- Locking¶
- dentry_operations¶
- inode_operations¶
- xattr_handler operations¶
- super_operations¶
- file_system_type¶
- address_space_operations¶
- File locking in Linux
- Introduction
- Advisory locking
- Common features
- Differing features
- File descriptors and i-nodes
- BSD locks (flock)
- POSIX record locks (fcntl)
- lockf function
- Open file description locks (fcntl)
- Emulating Open file description locks
- Test program
- Command-line tools
- Mandatory locking
- Example usage
Locking¶
The text below describes the locking rules for VFS-related methods. It is (believed to be) up-to-date. Please, if you change anything in prototypes or locking protocols — update this file. And update the relevant instances in the tree, don’t leave that to maintainers of filesystems/devices/ etc. At the very least, put the list of dubious cases in the end of this file. Don’t turn it into log — maintainers of out-of-the-tree code are supposed to be able to use diff(1).
Thing currently missing here: socket operations. Alexey?
dentry_operations¶
| ops | rename_lock | ->d_lock | may block | rcu-walk |
|---|---|---|---|---|
| d_revalidate: | no | no | yes (ref-walk) | maybe |
| d_weak_revalidate: | no | no | yes | no |
| d_hash | no | no | no | maybe |
| d_compare: | yes | no | no | maybe |
| d_delete: | no | yes | no | no |
| d_init: | no | no | yes | no |
| d_release: | no | no | yes | no |
| d_prune: | no | yes | no | no |
| d_iput: | no | no | yes | no |
| d_dname: | no | no | no | no |
| d_automount: | no | no | yes | no |
| d_manage: | no | no | yes (ref-walk) | maybe |
| d_real | no | no | yes | no |
inode_operations¶
locking rules: all may block
| ops | i_rwsem(inode) |
|---|---|
| lookup: | shared |
| create: | exclusive |
| link: | exclusive (both) |
| mknod: | exclusive |
| symlink: | exclusive |
| mkdir: | exclusive |
| unlink: | exclusive (both) |
| rmdir: | exclusive (both)(see below) |
| rename: | exclusive (all) (see below) |
| readlink: | no |
| get_link: | no |
| setattr: | exclusive |
| permission: | no (may not block if called in rcu-walk mode) |
| get_acl: | no |
| getattr: | no |
| listxattr: | no |
| fiemap: | no |
| update_time: | no |
| atomic_open: | shared (exclusive if O_CREAT is set in open flags) |
| tmpfile: | no |
See Documentation/filesystems/directory-locking.rst for more detailed discussion of the locking scheme for directory operations.
xattr_handler operations¶
locking rules: all may block
| ops | i_rwsem(inode) |
|---|---|
| list: | no |
| get: | no |
| set: | exclusive |
super_operations¶
locking rules: All may block [not true, see below]
| ops | s_umount | note |
|---|---|---|
| alloc_inode: | ||
| free_inode: | called from RCU callback | |
| destroy_inode: | ||
| dirty_inode: | ||
| write_inode: | ||
| drop_inode: | . inode->i_lock. | |
| evict_inode: | ||
| put_super: | write | |
| sync_fs: | read | |
| freeze_fs: | write | |
| unfreeze_fs: | write | |
| statfs: | maybe(read) | (see below) |
| remount_fs: | write | |
| umount_begin: | no | |
| show_options: | no | (namespace_sem) |
| quota_read: | no | (see below) |
| quota_write: | no | (see below) |
| bdev_try_to_free_page: | no | (see below) |
->statfs() has s_umount (shared) when called by ustat(2) (native or compat), but that’s an accident of bad API; s_umount is used to pin the superblock down when we only have dev_t given us by userland to identify the superblock. Everything else (statfs(), fstatfs(), etc.) doesn’t hold it when calling ->statfs() — superblock is pinned down by resolving the pathname passed to syscall.
->quota_read() and ->quota_write() functions are both guaranteed to be the only ones operating on the quota file by the quota code (via dqio_sem) (unless an admin really wants to screw up something and writes to quota files with quotas on). For other details about locking see also dquot_operations section.
