- Как сменить locale в Debian или пишем кириллицей в консоли linux
- Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux
- Программы для определения кодировки в Linux
- Команда file -i показывает неверную кодировку
- Программа enca для определения кодировки файла
- Как определить кодировку строки
- Изменение кодировки в Linux
- Использование команды iconv
- Конвертирование файлов из windows-1251 в UTF-8 кодировку
- Изменение кодировки программой enca
- Конвертация строки в правильную кодировку
- Linux Mint Forums
- Проблемы с кодировкой — Linux Mint 18.1 Cinnamon
- Проблемы с кодировкой — Linux Mint 18.1 Cinnamon
- Re: Проблемы с кодировкой — Linux Mint 18.1 Cinnamon
- Re: Проблемы с кодировкой — Linux Mint 18.1 Cinnamon
- Re: Проблемы с кодировкой — Linux Mint 18.1 Cinnamon
- Re: Проблемы с кодировкой — Linux Mint 18.1 Cinnamon
- Re: так я tty-консоли русифицировал от кракозябров
- Re: Проблемы с кодировкой — Linux Mint 18.1 Cinnamon
- How to Convert Files to UTF-8 Encoding in Linux
- Convert Files from UTF-8 to ASCII Encoding
- Convert Multiple Files to UTF-8 Encoding
- If You Appreciate What We Do Here On TecMint, You Should Consider:
Как сменить locale в Debian или пишем кириллицей в консоли linux

Я знаю что кириллица в логах Linux – это самый страшный грех для айтишника, но иногда это просто необходимость. Одна из таких необходимостей возникает при создании централизованного хранения log-файлов различных операционных систем. Microsoft всегда в своих log`ах применяет кириллицу и поэтому если мы хотим получать log-файлы и от Win-серверов, то стоит смириться, что в log`ах будет кирилица.
Для того, чтобы эти логи нормально отображались нам и нужно явно указать locale в Debian, Ubuntu или какой Linux-дистрибутив Вы используете.
Проблемы отображения кириллических символов в Linux не существует. Есть проблема у русской версии Windows. Весь мир и Linux в том числе, работает в кодировке UTF -8, когда русская версия Microsoft использует CP1251. Такая ситуация сложилось исторически благодаря компании «Парус», которая взяла на себя обязательства по локализации всех операционных систем Windows. Выбрали они почему-то кодировку CP1251, которая применяется до сих пор. Использование этой «неправильной» кодировки в наши дни обусловлено сохранением совместимости всех версий ОС.
Чтобы добавить кириллицу, чтобы Linux сервер нормально отображал русские буквы, нужно объяснить ему, что необходимо работать в той же кодировке, что и Windows.
Для того, чтобы управлять локалью в Linux, необходим пакет locales, который должен быть у Вас установлен. В большинстве случаев пакет locales уже будет у Вас установлен, поэтому для проформы просто проверяем этот факт.
Посмотреть установленную locale linux можно командой:
Для ручного указания кодировке в Linux Mint, Debian или ubuntu нужно отредактировать конфигурационный файл /etc/locale.gen :
Команду sudo не нужна, если Вы зашли как суперпользователь. Это относится к Linux Mint и Ubuntu, так как Debian ничего не знает о команде sudo.
В этом файле необходимо найти строчку и расскомментировать с той locale, которая Вам нужна. Для добавления кириллицы нужно раскомментировать строчки с UTF-8 или CP1251 .
- если хотим указать, чтобы ОС работала в UTF -8, раскомментирум:
- если хотим указать, чтобы ОС работала в CP1251, раскомментирум:
Стоит обратить внимание, что первые 2 символа (в нашем примере это ru) говорят нам о языке локализации (кириллица).
После этого переопределяем настройки locales командой:
Команда locale-gen позволяет запустить скрипт /etc/locale.gen и перечитывает все кодировки для консоли.
Чтобы увидеть кириллицу в консоли Linux, остается только перелогиниться.
Источник
Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux
В этой инструкции мы опишем что такое кодировка символов и рассмотрим несколько примеров конвертации файлов из одной кодировки в другую с использованием инструмента командной строки. Наконец, мы узнаем, как на Linux конвертировать несколько файлов из одного набора символов (charset) в UTF-8 кодировку.
Возможно, вы уже в курсе, что компьютер не понимает и не сохраняет буквы, числа или что-то ещё чем обычно оперируют люди. Компьютер работает с битами. Бит имеет только два возможных значения: 0 или 1, «истина» или «ложь», «да» или «нет». Все другие вещи, вроде букв, цифр, изображений должны быть представлены в битах, чтобы компьютер мог их обрабатывать.
Говоря простыми словами, кодировка символов – это способ информирования компьютера о том, как интерпретировать исходные нули и единицы в реальные символы, где символ представлен набором чисел. Когда мы печатаем текст в файле, слова и предложения, которые мы формируем, готовятся из разных символов, а символы упорядочиваются в кодировку.
Имеются различные схемы кодирования, среди них такие как ASCII, ANSI, Unicode. Ниже пример ASCII кодировки.
Программы для определения кодировки в Linux
Команда file -i показывает неверную кодировку
Чтобы узнать кодировку файла используется команда file с флагами -i или —mime, которые включают вывод строки с типом MIME. Пример:

Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
Установим программу enca:
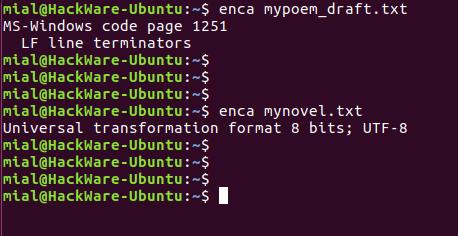
В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
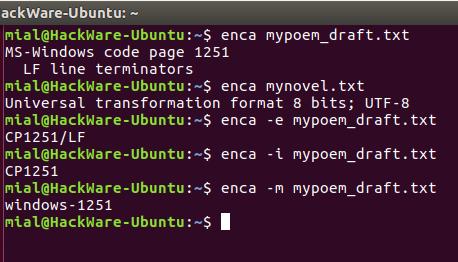
Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
Чтобы узнать список доступных языков наберите:
Как определить кодировку строки
Для определения, в какой кодировке строка, используйте одну из следующих конструкций:
Вместо СТРОКА_ДЛЯ_ПРОВЕРКИ впишите строку, для которой нужно узнать кодировку. Если у вас строка не на русском языке, то откорректируйте значение опции -L.
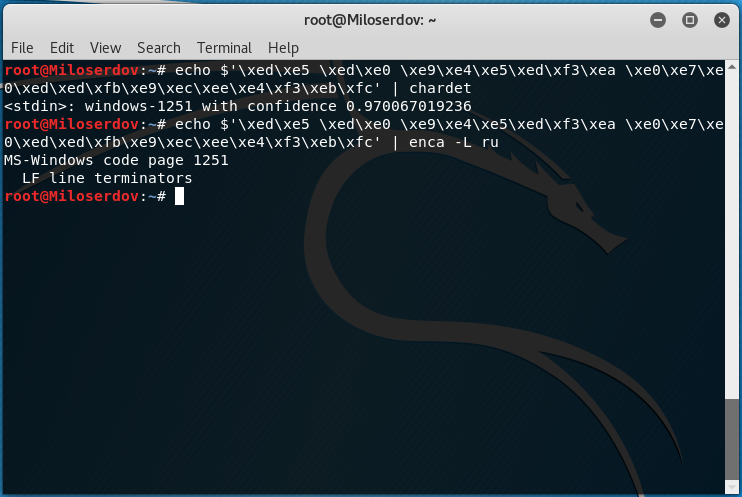
Если возникло сообщение об ошибке:
то попробуйте установить chardet из стандартных репозиториев.
Если chardet не найдена в репозиториях, то поищите программу uchardet, затем установите и используйте её.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
Где -f или —from-code означает кодировку исходного файла -t или —to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:

Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
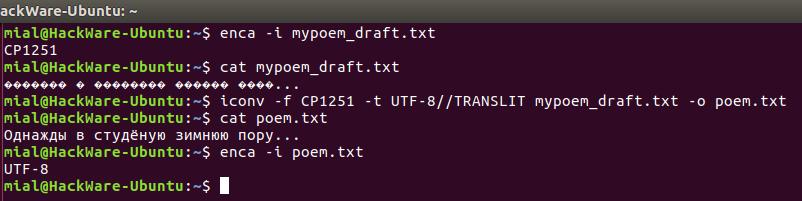
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном. Желаемую кодировку нужно указать после ключа -x:
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:

Также для изменения кодировки применяются программы:
- piconv
- recode
- enconv (другое название enca)
Источник
Linux Mint Forums
Welcome to the Linux Mint forums!
Проблемы с кодировкой — Linux Mint 18.1 Cinnamon
Проблемы с кодировкой — Linux Mint 18.1 Cinnamon
Post by Zeppelin250 » Sat Feb 25, 2017 12:54 pm

Re: Проблемы с кодировкой — Linux Mint 18.1 Cinnamon
Post by Chocobo » Sun Feb 26, 2017 4:55 pm
Re: Проблемы с кодировкой — Linux Mint 18.1 Cinnamon
Post by Olej » Fri Apr 21, 2017 7:47 am
Re: Проблемы с кодировкой — Linux Mint 18.1 Cinnamon
Post by motordig » Tue Jan 08, 2019 1:15 pm
Пропиши в dconf
[‘UTF-8’, ‘WINDOWS-1251’, ‘KOI8-R’, ‘CURRENT’, ‘ISO-8859-15’, ‘UTF-16’]
Re: Проблемы с кодировкой — Linux Mint 18.1 Cinnamon
Post by bgdnvs » Mon Apr 01, 2019 7:29 am

