- Фундаментальные основы Linux. Часть IV. Программные каналы и команды
- Глава 17. Фильтры
- Фильтр cat
- Фильтр tee
- Фильтр grep
- Фильтр cut
- Фильтр tr
- Фильтр wc
- Фильтр sort
- Фильтр uniq
- Фильтр comm
- Фильтр od
- Фильтр sed
- Примеры конвейеров
- Практическое задание: фильтры
- Корректная процедура выполнения практического задания: фильтры
- Filters in Linux
- Команды фильтрации в Linux. head, tail, sort, nl, wc, cut, sed, uniq, tac
- Фильтры в Linux
- head
- tail
- sort
- nl
- wc
- cut
- sed
- uniq
- tac
- Вывод
- Unix / Linux — Pipes and Filters
- The grep Command
- The sort Command
- The pg and more Commands
Фундаментальные основы Linux. Часть IV. Программные каналы и команды
Глава 17. Фильтры
Команды, которые были реализованы для использования совместно с программными каналами , называются фильтрами . Эти фильтры реализуются в виде простейших программ, которые крайне эффективно выполняют одну определенную задачу. Исходя из всего вышесказанного, они могут использоваться в качестве строительных блоков при создании сложных конструкций.
В данной главе представлена информация о наиболее часто используемых фильтрах . В результате комбинирования простых команд и фильтров с использованием программных каналов могут быть созданы элегантные решения.
Фильтр cat
Фильтр tee
Фильтр grep
Фильтр cut
Фильтр tr
Фильтр wc
Фильтр sort
Фильтр uniq
Фильтр comm
Фильтр od
Фильтр sed
Примеры конвейеров
Конвейер who | wc
Конвейер who | cut | sort
Конвейер grep | cut
Практическое задание: фильтры
1. Сохраните отсортированный список пользователей командной оболочки bash в файле bashusers.txt.
2. Сохраните отсортированный список пользователей, осуществивших вход в систему, в файле onlineusers.txt.
3. Создайте список всех имен файлов из директории /etc , в которых содержится строка conf .
4. Создайте список всех имен файлов из директории /etc , в которых содержится строка conf вне зависимости от регистра символов.
5. Рассмотрите вывод утилиты /sbin/ifconfg . Создайте команду, с помощью которой будут выводиться исключительно IP-адреса и маски подсетей.
6. Создайте команду, которая позволит удалить все не относящиеся к буквенным символы из потока данных.
7. Создайте команду, которая будет принимать файл и выводить каждое слово из него в отдельной строке.
8. Разработайте систему проверки орфографии с интерфейсом командной строки. (Словарь должен находиться в директории /usr/share/dict/ .)
Корректная процедура выполнения практического задания: фильтры
1. Сохраните отсортированный список пользователей командной оболочки bash в файле bashusers.txt.
2. Сохраните отсортированный список пользователей, осуществивших вход в систему, в файле onlineusers.txt.
3. Создайте список всех имен файлов из директории /etc , в которых содержится строка conf .
4. Создайте список всех имен файлов из директории /etc , в которых содержится строка conf вне зависимости от регистра символов.
5. Рассмотрите вывод утилиты /sbin/ifconfg . Создайте команду, с помощью которой будут выводиться исключительно IP-адреса и маски подсетей.
6. Создайте команду, которая позволит удалить все не относящиеся к буквенным символы из потока данных.
7. Создайте команду, которая будет принимать файл и выводить каждое слово из него в отдельной строке.
8. Разработайте систему проверки орфографии с интерфейсом командной строки. (Словарь должен находиться в директории /usr/share/dict/ .)
Также вы можете добавить решение из вопроса номер 6 для удаления не относящихся к буквенным символов и фильтр tr -s ‘ ‘ для удаления лишних символов пробелов.
Источник
Filters in Linux
Filters are programs that take plain text(either stored in a file or produced by another program) as standard input, transforms it into a meaningful format, and then returns it as standard output. Linux has a number of filters. Some of the most commonly used filters are explained below:
1. cat : Displays the text of the file line by line.
