- Virtualization in linux kernel
- Contents
- Checking support for KVM
- Hardware support
- Kernel support
- Para-virtualization with Virtio
- Kernel support
- List of para-virtualized devices
- How to use KVM
- Tips and tricks
- Nested virtualization
- Enabling huge pages
- 3. PCI Express I/O Virtualization Howto¶
- 3.1. Overview¶
- 3.1.1. What is SR-IOV¶
- 3.2. User Guide¶
- 3.2.1. How can I enable SR-IOV capability¶
- Виртуализация в Unix. Часть 1: Kernel-based Virtual Machine (KVM)
- Подготовка хоста виртуализации.
- Установка необходимых пакетов.
- Настройка Bridged Network.
- Подготовка хоста виртуализации с помощью Ansible.
- Управление хостом виртуализации.
- Создание и управление виртуальными машинами.
- Подключение к консоли.
- Использование NUMA.
- Проброс устройств (Passthrough).
- Работа со snapshots.
- Работа со Storage Pools.
- Операции с образами дисков.
- Ссылки.
Virtualization in linux kernel
KVM, Kernel-based Virtual Machine, is a hypervisor built into the Linux kernel. It is similar to Xen in purpose but much simpler to get running. Unlike native QEMU, which uses emulation, KVM is a special operating mode of QEMU that uses CPU extensions (HVM) for virtualization via a kernel module.
Using KVM, one can run multiple virtual machines running unmodified GNU/Linux, Windows, or any other operating system. (See Guest Support Status for more information.) Each virtual machine has private virtualized hardware: a network card, disk, graphics card, etc.
Differences between KVM and Xen, VMware, or QEMU can be found at the KVM FAQ.
This article does not cover features common to multiple emulators using KVM as a backend. You should see related articles for such information.
Contents
Checking support for KVM
Hardware support
KVM requires that the virtual machine host’s processor has virtualization support (named VT-x for Intel processors and AMD-V for AMD processors). You can check whether your processor supports hardware virtualization with the following command:
If nothing is displayed after running either command, then your processor does not support hardware virtualization, and you will not be able to use KVM.
Kernel support
Arch Linux kernels provide the required kernel modules to support KVM.
- One can check if the necessary modules, kvm and either kvm_amd or kvm_intel , are available in the kernel with the following command:
The module is available only if it is set to either y or m .
- Then, ensure that the kernel modules are automatically loaded, with the command:
If the command returns nothing, the module needs to be loaded manually, see Kernel modules#Manual module handling.
Para-virtualization with Virtio
Para-virtualization provides a fast and efficient means of communication for guests to use devices on the host machine. KVM provides para-virtualized devices to virtual machines using the Virtio API as a layer between the hypervisor and guest.
All Virtio devices have two parts: the host device and the guest driver.
Kernel support
Use the following command to check if the VIRTIO modules are available in the kernel inside the virtual machine:
Then, check if the kernel modules are automatically loaded with the command:
In case the above commands return nothing, you need to load the kernel modules manually.
List of para-virtualized devices
- network device (virtio-net)
- block device (virtio-blk)
- controller device (virtio-scsi)
- serial device (virtio-serial)
- balloon device (virtio-balloon)
How to use KVM
See the main article: QEMU.
Tips and tricks
Nested virtualization
Nested virtualization enables existing virtual machines to be run on third-party hypervisors and on other clouds without any modifications to the original virtual machines or their networking.
On host, enable nested feature for kvm_intel :
Verify that feature is activated:
Enable the «host passthrough» mode to forward all CPU features to the guest system:
- If using QEMU, run the guest virtual machine with the following command: qemu-system-x86_64 -enable-kvm -cpu host .
- If using virt-manager, change the CPU model to host-passthrough .
- If using virsh, use virsh edit vm-name and change the CPU line to
Boot VM and check if vmx flag is present:
Enabling huge pages
 This article or section is a candidate for merging with QEMU.
This article or section is a candidate for merging with QEMU.
