- Version control systems windows
- История систем управления версиями
- Хронология выхода VCS
- SCCS (Source Code Control System): первое поколение
- Архитектура
- Основные команды
- Пример файла истории SCCS
- RCS (Revision Control System): первое поколение
- Архитектура
- Основные команды
- Пример файла истории RCS
- CVS (Concurrent Versions System): второе поколение
- Архитектура
- Основные команды
- Пример файла истории CVS
- SVN (Subversion): второе поколение
- Архитектура
- Основные команды
- Пример файла истории SVN
- Git: третье поколение
- Архитектура
- Основные команды
- Пример блоба, дерева и коммита Git
- Mercurial: третье поколение
- Архитектура
- Основные команды
- Пример файлов Mercurial
Version control systems windows

What is a “version control system”?
Version control systems are a category of software tools that helps in recording changes made to files by keeping a track of modifications done to the code.
Why Version Control system is so Important?
As we know that a software product is developed in collaboration by a group of developers they might be located at different locations and each one of them contributes in some specific kind of functionality/features. So in order to contribute to the product, they made modifications in the source code(either by adding or removing). A version control system is a kind of software that helps the developer team to efficiently communicate and manage(track) all the changes that have been made to the source code along with the information like who made and what change has been made. A separate branch is created for every contributor who made the changes and the changes aren’t merged into the original source code unless all are analyzed as soon as the changes are green signalled they merged to the main source code. It not only keeps source code organized but also improves productivity by making the development process smooth.
Benefits of the version control system:
a) Enhances the project development speed by providing efficient collaboration,
b) Leverages the productivity, expedite product delivery, and skills of the employees through better communication and assistance,
c) Reduce possibilities of errors and conflicts meanwhile project development through traceability to every small change,
d) Employees or contributor of the project can contribute from anywhere irrespective of the different geographical locations through this VCS,
e) For each different contributor of the project a different working copy is maintained and not merged to the main file unless the working copy is validated. A most popular example is Git, Helix core, Microsoft TFS,
f) Helps in recovery in case of any disaster or contingent situation,
g) Informs us about Who, What, When, Why changes have been made.
Use of Version Control System:
- A repository: It can be thought of as a database of changes. It contains all the edits and historical versions (snapshots) of the project.
- Copy of Work (sometimes called as checkout): It is the personal copy of all the files in a project. You can edit to this copy, without affecting the work of others and you can finally commit your changes to a repository when you are done making your changes.
Types of Version Control Systems:
Local Version Control Systems: It is one of the simplest forms and has a database that kept all the changes to files under revision control. RCS is one of the most common VCS tools. It keeps patch sets (differences between files) in a special format on disk. By adding up all the patches it can then re-create what any file looked like at any point in time.
Centralized Version Control Systems: Centralized version control systems contain just one repository and each user gets their own working copy. You need to commit to reflecting your changes in the repository. It is possible for others to see your changes by updating.
Two things are required to make your changes visible to others which are:
- You commit
- They update
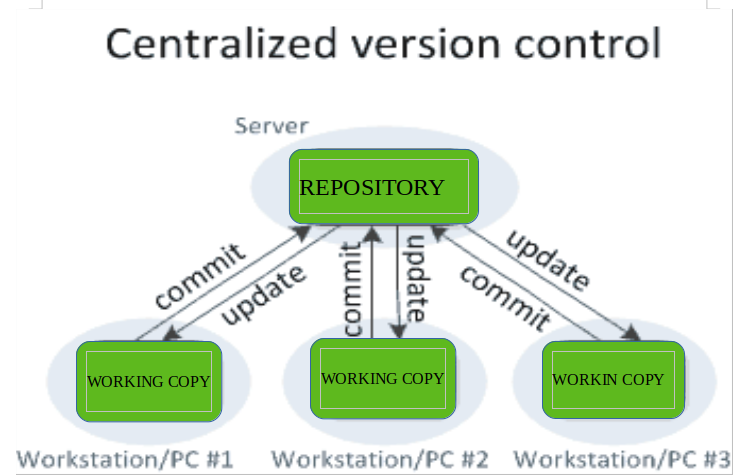
The benefit of CVCS (Centralized Version Control Systems) makes collaboration amongst developers along with providing an insight to a certain extent on what everyone else is doing on the project. It allows administrators to fine-grained control over who can do what.
