- Установка apache spark windows
- Latest Preview Release
- Link with Spark
- Installing with PyPi
- Release Notes for Stable Releases
- Archived Releases
- Apache Spark установка, настройка, запуск скриптов
- Оглавление:
- 1. Что такое Apache Spark.
- 2. Установка и настройка Apache Spark.
- 3. Запуск распределенных вычислений в Apache Spark (на примере скрипта python).
- Комментарии
- Spark 2: How to install it on Windows in 5 steps
- Before we begin:
- 1. Prerequisite — Java 8
- 2. Spark: Download and Install
- 3. Spark: Some more stuff (winutils)
- 4. Optional: Some tweaks to avoid future errors
- Hive Permissions Bug
- 5. Optional: Install Scala
- Testing Spark
- PySpark (Spark with Python)
- Scala-shell
- PySpark with PyCharm (Python 3.x)
- PySpark with Jupyter Notebook
- Big Data Engineering
- Установка Apache PySpark в Windows 10
- 1. Шаг 1
Установка apache spark windows
Choose a Spark release:
Choose a package type:
Verify this release using the and project release KEYS.
Note that, Spark 2.x is pre-built with Scala 2.11 except version 2.4.2, which is pre-built with Scala 2.12. Spark 3.0+ is pre-built with Scala 2.12.
Latest Preview Release
Preview releases, as the name suggests, are releases for previewing upcoming features. Unlike nightly packages, preview releases have been audited by the project’s management committee to satisfy the legal requirements of Apache Software Foundation’s release policy. Preview releases are not meant to be functional, i.e. they can and highly likely will contain critical bugs or documentation errors. The latest preview release is Spark 3.0.0-preview2, published on Dec 23, 2019.
Link with Spark
Spark artifacts are hosted in Maven Central. You can add a Maven dependency with the following coordinates:
Installing with PyPi
PySpark is now available in pypi. To install just run pip install pyspark .
Release Notes for Stable Releases
Archived Releases
As new Spark releases come out for each development stream, previous ones will be archived, but they are still available at Spark release archives.
NOTE: Previous releases of Spark may be affected by security issues. Please consult the Security page for a list of known issues that may affect the version you download before deciding to use it.
Apache Spark установка, настройка, запуск скриптов

Оглавление:
1. Что такое Apache Spark.
2. Установка и настройка Apache Spark.
3. Запуск распределенных вычислений в Apache Spark (на примере скрипта python).
Что такое Apache Spark.
Apache Spark – это универсальная и высокопроизводительная кластерная вычислительная платформа.
Фреймворк создан для того, чтобы охватить более широкий диапазон рабочих нагрузок, которые прежде требовали создания отдельных распределенных систем, включая приложения пакетной обработки, циклические алгоритмы, интерактивные запросы и потоковую обработку. Поддерживая все эти виды задач с помощью единого механизма, Spark упрощает и удешевляет объединение разных видов обработки, которые часто необходимо выполнять в едином конвейере обработки данных. Кроме того, он уменьшает бремя обслуживания, поддерживая отдельные инструменты.
Spark предоставляет простой API на языках Python, Java, Scala и SQL и богатую коллекцию встроенных библиотек. Он также легко объединяется с другими инструментами обработки больших данных. В частности, Spark может выполняться под управлением кластеров Hadoop и использовать любые источники данных Hadoop, включая Cassandra.
Внутренняя реализация Spark обеспечивает эффективное масштабирование от одного до многих тысяч вычислительных узлов. Для достижения такой гибкости Spark поддерживает большое многообразие диспетчеров кластеров (cluster managers), включая Hadoop YARN, Apache Mesos, а также простой диспетчер кластера, входящий в состав Spark, который называется Standalone Scheduler. При установке Spark на чистое множество машин на начальном этапе с успехом можно использовать Standalone Scheduler . При установке Spark на уже имеющийся кластер Hadoop YARN или Mesos можно пользоваться встроенными диспетчерами этих кластеров.
