- Управление памятью в Linux
- Cached
- dentry/inode caches
- Buffer Cache
- Отображение памяти в команде top: VIRT, RES и SHR
- Подкачка памяти — swap
- Кэширование памяти swap (Swap Cach)
- Подкачка памяти
- Заключение
- Управление памятью в Linux
- Типы адресов
- Физические адреса и страницы
- Верхняя и нижняя память
- Карта памяти и структура page
- Таблицы страниц
- Области виртуальной памяти
- Структура vm_area_struct
- Карта памяти процесса
Управление памятью в Linux
Я думаю, что обычно у каждого пользователя Linux рано или поздно возникает следующий вопрос, задаваемый при администрировании рабочей станции или сервера — «Почему в Linux используется вся моя оперативная память, хотя никакой большой работы не выполняется? «. К нему сегодня я добавлю еще один вопрос, который, я уверен, обычен для многих системных администраторов Linux — «Почему команда free показывает память swap и почему у меня так много свободной оперативной памяти?», так что сегодняшнее мое исследование SwapCached, которое я представляю вам, может оказаться полезным, либо, по крайней мере, ознакомит, как я надеюсь, с информацией об управлении памятью в системе Linux.
В Linux применяется следующее основное правило: неиспользуемая страница оперативной памяти считается потерянной памятью. Оперативная память тратится не только для данных, используемых прикладными приложениями. В ней также хранятся данные для самого ядра и, самое главное, в эту память могут отображаться данные, хранящиеся на жестком диске, что используется для супер-быстрого к ним доступа — команда top указывает об этом в столбцах «buffers/cache» («буферы / кэш»), «disk cache» («дисковый кэш)» или «cached» («кэшировано»). Кэшированная память по сути свободна, поскольку ее можно быстро освободить в случае, если работающей (или только что запущенной) программе потребуется память.
Сохранение кэша означает, что если кому-нибудь еще раз потребуются те же самые данные, то есть большая вероятность, что они все еще будут находиться в кэше в оперативной памяти.
Поэтому первое, чем можно воспользоваться в вашей системе, это команда free , которая предоставит вам первоначальную информацию о том, как используется ваша оперативная память.
Ниже приведены данные, выдаваемые на моем старом ноутбуке с системой Xubuntu:
В строке -/+ buffers/cache показывается, сколько памяти используется и сколько памяти свободно с точки зрения ее использования в приложениях. В этом примере приложениями уже используется 972 Мб памяти и еще 534 МБ памяти могут быть использованы.
Вообще говоря, если используется хотя бы немного памяти подкачки swap, то использование памяти вообще не повлияет на производительность системы.
Но если вы хотите получить более подробную информацию о вашей памяти, то вы должны проверить файл /proc/meminfo; в моей системе Xubuntu с ядром 3.2.0-25-generic результат будет следующим:
Что означает MemTotal (Всего памяти) и MemFree (Свободная память), понятно для всех; остальные значения поясняются дальше:
Cached
Страничный кэш в системе Linux («Cached:» в meminfo) является в большинстве систем самым крупным потребителем памяти. Каждый раз, когда вы выполняете операцию чтения read () из файла, расположенного на диске, данные считываются в память и помещаются в страничный кэш. После того, как операция read() завершается, ядро может просто выбросить страницу памяти, так как она не используется. Однако, если вы второй раз выполняете операцию чтения той же самой части файла, данные будут считываться непосредственно из памяти и обращения к диску не будет. Это невероятно ускоряет работу и, поэтому, в Linux так интенсивно используется кэширование страниц: ставка делается на то, что если вы обратились к некоторой странице дисковой памяти, то вскоре вы обратитесь к ней снова.
dentry/inode caches
Каждый раз, когда вы в файловой системе выполняете операцию «ls’» (или любую другую операцию: open(), stat() и т.д.), ядру требуются данные, которые находятся на диске. Ядро анализирует эти данные, находящиеся на диске, и помещает его в некоторых структуры данных, независимые от файловой системы, с тем, чтобы они могли в различных файловых системах обрабатываться одним и тем же образом. Таким же самым образом, как кэширование страниц в приведенных выше примерах, ядро может после того, как будет завершена команда «ls», стереть эти структуры. Тем не менее, делается такое же предположение, как и раньше: если вы однажды считали эти данные, вы обязательно прочитаете их еще раз. Ядро хранит эту информацию в нескольких местах «кэша», которые называются кэш памятью dentry и inode. Кэш память dentries являются общей для всех файловых систем, но каждая файловая система имеет свой собственный кэш inodes.
