- Формат файла WEBARCHIVE — описание, как открыть?
- Чем открыть файл в формате WEBARCHIVE
- Программы для открытия WEBARCHIVE файлов
- Конвертация WEBARCHIVE в другие форматы
- Почему именно WEBARCHIVE и в чем его достоинства?
- Web archive open windows
- 4 простых способа открыть WEBARCHIVE Files
- Использовать другую программу
- Получить ключ от типа файла
- Связаться с разработчиком
- Получить универсальный просмотрщик файлов
- Рекомендуем
- HackWare.ru
- Этичный хакинг и тестирование на проникновение, информационная безопасность
- Веб-архивы Интернета: как искать удалённую информацию и восстанавливать сайты
- Что такое Wayback Machine и Архивы Интернета
- Какие существуют веб-архивы Интернета
- web.archive.org
- Changes
- Summary
- Site Map
- Поиск по Интернет архиву
- Показ страницы на определённую дату
- archive.md
- web-arhive.ru
- Поиск сразу по всем Веб-архивам
- Что делать, если удалённая страница не сохранена ни в одном из архивов?
- Как полностью скачать сайт из веб-архива
- Как скачать все изменения страницы из веб-архива
- Как узнать все страницы сайта, которые сохранены в веб-архиве
- Заключение
Формат файла WEBARCHIVE — описание, как открыть?
Файл формата WEBARCHIVE открывается специальными программами. Чтобы открыть данный формат, скачайте одну из предложенных программ.
Чем открыть файл в формате WEBARCHIVE
WEBARCHIVE формат используется в качестве файла для хранения данных в интернет-браузере Safari (разработчик – Apple). Такой веб браузер доступен не только на базе Apple iOS (для iPhone, iPad, iPod), он также адаптирован для работы в ОС Windows и Mac.
Как правило, WEBARCHIVE содержит двоичное представление данных и являет собой полноценную копию HTML страницы, включая графические изображения, мультимедийный контент (аудио и видео записи), а также всю ту информацию, которая будет востребована системой для полного воспроизведения страницы без подключения к сети интернет (в автономном режиме).
Формат WEBARCHIVE – своего рода репозиторий файлов данных в двоичном коде с поддержкой возможности хранения интернет-страниц в виде индивидуальных автономных веб-пакетов.
По своей структуре WEBARCHIVE файл представляет собой смешанный двоичный и текстовый форматы (несжатая компиляция), необходимые для корректного представления содержимого страницы.
Некоторые расширения WEBARCHIVE могут быть воспроизведены в других интернет-браузерах (например, iCab и Cruz), но информация может воспроизводиться не полностью или искаженно.
С использованием плагинов WebArchive Folderizer/Extractor, находящихся в бесплатном доступе, у пользователя появляется возможность разархивации WEBARCHIVE файла в отдельный каталог для дальнейшего применения.
Программы для открытия WEBARCHIVE файлов
Для открытия и воспроизведения WebArchive-расширения на базе платформы ОС Windows можно воспользоваться одной из следующих интернет-браузером Safari.
Формат WebArchive также адаптирован для других ОС, например, в Mac ОС расширение может быть открыто с помощью плагинов:
Примечательно, что организовать работу с WebArchive архивом можно с использованием многочисленных мобильных устройств (iPhone, iPad, iPod) на платформе Apple iOS. Для этого потребуется установка плагина Web Archive Viewer.
В случае если при воспроизведении формата возникает ошибка: либо поврежден или заражен исходный файл, либо осуществляется открытие WebArchive-файла с применением некорректной программной утилиты.
Конвертация WEBARCHIVE в другие форматы
Не вызывает сомнений, что самый популярный формат для воспроизведения и форматирования веб-приложений – это HTML. Именно поэтому среди пользователей востребована конвертация расширения WebArchive в HTML.
Реализовать подобный процесс можно с помощью интегрированного в интернет-браузер Safari транслятора или же воспользовавшись одним из онлайн-сервисов, например, Onlineconvertfree.
Почему именно WEBARCHIVE и в чем его достоинства?
WEBARCHIVE – это уникальный формат пакетирования данных веб-страницы. Благодаря данному расширению пользователь получает прекрасную возможность получить представление HTML-страницы, включая графические изображения, мультимедийный контент (аудио и видео записи), для ее отображения в автономном режиме (исключая подключение к сети интернет).
Веб-страница, создаваемая веб-браузером Safari. Содержит HTML-код и изображения так, что страницу можно загружать целиком позднее, даже если компьютер выключен или не подсоединен к Интернету.
Веб-архивы Safari можно просматривать в Safari, а также в веб-браузерах iCab и Cruz. Их также можно открывать в Apple TextEdit, но содержимое может отображаться некорректно.
Чем открыть файл в формате WEBARCHIVE (Safari Web Archive)
Web archive open windows
4 простых способа открыть WEBARCHIVE Files
Мы все были там. Вы дважды щелкаете по файлу, и он не открывается так, как должен. Это обычная проблема. Многие расширения файлов могут быть открыты несколькими программами, и многие программы могут открывать несколько расширений файлов. Если у вас возникли проблемы с открытием файлов WEBARCHIVE, вот некоторые способы их работы.