Проще говоря, Spark — это отдельный программный продукт, который может эффективно взаимодействовать с такими компонентами Hadoop как: YARN, HDFS, Hive, HBase.
Установка и настройка Apache Spark.
Скачаем архив с официального сайта . Тут необходимо выбрать версию Spark, я скачал версию spark-2.4.4.
После скачивания архива его нужно разархивировать и перенести извлеченный каталог в /usr/local с помощью команды sudo mv /откуда /куда.
Теперь необходимо настроить переменные окружения для этого запустим редактор (у меня gedit, можно vim или nano):
sudo gedit .bashrc
В конец добавить следующие строки с переменными:
Выйдем из редактора и применим настройки:
Теперь необходимо настроить файл spark-env.sh
Перейти в каталог настроек:
Создать файл spark-env.sh из шаблона (template):
sudo cp spark-env.sh.template spark-env.sh
Открыть spark-env.sh в редакторе:
sudo gedit spark-env.sh
И добавить в конец строки:
Сохранить изменения и выйти.
Создать файл slaves из шаблона (template):
sudo cp slaves.template slaves
Открыть slaves в редакторе:
sudo gedit slaves
Прописать здесь IP-адреса (или имена как у меня) всех подчиненных машин кластера(worker в spark) мастер также может выступать в роли worker-а (как в моем примере).
Сохранить изменения и выйти.
Все практически настроено, осталось только скопировать наши настройки (весь каталог spark) на подчиненные машины.
Сначала на всех подчиненных узлах выпонить:
— создать каталог Spark:
sudo mkdir /usr/local/spark-2.4.4
Назначить владельцем каталога пользователя (в нашем примере hduser):
sudo chown hduser:hadoop -R /usr/local/spark-2.4.4
Теперь можно синхронизировать каталоги, я пользуюсь утилитой rsync но можно и scp:
sudo rsync -avxP /usr/local/spark-2.4.4/ hduser@1VM:/usr/local/spark-2.4.4
и на вторую машину:
sudo rsync -avxP /usr/local/spark-2.4.4/ hduser@2VM:/usr/local/spark-2.4.4
Все готово к запуску, перейдем в каталог:
запустим spark на всех подчиненных узлах с помощью скрипта:
При удачном запуске увидим следующее:
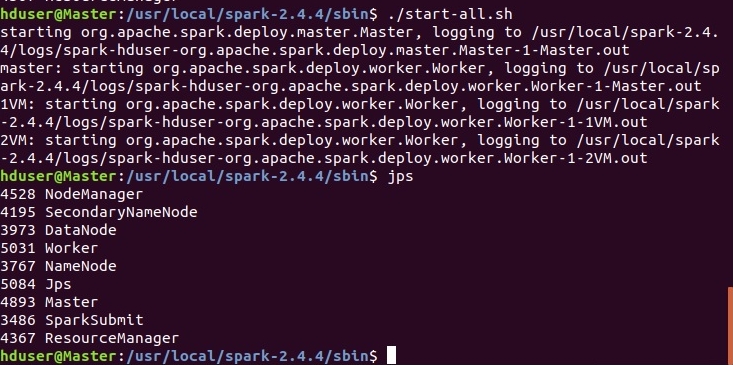
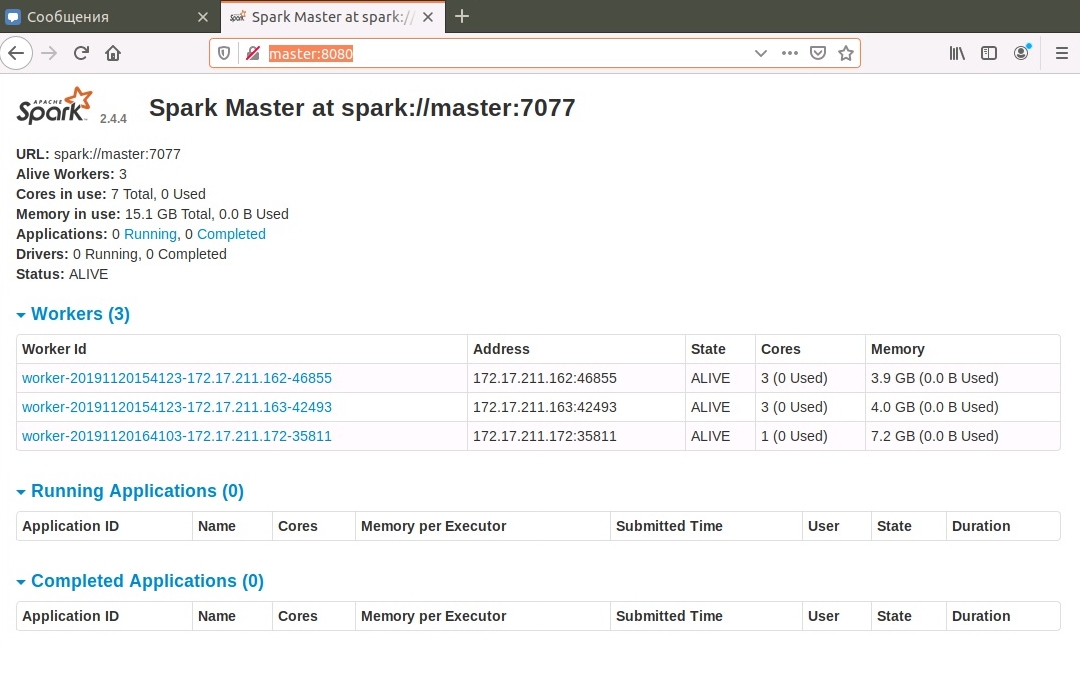
На мастере, порт 8080, доступен веб-интерфейс:
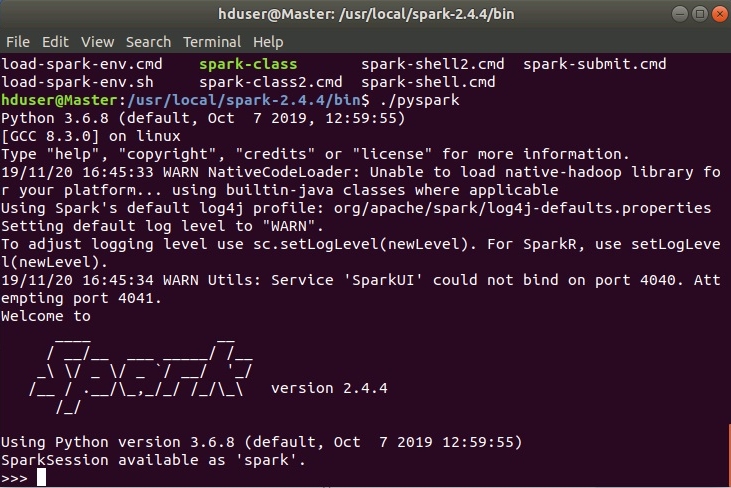
Также доступна командная строка pyspark. Она запускается из каталога $SPARK_HOME/bin:
При удачном запуске увидим следующее:
Все готово к распределенной обработке, приступим!
Запуск распределенных вычислений в Apache Spark (на примере скрипта python).
В этом разделе запустим скрипт python для подсчета слов в произведениях нашего любимого Уильяма Шекспира (в моем примере файл william.txt).
Для этого нам понадобится любой текстовый файл, который нужно загрузить в HDFS из локальной директории (в примере /home/hduser/william.txt):
Создадим входной каталог HDFS: hadoop fs -mkdir /input
Загружаем исследуемый файл в HDFS: hadoop fs -put /home/hduser/william.txt /input
Проверим, загрузился ли файл командой: hadoop fs -ls /input
Далее нам нужен сам скрипт wcount.py
Аккуратнее с форматированием файла! В синтаксисе python отступы важны!
Обратить внимание на следующие строки:
f = sc.textFile(«hdfs://Master:9000/input/*.txt») — здесь указан входной каталог, где хранится наш текстовый файл.
counts.saveAsTextFile(«/home/hduser/res/») — выходной каталог результата в локальной директории, каталог res не должен существовать, его создает сама программа, в противном случае ошибка.