Syntax:
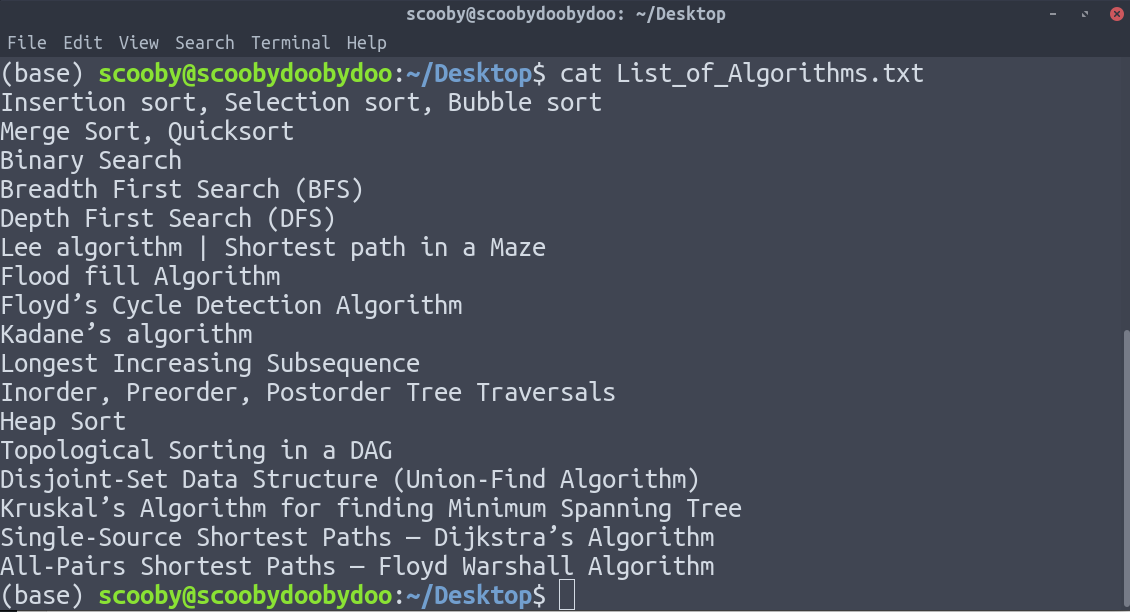
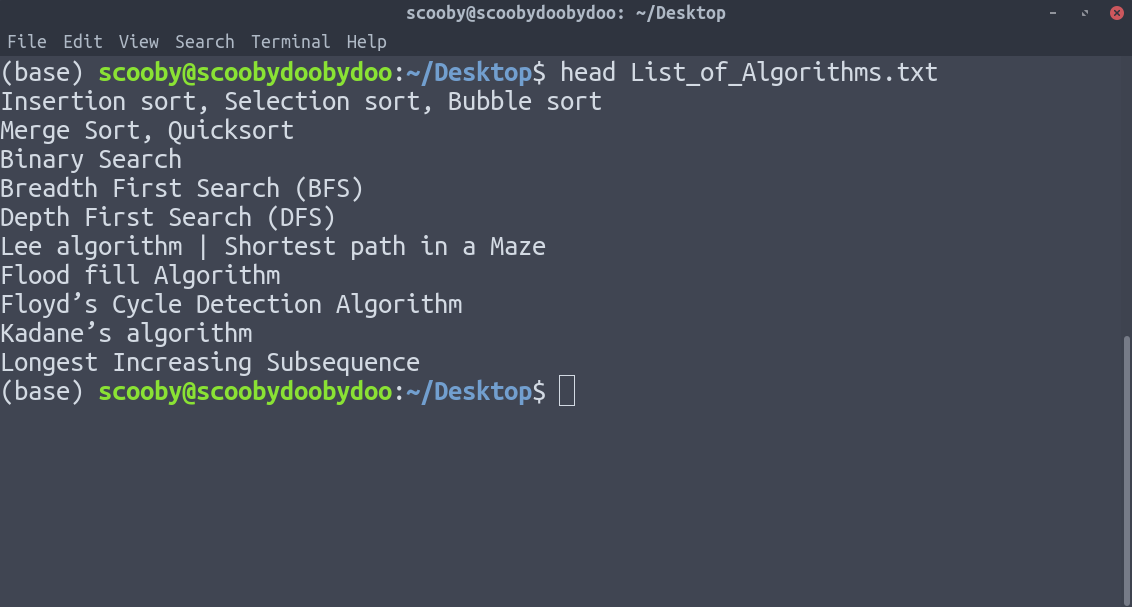
2. head : Displays the first n lines of the specified text files. If the number of lines is not specified then by default prints first 10 lines.
Syntax:
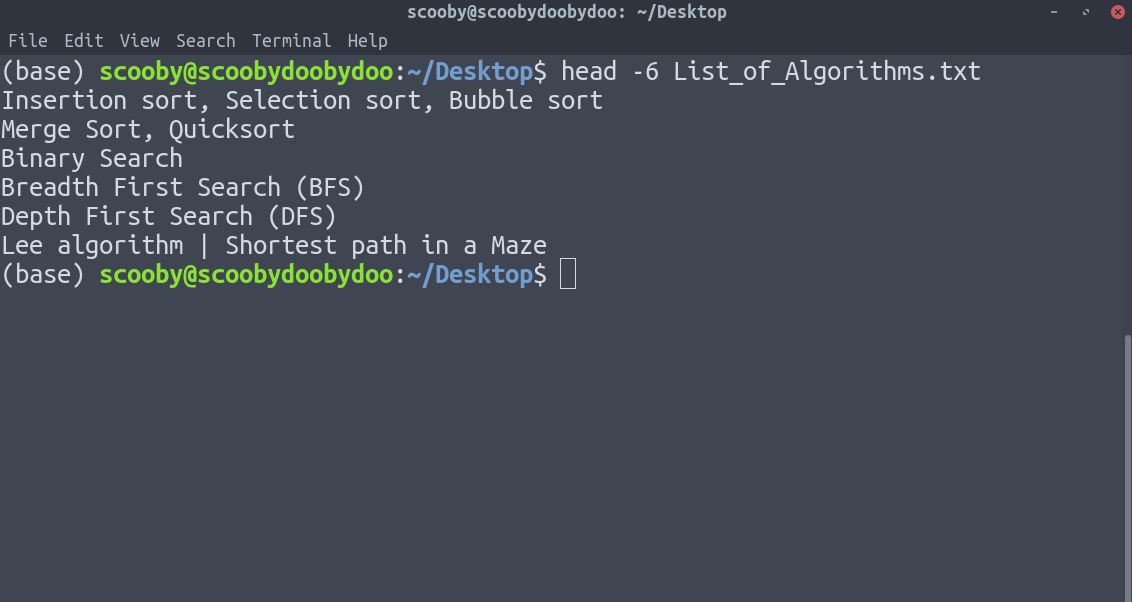
3. tail : It works the same way as head, just in reverse order. The only difference in tail is, it returns the lines from bottom to up.
