- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Как удалить раздел диска в Linux
- Удалить раздел в Linux
- Шаг 1. Составьте список схемы разделов
- Шаг 2: Выберите диск
- Шаг 3: удалить разделы
- Шаг 4: проверьте удаление раздела
- Шаг 5. Сохраните изменения и выйдите
- Полезно?
- Почему?
- Настольная книга по Linux/Блочные устройства
- Содержание
- Получение общей информации [ править ]
- Образы [ править ]
- Горячее подключение [ править ]
- Проверка состояния [ править ]
- LVM [ править ]
- Управление накопителями в Linux: основные понятия и подходы
- Блочные системы хранения
- Разделы диска
- MBR и GPT
- Форматирование и файловые системы
- Управление устройствами хранения в Linux
- Файлы устройств в /dev
- Монтирование блочных устройств
- Постоянное монтирование
- Продвинутое управление хранилищами
- Что такое RAID?
- Что такое LVM?
- Дальнейшие действия
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Как удалить раздел диска в Linux
Избавляемся от раздела
2 минуты чтения
Пользователи Linux создают разделы для эффективной организации своих данных. Разделы Linux могут быть удалены так же просто, как и созданы, чтобы переформатировать устройство хранения и освободить место для хранения.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps


Удалить раздел в Linux
Для удаления раздела в Linux необходимо выбрать диск, содержащий раздел, и использовать утилиту командной строки fdisk для его удаления.
Примечание. Утилита командной строки fdisk — это текстовый манипулятор таблицы разделов. Она используется для разделения и перераспределения устройств хранения.
Шаг 1. Составьте список схемы разделов
Перед удалением раздела выполните следующую команду, чтобы просмотреть схему разделов.
В нашем случае терминал распечатывает информацию о двух дисках: /dev/sda и /dev/sdb . Диск /dev/sda содержит операционную систему, поэтому его разделы удалять не следует.
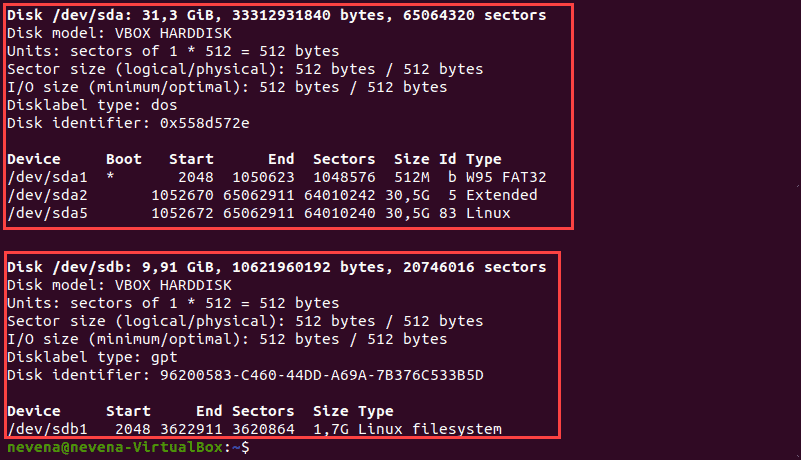
На диске /dev/sdb есть раздел /dev/sdb1 , который мы собираемся удалить.
Примечание. Число 1 в /dev/sdb1 указывает номер раздела. Запишите номер раздела, который вы собираетесь удалить.
Шаг 2: Выберите диск
Выберите диск, содержащий раздел, который вы собираетесь удалить.
Общие имена дисков в Linux включают:
| Тип диска | Имена дисков | Обычно используемые имена дисков |
| IDE | /dev/hd[a-h] | /dev/hda, /dev/hdb |
| SCSI | /dev/sd[a-p] | /dev/sda, /dev/sdb |
| ESDI | /dev/ed[a-d] | /dev/eda |
| XT | /dev/xd[ab] | /dev/xda |
Чтобы выбрать диск, выполните следующую команду:

Шаг 3: удалить разделы
Перед удалением раздела сделайте резервную копию своих данных. Все данные автоматически удаляются при удалении раздела.
Чтобы удалить раздел, выполните команду d в утилите командной строки fdisk .
Раздел выбирается автоматически, если на диске нет других разделов. Если диск содержит несколько разделов, выберите раздел, введя его номер.
Терминал распечатает сообщение, подтверждающее, что раздел удален.

