- Как сменить locale в Debian или пишем кириллицей в консоли linux
- [СИ] Как узнать кодировку локали.
- linux узнать кодировку файла
- iconv и большие файлы
- Как узнать кодировку файла в Ubuntu Linux: 5 комментариев
- Программы для определения кодировки в Linux
- Команда file -i показывает неверную кодировку
- Программа enca для определения кодировки файла
- Как определить кодировку строки
- Изменение кодировки в Linux
- Использование команды iconv
- Конвертирование файлов из windows-1251 в UTF-8 кодировку
- Изменение кодировки программой enca
- Конвертация строки в правильную кодировку
Как сменить locale в Debian или пишем кириллицей в консоли linux

Я знаю что кириллица в логах Linux – это самый страшный грех для айтишника, но иногда это просто необходимость. Одна из таких необходимостей возникает при создании централизованного хранения log-файлов различных операционных систем. Microsoft всегда в своих log`ах применяет кириллицу и поэтому если мы хотим получать log-файлы и от Win-серверов, то стоит смириться, что в log`ах будет кирилица.
Для того, чтобы эти логи нормально отображались нам и нужно явно указать locale в Debian, Ubuntu или какой Linux-дистрибутив Вы используете.
Проблемы отображения кириллических символов в Linux не существует. Есть проблема у русской версии Windows. Весь мир и Linux в том числе, работает в кодировке UTF -8, когда русская версия Microsoft использует CP1251. Такая ситуация сложилось исторически благодаря компании «Парус», которая взяла на себя обязательства по локализации всех операционных систем Windows. Выбрали они почему-то кодировку CP1251, которая применяется до сих пор. Использование этой «неправильной» кодировки в наши дни обусловлено сохранением совместимости всех версий ОС.
Чтобы добавить кириллицу, чтобы Linux сервер нормально отображал русские буквы, нужно объяснить ему, что необходимо работать в той же кодировке, что и Windows.
Для того, чтобы управлять локалью в Linux, необходим пакет locales, который должен быть у Вас установлен. В большинстве случаев пакет locales уже будет у Вас установлен, поэтому для проформы просто проверяем этот факт.
Посмотреть установленную locale linux можно командой:
Для ручного указания кодировке в Linux Mint, Debian или ubuntu нужно отредактировать конфигурационный файл /etc/locale.gen :
Команду sudo не нужна, если Вы зашли как суперпользователь. Это относится к Linux Mint и Ubuntu, так как Debian ничего не знает о команде sudo.
В этом файле необходимо найти строчку и расскомментировать с той locale, которая Вам нужна. Для добавления кириллицы нужно раскомментировать строчки с UTF-8 или CP1251 .
- если хотим указать, чтобы ОС работала в UTF -8, раскомментирум:
- если хотим указать, чтобы ОС работала в CP1251, раскомментирум:
Стоит обратить внимание, что первые 2 символа (в нашем примере это ru) говорят нам о языке локализации (кириллица).
После этого переопределяем настройки locales командой:
Команда locale-gen позволяет запустить скрипт /etc/locale.gen и перечитывает все кодировки для консоли.
Чтобы увидеть кириллицу в консоли Linux, остается только перелогиниться.
Источник
[СИ] Как узнать кодировку локали.
[СИ] Как узнать кодировку локали.
Язык СИ
ОС UNIX
Имеется самодельная СИ-программа. Она предназначена для работы
на машине-сервере в Дата-центре. Запускается через PuTTY.
Выдача программы должна быть на русском языке. Но ничего не
переключать вне этой программы.
В исходнике кодировка windows-1251. В программе есть перекодировщики
на koi8-r, utf-8.
На моем сервере и еще на двух других
опробована, там кодировка koi8-r. Работает, но я пока жестко
задал перекодировщик. Я слыхал, что некоторые работают на
других кодировках.
Вопрос-1.
Правильно ли я понимаю, что когда я подключаюсь через PuTTY,
то это моя локаль?
Вопрос-2.
Существует ли способ, чтоб программа узнала, какую кодировку
лучше выдать?
Кто знает прошу ответить.