It has some downsides as well which led to the development of DVS. The most obvious is the single point of failure that the centralized repository represents if it goes down during that period collaboration and saving versioned changes is not possible. What if the hard disk of the central database becomes corrupted, and proper backups haven’t been kept? You lose absolutely everything.
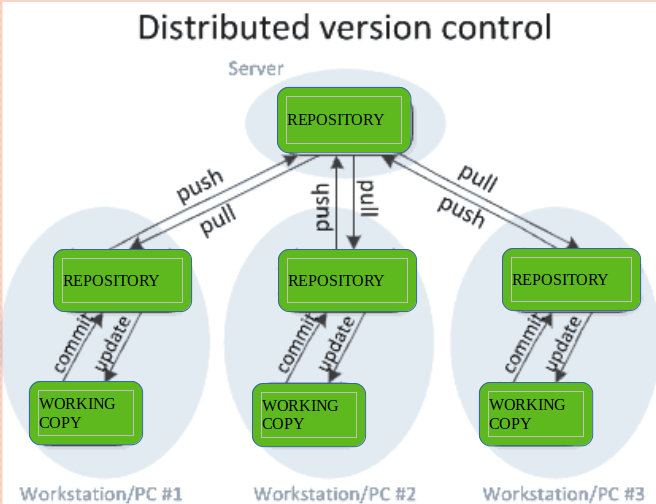
Distributed Version Control Systems: Distributed version control systems contain multiple repositories. Each user has their own repository and working copy. Just committing your changes will not give others access to your changes. This is because commit will reflect those changes in your local repository and you need to push them in order to make them visible on the central repository. Similarly, When you update, you do not get other’s changes unless you have first pulled those changes into your repository.
To make your changes visible to others, 4 things are required:
- You commit
- You push
- They pull
- They update
The most popular distributed version control systems are Git, Mercurial. They help us overcome the problem of single point of failure.
Purposeof Version Control:
- Multiple people can work simultaneously on a single project. Everyone works on and edits their own copy of the files and it is up to them when they wish to share the changes made by them with the rest of the team.
- It also enables one person to use multiple computers to work on a project, so it is valuable even if you are working by yourself.
- It integrates the work that is done simultaneously by different members of the team. In some rare case, when conflicting edits are made by two people to the same line of a file, then human assistance is requested by the version control system in deciding what should be done.
- Version control provides access to the historical versions of a project. This is insurance against computer crashes or data loss. If any mistake is made, you can easily roll back to a previous version. It is also possible to undo specific edits that too without losing the work done in the meanwhile. It can be easily known when, why, and by whom any part of a file was edited.
История систем управления версиями

В этой статье сравним с технической точки зрения самые известные системы управления версиями (в будущем планируем расширить список):
- Первое поколение
- SCCS (Source Code Control System)
- RCS (Revision Control System)
- Второе поколение
- CVS (Concurrent Versions System)
- SVN (Apache Subversion)
- Третье поколение
- Git
- Mercurial
Системы контроля версий (VCS) первого поколения отслеживали изменения в отдельных файлах, а редактирование поддерживалось только локально и одним пользователем за раз. Системы строились на предположении, что все пользователи будут заходить по своим учётными записям на один и тот же общий узел Unix.
В VCS второго поколения появилась поддержка сети, что привело к централизованным хранилищам с «официальными» версиями проектов. Это был значительный прогресс, поскольку несколько пользователей могли одновременно работать с кодом, делая коммиты в один и тот же центральный репозиторий. Однако для коммитов требовался доступ к сети.
Третье поколение состоит из распределённых VCS, где все копии репозитория считаются равными, нет центрального репозитория. Это открывает путь для коммитов, ветвей и слияний, которые создаются локально без доступа к сети и перемещаются в другие репозитории по мере необходимости.