->bdev_try_to_free_page is called from the ->releasepage handler of the block device inode. See there for more details.
file_system_type¶
| ops | may block |
|---|---|
| mount | yes |
| kill_sb | yes |
->mount() returns ERR_PTR or the root dentry; its superblock should be locked on return.
->kill_sb() takes a write-locked superblock, does all shutdown work on it, unlocks and drops the reference.
address_space_operations¶
locking rules: All except set_page_dirty and freepage may block
| ops | PageLocked(page) | i_rwsem |
|---|---|---|
| writepage: | yes, unlocks (see below) | |
| readpage: | yes, unlocks | |
| writepages: | ||
| set_page_dirty | no | |
| readahead: | yes, unlocks | |
| readpages: | no | |
| write_begin: | locks the page | exclusive |
| write_end: | yes, unlocks | exclusive |
| bmap: | ||
| invalidatepage: | yes | |
| releasepage: | yes | |
| freepage: | yes | |
| direct_IO: | ||
| isolate_page: | yes | |
| migratepage: | yes (both) | |
| putback_page: | yes | |
| launder_page: | yes | |
| is_partially_uptodate: | yes | |
| error_remove_page: | yes | |
| swap_activate: | no | |
| swap_deactivate: | no |
->write_begin(), ->write_end() and ->readpage() may be called from the request handler (/dev/loop).
->readpage() unlocks the page, either synchronously or via I/O completion.
->readahead() unlocks the pages that I/O is attempted on like ->readpage().
->readpages() populates the pagecache with the passed pages and starts I/O against them. They come unlocked upon I/O completion.
->writepage() is used for two purposes: for “memory cleansing” and for “sync”. These are quite different operations and the behaviour may differ depending upon the mode.
If writepage is called for sync (wbc->sync_mode != WBC_SYNC_NONE) then it must start I/O against the page, even if that would involve blocking on in-progress I/O.
If writepage is called for memory cleansing (sync_mode == WBC_SYNC_NONE) then its role is to get as much writeout underway as possible. So writepage should try to avoid blocking against currently-in-progress I/O.
If the filesystem is not called for “sync” and it determines that it would need to block against in-progress I/O to be able to start new I/O against the page the filesystem should redirty the page with redirty_page_for_writepage(), then unlock the page and return zero. This may also be done to avoid internal deadlocks, but rarely.
If the filesystem is called for sync then it must wait on any in-progress I/O and then start new I/O.
The filesystem should unlock the page synchronously, before returning to the caller, unless ->writepage() returns special WRITEPAGE_ACTIVATE value. WRITEPAGE_ACTIVATE means that page cannot really be written out currently, and VM should stop calling ->writepage() on this page for some time. VM does this by moving page to the head of the active list, hence the name.
Unless the filesystem is going to redirty_page_for_writepage(), unlock the page and return zero, writepage must run set_page_writeback() against the page, followed by unlocking it. Once set_page_writeback() has been run against the page, write I/O can be submitted and the write I/O completion handler must run end_page_writeback() once the I/O is complete. If no I/O is submitted, the filesystem must run end_page_writeback() against the page before returning from writepage.
That is: after 2.5.12, pages which are under writeout are not locked. Note, if the filesystem needs the page to be locked during writeout, that is ok, too, the page is allowed to be unlocked at any point in time between the calls to set_page_writeback() and end_page_writeback() .
Note, failure to run either redirty_page_for_writepage() or the combination of set_page_writeback()/ end_page_writeback() on a page submitted to writepage will leave the page itself marked clean but it will be tagged as dirty in the radix tree. This incoherency can lead to all sorts of hard-to-debug problems in the filesystem like having dirty inodes at umount and losing written data.
->writepages() is used for periodic writeback and for syscall-initiated sync operations. The address_space should start I/O against at least *nr_to_write pages. *nr_to_write must be decremented for each page which is written. The address_space implementation may write more (or less) pages than *nr_to_write asks for, but it should try to be reasonably close. If nr_to_write is NULL, all dirty pages must be written.
writepages should _only_ write pages which are present on mapping->io_pages.