You may also want to enable hugepages to improve the performance of your virtual machine. With an up to date Arch Linux and a running KVM you probably already have everything you need. Check if you have the directory /dev/hugepages . If not, create it. Now we need the right permissions to use this directory. The default permission is root’s uid and gid with 0755, but we want anyone in the kvm group to have access to hugepages.
Add to your /etc/fstab :
Of course the gid must match that of the kvm group or specify the group name directly with gid=kvm . The mode of 1770 allows anyone in the group to create files but not unlink or rename each other’s files. Make sure /dev/hugepages is mounted properly:
Now you can calculate how many hugepages you need. Check how large your hugepages are:
Normally that should be 2048 kB ≙ 2 MB. Let us say you want to run your virtual machine with 1024 MB. 1024 / 2 = 512. Add a few extra so we can round this up to 550. Now tell your machine how many hugepages you want:
If you had enough free memory you should see:
If the number is smaller, close some applications or start your virtual machine with less memory (number_of_pages x 2):
Note the -mem-path parameter. This will make use of the hugepages.
Now you can check, while your virtual machine is running, how many pages are used:
Источник
3. PCI Express I/O Virtualization Howto¶
В© 2009 Intel Corporation
3.1. Overview¶
3.1.1. What is SR-IOV¶
Single Root I/O Virtualization (SR-IOV) is a PCI Express Extended capability which makes one physical device appear as multiple virtual devices. The physical device is referred to as Physical Function (PF) while the virtual devices are referred to as Virtual Functions (VF). Allocation of the VF can be dynamically controlled by the PF via registers encapsulated in the capability. By default, this feature is not enabled and the PF behaves as traditional PCIe device. Once it’s turned on, each VF’s PCI configuration space can be accessed by its own Bus, Device and Function Number (Routing ID). And each VF also has PCI Memory Space, which is used to map its register set. VF device driver operates on the register set so it can be functional and appear as a real existing PCI device.
3.2. User Guide¶
3.2.1. How can I enable SR-IOV capability¶
Multiple methods are available for SR-IOV enablement. In the first method, the device driver (PF driver) will control the enabling and disabling of the capability via API provided by SR-IOV core. If the hardware has SR-IOV capability, loading its PF driver would enable it and all VFs associated with the PF. Some PF drivers require a module parameter to be set to determine the number of VFs to enable. In the second method, a write to the sysfs file sriov_numvfs will enable and disable the VFs associated with a PCIe PF. This method enables per-PF, VF enable/disable values versus the first method, which applies to all PFs of the same device. Additionally, the PCI SRIOV core support ensures that enable/disable operations are valid to reduce duplication in multiple drivers for the same checks, e.g., check numvfs == 0 if enabling VFs, ensure numvfs 3.2.2. How can I use the Virtual Functions¶
The VF is treated as hot-plugged PCI devices in the kernel, so they should be able to work in the same way as real PCI devices. The VF requires device driver that is same as a normal PCI device’s.
Источник
Виртуализация в Unix. Часть 1: Kernel-based Virtual Machine (KVM)

Sep 30, 2018 · 16 min read
KVM — программное решение с открытым исходным кодом, обеспечивающее виртуализацию в дистрибутивах Linux и FreeBSD-системах (который так же портирован в них, как модуль ядра). Подробней о принципах работы и об устройстве KVM можно прочитать на сайте RedHat, или на linux-kvm.org, ниже будет представлена лишь практическая часть по подготовке системы к использованию в качестве гипервизора, настройке и созданию виртуальных машин.
Подготовка хоста виртуализации.
Подготовить систему к использованию в качестве гипервизора можно, как с помощью ansible-ролей, так и вручную — путем установки и настройки необходимых пакетов. Ниже будут рассмотрены оба способа.
Установка необходимых пакетов.
Прежде, чем ис п ользовать сервер в качестве гипервизора, проверим включена ли в BIOS аппаратная виртуализация. Для Intel следующий вывод должен содержать инструкции “vmx”, для AMD — “svm”:
Можно так же проверить командой:
Для установки пакетов и использования системы в качестве гипервизора подойдет как серверный, так и desktop-дистрибутив. Ниже будет рассмотрена установка на Centos 7.x, Debian Stretch, Ubuntu 16.x, но в других версиях этих дистрибутивов установка может быть абсолютно идентична.