Syntax:
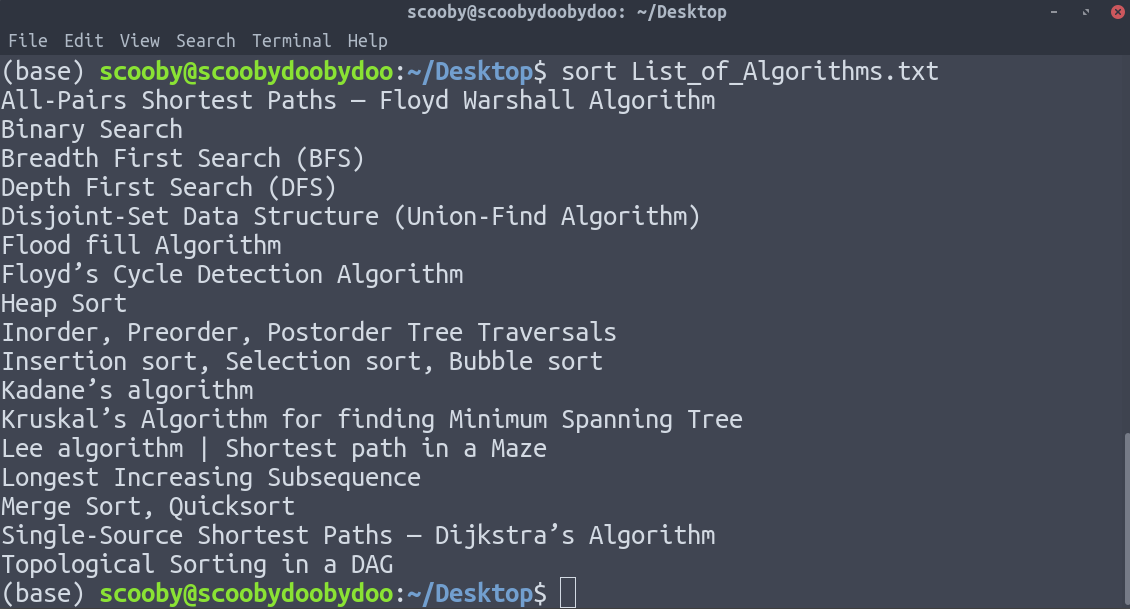
4. sort : Sorts the lines alphabetically by default but there are many options available to modify the sorting mechanism. Be sure to check out the main page to see everything it can do.
Syntax:
5. uniq : Removes duplicate lines. uniq has a limitation that it can only remove continuous duplicate lines(although this can be fixed by the use of piping). Assuming we have the following data.
