- Модуль BeautifulSoup4 в Python, разбор HTML.
- Извлечение данных из документов HTML и XML.
- Установка BeautifulSoup4 в виртуальное окружение:
- Содержание:
- Выбор парсера для использования в BeautifulSoup4.
- Парсер lxml .
- Парсер html5lib .
- Встроенный в Python парсер html.parser .
- Основные приемы работы с BeautifulSoup4.
- Навигация по структуре HTML-документа:
- Извлечение URL-адресов.
- Извлечение текста HTML-страницы.
- Поиск тегов по HTML-документу:
- Поиск тегов при помощи CSS селекторов:
- Дочерние элементы.
- Родительские элементы.
- Облегчаем себе жизнь с помощью BeautifulSoup4
- Начало
- Практика
- Как скачать и установить Python 3 на Ubuntu 18.04 (Linux)
- Как проверить текущую версию Python
- Как установить Python 3 на Linux через apt-get
- Как установить Python 3 на Linux из архива
- Ошибки, которые могут возникнуть при установке
- 1. Zipimport.zipimporterror
- 2. No module named ‘_ctypes’
- Как обновить команду python3 до последней версии
- Заключение
Модуль BeautifulSoup4 в Python, разбор HTML.
Извлечение данных из документов HTML и XML.
BeautifulSoup4 (bs4) — это библиотека Python для извлечения данных из файлов HTML и XML. Для естественной навигации, поиска и изменения дерева HTML, модуль BeautifulSoup4, по умолчанию использует встроенный в Python парсер | html.parser |. BS4 так же поддерживает ряд сторонних парсеров Python, таких как lxml , html5lib и xml (для разбора XML-документов).
Установка BeautifulSoup4 в виртуальное окружение:
Содержание:
Выбор парсера для использования в BeautifulSoup4.
BeautifulSoup4 представляет один интерфейс для разных парсеров, но парсеры неодинаковы. Разные парсеры, анализируя один и того же документ создадут различные деревья HTML. Самые большие различия будут между парсерами HTML и XML. Так же парсеры различаются скоростью разбора HTML документа.
Если дать BeautifulSoup4 идеально оформленный документ HTML, то различий построенного HTML-дерева не будет. Один парсер будет быстрее другого, но все они будут давать структуру, которая выглядит точно так же, как оригинальный документ HTML. Но если документ оформлен с ошибками, то различные парсеры дадут разные результаты.
Различия в построении HTML-дерева разными парсерами, разберем на короткой HTML-разметке:
Парсер lxml .
- Для запуска примера, необходимо установить модуль lxml .
- Очень быстрый, имеет внешнюю зависимость от языка C.
- Нестрогий.
Парсер html5lib .
- Для запуска примера, необходимо установить модуль html5lib .
- Ну очень медленный.
- Разбирает страницы так же, как это делает браузер, создавая валидный HTML5.
Обратите внимание, что парсер html5lib НЕ игнорирует висячий тег
, и к тому же добавляет открывающий тег
. Также html5lib добавляет пустой тег ( lxml этого не сделал).
Встроенный в Python парсер html.parser .
- Не требует дополнительной установки.
- Приличная скорость, но не такой быстрый, как lxml .
- Более строгий, чем html5lib .
Как и lxml , встроенный в Python парсер игнорирует закрывающий тег
. В отличие от html5lib , этот парсер не делает попытки создать правильно оформленный HTML-документ, добавив теги или .
Вывод: Парсер html5lib использует способы, которые являются частью стандарта HTML5, поэтому он может претендовать на то, что его подход самый «правильный«.
Основные приемы работы с BeautifulSoup4.
Чтобы разобрать HTML-документ, необходимо передать его в конструктор класса BeautifulSoup() . Можно передать строку или открытый дескриптор файла:
Первым делом документ конвертируется в Unicode, а HTML-мнемоники конвертируются в символы Unicode:
Дальнейшие примеры будут разбираться на следующей HTML-разметке.
Передача этого HTML-документа в конструктор класса BeautifulSoup() создает объект, который представляет документ в виде вложенной структуры:
Навигация по структуре HTML-документа:
Перемещаться по одному уровню можно при помощи атрибутов .previous_sibling и .next_sibling . Например, в представленном выше HTML, теги обернуты в тег
— следовательно они находятся на одном уровне.
Так же можно перебрать одноуровневые элементы данного тега с помощью .next_siblings или .previous_siblings .