Установить необязательные продукты — File Magic (Solvusoft) | EULA | Privacy Policy | Terms | Uninstall
Использовать другую программу

Если вы не можете просмотреть файл WEBARCHIVE, дважды щелкнув его, попробуйте открыть его в другой программе. Одной из самых популярных программ для открытия файлов WEBARCHIVE является Safari Web Archive. Просмотрите веб-сайты разработчиков, загрузите одну или несколько из этих программ, затем попробуйте снова открыть файл WEBARCHIVE.
Получить ключ от типа файла
Одно расширение файла может использоваться для нескольких типов файлов. Знание типа файла, который у вас есть, может помочь вам узнать, как его открыть. Большинство файлов WEBARCHIVE классифицируются как Web Files, которые могут быть открыты многочисленными пакетами программного обеспечения. Посмотрите, есть ли у вас программа, уже установленная на вашем компьютере, которая предназначена для открытия Web Files. Надеюсь, эта программа также может работать с вашим файлом WEBARCHIVE.
Вы можете узнать, какой тип файла представляет ваш файл WEBARCHIVE, просматривая свойства файла. Щелкните правой кнопкой мыши значок файла и выберите «Свойства» или «Дополнительная информация». На компьютере с Windows тип файла будет указан в разделе «Тип файла»; на Mac, он будет под «Доброй».
Связаться с разработчиком
Никто не знает больше о расширениях файлов, чем разработчики программного обеспечения. Если вы не можете открыть файл WEBARCHIVE с помощью любой из обычных программ, вы можете обратиться к разработчику программного обеспечения программы и попросить их о помощи. Найдите разработчика своей программы в списке ниже:
| Программного обеспечения | разработчик |
|---|---|
| Safari Web Archive | Apple Inc. |
Получить универсальный просмотрщик файлов
Когда никакая другая программа не откроет ваш файл WEBARCHIVE, универсальные файловые зрители, такие как File Magic (Download), здесь, чтобы сохранить день. Эти программы могут открывать много разных типов файлов, поэтому, если ни один из вышеприведенных советов не работает, универсальный просмотрщик файлов — это путь. Обратите внимание, что некоторые файлы не совместимы с универсальными файловыми программами и могут быть открыты только в двоичном формате.
Рекомендуем
Установить необязательные продукты — File Magic (Solvusoft) | EULA | Privacy Policy | Terms | Uninstall
HackWare.ru
Этичный хакинг и тестирование на проникновение, информационная безопасность
Веб-архивы Интернета: как искать удалённую информацию и восстанавливать сайты
Что такое Wayback Machine и Архивы Интернета
В этой статье мы рассмотрим Веб Архивы сайтов или Интернет архивы: как искать удалённую с сайтов информацию, как скачать больше несуществующие сайты и другие примеры и случаи использования.
Принцип работы всех Интернет Архивов схожий: кто-то (любой пользователь) указывает страницу для сохранения. Интернет Архив скачивает её, в том числе текст, изображения и стили оформления, а затем сохраняет. По запросу сохранённые страницу могут быть просмотрены из Интернет Архива, при этом не имеет значения, если исходная страница изменилась или сайт в данный момент недоступен или вовсе перестал существовать.
Многие Интернет Архивы хранят несколько версий одной и той же страницы, делая её снимок в разное время. Благодаря этому можно проследить историю изменения сайта или веб-страницы в течение всех лет существования.
В этой статье будет показано, как находить удалённую или изменённую информацию, как использовать Интернет Архивы для восстановления сайтов, отдельных страниц или файлов, а также некоторые другие случае использования.
Wayback Machine — это название одного из популярного веб архива сайтов. Иногда Wayback Machine используется как синоним «Интернет Архив».
Какие существуют веб-архивы Интернета
Я знаю о трёх архивах веб-сайтов (если вы знаете больше, то пишите их в комментариях):
web.archive.org
Этот сервис веб архива ещё известен как Wayback Machine. Имеет разные дополнительные функции, чаще всего используется инструментами по восстановлению сайтов и информации.
Для сохранения страницы в архив перейдите по адресу https://archive.org/web/ введите адрес интересующей вас страницы и нажмите кнопку «SAVE PAGE».

Для просмотра доступных сохранённых версий веб-страницы, перейдите по адресу https://archive.org/web/, введите адрес интересующей вас страницы или домен веб-сайта и нажмите «BROWSE HISTORY»:

В самом верху написано, сколько всего снимком страницы сделано, дата первого и последнего снимка.
