- Favicon
- Обучаем вместе с Tesseract OCR
- 0. Что нам нужно
- 1. Создаём и редактируем box-файл
- Распознавание текста с картинки. Python Tesseract ORC + OpenCV
- Что сделаем за урок?
- Установка библиотеки
- Разработка проекта
- Установка Tesseract для OCR
- Знакомство с программой
- Установка Tesseract
- Проверка правильности установки
- Проверка Tesseract OCR
- Ограничения Tesseract
- Резюме
- Installing and using Tesseract 4 on windows 10
- Installing Tesseract 4 on a Windows Machine using .exe File:
- Index of /tesseract
- These executables are provided by Mannheim University Library. Licensed under the Apache License, Version 2.0 (the…
- How to use Tesseract 4 using Command Line on a Windows Machine
- tesseract-ocr/tessdata
- These language data files only work with Tesseract 4.0.0. They are based on the sources in tesseract-ocr/langdata on…
Favicon
Блог по web технологиям. Веб студия г. Воронеж. Создание и поддержка сайтов на заказ.
- Главная
- /
- Разное
- /
- Обучаем вместе с Tesseract OCR
Обучаем вместе с Tesseract OCR
Tesseract — свободная платформа для оптического распознавания текста, исходники которой Google подарил сообществу в 2006 году. Если вы пишете софт для распознавания текста, то вам наверняка приходилось обращаться к услугам этой мощной библиотеки. И если она не справилась с вашим текстом (а скорее всего это именно так), то выход у вас остаётся один — научить её. Процесс этот достаточно сложный и изобилует не очевидными, а порой и прям-таки магическими действиями.
Оригинальный проект находится на гитхабе, а скачать установщик можно здесь, На момент написания статьи версия установщика была 3.05.01. Мне понадобилось немало времени на постижение всей его глубины, поэтому я решил написать что и как, вдруг забуду что-то в будущем, а также чтобы помочь другим пройти этот путь в следующий раз быстрее.
0. Что нам нужно
- Tesseract собственно.
Сборки этой библиотеки есть под windows (можно скачать установщик отсюда) и под linux. Для большинства linux-дистрибутивов установить tesseract можно просто через sudo apt-get install tesseract-ocr.
- Изображение с текстом для тренировки
Желательно чтобы это был реальный текст, который потом придётся распознавать. Важно, чтобы каждый символ шрифта встречался в сканированном фрагменте не менее 5 раз, а желательно — 20 раз. Использовать будем формат tiff, без сжатия, желательно не многостраничный, но можно и многостраничный. Создать многостраничный tiff можно с помощью просмотрщика IrfanView .
Между всеми символами должны быть чётко различимые промежутки. Кладём наше изображение в отдельную директорию и называем в виде . .exp .tif. Изображение может быть не одно и отличаться они должны только номером в наименовании файла. Формат наименований файлов очень важен. На файлы с неверными наименованиями утилиты, которые мы будем использовать будут ругаться ошибками сегментирования и т.п. Для определённости будем считать, что изучаем мы язык ссс и шрифт eee. Таким образом называем файл со сканом тренировочного образца ccc.eee.exp0.tif
1. Создаём и редактируем box-файл
Для того чтобы отметить символы на изображении и задать им соответствие utf-8 символам текста служат box-файлы. Это обычные текстовые файлы, в которых каждому символу соответствует строка с символом и координатами прямоугольника в пикселях. Первоначально файл генерируем утилитой из пакета tesseract:
tesseract ccc.eee.exp0.tif ccc.eee.exp0 batch.nochop makebox
получим файл
в текущей директории. Заглянем в него. Да, чуть не забыл, не забудьте прописать адрес установленной Tesseract-OCR в переменную среды Path в windows, иначе команда tesseract не будет работать в консоли.
Символы в начале строки полностью соответствуют символам в файле? Если это так, то тренировать ничего не нужно, вы можете спать спокойно. В нашем случае скорее всего символы не будут совпадать ни по существу ни по количеству. Т.е. tesseract со словарём по умолчанию не распознал не только символы, но и посчитал некоторые из них за два или больше. Возможно часть символов у нас «слипнется», т.е. попадёт в общую коробку и будет распознано как один. Это всё нужно поправить прежде чем идти дальше.
