- Regular Expressions in Linux Explained with Examples
- Basic Regular Expressions
- ^ Regular Expression
- $ Regular Expression
- * Regular Expression
- . Regular Expression
- [] Square braces/Brackets Regular Expression
- [^char] Regular Expression
- Regular expression
- Escape Regular Expression
- Regex basics
- Robin Winslow
- What is a regular expression (or regex)?
- When to use regex
- Avoid coding in regex if you can
- When to code in regex
- Other great uses for regex
- How to use regex
- What regex looks like
- Common regex characters
- Character shortcuts in regex
- Regex in conditionals
- Regex in substitutions
- Regex modifiers
- Lookahead and lookbehind in regex
- Regex resources
- Talk to us today
- Регулярные выражения Linux
- Регулярные выражения Linux
- Примеры использования регулярных выражений
- Выводы
Regular Expressions in Linux Explained with Examples
Regular expressions (Regexp) is one of the advanced concept we require to write efficient shell scripts and for effective system administration. Basically regular expressions are divided in to 3 types for better understanding.
1)Basic Regular expressions
2)Interval Regular expressions (Use option -E for grep and -r for sed)
3)Extended Regular expressions (Use option -E for grep and -r for sed)
Some FAQ’s before starting Regular expressions
What is a Regular expression?
A regular expression is a concept of matching a pattern in a given string.
Which commands/programming languages support regular expressions?
vi, tr, rename, grep, sed, awk, perl, python etc.
Basic Regular Expressions
Basic regular expressions: This set includes very basic set of regular expressions which do not require any options to execute. This set of regular expressions are developed long time back.
^ –Caret/Power symbol to match a starting at the beginning of line.
$ –To match end of the line
* –0 or more occurrence of the previous character.
. –To match any character
[] –Range of character
[^char] –negate of occurrence of a character set
–Actual word finding
–Escape character
Lets start with our Regexp with examples, so that we can understand it better.
^ Regular Expression
Example 1: Find all the files in a given directory
ls -l | grep ^-
As you are aware that the first character in ls -l output, – is for regular files and d for directories in a given folder. Let us see what ^- indicates. The ^ symbol is for matching line starting, ^- indicates what ever lines starts with -, just display them. Which indicates a regular file in Linux/Unix.
If we want to find all the directories in a folder use grep ^d option along ls -l as shown below
ls -l | grep ^d
How about character files and block files?
ls -l | grep ^c
ls -l | grep ^b
We can even find the lines which are commented using ^ operator with below example
grep ‘^#’ filename
How about finding lines in a file which starts with ‘abc’
grep ‘^abc’ filename
We can have number of examples with this ^ option.
$ Regular Expression
Example 2: Match all the files which ends with sh
ls -l | grep sh$
As $ indicates end of the line, the above command will list all the files whose names end with sh.
how about finding lines in a file which ends with dead
grep ‘dead$’ filename
How about finding empty lines in a file?
grep ‘^$’ filename
* Regular Expression
Example 3: Match all files which have a word twt, twet, tweet etc in the file name.
ls -l | grep ‘twe*t’
How about searching for apple word which was spelled wrong in a given file where apple is misspelled as ale, aple, appple, apppple, apppppple etc. To find all patterns
grep ‘ap*le’ filename
Readers should observe that the above pattern will match even ale word as * indicates 0 or more of the previous character occurrence.
. Regular Expression
Example 4: Filter a file which contains any single character between t and t in a file name.
ls -l | grep ‘t.t’
Here . will match any single character. It can match tat, t3t, t.t, t&t etc any single character between t and t letters.
How about finding all the file names which starts with a and end with x using regular expressions?
ls -l | grep ‘a.*x’
The above .* indicates any number of characters
Note: .* in this combination . indicates any character and it repeated(*) 0 or more number of times.
Suppose you have files as..
awx
awex
aweex
awasdfx
a35dfetrx
etc.. it will find all the files/folders which start with a and ends with x in our example.