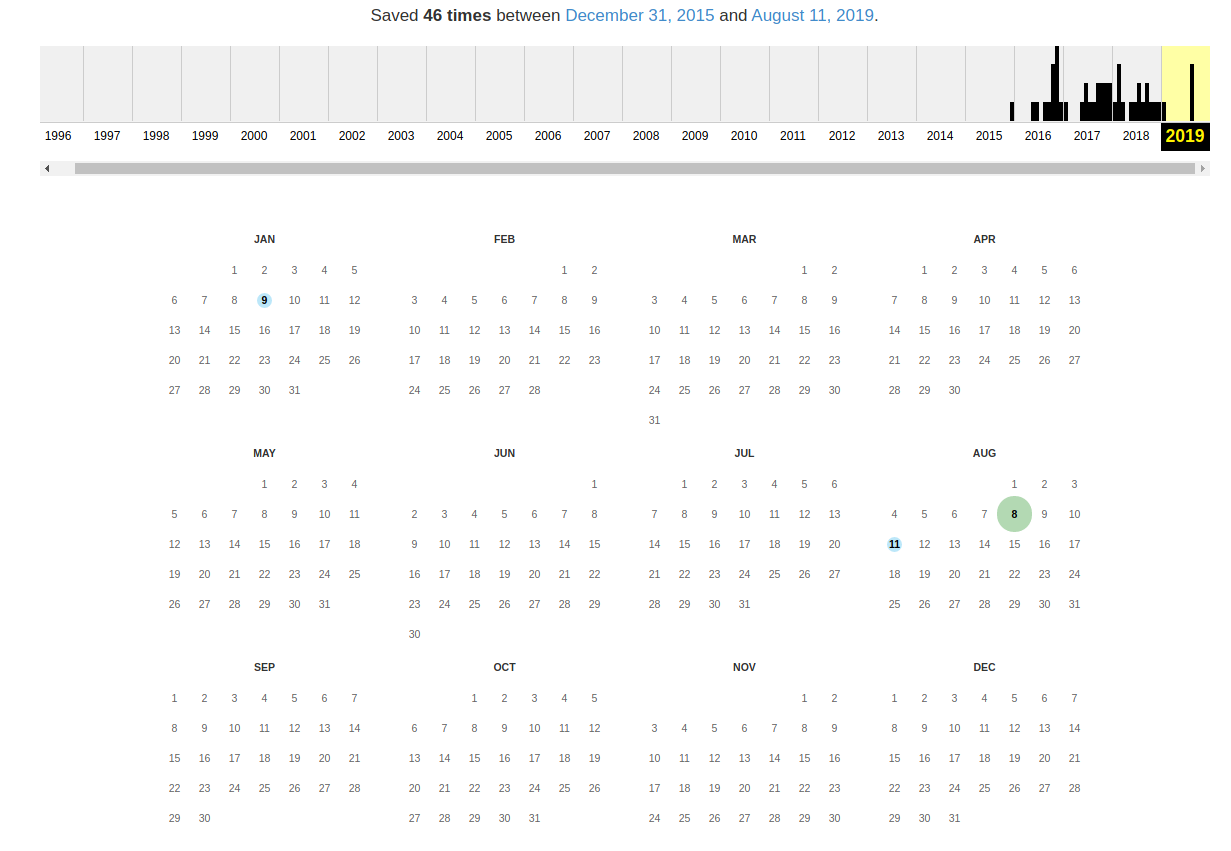
Затем идёт шкала времени на которой можно выбрать интересующий год, при выборе года, будет обновляться календарь.
Обратите внимание, что календарь показывает не количество изменений на сайте, а количество раз, когда был сделан архив страницы.
Точки на календаре означают разные события, разные цвета несут разный смысл о веб захвате. Голубой означает, что при архивации страницы от веб-сервера был получен код ответа 2nn (всё хорошо); зелёный означает, что архиватор получил статус 3nn (перенаправление); оранжевый означает, что получен статус 4nn (ошибка на стороне клиента, например, страница не найдена), а красный означает, что при архивации получена ошибка 5nn (проблемы на сервере). Вероятно, чаще всего вас должны интересовать голубые и зелёные точки и ссылки.

При клике на выбранное время, будет открыта ссылка, например, http://web.archive.org/web/20160803222240/https://hackware.ru/ и вам будет показано, как выглядела страница в то время:

Используя эту миниатюру вы сможете переходить к следующему снимку страницы, либо перепрыгнуть к нужной дате:
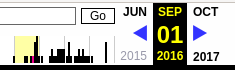
Лучший способ увидеть все файлы, которые были архивированы для определённого сайта, это открыть ссылку вида http://web.archive.org/*/www.yoursite.com/*, например, http://web.archive.org/*/hackware.ru/
Кроме календаря доступна следующие страницы:
- Collections — коллекции. Доступны как дополнительные функции для зарегистрированных пользователей и по подписке
- Changes
- Summary
- Site Map
Changes
«Changes» — это инструмент, который вы можете использовать для идентификации и отображения изменений в содержимом заархивированных URL.