Атрибут .next_element строки или HTML-тега указывает на то, что было разобрано непосредственно после него. Это могло бы быть тем же, что и .next_sibling , но обычно результат резко отличается.
Это потому, что в оригинальной разметке слово Tillie появилось перед точкой с запятой. Парсер обнаружил тег , затем слово Tillie, затем закрывающий тег , затем точку с запятой и оставшуюся часть предложения. Точка с запятой находится на том же уровне, что и тег , но слово Tillie встретилось первым.
Атрибут .previous_element является полной противоположностью .next_element . Он указывает на элемент, который был обнаружен при разборе непосредственно перед текущим:
При помощи атрибутов .next_elements и .previous_elements можно получить список элементов, в том порядке, в каком он был разобран парсером.
Извлечение URL-адресов.
Одна из распространенных задач, это извлечение URL-адресов, найденных на странице в HTML-тегах :
Извлечение текста HTML-страницы.
Другая распространенная задача — извлечь весь текст со HTML-страницы:
Поиск тегов по HTML-документу:
Найти первый совпавший HTML-тег можно методом BeautifulSoup.find() , а всех совпавших элементов — BeautifulSoup.find_all() .
Поиск тегов при помощи CSS селекторов:
Поиск тега под другими тегами:
Поиск тега непосредственно под другими тегами:
Поиск одноуровневых элементов:
Поиск тега по классу CSS:
Поиск тега по ID:
Дочерние элементы.
Извлечение НЕПОСРЕДСТВЕННЫХ дочерних элементов тега. Если посмотреть на HTML-разметку в коде ниже, то, непосредственными дочерними элементами первого
- будут являться три тега
и тег
- со всеми вложенными тегами.
Обратите внимание, что все переводы строк \n и пробелы между тегами, так же будут считаться дочерними элементами. Так что имеет смысл заранее привести исходный HTML к «нормальному виду«, например так: re.sub(r’>\s+
Извлечение ВСЕХ дочерних элементов. Эта операция похожа на рекурсивный обход HTML-дерева в глубину от выбранного тега.
Обратите внимание, что простой текст, который находится внутри тега, так же считается дочерним элементом этого тега.
Если внутри тега есть более одного дочернего элемента (как в примерен выше) и необходимо извлечь только текст, то можно использовать атрибут .strings или генератор .stripped_strings .
Генератор .stripped_strings дополнительно удаляет все переводы строк \n и пробелы между тегами в исходном HTML-документе.
Родительские элементы.
Что бы получить доступ к родительскому элементу, необходимо использовать атрибут .parent .
Taк же можно перебрать всех родителей элемента с помощью атрибута .parents .
Источник
Облегчаем себе жизнь с помощью BeautifulSoup4
Приветствую всех. В этой статье мы сделаем жизнь чуточку легче, написав легкий парсер сайта на python, разберемся с возникшими проблемами и узнаем все муки пайтона что-то новое.
Статья ориентирована на новичков, таких же как и я.
Начало
Для начала разберем задачу. Взял я малоизвестный сайт новостей об Израиле, так как сам проживаю в этой стране, и хочется читать новости без рекламы и не интересных новостей. И так, имеется сайт, на котором постятся новости: есть новости помеченные красным, а есть обычные. Те что обычные — не представляют собой ничего интересного, а отмеченные красным являются самым соком. Рассмотрим наш сайт.

Как видно сайт достаточно большой и есть много ненужной информации, а ведь нам нужно использовать лишь контейнер новостей. Давайте использовать мобильную версию сайта,
чтобы сэкономить себе же время и силы.
Как видите, сервер отдал нам красивый контейнер новостей (которых, кстати, больше чем на основном сайте, что нам на руку) без рекламы и мусора.
Давайте рассмотрим исходный код, чтобы понять с чем мы имеем дело.
Как видим каждая новость лежит по-отдельности в тэге ‘a’ и имеет класс ‘lenta’. Если мы откроем тэг ‘a’, то заметим, что внутри есть тэг ‘span’, в котором находится класс ‘time2’, либо ‘time2 time3’, а также время публикации и после закрытия тэга мы наблюдаем сам текст новости.
Что отличает важную новость от неважной? Тот самый класс ‘time2’ или ‘time2 time3’. Новости помеченые ‘time2 time3’ и являются нашими красными новостями. Раз уж суть задачи понятна, перейдем к практике.
Практика
Для работы с парсерами умные люди придумали библиотеку «BeautifulSoup4», в которой есть еще очень много крутых и полезных функций, но об этом в следующий раз. Нам также понадобиться библиотека Requests позволяющая отправлять различные http-запросы. Идем их скачивать.
