Поддержка Юникода Support for Unicode
Юникод — это спецификация для поддержки всех наборов символов, включая те, которые не могут быть представлены в одном байте. Unicode is a specification for supporting all character sets, including ones that can’t be represented in a single byte. При программировании на международном рынке рекомендуется использовать либо Юникод, либо многобайтовую кодировку (MBCS). If you’re programming for an international market, we recommend you use either Unicode or a multibyte character set (MBCS). Или постройте программу, чтобы ее можно было создать путем изменения параметра. Or, code your program so you can build it for either by changing a switch.
Расширенный символ — это двухбайтовый многоязыковой код символа. A wide character is a 2-byte multilingual character code. Десятки тысяч символов, включающие почти все символы, используемые в современных вычислениях во всем мире, включая технические символы и специальные символы публикации, могут быть представлены в соответствии со спецификацией Юникода в виде одного расширенного символа, закодированного с помощью UTF-16. Tens of thousands of characters, comprising almost all characters used in modern computing worldwide, including technical symbols and special publishing characters, can be represented according to the Unicode specification as a single wide character encoded by using UTF-16. Символы, которые не могут быть представлены только в одном расширенном символе, можно представить в паре Юникода с помощью суррогатной пары Юникода. Characters that cannot be represented in just one wide character can be represented in a Unicode pair by using the Unicode surrogate pair feature. Поскольку почти каждый символ в общем использовании представлен в кодировке UTF-16 в одном 16-разрядном расширенном символе, использование расширенных символов упрощает программирование с использованием международных наборов символов. Because almost every character in common use is represented in UTF-16 in a single 16-bit wide character, using wide characters simplifies programming with international character sets. Широкие символы, закодированные с помощью UTF-16LE (для прямого порядка байтов), являются собственными символьными форматами для Windows. Wide characters encoded using UTF-16LE (for little-endian) are the native character format for Windows.
Строка расширенных символов представляется как массив wchar_t[] , и на нее указывает указатель wchar_t* . A wide-character string is represented as a wchar_t[] array and is pointed to by a wchar_t* pointer. Любой символ ASCII может быть представлен как расширенный символ путем добавления к нему префикса «L». Any ASCII character can be represented as a wide character by prefixing the letter L to the character. Например, «L’\0′» является шестнадцатибитным расширенным символом для значения NULL. For example, L’\0′ is the terminating wide (16-bit) NULL character. Подобным образом все строковые литералы, составленные из символов ASCII, могут быть представлены как строковые литералы из расширенных символов путем добавления к литералу ASCII префикса «L» (L»Hello»). Similarly, any ASCII string literal can be represented as a wide-character string literal by prefixing the letter L to the ASCII literal (L»Hello»).
Как правило, расширенные символы занимают больше памяти, чем многобайтовые символы, однако они обрабатываются быстрее. Generally, wide characters take more space in memory than multibyte characters but are faster to process. Кроме того, в многобайтовой кодировке может быть представлен только один языковой стандарт, в то время как все наборы символов в мире представлены одновременно в представлении Юникода. In addition, only one locale can be represented at a time in a multibyte encoding, whereas all character sets in the world are represented simultaneously by the Unicode representation.
Поддержка Юникода обеспечивается для всех компонентов платформы MFC. MFC обеспечивает поддержку Юникода с помощью переносимых макросов, как показано в следующей таблице. The MFC framework is Unicode-enabled throughout, and MFC accomplishes Unicode enabling by using portable macros, as shown in the following table.