Начать вы можете с того, что выберите два различных дня какого-то URL. Для этого кликните на соответствующие точки:
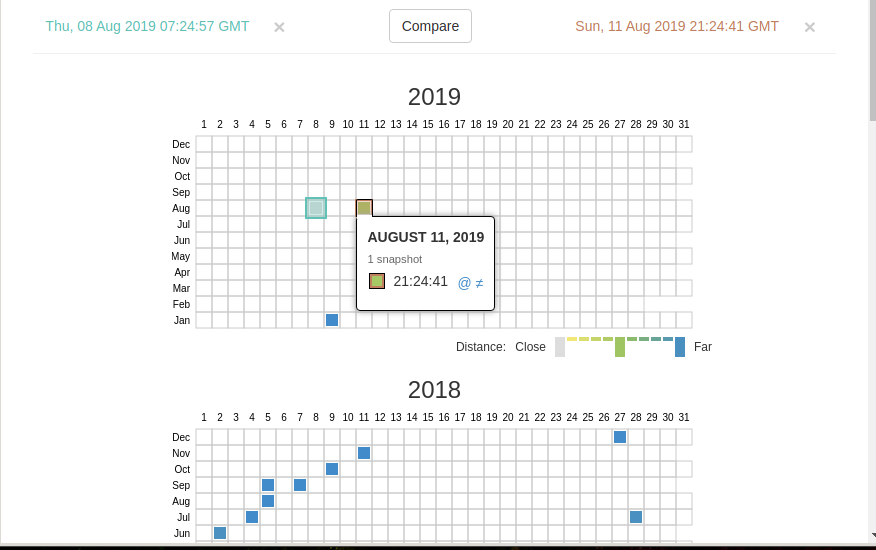
И нажмите кнопку Compare. В результате будут показаны два варианта страницы. Жёлтый цвет показывает удалённый контент, а голубой цвет показывает добавленный контент.
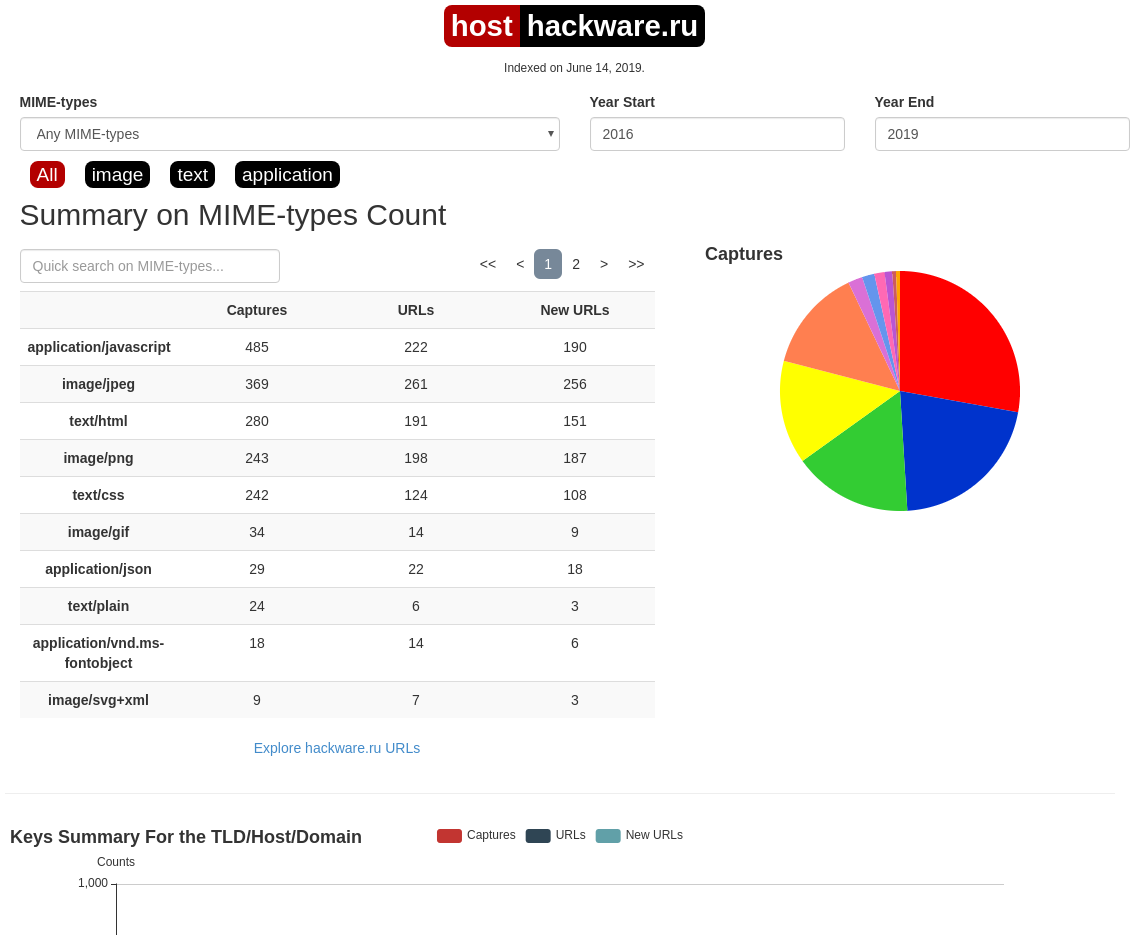
Summary
В этой вкладке статистика о количестве изменений MIME-типов.