Эта оперативная память является в meminfo составной частью «Slab:»
Вы можете просмотреть различную кэш память и узнать ее размеры с помощью следующей команды:
Buffer Cache
Кэш буфера («Buffers:» в meminfo) является близким родственником кэш памяти dentry/inode. Данные dentries и inodes, размещаемые в памяти, представляют собой описание структур на диске, но располагаются они по-разному. Это, возможно, связано с тем, что у нас в копии, расположенной в памяти, используется такая структура, как указатель, но на диске ее нет. Может также случиться, что на диске байты будут располагаться не в том порядке, как это нужно процессору.
Отображение памяти в команде top: VIRT, RES и SHR
Если вы запускаете команду top , то три строки будут описывать к использованию памяти. Вы должны понимать их значение с тем, чтобы понять, сколько памяти требуется вашему серверу.
VIRT является сокращением от virtual size of a process (виртуальный размер процесса) и представляет собой общий объем используемой памяти: памяти, отображаемой самой в себя (например, памяти видеокарты для сервера X), файлов на диске, которые отображаются в память (особенно это касается разделяемых библиотек) и памяти, разделяемой совместно с другими процессами. Значение VIRT указывает, сколько памяти в настоящий момент доступно программе.
RES является сокращением от resident size (размер резидентной части) и является точным указателем того, сколько в действительности потребляется процессом реальной физической памяти. (Что также соответствует значению, находящемуся непосредственно в колонке %MEM). Это значение практически всегда меньше, чем размер VIRT, т.к. большинство программ зависит от библиотеки C.
SHR показывает, какая величина от значения VIRT является в действительности разделяемой (по памяти или за счет использования библиотек). В случае библиотек, это не обязательно означает, что вся библиотека находится в резидентной памяти. Например, если программа использует только несколько функций библиотеки, то при отображении в память будет использована вся библиотека, что будет учтено в значениях VIRT и SHR, но, на самом деле, будет загружена часть библиотеки, содержащая используемые функции, и это будет учтено в значении RES.
Подкачка памяти — swap
Теперь мы видим некоторую информацию о нашей оперативной памяти, но что происходит, когда больше нет свободной оперативной памяти? Если у меня нет свободной памяти, а мне нужна память для страничного кэширования, кэширования inode или кэширования dentry, то где я ее могу получить?
Прежде всего, ядро пытается не допустить, чтобы у вас значение свободной оперативной памяти приближалось к 0 байтов. Это связано с тем, что когда нужно освободить оперативную память, то обычно требуется выделить немного больше памяти. Это обусловлено тем, что нашему ядру требуется своего рода «рабочее пространство» для выполнения своих действий, и поэтому, если размер свободной оперативной памяти становится равным нулю, ядро ничего больше сделать не сможет.
На основании общего объема оперативной памяти и соотношения ее различных типов (память high/low), ядро эвристически определяет то количество памяти в качестве рабочего пространства, при котором оно чувствует себя комфортно. Когда эта величина достигается, ядро начинает возвращать память для других различных задач, описанных выше. Ядро может вернуть себе память из любой из этих задач.
Однако, есть другой потребитель памяти, о котором мы, возможно, уже забыли: данные пользовательских приложений.
Как только ядро принимает решение, что ему не требуется получать память из каких-либо других источников, которые мы описывали ранее, оно запускает память подкачки swap. В ходе этого процесса оно получает данные пользовательских приложений и записывает их в специальное место (или места) на диске. Обратите внимание, что это происходит не только тогда, когда оперативная память близка к заполнению, ядро может принять решение перенести в память swap также данные, находящиеся в оперативной памяти, если они некоторое время не использовались (смотрите раздел «Подкачка памяти»).
По этой причине, даже система с огромным количеством оперативной памяти (даже если ее правильно настроить) может использовать память подкачки swap. Есть много страниц памяти, в которых находятся данные пользовательских приложений, но эти страницы используются редко. Все это является причиной, чтобы перенести их в раздел swap и использовать оперативную память для других целей.
Вы можете с помощью команды free проверить, используется ли память swap; для примера, который я уже использовал выше, в последней строке выдаваемых данных показывается информация о размере памяти swap:
Мы видим, что на этом компьютере уже используется 24 мегабайта памяти swap и для использования доступно еще 462 Мб.
Таким образом, сам факт использования памяти swap не является доказательством того, что в системе при ее текущей рабочей нагрузке слишком мало оперативной памяти. Лучший способ это определить с помощью команды vmstat — если вы увидите, что много страниц памяти swap перемещаются на диск и обратно, то это означает, что память swap используется активно, что система «пробуксовывает» или что ей нужна новая оперативная память поскольку это ускорит подкачку данных приложений.