Хронология выхода VCS
Для контекста, вот график c датами появления этих инструментов:

SCCS (Source Code Control System): первое поколение
SCCS считается одной из первых успешных систем управления версиями. Она была разработана в 1972 году Марком Рочкиндом из Bell Labs. Система написана на C и создана для отслеживания версий исходного файла. Кроме того, она значительно облегчила поиск источников ошибок в программе. Базовая архитектура и синтаксис SCCS позволяют понять корни современных инструментов VCS.
Архитектура
Как и большинство современных систем, в SCCS есть набор команд для работы с версиями файлов:
- Внесение (check-in) файлов для отслеживания истории в SCCS.
- Извлечение (check-out) конкретных версий файлов для ревью или компиляции.
- Извлечение конкретных версий для редактирования.
- Внесение новых версий файлов вместе с комментариями, объясняющими изменения.
- Отмена изменений, внесённых в извлечённый файл.
- Основные ветвления и слияния изменений.
- Журнал изменений файла.
При добавлении файла для отслеживания в SCCS создаётся файл специального типа, который называется s-файл или файл истории . Он именуется как исходный файл, только с префиксом s. , и хранится в подкаталоге SCCS . Таким образом, для файла test.txt будет создан файл истории s.test.txt в директории ./SCCS/ . В момент создания файл истории содержит начальное содержимое исходного файла, а также некоторые метаданные, помогающие отслеживать версии. Здесь хранятся контрольные суммы для гарантии, что содержимое не было изменено. Содержимое файла истории не сжимается и не кодируется (как в VCS следующего поколения).
Поскольку содержимое исходного файла теперь хранится в файле истории, его можно извлечь в рабочий каталог для просмотра, компиляции или редактирования. В файл истории можно внести изменения, такие как добавления строк, изменения и удаления, что увеличивает его номер версии.
Последующие добавления файла хранят только дельты или изменения, а не всё его содержимое. Это уменьшает размер файла истории. Каждая дельта сохраняется внутри файла истории в структуре под названием дельта-таблица . Как упоминалось ранее, фактическое содержимое файла более или менее копируется дословно, со специальными управляющими последовательностями для маркировки начала и конца разделов добавленного и удалённого содержимого. Поскольку файлы истории SCCS не используют сжатие, они обычно имеют больший размер, чем фактический файл, в котором отслеживаются изменения. SCCS использует метод под названием чередующиеся дельты (interleaved deltas), который гарантирует постоянное время извлечения независимо от давности извлечённой версии, то есть более старые версии извлекаются с той же скоростью, что и новые.
Важно отметить, что все файлы отслеживаются и регистрируются отдельно. Невозможно проверить изменения в нескольких файлах в виде одного атомарного блока, как коммиты в Git. У каждого отслеживаемого файла свой файл истории, в котором хранится его история изменений. В общем случае это означает, что номера версий различных файлов в проекте обычно не совпадают друг с другом. Однако эти версии можно согласовать путём одновременного редактирования всех файлов в проекте (даже не внося в них реальные изменения) и одновременного добавления всех файлов. Это одновременно увеличит номер версии для всех файлов, сохраняя их согласованность, но обратите внимание, что это не то же самое, что включение нескольких файлов в один коммит, как в Git. В SCCS происходит индивидуальное добавление в каждый файл истории, в отличие от одного большого коммита, включающего все изменения сразу.
Когда файл извлекается для редактирования в SCCS, на него ставится блокировка, так что его никто больше не может редактировать. Это предотвращает перезапись изменений другими пользователями, но также ограничивает разработку, потому что в каждый момент времени только один пользователь может работать с данным файлом.
SCCS поддерживает ветви, которые хранят последовательности изменений в определённом файле. Можно произвести слияние ветви с исходной версией или с другой веткой.
Основные команды
Ниже приведён список наиболее распространенных команд SCCS.
- sccs create : добавить новый файл в SCCS и создать для него новый файл истории (по умолчанию в каталоге ./SCCS/ ).
- sccs get : извлечь файл из соответствующего файла истории и поместить его в рабочий каталог в режиме только для чтения.
- sccs edit : извлечь файл из соответствующего файла истории для редактирования. Блокировать файл истории, чтобы другие пользователи не могли его изменить.