Работа нудная и кропотливая, но к счастью для этого есть ряд сторонних утилит. Я например пользовался jTessBoxEditor. Открываем им изображение, box-файл с таким же именем он сам подтянет (главное чтобы всё лежало в одной папке).
Переходим на вкладку Box Editor перетаскиваем туда наше изображение, либо жмем Open . Поигравшись немного с вкладками Box Coordinates , где с помощью кнопок Merge , Split , Insert , Delete можно соответственно объединить, разделить, добавить или удалить символы, дабы привести все в соответствии с изображением справа. Во вкладке Box View можно поправить координаты распознаваемого символа.
Прошло полдня… Вы с чувством глубокого удовлетворения закрываете jTessBoxEditor (вы ведь не забыли сохранить результат, верно?) и у вас есть корректный box-файл. Теперь можно переходить к следующему этапу.
Распознавание текста с картинки. Python Tesseract ORC + OpenCV
Сегодня мы с вами поговорим на тему языка Python и рассмотрим пример создания крутого приложения. Наша программа будет способна считывать текст из любой фотографии.
Что сделаем за урок?
Мы с вами рассмотрим пример работы с библиотекой Tesseract ORC и на её основе построим приложение для распознавания текста с фото.
Что забавно, так это возраст библиотеки. Tesseract — является программой, разрабатывавшейся компанией Hewlett-Packard с середины 1980-х по середину 1990-х годов. Затем программа около 10 лет «пролежала на полке» и в августе 2006 года её купила Google. Google открыл исходный код под лицензией Apache 2.0 для продолжения разработки.
На сегодняшний день библиотека является наиболее крутым решением, если вам требуется считать данные из какого-либо фото.
Установка библиотеки
Первое, что необходимо сделать, то это выполнить установку Tesseract ORC. Установка Tesseract удобна на Маке и Линукс. Если вы на Windows, то придется выполнить на одно движение больше.
Если вы на Маке, то скачайте HomeBrew и далее в терминале пропишите brew install tesseract . Если вы на Линукс, тогда в зависимости от операционной системы вам нужно прописать соответствующую команду в терминале.
И если вы на Windows, то вам нужно скачать приложение на ПК. Вам нужно скачать файл Windows Installer . После скачивания выполните установку данной программы.
С самой программой вам никак не придется взаимодействовать, а лишь скопировать её расположение. Обычно оно устанавливается на диск С в Program files. Найдите вашу программу и скопируйте путь к этой папке.
Разработка проекта
Полная разработка проекта показывается в видео. Вы можете просмотреть его ниже:
Установка Tesseract для OCR
OCR — механический или электронный перевод изображений рукописного, машинописного или печатного текста в текстовые данные, использующихся для представления символов в компьютере.
Знакомство с программой
Tesseract первоначально разработана Hewlett Packard в 1980-х годах, в 2005 году был опубликован её исходный код. В августе 2006 г. Google купил её и открыл исходные тексты под лицензией Apache 2.0 для последующей разработки.
Программное обеспечение Tesseract работает со многими естественными языками от английского (первоначально) до панджаби. С момента обновления в 2015 году он поддерживает более 100 письменных языков и содержит обучаемый код для других языков. Поддержка русского языка реализована подключением дополнительных модулей.
Первоначально программа была написана на C, в 1998 году была перенесена на C ++. У неё нет графического интерфейса, но есть сторонние программные проекты, которые обертывают Tesseract для предоставления графического интерфейса пользователя.
Установка Tesseract
Чтобы использовать библиотеку Tesseract, необходимо установить её в операционную систему.
Для пользователей MacOS воспользуемся brew:
Если используется операционная система Ubuntu:
Пользователям Windows официальных бинарных сборок Tesseract не предоставляется, поэтому рекомендуется воспользоваться поисковыми системами для поисков сторонних сборок.
Проверка правильности установки
Чтобы проверить, что Tesseract был успешно установлен, выполним следующую команду:
В командную строку должна распеваться версия Tesseract, а также список совместимых библиотек форматов файлов изображений.
