- Как я могу удалить завершающий перевод строки в bash?
- удаление замыкающего пустые линии-SED
- Аннотация
- Другие решения
- переменная
- Память
- Две строки в памяти
- Прямая обработка
- Как я могу удалить последний символ файла в Unix?
- Как удалить последний символ из вывода bash grep
- 14 ответов
- Основные приёмы обработки строк в bash
- Термины
- Сравнение строковых переменных
- Основные операторы сравнения
- Пример скрипта для сравнения двух строковых переменных
- Создание тестового файла
- Основы работы с grep
- Синтаксис команды
- Основные опции
- Практическое применение grep
- Поиск подстроки в строке
- Вывод нескольких строк
- Чтение строки из файла с использованием регулярных выражений
- Рекурсивный режим поиска
- Точное вхождение
- Поиск нескольких слов
- Количество строк в файле
- Вывод только имени файла
- Использование sed
- Синтаксис
- Распространенные конструкции с sed
- Замена слова
- Редактирование файла
- Удаление строк из файла
- Нумерация строк
- Удаление всех чисел из текста
- Замена символов
- Обработка указанной строки
- Работа с диапазоном строк
Как я могу удалить завершающий перевод строки в bash?
Я ищу что-то похожее на Perl chomp . Я ищу команду, которая просто печатает ввод, минус последний символ, если это новая строка:
(Подстановка команд в Bash и Zsh удаляет все завершающие новые строки, но я ищу что-то, что максимально удаляет одну завершающую новую строку.)
Это должно работать:
Скрипт всегда печатает предыдущую строку вместо текущей, а последняя строка обрабатывается по-разному.
Что это делает более подробно:
- NR>1
Распечатать предыдущую строку (кроме первого раза). - END
Также обратите внимание, что это приведет к удалению не более одной пустой строки в конце (без поддержки удаления «one\ntwo\n\n\n» ).
Вы можете использовать perl без chomp :
Но почему бы не использовать chomp себя:
Если вам нужен точный эквивалент chomp , первым методом, который мне приходит в голову, является решение awk, которое уже выложил LatinSuD . Я добавлю некоторые другие методы, которые не реализуют, chomp но реализуют некоторые общие задачи, которые chomp часто используются для.
Когда вы помещаете некоторый текст в переменную, все символы новой строки в конце удаляются. Таким образом, все эти команды выдают одинаковый однострочный вывод:
Если вы хотите добавить какой-либо текст в последнюю строку файла или вывода команды, это sed может быть удобно. С GNU sed и большинством других современных реализаций это работает, даже если ввод не заканчивается новой строкой¹; однако, это не добавит новую строку, если ее еще не было.
¹ Однако это не работает со всеми реализациями sed: sed — это инструмент обработки текста, а файл, который не пуст и не заканчивается символом перевода строки, не является текстовым файлом.
Другой perl подход. Он считывает весь ввод в память, поэтому он не может быть хорошей идеей для больших объемов данных (используйте cuonglm или awk подход для этого):
Я поймал это где-то в репозитории github, но не могу найти где
удаление замыкающего пустые линии-SED
Аннотация
Печатайте строки без новой строки, добавляйте новую строку, только если есть еще одна строка для печати.
Другие решения
Если мы работали с файлом, мы можем просто обрезать один символ из него (если он заканчивается на новой строке):
Это быстрое решение, так как нужно прочитать только один символ из файла, а затем удалить его напрямую ( truncate ), не читая весь файл.
Однако при работе с данными из stdin (потока) все данные должны быть прочитаны. И это «потребляется», как только это прочитано. Нет возврата (как с усечением). Чтобы найти конец потока, нам нужно прочитать его до конца. В этот момент нет возможности вернуться назад к входному потоку, данные уже «использованы». Это означает, что данные должны храниться в некотором виде буфера до тех пор, пока мы не совпадем с концом потока, а затем что-то сделаем с данными в буфере.
Наиболее очевидным из решений является преобразование потока в файл и обработка этого файла. Но вопрос требует какого-то фильтра потока. Не об использовании дополнительных файлов.