[] Square braces/Brackets Regular Expression
Example 5: Find all the files which contains a number in the file name between a and x
ls -l | grep ‘a2x’
This will find all the files which is
a0x sdf
asd a1x sdfas
..
..
asdfdsar a9x sdf
etc.
So where ever it finds a number it will try to match that number.
Some of the range operator examples for you.
[a-z] –Match’s any single char between a to z.
[A-Z] –Match’s any single char between A to Z.
4 –Match’s any single char between 0 to 9.
[a-zA-Z0-9] – Match’s any single character either a to z or A to Z or 0 to 9
[!@#$%^] — Match’s any ! or @ or # or $ or % or ^ character.
You just have to think what you want match and keep those character in the braces/Brackets.
[^char] Regular Expression
Example6: Match all the file names except a or b or c in it’s filenames
ls | grep ‘[^abc]’
This will give output all the file names except files which contain a or b or c.
Regular expression
Example7: Search for a word abc, for example I should not get abcxyz or readabc in my output.
Escape Regular Expression
Example 8: Find files which contain [ in it’s name, as [ is a special charter we have to escape it
grep «[» filename
or
grep ‘[[]’ filename
Note: If you observe [] is used to negate the meaning of [ regular expressions, so if you want to find any specail char keep them in [] so that it will not be treated as special char.
Note: No need to use -E to use these regular expressions with grep. We have egrep and fgrep which are equal to “grep -E”. I suggest you just concentrate on grep to complete your work, don’t go for other commands if grep is there to resolve your issues. Stay tuned to our next post on Regular expressions .
Источник
Regex basics
Robin Winslow
on 18 February 2021
In my team we run “masterclasses” every couple of weeks, where someone in the team presents a topic to the rest of the team.
This article is basically the content of the class on regular expressions (otherwise known as regex) I gave recently.
It’s an introduction to the basics of regular expressions. There are many like it, but this is mine.
What is a regular expression (or regex)?
Wikipedia defines regular expressions as:
“a sequence of characters that define a search pattern”
They are available in basically every programming language, and you’ll probably most commonly encounter them used for string matches in conditionals that are too complicated for simple logical comparisons (like “or”, “and”, “in”).
A couple of examples of regular expressions to get started:
]
(ASCII characters fall between space and “
”)
When to use regex
Use regular expressions with caution. The complexity of regex carries a cost.
Avoid coding in regex if you can
‘Some people, when confronted with a problem, think “I know, I’ll use regular expressions.” Now they have two problems.’ – Jamie Zawinski
In programming, only use regular expressions as a last resort. Don’t solve important problems with regex.
- regex is expensive – regex is often the most CPU-intensive part of a program. And a non-matching regex can be even more expensive to check than a matching one.
- regex is greedy – It’s extremely easy to match much more than intended, leading to bugs. We have multiple times had problems with regexes being too greedy, causing issues in our sites.
- regex is opaque – Even people who know regex well will take a while to pick apart a new regex string, and are still likely to make mistakes. This has a huge cost to project maintenance in the long run. (Check out this amazing regex for RFC822 email addresses)
Always try to be aware of all the language features at your disposal for operating on and checking strings, that could help you avoid regular expressions. In Python, for example, the in keyword, the powerful [] indexing, and string methods like contains and startswith (which can be fed either strings of tuples for multiple values) can be combined very effectively.
Most importantly, regexes should not be used for parsing strings. You should instead use or write a bespoke parser. For example, you can’t parse HTML with regex (in Python, use BeautifulSoup; in JavaScript, use the DOM).
When to code in regex
Of course, there are times when regular expressions can or should be used in programs:
- When it already exist and you have to maintain it (although if you can remove it, you should)
- String validation, where there’s no other option
- String manipulation (substitution), where there’s no other option
If you are writing anything more than the most basic regex, any maintainers are unlikely to be able to understand your regex easily, so you might want to consider adding liberal comments. E.g. this in Python:
Other great uses for regex
Regular expressions can be extremely powerful for quickly solving problems for yourself, where future maintenance is not a concern. E.g.:
- Grep (or Ripgrep), Sed, Less and other command line tools
- In editors (e.g. VSCode), for quickly reformatting text
It’s also worth taking advantage of opportunities to use regex in these ways to practice your regex skills.
For example, I recently used the following regex substitution in VSCode to format a dump of text into a table format:
How to use regex
Bear in mind that regular expressions parsers come in a few varieties. Basically, every language implements its own parser. However, Perl’s regex parser is the gold standard. If you have a choice, use Perl Compatible Regular Expressions.
What regex looks like
The traditional way to write a regular expression is by surrounding it with slashes.
This is how they’re written in Perl and JavaScript, and in many command-line tools like Less.
Many more modern languages (e.g. Python), however, have opted not to include a native regex type, and so regular expressions are simply written as strings:
Common regex characters
| . | Matches any single character (except newlines, normally) |
| \ | Escape a special character (e.g. \. matches a literal dot) |
| ? | The preceding character may or may not be present (e.g. /hell?o/ would match hello or helo ) |
| * | Any number of the preceding character is allowed (e.g. .* will match any single-line string, including an empty string, and gets used a lot) |
| + | One or more of the preceding character ( .+ is the same as .* except that it won’t match an empty string) |
| | | “or”, match the preceding section or the following section (e.g. hello|mad will match “hello” or “mad”) |
| () | group a section together. This can be useful for conditionals ( (a|b) ), multipliers ( (hello)+ ), or to create groups for substitutions (see below) |
| <> | Specify how many of the preceding character (e.g. a <12>matches 12 “a”s in a row) |
| [] | Match any character in this set. — defines ranges (e.g. [a-z] is any lowercase letter), ^ means “not” (e.g. [^,]+ match any number of non-commas in a row) |
| ^ | Beginning of line |
| $ | End of line |
Character shortcuts in regex
In most regex implementations, you can use backslash followed by a letter ( \x ) as a shortcut for a character set. Here’s a list of some common ones from rexegg.com’s regex cheat sheet.
Regex in conditionals
The simplest use-case for regexes in programming is a string comparison. This looks different in different languages, e.g.:
Regex in substitutions
You can also use regex to manipulate strings through substitution. In the following examples, “mad world” will be printed out:
Regex modifiers
You can alter how regular expressions behave based on a few modifiers. I’m just going to illustrate one here, which is the modifier to make regex case insensitive. In Perl, JavaScript and other more traditional regex contexts, the modifiers are added after the last / . More modern languages often user constants instead:
Lookahead and lookbehind in regex
These are only supported in some implementations of regular expressions, and give you the opportunity to match strings that precede or follow other strings, but without including the prefix or suffix in the match itself:
Regex resources
That is all I have for now. If you want to learn more, there’s are a lot of useful resources out there:
- Rexegg.com – Many great articles on most aspects of regex
- Regex101 – A tester for your regex, offering a few different implementations
- iHateRegex – A collection of example regex patterns for matching some common types of strings (e.g. phone number, email address)
- The official Perl Compatible Regular Expressions documentation
Talk to us today
Interested in running Ubuntu in your organisation?
Источник
Регулярные выражения Linux
Регулярные выражения — это очень мощный инструмент для поиска текста по шаблону, обработки и изменения строк, который можно применять для решения множества задач. Вот основные из них:
- Проверка ввода текста;
- Поиск и замена текста в файле;
- Пакетное переименование файлов;
- Взаимодействие с сервисами, таким как Apache;
- Проверка строки на соответствие шаблону.
Это далеко не полный список, регулярные выражения позволяют делать намного больше. Но для новых пользователей они могут показаться слишком сложными, поскольку для их формирования используется специальный язык. Но учитывая предоставляемые возможности, регулярные выражения Linux должен знать и уметь использовать каждый системный администратор.
В этой статье мы рассмотрим регулярные выражения bash для начинающих, чтобы вы смогли разобраться со всеми возможностями этого инструмента.
Регулярные выражения Linux
В регулярных выражениях могут использоваться два типа символов:
Обычные символы — это буквы, цифры и знаки препинания, из которых состоят любые строки. Все тексты состоят из букв и вы можете использовать их в регулярных выражениях для поиска нужной позиции в тексте.
Метасимволы — это кое-что другое, именно они дают силу регулярным выражениям. С помощью метасимволов вы можете сделать намного больше чем поиск одного символа. Вы можете искать комбинации символов, использовать динамическое их количество и выбирать диапазоны. Все спецсимволы можно разделить на два типа, это символы замены, которые заменяют собой обычные символы, или операторы, которые указывают сколько раз может повторяться символ. Синтаксис регулярного выражения будет выглядеть таким образом:
обычный_символ спецсимвол_оператор
спецсимвол_замены спецсимвол_оператор
Если оператор не указать, то будет считаться, что символ обязательно должен встретится в строке один раз. Таких конструкций может быть много. Вот основные метасимволы, которые используют регулярные выражения bash:
- \ — с обратной косой черты начинаются буквенные спецсимволы, а также он используется если нужно использовать спецсимвол в виде какого-либо знака препинания;
- ^ — указывает на начало строки;
- $ — указывает на конец строки;
- * — указывает, что предыдущий символ может повторяться 0 или больше раз;
- + — указывает, что предыдущий символ должен повторится больше один или больше раз;
- ? — предыдущий символ может встречаться ноль или один раз;
- — указывает сколько раз (n) нужно повторить предыдущий символ;
- — предыдущий символ может повторяться от N до n раз;
- . — любой символ кроме перевода строки;
- [az] — любой символ, указанный в скобках;
- х|у — символ x или символ y;
- [^az] — любой символ, кроме тех, что указаны в скобках;
- [a-z] — любой символ из указанного диапазона;
- [^a-z] — любой символ, которого нет в диапазоне;
- \b — обозначает границу слова с пробелом;
- \B — обозначает что символ должен быть внутри слова, например, ux совпадет с uxb или tuxedo, но не совпадет с Linux;
- \d — означает, что символ — цифра;
- \D — нецифровой символ;
- \n — символ перевода строки;
- \s — один из символов пробела, пробел, табуляция и так далее;
- \S — любой символ кроме пробела;
- \t — символ табуляции;
- \v — символ вертикальной табуляции;
- \w — любой буквенный символ, включая подчеркивание;
- \W — любой буквенный символ, кроме подчеркивания;
- \uXXX — символ Unicdoe.
Важно отметить, что перед буквенными спецсимволами нужно использовать косую черту, чтобы указать, что дальше идет спецсимвол. Правильно и обратное, если вы хотите использовать спецсимвол, который применяется без косой черты в качестве обычного символа, то вам придется добавить косую черту.
Например, вы хотите найти в тексте строку 1+ 2=3. Если вы используете эту строку в качестве регулярного выражения, то ничего не найдете, потому что система интерпретирует плюс как спецсимвол, который сообщает, что предыдущая единица должна повториться один или больше раз. Поэтому его нужно экранировать: 1 \+ 2 = 3. Без экранирования наше регулярное выражение соответствовало бы только строке 11=3 или 111=3 и так далее. Перед равно черту ставить не нужно, потому что это не спецсимвол.
Примеры использования регулярных выражений
Теперь, когда мы рассмотрели основы и вы знаете как все работает, осталось закрепить полученные знания про регулярные выражения linux grep на практике. Два очень полезные спецсимвола — это ^ и $, которые обозначают начало и конец строки. Например, мы хотим получить всех пользователей, зарегистрированных в нашей системе, имя которых начинается на s. Тогда можно применить регулярное выражение «^s». Вы можете использовать команду egrep:
egrep «^s» /etc/passwd
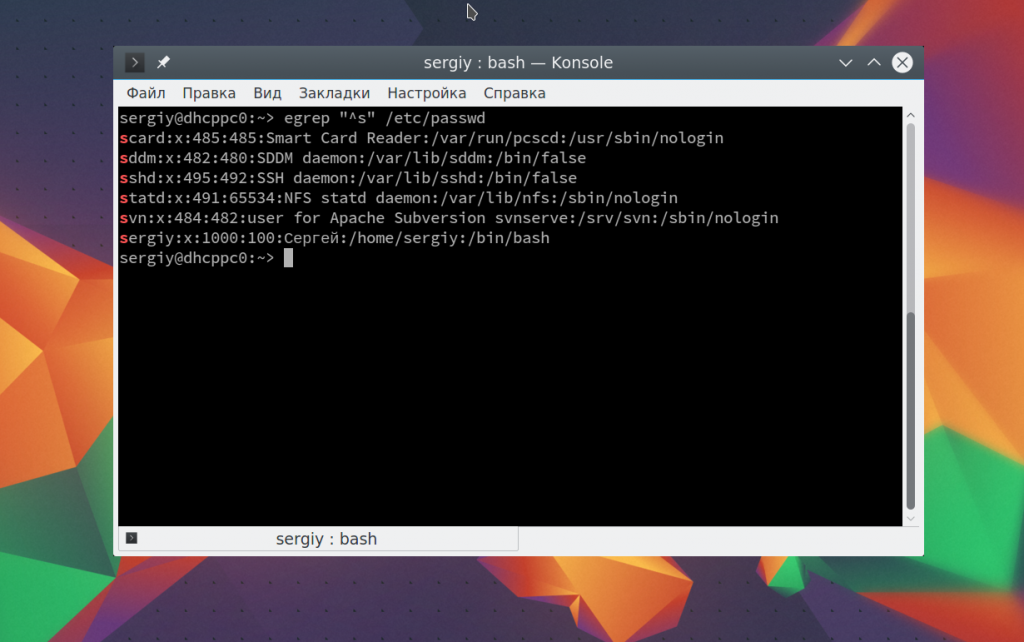
Если мы хотим отбирать строки по последнему символу в строке, что для этого можно использовать $. Например, выберем всех системных пользователей, без оболочки, записи о таких пользователях заканчиваются на false:
egrep «false$» /etc/passwd
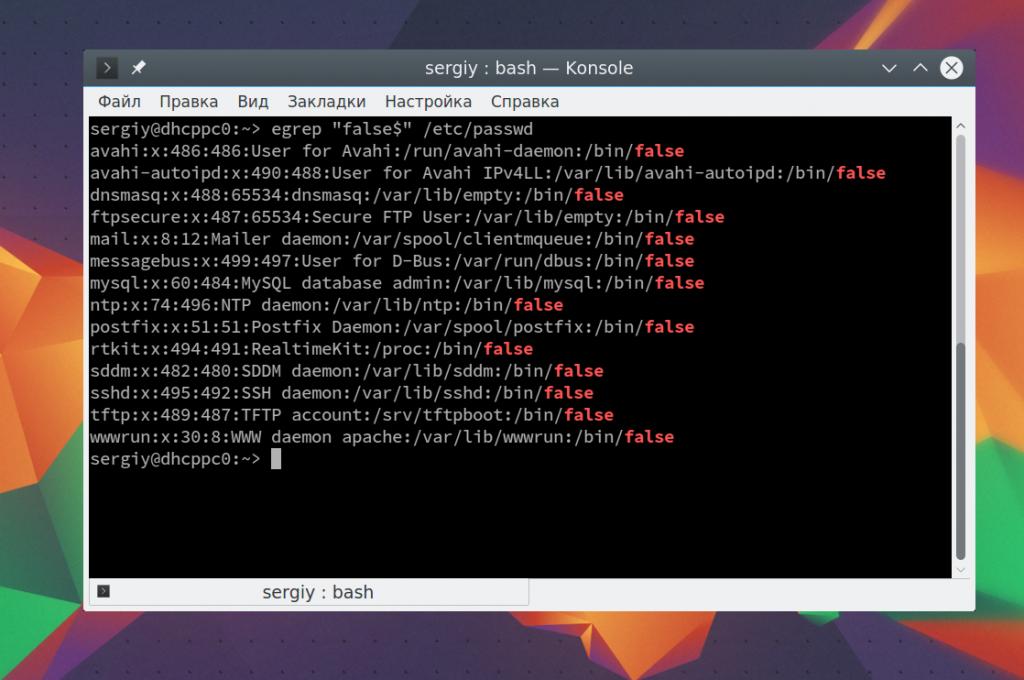
Чтобы вывести имена пользователей, которые начинаются на s или d используйте такое выражение:
egrep «^[sd]» /etc/passwd
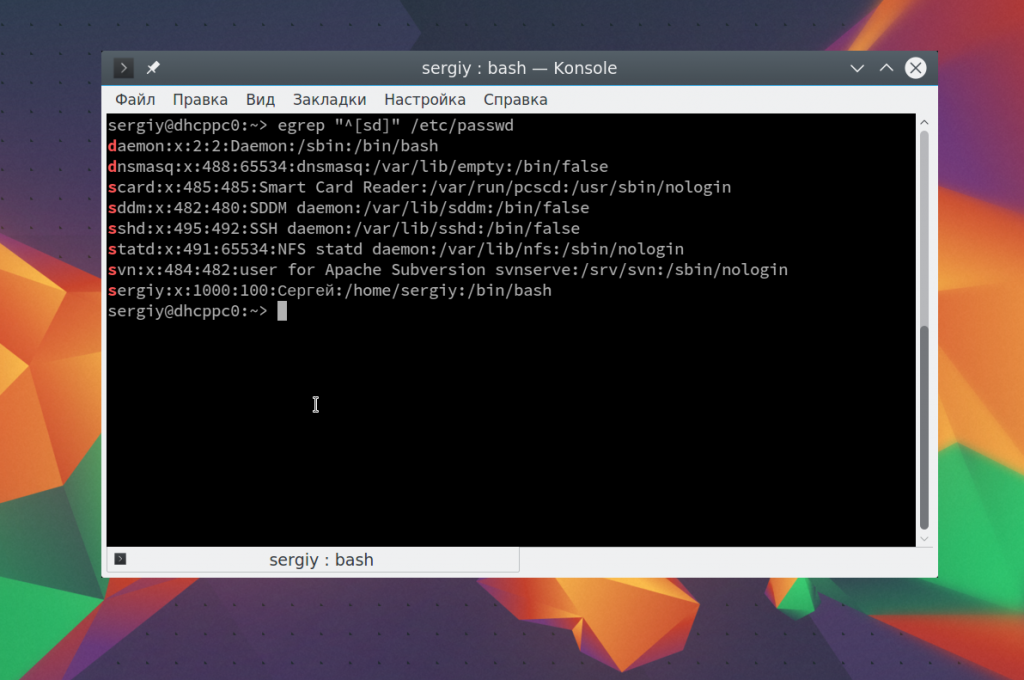 Такой же результат можно получить, использовав символ «|». Первый вариант более пригоден для диапазонов, а второй чаще применяется для обычных или/или:
Такой же результат можно получить, использовав символ «|». Первый вариант более пригоден для диапазонов, а второй чаще применяется для обычных или/или:
egrep «^[s|d]» /etc/passwd
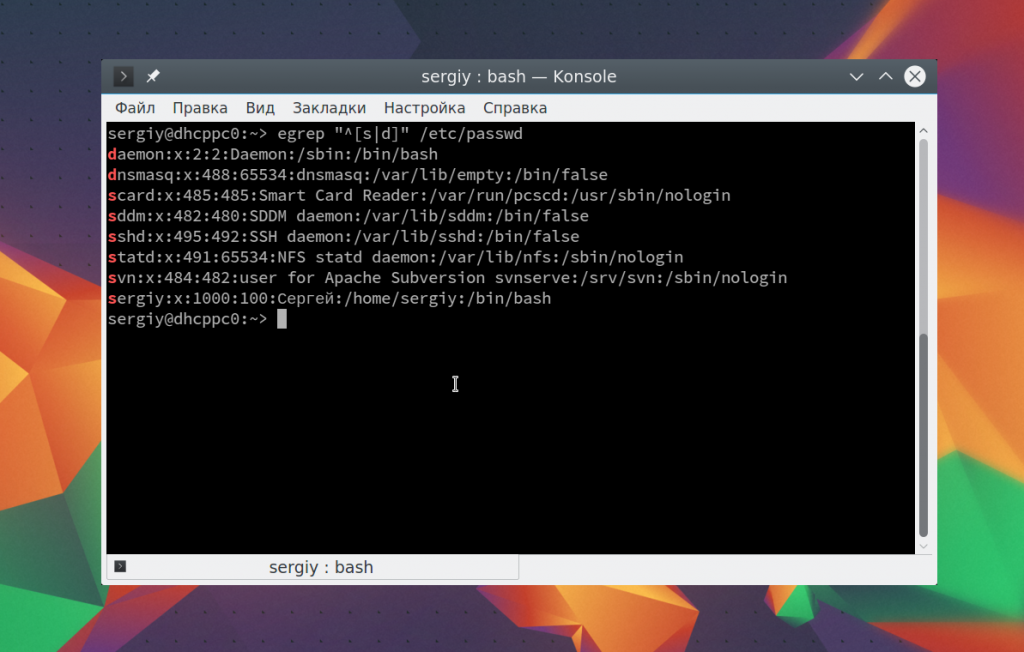
Теперь давайте выберем всех пользователей, длина имени которых составляет не три символа. Имя пользователя завершается двоеточием. Мы можем сказать, что оно может содержать любой буквенный символ, который должен быть повторен три раза, перед двоеточием:
egrep «^\w<3>:» /etc/passwd
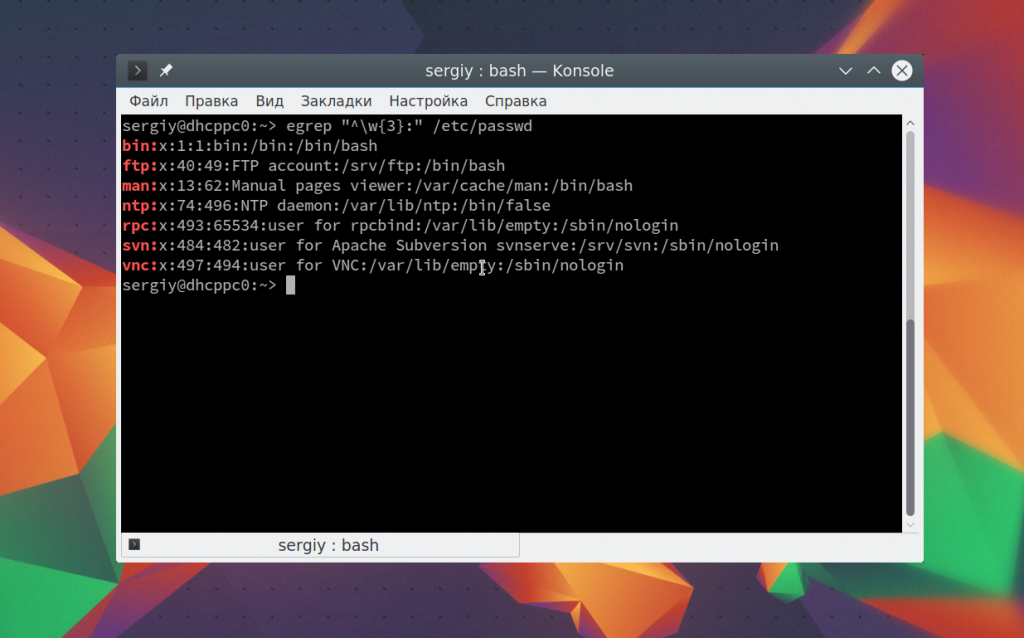
Выводы
В этой статье мы рассмотрели регулярные выражения Linux, но это были только самые основы. Если копнуть чуть глубже, вы найдете что с помощью этого инструмента можно делать намного больше интересных вещей. Время, потраченное на освоение регулярных выражений, однозначно будет стоить того.
На завершение лекция от Яндекса про регулярные выражения:
Источник