Site Map
Как следует из название, здесь показывается диаграмма карты сайта, используя которую вы можете перейти к архиву интересующей вас страницы.
Поиск по Интернет архиву
Если вместо адреса страницы вы введёте что-то другое, то будет выполнен поиск по архивированным сайтам:

Показ страницы на определённую дату
Кроме использования календаря для перехода к нужной дате, вы можете просмотреть страницу на нужную дату используя ссылку следующего вида: http://web.archive.org/web/ГГГГММДДЧЧММСС/АДРЕС_СТРАНИЦЫ/
Обратите внимание, что в строке ГГГГММДДЧЧММСС можно пропустить любое количество конечных цифр.
Если на нужную дату не найдена архивная копия, то будет показана версия на ближайшую имеющуюся дату.
archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы

Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- http://twitter.com/burgerkingfor покажет архив данного url (поиск чувствителен к регистру)
- http://twitter.com/burg* поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
Также возможно обратиться ко всем снимкам указанного URL:
Все сохранённые страницы домена:
Все сохранённые страницы всех субдоменов
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
Чтобы обратиться к определённой части длинной страницы имеется две опции:
- добавить хэштег (#) с позицией прокрутки в качество которого число между 0 (вершина страницы) и 100 (низ страницы). Например, http://archive.md/dva4n#95%
- выбрать текст на страницы и получить URL с хэштегом, указывающим на этот раздел. Например, http://archive.is/FWVL#selection-1493.0-1493.53
В доменах поддерживаются национальные символы:
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
web-arhive.ru
Архив интернет (Web archive) — это бесплатный сервис по поиску архивных копий сайтов. С помощью данного сервиса вы можете проверить внешний вид и содержимое страницы в сети интернет на определённую дату.
На момент написания, этот сервис, вроде бы, нормально не работает («Database Exception (#2002)»). Если у вас есть по нему какие-то новости, то пишите их в комментариях.
Поиск сразу по всем Веб-архивам
Может так случиться, что интересующая страница или файл отсутствует в веб архиве. В этом случае можно попытаться найти интересующую сохранённую страницу в другом Архиве Интернета. Специально для этого я сделал довольно простой сервис, который для введённого адреса даёт ссылки на снимки страницы в рассмотренных трёх архивах.

Что делать, если удалённая страница не сохранена ни в одном из архивов?
Архивы Интернета сохраняют страницы только если какой-то пользователь сделал на это запрос — они не имеют функции обходчиков и ищут новые страницы и ссылки. По этой причине возможно, что интересующая вас страница оказалась удалено до того, как была сохранена в каком-либо веб-архиве.
Тем не менее можно воспользоваться услугами поисковых движков, которые активно ищут новые ссылки и оперативно сохраняют новые страницы. Для показа страницы из кэша Google нужно в поиске Гугла ввести
Если ввести подобный запрос в поиск Google, то сразу будет открыта страница из кэша.
Для просмотра текстовой версии можно использовать ссылку вида:
- http://webcache.googleusercontent.com/search?q=cache:URL&strip=1&vwsrc=0
Для просмотра исходного кода веб страницы из кэша Google используйте ссылку вида:
- http://webcache.googleusercontent.com/search?q=cache:URL&strip=0&vwsrc=1
Например, текстовый вид:
Как полностью скачать сайт из веб-архива
Если вы хотите восстановить удалённый сайт, то вам поможет программа Wayback Machine Downloader.
Программа загрузит последнюю версию каждого файла, присутствующего в Архиве Интернета Wayback Machine, и сохранить его в папку вида ./websites/example.com/. Она также пересоздаст структуру директорий и автоматически создаст страницы index.html чтобы скаченный сайт без каких либо изменений можно было бы поместить на веб-сервер Apache или Nginx.