->set_page_dirty() is called from various places in the kernel when the target page is marked as needing writeback. It may be called under spinlock (it cannot block) and is sometimes called with the page not locked.
-> bmap() is currently used by legacy ioctl() (FIBMAP) provided by some filesystems and by the swapper. The latter will eventually go away. Please, keep it that way and don’t breed new callers.
->invalidatepage() is called when the filesystem must attempt to drop some or all of the buffers from the page when it is being truncated. It returns zero on success. If ->invalidatepage is zero, the kernel uses block_invalidatepage() instead.
->releasepage() is called when the kernel is about to try to drop the buffers from the page in preparation for freeing it. It returns zero to indicate that the buffers are (or may be) freeable. If ->releasepage is zero, the kernel assumes that the fs has no private interest in the buffers.
->freepage() is called when the kernel is done dropping the page from the page cache.
->launder_page() may be called prior to releasing a page if it is still found to be dirty. It returns zero if the page was successfully cleaned, or an error value if not. Note that in order to prevent the page getting mapped back in and redirtied, it needs to be kept locked across the entire operation.
->swap_activate will be called with a non-zero argument on files backing (non block device backed) swapfiles. A return value of zero indicates success, in which case this file can be used for backing swapspace. The swapspace operations will be proxied to the address space operations.
->swap_deactivate() will be called in the sys_swapoff() path after ->swap_activate() returned success.
Источник
File locking in Linux
Table of contents
Introduction
File locking is a mutual-exclusion mechanism for files. Linux supports two major kinds of file locks:
- advisory locks
- mandatory locks
Below we discuss all lock types available in POSIX and Linux and provide usage examples.
Advisory locking
Traditionally, locks are advisory in Unix. They work only when a process explicitly acquires and releases locks, and are ignored if a process is not aware of locks.
There are several types of advisory locks available in Linux:
- BSD locks (flock)
- POSIX record locks (fcntl, lockf)
- Open file description locks (fcntl)
All locks except the lockf function are reader-writer locks, i.e. support exclusive and shared modes.
Note that flockfile and friends have nothing to do with the file locks. They manage internal mutex of the FILE object from stdio.
- File Locks, GNU libc manual
- Open File Description Locks, GNU libc manual
- File-private POSIX locks, an LWN article about the predecessor of open file description locks
Common features
The following features are common for locks of all types:
- All locks support blocking and non-blocking operations.
- Locks are allowed only on files, but not directories.
- Locks are automatically removed when the process exits or terminates. It’s guaranteed that if a lock is acquired, the process acquiring the lock is still alive.
Differing features
This table summarizes the difference between the lock types. A more detailed description and usage examples are provided below.
| BSD locks | lockf function | POSIX record locks | Open file description locks | |
|---|---|---|---|---|
| Portability | widely available | POSIX (XSI) | POSIX (base standard) | Linux 3.15+ |
| Associated with | File object | [i-node, pid] pair | [i-node, pid] pair | File object |
| Applying to byte range | no | yes | yes | yes |
| Support exclusive and shared modes | yes | no | yes | yes |
| Atomic mode switch | no | — | yes | yes |
| Works on NFS (Linux) | Linux 2.6.12+ | yes | yes | yes |
File descriptors and i-nodes
A file descriptor is an index in the per-process file descriptor table (in the left of the picture). Each file descriptor table entry contains a reference to a file object, stored in the file table (in the middle of the picture). Each file object contains a reference to an i-node, stored in the i-node table (in the right of the picture).
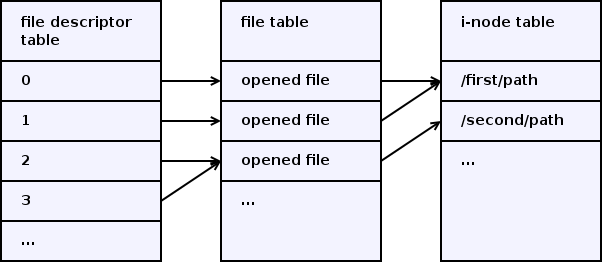
A file descriptor is just a number that is used to refer a file object from the user space. A file object represents an opened file. It contains things likes current read/write offset, non-blocking flag and another non-persistent state. An i-node represents a filesystem object. It contains things like file meta-information (e.g. owner and permissions) and references to data blocks.
File descriptors created by several open() calls for the same file path point to different file objects, but these file objects point to the same i-node. Duplicated file descriptors created by dup2() or fork() point to the same file object.
A BSD lock and an Open file description lock is associated with a file object, while a POSIX record lock is associated with an [i-node, pid] pair. We’ll discuss it below.
BSD locks (flock)
The simplest and most common file locks are provided by flock(2) .
- not specified in POSIX, but widely available on various Unix systems
- always lock the entire file
- associated with a file object
- do not guarantee atomic switch between the locking modes (exclusive and shared)
- up to Linux 2.6.11, didn’t work on NFS; since Linux 2.6.12, flock() locks on NFS are emulated using fcntl() POSIX record byte-range locks on the entire file (unless the emulation is disabled in the NFS mount options)
The lock acquisition is associated with a file object, i.e.:
- duplicated file descriptors, e.g. created using dup2 or fork , share the lock acquisition;
- independent file descriptors, e.g. created using two open calls (even for the same file), don’t share the lock acquisition;
This means that with BSD locks, threads or processes can’t be synchronized on the same or duplicated file descriptor, but nevertheless, both can be synchronized on independent file descriptors.
flock() doesn’t guarantee atomic mode switch. From the man page:
Converting a lock (shared to exclusive, or vice versa) is not guaranteed to be atomic: the existing lock is first removed, and then a new lock is established. Between these two steps, a pending lock request by another process may be granted, with the result that the conversion either blocks, or fails if LOCK_NB was specified. (This is the original BSD behaviour, and occurs on many other implementations.)
This problem is solved by POSIX record locks and Open file description locks.
POSIX record locks (fcntl)
POSIX record locks, also known as process-associated locks, are provided by fcntl(2) , see “Advisory record locking” section in the man page.
- specified in POSIX (base standard)
- can be applied to a byte range
- associated with an [i-node, pid] pair instead of a file object
- guarantee atomic switch between the locking modes (exclusive and shared)
- work on NFS (on Linux)
The lock acquisition is associated with an [i-node, pid] pair, i.e.:
- file descriptors opened by the same process for the same file share the lock acquisition (even independent file descriptors, e.g. created using two open calls);
- file descriptors opened by different processes don’t share the lock acquisition;
This means that with POSIX record locks, it is possible to synchronize processes, but not threads. All threads belonging to the same process always share the lock acquisition of a file, which means that:
- the lock acquired through some file descriptor by some thread may be released through another file descriptor by another thread;
- when any thread calls close on any descriptor referring to given file, the lock is released for the whole process, even if there are other opened descriptors referring to this file.
This problem is solved by Open file description locks.
lockf function
lockf(3) function is a simplified version of POSIX record locks.
- specified in POSIX (XSI)
- can be applied to a byte range (optionally automatically expanding when data is appended in future)
- associated with an [i-node, pid] pair instead of a file object
- supports only exclusive locks
- works on NFS (on Linux)
Since lockf locks are associated with an [i-node, pid] pair, they have the same problems as POSIX record locks described above.
The interaction between lockf and other types of locks is not specified by POSIX. On Linux, lockf is just a wrapper for POSIX record locks.
Open file description locks (fcntl)
Open file description locks are Linux-specific and combine advantages of the BSD locks and POSIX record locks. They are provided by fcntl(2) , see “Open file description locks (non-POSIX)” section in the man page.
- Linux-specific, not specified in POSIX
- can be applied to a byte range
- associated with a file object
- guarantee atomic switch between the locking modes (exclusive and shared)
- work on NFS (on Linux)
Thus, Open file description locks combine advantages of BSD locks and POSIX record locks: they provide both atomic switch between the locking modes, and the ability to synchronize both threads and processes.
These locks are available since the 3.15 kernel.
The API is the same as for POSIX record locks (see above). It uses struct flock too. The only difference is in fcntl command names:
- F_OFD_SETLK instead of F_SETLK
- F_OFD_SETLKW instead of F_SETLKW
- F_OFD_GETLK instead of F_GETLK
Emulating Open file description locks
What do we have for multithreading and atomicity so far?
- BSD locks allow thread synchronization but don’t allow atomic mode switch.
- POSIX record locks don’t allow thread synchronization but allow atomic mode switch.
- Open file description locks allow both but are available only on recent Linux kernels.
If you need both features but can’t use Open file description locks (e.g. you’re using some embedded system with an outdated Linux kernel), you can emulate them on top of the POSIX record locks.
Here is one possible approach:
Implement your own API for file locks. Ensure that all threads always use this API instead of using fcntl() directly. Ensure that threads never open and close lock-files directly.
In the API, implement a process-wide singleton (shared by all threads) holding all currently acquired locks.
Associate two additional objects with every acquired lock:
Now, you can implement lock operations as follows:
- First, acquire the RW-mutex. If the user requested the shared mode, acquire a read lock. If the user requested the exclusive mode, acquire a write lock.
- Check the counter. If it’s zero, also acquire the file lock using fcntl() .
- Increment the counter.
- Decrement the counter.
- If the counter becomes zero, release the file lock using fcntl() .
- Release the RW-mutex.
This approach makes possible both thread and process synchronization.
Test program
I’ve prepared a small program that helps to learn the behavior of different lock types.
The program starts two threads or processes, both of which wait to acquire the lock, then sleep for one second, and then release the lock. It has three parameters:
lock mode: flock (BSD locks), lockf , fcntl_posix (POSIX record locks), fcntl_linux (Open file description locks)
access mode: same_fd (access lock via the same descriptor), dup_fd (access lock via duplicated descriptors), two_fds (access lock via two descriptors opened independently for the same path)
concurrency mode: threads (access lock from two threads), processes (access lock from two processes)
Below you can find some examples.
Threads are not serialized if they use BSD locks on duplicated descriptors:
But they are serialized if they are used on two independent descriptors:
Threads are not serialized if they use POSIX record locks on two independent descriptors:
But processes are serialized:
Command-line tools
The following tools may be used to acquire and release file locks from the command line:
Provided by util-linux package. Uses flock() function.
There are two ways to use this tool:
run a command while holding a lock:
flock will acquire the lock, run the command, and release the lock.
open a file descriptor in bash and use flock to acquire and release the lock manually:
You can try to run these two snippets in parallel in different terminals and see that while one is sleeping while holding the lock, another is blocked in flock.
Provided by procmail package.
Runs the given command while holding a lock. Can use either flock() , lockf() , or fcntl() function, depending on what’s available on the system.
There are also two ways to inspect the currently acquired locks:
Provided by util-linux package.
Lists all the currently held file locks in the entire system. Allows to perform filtering by PID and to configure the output format.
A file in procfs virtual file system that shows current file locks of all types. The lslocks tools relies on this file.
Mandatory locking
Linux has limited support for mandatory file locking. See the “Mandatory locking” section in the fcntl(2) man page.
A mandatory lock is activated for a file when all of these conditions are met:
- The partition was mounted with the mand option.
- The set-group-ID bit is on and group-execute bit is off for the file.
- A POSIX record lock is acquired.
Note that the set-group-ID bit has its regular meaning of elevating privileges when the group-execute bit is on and a special meaning of enabling mandatory locking when the group-execute bit is off.
When a mandatory lock is activated, it affects regular system calls on the file:
When an exclusive or shared lock is acquired, all system calls that modify the file (e.g. open() and truncate() ) are blocked until the lock is released.
When an exclusive lock is acquired, all system calls that read from the file (e.g. read() ) are blocked until the lock is released.
However, the documentation mentions that current implementation is not reliable, in particular:
- races are possible when locks are acquired concurrently with read() or write()
- races are possible when using mmap()
Since mandatory locks are not allowed for directories and are ignored by unlink() and rename() calls, you can’t prevent file deletion or renaming using these locks.
Example usage
Below you can find a usage example of mandatory locking.
Mount the partition and create a file with the mandatory locking enabled:
Acquire a lock in the first terminal:
Try to read the file in the second terminal:
Источник