Если появилась ошибка:
тогда вернитесь к предыдущему шагу и устраните ошибки установки. Кроме того, может потребоваться обновить переменную окружения PATH (только для продвинутых пользователей).
Проверка Tesseract OCR
Для того чтобы получить разумные результаты в Tesseract OCR нужно предварительно обработать цифровыми фильтрами поступающие изображения.
При использовании Tesseract рекомендуется:
- Использовать входные изображения с максимально высоким разрешением и DPI;
- Применение пороговых фильтров для выделения текста из фона;
- Максимально чёткое сегментирование переднего плана по сравнению с задним фоном, без пикселяции или деформаций символов.
- Применение коррекции текста к входному изображению для обеспечения правильного выравнивания текста.
Отклонения от этих рекомендаций могут привести к неправильным результатам OCR.
Теперь применим OCR к следующему изображению:

Запустим команду в терминале:
Tesseract правильно распознал текст «Testing Tesseract OCR» и распечатал его в терминале.
Ограничения Tesseract
К сожалению, этот синтетический пример достаточно далёк от реальности. Если распознаваемый текст плохо отделим от фона или он сильно пикселирован, то Tesseract скорее всего вернёт ошибочные результаты. Tesseract лучше всего подходит для конвейерной обработки документов, в которых изображения сканируются, обрабатываются цифровыми фильтрами, а затем к ним применяется оптическое распознавание символов.
Следует отметить, что Tesseract не является готовым решением для OCR, которое сможет работать во всех приложениях обработки изображений и компьютерного зрения. Для сложных частных случаев необходимо применить методы извлечения признаков, машинное обучение и искусственный интеллект.
Резюме
Если обрабатываемые изображения не будут содержать чёткого текста, Tesseract даст плохие результаты. В случае зашумлённых входных изображений, получить лучшую точность можно обучая пользовательскую модель машинного обучения.
Tesseract лучше всего подходит для ситуаций с изображениями высокого разрешения, где текст переднего плана чётко отделим от фона.
Installing and using Tesseract 4 on windows 10


Tesseract is an optical character recognition engine which can be used on various operating systems. It’s a free software, released under the Apache License. Originally, Tesseract was developed by Hewlett-Packard as proprietary software in the 1980s, later, it was released as an open source software in 2005. Then from 2006, it’s development is being sponsored by Google. In this guide, I will take you through the steps that I followed in order to install Tesseract on my Windows 10 machine. I shall also show you how you can use tesseract off the command line once you have successfully installed it.
Installing Tesseract 4 on a Windows Machine using .exe File:
To install Tesseract 4 on our Windows system, go to the following link:
Index of /tesseract
These executables are provided by Mannheim University Library. Licensed under the Apache License, Version 2.0 (the…
Download windows executable file by clicking the hyper link titled tesseract-ocr-w64-setup-v4.1.0.20190314.exe. A notification asking you to save an exe file called “Tesseract-ocr-w64-setup-v4.1.0.20190314.exe” will appear. Save this .exe file wherever you have enough storage space.
Open this exe file. If it windows asks you “Do you want to allow this software to make changes to your system”, click yes. You will be taken to the installation section.
Hit next, click I agree to the terms and conditions and after selecting for whom and all you want to install Tesseract (anyone using this computer/just for me. You can select either one), click next.
Tick the boxes that say “ScrollView”, “Training Tools”, “Shortcuts creation” and importantly “Language data”. These should be ticked by default but just do them just in case they haven’t been ticked in your system.
Now, if you want to make predictions in foreign languages like Japanese, Chinese, Kurdish or Indian languages like Hindi, Tamil, Bengali etc., tick the “additional script data” and “additional language data” as well. If you want to make predictions only for the English language, you don’t have to tick this option.
Click on Next. Select the directory where you want to install Tesseract. By default it shows C:\Program Files\Tesseract-OCR for me and that’s where I installed it. You can install it as per your choice. But do take note of the path where you installed Tesseract on your machine. This is important.
Now you can select the start menu folder in which you would like to create the programs shortcut. I created it in a folder called “Tesseract-OCR”. If you want it in a new folder, just type the name of the folder in the blank space right under the “Select the Start Menu folder in which you would like ….” text.