Syntax:
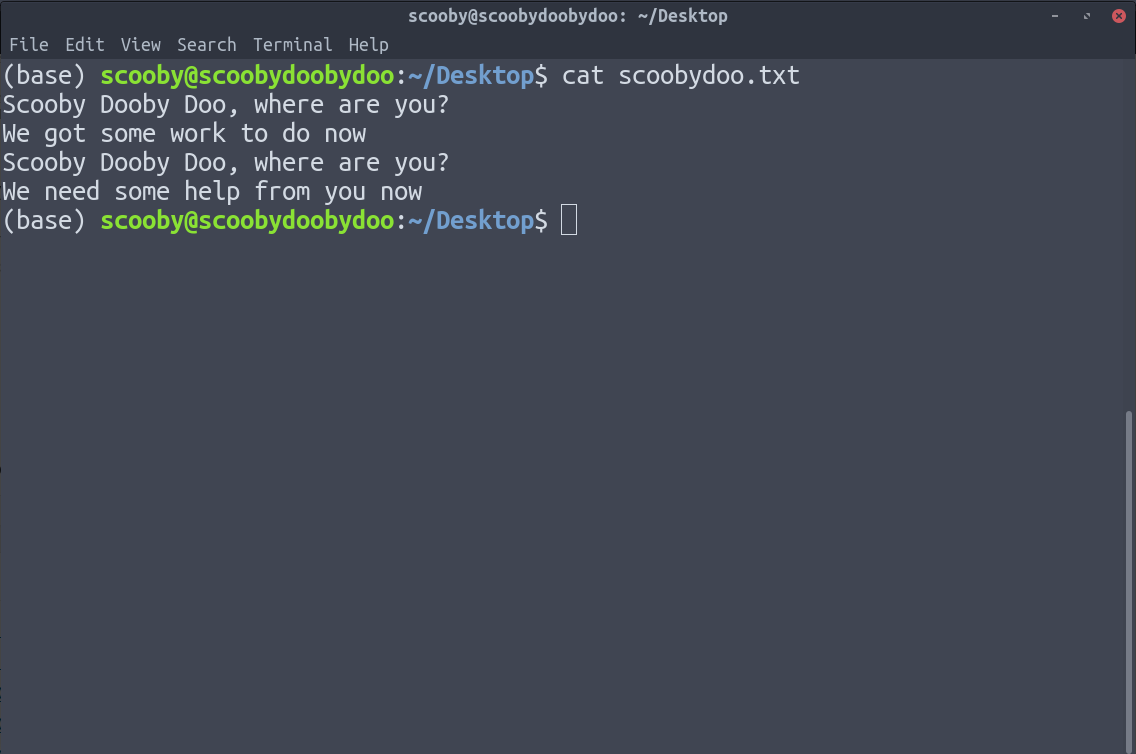
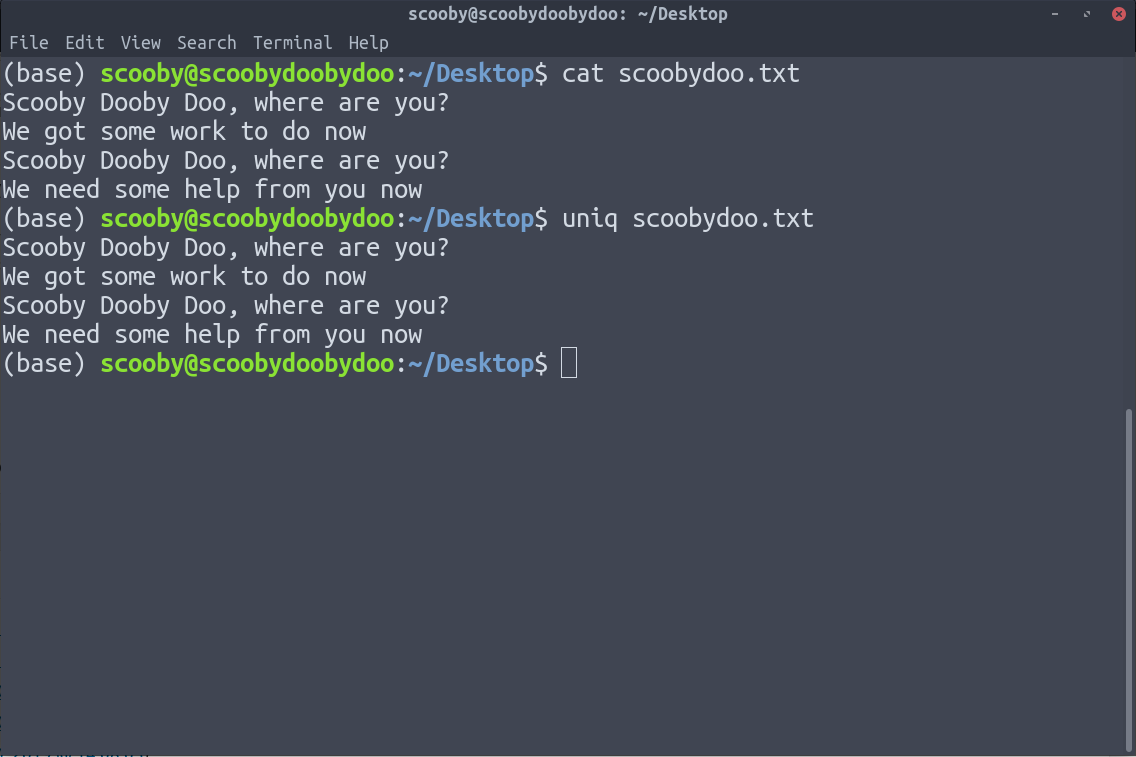
You can see that applying uniq doesn’t remove any duplicate lines, because uniq only removes duplicate lines which are together.