> Правильно ли я понимаю, что когда я подключаюсь через PuTTY,
.
При подключении в настройках Translation выставляйте CP1251 и в самой системе export LC_ALL=ru_RU.CP1251 и радуйтесь, если локаль сгенерирована.
Существует ли способ, чтоб программа узнала, какую кодировку
Запросто. Просто воспользуйтесь gettext при написании программы.
Если лень, смотрите из программы значения переменных окружения :
LANG
LANGUAGE
LC_CTYPE
LC_NUMERIC
LC_TIME
LC_COLLATE
LC_MONETARY
LC_MESSAGES
LC_PAPER
LC_NAME
LC_ADDRESS
LC_TELEPHONE
LC_MEASUREMENT
LC_IDENTIFICATION
LC_ALL
Локаль не твоя, твоей является только кодировка PuTTY.
Почитай man locale.h

Почитал темы oleg_2. Какой упорный парень. Молодец.
правда маны не читает
Ничего не понял.
Я не знаю что такое gettext.
Уточню вопрос.
Программа не для тиражирования, но ей все-таки будут пользоваться
разные люди. На разных машинах (UNIX). Поставит её человек (а всей
установки — положить файл и откомпилировать), и получит абракадабру.
А т. к. программа сама может разные кодировки выдавать, нельзя ли
сделать так, чтобы никаких настроек не менять, и сразу получить
хороший текст?

Вероятно, gettext — лучший вариант.
Но если хочется именно в программе держать константы на русском, то делаем так:

> Почитал темы oleg_2. Какой упорный парень.
У тебя опечатки в слове «упоротый»

Проще действительно воспользоваться gettext’ом. Это несложно, вначале делаем объявления макросов:
Чтобы при обновлении программы не вставлять новые строки вручную, добавляем их при помощи msgmerge:
Ну, а чтобы это все работало, в директорию, указанную в LOCALEDIR, надо поместить .mo-файл, который мы, после окончания перевода, генерируем командой
Все это легко поддается автоматизации в Makefile’ах или cmake’ах.
В итоге от вас требуется лишь заполнить перевод и прогнать make еще раз.
// кроме того, вы получаете возможность выводить сообщения на нескольких языках, что довольно удобно, если вдруг программу потребуется куда-то еще отправлять
Источник
linux узнать кодировку файла
Давно в категории «Ubuntu» у меня не было материалов. Сегодня я исправлюсь и выпущу сразу две статьи. Итак, начнём. вам приходилось менять кодировку текстовых файлов в linux’e? А что если объем такого файла больше 10 Gb?!
Что бы изменить кодировку файла нужно использовать замечательную утилиту iconv. В параметрах необходимо указывать исходную кодировку, а в этом нам поможет команда:
Ну а далее вот такие действия:
iconv -f WINDOWS-1251 -t UTF-8 -o output_file.txt original_file.txt
- -f WINDOWS-1251 — исходная кодировка,
- -t UTF-8 — конечная
- -o output_file.txt — куда выводить результат
- original_file.txt — исходный файл
Остальные ключики как обычно в man iconv.
iconv и большие файлы
Для быстрого выполнения процесса кодировки, iconv загружает файл в оперативную память и в swap. Но это работает только для небольших файлов. Если файл уж совсем большой, а ОЗУ не особо, то вы прост получите ошибку, мол «слишком большой файл», звиняйте хлопцы. Где взять такой файл? К примеру это может быть выборка из БД ( игры для ipad, PC, PSP или другие данные)
Вот здесь предлагают различные решения данного вопроса: и скриптами, и разбивка на части, вывод в потоки, а потом обратно сборка в файл. Лично мне понравилось весьма простое решение: команда split — она позволяет разбить текстовый файл на более мелкие, а дальше с ними работать как угодно можно.
В простом варианте чтобы разбить файл на куски объёмом по 1Gb выполнить:
Это самые просты решения, эти команды можно использовать в различных скриптах и получить от этого много кайфов. Надеюсь эта заметка вам чем-то помогла.
К сожалению ни в gEdit, ни в Leafpad я не нашёл функции, которая бы могла сказать в какой кодировке находится файл. Но на выручку, как всегда приходить консоль:
file -i file.txt
Как узнать кодировку файла в Ubuntu Linux: 5 комментариев
�� Тоже недавно наткнулся на этот совет.. Обязательно поможет кому нибудь…
В этой инструкции мы опишем что такое кодировка символов и рассмотрим несколько примеров конвертации файлов из одной кодировки в другую с использованием инструмента командной строки. Наконец, мы узнаем, как на Linux конвертировать несколько файлов из одного набора символов (charset) в UTF-8 кодировку.
Возможно, вы уже в курсе, что компьютер не понимает и не сохраняет буквы, числа или что-то ещё чем обычно оперируют люди. Компьютер работает с битами. Бит имеет только два возможных значения: 0 или 1, «истина» или «ложь», «да» или «нет». Все другие вещи, вроде букв, цифр, изображений должны быть представлены в битах, чтобы компьютер мог их обрабатывать.
Говоря простыми словами, кодировка символов – это способ информирования компьютера о том, как интерпретировать исходные нули и единицы в реальные символы, где символ представлен набором чисел. Когда мы печатаем текст в файле, слова и предложения, которые мы формируем, готовятся из разных символов, а символы упорядочиваются в кодировку.
Имеются различные схемы кодирования, среди них такие как ASCII, ANSI, Unicode. Ниже пример ASCII кодировки.
Программы для определения кодировки в Linux
Команда file -i показывает неверную кодировку
Чтобы узнать кодировку файла используется команда file с флагами -i или —mime, которые включают вывод строки с типом MIME. Пример:

Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
Установим программу enca:
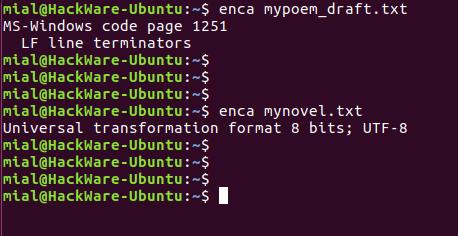
В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
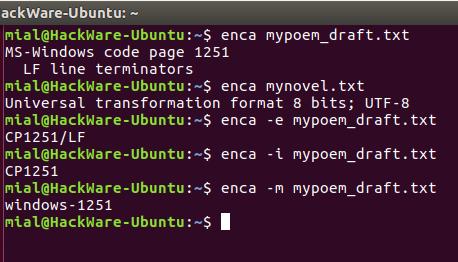
Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
Чтобы узнать список доступных языков наберите:
Как определить кодировку строки
Для определения, в какой кодировке строка, используйте одну из следующих конструкций:
Вместо СТРОКА_ДЛЯ_ПРОВЕРКИ впишите строку, для которой нужно узнать кодировку. Если у вас строка не на русском языке, то откорректируйте значение опции -L.
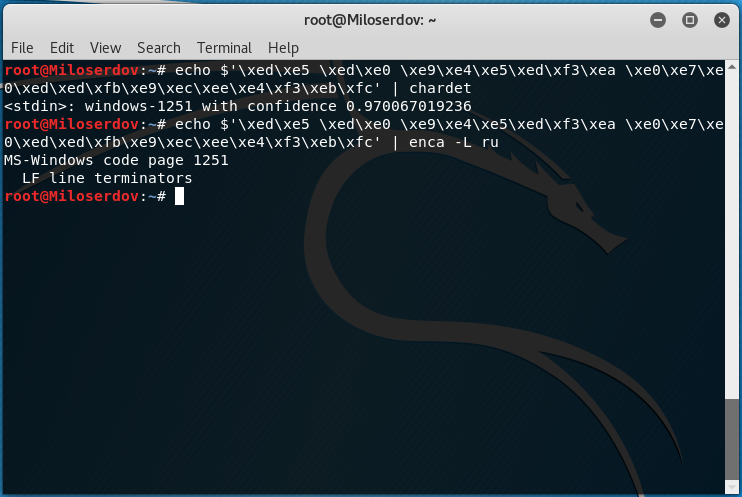
Если возникло сообщение об ошибке:
то попробуйте установить chardet из стандартных репозиториев.
Если chardet не найдена в репозиториях, то поищите программу uchardet, затем установите и используйте её.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
Где -f или —from-code означает кодировку исходного файла -t или —to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:

Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
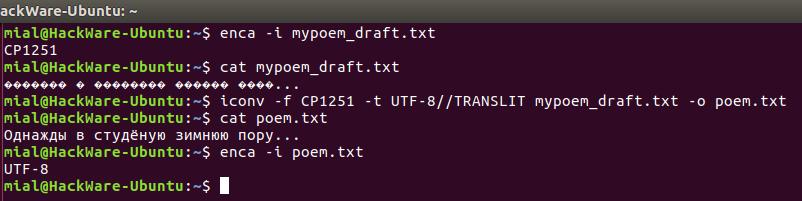
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном. Желаемую кодировку нужно указать после ключа -x:
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:

Также для изменения кодировки применяются программы:
- piconv
- recode
- enconv (другое название enca)
Источник



