- Ускорение и оптимизация настроек PostgreSQL для 1С
- Примеры оптимальных настроек:
- Полезные запросы:
- Ускорение работы 1С с postgresql и диагностика проблем производительности
- Введение
- Параллельное выполнение запросов на нескольких ядрах в postgresql
- Логирование sql запросов в postgresql
- Анализ запросов postgresql с помощью pgFouine
- Заключение
- Как одно изменение конфигурации PostgreSQL улучшило производительность медленных запросов в 50 раз
Ускорение и оптимизация настроек PostgreSQL для 1С
По умолчанию PostgreSQL настроен таким образом, чтобы расходовать минимальное количество ресурсов для работы с небольшими базами до 4 Gb на не очень производительных серверах. То есть, если дело касается систем посерьезней, то вы столкнетесь с большими потерями производительности базы данных лишь потому, что дефолтные настройки могут в корне не соответствовать производительности вашего северного оборудования. Настройки выделения ресурсов оперативной памяти RAM для работы PostgreSQL хранятся в файле postgresql.conf.
Доступен как из папки, куда установлен PostgreSQL / Data, так и из pgAdmin:

В общем на начальном этапе при возникновении трудностей и замедления работы БД, заметной для глаз пользователей достаточно увеличить три параметра:
shared_buffers
Это размер памяти, разделяемой между процессами PostgreSQL, отвечающими за выполнения активных операций. Максимально-допустимое значение этого параметра – 25% всего количества RAM
Например, при 1-2 Gb RAM на сервере, достаточно указать в этом параметре значение 64-128 Mb (8192-16384).
temp_buffers
Это размер буфера под временные объекты (временные таблицы). Среднее значение 2-4% всего количества RAM
Например, при 1-2 Gb RAM на сервере, достаточно указать в этом параметре значение 32-64 Mb.
work_mem
Это размер памяти, используемый для сортировки и кэширования таблиц.
При 1-2 Gb RAM на сервере, рекомендуемое значение 32-64 Mb.
Для вступления новых значений в силу, потребуется перезапуск службы, поэтому лучше делать во вне рабочее время.
Еще два важных параметра это maintenance_work_mem (для операций VACUUM, CREATE INDEX и других) и max_stack_depth
Примеры оптимальных настроек:
- CPU: E3-1240 v3 @ 3.40GHz
- RAM: 32Gb 1600Mhz
- Диски: Plextor M6Pro
- shared_buffers = 8GB
- work_mem = 128MB
- maintenance_work_mem = 2GB
- fsync = on
- synchronous_commit = off
- wal_sync_method = fdatasync
- checkpoint_segments = 64
- seq_page_cost = 1.0
- random_page_cost = 6.0
- cpu_tuple_cost = 0.01
- cpu_index_tuple_cost = 0.0005
- cpu_operator_cost = 0.0025
- effective_cache_size = 24GB
Вариант настроек от pgtune:

Полезные запросы:
Блокировки БД по пользователям
Вывести все таблицы, размером больше 10 Мб
Определение размеров таблиц в базе данных PostgreSQL
Пользователи блокирующие конкретную таблицу
Ускорение работы 1С с postgresql и диагностика проблем производительности