- sccs delta : добавить изменения в указанный файл. Система запросит комментарий, сохранит изменения в файле истории и снимет блокировку.
- sccs prt : отобразить журнал изменений для отслеживаемого файла.
- sccs diffs : показать различия между текущей рабочей копией файла и состоянием файла, когда он был извлечён.
Для дополнительной информации о внутренних компонентах SCCS см. руководство от Эрика Аллмана и «Руководство Oracle по утилитам для программирования».
Пример файла истории SCCS
RCS (Revision Control System): первое поколение
RCS написана в 1982 году Уолтером Тихи на языке С в качестве альтернативы системе SCCS, которая в то время не была опенсорсной.
Архитектура
У RCS много общего со своим предшественником, в том числе:
- Ведение версий отдельно для каждого файла.
- Изменения в нескольких файлах нельзя сгруппировать в единый коммит.
- Отслеживаемые файлы не могут одновременно изменяться несколькими пользователями.
- Нет поддержки сети.
- Версии каждого отслеживаемого файла хранятся в соответствующем файле истории.
- Ветвление и объединение версий только для отдельных файлов.
Когда файл впервые добавляется в RCS, для него в локальном хранилище создаётся соответствующий файл истории в локальной директории ./RCS/ . К этому файлу добавляется расширение ,v , то есть файл с названием test.txt будет отслеживаться файлом под названием test.txt,v .
Для хранения изменений RCS использует схему обратных дельт (reverse-delta). При добавлении файла полный снимок его содержимого сохраняется в файле истории. Когда файл изменяется и возвращается снова, вычисляется дельта на основе существующего содержимого файла истории. Старый снимок отбрасывается, а новый сохраняется вместе с дельтой, чтобы вернуться в старое состояние. Это называется обратной дельтой , так как для извлечения более старой версии RCS берёт последнюю версию и последовательно применяет дельты до тех пор, пока не достигнет нужной версии. Этот метод позволяет очень быстро извлекать текущие версии, так как всегда доступен полный снимок текущей ревизии. Однако чем старше версия, тем больше времени занимает проверка, потому что нужно проверить всё больше дельт.
В SCCS иначе: там извлечение любой версии занимает одинаково времени. Кроме того, в файлах истории RCS не хранится контрольная сумма, поэтому нельзя обеспечить целостность файла.
Основные команды
Ниже список наиболее распространённых команд RCS:
- : добавить новый файл в RCS и создать для него новый файл истории (по умолчанию в каталоге ./RCS/ ).
- co : извлечь файл из соответствующего файла истории и поместить его в рабочий каталог в режиме только для чтения.
- co -l : извлечь файл из соответствующего файла истории для редактирования. Блокировать файл истории, чтобы другие пользователи не могли его изменить.
- ci : добавить изменения файла и создать для него новую редакцию в соответствующем файле истории.
- merge
: произвести слияние изменений из двух изменённых дочерних элементов одного родительского файла.
Для дополнительной информации о внутренних компонентах RCS см. руководство по GNU RCS.
Пример файла истории RCS
CVS (Concurrent Versions System): второе поколение
CVS создана Диком Груном в 1986 году с целью добавить в систему управления версиями поддержку сети. Она также написана на C и знаменует собой рождение второго поколения инструментов VCS, благодаря которым географически рассредоточенные команды разработчиков получили возможность работать над проектами вместе.
Архитектура
CVS — это фронтенд для RCS, в нём появился новый набор команд для взаимодействия с файлами в проекте, но под капотом используется тот же формат файла истории RCS и команды RCS. Впервые CVS позволил нескольким разработчикам одновременно работать с одними и теми же файлами. Это реализовано с помощью модели централизованного репозитория. Первый шаг — настройка на удалённом сервере централизованного репозитория с помощью CVS. Затем проекты можно импортировать в репозиторий. Когда проект импортируется в CVS, каждый файл преобразуется в файл истории ,v и хранится в центральной директории: модуле . Репозиторий обычно находится на удалённом сервере, доступ к которому осуществляется через локальную сеть или интернет.