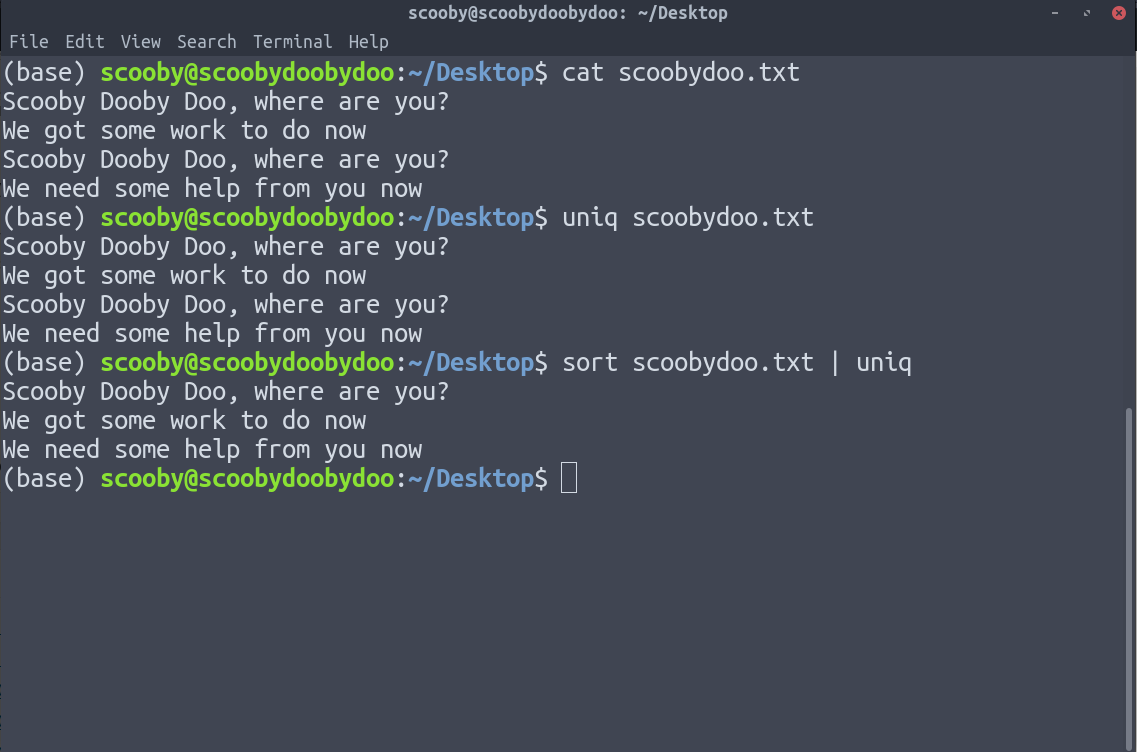
When applying uniq to sorted data, it removes the duplicate lines because, after sorting data, duplicate lines come together.
6. wc : wc command gives the number of lines, words and characters in the data.
Syntax:
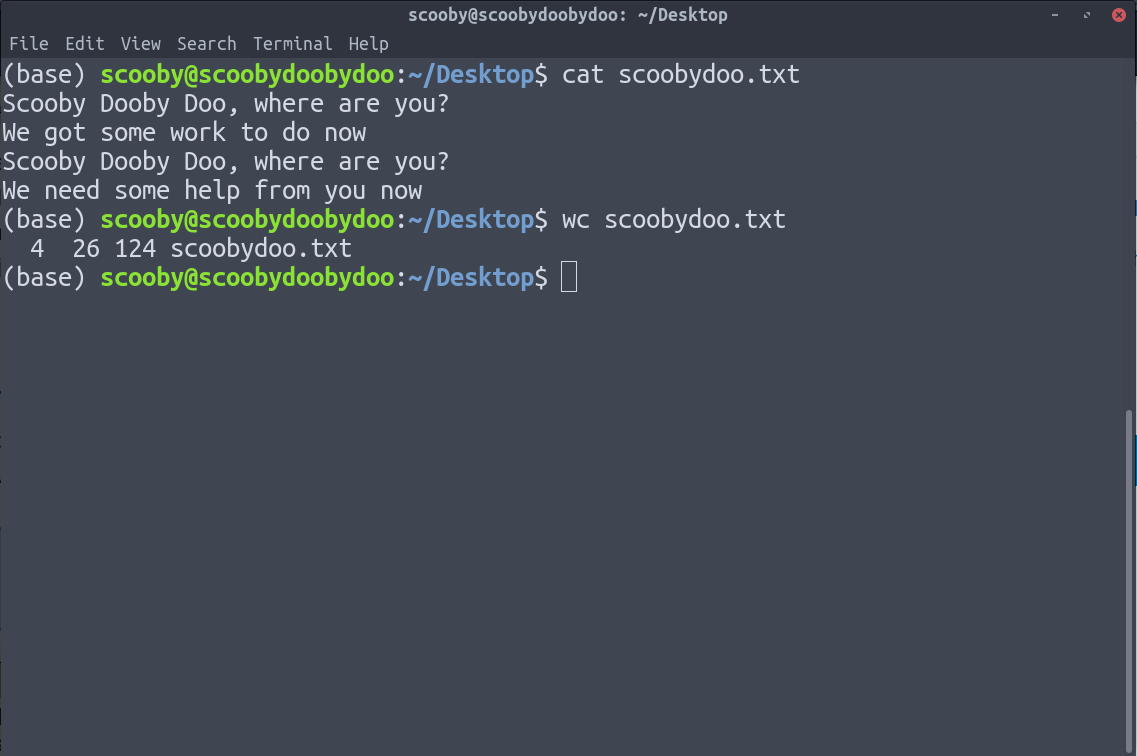
In above image the wc gives 4 outputs as:
- number of lines
- number of words
- number of characters
- path
7. grep : grep is used to search a particular information from a text file.