Примечание. Если вы хотите удалить несколько разделов, повторите этот шаг столько раз, сколько необходимо.
Шаг 4: проверьте удаление раздела
Перезагрузите таблицу разделов, чтобы убедиться, что раздел был удален. Для этого запустите команду p .
Терминал выведет структуру разделов диска, выбранного на шаге 2.
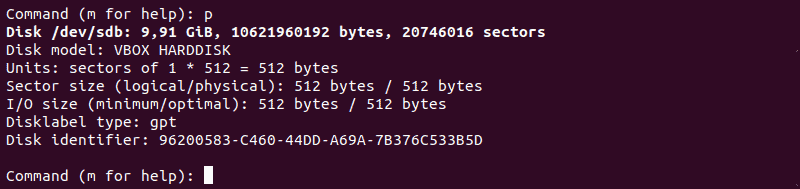
Шаг 5. Сохраните изменения и выйдите
Запустите команду w , чтобы записать и сохранить изменения, внесенные на диск.

Мини — курс по виртуализации
Знакомство с VMware vSphere 7 и технологией виртуализации в авторском мини — курсе от Михаила Якобсена

Полезно?
Почему?
😪 Мы тщательно прорабатываем каждый фидбек и отвечаем по итогам анализа. Напишите, пожалуйста, как мы сможем улучшить эту статью.
😍 Полезные IT – статьи от экспертов раз в неделю у вас в почте. Укажите свою дату рождения и мы не забудем поздравить вас.
Источник
Настольная книга по Linux/Блочные устройства
Содержание
Получение общей информации [ править ]
Вывести список действительных в данный момент блочных устройств:
… Включая информацию о подключенных файловых системах:
Вывести списки блочных устройств по идентификатору, способу подключения, метке и UUID (в последних двух случаях — только для тех устройств, где они назначены):
Вывести отдельные метаданные (UUID, метка, тип ФС, etc. ) блочных устройств:
Вывести сведения о разделах доступных носителей:
… Таблицу разделов, используемую ядром (можно использовать partprobe(8) для обновления): [1]
… Более подробную информацию о разделах устройства /dev/ sdX :
Вывести таблицу разделов MBR устройства /dev/ sdX в текстовом представлении:
… В виде, пригодном для последующего восстановления:
… Скопировать таблицу с /dev/ sdX на /dev/ sdY :
Скопировать главную загрузочную запись с устройства /dev/ sdX в файл sdX.mbr :
Считать данные температурных датчиков устройств:
… Получить эти же данные с hddtemp(8), работающего в режиме демона и обслуживающего запросы на порту 7634 :
Образы [ править ]
Снять образ устройства /dev/ sdX в файл image :
… Упакованный образ в файл image.gz ( image.bz2 , image.xz ):
Восстановить содержимое устройства /dev/ sdX из файла image (осторожно! очевидно, эта команда приведет к потере всех находящихся на устройстве данных):
Записать образ image на DVD в приводе /dev/ sr3 :
Горячее подключение [ править ]
Обнаружить и инициализировать новое устройство на порту hostA :
Удалить из системы устройство /dev/ sdX :
Проверка состояния [ править ]
Измерить производительность устройства /dev/ sdX :
Запустить процедуры самодиагностики S.M.A.R.T. для устройства /dev/ sdX :
LVM [ править ]
Вывести информацию об известных физических томах, группах, и логических томах LVM:
… Только о физических томах /dev/ sdX4 , /dev/ sdY2 :
… Только о логических томах группы vgfoo :
Активировать логический том lvbar группы vgfoo :
… Все тома группы vgfoo :
Запретить (разрешить) запись на логический том lvbar группы vgfoo :
Инициализировать устройства /dev/ sdX4 , /dev/ sdY2 как физические тома:
Создать группу томов vgfoo с использованием физических томов /dev/ sdX4 , /dev/ sdY2 :
… Удалить (осторожно! перед выполнением проверьте, что группа не содержит каких-либо имеющих значение данных):
Создать логический том lvbar объемом 4880 MiB в группе vgfoo :
… Используя только свободное пространство физических томов /dev/ sdY2 , /dev/ sdZ :
… Удалить (осторожно! перед выполнением проверьте, что том не содержит каких-либо имеющих значение данных):
Перенести данные физического тома /dev/ sdY2 на другие физические тома группы:
… На физический том /dev/ sdX4
… Исключение из группы физического тома /dev/ sdY2 :
… Включение в группу физического тома /dev/ sdZ :
Источник
Управление накопителями в Linux: основные понятия и подходы
Операционная система Linux предоставляет производительные средства и наборы инструментов для управления аппаратными устройствами, в том числе накопителями. Эта статья расскажет, как Linux представляет эти устройства и, как превратить неформатированное хранилище (raw storage) в полезное пространство.
Блочные системы хранения
Блочная система хранения (block storage) – это ещё одно название блочного устройства в Linux. Блочное устройство – это часть аппаратных средств, предназначенная для хранения данных, например жесткий диск (hard disk drive, HDD), твердотельный накопитель (solid state drive, SSD), флэш-карта памяти и т.д. Они называются блочными устройствами, так как ядро подключается к аппаратным средствам путем ссылки на блоки фиксированного размера (фрагменты пространства).
По сути, блоковая система хранения – это обычное дисковое хранилище на компьютере. После установки и настройки такая система работает как продолжение дерева текущей файловой системы и позволяет записывать или считывать информацию с диска.
Разделы диска
Дисковые разделы – один из способов разделения накопителя на меньшие единицы. Разделом называется логически выделенная часть накопителя, которую, по сути, можно воспринимать и обрабатывать как сам накопитель.
Разделение диска позволяет сегментировать доступное пространство и использовать каждый его раздел для индивидуальной цели. Это дает пользователю большую гибкость, позволяя разделить установку на несколько операционных систем, пространств подкачки или специализированных файловых систем.
Конечно, диски можно форматировать и использовать без разделения. Однако некоторые операционные системы требуют предоставить им таблицу разделов, даже если на диске есть только один раздел. Как правило, для достижения большей гибкости в дальнейшем новые диски рекомендуется заранее разделять.
MBR и GPT
При разделении диска важно учитывать формат. Как правило, при этом используются форматы MBR (Master Boot Record) и GPT (GUID Partition Table).
MBR – традиционная система дискового разделения, которая используется уже более 30 лет. Из-за её возраста в ней есть ряд серьёзных ограничений. Например, её нельзя использовать для разделения дисков, чей объём превышает 2Тб. Также MBR позволяет создать максимум четыре первичных раздела; при этом четвертый раздел, как правило, является «расширенным разделом», в котором можно создавать «логические разделы» (то есть, таким образом можно разделить последний раздел, чтобы добавить дополнительные разделы).
GPT – более современная модель разделения диска, которая пытается решить некоторые из проблем MBR. Системы, использующие GPT, могут делить диск на большее количество разделов (как правило, ограничения в этом смысле накладываются самой операционной системой). Кроме того, GPT не ограничивает размеры диска, а таблица разделов доступна в нескольких точках системы из соображений безопасности.
В большинстве случаев лучше использовать GPT (если только операционная система или наборы инструментов не подразумевают другого решения).
Форматирование и файловые системы
Ядро Linux может распознавать неформатированный диск. Но накопитель должен обязательно быть отформатированным.
Форматирование – это процедура записи на диск меток, файловой системы и другой управляющей информации для дальнейшей работы с файлами. Файловая система – это система, которая структурирует данные и управляет операциями записи и извлечения данных на диске. Без файловой системы невозможно использовать устройство для хранения файлов и выполнения любых файловых операций.
Существует множество различных форматов файловых систем. На базовом уровне все они обеспечивают похожее представление диска, но каждый из них поддерживает разные функции и механизмы для обслуживания пользователей и выполнения операций.
Наиболее популярными файловыми системами в Linux являются:
- Ext4: (четвертая версия расширенной файловой системы) самая популярная на сегодняшний день файловая система. Ext4 обеспечивает систему журналирования и обратную совместимость с существующими системами, она невероятно надёжна и имеет зрелую поддержку и инструментарий. Это отличный выбор, если у вас нет никаких особенных требований.
- XFS: специализируется на производительности и больших файлах данных. Эта файловая система быстро форматируется и предоставляет высокую пропускную способность при работе с большими файлами и дисками. Также она поддерживает быстрые снапшоты. XFS журналирует только метаданные. Это обеспечивает высокую производительность, но может привести к повреждению данных в случае резкой потери мощности.