переменная
Наивным решением было бы захватить весь ввод в переменную:
Память
Можно загрузить весь файл в память с помощью sed. В sed невозможно избежать завершающего перевода строки на последней строке. GNU sed может не печатать завершающий символ новой строки, но только если в исходном файле его уже нет. Так что нет, простой sed не может помочь.
За исключением GNU awk с -z опцией:
С помощью awk (любой awk) хлебать весь поток, и printf это без завершающего перевода строки.
Загрузка всего файла в память может быть не очень хорошей идеей, поскольку она может занимать много памяти.
Две строки в памяти
В awk мы можем обработать две строки в цикле, сохранив предыдущую строку в переменной и напечатав текущую:
Прямая обработка
Но мы могли бы сделать лучше.
Если мы печатаем текущую строку без новой строки и печатаем новую только тогда, когда существует следующая строка, мы обрабатываем по одной строке за раз, и последняя строка не будет иметь завершающий символ новой строки:
Источник
Как я могу удалить последний символ файла в Unix?
Скажем, у меня есть произвольный многострочный текстовый файл:
Как я могу удалить только последний символ (e, а не символ новой строки или ноль) файла, не делая текстовый файл недействительным?
Более простой подход (выводит в stdout, не обновляет входной файл):
- $ — это адрес Sed, который соответствует только последней строке ввода, поэтому следующий вызов функции ( s/.$// ) будет выполняться только в последней строке.
- s/.$// заменяет последний символ в строке (в данном случае last) пустой строкой; т.е. эффективно удаляет последний символ. (до новой строки) на строке.
. сопоставляет любой символ в строке, а после него $ привязывает совпадение к концу строки; обратите внимание, что использование $ в этом регулярном выражении концептуально связано, но технически отличается от предыдущего использования $ в качестве Sed address.
Пример с вводом stdin (предполагает Bash, Ksh или Zsh):
Для обновления входного файла тоже (не используйте, если входной файл является символической ссылкой):
Замечания:
* В OSX вам придется использовать -i » вместо просто -i ; для обзора ловушек, связанных с -i , смотрите нижнюю половину мой ответ здесь .
* Если вам нужно обрабатывать очень большие входные файлы и/или производительность/использование диска вызывает озабоченность и вы используете утилиты GNU (Linux), см. полезный ответ sorontar .
truncate
Удаляет один (-1) символ из конца того же файла. Точно так же, как >> добавит к тому же файлу.
Проблема с этим подходом состоит в том, что он не сохраняет завершающий символ новой строки, если он существует.
Это работает, потому что tail занимает последний байт (не char).
Это занимает почти нет времени даже с большими файлами.
Почему бы не sed
Проблема с решением sed, таким как sed ‘$ s/.$//’ file , заключается в том, что сначала он читает весь файл (что занимает много времени с большими файлами), затем вам нужен временный файл (того же размера, что и оригинал):
А затем переместите временный файл для замены файла.
Вот еще один пример использования ex , который я считаю не таким загадочным, как решение sed:
$ идет до последней строки, s удаляет последний символ, а wq — это хорошо известная (для пользователей vi) запись + выход.
Если цель состоит в том, чтобы удалить последний символ в последней строке, эта awk должна сделать:
Он сохраняет все данные в массив, затем распечатывает их и изменяет последнюю строку.
Просто замечание: sed временно удалит файл . Поэтому, если вы настраиваете файл, вы получите предупреждение «Нет такого файла или каталога», пока вы не повторите команду tail.
Отредактированный ответ
Я создал скрипт и разместил ваш текст внутри на рабочем столе. этот тестовый файл сохраняется как «old_file.txt»
После этого я написал небольшой скрипт, чтобы взять старый файл и удалить последний символ в последней строке
открывая созданный мной новый_файл, показал вывод следующим образом:
Я прошу прощения за мой предыдущий ответ (не читал внимательно)
После целого ряда игр с разными стратегиями (и избегая sed -i или Perl), лучший способ, который я нашел для этого, был с:
Источник
Как удалить последний символ из вывода bash grep
выводит что-то вроде этого
что я хочу сделать, так это удалить трейлинг»;». Как я могу это сделать? Я новичок в bash. Любые мысли или предложения были бы полезны.
