- Как я боролся с кодировками в консоли
- В чем разница между Linux и Windows.файлы txt (кодировка Unicode )
- 5 ответов
- разрывы строк
- Кодировка
- Проблемные Специальные Символы
- U+001A ЗАМЕНИТЬ
- U+FEFF ноль без пробела (Знак порядка байтов)
- Использование кодовой страницы UTF-8
- — API-интерфейсы и-W
- Задание кодовой страницы процесса UTF-8
- Примеры
- Преобразование кодовой страницы
- Кроссплатформенная работа со строками на C++
Как я боролся с кодировками в консоли
В очередной раз запустив в Windows свой скрипт-информер для СамИздат-а и увидев в консоли «загадочные символы» я сказал себе: «Да уже сделай, наконец, себе нормальный кросс-платформенный логгинг!»
Об этом, и о том, как раскрасить вывод лога наподобие Django-вского в Win32 я попробую рассказать под хабра-катом (Всё ниженаписанное применимо к Python 2.x ветке)
Задача первая. Корректный вывод текста в консоль
Симптомы
До тех пор, пока мы не вносим каких-либо «поправок» в проинициализировавшуюся систему ввода-вывода и используем только оператор print с unicode строками, всё идёт более-менее нормально вне зависимости от ОС.
«Чудеса» начинаются дальше — если мы поменяли какие-либо кодировки (см. чуть дальше) или воспользовались модулем logging для вывода на экран. Вроде бы настроив ожидаемое поведение в Linux, в Windows получаешь «мусор» в utf-8. Начинаешь править под Win — вылезает 1251 в консоли…
Теоретический экскурс
Ищем решение
Очевидно, чтобы избавиться от всех этих проблем, надо как-то привести их к единообразию.
И вот тут начинается самое интересное:
Ага! Оказывается «система» у нас живёт вообще в ASCII. Как следствие — попытка по-простому работать с вводом/выводом заканчивается «любимым» исключением UnicodeEncodeError/UnicodeDecodeError .
Кроме того, как замечательно видно из примера, если в linux у нас везде utf-8, то в Windows — две разных кодировки — так называемая ANSI, она же cp1251, используемая для графической части и OEM, она же cp866, для вывода текста в консоли. OEM кодировка пришла к нам со времён DOS-а и, теоретически, может быть также перенастроена специальными командами, но на практике никто этого давно не делает.
До недавнего времени я пользовался распространённым способом исправить эту неприятность:
И это, в общем-то, работало. Работало до тех пор, пока пользовался print -ом. При переходе к выводу на экран через logging всё сломалось.
Угу, подумал я, раз «оно» использует кодировку по-умолчанию, — выставлю-ка я ту же кодировку, что в консоли:
Уже чуть лучше, но:
- В Win32 текст печатается кракозябрами, явно напоминающими cp1251
- При запуске с перенаправленным выводом опять получаем не то, что ожидалось
- Периодически, при попытке напечатать текст, где есть преобразованный в unicode символ типа ① ( ① ), «любезно» добавленный автором в какой-нибудь заголовок, снова получаем UnicodeEncodeError !
Присмотревшись к первому примеру, нетрудно заметить, что так желаемую кодировку «cp866» можно получить только проверив атрибут соответствующего потока. А он далеко не всегда оказывается доступен.
Вторая часть задачи — оставить системную кодировку в utf-8, но корректно настроить вывод в консоль.
Для индивидуальной настройки вывода надо переопределить обработку выходных потоков примерно так:
Этот код позволяет убить двух зайцев — выставить нужную кодировку и защититься от исключений при печати всяких умляутов и прочей типографики, отсутствующей в 255 символах cp866.
Осталось сделать этот код универсальным — откуда мне знать OEM кодировку на произвольном сферическом компе? Гугление на предмет готовой поддержки ANSI/OEM кодировок в python ничего разумного не дало, посему пришлось немного вспомнить WinAPI
… и собрать всё вместе:
Задача вторая. Раскрашиваем вывод
Насмотревшись на отладочный вывод Джанги в связке с werkzeug, захотелось чего-то подобного для себя. Гугление выдаёт несколько проектов разной степени проработки и удобности — от простейшего наследника logging.StreamHandler , до некоего набора, при импорте автоматически подменяющего стандартный StreamHandler.