- Btrfs: современная многофункциональная файловая система, работающая по принципу «копирование при записи» (copy-on-write). Такая архитектура позволяет интегрировать функциональные возможности управления томами на уровне файловой системы. Готовность системы Btrfs к производственным нагрузкам всё ещё остаётся предметом активного обсуждения; многие системные администраторы считают её несколько незрелой для этого.
- ZFS: современная файловая система и менеджер томов с широким и зрелым набором функций, работающий по принципу «копирование при записи». ZFS обеспечивает высокую целостность данных, может обрабатывать большие файловые системы, предоставляет функции управления томами (клонирование, создание снапшотов, систематизация томов в RAID и RAID-подобные массивы для обеспечения избыточности данных и повышения производительности). Что касается работы в Linux, ZFS имеет противоречивую историю из-за проблем с лицензированием. Несмотря на это Ubuntu поставляет двоичный модуль ядра ZFS, а Debian включает исходный код ZFS в свои репозитории. Другие дистрибутивы ещё не определились с поддержкой ZFS.
Управление устройствами хранения в Linux
Файлы устройств в /dev
Система Linux почти всё представляет в виде файлов. Это касается и аппаратных накопителей, которые представлены в системе в виде файлов в каталоге /dev. Как правило, имена файлов, представляющих устройства хранения данных, начинаются с sd или hd, после чего следует буква. Например, первый диск на сервере, как правило, будет называться примерно так: /dev/sda.
Разделы таких накопителей тоже будут иметь свои файлы в /dev. В имя такого файла входит sd или hd + буква + порядковый номер раздела. Например, первый раздел на первом диске сервера будет называться /dev/sda1.
Файлы /dev/sd* и /dev/hd* представляют традиционный способ обозначения дисков и разделов, существует значительный недостаток в использовании значений. Ядро Linux распределяет имена устройств при каждой загрузке системы, а это может привести к путанице при изменении узлов устройств.
Чтобы обойти эту проблему, каталог /dev/disk содержит подкаталоги, которые предоставляют более надёжный способ определения дисков и разделов в системе. Они содержат символические ссылки на правильные файлы /dev/[sh]da*, которые создаются при загрузке системы. В названии ссылки содержится идентифицирующий признак каталога. Эти ссылки всегда указывают на правильные устройства, потому они используются как статические идентификаторы хранилищ.
В каталоге /dev/disk могут существовать следующие подкаталоги:
- by-label: большинство файловых систем предоставляет механизмы маркировки, которые позволяют назначать произвольные имена для диска или раздела. Этот каталог хранит ссылки, названные с помощью предоставленных пользователем меток.
- by-uuid: UUID (универсально уникальные идентификаторы) – это длинные уникальные последовательности букв и цифр, которые можно использовать в качестве идентификатора для ресурса хранения. Как правило, они очень сложные для человеческого восприятия, но зато они обеспечивают уникальность (даже при работе между несколькими системами). UUID отлично подходят для создания ссылок на хранилища, которые могут мигрировать между системами, так как они устраняют конфликты имён.
- by-partlabel и by-partuuid: GPT таблицы предоставляют свой собственный набор меток и UUID. Они во многом похожи на идентификаторы из предыдущих каталогов, но используют специфические идентификаторы GPT.
- by-id: хранит ссылки, сгенерированные серийным номером устройства.
- by-path: как и by-id, этот каталог использует подключения устройств хранения к самой системе. Ссылки здесь построены на основе интерпретации системой аппаратного обеспечения, используемого для доступа к устройству. Серьёзным недостатком является то, что при подключении устройства к другому порту это значение может измениться.
Как правило, для постоянной идентификации конкретных устройств используются каталоги by-label или by-uuid.
Монтирование блочных устройств
Файлы устройств в каталоге /dev используются для обмена данными с драйвером ядра. Тем не менее, чтобы рассматривать устройство в качестве сегмента доступного пространства, требуется более удобное разделение.
В Linux и других Unix-подобных системах вся система представлена единым унифицированным деревом файлов независимо от количества физических устройств. Таким образом, когда на диске или разделе используется файловая система, её нужно подключить к существующему дереву. Монтирование – это процесс присоединения отформатированного раздела или диска к каталогу в файловой системе Linux. Доступ к содержимому накопителя можно получить с помощью этого каталога.