14 ответов
Я хотел бы использовать sed ‘s/;$//’ . например:
это удалит последний символ, содержащийся в вашем COMPANY_NAME var, независимо от того, является ли он точкой с запятой:
Я хотел бы использовать head —bytes -1 или head -c-1 для краткости.
head выводит только начало потока или файла. Обычно он подсчитывает строки, но вместо этого его можно сделать для подсчета символов/байтов. head —bytes 10 выводит первые десять символов, но head —bytes -10 выведет все, кроме последних десяти.
Примечание: Вы можете иметь проблемы, если последним символом является многобайтовой, но запятой не
Я бы рекомендовал это решение sed или cut потому что
- это точно head был разработан, чтобы сделать, таким образом, меньше параметров командной строки и проще для чтения команды
- это избавляет вас от необходимости думать о регулярных выражениях, что это круто/мощный, но часто перебор
- это экономит вашу машину, чтобы думать о регулярных выражениях, так что будет незаметно быстрее
Я считаю, что самый чистый способ удалить один символ из строки с bash:
но я не смог вставить часть grep в фигурные скобки, поэтому ваша конкретная задача становится двухстрочной:
это очистит любой символ, точку с запятой или нет,но может избавиться от точки с запятой специально. Чтобы удалить все точки с запятой, куда бы они ни падали:
удалить только точку с запятой в конец:
или, чтобы удалить несколько точек с запятой в конце:
для большей детализации и больше на этом подходе, проект документации Linux охватывает много земли на http://tldp.org/LDP/abs/html/string-manipulation.html
используя sed , Если вы не знаете, какой последний символ на самом деле:
не злоупотребляйте cat s. Вы знали, что grep может читать файлы, тоже?
канонический подход будет следующим:
более умный подход будет использовать один perl или awk оператор, который может выполнять фильтрацию и различные преобразования сразу. Например что-то вроде этого:
Не нужно связывать так много инструментов. Только одна команда awk делает работу
Источник
Основные приёмы обработки строк в bash
Работа со строками в bash осуществляется при помощи встроенных в оболочку команд.
Термины
- Консольные окружения — интерфейсы, в которых работа выполняется в текстовом режиме.
- Интерфейс — механизм взаимодействия пользователя с аппаратной частью компьютера.
- Оператор — элемент, задающий законченное действие над каким-либо объектом операционной системы (файлом, папкой, текстовой строкой и т. д.).
- Текстовые массивы данных — совокупность строк, записанных в переменную или файл.
- Переменная — поименованная область памяти, позволяющая осуществлять запись и чтение данных, которые в нее записываются. Она может принимать любые значения: числовые, строковые и т. д.
- Потоковый текстовый редактор — программа, поддерживающая потоковую обработку текстовой информации в консольном режиме.
- Регулярные выражения — формальный язык поиска части кода или фрагмента текста (в том числе строки) для дальнейших манипуляций над найденными объектами.
- Bash-скрипты — файл с набором инструкций для выполнения каких-либо манипуляций над строкой, текстом или другими объектами операционной системы.
Сравнение строковых переменных
Для выполнения операций сопоставления 2 строк (str1 и str2) в ОС на основе UNIX применяются операторы сравнения.
Основные операторы сравнения
- Равенство « = »: оператор возвращает значение «истина» («TRUE»), если количество символов в строке соответствует количеству во второй.
- Сравнение строк на эквивалентность « == »: возвращается «TRUE», если первая строка эквивалентна второй ( дом == дом ).
- Неравенство «str1 != str2»: «TRUE», если одна строковая переменная не равна другой по количеству символов.
- Неэквивалентность «str1 !== str2»: «TRUE», если одна строковая переменная не равна другой по смысловому значению ( дерево !== огонь ).
- Первая строка больше второй «str1 > str2»: «TRUE», когда str1 больше str2 по алфавитному порядку. Например, « дерево > огонь » , поскольку литера «д» находится ближе к алфавитному ряду, чем «о».