(убедитесь, что стоит последняя версия pip)
Переходим в редактор кода и импортируем наши библиотеки:
Для начала сохраним наш URL в переменную:
Теперь отправим GET()-запрос на сайт и сохраним полученное в переменную ‘page’:
Код вернул нам статус код ‘200’, значит это, что мы успешно подключены и все в полном порядке.
Теперь создадим два списка (позже я объясню для чего они нужны):
Самое время воспользоваться BeautifulSoup4 и скормить ему наш page, указав в кавычках как он нам поможет ‘html.parcer’:
Если попросить его показать, что он там сохранил:
Нам вылезет весь html-код нашей страницы.
Теперь воспользуемся функцией поиска в BeautifulSoup4:
Давайте разберём поподробнее, что мы тут написали.
В ранее созданный список ‘news’ (к которому я обещал вернуться), сохраняем все с тэгом ‘а’ и классом ‘news’. Если попросим вывести в консоль все, что он нашел, он покажет нам все новости, что были на странице:
Как видите, вместе с текстом новостей вывелись теги ‘a’, ‘span’, классы ‘lenta’ и ‘time2’, а также ‘time2 time3’, в общем все, что он нашел по нашим пожеланиям.
Тут мы в цикле for перебираем весь наш список новостей. Если в новости мы находим тэг ‘span’ и класc ‘time2 time3’, то сохраняем текст из этой новости в новый список ‘filteredNews’.
Обратите внимание, что мы используем ‘.text’, чтобы переформатировать строки в нашем списке из ‘bs4.element.ResultSet’, который использует BeautifulSoup для своих поисков, в обычный текст.
Однажды я застрял на этой проблеме надолго в силу недопонимания работы форматов данных и неумения использовать debug, будьте осторожны. Таким образом теперь мы можем сохранять эти данные в новый список и использовать все методы списков, ведь теперь это обычный текст и, в общем, делать с ним, что нам захочется.
Выведем наши данные:
Вот что мы получаем:
Мы получаем время публикации и лишь интересные новости.
Дальше можно построить бот в Телеге и выгружать туда эти новости, либо создать виджет на рабочий стол с актуальными новостями. В общем, можно придумать удобный для себя способ узнавать о новостях.
Надеюсь эта статья поможет новичкам понять, что можно делать с помощью парсеров и поможет им немного продвинуться вперед с обучением.
Спасибо за внимание, был рад поделиться опытом.
Источник
Как скачать и установить Python 3 на Ubuntu 18.04 (Linux)
В этой статье мы скачаем и установим последнюю версию Python 3 на Ubuntu. Затем убедимся, что python установлен корректно, рассмотрим популярные ошибки и их решения.
Все команды выполнялись в Ubuntu 18.04 LTS, но эта статья поможет установить python на Ubuntu 16.04, Debian, Mint и другие Linux-системы.
Мы используем командную строку Ubuntu — Терминал, для работы. Вы можете открыть Терминал через поиск или комбинацию клавиш Ctrl+Alt+T.
Как проверить текущую версию Python
Проверка текущей версии программного обеспечения не только помогает вам получить номер версии этого программного обеспечения, установленного в вашей системе, но и проверяет, действительно ли программное обеспечение установлено в вашей системе.
Мы сделаем то же самое для Python, выполнив следующую команду в нашем терминале:

Версия будет отображаться, как показано в приведенном выше выводе. Число зависит от того, когда вы обновили систему.