На моем ноутбуке Gentoo, когда он простаивает, это выглядит следующим образом:
Обратите внимание на то, что в выходных данных команды free у вас есть только 2 значения, относящихся к памяти swap: free (свободная память) и used (используемая память), но для памяти подкачки swap также есть еще одно важное значение: Swap cache (показатель кэширования памяти подкачки).
Кэширование памяти swap (Swap Cach)
Кеширование памяти swap по сути очень похоже на страничное кеширование. Страница данных пользовательского приложения, записываемая на диск, очень похожа на страницу данных файла, находящуюся на диске. Каждый раз, когда страница считывается из файла подкачки («si» в vmstat), она помещается в кэш подкачки. Так же, как страничное кэширование, все это выполняется ядром. Ядро решает, нужно ли вернуть обратно на диск конкретную страницу. Если в этом возникнет необходимость, то можно проверить, есть ли копия этой страницы на диске и можно просто выбросить страницу из памяти. Это избавит нас от затрат на переписывание страницы на диск.
Кэширование памяти swap действительно полезно только когда мы читаем данные из памяти swap и никогда в нее не делаем записи. Если мы выполняем запись на страницу, то копия на диске не будет соответствовать копии, находящейся в памяти. Если это случится, то мы должны произвести запись страницы на диск точно также, как мы делали это первый раз. Несмотря на то, что затраты на сохранение всей страницы больше, чем затраты на запись небольшого измененного кусочка, система будет работать лучше.
Поэтому, чтобы узнать, что память swap действительно используется, мы должны из значения SwapUsed вычесть значение SwapCached, вы можете найти эту информацию в /proc/meminfo.
Подкачка памяти
Когда приложению нужна память, а вся оперативная память полностью занята, то в распоряжении ядра есть два способа освободить память: оно может либо уменьшить размер дискового кэша в оперативной памяти, убирая устаревшие данные, либо оно может сбросить на диск в swap раздел несколько достаточно редко используемых порций (страниц) программы. Трудно предсказать, какой из способов будет более эффективным. Ядро, исходя из недавней истории действий в системе, делает попытку приблизительно отгадать на данный момент эффективность каждого из этих двух методов.
До ядер версии 2.6 у пользователя не было возможности влиять на эти оценки, так что могла возникнуть ситуации, когда ядро часто делало неправильный выбор, что приводило к пробуксовыванию и низкой производительности. В версии 2.6 ситуация с подкачкой памяти была изменена.
Подкачке памяти назначается значение от 0 до 100, которое изменяет баланс между подкачкой памяти приложений и освобождением кэш памяти. При значении 100 ядро всегда предпочтет найти неактивные страницы и сбросить их на диск в раздел swap; в других случаях этот сброс будет осуществляться в зависимости от того, сколько памяти занимает приложение и насколько трудно выпонять кэширование при поиске и удалении неактивных элементов.
По умолчанию для этого устанавливается значение 60. Значение 0 дает нечто близкое к старому поведению, когда приложения, которым нужна память, заставляли немного уменьшить размер кэша оперативной памяти. Для ноутбуков, для которых предпочтительно иметь диски с меньшей скоростью вращения, рекомендуется использовать значение 20 или меньше.
Заключение
В этой статье я поместил информацию, которая была мне полезной в моей работе в качестве системного администратора, и я надеюсь, что она может оказаться полезной и для вас.
Источник
Управление памятью в Linux
Вместо того, чтобы описывать теорию управления памятью в операционных системах, этот раздел попытается выявить основные особенности её реализации в Linux. Хотя вам не требуется быть гуру в виртуальный памяти Linux для выполнения mmap , основной обзор того, как всё это работает, полезен. Далее следует довольно пространное описание структур данных, используемых ядром для управления памятью. После получения необходимых предварительных знаний мы сможем приступить к работе с этими структурами.
Типы адресов
Linux, конечно же, система с виртуальной памятью, а это означает, что адреса, видимые пользовательскими программами, не соответствуют напрямую физическим адресам, используемым оборудованием. Виртуальная память вводит слой косвенности, который позволяет ряд приятных вещей. С виртуальной памятью программы, выполняющиеся в системе, могут выделить гораздо больше памяти, чем доступно физически; более того, даже один процесс может иметь виртуальное адресное пространство больше физической памяти системы. Виртуальная память позволяет также программе использовать разные ухищрения с адресным пространством процесса, в том числе отображение памяти программы в память устройства.
До сих пор мы говорили о виртуальных и физических адресах, но подробности умалчивались. Система Linux имеет дело с несколькими типами адресов, каждый со своей собственной семантикой. К сожалению, в коде ядра не всегда чётко понятно, какой именно тип адреса используется в каждой ситуации, так что программист должен быть осторожным.