Для Centos пакеты лучше устанавливать из EPEL репозитория:
или из oVirt, где они новей:
Непосредственно сама установка пакетов:
Настройка Bridged Network.
По умолчанию, все создаваемые виртуальные машины будут в дефолтной сети KVM, которая находится за NAT’ом. Её можно удалить:
Список всех сетей для KVM можно получить командой:
Для того, чтобы создаваемые виртуальные машины находились в одной сети необходимо настроить network bridge.
Убедимся, загружен ли модуль bridge:
Если нет, то загрузим:
Устанавливаем пакет bridge-utils и редактируем настройки сетевых интерфейсов:
Для статических адресов:
Переподнимаем интерфейс и перегружаем daemon:
Для конфигурации можно использовать текстово-графический интерфейс network manager’а:
или исправить конфигурацию интерфейсов вручную. Приводим конфиг интерфейса, к которому будет подключен bridge к следующему виду:
Непосредственно сам bridge:
Для статических адресов:
Если интерфейс не управляется network manager’ом следует добавить строчку:
Переподнимаем интерфейс и перегружаем daemon:
Подготовка хоста виртуализации с помощью Ansible.
Перед тем как управлять хостами с помощью Ansible для Debian/Ubuntu дополнительно может потребоваться установить python (или python-minimal):
Нам понадобятся три роли: epel-repo для установки репозитория Epel, network — для создания network bridge и kvm — непосредственно для самой подготовки хоста виртуализации. Устанавливаем Ansible. Для Ubuntu/Debian:
Установку для других дистрибутивов смотрите в официальной документации. Указываем в конфиге путь к скачанным ролям — например, /home/username/ansible/roles:
Приводим файл inventory приблизительно к следующему виду:
И далее задаем в playbook’е, вызывающем роли kvm и network необходимые параметры — настройки сети (IP-адресс хоста не меняется), имя bridge-интерфейса:
В некоторых дистрибутивах (Centos) создание bridged interface может завершиться с ошибкой (bug пока что не исправлен), поэтому лучше явно указать, к какому интерфейсу подключать bridge. Задаем его имя, исправляя перед запуском playbook’а:
Управление хостом виртуализации.
Управление гипервизором проще всего осуществлять через virt-manager. Устанавливаем в локальной системе:
Предположим, что подключаться к гипервизору будем под пользователем user. Создаем пользователя:
Для того, чтобы пользователь имел возможность управлять libvirt’ом его нужно добавить в соответствующую группу: в Centos — это группа libvirt, в Ubuntu — libvirtd. Проверим:
Следовательно, добавляем пользователя user в группу libvirtd:
В некоторых дистрибутивах (Debian 9.x) пользователя так же необходимо будет добавить в группу “libvirt-qemu”. Просмотреть список групп можно:
Теперь необходимо сгенерировать ключ ssh и установить его на сервер, к которому будем подключаться через libvirt. Поскольку virt-manager по умолчанию запускается от обычного пользователя (не из под root), то и ключ генерируем не из под root’а. Обычно ключи лежат в папке /home/user/.ssh/id_rsa. Если их нет, то создаем:
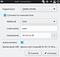
и устанавливаем на сервер с libvirt:
Далее подключаемся в virt-manager к серверу виртуализации (рис. 1).
Помимо графического интерфейса virt-manager возможно так же подключение из консоли (virsh). Подробную инструкцию можно найти на сайте libvirt.
Создание и управление виртуальными машинами.