Syntax:
Below are the two ways in which we can implement grep.
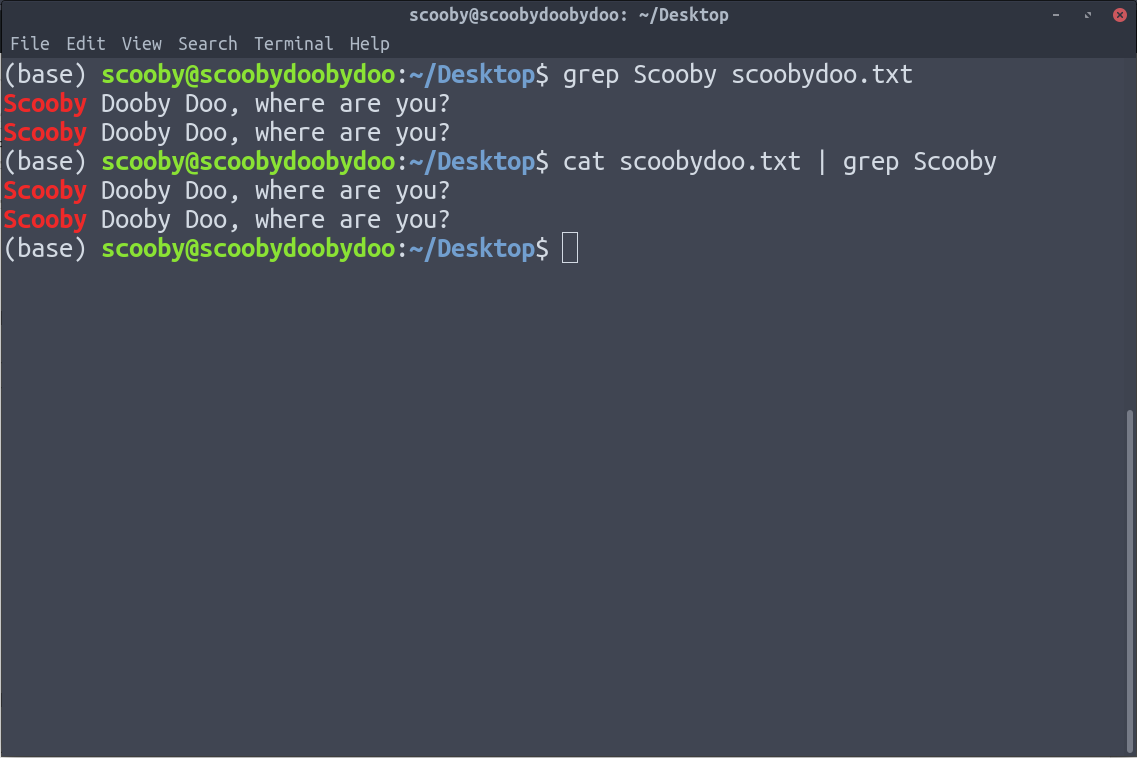
8. tac : tac is just the reverse of cat and it works the same way, i.e., instead of printing from lines 1 through n, it prints lines n through 1. It is just reverse of cat command.
Syntax:
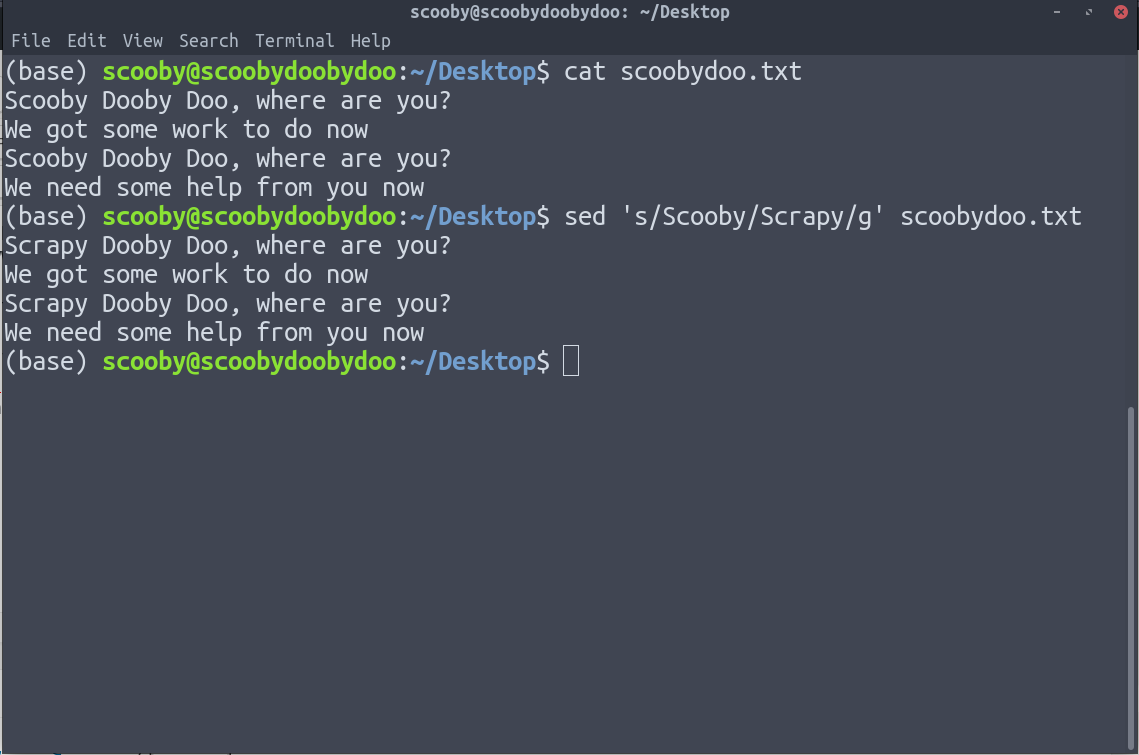
9. sed : sed stands for stream editor. It allows us to apply search and replace operation on our data effectively. sed is quite an advanced filter and all its options can be seen on its man page.