Ниже приведён список типов адресов используемых в Linux. Рисунок 15-1 показывает, как эти типы адресов связаны с физической памятью.
Пользовательские виртуальные адреса
Это обычные адреса, видимые программами пространства пользователя. Пользовательские адреса имеют размерность 32 или 64 бита, в зависимости от архитектуры используемого оборудования, и каждый процесс имеет своё собственное виртуальное адресное пространство.
Адреса, используемые между процессором и памятью системы. Физические адреса 32-х или 64-х разрядные; даже 32-х разрядные системы могут использовать большие физические адреса в некоторых ситуациях.
Адреса, используемые между периферийными шинами и памятью. Зачастую они такие же, как физические адреса, используемые процессором, но это не обязательно так. Некоторые архитектуры могут предоставить блок управления памятью ввода/вывода (I/O memory management unit, IOMMU), который переназначает адреса между шиной и оперативной памяти. IOMMU может сделать жизнь легче несколькими способами (делая разбросанный в памяти буфер выглядящим непрерывным для устройства, например), но программирование IOMMU является дополнительным шагом, который необходимо выполнить при настройке DMA операций. Конечно, адреса шин сильно зависят от архитектуры.
Логические адреса ядра
Они составляют обычное адресное пространство ядра. Эти адреса отображают какую-то часть (возможно, всю) основной памяти и часто рассматриваются, как если бы они были физическими адресами. На большинстве архитектур логические адреса и связанные с ними физические адреса отличаются только на постоянное смещение. Логические адреса используют родной размер указателя оборудования и, следовательно, могут быть не в состоянии адресовать всю физическую память на 32-х разрядных системах, оборудованных в большей степени. Логические адреса обычно хранятся в переменных типа unsigned long или void * . Память, возвращаемая kmalloc , имеет логический адрес ядра.
Виртуальные адреса ядра
Виртуальные адреса ядра похожи на логические адреса в том, что они являются отображением адреса пространства ядра на физический адрес. Однако, виртуальные адреса ядра не всегда имеют линейную, взаимно-однозначную связь с физическими адресами, которая характеризует логическое адресное пространство. Все логические адреса являются виртуальными адресами ядра, но многие виртуальные адреса ядра не являются логическими адресами. Так, например, память, выделенная vmalloc , имеет виртуальный адрес (но без прямого физического отображения). Функция kmap (описываемая далее в этой главе) также возвращает виртуальные адреса. Виртуальные адреса обычно хранятся в переменных указателей.
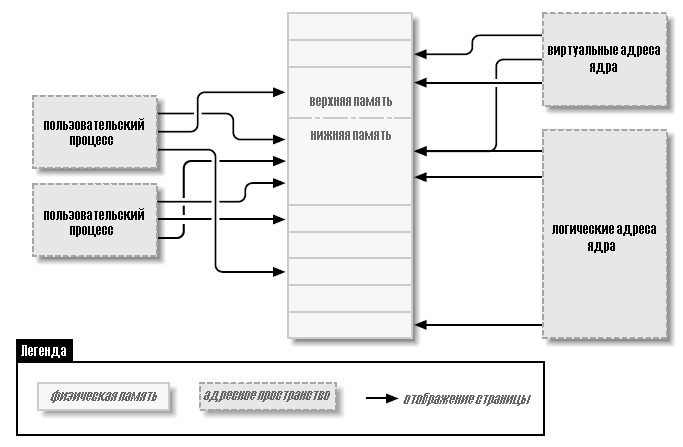
Рисунок 15-1. Типы адресов, используемые в Linux
Различные функции ядра требуются разные типы адресов. Было бы неплохо, если бы были определены различные типы Си, так, чтобы необходимый тип адреса был бы явным, но этого нет. В этой главе мы стараемся ясно указывать, какой тип адресов где используется.
Физические адреса и страницы
Физическая память разделена на отдельные модули, называемые страницами . Значительная часть внутренней системной обработки памяти производится на постраничной основе. Размер страницы варьируется от одной архитектуры к другой, хотя большинство систем в настоящее время использует страницы по 4096 байт. Постоянная PAGE_SIZE (определённая в ) задаёт размер страницы для любой архитектуры.
Если вы посмотрите на адрес памяти, виртуальный или физический, он делится на номер страницы и смещение внутри этой страницы. Например, если используются страницы по 4096 байт, 12 младших значащих бит являются смещением, а остальные, старшие биты, указывают номер страницы. Если отказаться от смещения и сдвинуть оставшуюся часть адреса вправо, результат называют номером страничного блока (page frame number, PFN). Сдвиг битов для конвертации между номером страничного блока и адресами является довольно распространённой операцией; макрос PAGE_SHIFT сообщает, сколько битов должны быть смещены для выполнения этого преобразования.