Создание виртуальных машин из virt-manager’а тривиально и в дополнительном описании не нуждается. Что касаемо CLI, то создание виртуальной машины с именем “ubuntu-vm” ОС Ubuntu с 1024 килобайтами RAM и 1 ядром CPU будет выглядеть:
После создания виртуальная машина сама запустится, в противном случае запустить можно командой:
Завершить работу ВМ можно командой:
Завершить работу принудительно (hard power-off):
Просмотреть список всех виртаульных машин можно командой:
а только запущенных (running):
“Заморозить” (suspend) и запустить далее (resume) виртуальную машину можно командами:
Сохранить состояние машины можно командой:
По умолчанию все конфигурации виртуальных машин находятся в xml-формате папке /etc/libvirt/qemu. Можно открыть их на редактирование любым привычным редактором, а можно выполнить команду (откроется в vi):
Просмотреть конфигурацию в более читаемом виде можно командой:
Отобразить потребляемые ресурсы (CPU и Memory) можно командой:
Если пакет не установлен в системе, то:
Клонирование виртуальных машин может быть осуществлено через графический интерфейс virt-manager’а, или через консольный virt-clone. Следующая команда создаст клон оригинальной и автоматически сгенерирует образ диска:
Принудительно задать имя клона:
Задать имена виртуальных дисков (например, если клонируемая ВМ имеет два диска):
Если в качестве носителей ВМ используется LVM:
Можно так же клонировать ВМ, которые содержат snapshots. Более подробную информацию об управлении виртуальными машинами можно найти на сайте centos.org, или RedHat.
Подключение к консоли.
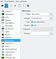
Для подключения через virt-manager достаточно, чтобы в качестве сервера был выбран Spice (см. настройки на рис. 2), а в качестве дисплей адаптеров виртуальной машины — QXL, или VGA. Подключение через virt-manager необходимо осуществлять по SSH-ключу (не по паролю). В большинстве случаев дефолтные конфиги libvirt уже пригодны для подключения к Spice, в противном случае стоит сверить следующие настройки:
Все остальные параметры Spice должны быть дефолтными (обычно закомментированы).
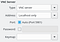
Для подключения по VNC аналогично достаточно в virt-manager выбрать “VNC Server” (рис. 3), а в качестве display-адаптеров в гостевых системах использовать QXL, или VGA.
Можно так же отредактировать настройки видео через CLI:
Приведенный пример будет слушать подключения на всех IP-адресах KVM сервера и при подключении запрашивать пароль “yourpassword”. Если убрать параметр passwd, то можно будет подключиться без пароля. Для того, чтобы определить IP-адрес и порт для подкючения к виртуальной машины по VNC выполните команду:
К полученному значению порта нужно прибавить 5900. Таким образом, в приведенном примере, подключение возможно с любого IP-адреса по порту 5901.
Подключение к текстовой консоли так же возможно напрямую через CLI. Но для этого предварительно нужно указать некоторые параметры загрузки. Для Centos/RHEL:
Альтернативно можно дописать в /etc/grub следующие параметры:
Подключаемся к консоли:
Использование NUMA.
По умолчанию libvirt использует дефолтную политику гипервизора, которая в свою очередь подразумевает запуск виртуальной машины на любых свободных вычислительных ресурсах (процессорах и ядрах). Но бывают случаи, когда явное задание ресурсов процессора бывает рациональней, особенно для систем с архитектурой NUMA (Non-Uniform Memory Access). Рассмотрим пример конфига, когда нужно назначить виртуальной машины определенные ядра процессора. Но для начала просмотрим информацию о процессорных ресурсах:
Таким образом видим, что установлен два процессора с 4 ядрами и двумя потоками на каждом ядре. Из вывода так же видим, что имеется две NUMA-ноды. Дополнительные параметры CPU можно получить командой:
Но назначение ресурсов CPU конкретной ноде не даст никакой пользы, если у этой NUMA-ноды недостаточно памяти. libvrit хранит информацию о доступной памяти на каждой NUMA-ноде. Получить информацию можно:
Таким образом видим, что для запуска ВМ с 3Гб оперативной памяти лучше использовать первую NUMA-ноду (cell 1). Просмотреть информацию можно так же через numactl. Устанавливаем:
Для примера создадим виртуальную машину, которой назначено по 2 ядра от каждого процессора:
Просмотреть результат CPU affintiy можно командой:
Подробней об использовании NUMA можно узнать на сайте Fedora и RedHat.
Проброс устройств (Passthrough).
Рассмотрим проброс устройств на примере проброса Ethernet-порта с хоста гипервизора внутрь гостевой системы в режиме PCI Passthrough. Вообще, Network адаптеры создаваемые для виртуальных машин в KVM можно так же назначать (assign) к любому ethernet-интерфейсу, но тогда теряется часть функционала hardware, а трафик пойдет через ядро хостовой системы. Для работы PCI Passthrough нужно чтобы процессор и чипсет поддерживали технологию виртуализации (в Intel — это VT-d, в AMD — AMD-Vi) и была активирована опция intel_iommu/amd_iommu. В первую очередь необходимо проверить, активированы ли данные опции в BIOS. Далее проверяем доступна ли IOMMU в самой ОС. Для AMD:
Возможно, в /etc/default/grub так же придется добавить опцию. Для Intel:
Обновляем grub и перезагружаемся:
Теперь необходимо добавить адрес PCI-устройства:
Соответственно, адрес устройства 01:00.0, или 01:00.1. Находим его в virt-manager’е в настройках ВМ:
или добавляем через CLI при создании машины, добавив следующую строчку:
Дополнительную информацию про Assign Device in KVM можно получить на сайте RedHat и linux-kvm.org. Так же, на habr’е была отличная статья по GPU Passthrough.
Работа со snapshots.
Наиболее простой способ управления snapshots — это virt-manager, который в свою очередь использует команды qemu. “Замораживаем” виртуальную машину, создаем snapshot и по завершении “размораживаем” виртуальную машину:
QEMU также поддерживает временные снимки, в которых пользователю не нужно создавать отдельный img-файл: флаг “-snapshot” позволяет создавать временные файлы пока виртуальная машина включена и, как только она будет выключена, все изменения удалятся:
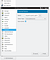
Но QEMU в отличие от virsh не может создавать snapshot виртуальных машин “на ходу”, но для того, чтобы воспользоваться этой возможностью необходимо в гостевой системе установить qemu-guest-agent и добавить для этой виртуальной машины устройство “QEMU channel device”. Заходим в свойства виртуальной машины в virt-manager (рис. 4) и добавляем устройство:
Или через консоль:
Устройство так же может быть добавлено и для запущенной виртуальной машины. Создаем xml:
Теперь на виртуальной машине (так же еще называют “dom name”) необходимо установить “гостевой агент”. Ubuntu/Debian:
Запускаем агент и добавляем в автозагрузку:
Для того, чтобы проверить доступность гостевого агента с хоста виртуализации можно выполнить команду:
Получим следующий вывод:
Но по факту, для создания snapshots нам потребуется поддержка “заморозки” гостевой файловой системы (fsreeze). Проверяем, выполнив команду с хоста гипервизора:
Если получим вывод вида:
значит поддерживается и можно приступать к созданию snapshots. Дополнительную информацию о QMP-командах и принципах работы гостевого агента можно найти на сайте qemu.org.
Дампим настройки машины в xml:
Создаем snapshot непосредственно с самими данными:
Получим сообщение вида:
В последствии подобные snapshots, содержащие только состояние дисков, удобно использовать для backup’ов (за счет использования опции blockcommit). Во всех остальных случаях удобней пользоваться полными снимками виртуальных машин. Создадим полный snapshot:
Как видно, можно так же задать имя (ключ “name”) и описание (ключ “description). За списком остальных ключей следует обратиться к документации на сайте RedHat.
Просмотреть список всех snapshots для виртуальной машины можно командой:
В результате получите список полных snapshots. Snapshot’ы содержащие только блочные устройства (ключи “—disk-only —quiesce —no-metadata”) можно получить командой:
Получить информацию о каком-либо конкретном snapshot’e:
Получим примерно следующий вывод:
Откатить состояние ВМ к определенному snapshot’у можно командой:
Иногда snapshot может быть случайно удален. Если виртуальная машина не остановлена, то snapshot можно восстановить: на Stackoverflow есть post, описывающий пошаговое восстановление образов/snapshots виртуальных машин.
Работа со Storage Pools.
Образы жестких дисков виртуальных машин располагаются в так называемых Storage Pools. libvirt поддерживает различные типы storage pool’ов — от обычной локальной папки (local storage, или filesystem pool), или LVM-based до NFS, iSCSI, CEPH и тд. По умолчанию libvirt хранит образы дисков в локальном filesystem pool, который располагается в /var/lib/libvirt/images. Как обычно, большую часть операций со storage pools можно производить из virt-manager:
Что касаемо, консоли, то получить список доступных для хоста pool’ов можно командой:
Если требуется вывести так же список неактивных pool’ов, то следует воспользоваться ключом “—all”:
Информацию о конкретном pool’е можно получить:
Обновить имеющиеся образы в storage pool’е:
К примеру, если требуется создать дополнительный storage pool, расположенный локально в папке /mnt/somefolder, то для начала требуется создать xml:
Создаем pool из этого xml, проверяем результат и запускаем:
Если по каким-то причинам Pool неактивен, можно активировать командой:
Или даже добавить в автозапуск:
Если требуется удалить Pool, то для того, чтобы избежать проблем с виртуальными машинами использующими этот Pool, требуется вначале выполнить:
При желании, если вы хотите удалить каталог, в котором находится пул хранилищ, используйте следующую команду:
Удалить предопределяющие Pool данные можно командой:
Остальную более подробную информацию об управлении Storage Pool’ами можно найти на сайте RedHat и libvirt.org.
Операции с образами дисков.
Операции с образами виртуальных дисков обеспечивает пакет QEMU, который в свою очередь поддерживает множество различных форматов: qcow, qcow2, raw, vdi, vmdk, vhdx и тд (более полный список опубликован здесь). Проще всего управлять образами через virt-manager, однако функционал QEMU будет несколько ограничен (например, нельзя изменить размер образа, или сконвертировать образ из одного формата в другой). Через консоль создание образа диска в нативном для KVM формате qcow2:
с последующим attach’ем к виртуальной машине как устройство vdb будет выглядеть следующим образом:
В целом интерфейс virsh c функцией attach-disk используется в следующем формате:
В качестве driver’а в большинстве случаев указывается “qemu”, в качестве cache можно указать “writethrough”. Подробней о режимах дискового кэширования можно ознакомиться здесь. Если параметр кэширования не задан, то используются параметры “Hypervisor defaults”.
Альтернативным способом будет добавление уcтройства через его xml-конфиг:
Дополнительно информацию о процессе добавления образов можно получить на сайтах: RedHat и Fedoraproject.org.
Изменим размер образа (увеличим на 10Гб):
Иногда при попытке изменить размер образа диска можно получить сообщение:
Но при этом в virt-manager’е не отображается ни одного снимка, а команда:
так же е выводит никаких результатов о созданных snapshots. Вероятней всего, snapshot был создан через qemu и получить информацию об образе можно командой:
которая, к примеру, выдает:
Как видим, перед расширением образа необходимо удалить snapshot по его ID:
Смотрим информацию об образе можно командой:
Зачастую бывает нужно сконвертировать образ из одного формата в другой (например, для того, чтобы native-формат qcow2 работал быстрей, чем vmdk от VMware). Для этого можно воспользоваться пакетом qemu-img:
Пакет qemu-img поддерживает vmdk, qcow2, vhd, vhdx, raw, vdi. По факту нужно указать исходный и конечный формат. Сконвертируем vdi в qcow2:
Возможно использовать следующие опции:
Дополнительную информацию по qemu-img можно получить на сайтах fedoraproject.org и RedHat.
Ссылки.
Многое (за исключением специфических для RedHat компонентов) можно так же почерпнуть по следующим ссылкам:
Информацию по распоространенным проблемам при работе с livbirt можно найти в отдельном разделе сайта RedHat:
Источник



