- grep command in Unix/Linux
- Что такое grep и с чем его едят
- What is Grep Command in Linux? Why is it Used and How Does it Work?
- What is grep?
- The interesting story behind creation of grep
- What is a Regular Expression, again?
- A practical example of grep: Matching phone numbers
- Understanding regex, one segment at a time
- Pseudo-code of the Area Code RegEx
- Area Code
- Prefix
- Line Numbers
- Here’s the complete expression again
- Bonus Tip
grep command in Unix/Linux
The grep filter searches a file for a particular pattern of characters, and displays all lines that contain that pattern. The pattern that is searched in the file is referred to as the regular expression (grep stands for globally search for regular expression and print out).
Syntax:
Sample Commands
Consider the below file as an input.
1. Case insensitive search : The -i option enables to search for a string case insensitively in the give file. It matches the words like “UNIX”, “Unix”, “unix”.
Output:
2. Displaying the count of number of matches : We can find the number of lines that matches the given string/pattern
Output:
3. Display the file names that matches the pattern : We can just display the files that contains the given string/pattern.
Output:
4. Checking for the whole words in a file : By default, grep matches the given string/pattern even if it found as a substring in a file. The -w option to grep makes it match only the whole words.
Output:
5. Displaying only the matched pattern : By default, grep displays the entire line which has the matched string. We can make the grep to display only the matched string by using the -o option.
Output:
6. Show line number while displaying the output using grep -n : To show the line number of file with the line matched.
Output:
7. Inverting the pattern match : You can display the lines that are not matched with the specified search sting pattern using the -v option.
Output:
8. Matching the lines that start with a string : The ^ regular expression pattern specifies the start of a line. This can be used in grep to match the lines which start with the given string or pattern.
Output:
9. Matching the lines that end with a string : The $ regular expression pattern specifies the end of a line. This can be used in grep to match the lines which end with the given string or pattern.
10.Specifies expression with -e option. Can use multiple times :
11. -f file option Takes patterns from file, one per line.
12. Print n specific lines from a file: -A prints the searched line and n lines after the result, -B prints the searched line and n lines before the result, and -C prints the searched line and n lines after and before the result.
Syntax:
Example:
Output:
This article is contributed by Akshay Rajput. If you like GeeksforGeeks and would like to contribute, you can also write an article using write.geeksforgeeks.org or mail your article to review-team@geeksforgeeks.org. See your article appearing on the GeeksforGeeks’ main page and help other Geeks.
Please write comments if you find anything incorrect, or you want to share more information about the topic discussed above.
Источник
Что такое grep и с чем его едят
Эта заметка навеяна мелькавшими последнее время на хабре постами двух тематик — «интересные команды unix» и «как я подбирал программиста». И описываемые там команды, конечно, местами интересные, но редко практически полезные, а выясняется, что реально полезным инструментарием мы пользоваться и не умеем.
Небольшое лирическое отступление:
Года три назад меня попросили провести собеседование с претендентами на должность unix-сисадмина. На двух крупнейших на тот момент фриланс-биржах на вакансию откликнулись восемь претендентов, двое из которых входили в ТОП-5 рейтинга этих бирж. Я никогда не требую от админов знания наизусть конфигов и считаю, что нужный софт всегда освоится, если есть желание читать, логика в действиях и умение правильно пользоваться инструментарием системы. Посему для начала претендентам были даны две задачки, примерно такого плана:
— поместить задание в крон, которое будет выполняться в каждый чётный час и в 3 часа;
— распечатать из файла /var/run/dmesg.boot информацию о процессоре.
К моему удивлению никто из претендентов с обоими вопросами не справился. Двое, в принципе, не знали о существовании grep.