Об установке программы и дополнительных опциях смотрите на странице https://kali.tools/?p=5211
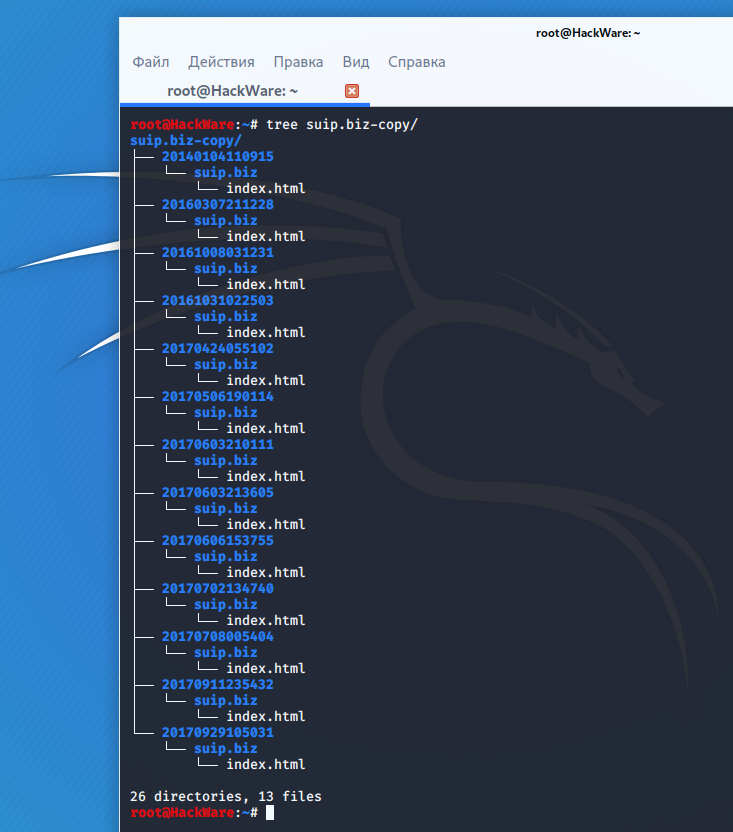
Пример скачивания полной копии сайта suip.biz из веб-архива:
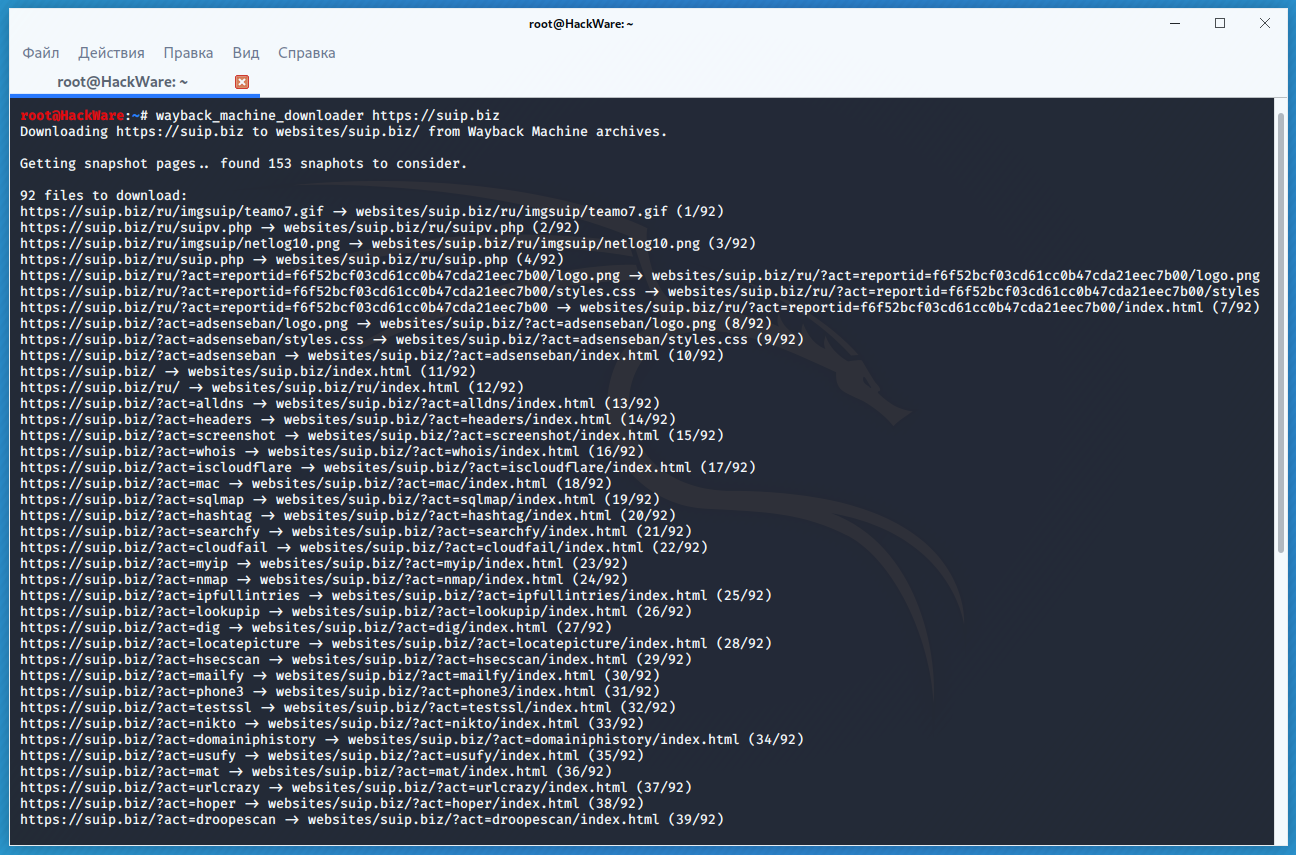
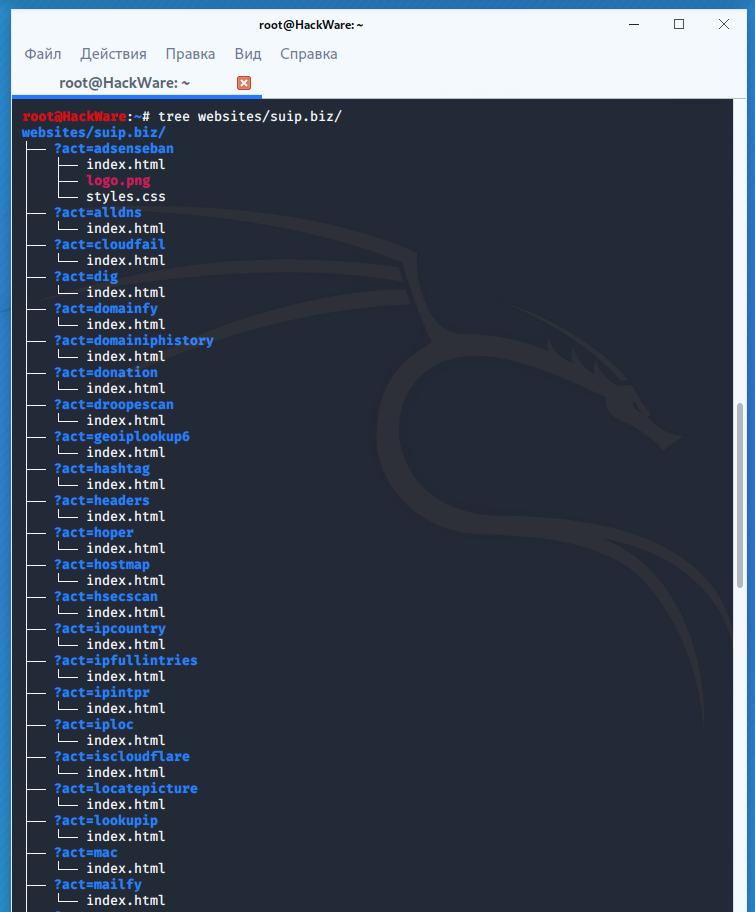
Структура скаченных файлов:
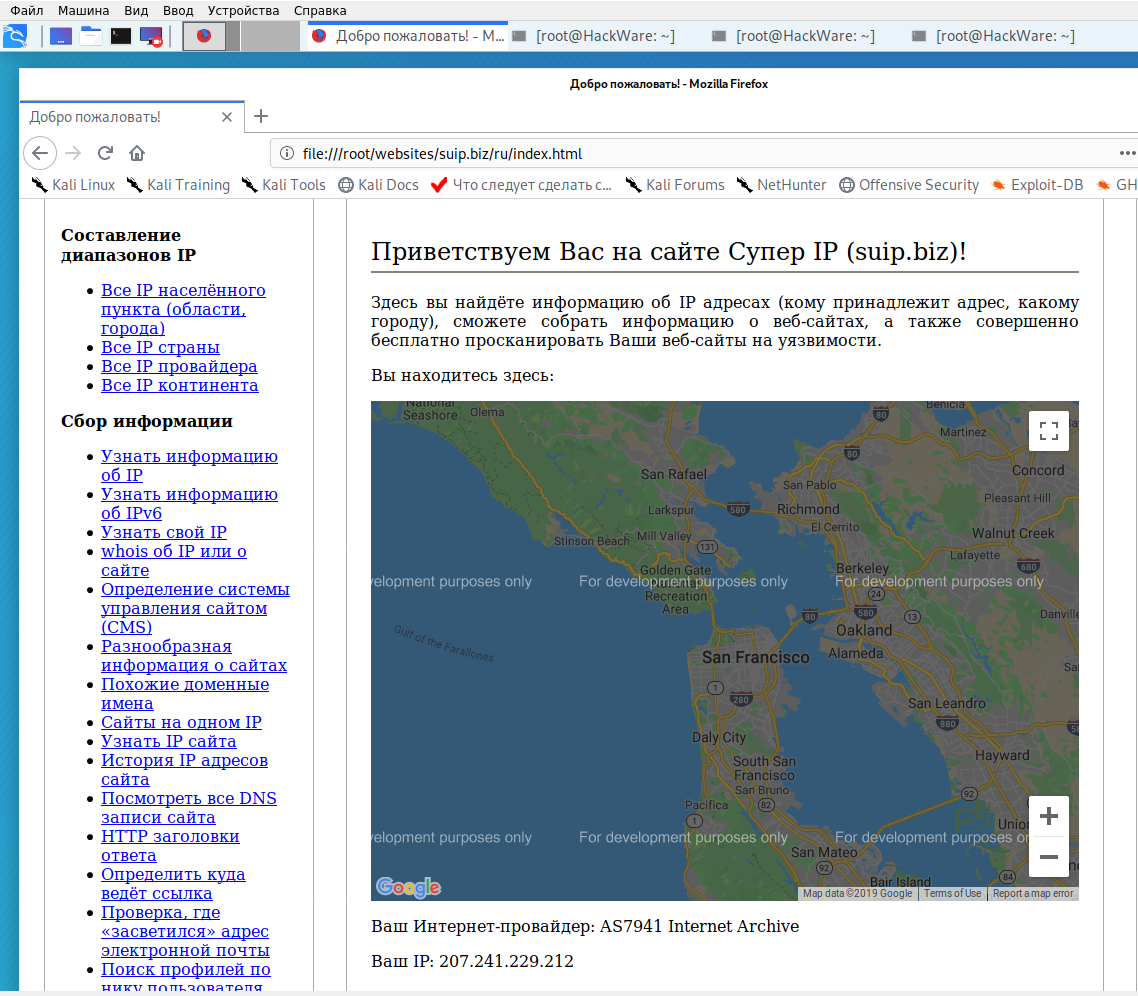
Локальная копия сайта, обратите внимание на провайдера Интернет услуг:
Как скачать все изменения страницы из веб-архива
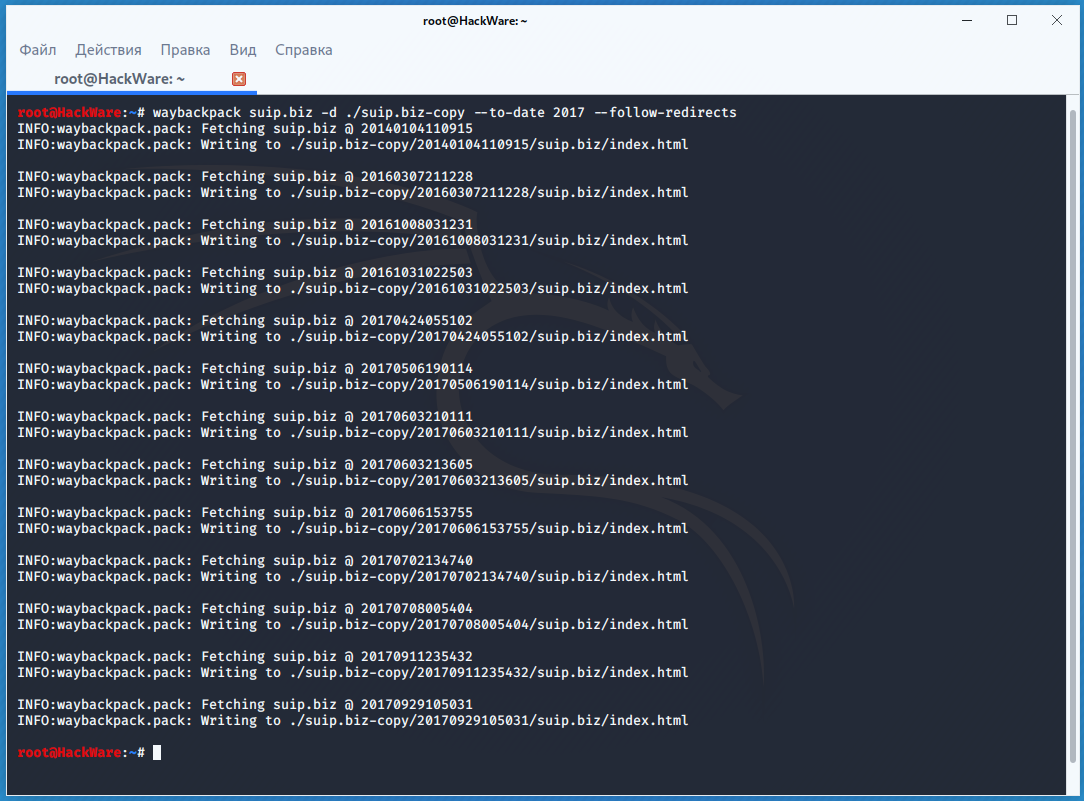
Если вас интересует не весь сайт, а определённая страница, но при этом вам нужно проследить все изменения на ней, то в этом случае используйте программу Waybackpack.
К примеру для скачивания всех копий главной страницы сайта suip.biz, начиная с даты (—to-date 2017), эти страницы должны быть помещены в папку (-d /home/mial/test), при этом программа должна следовать HTTP редиректам (—follow-redirects):
Чтобы для указанного сайта (hackware.ru) вывести список всех доступных копий в веб-архиве (—list):
Как узнать все страницы сайта, которые сохранены в веб-архиве
Для получения ссылок, которые хранятся в Архиве Интернета, используйте программу waybackurls.
Эта программа извлекает все URL указанного домена, о которых знает Wayback Machine. Это можно использовать для быстрого составления карты сайта.
Чтобы получить список всех страниц о которых знает Wayback Machine для домена suip.biz:
Заключение
Предыдущие три программы рассмотрены совсем кратко. Дополнительную информацию об их установке и об имеющихся опциях вы сможете найти по ссылкам на карточки этих программ.
Ещё парочка программ, которые работают с архивом интернета:



