившемся окне редактирования переместите нужную вам кодировку вверх, так, чтобы она находилась сразу после UTF-8. Нажмите OK и закройте редактор. 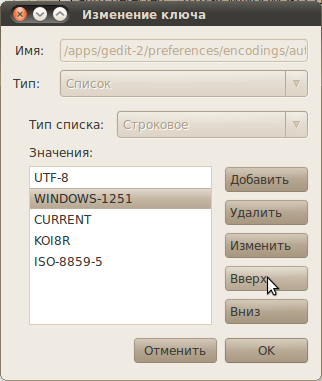



 tiinn best.
tiinn best.