Сам скрипт я создал в корневом каталоге spark, создав в нем файл и скопировав из браузера код:
sudo gedit $SPARK_HOME/wcount.py
Запуск скриптов осуществляется с помощью утилиты spark-submit в каталоге $SPARK_HOME/bin
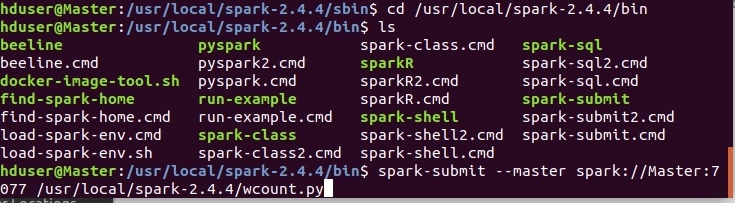
spark-submit —master spark://Master:7077 /usr/local/spark-2.4.4/wcount.py
Вместо имени хоста-мастера может быть его IP-адрес.
Все готово! Запускаем!
Процесс выполнения подробно логгируется, что наводит на мысли о серьезности производимых вычислений!)))
Итог при успешном завершении должен быть такой:
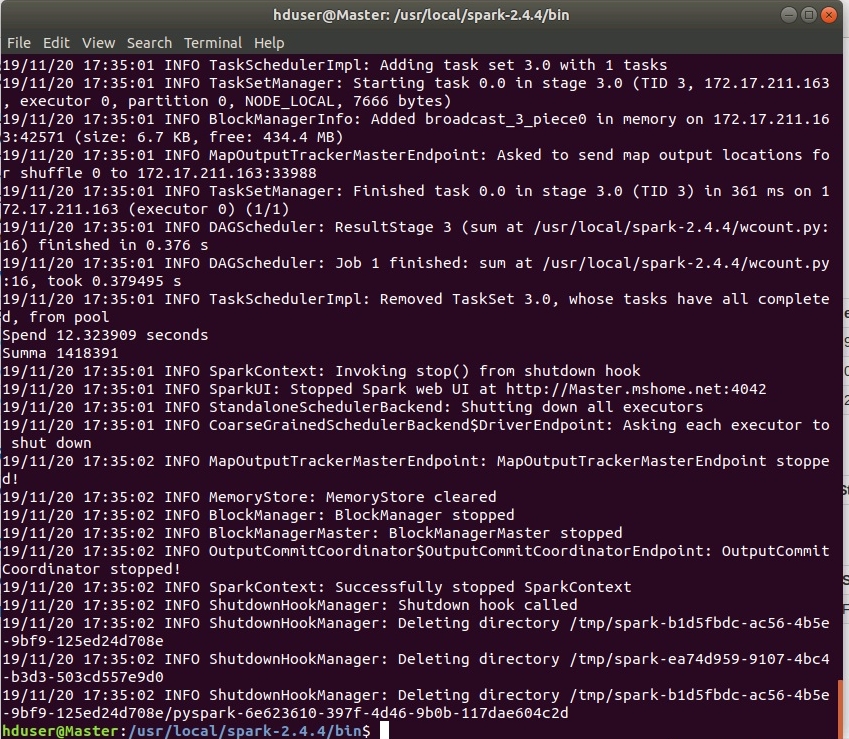
Задача выполнена, результат в каталоге /home/hduser/res/ файл part-00000! В нем приведены встретившиеся слова и напротив — их частота встречаемости.