Syntax:
The expression we have used above is very basic and is of the form ‘s/search/replace/g’
In the above image, we can clearly see that Scooby is replaced by Scrapy.
10. nl : nl is used to number the lines of our text data.
Syntax:
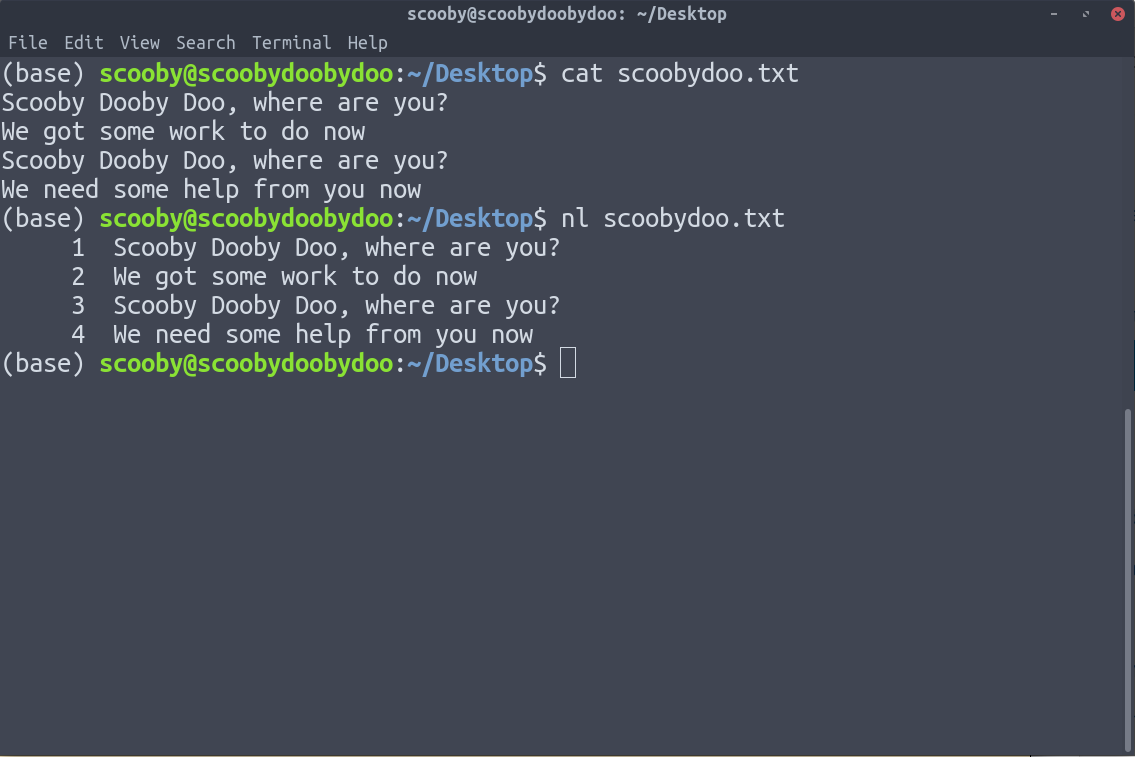
It can clearly be seen in the above image that the lines have been numbered
Источник
Команды фильтрации в Linux. head, tail, sort, nl, wc, cut, sed, uniq, tac
В статье мы рассмотрим множество команд для фильтрации. Изучение команд будет сопровождаться подробными примерами.
Фильтры в Linux
Фильтры — это способ получения необработанных данных, созданных другой программой или сохраненных в файле.
Эти фильтры имеют различные параметры командной строки, которые изменяют их поведение. В результате, всегда полезно проверить страницу руководства для фильтра.
В приведенных ниже примерах мы будем предоставлять данные для этих программ с помощью файла.