You can also tick the “Do not create shortcuts” box in the bottom left if you don’t want to create any shortcuts. Once you are done with selecting your preferred option, click install. It should take a few minutes for the installation to happen.
Once the installation is over, go to the directory where you have installed your Tesseract. We want to use Tesseract from our windows command line and to do that, we have to add Tesseract to our path in the system’s environment variable.
To do so, click on your start button on windows and search “environment variable”. You will see a result called “Edit the system environment variables”. Click on that. After clicking this, you should be in the “Advanced” section of “System properties” and a button called “Environment Variables ….” should be visible on the bottom right. Click on that button.
Now, you will see two tables here. One named User variables for . Here, the is a variable that stands for the username using the PC currently. The other table called “System variables”. In the “System variables” table click on the variable called “Path” and then click on this button called “Edit” right above the “OK” button as shown down in the screenshot below.
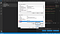
Once you’re done with this, you will see a page called “Edit environment variable”. Here on the top right, you will see a button called “New”. Click on that “New” button. You will get a blank space where you can add some text. Here, add your directory name where all your Tesseract-OCR files are stored.
Once you have keyed in the directory name, hit “Enter” and check if your directory name has been added to the “Edit environment variable table”. Once it has been, click “OK”. Click on OK again in the “Environment Variables” page. Click “OK” in the “System Properties” page again. You must have exited from all the settings options now.
Open command prompt and type tesseract —version on the command prompt and hit enter. You will see something like this:
If you see any error like tesseract command not found , most probably you have made some mistake while following this guide. Go back and see where have you gone wrong and try to fix it. Alternatively, you can repeat the whole process again.
Great! Now you have Tesseract installed on your machine. You can start playing around with it and explore it further.
How to use Tesseract 4 using Command Line on a Windows Machine
First, make sure you have some handwritten document or some typed document in the form of an image. Let’s say you have some photo in png form called handwritten_photo_1 on your Desktop and want to test Tesseract with it. Open your command prompt. You will start in this directory:
where username is your username on that system. I need to go to the desktop directory. So I use the following command:
Now I am in the Desktop directory, where my image is located. You can see what Tesseract predicts the text in the document using the following command:
Tesseract will directly output the text in the command line itself. The -l parameter is used to specify the language. Here we have specified it as English, which is the case by default anyway, so using -l eng was redundant in this case. If you want to use some other language for OCR, check this link here which has all the .traineddata files, which specify the language:
tesseract-ocr/tessdata
These language data files only work with Tesseract 4.0.0. They are based on the sources in tesseract-ocr/langdata on…
Say you have a text document written in Hindi. Then, go to this above link, click on the file titled hin.traineddata and download it. Once you have downloaded it, you need to move to the “tessdata” folder, which will be inside your directory where you had originally installed tesseract. Once you have done that, you can perform OCR of Hindi documents by using the following command:
Instead of displaying the OCR output on the command line itself, let’s say you want your OCR output to be stored in a text file. In that case you can enter the following command instead:
The text in handwritten_photo_1.png will be stored in a text file called output.txt which will be located in your present working directory, which was Desktop in my case.
Tesseract can also take a text file as input, where the text needs to contain all the absolute path of the images that you want to process.
This is especially useful when, let’s say you have two images handwritten in English called handwritten_photo_1.png and handwritten_photo_2.png in the C:\Program Files directory. Now, in your present working directory, you have a text file called input.txt whose contents are:
In the first and second line respectively.
Now if you want to store the contents of the these two handwritten photos in a text file, you can just do the following:
output.txt will have the OCR contents of both handwritten_photo_1.png and handwritten_photo_2.png , in that order. Here, you should note that input.txt was in the current working directory. You can use tesseract on a text file which is not in your present working directory either by including the directory location like here:
output.txt will again be located in the present working directory. You can do this for more than two photos as well. Note that the prediction for a new photo in the output.txt file will be preceded by some symbol as:
So in this case, Viral Calic is the prediction for the first image, CY am the king of the world the prediction for the second image, Com and Serr the prediction for the third image and so on. You can check the output for all your input images and check the accuracy of the predictions.
That’s it! Congratulations, you are now all set and ready to use Tesseract on your Windows 10 system.