Некоторое время назад я настраивал работу 1С предприятия с базой данных postgresql. Во время тестирования столкнулся с проблемой медленной работы некоторых запросов. Хочу поделиться полезной информацией, которая позволит разобраться в таких ситуациях и попытаться ускорить работу и избавиться от узких мест в базе.
Данная статья является частью единого цикла статьей про сервер Debian.
Введение
Сервер postgresql настроен по предыдущей статье — Установка и настройка postgresql на debian 8 для работы с 1С. Основные моменты по ускорению работы базы там приведены. Они существенно увеличивают производительность по сравнению с настройками по-умолчанию. В большинстве случаев этого бывает достаточно. Если нет — то у вас уже не типичный случай и надо разбираться более детально.
Проблема, с которой столкнулся я, кроется в особенности работы postgresql и отсутствии оптимизации 1С для работы с этой бд. База данных postgresql, в отличие от mssql, не умеет распараллеливать выполнение одного запроса не несколько ядер процессора. Даже если у вас очень высокопроизводительный сервер с большим числом ядер, вы можете попасть в ситуацию, когда какой-то тяжелый запрос будет очень сильно тормозить, нагружая только одно ядро. Остальные мощности процессора будут простаивать при этом. Увеличение ресурсов сервера никак не поможет вам ускорить работу базы. Она будет всегда спотыкаться на этом запросе.
Параллельное выполнение запросов на нескольких ядрах в postgresql
Я использовал версию postgresql 9.6. Если верить новости — http://www.opennet.ru/opennews/art.shtml?num=43313 в ней добавлена поддержка распараллеливания запросов. Я стал пробовать на практике это распараллеливание. Информации в интернете, к моему сожалению, не так много. Вроде проблема популярная, много где видел вопросов на эту тему. Например, вот тут обсуждают тему использования нескольких ядер процессора для выполнения запроса — http://www.sql.ru/forum/1002408/zadeystvovanie-neskolkih-processorov.
Наиболее популярные рекомендации, это изменить запросы и логику работы приложения с БД, чтобы не попадать в ситуацию, когда возникает один большой запрос, который невозможно разбить и обработать параллельно на нескольких ядрах. Пример такого подхода есть на хабре — https://habrahabr.ru/post/76309/. У меня нет ни должных знаний sql, ни тем более 1С, чтобы на уровне приложения что-то менять. Стал разбираться с возможностями postgresql.
Есть несколько параметров, которые как раз отвечают за параллельную обработку запросов:
Их необходимо подбирать под свое количество ядер. В данном случае настройки представлены для 16-ти ядерной системы. Далее необходимо применить скрипт на базе 1С, который позволит оптимизатору постгреса использовать параллельную обработку тех запросов 1С где участвуют текстовые поля (большинство запросов), путём изменения определений функций. Текст скрипта очень длинный, поэтому не привожу его здесь, чтобы не нагружать статью. Качаем его с сайта — postgre.sql.
Запрос необходимо выполнить в базе, которую использует 1С. Для этого можно воспользоваться либо программой pgAdmin, либо напрямую подключиться к базе, через консоль сервера. Опишу второй вариант в подробностях.
Подключаемся к серверу с postgresql по ssh. Заходим под юзером postgres:
Переходим в домашний каталог пользователя:
Создаем файл с запросом, который будем выполнять. В данном случае можете сразу скопировать файл, который скачали ранее, либо создайте вручную и скопируйте в него текст запроса.
Если будете копировать готовый файл, убедитесь, что у пользователя postgres есть доступ к этому файлу.
Подключаемся к серверу бд:
Подключаемся к нужной базе данных:
Выполняем sql запрос из файла:
Все, можно идти проверять. Мы должны были увеличить быстродействие 1С запросов в базе postgresql, разрешив использовать параллельную обработку некоторых запросов. В моем случае это не дало никакого прироста по проблемным запросам. Сама база в целом работала нормально, но спотыкалась на определенных запросах. Разбираемся дальше.
Логирование sql запросов в postgresql
Для того, чтобы разобраться, что же конкретно у нас тормозит, надо посмотреть на сами запросы. Для этого нам нужно включить логирование запросов к базе данных. Запросов будет очень много, нам не нужны все подряд. Сделаем ограничение на логирование только тех запросов, которые выполняются дольше, чем 3 секунды. Для этого рисуем следующие параметры в конфиге БД:
И добавляем описание канала для логов LOCAL0 в конфиг rsyslog в файле /etc/rsyslog.conf, в самый конец:
Если оставить настройки rsyslog в таком виде, то лог запросов будет писаться не только в файл /var/log/postgresql/sql.log, но и в messages, и в syslog. Я не люблю спамить в системные логи, поэтому отключим запись sql логов туда. Добавляем в описание этих лог файлов значение LOCAL0.none. Должно получиться примерно так:
Перезапускаем postgresql и rsyslog:
Идем в базу 1С и вызываем свой запрос, который тормозит. Если его выполнение занимает больше, чем 3 секунды, вы увидите текст запроса в лог файле. Можете подольше попользоваться базой, чтобы собрать список запросов для анализа. Запросы 1С настолько громоздкие, что даже просто скопировать их из лога и обработать непростая задача. Воспользуемся для этого специальной программой.
Анализ запросов postgresql с помощью pgFouine
Устанавливаем pgFouine в debian:
Это старая программа, но для наших целей сойдет. Пользоваться ей очень просто. Я не вдавался в подробности настройки и не смотрел возможные параметры. Мне было достаточно сделать вот так:
Забираем файл report.html к себе на компьютер и открываем в браузере. У меня получилось примерно так:
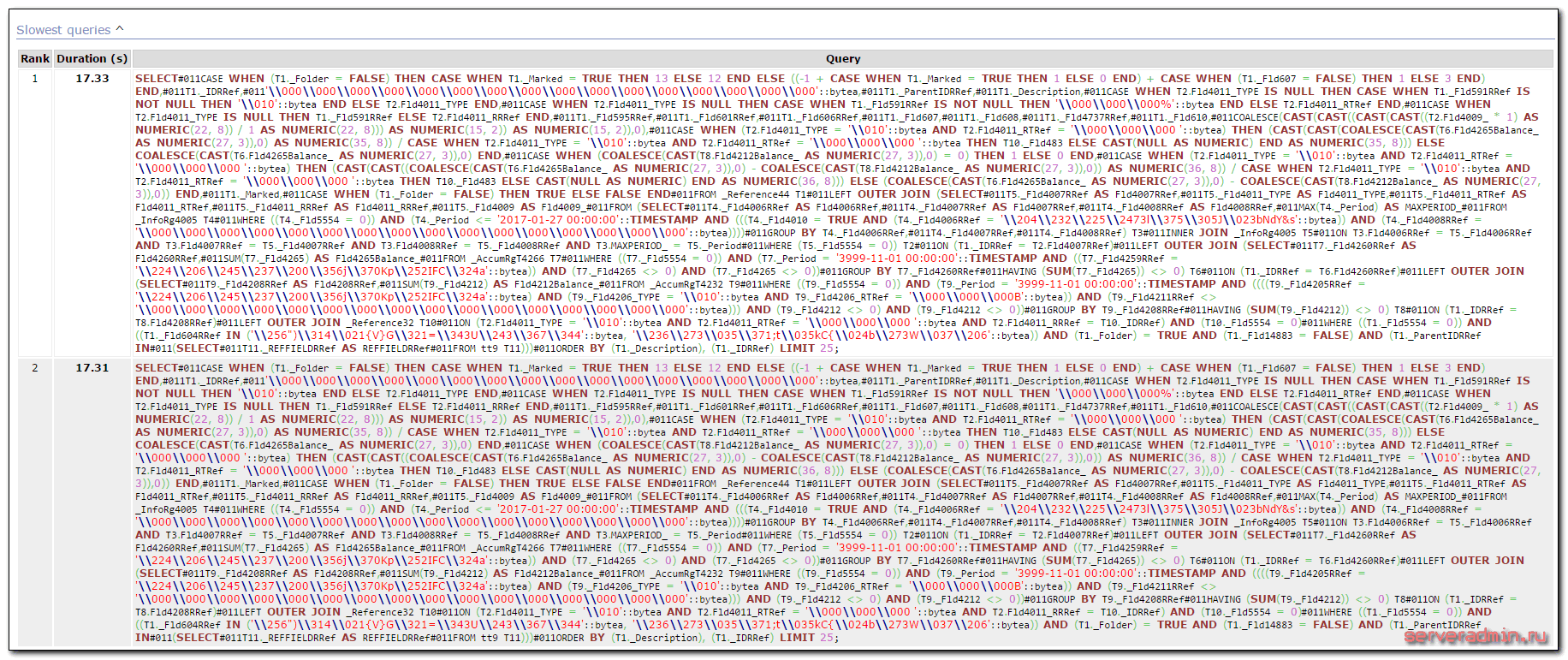
Запрос впечатляет 🙂 Не удивительно, что он тормозит! Сказать, что я был удивлен, это ничего не сказать. Глядя на эти запросы, я понимал, что никакой оптимизации в 1С для работы с postgresql нет. Хотя я очень плохо разбираюсь в sql, знаком поверхностно с синтаксисом, и сам составлял только очень простые запросы. Но даже я вижу, что проблема тормозов в том, что этот запрос просто безобразно огромный. Парсер запроса нахватал в код мусорных символов. В моем случае это символы #011, они присутствую в логе sql.log. Я не знаю, откуда они там берутся, но чтобы получить чистый запрос, их надо убрать. Я скопировал текст запроса в текстовый редактор и сделал замену символов #011 на пробел. В итоге получился синтаксически корректный запрос. В моем случае он выглядит таким образом:
Дальше вы можете разбираться со своими запросами, в зависимости от ваших знаний и возможностей. Я не знал, что делать дальше, для решения своей проблемы. Попытался построить карту запроса с помощью EXPLAIN ANALYZE, но не получилось. Запрос использует какие-то временные таблицы, так что просто скопировать и повторить его не получалось. Выходила ошибка, что какой-то таблицы не существует.
В настоящий момент я получил совет на профильном форуме по моей проблеме. Мне сказали, что ситуация известная и достаточно типичная для 1С. Исправлять ее нужно на стороне самой 1С, изменяя код запроса выборки из виртуальных таблиц на запросы из временных таблиц, соединяя их потом с основной. Это уже задача для программиста. Я в самой 1С не разбираюсь вообще.
Заключение
На текущий момент моя проблема не решена, но стало понятно, в каком направлении двигаться и что делать. В принципе, я изначально, когда стал заниматься этой задачей, предполагал, что проблема именно на стороне 1С из-за сложного запроса и отсутствии оптимизации работы 1С именно с postgresql. Я это понял, потому что с mssql таких тормозов никогда наблюдал на базах такого размера. В данном случае объем базы всего 10 гб, она не очень большая. 15 секунд лопатить запрос на такой базе можно только, если этот запрос ужасен. На деле все так и оказалось.
В процессе разбора ситуации приобрел определенный опыт, который постарался зафиксировать в этой статье. Думаю, он пригодится в будущем, как мне, так и другим пользователям. В интернете не нашел хороших статей по анализу производительности постгрес. Пришлось все собирать по крохам в разных статьях, но больше на форумах. С учетом стоимости лицензии mssql, замена ее на postgresql выглядит весьма обоснованной, так что тема актуальна.
Буду рад любым замечаниям и советам в комментариях. Тема для меня новая, но полезная. Хотелось бы разобраться в работе постгрес.
Напоминаю, что данная статья является частью единого цикла статьей про сервер Debian.
Как одно изменение конфигурации PostgreSQL улучшило производительность медленных запросов в 50 раз
Здравствуйте, хабровчане! Предлагаю вашему вниманию перевод статьи «How a single PostgreSQL config change improved slow query performance by 50x» автора Pavan Patibandla. Она очень сильно мне помогла улучшить производительность PostgreSQL.
В Amplitude наша цель — предоставить простую в использовании интерактивную аналитику продуктов, чтобы каждый мог найти ответы на свои вопросы о продукте. Чтобы обеспечить удобство работы, Amplitude должен быстро предоставить эти ответы. Поэтому, когда один из наших клиентов пожаловался на то, сколько времени потребовалось для загрузки раскрывающегося списка свойств события в пользовательском интерфейсе Amplitude, мы приступили к детальному изучению проблемы.
Отслеживая задержку на разных уровнях, мы поняли, что одному конкретному запросу PostgreSQL потребовалось 20 секунд для завершения. Для нас это стало неожиданностью, так как обе таблицы имеют индексы в соединяемом столбце.