Логи выполненной задачи также доступны в веб-интерфейсе:
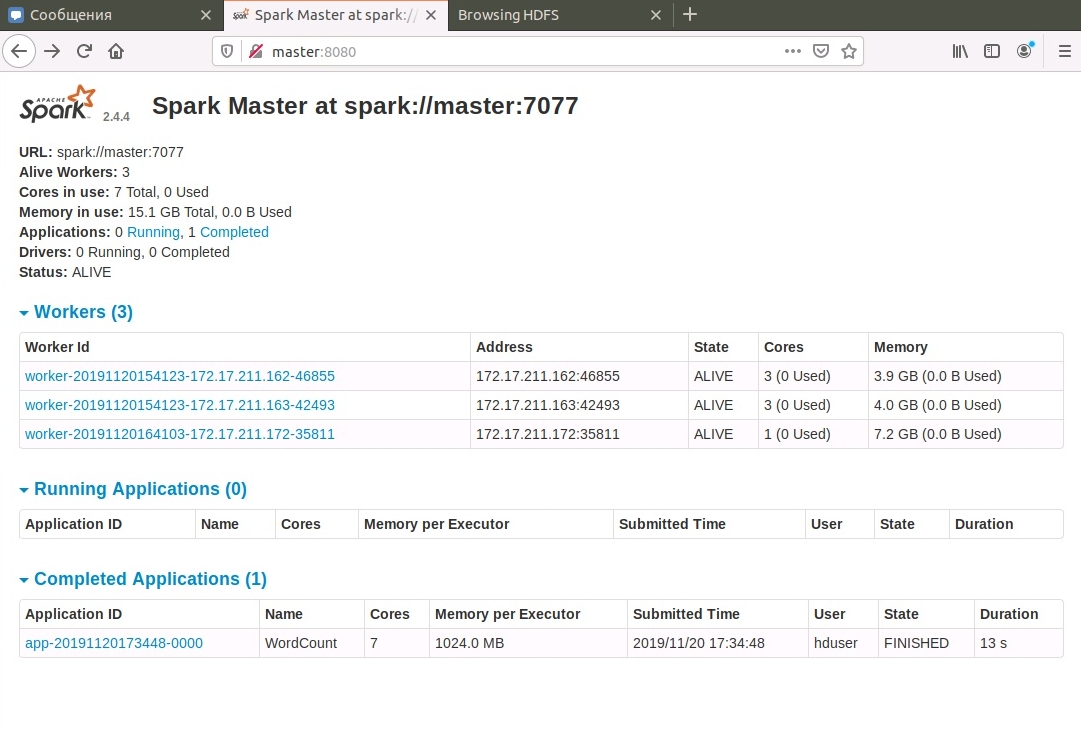
Вот как-то так, вопросы и критика принимаются в группе в контакте, или прямо здесь, в комментариях, доступных после регистрации.
Комментарии
Комментировать могуть только зарегистрированные пользователи
Spark 2: How to install it on Windows in 5 steps

This is a very easy tutorial that will let you install Spark in your Windows PC without using Docker.
By the end of the tutorial you’ll be able to use Spark with Scala or Python.

Before we begin:
It’s important that you replace all the paths that include the folder “Program Files” or “Program Files (x86)” as explained below to avoid future problems when running Spark.
If you have Java already installed, you still need to fix the JAVA_HOME and PATH variables
- Replace “Program Files” with “Progra
1”
Replace “Program Files (x86)” with “Progra
2”
Example: “C:\Program FIles\Java\jdk1.8.0_161” —> “C:\Progra
1. Prerequisite — Java 8
Before you start make sure you have Java 8 installed and the environment variables correctly defined:
- Download Java JDK 8 from Java’s official website
- Set the following environment variables:
- JAVA_HOME = C:\Progra
1\Java\jdk1.8.0_161
PATH += C:\Progra1\Java\jdk1.8.0_161\bin
- Optional: _JAVA_OPTIONS = -Xmx512M -Xms512M (To avoid common Java Heap Memory problems whith Spark)
1 is the shortened path for “Program Files”.