Попробовав несколько из них, я, в итоге, воспользовался простейшим наследником StreamHandler, приведённом в одном из комментов на Stack Overflow и пока вполне доволен:
Однако, в Windows всё это работать, разумеется, отказалось. И если раньше можно было «включить» поддержку ansi-кодов в консоли добавлением «магического» ansi.dll из проекта symfony куда-то в недра системных папок винды, то, начиная (кажется) с Windows 7 данная возможность окончательно «выпилена» из системы. Да и заставлять юзера копировать какую-то dll в системную папку тоже как-то «не кошерно».
Снова обращаемся к гуглу и, снова, получаем несколько вариантов решения. Все варианты так или иначе сводятся к подмене вывода ANSI escape-последовательностей вызовом WinAPI для управления атрибутами консоли.
Побродив некоторое время по ссылкам, набрёл на проект colorama. Он как-то понравился мне больше остального. К плюсам именно этого проекта ст́оит отнести, что подменяется весь консольный вывод — можно выводить раскрашенный текст простым print u»\x1b[31;40mЧто-то красное на чёрном\x1b[0m» если вдруг захочется поизвращаться.
Сразу замечу, что текущая версия 0.1.18 содержит досадный баг, ломающий вывод unicode строк. Но простейшее решение я привёл там же при создании issue.
Собственно осталось объединить оба пожелания и начать пользоваться вместо традиционных «костылей»:
Дальше в своём проекте, в запускаемом файле пользуемся:
На этом всё. Из потенциальных доработок осталось проверить работоспособность под win64 python и, возможно, добаботать ColoredHandler чтобы проверял себя на isatty, как в более сложных примерах на том же StackOverflow.
Источник
В чем разница между Linux и Windows.файлы txt (кодировка Unicode )
Я использую только 128 символов, определенных в исходном стандарте ANSI.
но в целом, как файлы implmeneted по-разному.
меня не волнует дисплей, т. е. если вкладка отображается с 6 или 8 символами, но фактическое внутреннее представление в памяти
одно из различий, которое я слышал, — это использование rn (Windows) и n для завершения строки (Linux).
5 ответов
«Unicode» в Windows-UTF-16LE, и каждый символ равен 2 или 4 байтам. Linux использует UTF-8, и каждый символ составляет от 1 до 4 байт.
разрывы строк
Windows использует CRLF ( \r\n , 0D 0A ) окончания строк, в то время как Unix просто использует LF ( \n , 0A ).
Кодировка
самые современные (т. е. с 2004 года или около того) Unix-подобные системы делают UTF-8 кодировка символов по умолчанию.
Windows, однако, не имеет встроенной поддержки UTF-8. Он внутренне работает в UTF-16, и предполагает, что char -строки на основе находятся в наследство страницу код. К счастью, Блокнот способен читать файлы UTF-8; к сожалению, кодировка «ANSI»еще по умолчанию.
Проблемные Специальные Символы
U+001A ЗАМЕНИТЬ
в Windows (редко) использует Ctrl + Z как символ конца файла. Например, если вы type файл в командной строке, он будет усечен на первом 1A байт.
В Unix, Ctrl + Z ничего особенного.
U+FEFF ноль без пробела (Знак порядка байтов)
в Windows файлы UTF-8 часто начинаются с «метки порядка байтов» EF BB BF , чтобы отличить их от файлов ANSI.
в Linux BOM не рекомендуется, потому что он ломает такие вещи, как строки shebang в сценариях оболочки. Кроме того, было бы бессмысленно иметь подпись UTF-8, когда UTF-8 является кодировкой по умолчанию.
одно из различий, которое я слышал, — это использование \r\n (Windows) и \n для разрывов строк (Linux).
да. Большинство текстовых редакторов UNIX будут обрабатывать это автоматически, Редакторы программистов Windows могут обрабатывать это, общие текстовые редакторы (базовый Блокнот) не будут.
Windows, кажется, также нужен EOF (Ctrl-Z) как КОНЕЦ ФАЙЛА в некоторых контекстах, в то время как вы, вероятно, никогда не увидите его на UNIX.
помните, что MacOS X теперь UNIX внизу, поэтому он использует окончания строк UNIX. Хотя до OS X (MacOS 9 и ниже) у нее была своя концовка (\r)
EDIT: в другом формате CR и LF:
- \n-ASCII 0x0A ,перевод строки (LF)
- \R-ASCII 0x0D, возврат каретки (CR)
какая кодировка Unicode используется не на основе ОС.