План выполнения PostgreSQL для этого запроса был для нас неожиданным. Несмотря на то, что в обеих таблицах есть индексы, PostgreSQL решил выполнить Hash Join с последовательным сканированием большой таблицы. Последовательное сканирование большой таблицы занимало большую часть времени запроса.
План выполнения медленого запроса

Я изначально подозревал, что это может быть из-за фрагментации. Но после проверки данных я понял, что в эту таблицу данные только добавляются и практически не удаляются оттуда. Так как очистка места с помощью VACUUM здесь не очень поможет, я начал копать дальше. Затем я попробовал этот же запрос на другом клиенте с хорошим временем ответа. К моему удивлению, план выполнения запроса выглядел совершенно иначе!
План выполнения того же запроса на другом клиенте

Интересно, что приложение A получило доступ только к 10 раз большему количеству данных, чем приложение B, но время отклика было в 3000 раз больше.
Чтобы увидеть альтернативные планы запросов PostgreSQL, я отключил хеш-соединение и перезапустил запрос.
Альтернативный план выполнения для медленного запроса

Ну вот! Тот же запрос завершается в 50 раз быстрее при использовании вложенного цикла вместо хэш-соединения. Итак, почему PostgreSQL выбрал худший план для приложения A?
При более тщательном рассмотрении предполагаемой стоимости и фактического времени выполнения для обоих планов предполагаемые соотношения стоимости и фактического времени выполнения были очень разными. Основным виновником этого несоответствия была оценка стоимости последовательного сканирования. PostgreSQL подсчитал, что последовательное сканирование было бы лучше, чем 4000+ сканирований индекса, но в действительности сканирование индекса было в 50 раз быстрее.
Это привело меня к параметрам конфигурации random_page_cost и seq_page_cost. Значения PostgreSQL по умолчанию 4 и 1 для random_page_cost, seq_page_cost, которые настроены для HDD, где произвольный доступ к диску дороже, чем последовательный доступ. Однако эти затраты были неточными для нашего развертывания с использованием тома gp2 EBS, которые являются твердотельными накопителями. Для нашего развертывания случайный и последовательный доступ практически одинаков.
Я изменил значение random_page_cost на 1 и повторил запрос. На этот раз PostgreSQL использовал Nested Loop, и запрос выполнялся в 50 раз быстрее. После изменения мы также заметили значительное снижение максимального времени отклика от PostgreSQL.
Общая производительность медленного запроса значительно улучшилась

Если вы используете SSD и используете PostgreSQL с конфигурацией по умолчанию, я советую вам попробовать настроить random_page_cost и seq_page_cost. Вы можете быть удивлены сильным улучшением производительности.
От себя добавлю, что я выставил минимальные параметры seq_page_cost = random_page_cost = 0.1, чтобы отдать приоритет данным в памяти (кэш) над процессорными операциями, так как у меня выделено большое количество ОЗУ для PostgreSQL (размер ОЗУ превышает размер базы на диске). Не очень понятно, почему сообщество postgres до сих пор использует настройки по умолчанию, актуальные для сервера с небольшим объемом ОЗУ и дисками HDD, а не для современных серверов. Надеюсь в скором времени это исправят.