Поэтому… Лето… Пятница… Перед шашлыками немного поговорим о grep.
Зная местную публику и дабы не возникало излишних инсинуаций сообщаю, что всё нижеизложенное справедливо для
Это важно в связи с
Для начала о том как мы обычно grep’аем файлы.
Используя cat:
Но зачем? Ведь можно и так:
Или вот так (ненавижу такую конструкцию):
Зачем-то считаем отобранные строки с помощью wc:
Сделаем тестовый файлик:
И приступим к поискам:
Опция -w позволяет искать по слову целиком:
А если нужно по началу или концу слова?
Стоящие в начале или конце строки?
Хотите увидеть строки в окрестности искомой?
Только снизу или сверху?
А ещё мы умеем так
И наоборот исключая эти
Разумеется grep поддерживает и прочие базовые квантификаторы, метасимволы и другие прелести регулярок
Пару практических примеров:
Отбираем только строки с ip:
Работает, но так симпатичнее:
Уберём строку с комментарием?
А теперь выберем только сами ip
Вот незадача… Закомментированная строка вернулась. Это связано с особенностью обработки шаблонов. Как быть? Вот так:
Здесь остановимся на инвертировании поиска ключом -v
Допустим нам нужно выполнить «ps -afx | grep ttyv»
Всё бы ничего, но строка «48798 2 S+ 0:00.00 grep ttyv» нам не нужна. Используем -v
Некрасивая конструкция? Потрюкачим немного:
Также не забываем про | (ИЛИ)
ну и тоже самое, иначе:
Ну и если об использовании регулярок в grep’e помнят многие, то об использовании POSIX классов как-то забывают, а это тоже иногда удобно.
Отберём строки с заглавными символами:
Плохо видно что нашли? Подсветим: 
Ну и ещё пару трюков для затравки.
Первый скорее академичный. За лет 15 ни разу его не использовал:
Нужно из нашего тестового файла выбрать строки содержащие six или seven или eight:
Пока всё просто:
А теперь только те строки в которых six или seven или eight встречаются несколько раз. Эта фишка именуется Backreferences
Ну и второй трюк, куда более полезный. Необходимо вывести строки в которых 504 с обеих сторон ограничено табуляцией.
Ох как тут не хватает поддержки PCRE…
Использование POSIX-классов не спасает:
На помощь приходит конструкция [CTRL+V][TAB]:
Что ещё не сказал? Разумеется, grep умеет искать в файлах/каталогах и, разумеется, рекурсивно. Найдём в исходниках код, где разрешается использование Intel’ом сторонних SFP-шек. Как пишется allow_unsupported_sfp или unsupported_allow_sfp не помню. Ну да и ладно — это проблемы grep’а:
Надеюсь не утомил. И это была только вершина айсберга grep. Приятного Вам чтения, а мне аппетита на шашлыках!
Ну и удачного Вам grep’a!
Источник
What is Grep Command in Linux? Why is it Used and How Does it Work?
If you use Linux for regular work or developing and deploying software, you must have come across the grep command.
In this explainer article, I’ll tell you what is grep command and how does it work.
What is grep?
Grep is a command line utility in Unix and Linux systems. It is used for finding a search patterns in the content of a given file.
With its unusual name, you may have guessed that grep is an acronym. This is at least partially true, but it depends on who you ask.
According to reputable sources, the name is actually derived from a command in a UNIX text editor called ed. In which, the input g/re/p performed a global (g) search for a regular expression (re), and subsequently printed (p) any matching lines.
The grep command does what the g/re/p commands did in the editor. It performs a global research for a regular expression and prints it. It is much faster at searching large files.

This is the official narrative, but you may also see it described as Global Regular Expression (Processor | Parser | Printer). Truthfully, it does all of that.
The interesting story behind creation of grep
Ken Thompson has made some incredible contributions to computer science. He helped create Unix, popularized its modular approach, and wrote many of its programs including grep.
Thompson built grep to assist one of his colleagues at Bell Labs. This scientist’s goal was to examine linguistic patterns to identify the authors (including Alexander Hamilton) of the Federalist Papers. This extensive body of work was a collection of 85 anonymous articles and essays drafted in defense of the United States Constitution. But since these articles were anonymous, the scientist was trying to identify the authors based on linguistic pattern.
The original Unix text editor, ed, (also created by Thompson) wasn’t capable of searching such a large body of text given the hardware limitations of the time. So, Thompson transformed the search feature into a standalone utility, independent of the ed editor.
If you think about it, that means Alexander Hamilton technically helped create grep. Feel free to share this fun fact with your friends at your Hamilton watch party. 🤓
What is a Regular Expression, again?
A regular expression (or regex) can be thought of as kind of like a search query. Regular expressions are used to identify, match, or otherwise manage text.
Regex is capable of much more than keyword searches, though. It can be used to find any kind of pattern imaginable. Patterns can be found easier by using meta-characters. These special characters that make this search tool much more powerful.

It should be noted that grep is just one tool that uses regex. There are similar capabilities across the range of tools, but meta characters and syntax can vary. This means it’s important to know the rules for your particular regex processor.

A practical example of grep: Matching phone numbers
This tool can be intimidating to newbies and experienced Linux users alike. Unfortunately, even a relatively simple pattern like a phone number can result in a «scary» looking regex string.
I want to reassure you that there is no need to panic when you see expressions like this. Once you become familiar with the basics of regex, it can open up a new world of possibilities for your computing.
Cultural note: This example uses US (NANP) conventions for phone numbers. These are 10-digit IDs that are broken up into an area code (3 digits), and a unique 7 digit combination where the first 3 digits correspond to a central telecom office (known as a prefix) and the last 4 are called the line number. So the pattern is AAA-PPP-LLLL.
I’ve created a file called phone.txt and written down 4 common variations of the same phone number. I am going to use grep to recognize the number pattern regardless of the format.
I’ve also added one line that will not conform to the expression to use as a control. The final line 555!123!1234 is not a standard phone number pattern, and will not be returned by the grep expression.
Contents of phone.txt files are:
To «grep» the phone numbers, I am going to write my regex using meta-characters to isolate the relevant data and ignore what I don’t need.
The complete command is going to look like this:
Looks a little intense, right? Let’s break it down into chunks to get a better idea of what is happening.
Understanding regex, one segment at a time
First let’s separate the section of the RegEx that looks for the «area code» in the phone number.
A similar pattern is partially repeated to get the rest of the digits, as well. It’s important to note that the area code is sometimes encapsulated in parentheses, so you need to account for that with the expression here.
The logic of the entire area code section is encapsulated in an escaped set of round braces. You can see that my code starts with \( and ends with \) .
When you use the square brackets 1 , you’re letting grep know that you’re looking for a number between 0 and 9. Similarly, you could use [a-z] to match letters of the alphabet.
The number in the curly brackets <3\>, means that the item in the square braces is matched exactly three times.
Still confused? Don’t get stressed out. You’re going to look at this example in several ways so that you feel confident moving forward.
Let’s try looking at the logic of the area code section in pseudo-code. I’ve isolated each segment of the expression.
Pseudo-code of the Area Code RegEx
- \(
- (3-Digit Number)
- |
- 3-Digit Number
- \)
Hopefully, seeing it like this makes the regex more straightforward. In plain language you are looking for 3-digit numbers. Each digit could be 0-9, and there may or may not be parenthesis around the area code.
Then, there’s this weird bit at the end of our first section.
What does it mean? The \? symbol means «match zero or one of the preceding character». Here, that’s referring to what is in our square brackets [ -] .
In other words, there may or may not be a hyphen that follows the digits.
Area Code
Now, let’s re-build the same block with the actual code. Then, I’ll add the other parts of the expression.
Prefix
To complete the phone number pattern, you can just re-purpose some of your existing code.
You don’t have to be concerned about the parenthesis surrounding the prefix, but you still may or may not have a — between the prefix and the line digits of the phone number.
Line Numbers
The last section of the phone number does not require us to look for any other characters, but you need to update the expression to reflect the extra digit.
That’s it. Now let’s make sure that the expression is contained in quotes to minimize unexpected behaviors.
Here’s the complete expression again
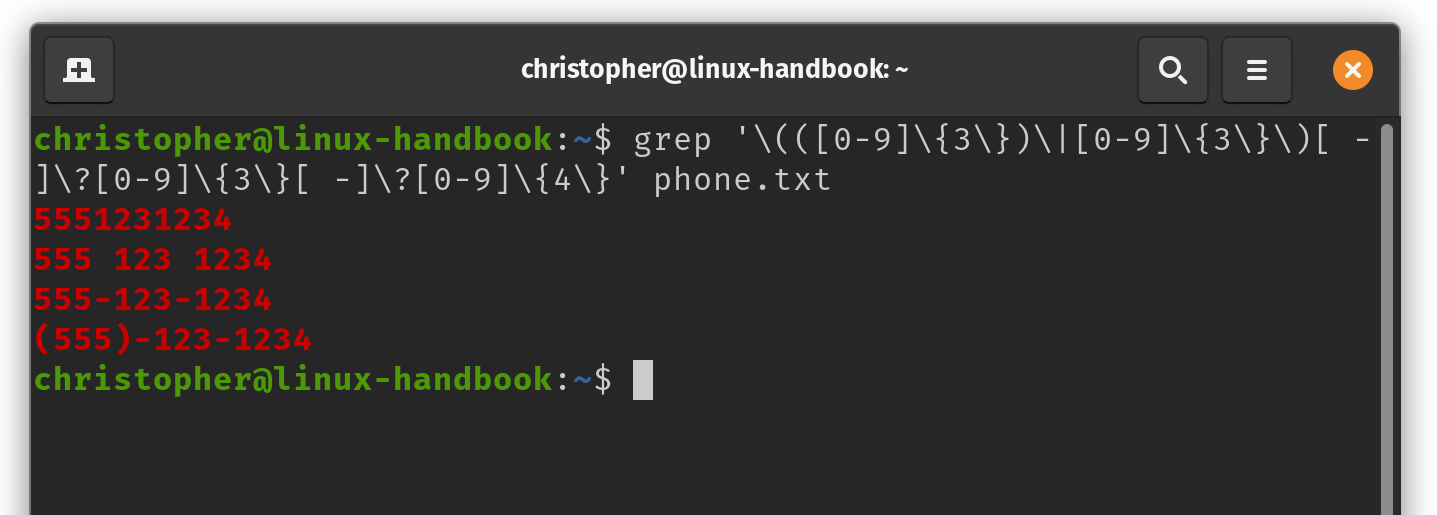
You can see that the results are highlighted in color. This may not be the default behavior on your Linux distribution.

Bonus Tip
If you’d like your results to be highlighted, you could add —color=auto to your command. You could also add this to your shell profile as an alias so that every time you type grep it runs as a grep —color=auto .
I hope you have a better understand of the grep command now. I showed just one example to explain the things. If interested, you may check out this article for more practical examples of the grep command.
Do provide your suggestion on the article by leaving a comment.
Источник