Разработчик получает копию модуля, который копируется в рабочий каталог на его локальном компьютере. В этом процессе никакие файлы не блокируются, так что нет ограничения на количество разработчиков, которые могут одновременно работать с модулем. Разработчики могут изменять свои файлы и по мере необходимости фиксировать изменения (делать коммит). Если разработчик фиксирует изменение, другие разработчики должны обновить свои рабочие копии с помощью (обычно) автоматизированного процесса слияния перед фиксацией своих изменений. Иногда приходится вручную разрешать конфликты слияния, прежде чем выполнить коммит. CVS также предоставляет возможность создавать и объединять ветви.
Основные команды
: задать корневой каталог репозитория CVS, так что его потом не нужно указывать в каждой команде.
: извлечь существующую ветвь в рабочий каталог.
: объединить существующую ветвь с локальной рабочей копией.
Для дополнительной информации о внутренних компонентах CVS см. руководство по GNU CVS и статью Дика Груна.
Пример файла истории CVS
SVN (Subversion): второе поколение
Subversion создана в 2000 году компанией Collabnet Inc., а в настоящее время поддерживается Apache Software Foundation. Система написана на C и разработана как более надёжное централизованное решение, чем CVS.
Архитектура
Как и CVS, Subversion использует модель централизованного репозитория. Удалённым пользователям требуется сетевое подключение для коммитов в центральный репозиторий.
Subversion представила функциональность атомарных коммитов с гарантией, что коммит либо полностью успешен, либо полностью отменяется в случае проблемы. В CVS при неполадке посреди коммита (например, из-за сбоя сети) репозиторий мог остаться в повреждённом и несогласованном состоянии. Кроме того, коммит или версия в Subversion может включать в себя несколько файлов и директорий. Это важно, потому что позволяет отслеживать наборы связанных изменений вместе как сгруппированный блок, а не отдельно для каждого файла, как в системах прошлого.
В настоящее время Subversion использует файловую систему FSFS (File System atop the File System). Здесь создаётся база данных со структурой файлов и каталогов, которые соответствуют файловой системе хоста. Уникальная особенность FSFS заключается в том, что она предназначена для отслеживания не только файлов и каталогов, но и их версий. Это файловая система с восприятием времени. Кроме того, директории являются полноценными объектами в Subversion. В систему можно коммитить пустые директории, тогда как остальные (даже Git) не замечают их.
При создании репозитория Subversion в его составе создаётся (почти) пустая база данных файлов и папок. Создаётся каталог db/revs , в котором хранится вся информация отслеживания версий для добавленных (зафиксированных) файлов. Каждый коммит (который может включать изменения в нескольких файлах) хранится в новом файле в каталоге revs , и ему присваивается имя с последовательным числовым идентификатором, начинающимся с 1. При первом коммите сохраняется полное содержимое файла. Будущие коммиты одного и того же файла приведут к сохранению только изменений, которые также называются диффами или дельтами — для экономии места. Кроме того, для уменьшения размера дельты сжимаются с помощью алгоритмов сжатия lz4 или zlib .
Такая система работает только до определёного момента. Хотя дельты экономят место, но если их очень много, то на операции уходит немало времени, так как для воссоздания текущего состояния файла нужно обработать все дельты. По этой причине по умолчанию Subversion сохраняет до 1023 дельт на файл, а потом делает новую полную копию файла. Это обеспечивает хороший баланс хранения и скорости.
SVN не использует обычную систему ветвления и тегов. Обычный шаблон репозитория Subversion содержит три папки в корне:
- trunk/
- branches/
- tags/
Директория trunk/ используется для продакшн-версии проекта. Директория branches/ — для хранения вложенных папок, соответствующих отдельным ветвям. Директория tags/ — для хранения тегов, представляющих определённые (обычно значительные) версии проекта.
Основные команды
: создать новую пустую оболочку репозитория в указанном каталоге.
svn import
: импортировать каталог файлов в указанный репозиторий Subversion.
svn checkout
: скопировать репозиторий в рабочий каталог.
: создать новую ветку путём копирования существующей.