- Первая строка меньше второй «str1 str2»: «TRUE», когда str1 меньше str2 по алфавитному порядку. Например, « огонь », поскольку «о» находится дальше к началу алфавитного ряда, чем «д».
- Длина строки равна 0 « -z str2»: при выполнении этого условия возвращается «TRUE».
- Длина строки отлична от нулевого значения « -n str2»: «TRUE», если условие выполняется.
Пример скрипта для сравнения двух строковых переменных
- Чтобы сравнить две строки, нужно написать bash-скрипт с именем test .

- Далее необходимо открыть терминал и запустить test на выполнение командой:
- Предварительно необходимо дать файлу право на исполнение командой:
- После указания пароля скрипт выдаст сообщение на введение первого и второго слова. Затем требуется нажать клавишу «Enter» для получения результата сравнения.


Создание тестового файла
Обработка строк не является единственной особенностью консольных окружений Ubuntu. В них можно обрабатывать текстовые массивы данных.
- Для практического изучения команд, с помощью которых выполняется работа с текстом в интерпретаторе bash, необходимо создать текстовый файл txt .
- После этого нужно наполнить его произвольным текстом, разделив его на строки. Новая строка не должна сливаться с другими элементами.
- Далее нужно перейти в директорию, в которой находится файл, и запустить терминал с помощью сочетания клавиш — Ctrl+Alt+T.
Основы работы с grep
Поиск строки в файле операционной системы Linux Ubuntu осуществляется посредством специальной утилиты — grep . Она позволяет также отфильтровать вывод информации в консоли. Например, вывести все ошибки из log-файла утилиты ps или найти PID определенного процесса в ее отчете.
Команда grep работает с шаблонами и регулярными выражениями. Кроме того, она применяется с другими командами интерпретатора bash.
Синтаксис команды
Для работы с утилитой grep необходимо придерживаться определенного синтаксиса
- grep [options] pattern [file_name1 file_name2 file_nameN] (где «options» — дополнительные параметры для указания настроек поиска и вывода результата; «pattern» — шаблон, представляющий строку поиска или регулярное выражение, по которым будет осуществляться поиск; «file_name1 file_name2 file_nameN» — имя одного или нескольких файлов, в которых производится поиск).
- instruction | grep [options] pattern (где «instruction» — команда интерпретатора bash, «options» — дополнительные параметры для указания настроек поиска и вывода результата, «pattern» — шаблон, представляющий строку поиска или регулярное выражение, по которым будет производиться поиск).
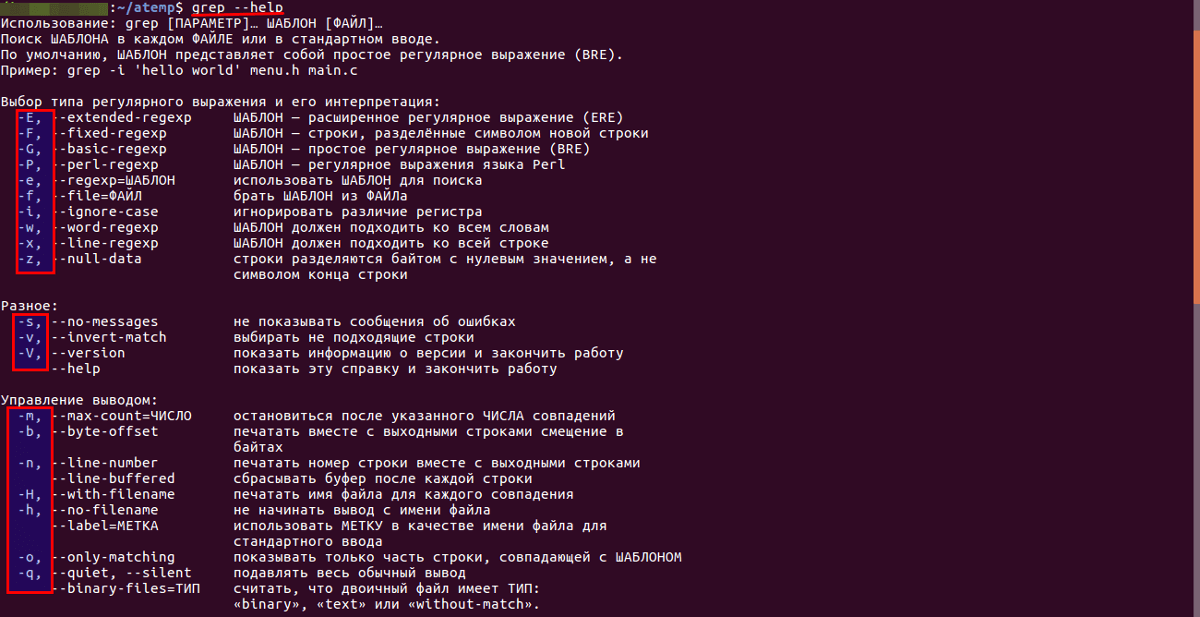
Основные опции
- Отобразить в консоли номер блока перед строкой — -b .