Для каждой из демонстраций ниже будет использоваться следующий файл в качестве примера. Этот файл примера содержит список содержимого, чтобы немного облегчить понимание примеров. Кроме того, файл фактически указан как путь, и поэтому вы можете использовать абсолютные и относительные пути, а также подстановочные знаки.
head
Head — это программа, которая печатает первые строки ввода. По умолчанию он напечатает первые 10 строк, но мы можем изменить это с помощью аргумента командной строки.
head [-количество строк для печати] [путь]

tail
Данная команда противоположна head. Tail — это команда, которая печатает последние строки ввода. По умолчанию он напечатает последние 10 строк, но мы можем изменить это с помощью аргумента командной строки.
tail [-количество строк для печати] [путь]

Выше было поведение tail по умолчанию. А ниже указывается заданное количество строк.
sort
Сортировка — это красиво и просто. По умолчанию сортировка выполняется в алфавитном порядке. Между тем, существует множество параметров, позволяющих изменить механизм сортировки. Кроме того, не забудьте проверить справочную страницу, чтобы увидеть все, что он может сделать.
sort [-options] [path]

nl
Обозначение чисел в Linux реализуется за счет команды nl.
nl [-options] [путь]

Вот еще несколько полезных опций командной строки.

В приведенном выше примере мы использовали 2 параметра командной строки. Первый -s указывает, что следует печатать после числа. С другой стороны, второй -w указывает, сколько отступов ставить перед числами. Для первого нам нужно было включить пробел как часть того, что было напечатано.
Поскольку пробелы обычно используются в качестве символов-разделителей в командной строке, нам нужен был способ указать, что пробел является частью нашего аргумента, а не просто между аргументами. Мы сделали это, включив аргумент в кавычки.
wc
wc обозначает количество слов, а также символы и строки. По умолчанию он подсчитывает все вышеперечисленное. Между тем, используя параметры командной строки, мы можем ограничить его только тем, что нам нужно.
wc [-options] [путь]

Иногда вам просто нужно одно из этих значений. -l даст нам только строки, -w даст нам слова, а -m даст нам символы.

Кроме того, Вы можете комбинировать аргументы командной строки.

cut
Cut — это хорошая команда, которую можно использовать, если ваш контент разделен на столбцы и вам нужны только определенные поля.
вырезать [-опции] [путь]
В нашем примере файла у нас есть данные в 3 столбцах. Допустим, мы хотели только первый столбец.

По умолчанию cut использует символ TAB в качестве разделителя для идентификации полей. Опция -f позволяет нам указать, какое поле мы бы хотели. Если нам нужно 2 или более полей, мы разделяем их запятой, как показано ниже.
sed
Sed расшифровывается как Stream Editor и позволяет эффективно выполнять поиск и замену наших данных. Это довольно мощная команда, но мы будем использовать ее здесь в ее базовом формате.
Инициал s обозначает замену и определяет действие, которое нужно выполнить. Между первой и второй косой чертой (/) мы размещаем то, что ищем. Затем между вторым и третьим слэшем, чем мы хотим его заменить.

uniq
Uniq означает уникальный, и его работа заключается в удалении повторяющихся строк из данных. Однако одно ограничение заключается в том, что эти линии должны быть смежными.
uniq [опции] [путь]

tac
Ребята из Linux известны своим забавным чувством юмора. Программа TAC на самом деле является CAT наоборот. Это было названо так, как это делает противоположность CAT. Получив данные, он напечатает последнюю строку первой, вплоть до первой строки.

Вывод
В данной статье мы ознакомились со следующими командами:
- head — просмотр первых n строк данных.
- tail — просмотр последних n строк данных.
- sort — организуйте данные в порядке.
- nl — напечатайте номера строк перед данными.
- wc — распечатать количество строк, слов и символов.
- cut — разрезать данные на поля и отображать только указанные поля.
- sed — сделайте поиск и замените данные.
- uniq — удалить дубликаты строк.
- tac — распечатайте данные в обратном порядке.
Источник
Unix / Linux — Pipes and Filters
In this chapter, we will discuss in detail about pipes and filters in Unix. You can connect two commands together so that the output from one program becomes the input of the next program. Two or more commands connected in this way form a pipe.
To make a pipe, put a vertical bar (|) on the command line between two commands.
When a program takes its input from another program, it performs some operation on that input, and writes the result to the standard output. It is referred to as a filter.
The grep Command
The grep command searches a file or files for lines that have a certain pattern. The syntax is −
The name «grep» comes from the ed (a Unix line editor) command g/re/p which means “globally search for a regular expression and print all lines containing it”.
A regular expression is either some plain text (a word, for example) and/or special characters used for pattern matching.
The simplest use of grep is to look for a pattern consisting of a single word. It can be used in a pipe so that only those lines of the input files containing a given string are sent to the standard output. If you don’t give grep a filename to read, it reads its standard input; that’s the way all filter programs work −
There are various options which you can use along with the grep command −
| Sr.No. | Option & Description | ||
|---|---|---|---|
| 1 |
| Sr.No. | Description |
|---|---|
| 1 |