Дополнительные сведения о внутренних компонентах SVN см. в книге «Управление версиями в Subversion».
Пример файла истории SVN
Git: третье поколение
Систему Git разработал в 2005 году Линус Торвальдс (создатель Linux). Она написана в основном на C в сочетании с некоторыми сценариями командной строки. Отличается от VCS по функциям, гибкости и скорости. Торвальдс изначально написал систему для кодовой базы Linux, но со временем её сфера использования расширилась, и сегодня это самая популярная в мире система управлениями версиями.
Архитектура
Git является распределённой системой. Центрального репозитория не существует: все копии создаются равными, что резко отличается от VCS второго поколения, где работа основана на добавлении и извлечении файлов из центрального репозитория. Это означает, что разработчики могут обмениваться изменениями друг с другом непосредственно перед объединением своих изменений в официальную ветвь.
Кроме того, разработчики могут вносить свои изменения в локальную копию репозитория без ведома других репозиториев. Это допускает коммиты без подключения к сети или интернету. Разработчики могут работать локально в автономном режиме, пока не будут готовы поделиться своей работой с другими. В этот момент изменения отправляются в другие репозитории для проверки, тестирования или развёртывания.
Когда файл добавляется для отслеживания в Git, он сжимается с помощью алгоритма сжатия zlib . Результат хэшируется с помощью хэш-функции SHA-1. Это даёт уникальный хэш, который соответствует конкретно содержимому в этом файле. Git хранит его в базе объектов , которая находится в скрытой папке .git/objects . Имя файла — это сгенерированный хэш, а файл содержит сжатый контент. Данные файлы называются блобами и создаются каждый раз при добавлении в репозиторий нового файла (или изменённой версии существующего файла).
Git реализует промежуточный индекс (staging index), который выступает в качестве промежуточной области для изменений, которые готовятся к коммиту. По мере подготовки новых изменений на их сжатое содержимое ссылаются в специальном индексном файле, который принимает форму объекта дерева . Дерево — это объект Git, который связывает блобы с их реальными именами файлов, разрешениями на доступ к файлам и ссылками на другие деревья и таким образом представляет состояние определённого набора файлов и каталогов. Когда все соответствующие изменения подготовлены для коммита, индексное дерево можно зафиксировать в репозитории, который создаёт объект коммит в базе данных объектов Git. Коммит ссылается на дерево заголовков для конкретной версии, а также на автора коммита, адрес электронной почты, дату и сообщение коммита. Каждый коммит также хранит ссылку на свой родительский коммит(-ы), и так со временем создаётся история развития проекта.
Как уже упоминалось, все объекты Git — блобы, деревья и коммиты — сжимаются, хэшируются и хранятся в базе данных объектов на основе их хэшей. Они называются свободными объектами (loose objects). Здесь не используются никакие диффы для экономии места, что делает Git очень быстрым, поскольку полное содержимое каждой версии файла доступно как свободный объект. Однако некоторые операции, такие как передача коммитов в удалённый репозиторий, хранение очень большого количества объектов или ручной запуск команды сборки мусора Git вызывают переупаковку объектов в пакетные файлы . В процессе упаковки вычисляются обратные диффы, которые сжимаются для исключения избыточности и уменьшения размера. В результате создаются файлы .pack с содержимым объекта, а для каждого из них создаётся файл .idx (или индекс) со ссылкой на упакованные объекты и их расположение в пакетном файле.
Когда ветви перемещаются в удалённые хранилища или извлекаются из них, по сети передаются эти пакетные файлы. При вытягивании или извлечении ветвей файлы пакета распаковываются для создания свободных объектов в репозитории объектов.
Основные команды
- git init : инициализировать текущий каталог как репозиторий Git (создаётся скрытая папка .git и её содержимое).
- git clone : загрузить копию репозитория Git по указанному URL.
- git add : добавить неотслеженный или изменённый файл в промежуточную область (создаёт соответствующие записи в базе данных объектов).
- git commit -m ‘Commit message’ : зафиксировать набор изменённых файлов и папок вместе с сообщением о коммите.
- git status : показать статус рабочего каталога, текущей ветви, неотслеженных файлов, изменённых файлов и т. д.