У вас также может быть несколько версий Python, установленных в вашей системе. Следующая команда выведет список всех версий Python, которые есть в вашей системе:
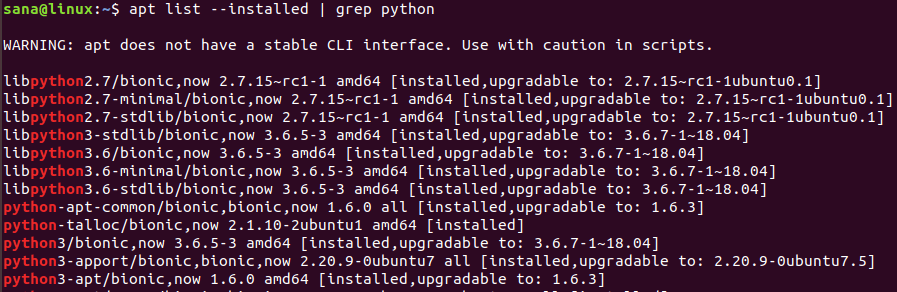
Как установить Python 3 на Linux через apt-get
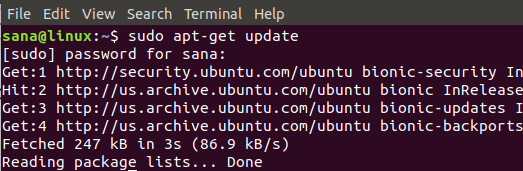
Установка Python 3 на Ubuntu с помощью команды apt-get довольно просто. Во-первых, вам необходимо обновить репозиторий системы, чтобы можно было установить последнюю доступную версию без проблем совместимости. Для этого выполните команду от имени администратора:
Так как Python уже установлен в нашей системе (это мы проверили в предыдущем разделе), нам нужно обновить его до последней версии следующим образом:
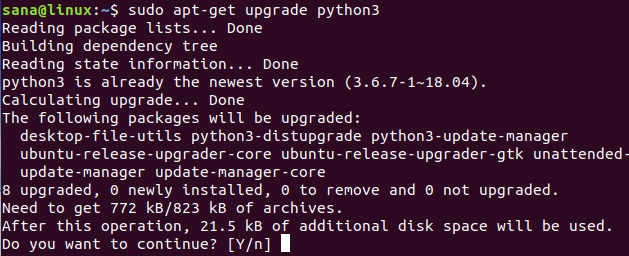
Система может попросить вас ввести пароль для прав sudo , поскольку только авторизованный пользователь может добавлять / удалять и обновлять программное обеспечение в Ubuntu.
Система также запросит подтверждение обновления. Введите Y , а затем нажмите Enter, чтобы продолжить.
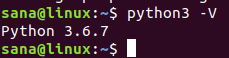
Так вы обновили Python до последней доступной версии. Проверьте:
Если Python не установлен, вы можете установить его с правами sudo используя команду apt-get :
Как установить Python 3 на Linux из архива
Сайт Python.org содержит список всех выпусков Python по этой ссылке:
https://www.python.org/downloads/source/
Поэтому, если вы решите установить Python вручную, можете скачать python любой сборки c официального сайта. На сайте также есть последние версии, которые вы не загрузите с помощью команды apt-get .
На момент подготовки материала Python-3.7.1 последняя доступная версия, поэтому мы скачаем его файл .tgz с помощью следующей команды:
Когда архив с ptyhon будет скачан, выполните следующую команду, чтобы извлечь файлы:
После того, как файлы извлечены, нужно запустить C-программу «configure». Для этого вам необходимо установить компилятор языка программирования C — gcc в вашу Linux-систему. Если он не предустановлен, установите его с помощью следующей команды:
Измените текущую директорию на Python-3.7.1 или на ту версию python, которую вы скачали и извлекли:
Теперь используйте следующую команду, чтобы запустить скрипт конфигурации:
Теперь пришло время установить Python.
Если вы не можете запустить команду make , установите make с помощью следующей команды:
Запустите следующую команду для установки языка программирования Python:
Скачанная версия Python с официального сайта установлена в вашей Linux-системе.
Ошибки, которые могут возникнуть при установке
1. Zipimport.zipimporterror
Когда вы запускаете команду sudo make install , можете столкнуться со следующей ошибкой:

Это значит, что нужно установить пакет с именем zlib1g-dev , так как он, возможно, вам не был нужен раньше.
Решение:
Выполните следующую команду с правами sudo, чтобы установить отсутствующий пакет zlib1g-dev :
Затем повторите команду для завершения установки Python:
2. No module named ‘_ctypes’
Это ошибка появляется также при запуске команды sudo make install :

Это значит, что нужно установить пакет с именем libffi-dev , так как он, возможно, вам не был нужен раньше.
Решение:
Выполните следующую команду с правами sudo, чтобы установить отсутствующий пакет libffi-dev :
Затем повторите команду для завершения установки Python:
Как обновить команду python3 до последней версии
Перед установкой Python вручную из архива номер версии нашей установки Python был 3.6.7
Когда я проверил номер версии python3.7 , он дает следующий вывод:
Обновите версию python для команды python3 следующей командой:
Теперь команда python3 работает с последней версией Python в моей системе (3.7.1).
Заключение
В большинстве версий Ubuntu уже установлены Python и Pip3, но после прочтения этой статьи вы узнали, как загрузить и обновить их до последних версий.
Источник