Верхняя и нижняя память
Разница между логическими и виртуальными адресами ядра хорошо видна на 32-х разрядных системах, которые оборудованы большими объёмами памяти. Используя 32 бита можно адресовать 4 ГБ памяти. Однако, Linux на 32-х разрядных системах до недавнего времени был ограничен значительно меньшей памятью, чем это, из-за способа инициализации виртуального адресного пространства.
Ядро (на архитектуре x86, в конфигурации по умолчанию) разделяет 4 ГБ виртуальное адресное пространство между пространством пользователя и ядром; в обоих контекстах используется один и тот же набор отображений. Типичное разделение выделяет 3 Гб для пространства пользователя и 1 ГБ для пространства ядра. (* Многие не-x86 архитектуры способны эффективно обходиться без описанного здесь разделения на ядро/пользовательское пространство, так что они могут работать с адресным пространством ядра до 4 ГБ на 32-х разрядных системах. Однако, ограничения, описанные в этом разделе, до сих пор относятся к таким системам, где установлено более 4 ГБ оперативной памяти.) Код ядра и структуры данных должны вписываться в это пространство, но самым большим потребителем адресного пространства ядра является виртуальное отображение на физическую память. Ядро не может напрямую управлять памятью, которая не отображена в адресное пространство ядра. Ядру, другими словами, необходим свой виртуальный адрес для любой памяти, с которой оно должно непосредственно соприкасаться. Таким образом, на протяжении многих лет, максимальным объёмом физической памяти, которая могла быть обработана ядром, было значение, которое могло быть отображено в часть для ядра виртуального адресного пространства, минус пространство, необходимое для самого кода ядра. В результате, базирующиеся на x86 системы Linux могли работать максимально с немногим менее 1 ГБ физической памяти.
В ответ на коммерческое давление, чтобы поддержать больше памяти, не нарушая в то же время работу 32-х разрядных приложений и совместимость системы, производители процессоров добавили в свои продукты функцию «расширение адреса». Результатом является то, что во многих случаях даже 32-х разрядные процессоры могут адресовать более 4 ГБ физической памяти. Однако, ограничение на объём памяти, которая может быть непосредственно связана с логическими адресами, остаётся. Только самая нижняя часть памяти (до 1 или 2 ГБ, в зависимости от оборудования и конфигурации ядра) имеет логические адреса; (* Ядро версии 2.6 (с дополнительным патчем) может поддерживать на архитектуре x86 режим «4G/4G», который разрешает большие виртуальные адресные пространства ядра и пользовательского пространства при умеренных затратах производительности.) остальная (верхняя память) не имеет. Перед доступом к заданной странице верхней памяти ядро должно установить явное виртуальное соответствие, чтобы сделать эту страницу доступной в адресном пространстве ядра. Таким образом, многие структуры данных ядра должны быть размещены в нижней памяти; верхняя память имеет тенденцию быть зарезервированной для страниц процесса пространства пользователя.
Термин «верхняя память» может ввести некоторых в заблуждение, особенно поскольку он имеет другое значение в мире персональных компьютеров. Таким образом, чтобы внести ясность, мы определим здесь эти термины:
Память, для которой существуют логические адреса в пространстве ядра. Почти на каждой системе, с которой вы скорее всего встретитесь, вся память является нижней памятью.
Память, для которой логические адреса не существуют, потому что она выходит за рамки диапазона адресов, отведённых для виртуальных адресов ядра.
На системах i386 граница между нижней и верхней памятью обычно установлена на уровне только до 1 Гб, хотя эта граница может быть изменена во время конфигурации ядра. Эта граница не связана никаким образом со старым ограничением 640 Кб, имеющимся на оригинальном ПК, и её размещение не продиктовано оборудованием. Напротив, это предел, установленный в самом ядре, так как он разделяет 32-х разрядное адресное пространство между ядром и пространством пользователя.
Мы укажем на ограничения на использование верхней памяти, когда мы подойдём к ним в этой главе.
Карта памяти и структура page
Исторически сложилось, что для обращения к страницам физической памяти ядро использует логические адреса. Однако, добавление поддержки верхней памяти выявило очевидную проблему с таким подходом — логические адреса не доступны для верхней памяти.
Таким образом, функции ядра, которые имеют дело с памятью, вместо этого всё чаще используют указатели на struct page (определённой в
). Эта структура данных используется для хранения информации практически обо всём, что ядро должно знать о физической памяти; для каждой физической страницы в системе существует одна struct page . Некоторые из полей этой структуры включают следующее:
Число существующих ссылок на эту страницу. Когда количество падает до 0, страница возвращается в список свободных страниц.