даже блокнот Windows.exe имеет перечисленные параметры — (я поставлю в скобках, что означает Блокнот) Стандарт ANSI(не Unicode), Юникод(Блокнот означает Юникод ЛЕ), с обратным порядком байтов Юникода(быть), в UTF-8
ANSI не является unicode, он включает в себя очень ограниченное количество символов, поэтому давайте отложим это.
но смотри даже блокнот может сделать LE, или BE, или UTF-8
и блокнот в сторону, UTF-8 может быть с или без ВЕДОМОСТЬ МАТЕРИАЛОВ.
и я использую Windows с Cygwin, хотя порты Windows вполне могут делать \r\n, даже если вы укажете \n, видели, что sed это делает.
существует одно правило, что в кодировке Юникод конкретной ОС. Это была бы не очень гибкая ОС, если бы она была.
чтобы действительно увидеть различия знать программное обеспечение, что кодирование кусок программного обеспечения использует или предлагает.
получить Cygwin и xxd, и / или шестнадцатеричный редактор и посмотреть, что на самом деле внутри файла. Используйте команда ‘file’ помогает идентифицировать файл. Тогда вы действительно видите, что такое UTF 16bit LE. Что UTF 16bit быть. Что такое UTF-8 (и UTF-8 может быть с или без BOM).
иногда вы можете сказать Блокноту сохранить как unicode(под которым Блокнот означает 16 бит unicode little endian), и он не будет. Но выберите шрифт unicode, такой как arial unicode, и скопируйте некоторые символы unicode из charmap, и это будет.. И хороший способ увидеть, что делает блокнот или любое другое программное обеспечение, — это посмотреть на hex файла
команда dd (команда *nix, которую я запускаю из cygwin в windows) может переключить ее
и сам Блокнот может сохранить как UTF-16 Big Endian или UTF-16 Little Endian или UTF-8
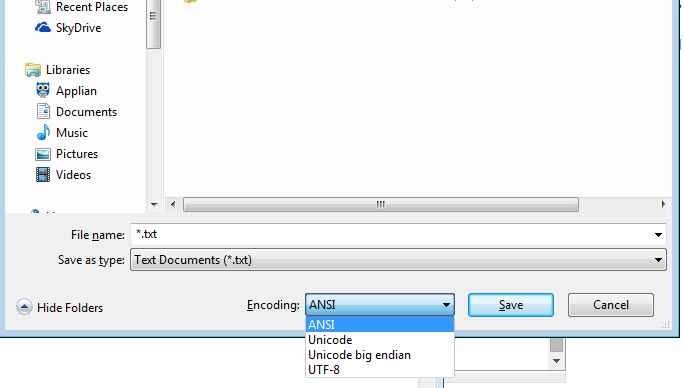
Если вы технический человек или даже просто пользователь Блокнота, вы не привязаны к одной кодировке из-за своей ОС!
Я полагаю, что UTF-8 имеет больше смысла, чем UTF-16, UTF-16 будет использовать 16 бит даже для символов для этого нужно всего 8 бит. Кроме того, имейте в виду, что charmap показывает код UTF-16.
Sublime (текстовый редактор windows) сохраняет Юникод как UTF-8 по умолчанию.
Я использую Windows, а иногда и unicode, и я использую UTF-8 в основном.
и поскольку Windows технически гибка, linux, по крайней мере, технически гибок!
Источник
Использование кодовой страницы UTF-8
Используйте кодировку UTF-8 для обеспечения оптимальной совместимости между веб-приложениями и другими * платформами на основе nix (UNIX, Linux и разновидности), свести к сведению ошибки локализации и снизить затраты на тестирование.
UTF-8 — это универсальная кодовая страница для интернационализации и способная кодировать весь набор символов Юникода. Он используется в Интернете по умолчанию, а также на платформах на основе NIX.
Закодированный символ занимает от 1 до 4 байт. Кодировка UTF-8 поддерживает более длинные последовательности байтов (до 6 байт), но большая кодовая точка Юникода 6,0 (U + 10FFFF) занимает всего 4 байта.
— API-интерфейсы и-W
Интерфейсы API Win32 часто поддерживают варианты «-A» и «W».
— Варианты, распознаваемые кодовую страницу ANSI, настроенную для системы и поддержки char* , а варианты-W работают в кодировке UTF-16 и поддерживают WCHAR .