- Число вхождений шаблона строки — -с .
- Не выводить имя файла в результатах поиска — -h .
- Без учета регистра — -i .
- Отобразить только имена файлов с совпадением строки — -l .
- Показать номер строки — -n .
- Игнорировать сообщения об ошибках — -s .
- Инверсия поиска (отображение всех строк, в которых не найден шаблон) — -v .
- Слово, окруженное пробелами, — -w .
- Включить регулярные выражения при поиске — -e .
- Отобразить вхождение и N строк до и после него — -An и -Bn соответственно.
- Показать строки до и после вхождения — -Cn .
Практическое применение grep
Поиск подстроки в строке

В окне терминала выводятся все строки, содержащие подстроку. Найденные совпадения подсвечиваются другим цветом.
- С учетом регистра:
- Без учета регистра:
Вывод нескольких строк
- Строка с вхождением и две после нее:
- Строка с вхождением и три до нее:
- Строка, содержащая вхождение, и одну до и после нее:
Чтение строки из файла с использованием регулярных выражений
Регулярные выражения расширяют возможности поиска и позволяют выполнить разбор строки на отдельные элементы. Они активируются при помощи ключа -e.
- Вывод строки, в начале которой встречается слово «Фамилия».
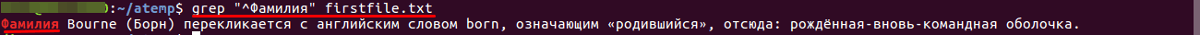 В регулярных выражения для обозначения начала строки используется специальный символ «^».
В регулярных выражения для обозначения начала строки используется специальный символ «^». Чтобы вывести первый символ строки, нужно воспользоваться конструкцией
grep «оболочка$» firstfile.txt Если требуется вывести символ конца строки, то следует применять конструкцию
grep «а.$» firstfile.txt . В этом случае будут выведены все строки, заканчивающиеся на литеру «а».

Если воспользоваться числовыми интервалами, то можно вывести все строки, в которых встречаются числа:
Рекурсивный режим поиска
- Чтобы найти строку или слово в нескольких файлах, расположенных в одной папке, нужно использовать рекурсивный режим поиска:
- Если нет необходимости выводить имена файлов, содержащих искомую строку, то можно воспользоваться ключом-параметром деактивации отображения имен:
Точное вхождение
При поиске союза «и» grep будет выводить все строки, в которых он содержится. Чтобы этого избежать, требуется использовать специальный ключ « w »:
Поиск нескольких слов
Утилита «w» позволяет искать не только одно слово, но и несколько одновременно
Количество строк в файле
При помощи grep можно определить число вхождений строки или подстроки в текстовом файле и вывести ее номер.

- Число вхождений:
- Номера строк с совпадениями:
Инверсия
Если в тексте требуется найти определенные строки, которые не содержат какого-либо слова или подстроки, то рекомендуется использовать инверсионный режим поиска.