Виртуальный адрес страницы ядра, если она отображена; в противном случае NULL. Страницы нижней памяти отображаются всегда; страницы верхней памяти — обычно нет. Это поле появляется не на всех архитектурах; оно обычно компилируется только тогда, когда виртуальный адрес страницы ядра не может быть легко вычислен. Если вы хотите посмотреть на это поле, правильный метод заключается в использовании макроса page_address , описанного ниже.
unsigned long flags;
Набор битовых флагов, характеризующих состояние этой странице. К ним относятся PG_locked , который указывает, что страница была заблокирована в памяти, и PG_reserved , который препятствует тому, чтобы система управления памятью вообще работала с этой страницей.
Внутри struct page существует гораздо больше информации, но она является частью более глубокой чёрной магии управления памятью и не представляет интерес для авторов драйверов.
Ядро поддерживает один или несколько массивов записей struct page , которые позволяют отслеживать всю физическую память системы. На некоторых системах имеется единственный массив, называемый mem_map . На других системах, однако, ситуация более сложная. Системы с неоднородным доступом к памяти (nonuniform memory access, NUMA) и другие с сильно разделённой физической памятью могут иметь более одного массива карты памяти, поэтому код, который предназначен для переносимости, должен избегать прямого доступа к массиву, когда это возможно. К счастью, как правило, довольно легко просто работать с указателями struct page не беспокоясь о том, откуда они берутся.
Некоторые функции и макросы, определённые для перевода между указателями struct page и виртуальными адресами:
struct page *virt_to_page(void *kaddr);
struct page *pfn_to_page(int pfn);
Возвращает указатель struct page для заданного номера страничного блока. При необходимости он проверяет номер страничного блока на корректность с помощью pfn_valid перед его передачей в pfn_to_page .
void *page_address(struct page *page);
Возвращает виртуальный адрес ядра этой страницы, если такой адрес существует. Для верхней памяти этот адрес существует, только если страница была отображена. Эта функция определена в
. В большинстве случаев вы захотите использовать версию kmap , а не page_address .
void *kmap(struct page *page);
void kunmap(struct page *page);
kmap возвращает виртуальный адрес ядра для любой страницы в системе. Для страниц нижней памяти она просто возвращает логический адрес страницы; для страниц верхней памяти kmap создаёт специальное отображение в предназначенной для этого части адресного пространства ядра. Отображения, созданные kmap , всегда должны быть освобождены с помощью kunmap ; доступно ограниченное число таких отображений, так что лучше не удерживать их слишком долго. Вызовы kmap поддерживают счётчик, так что если две или более функции вызывают kmap на той же странице, всё работает правильно. Отметим также, что kmap может заснуть, если отображение недоступно.
void *kmap_atomic(struct page *page, enum km_type type);
void kunmap_atomic(void *addr, enum km_type type);
kmap_atomic является высокопроизводительной формой kmap . Каждая архитектура поддерживает небольшой список слотов (специализированные записи таблицы страниц) для атомарных kmap-ов; вызывающий kmap_atomic должен сообщить системе в аргументе type , какой из этих слотов использовать. Единственными слотами, которые имеют смысл для драйверов, являются KM_USER0 и KM_USER1 (для кода, работающего непосредственно из вызова из пользовательского пространства), и KM_IRQ0 и KM_IRQ1 (для обработчиков прерываний). Обратите внимание, что атомарные kmap-ы должны быть обработаны атомарно; ваш код не может спать, удерживая её. Отметим также, что ничто в ядре не предохраняет две функции от попытки использовать тот же слот и помешать друг другу (хотя для каждого процессора имеется уникальный набор слотов). На практике, конкуренция для атомарных слотов kmap, кажется, не будет проблемой.
Мы увидим варианты использования этих функций, когда перейдём к примеру кода далее в этой главе, и в последующих главах.
Таблицы страниц
В любой современной системе процессор должен иметь механизм для трансляции виртуальных адресов в соответствующие физические адреса. Этот механизм называется таблицей страниц ; по существу, это многоуровневый древовидный массив, содержащий отображения виртуального к физическому и несколько связанных флагов. Ядро Linux поддерживает набор таблиц страниц даже на архитектурах, которые не используют такие таблицы напрямую.
Многие операции, обычно выполняемые драйверами устройств, могут включать манипуляции таблицами страниц. К счастью для автора драйвера, ядро версии 2.6 ликвидировало всю необходимость непосредственно работать с таблицами страниц. В результате, мы не описываем их детально; любопытные читатели могут захотеть взглянуть на Understanding The Linux Kernel от Daniel P. Bovet и Marco Cesati (O’Reilly) для полной информации.