Устройства обычно монтируются в специальные выделенные пустые каталоги; если устройство было смонтировано в непустой каталог, то текущее содержимое этого каталога будет недоступно, пока устройство не демонтируют. Существует множество различных опций для монтирования, которые можно настроить, чтобы изменить поведение смонтированного устройства (например, открыть устройство только для чтения, чтобы защитить его данные от изменений).
Стандарт иерархии файловой системы рекомендует использовать для временно смонтированных файловых систем каталог /mnt или его подкаталоги. Однако этот стандарт не дает никаких рекомендаций относительно того, где хранить более постоянные устройства, потому вы можете выбрать для них любое удобное место. Обычно для этого также используется каталог /mnt или его подкаталоги.
Постоянное монтирование
Дистрибутивы Linux читают файл /etc/fstab, чтобы узнать, какие файловые системы нужно монтировать во время запуска. Если этот файл не содержит записи о какой-либо файловой системе, то такая файловая система не будет смонтирована автоматически. Исключение составляют только системы, которые определяются файлами .mount системы инициализации systemd.
Файл /etc/fstab достаточно прост. Каждая строка определяет блочное устройство, его точку монтирования, формат диска, параметры монтирования, а также некоторую другую информацию.
Продвинутое управление хранилищами
Большинство случаев простого использования накопителей и хранилищ не требует дополнительных структур управления. При работе со сложными парадигмами можно получить более высокую производительность, избыточность или гибкость.
Что такое RAID?
RAID (Redundant Array of Independent Disks) – это технология управления хранением данных и виртуализацией, которая позволяет сгруппировать диски и управлять ими как единым целым.
Характеристики RAID-массива зависит от уровня RAID, который определяет, как именно диски в массиве связаны друг с другом. Выбранный уровень влияет на производительность и избыточность. Наиболее распространенными уровнями являются:
- RAID 0: также известен как распределение данных. При записи данных в массив они разделяются на блоки и распределяются между дисками в наборе. Это дает прирост производительности, поскольку можно одновременно записывать или читать несколько дисков. Недостатком является то, что отказ одного диска может стать причиной потери данных всего массива, так как ни один диск не содержит достаточных для восстановления данных.
- RAID 1: технология зеркалирования. Данные, записанные в массив RAID 1, записываются на несколько дисков. Главным преимуществом такого подхода является избыточность данных, что позволяет сохранить данные даже в случае потери жёсткого диска. Поскольку несколько дисков содержат одни и те же данные, полезная емкость уменьшается наполовину.
- RAID 5: технология распределения данных (подобно RAID 0). Этот уровень также реализует распределенную четность по всем дискам. Это означает, что если диск выйдет из строя, остальные диски позволяют восстановить массив с помощью информации о четности. Этой информации достаточно, чтобы восстановить один из дисков, то есть массив может пережить потерю любого диска.
- RAID 6: обладает теми же параметрами, что и RAID 5, но использует два диска чётности. То есть, такие массивы могут переносить потерю любых двух дисков. Конечно, емкость массива зависит от четности.
- RAID 10: комбинация уровней 1 и 0 (массив RAID 0, построенный из массивов RAID 1). Этот уровень предоставляет два набора зеркальных массивов, в которых можно распределять данные. В результате получается высокопроизводительный массив, обладающий некоторыми характеристиками избыточности. Суммарная мощность такого массива составляет половину объединенного дискового пространства.
Что такое LVM?
LVM (или Logical Vvolume Management) – это система, которая абстрагирует основные физические характеристики устройств хранения данных для повышения гибкости и мощности. LVM может создавать группы физических устройств и управлять ими как единым блоком. Это позволяет по мере необходимости сегментировать пространство в логические тома, которые будут работать как разделы.
LVM реализуется на основе обычных разделов и позволяет обойти множество ограничений, присущих традиционным дисковым разделам. Например, при использовании томов LVM можно легко расширять разделы, создавать новые разделы, которые охватывают несколько дисков, создавать снапшоты и перемещать тома на разные физические диски. LVM можно комбинировать с RAID.
Дальнейшие действия
Если у вас есть новое накопительное устройство, которое вы хотите использовать в системе Linux, это руководство поможет разобраться с основами разделения дисков, форматирования и монтирования новых файловых систем. Чтобы научиться выполнять базовые операции по управлению хранилищем, читайте это руководство.
Источник