Типы переносимых данных в MFC Portable Data Types in MFC
| Непереносимый тип данных Non-portable data type | Макрос, которым он заменяется Replaced by this macro |
|---|---|
| char , wchar_t char , wchar_t | _TCHAR |
| char* , LPSTR (Тип данных Win32), LPWSTR char* , LPSTR (Win32 data type), LPWSTR | LPTSTR |
| const char* , LPCSTR (Тип данных Win32), LPCWSTR const char* , LPCSTR (Win32 data type), LPCWSTR | LPCTSTR |
Класс CString использует _TCHAR в качестве базового и предоставляет конструкторы и операторы для простоты преобразований. Class CString uses _TCHAR as its base and provides constructors and operators for easy conversions. Большинство операций со строками Юникода может быть написано с помощью средств, которые используются для обработки кодировки Windows ANSI. Единственным отличием является то, что основной единицей операции является шестнадцатибитный символ, а не восьмибитный. Most string operations for Unicode can be written by using the same logic used for handling the Windows ANSI character set, except that the basic unit of operation is a 16-bit character instead of an 8-bit byte. В отличие от многобайтовых кодировок нет необходимости (и не следует) обрабатывать символы Юникода как два отдельных байта. Unlike working with multibyte character sets, you do not have to (and should not) treat a Unicode character as if it were two distinct bytes. Однако необходимо иметь дело с возможностью использования одного символа, представленного суррогатной парой расширенных символов. You do, however, have to deal with the possibility of a single character represented by a surrogate pair of wide characters. Как правило, не следует писать код, который предполагает, что длина строки совпадает с количеством символов, будь то узкие или широкие, которые она содержит. In general, do not write code that assumes the length of a string is the same as the number of characters, whether narrow or wide, that it contains.
Unicode
Unicode is a worldwide character-encoding standard. The system uses Unicode exclusively for character and string manipulation. For a detailed description of all aspects of Unicode, refer to The Unicode Standard.
Compared to older mechanisms for handling character and string data, Unicode simplifies software localization and improves multilingual text processing. By using Unicode to represent character and string data in your applications, you can enable universal data exchange capabilities for global marketing, using a single binary file for every possible character code. Unicode does the following:
- Allows any combination of characters, drawn from any combination of scripts and languages, to co-exist in a single document.
- Defines semantics for each character.
- Standardizes script behavior.
- Provides a standard algorithm for bidirectional text.
- Defines cross-mappings to other standards.
- Defines multiple encodings of its single character set: UTF-7, UTF-8, UTF-16, and UTF-32. Conversion of data among these encodings is lossless.
Unicode supports numerous scripts used by languages around the world, and also a large number of technical symbols and special characters used in publishing. The supported scripts include, but are not limited to, Latin, Greek, Cyrillic, Hebrew, Arabic, Devanagari, Thai, Han, Hangul, Hiragana, and Katakana. Supported languages include, but are not limited to, German, French, English, Greek, Russian, Hebrew, Arabic, Hindi, Thai, Chinese, Korean, and Japanese. Unicode currently can represent the vast majority of characters in modern computer use around the world, and continues to be updated to make it even more complete.
Unicode-enabled functions are described in Conventions for Function Prototypes. These functions use UTF-16 (wide character) encoding, which is the most common encoding of Unicode and the one used for native Unicode encoding on Windows operating systems. Each code value is 16 bits wide, in contrast to the older code page approach to character and string data, which uses 8-bit code values. The use of 16 bits allows the direct encoding of 65,536 characters. In fact, the universe of symbols used to transcribe human languages is even larger than that, and UTF-16 code points in the range U+D800 through U+DFFF are used to form surrogate pairs, which constitute 32-bit encodings of supplementary characters. See Surrogates and Supplementary Characters for further discussion.
The Unicode character set includes numerous combining characters, such as U+0308 («ВЁ»), a combining dieresis or umlaut. Unicode can often represent the same glyph in either a »composed» or a »decomposed» form: for example, the composed form of «Г„» is the single Unicode code point «Г„» (U+00C4), while its decomposed form is «A» + «ВЁ» (U+0041 U+0308). Unicode does not define a composed form for every glyph. For example, the Vietnamese lowercase «o» with circumflex and tilde («oМ‚Мѓ») is represented by U+006f U+0302 U+0303 (o + Circumflex + Tilde). For further discussion of combining characters and related issues, see Using Unicode Normalization to Represent Strings.