2. Spark: Download and Install
- Download Spark from Spark’s official website
- Choose the newest release ( 2.3.0 in my case)
- Choose the newest package type ( Pre-built for Hadoop 2.7 or later in my case)
- Download the . tgz file
2. Extract the .tgz file into D:\Spark
Note: In this guide I’ll be using my D drive but obviously you can use the C drive also
3. Set the environment variables:
- SPARK_HOME = D:\Spark\spark-2.3.0-bin-hadoop2.7
- PATH += D:\Spark\spark-2.3.0-bin-hadoop2.7\bin
3. Spark: Some more stuff (winutils)
- Download winutils.exe from here: https://github.com/steveloughran/winutils
- Choose the same version as the package type you choose for the Spark .tgz file you chose in section 2 “Spark: Download and Install” (in my case: hadoop-2.7.1)
- You need to navigate inside the hadoop-X.X.X folder, and inside the bin folder you will find winutils.exe
- If you chose the same version as me (hadoop-2.7.1) here is the direct link: https://github.com/steveloughran/winutils/blob/master/hadoop-2.7.1/bin/winutils.exe
2. Move the winutils.exe file to the bin folder inside SPARK_HOME,
- In my case: D:\Spark\spark-2.3.0-bin-hadoop2.7\bin
3. Set the folowing environment variable to be the same as SPARK_HOME:
4. Optional: Some tweaks to avoid future errors
This step is optional but I highly recommend you do it. It fixed some bugs I had after installing Spark.
Hive Permissions Bug
- Create the folder D:\tmp\hive
- Execute the following command in cmd started using the option Run as administrator
- cmd> winutils.exe chmod -R 777 D:\tmp\hive
3. Check the permissions
5. Optional: Install Scala

If you are planning on using Scala instead of Python for programming in Spark, follow this steps:
- Download the Scala binaries for Windows ( scala-2.12.4.msi in my case)
2. Install Scala from the .msi file
3. Set the environment variables:
2\scala
PATH += C:\Progra
2 is the shortened path for “Program Files (x86)”.
4. Check if scala is working by running the following command in the cmd
Testing Spark
PySpark (Spark with Python)

To test if Spark was succesfully installed, run the following code from pyspark’s shell (you can ignore the WARN messages):
Scala-shell
To test if Scala and Spark where succesfully installed, run the following code from spark-shell (Only if you installed Scala in your computer):
PD: The query will not work if you have more than one spark-shell instance open
PySpark with PyCharm (Python 3.x)
If you have PyCharm installed, you can also write a “Hello World” program to test PySpark
PySpark with Jupyter Notebook
You will need to use the findSpark package to make a Spark Context available in your code. This package is not specific to Jupyter Notebook, you can use it in you IDE too.
Install and launch the notebook from the cmd:
Create a new Python notebook and write the following at the beginning of the script:
Now you can add your code to the bottom of the script and run the notebook.
Big Data Engineering
Best technical posts about data (we love both small and…
Установка Apache PySpark в Windows 10
Дата публикации Aug 30, 2019

Последние несколько месяцев я работал над проектом Data Science, который обрабатывает огромный набор данных, и стало необходимым использовать распределенную среду, предоставляемую Apache PySpark.
Я много боролся при установке PySpark на Windows 10. Поэтому я решил написать этот блог, чтобы помочь любому легко установить и использовать Apache PySpark на компьютере с Windows 10.
1. Шаг 1
PySpark требует Java версии 7 или новее и Python версии 2.6 или новее. Давайте сначала проверим, установлены ли они, или установим их и убедимся, что PySpark может работать с этими двумя компонентами.
Установка Java
Проверьте, установлена ли на вашем компьютере Java версии 7 или новее. Для этого выполните следующую команду в командной строке.

Если Java установлена и настроена для работы из командной строки, выполнение вышеуказанной команды должно вывести информацию о версии Java на консоль. Иначе, если вы получите сообщение, подобное:
«Java» не распознается как внутренняя или внешняя команда, работающая программа или пакетный файл.
тогда вы должны установить Java.
б) Получить Windows x64 (например, jre-8u92-windows-x64.exe), если вы не используете 32-разрядную версию Windows, в этом случае вам нужно получитьWindows x86 Offlineверсия.
в) Запустите установщик.
d) После завершения установки закройте текущую командную строку, если она уже была открыта, снова откройте ее и проверьте, можете ли вы успешно запуститьJava — версиякоманда.