до последнего момента Windows выделены «юникод»-W variant через api. Однако последние выпуски использовали кодовую страницу ANSI и — API-интерфейсы в качестве средства для поддержки приложений в кодировке UTF-8. Если кодовая страница ANSI настроена для UTF-8, то API-интерфейсы работают в кодировке UTF-8. Эта модель имеет преимущество поддержки существующего кода, построенного с помощью API-интерфейсов, без изменения кода.
Задание кодовой страницы процесса UTF-8
начиная с версии Windows 1903 (обновление 2019 мая) можно использовать свойство активекодепаже в appxmanifest для упакованных приложений или манифест fusion для неупакованных приложений, чтобы принудительно использовать UTF-8 в качестве кодовой страницы процесса.
вы можете объявить это свойство и целевой объект или выполнить его в более ранних Windows сборках, но необходимо как обычно выполнять обнаружение и преобразование кодовых страниц прежних версий. с минимальной целевой версией Windows версии 1903, кодовая страница процесса всегда будет UTF-8, поэтому можно избежать обнаружения и преобразования кодовой страницы прежних версий.
Примеры
Манифест appx для упакованного приложения:
Манифест Fusion для неупакованного приложения Win32:
Добавление манифеста в существующий исполняемый файл из командной строки с помощью команды mt.exe -manifest -outputresource: ;#1
Преобразование кодовой страницы
по мере того, как Windows работает в кодировке utf-16 ( WCHAR ), может потребоваться преобразовать данные utf-8 в utf-16 (или наоборот) для взаимодействия с интерфейсами api Windows.
MultiByteToWideChar и WideCharToMultiByte позволяют выполнить преобразование между UTF-8 и UTF-16 ( WCHAR ) (и другими кодовыми страницами). Это особенно полезно, когда устаревший API Win32 может понимать только WCHAR . Эти функции позволяют преобразовать входные данные UTF-8 в WCHAR для передачи в API-интерфейс, а затем преобразовать все результаты при необходимости. При использовании этих функций с CodePage параметром CP_UTF8 , имеющим значение, используйте dwFlags либо 0 или MB_ERR_INVALID_CHARS , в противном случае — ERROR_INVALID_FLAGS .
CP_ACP«CP_UTF8 соответствует только в том случае, если работает на Windows версии 1903 (май 2019) или выше, а свойство активекодепаже, описанное выше, имеет значение UTF-8. В противном случае она учитывает устаревшую системную кодовую страницу. Рекомендуется использовать CP_UTF8 явно.
Источник
Кроссплатформенная работа со строками на C++
Не так давно озадачился вопросом кроссплатформенной работы со строками в приложениях c++. Задача была, грубо говоря, поставлена как регистронезависимый поиск подстроки в любой кодировке на любой платформе.
Итак, первое с чем пришлось понять — что со строками в Линуксе нужно работать в кодировке UTF-8 и в типе std::string, а в Windows строки должны быть в UTF-16LE (тип std::wstring). Почему? Потому что это by design операционных систем. Хранить строки в std::wstring в Линуксе крайне накладно, поскольку один символ wchar_t занимает 4 байта (в Windows — 2 байта), а работать std::string в Windows нужно было во времена Windows 98. Для работы со строками определяем свой платформонезависимый тип:
Второе — задача преобразование текста из любой кодировки в тип mstring. Тут вариантов не так много. Первый вариант — использование std::locale и прочих соответствующих стандартных вещей. Сразу бросилось в глаза необходимость поиска для каждого charset’a соотвествующей ему локали (типа кодировке «windows-1251» соответствует локаль Russian_Russia.1251 и т.п.). В стандартной библиотеке такая таблица не нашлась (может плохо искал?), искать примочку для списка локалей не захотелось. Да и вообще, работа с локалалями в C++ вещь очень неочевидная, на мой взгляд. На форумах советовали использовать библиотеки libiconv или icu. libiconv выглядел очень легко и просто, с задачей перекодировки из любого charset’a в mstring справлялся отлично, но когда дело дошло до преобразования mstring в нижний регистр меня постиг fail. Оказалось libiconv делать это не умеет, а преобразовать строку utf8 в нижний регистр просто и красиво в Линуксе у меня не получилось. Итак, выбор пал на icu, который с честью решил все поставленные задачи (конвертация и перевод в нижний регистр). Процедура платформонезависимой перекодировки с использованием библиотеки icu выглядит примерно так:
Вопросы работы с Юникодом в Windows описывать не буду — все там достаточно хорошо документировано.
Источник