Re: так я tty-консоли русифицировал от кракозябров
Post by Labuzhskiy » Sun Jun 30, 2019 6:19 am
Для русификации консолей tty Линукс, по завершении русификации интерфейса по-умолчанию,
необходимо выполнить ряд не сложных манипуляций:
1. Приводим файл /etc/default/console-setup к виду:
labuzhskiy@MINT-LIN-CIN-X64
$ cat /etc/default/console-setup
# CONFIGURATION FILE FOR SETUPCON
# Consult the console-setup(5) manual page.
CODESET=»CyrSlav»
FONTFACE=»Fixed»
FONTSIZE=»8×16″
# The following is an example how to use a braille font
# FONT=’lat9w-08.psf.gz brl-8×8.psf’
2. Выявив местоположение файла rc.local в операционной системе (стандартный путь /etc/rc.local либо /etc/init.d/rc.local), дописываем в него следующие строки:
setfont CyrSlav
DAEMON_LOCALE= «yes»
можно так:
sudo -s
echo ‘setfont CyrSlav’ >> /etc/init.d/rc.local && echo ‘DAEMON_LOCALE=»yes»‘ >> /etc/init.d/rc.local
пример конфигов NanoPC-T4 здесь
Re: Проблемы с кодировкой — Linux Mint 18.1 Cinnamon
Post by altRUist » Sat Apr 11, 2020 7:31 pm
Источник
How to Convert Files to UTF-8 Encoding in Linux
In this guide, we will describe what character encoding and cover a few examples of converting files from one character encoding to another using a command line tool. Then finally, we will look at how to convert several files from any character set (charset) to UTF-8 encoding in Linux.
As you may probably have in mind already, a computer does not understand or store letters, numbers or anything else that we as humans can perceive except bits. A bit has only two possible values, that is either a 0 or 1 , true or false , yes or no . Every other thing such as letters, numbers, images must be represented in bits for a computer to process.
In simple terms, character encoding is a way of informing a computer how to interpret raw zeroes and ones into actual characters, where a character is represented by set of numbers. When we type text in a file, the words and sentences we form are cooked-up from different characters, and characters are organized into a charset.
There are various encoding schemes out there such as ASCII, ANSI, Unicode among others. Below is an example of ASCII encoding.
In Linux, the iconv command line tool is used to convert text from one form of encoding to another.
You can check the encoding of a file using the file command, by using the -i or —mime flag which enables printing of mime type string as in the examples below:
![]() Check File Encoding in Linux
Check File Encoding in Linux
The syntax for using iconv is as follows:
Where -f or —from-code means input encoding and -t or —to-encoding specifies output encoding.
To list all known coded character sets, run the command below:
![]() List Coded Charsets in Linux
List Coded Charsets in Linux
Convert Files from UTF-8 to ASCII Encoding
Next, we will learn how to convert from one encoding scheme to another. The command below converts from ISO-8859-1 to UTF-8 encoding.
Consider a file named input.file which contains the characters:
Let us start by checking the encoding of the characters in the file and then view the file contents. Closely, we can convert all the characters to ASCII encoding.
After running the iconv command, we then check the contents of the output file and the new encoding of the characters as below.
![]() Convert UTF-8 to ASCII in Linux
Convert UTF-8 to ASCII in Linux
Note: In case the string //IGNORE is added to to-encoding, characters that can’t be converted and an error is displayed after conversion.
Again, supposing the string //TRANSLIT is added to to-encoding as in the example above (ASCII//TRANSLIT), characters being converted are transliterated as needed and if possible. Which implies in the event that a character can’t be represented in the target character set, it can be approximated through one or more similar looking characters.
Consequently, any character that can’t be transliterated and is not in target character set is replaced with a question mark (?) in the output.
Convert Multiple Files to UTF-8 Encoding
Coming back to our main topic, to convert multiple or all files in a directory to UTF-8 encoding, you can write a small shell script called encoding.sh as follows:
Save the file, then make the script executable. Run it from the directory where your files ( *.txt ) are located.
Important: You can as well use this script for general conversion of multiple files from one given encoding to another, simply play around with the values of the FROM_ENCODING and TO_ENCODING variable, not forgetting the output file name «$
For more information, look through the iconv man page.
To sum up this guide, understanding encoding and how to convert from one character encoding scheme to another is necessary knowledge for every computer user more so for programmers when it comes to dealing with text.
Lastly, you can get in touch with us by using the comment section below for any questions or feedback.
If You Appreciate What We Do Here On TecMint, You Should Consider:
TecMint is the fastest growing and most trusted community site for any kind of Linux Articles, Guides and Books on the web. Millions of people visit TecMint! to search or browse the thousands of published articles available FREELY to all.
If you like what you are reading, please consider buying us a coffee ( or 2 ) as a token of appreciation.

We are thankful for your never ending support.
Источник