Области виртуальной памяти
Область виртуальной памяти (virtual memory area, VMA) представляет собой структуру данных ядра, используемую для управления различными регионами адресного пространства процесса. VMA представляет собой однородный регион в виртуальной памяти процесса: непрерывный диапазон виртуальных адресов, которые имеют одинаковые флаги разрешения и созданы одним и тем же объектом (скажем, файлом, или пространством для своппинга). Она примерно соответствует концепции «сегмента», хотя это лучше описывается как «объект памяти со своими свойствами». Карта памяти процесса состоит (по крайней мере) из следующих областей:
• Область для исполняемого кода программы (часто называемого текстом).
• Несколько областей для данных, в том числе проинициализированные данные (те, которые имеют явно заданные значения в начале исполнения), неинициализированные данных (BSS), (* имя BSS является историческим пережитком старого ассемблерного оператора, означающего «блок, начатый символом» (“block started by symbol”). Сегмент BSS исполняемых файлов не сохраняется на диске и ядро отображает нулевую страницу в диапазоне адресов BSS.) и программный стек.
• По одной области для каждого активного отображения памяти.
Области памяти процесса можно увидеть, посмотрев в /proc/
/maps (где pid , конечно, заменяется на ID процесса). /proc/self является особым случаем /proc/pid , потому что он всегда обращается к текущему процессу. Вот, например, несколько карт памяти (к которым мы курсивом добавили краткие комментарии):
# cat /proc/1/maps look at init
08048000-0804e000 r-xp 00000000 03:01 64652 /sbin/init text
0804e000-0804f000 rw-p 00006000 03:01 64652 /sbin/init data
0804f000-08053000 rwxp 00000000 00:00 0 zero-mapped BSS
40000000-40015000 r-xp 00000000 03:01 96278 /lib/ld-2.3.2.so text
40015000-40016000 rw-p 00014000 03:01 96278 /lib/ld-2.3.2.so data
40016000-40017000 rw-p 00000000 00:00 0 BSS for ld.so
42000000-4212e000 r-xp 00000000 03:01 80290 /lib/tls/libc-2.3.2.so text
4212e000-42131000 rw-p 0012e000 03:01 80290 /lib/tls/libc-2.3.2.so data
42131000-42133000 rw-p 00000000 00:00 0 BSS for libc
bffff000-c0000000 rwxp 00000000 00:00 0 Stack segment
ffffe000-fffff000 —p 00000000 00:00 0 vsyscall page
# rsh wolf cat /proc/self/maps #### x86-64 (trimmed)
00400000-00405000 r-xp 00000000 03:01 1596291 /bin/cat text
00504000-00505000 rw-p 00004000 03:01 1596291 /bin/cat data
00505000-00526000 rwxp 00505000 00:00 0 bss
3252200000-3252214000 r-xp 00000000 03:01 1237890 /lib64/ld-2.3.3.so
3252300000-3252301000 r—p 00100000 03:01 1237890 /lib64/ld-2.3.3.so
3252301000-3252302000 rw-p 00101000 03:01 1237890 /lib64/ld-2.3.3.so
7fbfffe000-7fc0000000 rw-p 7fbfffe000 00:00 0 stack
ffffffffff600000-ffffffffffe00000 —p 00000000 00:00 0 vsyscall
Поля в каждой строке:
start-end perm offset major:minor inode image
Каждое поле в /proc/*/maps (за исключением имени отображения) соответствует полю в структуре vm_area_struct :
Начало и окончание виртуальных адресов для этой области памяти.
Битовая маска с разрешениями для области памяти на чтение, запись и исполнение. Это поле описывает, что процессу разрешено делать со страницами, которые принадлежат этой области. Последний символ в поле — это либо p для «закрытых» (“private”), или s для «общих» (“shared”).
Где начинается область памяти в файле, с которым она связана. Смещение 0 означает, что начало области памяти соответствует началу файла.
Старший и младший номера устройства удерживающего файл, который был на отображён. Как ни странно, при отображении устройства, старший и младший номера ссылаются на дисковый раздел, содержащий специальный файл устройства, который был открыт пользователем, а не самого устройства.
Номер inode отображённого файла.
Имя файла (обычно это исполняемый файл), который был отображён.