2. Шаг 2
питон
Python используется многими другими программными инструментами. Поэтому вполне возможно, что требуемая версия (в нашем случае версия 2.6 или более поздняя) уже доступна на вашем компьютере. Чтобы проверить, доступен ли Python и найти его версию, откройте командную строку и введите командуPython — версия
Если Python установлен и настроен для работы из командной строки, при выполнении вышеуказанной команды информация о версии Python должна выводиться на консоль. Например, я получил следующий вывод на моем ноутбуке:
C: \ Users \ uug20> python —version
Python 3.7.3
Вместо этого, если вы получите сообщение, как
«Python» не распознается как внутренняя или внешняя команда, работающая программа или пакетный файл ».
Это означает, что вам нужно установить Python. Для этого
а) Перейти к питонускачатьстр.
б) НажмитеПоследний выпуск Python 2ссылка.
c) Загрузите установочный файл MSI для Windows x86–64. Если вы используете 32-разрядную версию Windows, загрузите установочный файл MSI для Windows x86.
г) Когда вы запускаете установщик, наНастроить Pythonраздел, убедитесь, что опцияДобавить python.exe в путьвыбран. Если этот параметр не выбран, некоторые утилиты PySpark, такие как pyspark и spark-submit, могут не работать.
e) После завершения установки закройте командную строку, если она уже была открыта, снова откройте ее и проверьте, можете ли вы успешно запуститьPython — версиякоманда.
3. Шаг 3
Установка Apache Spark
а) Перейти к искрескачатьстр.
б) Выберите последнюю стабильную версию Spark.
с)Выберите тип упаковки: sвыберите версию, предварительно созданную для последней версии Hadoop, такую какПредварительно построен для Hadoop 2.6,
г)Выберите тип загрузки:ВыбратьПрямое скачивание,
д) Нажмите на ссылку рядом сСкачать Sparkзагрузить заархивированный tar-файл, заканчивающийся расширением .tgz, такой как spark-1.6.2-bin-hadoop2.6.tgz.
f) Для установки Apache Spark вам не нужно запускать какой-либо установщик. Извлеките файлы из загруженного tar-файла в любую папку по вашему выбору, используя7Zipинструмент / другие инструменты для разархивирования.
Убедитесь, что путь к папке и имя папки, содержащей файлы Spark, не содержат пробелов.
Я создал папку с именем spark на моем диске D и распаковал заархивированный tar-файл в папку с именем spark-2.4.3-bin-hadoop2.7. Таким образом, все файлы Spark находятся в папке с именем D: \ spark \ spark-2.4.3-bin-hadoop2.7. Давайте назовем эту папку SPARK_HOME в этом посте.
Чтобы проверить успешность установки, откройте командную строку, перейдите в каталог SPARK_HOME и введите bin \ pyspark. Это должно запустить оболочку PySpark, которую можно использовать для интерактивной работы со Spark.
Последнее сообщение содержит подсказку о том, как работать со Spark в оболочке PySpark с использованием имен sc или sqlContext. Например, при вводе sc.version в оболочке должна появиться версия Spark. Вы можете выйти из оболочки PySpark так же, как вы выходите из любой оболочки Python — набрав exit ().
Оболочка PySpark выводит несколько сообщений при выходе. Поэтому вам нужно нажать Enter, чтобы вернуться в командную строку.
4. Шаг 4
Настройка установки Spark
Первоначально, когда вы запускаете оболочку PySpark, она выдает много сообщений типа INFO, ERROR и WARN. Давайте посмотрим, как удалить эти сообщения.
Установка Spark в Windows по умолчанию не включает утилиту winutils.exe, которая используется Spark. Если вы не укажете своей установке Spark, где искать winutils.exe, вы увидите сообщения об ошибках при запуске оболочки PySpark, такие как
«ОШИБКА Shell: не удалось найти двоичный файл winutils в двоичном пути hadoop java.io.IOException: не удалось найти исполняемый файл null \ bin \ winutils.exe в двоичных файлах Hadoop».