For compatibility with 8-bit and 7-bit environments, Unicode can also be encoded as UTF-8 and UTF-7, respectively. While Unicode-enabled functions in Windows use UTF-16, it is also possible to work with data encoded in UTF-8 or UTF-7, which are supported in Windows as multibyte character set code pages.
New Windows applications should use UTF-16 as their internal data representation. Windows also provides extensive support for code pages, and mixed use in the same application is possible. Even new Unicode-based applications sometimes have to work with code pages. Reasons for this are discussed in Code Pages.
An application can use the MultiByteToWideChar and WideCharToMultiByte functions to convert between strings based on code pages and Unicode strings. Although their names refer to «MultiByte», these functions work equally well with single-byte character set (SBCS), double-byte character set (DBCS), and multibyte character set (MBCS) code pages.
Typically, a Windows application should use UTF-16 internally, converting only as part of a «thin layer» over the interface that must use another format. This technique defends against loss and corruption of data. Each code page supports different characters, but none of them supports the full spectrum of characters provided by Unicode. Most of the code pages support different subsets, differently encoded. The code pages for UTF-8 and UTF-7 are an exception, since they support the complete Unicode character set, and conversion between these encodings and UTF-16 is lossless.
Data converted directly from the encoding used by one code page to the encoding used by another is subject to corruption, because the same data value on different code pages can encode a different character. Even when your application is converting as close to the interface as possible, you should think carefully about the range of data to handle.
Data converted from Unicode to a code page is subject to data loss, because a given code page might not be able to represent every character used in that particular Unicode data. Therefore, note that WideCharToMultiByte might lose some data if the target code page cannot represent all of the characters in the Unicode string.
When modernizing code page-based legacy applications to use Unicode, you can use generic functions and the TEXT macro to maintain a single set of sources from which to compile two versions of your application. One version supports Unicode and the other one works with Windows code pages. Using this mechanism, you can convert even very large applications from Windows code pages to Unicode while maintaining application sources that can be compiled, built, and tested at all phases of the conversion. For more information, see Conventions for Function Prototypes.
Unicode characters and strings use data types that are distinct from those for code page-based characters and strings. Along with a series of macros and naming conventions, this distinction minimizes the chance of accidentally mixing the two types of character data. It facilitates compiler type checking to ensure that only Unicode parameter values are used with functions expecting Unicode strings.
How to display Unicode languages in Windows
— September 5, 2014
Languages like Chinese, Korean, and Vietnamese, based on symbols as opposed to letters, can frequently run into display issues on Windows.
Displaying these language symbols requires a standard system called Unicode, which according to Wikipedia, “is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world’s writing systems.” The standard includes a big set of languages including right-to-left scripts like Arabic.
If you want to display foreign languages in Windows, however, the operating system isn’t always the problem. Some programs aren’t designed to display different languages. On the web, browsers take encoding information from the website, but if the browser can’t read the correct information, then Unicode won’t display properly.
This doesn’t mean that you can’t display them though. To get Unicode to display in Windows and your browser only takes a few steps.
Windows Region Settings
A frequent problem is programs that don’t support Unicode, but making it work is actually quite simple.
Go to Control Panel and locate Clock, Language, and Region.
Select Change location.
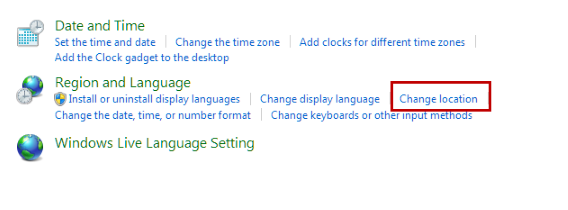
The Region and Language menu will open. Choose the Administrative tab. In this tab, you’ll see Language for non-Unicode programs. Select Change system locale. Note that you need to be the administrator to change the system locale.
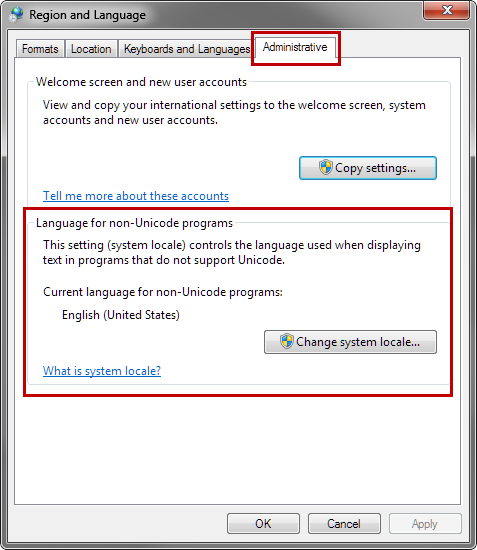
Choose the appropriate location for the language you want to display. You may need to restart Windows for the changes to apply. Now, you should be able to view the language that wasn’t previously displaying in the program.
Generally, you won’t ever need to change this setting for recent programs, but older programs may have problems.
Check out the video tutorial below for changing language in Windows 8.
Google Chrome
If you upgraded to Chrome 64-bit, there may be a bug within Chrome that’s causing errors when displaying Unicode. I found this problem when trying to read Korean. The fix that appears to be working is disabling DirectWrite within the developer section of Chrome 64-bit.
If you’re using an older version, you may still have some problems, but here’s how to display Unicode within Chrome.
Auto-detect encoding in Chrome
Chrome has built-in support for a lot of languages, and it can get annoying to switch between them. The best option is to set Chrome to Auto detect language encoding. Follow this flow to select the auto detect option:
Chrome Menu (three bars) > Tools > Encoding > Auto detect.
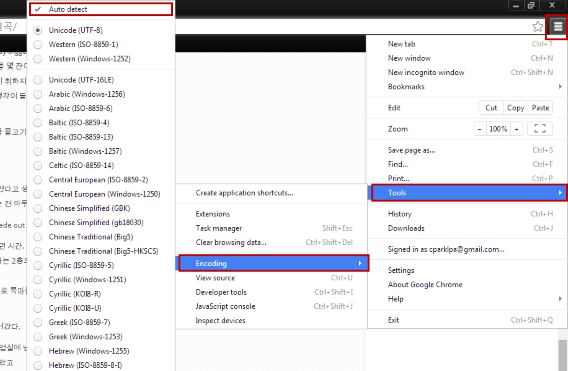
This can impact Chrome’s speed because it has to check every site you visit, but it shouldn’t get to the point where you notice a huge drop in performance.
Mozilla Firefox
Recent versions of Firefox don’t have direct options to control Unicode. Instead, the browser can allow sites to choose their own fonts. This is active by default, but here’s how to make sure the option is enabled.
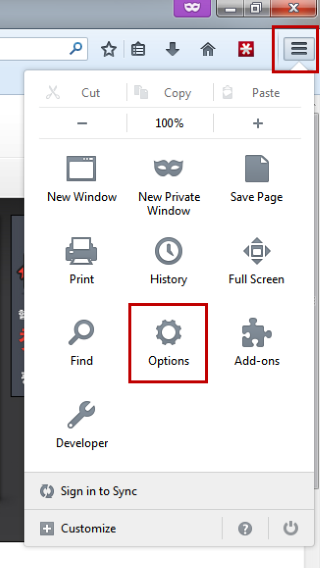
Select the options menu (three bars) and click on Options. Under the Content tab select Advanced.