Структура vm_area_struct
Когда процесс пользовательского пространства вызывает mmap , чтобы отобразить память устройства в его адресное пространство, система реагирует, создавая новую VMA для предоставления этого отображения. Драйвер, который поддерживает mmap (и, таким образом, который реализует метод mmap ), должен помочь такому процессу завершая инициализацию этой VMA. Автор драйвера должен, следовательно, иметь по крайней мере минимальное понимание VMA для поддержки mmap .
Давайте посмотрим на наиболее важные поля в struct vm_area_struct (определённой в
). Эти поля могут быть использованы драйверами устройств в их реализации mmap . Заметим, что ядро поддерживает списки и деревья VMA для оптимизации области поиска и некоторые поля vm_area_struct используются для поддержки такой организации. Поэтому VMA не могут быть созданы по желанию драйвера, или эти структуры нарушатся. Основными полями VMA являются следующие (обратите внимание на сходство между этими полями и выводом /proc , который мы только что видели):
unsigned long vm_start;
unsigned long vm_end;
Диапазон виртуальных адресов, охватываемый этой VMA. Эти поля являются первыми двумя полями, показываемыми в /proc/*/maps .
struct file *vm_file;
Указатель на структуру struct file , связанную с этой областью (если таковая имеется).
unsigned long vm_pgoff;
Смещение области в файле, в страницах. Когда отображается файл или устройство, это позиция в файле первой страницы, отображённой в эту область.
unsigned long vm_flags;
Набор флагов, описывающих эту область. Флагами, представляющими наибольший интерес для автора драйвера устройства, являются VM_IO и VM_RESERVED . VM_IO отмечает VMA как являющийся отображённым на память регион ввода/вывода. Среди прочего, флаг VM_IO мешает региону быть включенным в дампы процессов ядра. VM_RESERVED сообщает системе управления памятью не пытаться выгрузить эту VMA; он должен быть установлен в большинстве отображений устройства.
struct vm_operations_struct *vm_ops;
Набор функций, которые ядро может вызывать для работы в этой области памяти. Его присутствие свидетельствует о том, что область памяти является «объектом» ядра, как и struct file , которую мы используем везде в этой книге.
Области, которые могут быть использованы драйвером для сохранения своей собственной информации.
Как и struct vm_area_struct , vm_operations_struct определена в
; она включает операции, перечисленные ниже. Эти операции являются единственными необходимыми для обработки потребностей процесса в памяти и они перечислены в том порядке, как они объявлены. Далее в этой главе реализованы некоторые из этих функций.
void (*open)(struct vm_area_struct *vma);
Метод open вызывается ядром, чтобы разрешить подсистеме реализации VMA проинициализировать эту область. Этот метод вызывается в любое время, когда создаётся новая ссылка на эту VMA (например, когда процесс разветвляется). Единственное исключение происходит, когда VMA создана впервые через mmap ; в этом случае вместо этого вызывается метод драйвера mmap .
void (*close)(struct vm_area_struct *vma);
При удалении области ядро вызывает эту операцию close . Обратите внимание, что нет счётчика использований, связанного с VMA; область открывается и закрывается ровно один раз каждым процессом, который её использует.
struct page *(*nopage)(struct vm_area_struct *vma, unsigned long address, int *type);
Когда процесс пытается получить доступ к странице, которая относится к действительной VMA, но которая в настоящее время не в памяти, для соответствующей области вызывается метод nopage (если он определён). Метод возвращает указатель struct page для физической страницы после того как, может быть, прочитал его из вторичного хранилища. Если для этой области метод nopage не определён, ядром выделяется пустая страница.
int (*populate)(struct vm_area_struct *vm, unsigned long address, unsigned long len,
pgprot_t prot, unsigned long pgoff, int nonblock);
Этот метод позволяет ядру «повредить» страницы в памяти, прежде чем они будут доступны пользовательскому пространству. Вообще-то, драйверу нет необходимости реализовывать метод populate .
Карта памяти процесса
Последней частью головоломки управления памятью является структура карты памяти процесса, которая удерживает все другие структуры данных вместе. Каждый процесс в системе (за исключением нескольких вспомогательных потоков пространства ядра) имеет struct mm_struct (определённую в
), которая содержит список виртуальных областей памяти процесса, таблицы страниц и другие разные биты информации управления домашним хозяйством памяти вместе с семафором ( mmap_sem ) и спин-блокировкой ( page_table_lock ). Указатель на эту структуру можно найти в структуре задачи; в редких случаях, когда драйверу необходим к ней доступ, обычным способом является использование current->mm . Обратите внимание, что структура управления памятью может быть разделяемой между процессами; к примеру, таким образом работает реализация потоков в Linux.
На том мы завершаем обзор структур данных управления памятью в Linux. Покончив с этим, мы можем теперь приступить к реализации системного вызова mmap .
Источник