Это сообщение об ошибке не препятствует запуску оболочки PySpark. Однако если вы попытаетесь запустить автономный скрипт Python с помощью утилиты bin \ spark-submit, вы получите ошибку. Например, попробуйте запустить скрипт wordcount.py из папки примеров в командной строке, когда вы находитесь в каталоге SPARK_HOME.
«Bin \ spark-submit examples \ src \ main \ python \ wordcount.py README.md»
Установка winutils
Давайте загрузим winutils.exe и сконфигурируем нашу установку Spark, чтобы найти winutils.exe.
a) Создайте папку hadoop \ bin внутри папки SPARK_HOME.
б) Скачатьwinutils.exeдля версии hadoop, для которой была создана ваша установка Spark. В моем случае версия hadoop была 2.6.0. Так что язагруженноеwinutils.exe для hadoop 2.6.0 и скопировал его в папку hadoop \ bin в папке SPARK_HOME.
c) Создайте системную переменную среды в Windows с именем SPARK_HOME, которая указывает путь к папке SPARK_HOME.
d) Создайте в Windows другую переменную системной среды с именем HADOOP_HOME, которая указывает на папку hadoop внутри папки SPARK_HOME.
Поскольку папка hadoop находится внутри папки SPARK_HOME, лучше создать переменную среды HADOOP_HOME, используя значение% SPARK_HOME% \ hadoop. Таким образом, вам не нужно менять HADOOP_HOME, если SPARK_HOME обновлен.
Если вы теперь запустите сценарий bin \ pyspark из командной строки Windows, сообщения об ошибках, связанные с winutils.exe, должны исчезнуть.
5. Шаг 5
Настройка уровня журнала для Spark
Каждый раз при запуске или выходе из оболочки PySpark или при запуске утилиты spark-submit остается много дополнительных сообщений INFO. Итак, давайте внесем еще одно изменение в нашу установку Spark, чтобы в консоль записывались только предупреждения и сообщения об ошибках. Для этого:
a) Скопируйте файл log4j.properties.template в папку SPARK_HOME \ conf как файл log4j.properties в папке SPARK_HOME \ conf.
b) Установите для свойства log4j.rootCategory значение WARN, console.
c) Сохраните файл log4j.properties.
Теперь любые информационные сообщения не будут записываться на консоль.
Резюме
Чтобы работать с PySpark, запустите командную строку и перейдите в каталог SPARK_HOME.
а) Чтобы запустить оболочку PySpark, запустите утилиту bin \ pyspark. Когда вы окажетесь в оболочке PySpark, используйте имена sc и sqlContext и введите exit (), чтобы вернуться в командную строку.
б) Чтобы запустить автономный скрипт Python, запустите утилиту bin \ spark-submit и укажите путь к вашему скрипту Python, а также любые аргументы, которые нужны вашему скрипту Python, в командной строке. Например, чтобы запустить скрипт wordcount.py из каталога examples в папке SPARK_HOME, вы можете выполнить следующую команду:
«bin \ spark-submit examples \ src \ main \ python \ wordcount.py README.md«
6. Шаг 6
Важно: я столкнулся с проблемой при установке
После завершения процедуры установки на моем компьютере с Windows 10 я получал следующее сообщение об ошибке.
Файл «C: \ Users \ uug20 \ Anaconda3 \ lib \ site-packages \ zmq \ backend \ cython \ __ init__.py», строка 6, в от . import (константы, ошибка, сообщение, контекст, ImportError: сбой загрузки DLL: указанный модуль не найден.
Решение:
Я просто разобрался, как это исправить!
В моем случае я не знал, что мне нужно добавить ТРИ пути, связанные с миникондами, в переменную окружения PATH.
C: \ Users \ uug20 \ Anaconda3
C: \ Users \ uug20 \ Anaconda3 \ Scripts
C: \ Users \ uug20 \ Anaconda3 \ Library \ bin
После этого я не получил никаких сообщений об ошибках, и pyspark начал работать правильно и открыл записную книжку Jupyter после ввода pyspark в командной строке.