Вывод только имени файла
Чтобы не выводить все строки с совпадением, а вывести только имя файла, нужно воспользоваться конструкцией:
Использование sed
Потоковый текстовый редактор « sed » встроен в bash Linux Ubuntu. Он использует построчное чтение, а также позволяет выполнить фильтрацию и преобразование текста.
Синтаксис
Для работы с потоковым текстовым редактором sed используется следующий синтаксис:
sed [options] instructions [file_name] (где «options» — ключи-опции для указания метода обработки текста, «instructions» — команда, совершаемая над найденным фрагментом текста, «file_name» — имя файла, над которым совершаются действия).
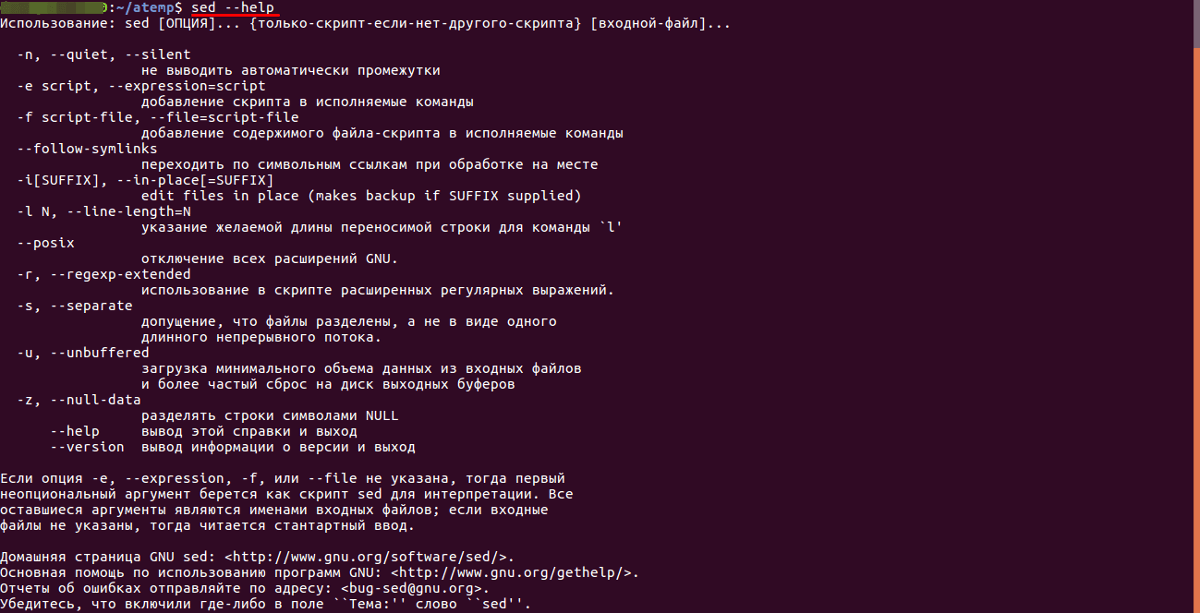
Для вывода всех опций потокового текстового редактора нужно воспользоваться командой:
Распространенные конструкции с sed
Замена слова
Например, если требуется заменить строку в файле или слово с «команды» на «инструкции». Для этого нужно воспользоваться следующими конструкциями:
- Для первого вхождения:
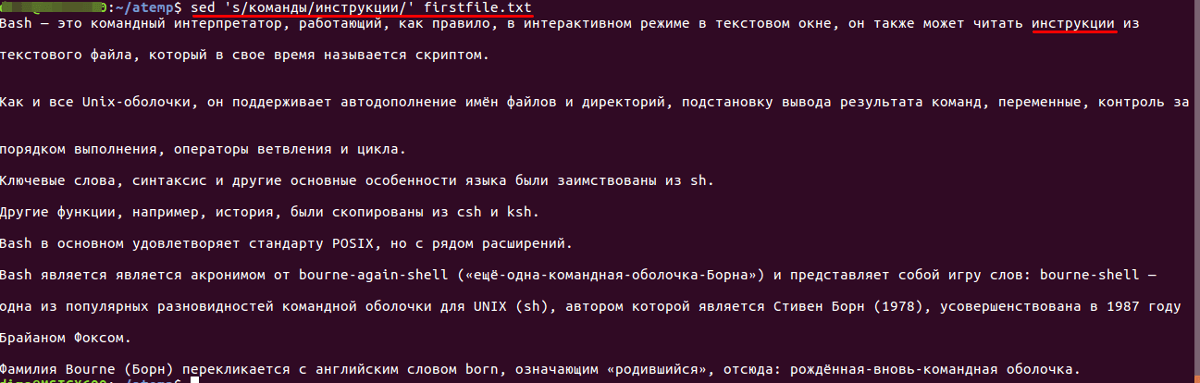
Произвести замену только в строках, которые заканчиваются на«Bash»:
Редактирование файла
Чтобы записать строку в файл, нужно указать параметр замены одной строки на другую, воспользовавшись ключом — -i :
После выполнения команды произойдет замена слова «команды» на «инструкции» с последующим сохранением файла.