- git branch : создать новую ветвь на основе текущей извлечённой ветви.
- git checkout
: извлечь указанную ветвь в рабочий каталог. - git merge
: объединить указанную ветвь с текущей, которая извлечена в рабочий каталог. - git pull : обновить рабочую копию, объединив в неё зафиксированные изменения, которые существуют в удалённом репозитории, но не в рабочей копии.
- git push : упаковать свободные объекты для локальных коммитов активной ветви в файлы пакета и перенести в удалённый репозиторий.
- git log : показать историю коммитов и соответствующие сообщения для активной ветви.
- git stash : сохранить все незафиксированные изменения из рабочего каталога в кэш, чтобы извлечь их позже.
Если хотите узнать, как работает код Git, ознакомьтесь с руководством Git для начинающих. Дополнительные сведения о внутренних компонентах см. в соответствующей главе книги Pro Git.
Пример блоба, дерева и коммита Git
Блоб с хэшем 37d4e6c5c48ba0d245164c4e10d5f41140cab980 :
Объект дерева с хэшем b769f35b07fbe0076dcfc36fd80c121d747ccc04 :
Коммит с хэшем dc512627287a61f6111705151f4e53f204fbda9b :
Mercurial: третье поколение
Mercurial создан в 2005 году Мэттом Макколлом и написан на Python. Он тоже разработан для хостинга кодовой базы Linux, но для этой задачи в итоге выбрали Git. Это вторая по популярности система управления версиями, хотя она используется гораздо реже.
Архитектура
Mercurial — тоже распределённая система, которая позволяет любому числу разработчиков работать со своей копией проекта независимо от других. Mercurial использует многие из тех же технологий, что и Git, в том числе сжатие и хэширование SHA-1, но делает это иначе.
Когда новый файл фиксируется для отслеживания в Mercurial, для него создаётся соответствующий файл revlog в скрытом каталоге .hg/store/data/ . Можете рассматривать файл revlog (журнал изменений) как модернизированную версию файлов истории в старых VCS, таких как CVS, RCS и SCCS. В отличие от Git, который создаёт новый блоб для каждой версии каждого подготовленного файла, Mercurial просто создаёт новую запись в revlog для этого файла. Для экономии места каждая новая запись содержит только дельту от предыдущей версии. Когда достигается пороговое число дельт, снова сохраняется полный снимок файла. Это сокращает время поиска при обработке большого количества дельт для восстановления определённой версии файла.
Каждый revlog именуется в соответствии с файлом, который он отслеживает, но с расширением .i или .d . Файлы .d содержат сжатую дельту. Файлы .i используются в качестве индексов для быстрого отслеживания различных версий внутри файлов .d . Для небольших файлов с малым количеством изменений индексы и содержимое хранятся внутри файлов .i . Записи файла revlog сжимаются для производительности и хэшируются для идентификации. Эти хэш-значения именуются nodeid .
При каждом коммите Mercurial отслеживает все версии файлов этого коммита в так называемом манифесте . Манифест также является файлом revlog — в нём хранятся записи, соответствующие определённым состояниям репозитория. Вместо отдельного содержимого файла, как revlog, манифест хранит список имён файлов и nodeids, которые определяют, какие версии файла существуют в версии проекта. Эти записи манифеста также сжимаются и хэшируются. Хэш-значения тоже называются nodeid .
Наконец, Mercurial использует ещё один тип revlog, который называется changelog, то есть журнал изменений. Это список записей, которые связывают каждый коммит со следующей информацией:
- nodeid манифеста: полный набор версий файла, которые существуют в конкретный момент времени.
- один или два nodeid для родительских коммитов: это позволяет Mercurial строить временную шкалу или ветвь истории проекта. В зависимости от типа коммита (обычный или слияние) хранится один или два родительских ID.
- Автор коммита
- Дата коммита
- Сообщение коммита
Каждая запись changelog также генерирует хэш, известный как его nodeid .
Основные команды
Пример файлов Mercurial
Журнал изменений (changelog):
Дополнительная информация об устройстве Mercurial:



