- What is bcast in linux
- How To Linux Bcast
- What is my inet addr, Bcast, and Mask when I ‘ifconfig’ in
- What is a broadcast ip? — LinuxQuestions.org
- How Do I Change the Bcast Addr?? — openSUSE
- c — Using MPI_Bcast for MPI communication — Stack …
- networking — When are network, broadcast and gateway
- What is Bonding & How to Configure Bonding in Linux
- Bioinformatics: introduction to using BLAST with Ubuntu
- networking — Is «inet addr» my or «bcast» my machine’s
- Configuring virtual network interfaces in Linux — Linux
- SMB HOWTO: Accessing an SMB Share With Linux Machines
- Starting Your Linux Box Remotely. : 6 Steps — Instructables
- How To Cast Your GNOME Shell Desktop — Linux Uprising Blog
- How to Manually Set Your IP in Linux (including ip/netplan
- How to Make Channel Access Reach Multiple Soft IOCs on a
- 74. Watch TV on Your Computer — Linux Multimedia Hacks [Book]
- How To Change IP Address on Linux – devconnected
- Bash Shell Command to Find or Get IP address — nixCraft
- How to Find What Devices are Connected to Network in Linux
- Setup DHCP or static IP address from command line in Linux
- linux — show gateway IP address when performing ifconfig
- How to Find out the IP address assigned to eth0 and
- Configure Ethernet Connection Manually on Linux for USRP
- How to Cast Android Screen on Linux — TechWiser
- How to change link status of ethernet interface (U
- bCast Pricing, Alternatives & More 2021 — Capterra
- Quick Guide: How to Linux get ip address — UX Techno
- How to Set External Network For Containers in Linux
- How to Run Headless Linux on Amlogic S905 Devices Such as
- 13 Linux Network Configuration and Troubleshooting Commands
- How to find IP address on linux? — Linux Tutorials — Learn
- How to setup Icecast on Linux and make a Web Radio (Part 1
- Linux server tutorials: Ubuntu ifconfig static ip
- how to stop broadcast service in linux
- 1 Answer 1
- fbset(8) — Linux man page
- Synopsis
- Description
- Options
- Linux IP Networking A Guide to the Implementation and Modification of the Linux Protocol Stack
- Glenn Herrin
- May 31, 2000
- Contents
- Chapter 1 Introduction
- 1.1 Background
- 1.2 Document Conventions
- 1.3 Sample Network Example
- 1.4 Copyright, License, and Disclaimer
- 1.5 Acknowledgements
- Chapter 2 Message Traffic Overview
- 2.1 The Network Traffic Path
- 2.2 The Protocol Stack
- 2.3 Packet Structure
- 2.4 Internet Routing
- Chapter 3 Network Initialization
- 3.1 Overview
- 3.2 Startup
- 3.2.1 The Network Initialization Script
- 3.2.2 ifconfig
- 3.2.3 route
- 3.2.4 Dynamic Routing Programs
- 3.3 Examples
- 3.3.1 Home Computer
- 3.3.2 Host Computer on a LAN
- 3.3.3 Network Routing Computer
- 3.4 Linux and Network Program Functions
- 3.4.1 ifconfig
- 3.4.2 route
- Chapter 4 Connections
- 4.1 Overview
- 4.2 Socket Structures
- 4.3 Sockets and Routing
- 4.4 Connection Processes
- 4.4.1 Establishing Connections
- 4.4.2 Socket Call Walk-Through
- 4.4.3 Connect Call Walk-Through
- 4.4.4 Closing Connections
- 4.4.5 Close Walk-Through
- 4.5 Linux Functions
- Chapter 5 Sending Messages
- 5.1 Overview
- 5.2 Sending Walk-Through
- 5.2.1 Writing to a Socket
- 5.2.2 Creating a Packet with UDP
- 5.2.3 Creating a Packet with TCP
- 5.2.4 Wrapping a Packet in IP
- 5.2.5 Transmitting a Packet
- 5.3 Linux Functions
- Chapter 6 Receiving Messages
- 6.1 Overview
- 6.2 Receiving Walk-Through
- 6.2.1 Reading from a Socket (Part I)
- 6.2.2 Receiving a Packet
- 6.2.3 Running the Network «Bottom Half»
- 6.2.4 Unwrapping a Packet in IP
- 6.2.5 Accepting a Packet in UDP
- 6.2.6 Accepting a Packet in TCP
- 6.2.7 Reading from a Socket (Part II)
- 6.3 Linux Functions
- Chapter 7 IP Forwarding
- 7.1 Overview
- 7.2 IP Forward Walk-Through
- 7.2.1 Receiving a Packet
- 7.2.2 Running the Network «Bottom Half»
- 7.2.3 Examining a Packet in IP
- 7.2.4 Forwarding a Packet in IP
- 7.2.5 Transmitting a Packet
- 7.3 Linux Functions
- Chapter 8 Basic Internet Protocol Routing
- 8.1 Overview
- 8.2 Routing Tables
- 8.2.1 The Neighbor Table
- 8.2.2 The Forwarding Information Base
- 8.2.3 The Routing Cache
- 8.2.4 Updating Routing Information
- 8.3 Linux Functions
- Chapter 9 Dynamic Routing with routed
- 9.1 Overview
- 9.2 How routed Works
- 9.2.1 Data Structures
- 9.2.2 Initialization
- 9.2.3 Normal Operations
- 9.3 routed Functions
- Chapter 10 Editing Linux Source Code
- 10.1 The Linux Source Tree
- 10.2 Using EMACS Tags
- 10.2.1 Referencing with TAGS
- 10.2.2 Constructing TAGS files
- 10.3 Using vi tags
- 10.4 Rebuilding the Kernel
- 10.5 Patching the Kernel Source
- 12.3 Registering proc Files
- 12.3.1 Formatting a Function to Provide Information
- 12.3.2 Building a proc Entry
- 12.3.3 Registering a proc Entry
- 12.3.4 Unregistering a proc Entry
- 12.4 Example
- Chapter 13 Example - Packet Dropper
- 13.1 Overview
- 13.2 Considerations
- 13.3 Experimental Systems and Benchmarks
What is bcast in linux
Синтаксис функции широковещательной посылки данных MPI_BCAST приводится ниже.
MPI_BCAST(buffer, count, datatype, root, comm)
| INOUT | buffer | адрес начала буфера (альтернатива) |
| IN | count | количество записей в буфере (целое) |
| IN | datatype | тип данных в буфере (дескриптор) |
| IN | root | номер корневого процесса (целое) |
| IN | comm | коммуникатор (дескриптор) |
int MPI_Bcast(void* buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm)
MPI_BCAST(BUFFER, COUNT, DATATYPE, ROOT, COMM, IERROR)
BUFFER(*)
INTEGER COUNT, DATATYPE, ROOT, COMM, IERROR
void MPI::Intracomm::Bcast(void* buffer, int count,
const Datatype& datatype, int root) const
Функция широковещательной передачи MPI_BCAST посылает сообщение из корневого процесса всем процессам группы, включая себя. Она вызывается всеми процессами группы с одинаковыми аргументами для comm и root . В момент возврата управления содержимое корневого буфера обмена будет уже скопировано во все процессы.
В аргументе datatype можно задавать производные типы данных. Сигнатура типа данных count, datatype любого процесса обязана совпадать с соответствующей сигнатурой в корневом процессе. Необходимо, чтобы количество посланных и полученных данных совпадало попарно для корневого и каждого другого процессов. Такое ограничение имеют и все остальные коллективные операции, выполняющие перемещение данных. Однако по-прежнему разрешается различие в картах типов данных между отправителями и получателями.
Источник
How To Linux Bcast
What is my inet addr, Bcast, and Mask when I ‘ifconfig’ in
› Verified 2 days ago
What is a broadcast ip? — LinuxQuestions.org
› Verified 5 days ago
How Do I Change the Bcast Addr?? — openSUSE
netmask; 27-Aug-2008, 15:31 #5. what is my broadcast ip
› Verified Just Now
c — Using MPI_Bcast for MPI communication — Stack …
› Verified 1 days ago
networking — When are network, broadcast and gateway
› Verified 8 days ago
What is Bonding & How to Configure Bonding in Linux
› Verified 3 days ago
Bioinformatics: introduction to using BLAST with Ubuntu
› Verified 8 days ago
networking — Is «inet addr» my or «bcast» my machine’s
› Verified 7 days ago
Configuring virtual network interfaces in Linux — Linux
› Verified 1 days ago
SMB HOWTO: Accessing an SMB Share With Linux Machines
› Verified 9 days ago
Starting Your Linux Box Remotely. : 6 Steps — Instructables
› Verified 3 days ago
How To Cast Your GNOME Shell Desktop — Linux Uprising Blog
› Verified 2 days ago
How to Manually Set Your IP in Linux (including ip/netplan
› Verified 5 days ago
How to Make Channel Access Reach Multiple Soft IOCs on a
› Verified 2 days ago
74. Watch TV on Your Computer — Linux Multimedia Hacks [Book]
› Verified 3 days ago
How To Change IP Address on Linux – devconnected
› Verified 9 days ago
Bash Shell Command to Find or Get IP address — nixCraft
› Verified 2 days ago
How to Find What Devices are Connected to Network in Linux
› Verified Just Now
Setup DHCP or static IP address from command line in Linux
› Verified 9 days ago
linux — show gateway IP address when performing ifconfig
› Verified 3 days ago
How to Find out the IP address assigned to eth0 and
› Verified 8 days ago
Configure Ethernet Connection Manually on Linux for USRP
› Verified 7 days ago
How to Cast Android Screen on Linux — TechWiser
› Verified Just Now
How to change link status of ethernet interface (U
# ifconfig eth1 #SFP is inserted eth1 Link encap:Ethernet HWaddr 00:0A:35:00:00:01 inet
› Verified Just Now
bCast Pricing, Alternatives & More 2021 — Capterra
› Verified Just Now
Quick Guide: How to Linux get ip address — UX Techno
]# ip r l 192.168.48.0/22 dev eth0 proto kernel scope link src 192.168.49.180 default via 192.168.51.1 dev eth0 [[email protected]
› Verified 5 days ago
How to Set External Network For Containers in Linux
› Verified 6 days ago
How to Run Headless Linux on Amlogic S905 Devices Such as
› Verified 7 days ago
13 Linux Network Configuration and Troubleshooting Commands
› Verified 1 days ago
How to find IP address on linux? — Linux Tutorials — Learn
› Verified 5 days ago
How to setup Icecast on Linux and make a Web Radio (Part 1
› Verified 3 days ago
Linux server tutorials: Ubuntu ifconfig static ip
$ ifconfig eth0 192.168.1.3. [email protected]:
Источник
how to stop broadcast service in linux
I have a query: in our environment all Linux servers have broadcasting enabled
I need to stop the broadcast service in my Linux server.
I have tried to stop the service by doing the following:
- change the broadcast address 0.0.0.0 manually
- add the broadcast address 0.0.0.0 to /etc/sysconfig/network-scripts/ifcfg-eth0
But, still same result. Can any body tell me the procedure to close the broadcast service in Linux.
1 Answer 1
I don’t think you can do what you are trying to do. What exactly is the problem you are seeing, and why is it a problem ?
Broadcasting is not a service, its part of the IP stack, so there isn’t a way of stopping the service. You might be able to write an IPTables rule to fix whatever it is you are trying to fix, but there will almost certainly be colateral damage, probably killing your ability to network at all.
If you don’t want computers on the same network to see each other, maybe you need to assign each computer with an IP address which has a network comprising only itself and the router. This won’t stop any kind of attacks across the LAN, but might cut down on the traffic you are worried about.
Some examples (assuming 192.168.0.x subnet) ifconfig eth0 192.168.0.1 netmask 255.255.255.252 gateway 192.168.0.2 (This will use 192.168.0.0 as the network, 192.168.0.3 as the broadcast, so you will only be able to see the router, assuming you bring up an interface on the router of 192.168.0.2 with an otherwise similar command)
1 for each host with a corresponding interface/virtual interface on the core router.
Источник
fbset(8) — Linux man page
Synopsis
Description
fbset is a system utility to show or change the settings of the frame buffer device. The frame buffer device provides a simple and unique interface to access different kinds of graphic displays.
Frame buffer devices are accessed via special device nodes located in the /dev directory. The naming scheme for these nodes is always fb , where n is the number of the used frame buffer device.
fbset uses an own video mode database located in /etc/fb.modes. An unlimited number of video modes can be defined in this database. For further information see fb.modes(5).
Options
—help, -h display an usage information —now, -n change the video mode immediately. If no frame buffer device is given via -fb , then this option is activated by default —show, -s display the video mode settings. This is default if no further option or only a frame buffer device via -fb is given —info, -i display all available frame buffer information —verbose, -v display information what fbset is currently doing —version, -V display the version information about fbset —xfree86, -x display the timing information as it’s needed by XFree86
Frame buffer device nodes:
-fb device gives the frame buffer device node. If no device via -fb is given, /dev/fb0 is used
-xres set visible horizontal resolution (in pixels) -yres set visible vertical resolution (in pixels) -vxres set virtual horizontal resolution (in pixels) -vyres set virtual vertical resolution (in pixels) -depth set display depth (in bits per pixel) —geometry, -g . set all geometry parameters at once in the order , e.g. -g 640 400 640 400 4 -match make the physical resolution match the virtual resolution
-pixclock set the length of one pixel (in picoseconds). Note that the frame buffer device may only support some pixel lengths -left set left margin (in pixels) -right set right margin (in pixels) -upper set upper margin (in pixel lines) -lower set lower margin (in pixel lines) -hslen set horizontal sync length (in pixels) -vslen set vertical sync length (in pixel lines) —timings, -t . set all timing parameters at once in the order , e.g. -g 35242 64 96 35 12 112 2
-hsync <low|high> set the horizontal sync polarity -vsync <low|high> set the vertical sync polarity -csync <low|high> set the composite sync polarity -extsync <false|true> enable or disable external resync. If enabled the sync timings are not generated by the frame buffer device and must be provided externally instead. Note that this option may not be supported by every frame buffer device -bcast <false|true> enable or disable broadcast modes. If enabled the frame buffer generates the exact timings for several broadcast modes (e.g. PAL or NTSC). Note that this option may not be supported by every frame buffer device -laced <false|true> enable or disable interlace. If enabled the display will be split in two frames, each frame contains only even and odd lines respectively. These two frames will be displayed alternating, this way twice the lines can be displayed and the vertical frequency for the monitor stays the same, but the visible vertical frequency gets halved -double <false|true> enable or disable doublescan. If enabled every line will be displayed twice and this way the horizontal frequency can easily be doubled, so that the same resolution can be displayed on different monitors, even if the horizontal frequency specification differs. Note that this option may not be supported by every frame buffer device
-move <left|right|up|down> move the visible part of the display in the specified direction -step set step size for display positioning (in pixels or pixel lines), if -step is not given display will be moved 8 pixels horizontally or 2 pixel lines vertically
Источник
Linux IP Networking
A Guide to the Implementation and Modification of the Linux Protocol Stack
Glenn Herrin
May 31, 2000
This document is a guide to understanding how the Linux kernel (version 2.2.14 specifically) implements networking protocols, focused primarily on the Internet Protocol (IP). It is intended as a complete reference for experimenters with overviews, walk-throughs, source code explanations, and examples. The first part contains an in-depth examination of the code, data structures, and functionality involved with networking. There are chapters on initialization, connections and sockets, and receiving, transmitting, and forwarding packets. The second part contains detailed instructions for modifiying the kernel source code and installing new modules. There are chapters on kernel installation, modules, the proc file system, and a complete example.
Contents
Chapter 1
Introduction
1.1 Background
This document is an effort to bring together many of these sources into one coherent reference on and guide to modifying the networking code within the Linux kernel. It presents the internal workings on four levels: a general overview, more specific examinations of network activities, detailed function walk-throughs, and references to the actual code and data structures. It is designed to provide as much or as little detail as the reader desires. This guide was written specifically about the Linux 2.2.14 kernel (which has already been superseded by 2.2.15) and many of the examples come from the Red Hat 6.1 distribution; hopefully the information provided is general enough that it will still apply across distributions and new kernels. It also focuses almost exclusively on TCP/UDP, IP, and Ethernet — which are the most common but by no means the only networking protocols available for Linux platforms.
As a reference for kernel programmers, this document includes information and pointers on editing and recompiling the kernel, writing and installing modules, and working with the /proc file system. It also presents an example of a program that drops packets for a selected host, along with analysis of the results. Between the descriptions and the examples, this should answer most questions about how Linux performs networking operations and how you can modify it to suit your own purposes.
This project began in a Computer Science Department networking lab at the University of New Hampshire as an effort to institute changes in the Linux kernel to experiment with different routing algorithms. It quickly became apparent that blindly hacking the kernel was not a good idea, so this document was born as a research record and a reference for future programmers. Finally it became large enough (and hopefully useful enough) that we decided to generalize it, formalize it, and release it for public consumption.
As a final note, Linux is an ever-changing system and truly mastering it, if such a thing is even possible, would take far more time than has been spent putting this reference together. If you notice any misstatements, omissions, glaring errors, or even typos (!) within this document, please contact the person who is currently maintaining it. The goal of this project has been to create a freely available and useful reference for Linux programmers.
1.2 Document Conventions
Almost all of the code presented requires superuser access to implement. Some of the examples can create security holes where none previously existed; programmers should be careful to restore their systems to a normal state after experimenting with the kernel.
File references and program names are written in a slanted font.
Code, command line entries, and machine names are written in a typewriter font.
Generic entries or variables (such as an output filename) and comments are written in an italic font.
1.3 Sample Network Example
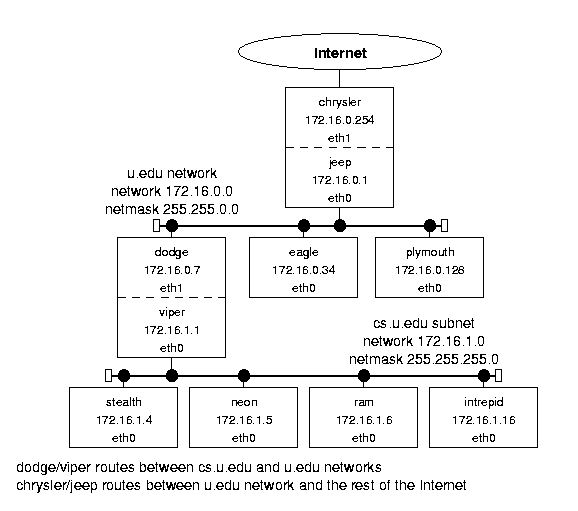
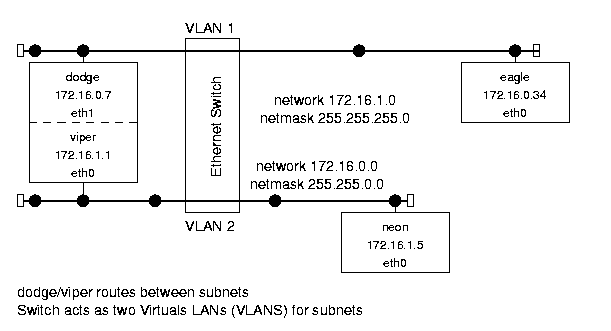
Figure 1.1: Sample network structure.
This network represents the computer system at a fictional unnamed University (U!). It has a router connected to the Internet at large (chrysler). That machine is connected (through the jeep interface) to the campus-wide network, u.edu, consisting of computers named for Chrysler owned car companies (dodge, eagle, etc.). There is also a LAN subnet for the computer science department, cs.u.edu, whose hosts are named after Dodge vehicle models (stealth, neon, etc.). They are connected to the campus network by the dodge/viper computer. Both the u.edu and cs.u.edu networks use Ethernet hardware and protocols.
This is obviously not a real network. The IP addresses are all taken from the block reserved for class B private networks (that are not guaranteed to be unique). Most real class B networks would have many more computers, and a network with only eight computers would probably not have a subnet. The connection to the Internet (through chrysler) would usually be via a T1 or T3 line, and that router would probably be a «real» router (i.e. a Cisco Systems hardware router) rather than a computer with two network cards. However, this example is realistic enough to serve its purpose: to illustrate the the Linux network implementation and the interactions between hosts, subnets, and networks.
1.4 Copyright, License, and Disclaimer
Copyright (c) 2000 by Glenn Herrin. This document may be freely reproduced in whole or in part provided credit is given to the author with a line similar to the following:
Please note any modifications including deletions.
This is a variation (changes are intentional) of the Linux Documentaion Project (LDP) License available at:
This document is distributed in the hope that it will be useful but (of course)without any given or implied warranty of fitness for any purpose whatsoever. Use it at your own risk.
1.5 Acknowledgements
Glenn Herrin
Major, United States Army
Primary Documenter and Researcher, Version 1.0
gherrin@cs.unh.edu
Chapter 2
Message Traffic Overview
This chapter presents an overview of the entire Linux messaging system. It provides a discussion of configurations, introduces the data structures involved, and describes the basics of IP routing.
2.1 The Network Traffic Path
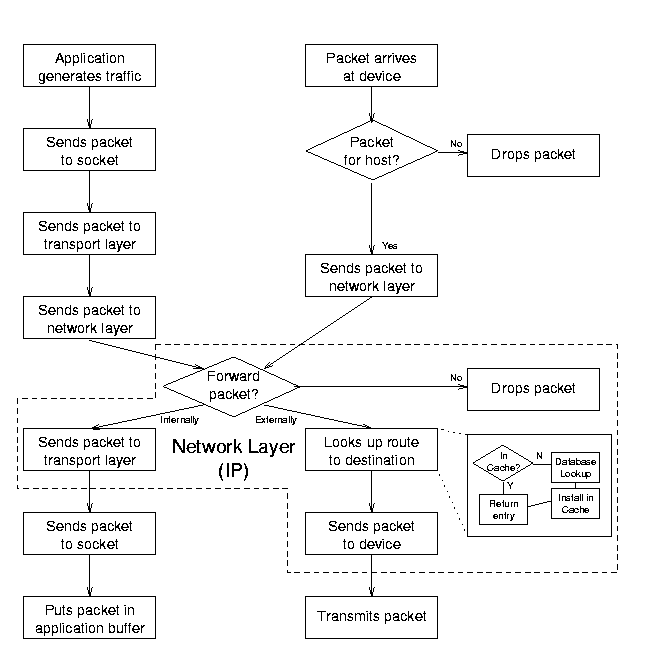
Figure 2.1: Abstraction of the Linux message traffic path.
When an application generates traffic, it sends packets through sockets to a transport layer (TCP or UDP) and then on to the network layer (IP). In the IP layer, the kernel looks up the route to the host in either the routing cache or its Forwarding Information Base (FIB). If the packet is for another computer, the kernel addresses it and then sends it to a link layer output interface (typically an Ethernet device) which ultimately sends the packet out over the physical medium.
When a packet arrives over the medium, the input interface receives it and checks to see if the packet is indeed for the host computer. If so, it sends the packet up to the IP layer, which looks up the route to the packet’s destination. If the packet has to be forwarded to another computer, the IP layer sends it back down to an output interface. If the packet is for an application, it sends it up through the transport layer and sockets for the application to read when it is ready.
Along the way, each socket and protocol performs various checks and formatting functions, detailed in later chapters. The entire process is implemented with references and jump tables that isolate each protocol, most of which are set up during initialization when the computer boots. See Chapter 3 for details of the initialization process.
2.2 The Protocol Stack
IP is the standard network layer protocol. It checks incoming packets to see if they are for the host computer or if they need to be forwarded. It defragments packets if necessary and delivers them to the transport protocols. It maintains a database of routes for outgoing packets; it addresses and fragments them if necessary before sending them down to the link layer.
TCP and UDP are the most common transport layer protocols. UDP simply provides a framework for addressing packets to ports within a computer, while TCP allows more complex connection based operations, including recovery mechanisms for packet loss and traffic management implementations. Either one copies the packet’s payload between user and kernel space. However, both are just part of the intermediate layer between the applications and the network.
IP Specific INET Sockets are the data elements and implementations of generic sockets. They have associated queues and code that executes socket operations such as reading, writing, and making connections. They act as the intermediary between an application’s generic socket and the transport layer protocol.
Generic BSD Sockets are more abstract structures that contain INET sockets. Applications read from and write to BSD sockets; the BSD sockets translate the operations into INET socket operations. See Chapter 4 for more on sockets.
Applications, run in user space, form the top level of the protocol stack; they can be as simple as two-way chat connection or as complex as the Routing Information Protocol (RIP — see Chapter 9).
2.3 Packet Structure
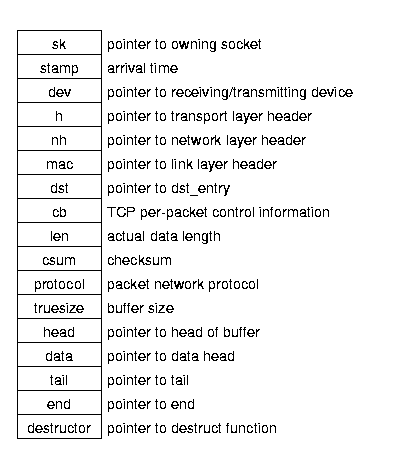
Figure 2.2: Packet (sk_buff) structure.
This structure contains pointers to all of the information about a packet — its socket, device, route, data locations, etc. Transport protocols create these packet structures from output buffers, while device drivers create them for incoming data. Each layer then fills in the information that it needs as it processes the packet. All of the protocols — transport (TCP/UDP), internet (IP), and link level (Ethernet) — use the same socket buffer.
2.4 Internet Routing
The FIB is the primary routing reference; it contains up to 32 zones (one for each bit in an IP address) and entries for every known destination. Each zone contains entries for networks or hosts that can be uniquely identified by a certain number of bits — a network with a netmask of 255.0.0.0 has 8 significant bits and would be in zone 8, while a network with a netmask of 255.255.255.0 has 24 significant bits and would be in zone 24. When IP needs a route, it begins with the most specific zones and searches the entire table until it finds a match (there should always be at least one default entry). The file /proc/net/route has the contents of the FIB.
The routing cache is a hash table that IP uses to actually route packets. It contains up to 256 chains of current routing entries, with each entry’s position determined by a hash function. When a host needs to send a packet, IP looks for an entry in the routing cache. If there is none, it finds the appropriate route in the FIB and inserts a new entry into the cache. (This entry is what the various protocols use to route, not the FIB entry.) The entries remain in the cache as long as they are being used; if there is no traffic for a destination, the entry times out and IP deletes it. The file /proc/net/rt_cache has the contents of the routing cache.
These tables perform all the routing on a normal system. Even other protocols (such as RIP) use the same structures; they just modify the existing tables within the kernel using the ioctl() function. See Chapter 8 for routing details.
Chapter 3
Network Initialization
This chapter presents network initialization on startup. It provides an overview of what happens when the Linux operating system boots, shows how the kernel and supporting programs ifconfig and route establish network links, shows the differences between several example configurations, and summarizes the implementation code within the kernel and network programs.
3.1 Overview
The entire configuration process can be static or dynamic. If addresses and names never (or infrequently) change, the system administrator must define options and variables in files when setting up the system. In a more mutable environment, a host will use a protocol like the Dynamic Hardware Configuration Protocol (DHCP) to ask for an address, router, and DNS server information with which to configure itself when it boots. (In fact, in either case, the administrator will almost always use a GUI interface — like Red Hat’s Control Panel — which automatically writes the configuration files shown below.)
An important point to note is that while most computers running Linux start up the same way, the programs and their locations are not by any means standardized; they may vary widely depending on distribution, security concerns, or whim of the system administrator. This chapter presents as generic a description as possible but assumes a Red Hat Linux 6.1 distribution and a generally static network environment.
3.2 Startup
3.2.1 The Network Initialization Script
The script(s) involved in establishing networking can be very straightforward; it is entirely possible to have one big script that simply executes a series of commands that will set up a single machine properly. However, most Linux distributions come with a large number of generic scripts that work for a wide variety of machine setups. This leaves a lot of indirection and conditional execution in the scripts, but actually makes setting up any one machine much easier. For example, on Red Hat distributions, the /etc/rc.d/init.d/network script runs several other scripts and sets up variables like interfaces_boot to keep track of which /etc/sysconfig/network-scripts/ifup scripts to run. Tracing the process manually is very complicated, but simple modifications of only two configuration files (putting the proper names and IP addresses in the /etc/sysconfig/network and /etc/sysconfig/network-scripts/ifcfg-eth0 files) sets up the entire system properly (and a GUI makes the process even simpler).
When the network script finishes, the FIB contains the specified routes to given hosts or networks and the routing cache and neighbor tables are empty. When traffic begins to flow, the kernel will update the neighbor table and routing cache as part of the normal network operations. (Network traffic may begin during initialization if a host is dynamically configured or consults a network clock, for example.)
3.2.2 ifconfig
The ifconfig program can also provide information about currently configured network devices (calling with no arguments displays all the active interfaces; calling with the -a option displays all interfaces, active or not):
ifconfig eth0 down — shut down eth0
ifconfig eth1 up — activate eth1
ifconfig eth0 arp — enable ARP on eth0
ifconfig eth0 -arp — disable ARP on eth0
ifconfig eth0 netmask 255.255.255.0 — set the eth0 netmask
ifconfig lo mtu 2000 — set the loopback maximum transfer unit
ifconfig eth1 172.16.0.7 — set the eth1 IP address
3.2.3 route
The route program can also delete routes (if run with the del option) or provide information about the routes that are currently defined (if run with no options):
route add [-net | -host] target [option arg]
route del [-net | -host] target [option arg]
route add -host 127.16.1.0 eth1 — adds a route to a host
route add -net 172.16.1.0 netmask 255.255.255.0 eth0 — adds a network
route add default gw jeep — sets the default route through jeep
(Note that a route to jeep must already be set up)
route del -host 172.16.1.16 — deletes entry for host 172.16.1.16
3.2.4 Dynamic Routing Programs
3.3 Examples
3.3.1 Home Computer
This is the first file the network script will read; it sets several environment variables. The first two variables set the computer to run networking programs (even though it is not on a network) but not to forward packets (since it has nowhere to send them). The last two variables are generic entries.
NETWORKING=yes
FORWARD_IPV4=false
HOSTNAME=localhost.localdomain
GATEWAY=
DEVICE=lo
IPADDR=127.0.0.1
NMASK=255.0.0.0
NETWORK=127.0.0.0
BCAST=127.255.255.255
ONBOOT=yes
NAME=loopback
BOOTPROTO=none
3.3.2 Host Computer on a LAN
This is the first file the network script will read; again the first variables simply determine that the computer will do networking but that it will not forward packets. The last four variables identify the computer and its link to the rest of the Internet (everything that is not on the LAN).
NETWORKING=yes
FORWARD_IPV4=false
HOSTNAME=stealth.cs.u.edu
DOMAINNAME=cs.u.edu
GATEWAY=172.16.1.1
GATEWAYDEV=eth0
DEVICE=eth0
IPADDR=172.16.1.4
NMASK=255.255.255.0
NETWORK=172.16.1.0
BCAST=172.16.1.255
ONBOOT=yes
BOOTPROTO=none
After setting these variables, the network script will run the ifconfig program to start the device. Finally, the script will run the route program to add the default route (GATEWAY) and any other specified routes (found in the /etc/sysconfig/static-routes file, if any). In this case only the default route is specified, since all traffic either stays on the LAN (where the computer will use ARP to find other hosts) or goes through the router to get to the outside world.
3.3.3 Network Routing Computer
This is the first file the network script will read; it sets several environment variables. The first two simply determine that the computer will do networking (since it is on a network) and that this one will forward packets (from one network to the other). IP Forwarding is built into most kernels, but it is not active unless there is a 1 «written» to the /proc/net/ipv4/ip_forward file. (One of the network scripts performs an echo 1 > /proc/net/ipv4/ip_forward if FORWARD_IPV4 is true.) The last four variables identify the computer and its link to the rest of the Internet (everything that is not on one of its own networks).
NETWORKING=yes
FORWARD_IPV4=true
HOSTNAME=dodge.u.edu
DOMAINNAME=u.edu
GATEWAY=172.16.0.1
GATEWAYDEV=eth1
DEVICE=eth0
IPADDR=172.16.1.1
NMASK=255.255.255.0
NETWORK=172.16.1.0
BCAST=172.16.1.255
ONBOOT=yes
BOOTPROTO=static
DEVICE=eth1
IPADDR=172.16.0.7
NMASK=255.255.0.0
NETWORK=172.16.0.0
BCAST=172.16.255.255
ONBOOT=yes
3.4 Linux and Network Program Functions
These sources are available as a package separate from the kernel source (Red Hat Linux uses the rpm package manager). The code below is from the net-tools-1.53-1 source code package, 29 August 1999. The packages are available from the www.redhat.com/apps/download web page. Once downloaded, root can install the package with the following commands (starting from the directory with the package):
rpm -i net-tools-1.53-1.src.rpm
cd /usr/src/redhat/SOURCES
tar xzf net-tools-1.53.tar.gz
3.4.1 ifconfig
3.4.2 route
Chapter 4
Connections
This chapter presents the connection process. It provides an overview of the connection process, a description of the socket data structures, an introduction to the routing system, and summarizes the implementation code within the kernel.
4.1 Overview
4.2 Socket Structures
BSD sockets are of type struct socket as defined in include/linux/socket.h. BSD socket variables are usually named sock or some variation thereof. This structure has only a few entries, the most important of which are described below.
- struct proto_ops *ops — this structure contains pointers to protocol specific functions for implementing general socket behavior. For example, ops- > sendmsg points to the inet_sendmsg() function.
- struct inode *inode — this structure points to the file inode that is associated with this socket.
- struct sock *sk — this is the INET socket that is associated with this socket.
INET sockets are of type struct sock as defined in include/net/sock.h. INET socket variables are usually named sk or some variation thereof. This structure has many entries related to a wide variety of uses; there are many hacks and configuration dependent fields. The most important data members are described below:
- struct sock *next, *pprev — all sockets are linked by various protocols, so these pointers allow the protocols to traverse them.
- struct dst_entry *dst_cache — this is a pointer to the route to the socket’s other side (the destination for sent packets).
- struct sk_buff_head receive_queue — this is the head of the receive queue.
- struct sk_buff_head write_queue — this is the head of the send queue.
- __u32 saddr — the (Internet) source address for this socket.
- struct sk_buff_head back_log,error_queue — extra queues for a backlog of packets (not to be confused with the main backlog queue) and erroneous packets for this socket.
- struct proto *prot — this structure contains pointers to transport layer protocol specific functions. For example, prot- > recvmsg may point to the tcp_v4_recvmsg() function.
- union struct tcp_op af_tcp; tp_pinfo — TCP options for this socket.
- struct socket *sock — the parent BSD socket.
- Note that there are many more fields within this structure; these are only the most critical and non-obvious. The rest are either not very important or have self-explanatory names (e.g., ip_ttl is the IP Time-To-Live counter).
4.3 Sockets and Routing
4.4 Connection Processes
4.4.1 Establishing Connections
The socket() call is more interesting. It creates a socket object, with the appropriate data type (a sock for INET sockets) and initializes it. The socket contains inode information and protocol specific pointers for various network functions. It also establishes defaults for queues (incoming, outgoing, error, and backlog), a dummy header info for TCP sockets, and various state information.
Finally, the connect() call goes to the protocol dependent connection routine (e.g., tcp_v4_connect() or udp_connect()). UDP simply establishes a route to the destination (since there is no virtual connection). TCP establishes the route and then begins the TCP connection process, sending a packet with appropriate connection and window flags set.
4.4.2 Socket Call Walk-Through
- Check for errors in call
- Create (allocate memory for) socket object
- Put socket into INODE list
- Establish pointers to protocol functions (INET)
- Store values for socket type and protocol family
- Set socket state to closed
- Initialize packet queues
4.4.3 Connect Call Walk-Through
- Check for errors
- Determine route to destination:
- Check routing table for existing entry (return that if one exists)
- Look up destination in FIB
- Build new routing table entry
- Put entry in routing table and return it
- Store pointer to routing entry in socket
- Call protocol specific connection function (e.g., send a TCP connection packet)
- Set socket state to established
4.4.4 Closing Connections
4.4.5 Close Walk-Through
- Check for errors (does the socket exist?)
- Change the socket state to disconnecting to prevent further use
- Do any protocol closing actions (e.g., send a TCP packet with the FIN bit set)
- Free memory for socket data structures (TCP/UDP and INET)
- Remove socket from INODE list
4.5 Linux Functions
Chapter 5
Sending Messages
This chapter presents the sending side of message trafficking. It provides an overview of the process, examines the layers packets travel through, details the actions of each layer, and summarizes the implementation code within the kernel.
5.1 Overview
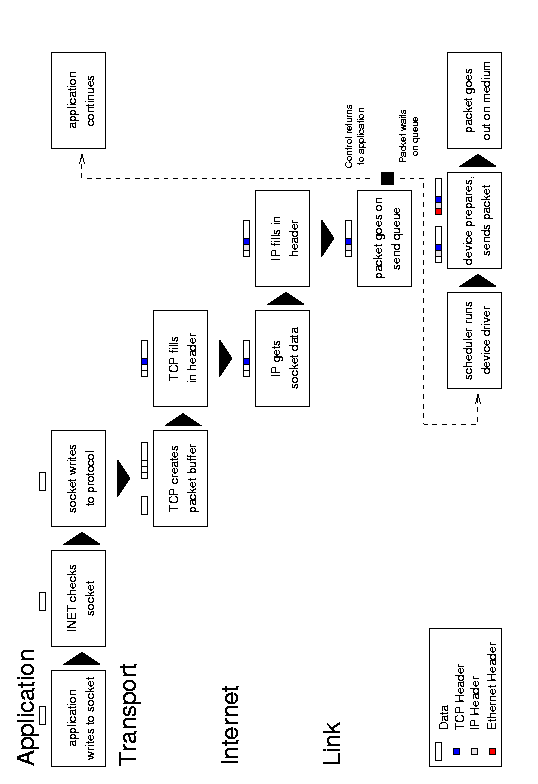
Figure 5.1: Message transmission.
An outgoing message begins with an application system call to write data to a socket. The socket examines its own connection type and calls the appropriate send routine (typically INET). The send function verifies the status of the socket, examines its protocol type, and sends the data on to the transport layer routine (such as TCP or UDP). This protocol creates a new buffer for the outgoing packet (a socket buffer, or struct sk_buff skb), copies the data from the application buffer, and fills in its header information (such as port number, options, and checksum) before passing the new buffer to the network layer (usually IP). The IP send functions fill in more of the buffer with its own protocol headers (such as the IP address, options, and checksum). It may also fragment the packet if required. Next the IP layer passes the packet to the link layer function, which moves the packet onto the sending device’s xmit queue and makes sure the device knows that it has traffic to send. Finally, the device (such as a network card) tells the bus to send the packet.
5.2 Sending Walk-Through
5.2.1 Writing to a Socket
- Write data to a socket (application)
- Fill in message header with location of data (socket)
- Check for basic errors — is socket bound to a port? can the socket send messages? is there something wrong with the socket?
- Pass the message header to appropriate transport protocol (INET socket)
5.2.2 Creating a Packet with UDP
- Check for errors — is the data too big? is it a UDP connection?
- Make sure there is a route to the destination (call the IP routing routines if the route is not already established; fail if there is no route)
- Create a UDP header (for the packet)
- Call the IP build and transmit function
5.2.3 Creating a Packet with TCP
- Check connection — is it established? is it open? is the socket working?
- Check for and combine data with partial packets if possible
- Create a packet buffer
- Copy the payload from user space
- Add the packet to the outbound queue
- Build current TCP header into packet (with ACKs, SYN, etc.)
- Call the IP transmit function
5.2.4 Wrapping a Packet in IP
- Create a packet buffer (if necessary — UDP)
- Look up route to destination (if necessary — TCP)
- Fill in the packet IP header
- Copy the transport header and the payload from user space
- Send the packet to the destination route’s device output funtion
5.2.5 Transmitting a Packet
- Put the packet on the device output queue
- Wake up the device
- Wait for the scheduler to run the device driver
- Test the medium (device)
- Send the link header
- Tell the bus to transmit the packet over the medium
5.3 Linux Functions
Chapter 6
Receiving Messages
This chapter presents the receiving side of message trafficking. It provides an overview of the process, examines the layers packets travel through, details the actions of each layer, and summarizes the implementation code within the kernel.
6.1 Overview
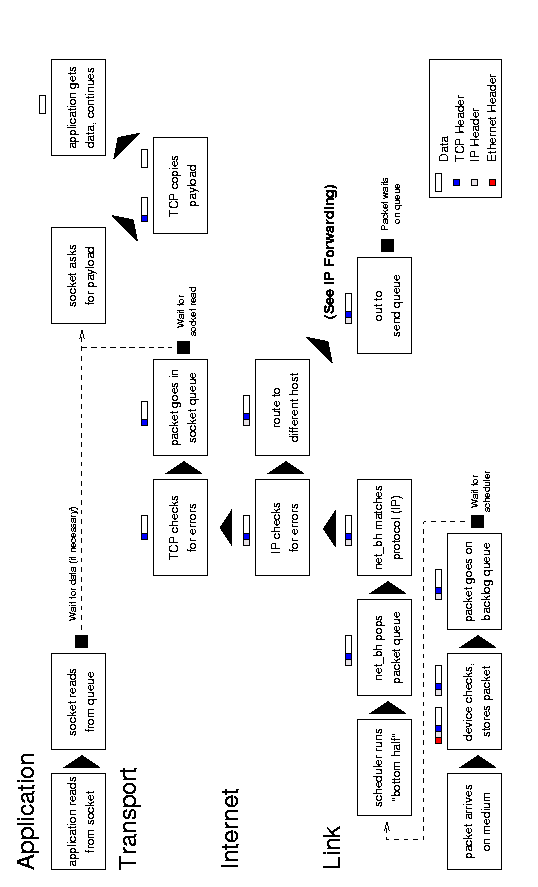
Figure 6.1: Receiving messages.
An incoming message begins with an interrupt when the system notifies the device that a message is ready. The device allocates storage space and tells the bus to put the message into that space. It then passes the packet to the link layer, which puts it on the backlog queue, and marks the network flag for the next «bottom-half» run.
The bottom-half is a Linux system that minimizes the amount of work done during an interrupt. Doing a lot of processing during an interrupt is not good precisely because it interrupts a running process; instead, interrupt handlers have a «top-half» and a «bottom-half». When the interrupt arrives, the top-half runs and takes care of any critical operations, such as moving data from a device queue into kernel memory. It then marks a flag that tells the kernel that there is more work to do — when the processor has time — and returns control to the current process. The next time the process scheduler runs, it sees the flag, does the extra work, and only then schedules any normal processes.
When the process scheduler sees that there are networking tasks to do it runs the network bottom-half. This function pops packets off of the backlog queue, matches them to a known protocol (typically IP), and passes them to that protocol’s receive function. The IP layer examines the packet for errors and routes it; the packet will go into an outgoing queue (if it is for another host) or up to the transport layer (such as TCP or UDP). This layer again checks for errors, looks up the socket associated with the port specified in the packet, and puts the packet at the end of that socket’s receive queue.
Once the packet is in the socket’s queue, the socket will wake up the application process that owns it (if necessary). That process may then make or return from a read system call that copies the data from the packet in the queue into its own buffer. (The process may also do nothing for the time being if it was not waiting for the packet, and get the data off the queue when it needs it.)
6.2 Receiving Walk-Through
6.2.1 Reading from a Socket (Part I)
- Try to read data from a socket (application)
- Fill in message header with location of buffer (socket)
- Check for basic errors — is the socket bound to a port? can the socket accept messages? is there something wrong with the socket?
- Pass the message header with to the appropriate transport protocol (INET socket)
- Sleep until there is enough data to read from the socket (TCP/UDP)
6.2.2 Receiving a Packet
- Wake up the receiving device (interrupt)
- Test the medium (device)
- Receive the link header
- Allocate space for the packet
- Tell the bus to put the packet into the buffer
- Put the packet on the backlog queue
- Set the flag to run the network bottom half when possible
- Return control to the current process
6.2.3 Running the Network «Bottom Half»
- Run the network bottom half (scheduler)
- Send any packets that are waiting to prevent interrupts (bottom half)
- Loop through all packets in the backlog queue and pass the packet up to its Internet reception protocol — IP
- Flush the sending queue again
- Exit the bottom half
6.2.4 Unwrapping a Packet in IP
- Check packet for errors — too short? too long? invalid version? checksum error?
- Defragment the packet if necessary
- Get the route for the packet (could be for this host or could need to be forwarded)
- Send the packet to its destination handling routine (TCP or UDP reception, or possibly retransmission to another host)
6.2.5 Accepting a Packet in UDP
- Check UDP header for errors
- Match destination to socket
- Send an error message back if there is no such socket
- Put packet into appropriate socket receive queue
- Wake up any processes waiting for data from that socket
6.2.6 Accepting a Packet in TCP
- Check sequence and flags; store packet in correct space if possible
- If already received, send immediate ACK and drop packet
- Determine which socket packet belongs to
- Put packet into appropriate socket receive queue
- Wake up and processes waiting for data from that socket
6.2.7 Reading from a Socket (Part II)
- Wake up when data is ready (socket)
- Call transport layer receive function
- Move data from receive queue to user buffer (TCP/UDP)
- Return data and control to application (socket)
6.3 Linux Functions
Chapter 7
IP Forwarding
This chapter presents the pure routing side (by IP forwarding) of message traffic. It provides an overview of the process, examines the layers packets travel through, details the actions of each layer, and summarizes the implementation code within the kernel.
7.1 Overview
See Figure 7.1 for an abstract diagram of the the forwarding process. (It is essentially a combination of the receiving and sending processes.)
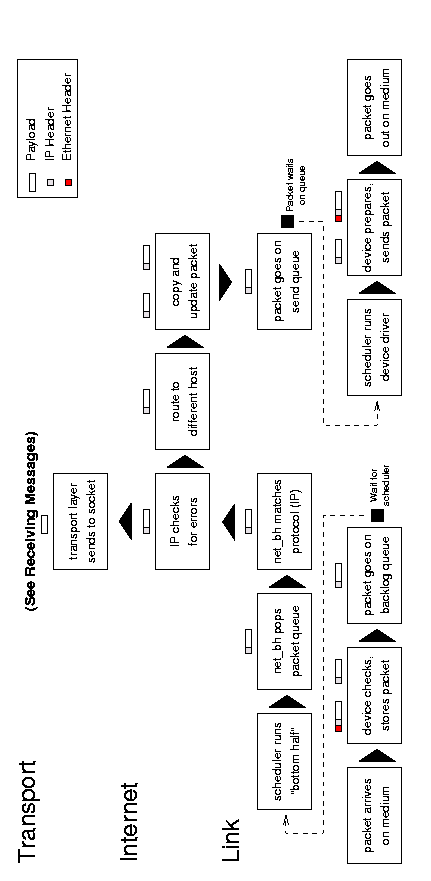
Figure 7.1: IP forwarding.
A forwarded packet arrives with an interrupt when the system notifies the device that a message is ready. The device allocates storage space and tells the bus to put the message into that space. It then passes the packet to the link layer, which puts it on the backlog queue, marks the network flag for the next «bottom-half» run, and returns control to the current process.
When the process scheduler next runs, it sees that there are networking tasks to do and runs the network «bottom-half». This function pops packets off of the backlog queue, matches them to IP, and passes them to the receive function. The IP layer examines the packet for errors and routes it; the packet will go up to the transport layer (such as TCP or UDP if it is for this host) or sideways to the IP forwarding function. Within the forwarding function, IP checks the packet and sends an ICMP message back to the sender if anything is wrong. It then copies the packet into a new buffer and fragments it if necessary.
Finally the IP layer passes the packet to the link layer function, which moves the packet onto the sending device’s xmit queue and makes sure the device knows that it has traffic to send. Finally, the device (such as a network card) tells the bus to send the packet.
7.2 IP Forward Walk-Through
7.2.1 Receiving a Packet
- Wake up the receiving device (interrupt)
- Test the medium (device)
- Receive the link header
- Allocate space for the packet
- Tell the bus to put the packet into the buffer
- Put the packet on the backlog queue
- Set the flag to run the network bottom half when possible
- Return control to the current process
7.2.2 Running the Network «Bottom Half»
- Run the network bottom half (scheduler)
- Send any packets that are waiting to prevent interrupts (net_bh)
- Loop through all packets in the backlog queue and pass the packet up to its Internet reception protocol — IP
- Flush the sending queue again
- Exit the bottom half
7.2.3 Examining a Packet in IP
- Check packet for errors — too short? too long? invalid version? checksum error?
- Defragment the packet if necessary
- Get the route for the packet (could be for this host or could need to be forwarded)
- Send the packet to its destination handling routine (retransmission to another host in this case)
7.2.4 Forwarding a Packet in IP
- Check TTL field (and decrement it)
- Check packet for improper (undesired) routing
- Send ICMP back to sender if there are any problems
- Copy packet into new buffer and free old one
- Set any IP options
- Fragment packet if it is too big for new destination
- Send the packet to the destination route’s device output function
7.2.5 Transmitting a Packet
- Put the packet on the device output queue
- Wake up the device
- Wait for the scheduler to run the device driver
- Test the medium (device)
- Send the link header
- Tell the bus to transmit the packet over the medium
7.3 Linux Functions
Chapter 8
Basic Internet Protocol Routing
This chapter presents the basics of IP Routing. It provides an overview of how routing works, examines how routing tables are established and updated, and summarizes the implementation code within the kernel.
8.1 Overview
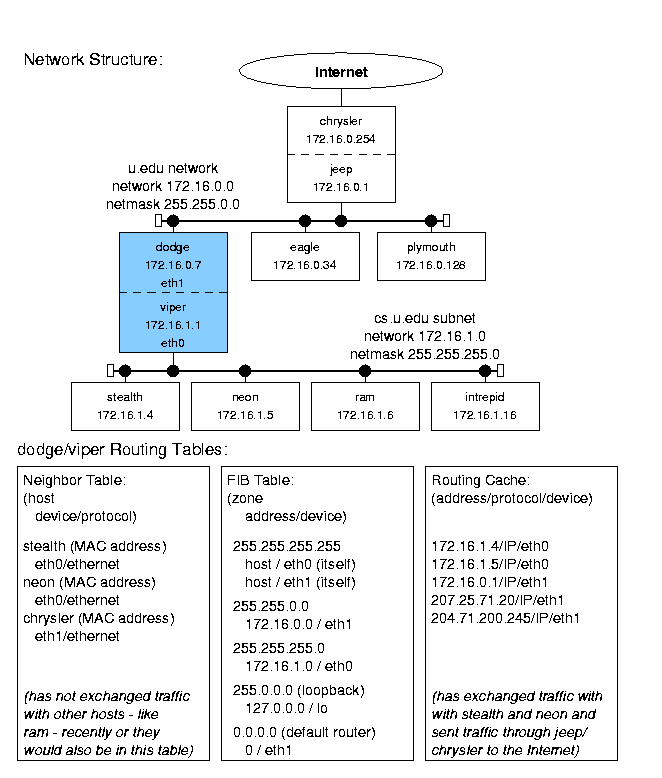
Figure 8.1: General routing table example.
The neighbor table contains address information for computers that are physically connected to the host (hence the name «neighbor»). It includes information on which device connects to which neighbor and what protocols to use in exchanging data. Linux uses the Address Resolution Protocol (ARP) to maintain and update this table; it is dynamic in that entries are added when needed but eventually disappear if not used again within a certain time. (However, administrators can set up entries to be permanent if doing so makes sense.)
Linux uses two complex sets of routing tables to maintain IP addresses: an all-purpose Forwarding Information Base (FIB) with directions to every possible address, and a smaller (and faster) routing cache with data on frequently used routes. When an IP packet needs to go to a distant host, the IP layer first checks the routing cache for an entry with the appropriate source, destination, and type of service. If there is such an entry, IP uses it. If not, IP requests the routing information from the more complete (but slower) FIB, builds a new cache entry with that data, and then uses the new entry. While the FIB entries are semi-permanent (they usually change only when routers come up or go down) the cache entries remain only until they become obsolete (they are unused for a «long» period).
8.2 Routing Tables
8.2.1 The Neighbor Table
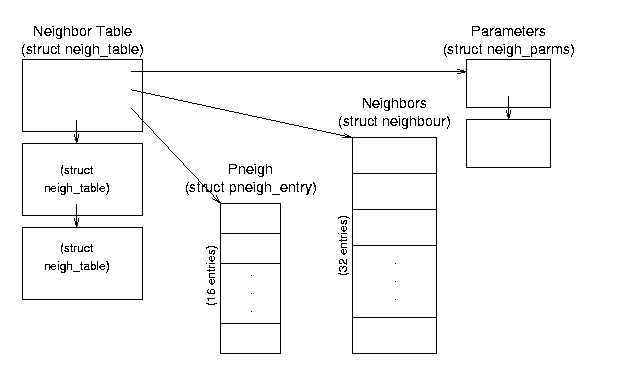
Figure 8.2: Neighbor Table data structure relationships.
struct neigh_table *neigh_tables — this global variable is a pointer to a list of neighbor tables; each table contains a set of general functions and data and a hash table of specific information about a set of neighbors. This is a very detailed, low level table containing specific information such as the approximate transit time for messages, queue sizes, device pointers, and pointers to device functions.
Neighbor Table (struct neigh_table) Structure — this structure (a list element) contains common neighbor information and table of neighbor data and pneigh data. All computers connected through a single type of connection (such as a single Ethernet card) will be in the same table.
- struct neigh_table *next — pointer to the next table in the list.
- struct neigh_parms parms — structure containing message travel time, queue length, and statistical information; this is actually the head of a list.
- struct neigh_parms *parms_list — pointer to a list of information structures.
- struct neighbour *hash_buckets[] — hash table of neighbors associated with this table; there are NEIGH_HASHMASK+1 (32) buckets.
- struct pneigh_entry *phash_buckets[] — hash table of structures containing device pointers and keys; there are PNEIGH_HASHMASK+1 (16) buckets.
- Other fields include timer information, function pointers, locks, and statistics.
Neighbor Data (struct neighbour) Structure — these structures contain the specific information about each neighbor.
- struct device *dev — pointer to the device that is connected to this neighbor.
- __u8 nud_state — status flags; values can be incomplete, reachable, stale, etc.; also contains state information for permanence and ARP use.
- struct hh_cache *hh — pointer to cached hardware header for transmissions to this neighbor.
- struct sk_buff_head arp_queue — pointer to ARP packets for this neighbor.
- Other fields include list pointers, function (table) pointers, and statistical information.
8.2.2 The Forwarding Information Base
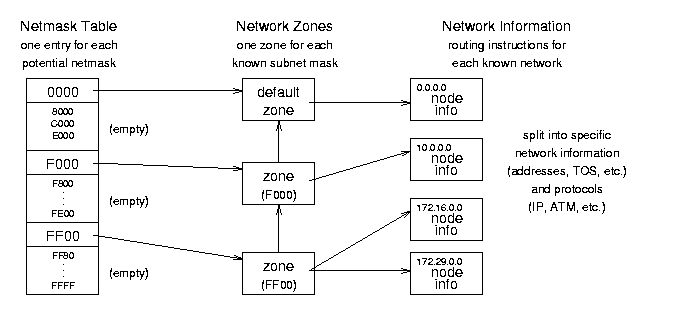
Figure 8.3: Forwarding Information Base (FIB) conceptual organization.
The Forwarding Information Base (FIB) is the most important routing structure in the kernel; it is a complex structure that contains the routing information needed to reach any valid IP address by its network mask. Essentially it is a large table with general address information at the top and very specific information at the bottom. The IP layer enters the table with the destination address of a packet and compares it to the most specific netmask to see if they match. If they do not, IP goes on to the next most general netmask and again compares the two. When it finally finds a match, IP copies the «directions» to the distant host into the routing cache and sends the packet on its way. See Figures 8.3 and 8.4 for the organization and data structures used in the FIB — note that Figure 8.3 shows some different FIB capabilities, like two sets of network information for a single zone, and so does not follow the general example.)
struct fib_table *local_table, *main_table — these global variables are the access points to the FIB tables; they point to table structures that point to hash tables that point to zones. The contents of the main_table variable are in /proc/net/route.
FIB Table fib_table Structure — include/net/ip_fib.h — these structures contain function jump tables and each points to a hash table containing zone information. There are usually only one or two of these.
- int (*tb_functions)() — pointers to table functions (lookup, delete, insert, etc.) that are set during initialization to fn_hash_function().
- unsigned char tb_data[0] — pointer to the associated FIB hash table (despite its declaration as a character array).
- unsigned char tb_id — table identifier; 255 for local_table, 254 for main_table.
- unsigned tb_stamp
Netmask Table fn_hash Structure — net/ipv4/fib_hash.c — these structures contain pointers to the individual zones, organized by netmask. (Each zone corresponds to a uniquely specific network mask.) There is one of these for each FIB table (unless two tables point to the same hash table).
- struct fn_zone *fn_zones[33] — pointers to zone entries (one zone for each bit in the mask; fn_zone[0] points to the zone for netmask 0x0000, fn_zone[1] points to the zone for 0x8000, and fn_zone[32] points to the zone for 0xFFFF.
- struct fn_zone *fn_zone_list — pointer to first (most specific) non-empty zone in the list; if there is an entry for netmask 0xFFFF it will point to that zone, otherwise it may point to zone 0xFFF0 or 0xFF00 or 0xF000 etc.
Network Zone fn_zone Structure — net/ipv4/fib_hash.c — these structures contain some hashing information and pointers to hash tables of nodes. There is one of these for each known netmask.
- struct fn_zone *fz_next — pointer to the next non-empty zone in the hash structure (the next most general netmask; e.g., fn_hash- > fn_zone[28]- > fz_next might point to fn_hash- > fn_zone[27]).
- struct fib_node **fz_hash — pointer to a hash table of nodes for this zone.
- int fz_nent — the number of entries (nodes) in this zone.
- int fx_divisor — the number of buckets in the hash table associated with this zone; there are 16 buckets in the table for most zones (except the first zone — 0000 — the loopback device).
- u32 fz_hashmask — a mask for entering the hash table of nodes; 15 (0x0F) for most zones, 0 for zone 0).
- int fz_order — the index of this zone in the parent fn_hash structure (0 to 32).
- u32 fz_mask — the zone netmask defined as
((1 Figure 8.4: Forwarding Information Base (FIB) data relationships.
FIB Traversal Example:
- ip_route_output_slow() (called because the route is not in the routing cache) sets up an rt_key structure with a source address of 172.16.0.7, a destination address of 172.16.0.34, and a TOS of 2.
- ip_route_output_slow() calls fib_lookup() and passes it the key to search for.
- fib_lookup() calls local_table- > tb_lookup() (which is a reference to the fn_hash_lookup function) to make the local table find the key.
- fn_hash_lookup() searches the local table's hash table, starting in the most specific zone - 24 (netmask 255.255.255.0 dotted decimal) (pointed to by the fn_zone_list variable).
- fz_key() builds a test key by ANDing the destination address with the zone netmask, resulting in a key value 172.16.0.0.
- fz_chain() performs the hash function (see fn_hash()) and ANDs this value with the zone's fz_hashmask (15) to get an index (6) into the zone's hash table of nodes. Unfortunately, this node is empty; there are no possible matches in this zone.
- fn_hash_lookup() moves to the next non-empty zone - 16 (netmask 255.255.0.0 dotted decimal) (pointed to by the current zone's fz_next variable).
- fz_key() builds a new test key by ANDing the destination address with this zone's netmask, resulting in a key value of 172.16.0.0.
- fz_chain() performs the hash function and ANDs this value with the zone's fz_hashmask (15) to get an index (10) into the zone's hash table of nodes. There is a node in that slot.
- fn_hash_lookup() compares its search key to the node's key. They do not match, but the search key value is less than that of the node key, so it moves on to the next node.
- fn_hash_lookup() compares its search key to the new node's key. These do match, so it does some error checking and tests for an exact match with the node and its associated info variable.
- Since everything matches, fn_hash_lookup() fills in a fib_result structure with all the information about this route. (Otherwise it would continue checking more nodes and more zones until it finds a match or fails completely.)
- ip_route_output_slow() takes the fib_result structure and, assuming everything is in order, creates a new routing cache entry from it.
8.2.3 The Routing Cache
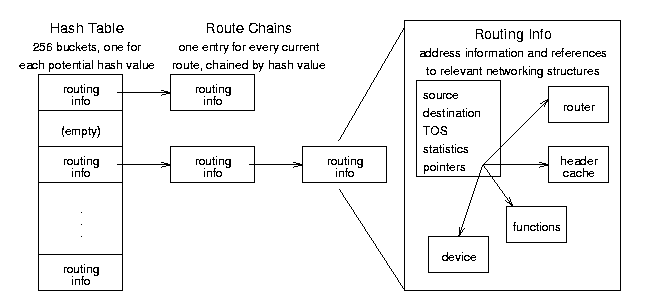
Figure 8.5: Routing Cache conceptual organization.
The routing cache is the fastest method Linux has to find a route; it keeps every route that is currently in use or has been used recently in a hash table. When IP needs a route, it goes to the appropriate hash bucket and searches the chain of cached routes until finds a match, then sends the packet along that path. (See Section 8.2.2 for what happens when the route is not yet in the cache.) Routes are chained in order, most frequently used first, and have timers and counters that remove them from the table when they are no longer in use. See Figure 8.5 for an abstract overview and Figures 8.6 and 8.7 for detailed diagrams of the data structures.
struct rtable *rt_hash_table[RT_HASH_DIVISOR] - this global variable contains 256 buckets of (pointers to) chains of routing cache (rtable) entries; the hash function combines the source address, destination address, and TOS to get an entry point to the table (between 0 and 255). The contents of this table are listed in /proc/net/rt_cache.
Routing Table Entry (rtable) Structure - include/net/route.h - these structures contain the destination cache entries and identification information specific to each route.
- union u - this is an entry in the table; the union structure allows quick access to the next entry in the table by overusing the rtable's next field to point to the next cache entry if required.
- __u32 rt_dst - the destination address.
- __u32 rt_src - the source address.
- rt_int iif - the input interface.
- __u32 rt_gateway - the address of the neighbor to route through to get to a destination.
- struct rt_key key - a structure containing the cache lookup key (with src, dst, iif, oif, tos, and scope fields)
- Other fields contain flags, type, and other miscellaneous information.
Destination Cache (dst_entry) Structure - include/net/dst.h - these structures contain pointers to specific input and output functions and data for a route.
- struct device *dev - the input/output device for this route.
- unsigned pmtu - the maximum packet size for this route.
- struct neighbor *neighbor - a pointer to the neighbor (next link) for this route.
- struct hh_cache *hh - a pointer to the hardware header cache; since this is the same for every outgoing packet on a physical link, it is kept for quick access and reuse.
- int (*input)(struct sk_buff*) - a pointer to the input function for this route (typically tcp_recv()).
- int (*output)(struct sk_buff*) - a pointer to the output function for this route (typically dev_queue_xmit()).
- struct dst_ops *ops - a pointer to a structure containing the family, protocol, and check, reroute, and destroy functions for this route.
- Other fields hold statistical and state information and links to other routing table entries.
Neighbor Link (neighbor) Structure - include/net/neighbor.h - these structures, one for each host that is exactly one hop away, contain pointers to their access functions and information.
- struct device *dev - a pointer to device that is physically connected to this neighbor.
- struct hh_cache *hh - a pointer to the hardware header that always precedes traffic sent to this neighbor.
- int (*output)(struct sk_buff*) - a pointer to the output function for this neighbor (typically dev_queue_xmit()?).
- struct sk_buff_head arp_queue - the first element in the ARP queue for traffic concerning this neighbor - incoming or outgoing?
- struct neigh_ops *ops - a pointer to a structure that containing family data and and output functions for this link.
- Other fields hold statistical and state information and references to other neighbors.
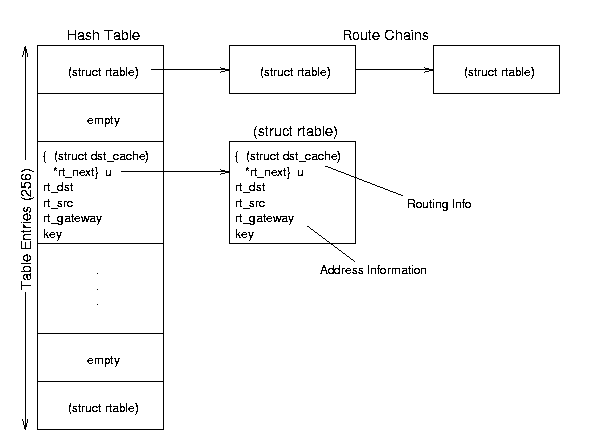
Figure 8.6: Routing Cache data structure relationships.
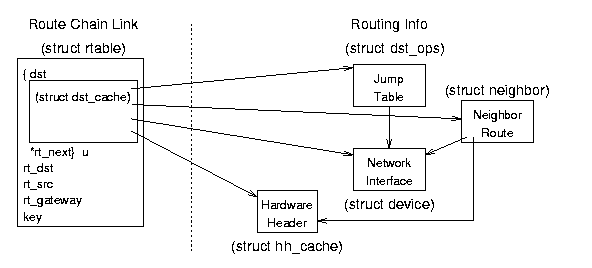
Figure 8.7: Destination Cache data structure relationships.
Routing Cache Traversal Example:
- ip_route_output() (called to find a route) calls rt_hash_code() with a source address of 172.16.1.1, a destination address of 172.16.1.6, and a TOS of 2.
- rt_hash_code() performs a hash function on the source, destination, and TOS and ANDs the result with 255 to get an entry into the hash table (5).
- ip_route_output() enters the hash table at index 5. There is an entry there, but the destination addresses do not match.
- ip_route_output() moves to the next entry (pointed to by the u.rt_next field of the last entry). This one matches in every case - destination address, source address, iif of 0, matching oif, and acceptable TOS.
- ip_route_output() updates the statistics in the newfound dst_cache structure of the table entry, sets a pointer for the calling function to refer to the route, and returns a 0 indicating success.
8.2.4 Updating Routing Information
The neighbor table changes as network traffic is exchanged. If a host needs to send something to an address that is on the local subnet but not already in the neighbor table, it simply broadcasts an ARP request and adds a new entry in the neighbor table when it gets a reply. Periodically entries time out and disappear; this cycle continues indefinitely (unless a route has been specifically marked as ARP permanent). The kernel handles most changes automatically.
The FIB on most hosts and even routers remains static; it is filled in during initialization with every possible zone to route through all connected routers and never changes unless one of the routers goes down. (See Chapter 9 for details on IP routing daemons). Changes have to come through external ioctl() calls to add or delete zones.
The routing cache changes frequently depending on message traffic. If a host needs to send packets to a remote address, it looks up the address in the routing cache (and FIB if necessary) and sends the packet off through the appropriate router. On a host connected to a LAN with one router to the Internet, every entry will point to either a neighbor or the router, but there may be many entries that point to the router (one for each distant address). The entries are created as connections are made and time out quickly when traffic to that address stops flowing. Everything is done with IP level calls to create routes and kernel timers to delete them.
8.3 Linux Functions
Chapter 9
Dynamic Routing with routed
This chapter presents dynamic routing as performed by a router (as opposed to an end host computer). It provides an overview of how the routed program implements routing protocols under Linux, examines how it modifies the kernel routing tables, and summarizes the implementation code.
9.1 Overview
However, a router must make decisions on where to send traffic. There may be several routes to a destination, and the router must select one (based on distance, measured in hops or some other metric such as the nebulous quality of service). The Routing Information Protocol (RIP) is a simple protocol that allows routing computers to track the distance to various destinations and to share this information amongst themselves.
Using RIP, each node maintains a table that contains the distance from itself to other networks and the route along which it will send packets to that destination. Periodically the routers update each other; when shorter routes becomes apparent, the node updates its table. Updates are simply RIP messages with the destination address and metric components of this table. See Figure 9.1 for a diagram of an RIP routing table and an RIP packet.
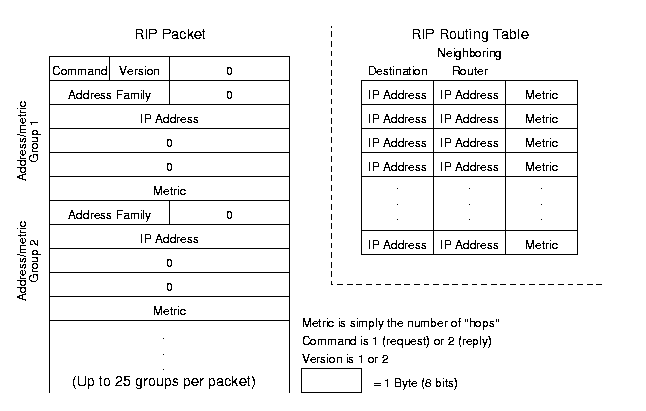
Figure 9.1: Routing Information Protocol packet and table.
9.2 How routed Works
9.2.1 Data Structures
9.2.2 Initialization
9.2.3 Normal Operations
When the update timer expires, every TIMER_RATE seconds, routed goes through every entry in both tables and updates their timers. Entries which are out of date are set to a distance of infinity (HOPCNT_INFINITY) and entries which are too old are deleted (only from the RIP table, not from the kernel's FIB). Finally, it sends an update to its neighboring routers. This update contains the new table information (response messages) for any entries which have changed since the last update.
routed leaves the actual routing to the normal kernel routing mechanisms; all it does is update the kernel's tables based on information from other routers and pass on its own routing information. The updates then change how the kernel routes packets, but routed itself does not actually do any routing.
9.3 routed Functions
The routed source is available as a package separate from the kernel source (Red Hat Linux uses the rpm package manager). The code below is from the netkit-routed-0.10 source code package, 8 March 1997. This package is available from the www.redhat.com/apps/download web page; specifically this came from www.redhat.com/swt/src/netkit-routed-0.10.src.html. Once downloaded, root can install the package with the following commands (starting from the directory with the package):
rpm -i netkit-routed-0.10.src.rpm
cd /usr/src/redhat/SOURCES
tar xzf netkit-routed-0.10.tar.gz
Chapter 10
Editing Linux Source Code
10.1 The Linux Source Tree
This is an overview of the Linux source directory structure (not all branches are shown:
- arch - architecture specific code, by processor
- i386 - code for Intel processors (including 486 and Pentium lines)
- boot - location of newly compiled kernels
- drivers - code for drivers of all sorts
- block - block device drivers (e.g., hard drives)
- cdrom - CD ROM device drivers
- net - network device drivers
- pci - PCI bus drivers
- fs - code for different file systems (EXT2, MS-DOS, etc.)
- include - header files used throughout the code
- asm ® asm-i386 - processor dependent headers
- config - general configuration headers
- linux - common headers
- net - networking headers
- kernel - code for the kernel specific routines
- lib - code for errors, strings, and printf
- mm - code for memory management
- modules - object files and references for the kernel to load as required
- net - code for networking
- core - protocol independent code
- ipv4 - code specific to IPv4
- packet - protocol independent packet code
- sched - code for scheduling network actions
10.2 Using EMACS Tags
10.2.1 Referencing with TAGS
These tags work even as you make changes to the source files, though they will run slower as more and more changes are made. EMACS stores the tags in a file (defaulted to TAGS) with each reference, filename, and line number. If the tag is not at the stored line number, EMACS will search the file to find the new location.
10.2.2 Constructing TAGS files
The command to make a tags file is:
For example, to create a tags file for the ipv4 source files, enter:
10.3 Using vi tags
10.4 Rebuilding the Kernel
This is a quick step-by-step guide to recompiling and installing a kernel from scratch.
Go to the top of the source directory (/usr/src/linux). If there is not already a historical copy of a working .config file (such as the current one), MAKE ONE. Until you have enough experience that you no longer need this guide, do not overwrite anything until you have made sure there is a copy to which you can revert. (On the other hand, once you have a stable kernel version, there is no reason to keep old ones around. Even a development system should probably only have an original working version, a last known stable version, and a current version.Run make xconfig (make config and make menuconfig also work, but xconfig is by far the user-friendliest). Configure the system as desired; there is help available for most options. The config file should default to the current settings, so you should only have to change the things you want to add or take out. As a general rule, select ``Y'' for essential or frequently used features (like the ext2 file system), ``M'' for things that are sometimes useful (like sound drivers), and ``N'' for things that do not apply (like amateur radio support). If in doubt, consult the help text or include something as a module.
Run make dep to make sure the options you heve selected will compile properly. This make take a few minutes as the computer checks all of the dependencies. If all goes well, the make program will simply exit; if there is a problem, it will display error messages and stop.
Run make clean to remove old object files IF you want to recompile everything. This obviously will make the compilation process take longer.
Run make bzImage to build the new kernel. (make zImage and make boot also build kernel images, but the bzImage will compile into the most compact file. If you are using one of these two methods for some reason, you may get a ``kernel too big'' error when you run lilo - try again with a bzImage.) This will take quite some time, depending on available memory.
Run make modules to build any modules (not included in the main kernel image).
Rename the old modules if necessary:
Run make modules_install to install the new modules. You must do this even if you built a monolithic kernel (one with no modules). (Note that there may be a Red Hat module-info text file or link in the boot directory; it is not terribly important and this does not update it.)
Copy the new kernel to the /boot directory and change the kernel link (usually vmlinuz):
cp arch/i386/boot/bzImage /boot/vmlinuz-2.2.xx
ln -sf /boot/vmlinuz-2.2.xx /boot/vmlinuzCopy the new System.map file to the /boot directory and change the map link:
cp System.map /boot/System.map-2.2.xx
ln -sf /boot/System.map-2.2.xx /boot/System.mapCreate a new initrd file if there are any SCSI devices on the computer:
Edit the file /etc/lilo.conf to install the new kernel; copy the block for the old kernel (image=vmlinuz) and change the existing one to keep it as an option. For example, rename the image to vmlinuz-2.2.xx-old and change the label to stable. This way you can always reboot to the current (presumably stable) kernel if your changes cause problems.
Run /sbin/lilo to install the new kernel as a boot option.
Reboot the computer with the new kernel.
If the new kernel does not work properly, boot the old kernel and reconfigure the system before trying again.
10.5 Patching the Kernel Source
Linux is a constantly changing operating system; updates can be released every few months. There are two ways to install a new kernel version: downloading the new source in its entirety or downloading patches and applying them.
Downloading the entire source may be preferable to guarantee everything works properly. To do so, download the latest kernel source and install (untar) it. Note that this will (probably) be a complete distribution, not a machine-specific one, and will contain a lot of extra code. Much of this can be deleted, but the configuration Makefiles rely on some for information. If space is an issue, delete the *.c and *.h files in the non-i386 arch/ and include/asm-* directories, but tread lightly.
Downloading patches may be quicker to do, but is somewhat harder. Because of distribution variations, changes you have made, or other modifications the patches may not quite work properly. You must apply patch files in order (to go from 2.2.12 to 2.2.14, first apply patch 2.2.13 then apply 2.2.14). Nevertheless, patches may be preferable because they work on an existing directory tree.
Once you have downloaded a patch (and unzipped it, if necessary), simply put it in the directory above linux (e.g., /usr/src/) and run the patch program to install it:
patch -Np0 -verbose -r rejfile arp displays the neighbor table (arp_tbl); the IP and hardware addresses, hardware type, device, and flags. (arp_get_info() : net/ipv4/arp.c 988) dev displays reception and transmission statistics for each registered interface dev_stat displays number of received packets dropped and throttle and FASTROUTE statistics (dev_proc_stats() : net/core/dev.c 1228) netstat displays sync cookie, pruning, and ICMP statistics (netstat_get_info() : net/ipv4/proc.c 355) raw displays address, queue, and timeout information for each open RAW socket from struct proto raw_prot (get__netinfo() : net/ipv4/proc.c 165) route displays the FIB table (main_table); the interface, address, gateway, flags, and usage information. (fib_get_procinfo()) : net/ipv4/fib_frontend.c 109) rt_cache displays the routing cache (rt_hash_table); the interface, address, gateway, usage, source, and other information. (rt_cache_get_info() : net/ipv4/route.c 191) sockstat displays number of sockets that have been used and some statistics on how many were TCP, UDP, and RAW (afinet_get_info() : net/ipv4/proc.c 244) tcp displays address, queue, and timeout information for each open TCP socket from struct proto tcp_prot (get__netinfo() : net/ipv4/proc.c 165) udp displays address, queue, and timeout information for each open UDP socket from struct proto udp_prot (get__netinfo() : net/ipv4/proc.c 165)
12.3 Registering proc Files
12.3.1 Formatting a Function to Provide Information
static int read_proc_function(char *buf,char **start,off_t offset,int len,int unused)
This is the function that the Linux kernel will call whenever it tries to read from the newly created proc ``file''. The only parameter that is usually significant is buf - a pointer to the buffer the kernel makes available for storing information. The others normally will not change. (read_proc_function is of course the name of the new function.)
Typically this function prints out a header, iterates through a list or table printing its contents (using the normal sprintf routine), and returns the length of the resulting string. The only limitation is that the buffer (buf) is at most PAGE_SIZE bytes (this is at least 4KB).
For an example of this kind of function, look at the fib_get_procinfo() function beginning on line 109 of net/ipv4/fib_frontend.c. This function displays the contents of the main FIB table.
12.3.2 Building a proc Entry
For an example of this kind of entry, look at the __init_func() function beginning on line 607 of net/ipv4/fib_frontend.c. This functions calls proc_net_register() (described below) with a newly created proc_dir_entry structure.
12.3.3 Registering a proc Entry
int proc_register(struct proc_dir_entry *dir, struct proc_dir_entry *entry)
int proc_net_register(struct proc_dir_entry *entry)dir is a pointer to the directory in which the entry belongs - &proc_root and proc_net (defined in include/proc_fs.h) are probably the most useful. entry is a pointer to the entry itself, as created above. These two functions are identical except that proc_net_register automatically uses the /proc/net directory. They return either 0 (success) or EAGAIN (if there are no available inodes).
12.3.4 Unregistering a proc Entry
int proc_unregister(struct proc_dir_entry *dir,int inode)
int proc_net_unregister(int inode)dir is the proc directory in which the file resides, and inode is the inode number of the file. (The inode is available in the entry's struct proc_dir_entry.low_ino field if it is not a constant.) Again, these functions are identical except that proc_net_unregister automatically uses the /proc/net directory. They return either 0 (success) or EINVAL (if there is no such entry).
12.4 Example
This is the Makefile:
To use (must be root):
Chapter 13
Example - Packet DropperThis sample experiment inserts a routine into the kernel that selectively drops packets to a given host. It discusses the placement of the code, outlines the data from an actual trial, presents a lightweight analysis of the results, and includes the code itself.
13.1 Overview
13.2 Considerations
Protocol Level This code could be implemented at many levels:
- Device Driver - this is a possibility since all traffic comes through the device. However, this breaks the layering protocols and requires hacking a (presumably) stable hardware driver.
- Generic Device Functions - this is the best choice, since this is the lowest level through which all traffic travels (specifically the dev_queue_xmit() and netif_rx() functions). It still violates the protocol layering, but all of the modifications can be made in one section of code.
- IP Protocol - this is conceptually the right place to insert a special function, either in the input, routing, or output routines. However, this is unsuitable precisely because there are three different routines in the implementation that a packet might go through - ip_forward() (forwarded packets), ip_queue_xmit() (TCP packets), or ip_build_xmit() (UDP packets). See the coding sections in Chapters 5 and 7 to see how these routines interact. These functions would be a good choice for inserting a special-purpose dropper, but not one that affects all traffic.
- Transport Protocol - these routines would be appropriate for affecting specific traffic types (such as UDP only) but are not useful for this example.
13.3 Experimental Systems and Benchmarks

Figure 13.1: Experimental system setup.The switch is a Cisco Catalyst 2900 set up with Virtual LANs (VLANs) for each ``subnetwork'' (one for the source computer and one for the destination computer, with the routing computer acting as the router between the two. The switch operates entirely on the link level and is essentially invisible for routing purposes.
The routing computer (dodge/viper) is a Dell Optiplex GX1 with a Pentium II/350 processor and 128M of RAM. It has three 3Com 3c59x Ethernet cards with 10Mbps connections to the switch.
One host computer (neon) is an AST Premmia GX with a Pentium/100 processor and 32M of RAM. It has an AMD Lance Ethernet card with a 10Mbps connection to the switch.
The other host computer (eagle) is a Dell Optiplex XL590 with a Pentium/90 processor and 32M of RAM. It has a 3Com 3c509 Ethernet card with a 10Mbps connection to the switch.
All computers have the Red Hat 6.1 distribution of Linux; the source and destination computers have standard recompiled version 2.2.14 kernels, while the router uses either a standard (2.2.14) kernel or a slightly modified one as indicated.
The first benchmark is a ``ping-pong'' test that establishes a TCP connection and then repeatedly sends packets back and forth. It returns a total transmission time (from start to finish, not including making and closing the connection); dividing the time by the number of iterations yields an average Round Trip Time (RTT). This test was run with 20,000 iterations of 5 byte packets and 5,000 iterations of 500 byte packets.
The second benchmark is a ``blast'' test that establishes a TCP connection and then sends data from a source to a destination. It returns a total transmission time (from start to finish, not including making and closing the connection); multiplying the number of packets by the size of the packets and dividing by the time yields the throughput. This test was run with 50,000 5 byte packets, 5,000 500 byte packets, and 1,000 1500 byte packets.
Источник
- i386 - code for Intel processors (including 486 and Pentium lines)