Удаление строк из файла
- Удалить первую строку из файла:
- Удалить строку из файла, содержащую слово«окне»:
После выполнения команды будет удалена первая строка, поскольку она содержит указанное слово.
Нумерация строк
Строки в файле будут пронумерованы следующим образом: первая строка — 1, вторая — 2 и т. д.
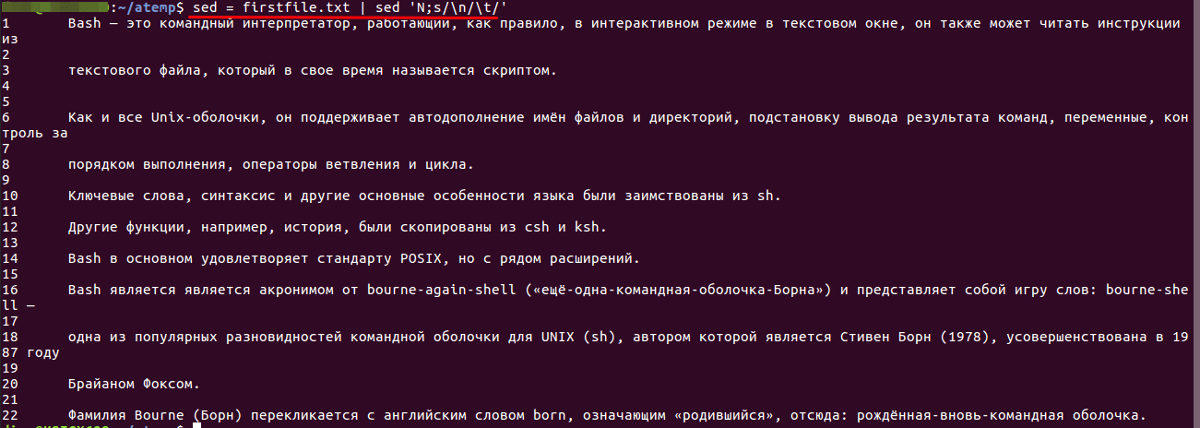
Следует обратить внимание, что нумерация начинается не с «0», как в языках программирования.
Удаление всех чисел из текста
Замена символов
Чтобы заменить набор символов, нужно воспользоваться инструкцией, содержащей команду « y »:
Обработка указанной строки
Утилита производит манипуляции не только с текстом, но и со строкой, указанной в правиле шаблона (3 строка):
Работа с диапазоном строк
Для выполнения замены только в 3 и 4 строках нужно использовать конструкцию:
Вставка содержимого файла после строки
Иногда требуется вставить содержимое одного файла (input_file.txt) после определенной строки другого (firstfile.txt). Для этой цели используется команда:
sed ‘5r input_file.txt’ firstfile.txt (где «5r» — 5 строка, «input_file.txt» — исходный файл и «firstfile.txt» — файл, в который требуется вставить массив текста).
Начни экономить на хостинге сейчас — 14 дней бесплатно!
Источник