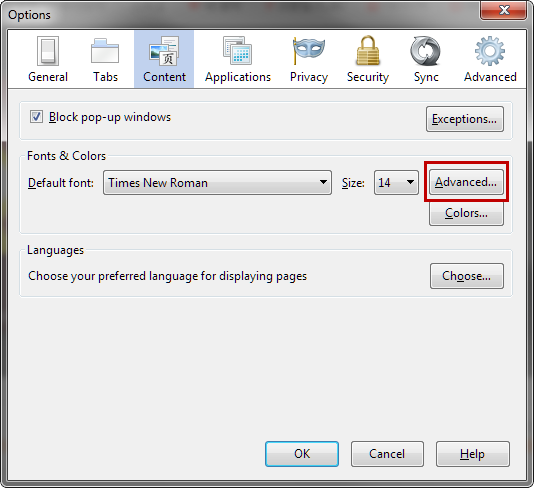
Under Advanced is the Fonts option, where you can set default fonts.
Under the set of fonts, check to see if Allow pages to choose their own fonts, instead of my selections above is selected. If that option isn’t checked, Firefox will display the fonts selected above that, which can make pages display incorrectly.
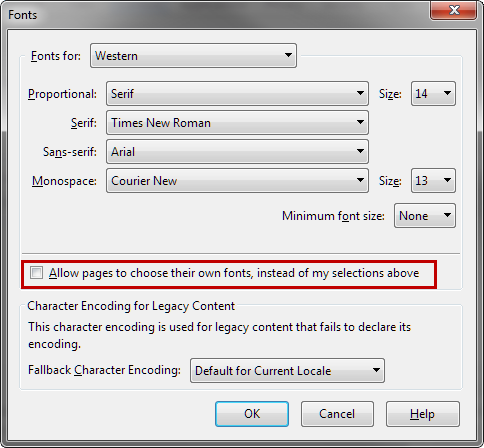
With the option selected, Firefox will display the site’s fonts. In the case of Unicode, Firefox should be able to display any Unicode fonts that exist.
Internet Explorer
If you use Internet Explorer, then you have a similar option like in Chrome. You will need to use the Menu bar, which isn’t shown by default in Internet Explorer 11. Enable the Menu bar by right-clicking with the mouse in the header.
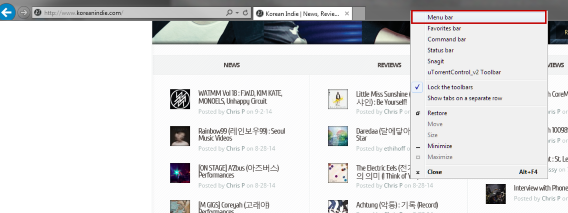
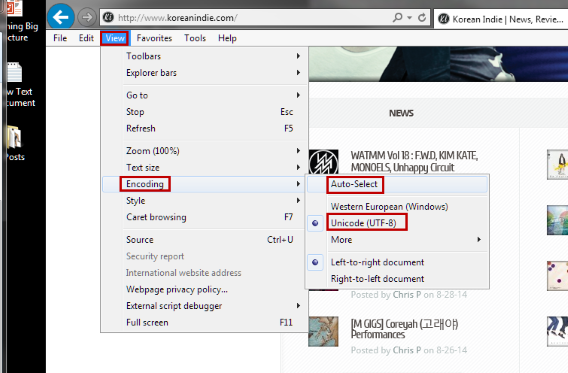
Click on View, then find Encoding. By default, Internet Explorer 11 has selected Unicode (UTF-8) and that should cover most languages. If you ever run into a problem, you can enable Auto-Select. This option will automatically choose the correct encoding for the page.
Unicode compatible
Unicode isn’t something people think about if they view the same pages all the time, but if you know another language and browse other sites, you can run into this problem. Although most programs support multiple languages, and web browsers are designed with Unicode support, the problems can emerge with older programs or sites that don’t push the right information.
You shouldn’t have issues with Unicode if you’re running the latest software, but there are always possible problems like the case of Chrome 64-bit. Make sure that when you update your browsers, you check the settings to make sure they aren’t changed, or you could run into problems.



