- LVM on software RAID
- Contents
- Introduction
- Swap space
- Boot loader
- Installation
- Load kernel modules
- Prepare the hard drives
- Partition hard drives
- RAID installation
- Synchronization
- Scrubbing
- LVM installation
- Create physical volumes
- Create the volume group
- Create logical volumes
- Update RAID configuration
- Prepare hard drive
- Configure system
- mkinitcpio.conf
- Conclusion
- Install the bootloader on the Alternate Boot Drives
- Syslinux
- GRUB legacy
- Archive your filesystem partition scheme
- Management
- Записки IT специалиста
- LVM для начинающих. Часть 1. Общие вопросы
- Что такое LVM и для чего он нужен
- LVM и RAID
- Экстенты и способы их отображения
- Управление томами в LVM
LVM on software RAID
This article will provide an example of how to install and configure Arch Linux with Logical Volume Manager (LVM) on top of a software RAID.
Contents
Introduction
![]() This article or section needs language, wiki syntax or style improvements. See Help:Style for reference.
This article or section needs language, wiki syntax or style improvements. See Help:Style for reference.![]()
Although RAID and LVM may seem like analogous technologies they each present unique features. This article uses an example with three similar 1TB SATA hard drives. The article assumes that the drives are accessible as /dev/sda , /dev/sdb , and /dev/sdc . If you are using IDE drives, for maximum performance make sure that each drive is a master on its own separate channel.
![]() This article or section needs language, wiki syntax or style improvements. See Help:Style for reference.
This article or section needs language, wiki syntax or style improvements. See Help:Style for reference.![]()
| LVM Logical Volumes | / | /var | /swap | /home |
| LVM Volume Groups | /dev/VolGroupArray |
| RAID Arrays | /dev/md0 | /dev/md1 |
| Physical Partitions | /dev/sda1 | /dev/sdb1 | /dev/sdc1 | /dev/sda2 | /dev/sdb2 | /dev/sdc2 |
| Hard Drives | /dev/sda | /dev/sdb | /dev/sdc |
Swap space
Many tutorials treat the swap space differently, either by creating a separate RAID1 array or a LVM logical volume. Creating the swap space on a separate array is not intended to provide additional redundancy, but instead, to prevent a corrupt swap space from rendering the system inoperable, which is more likely to happen when the swap space is located on the same partition as the root directory.
Boot loader
This tutorial will use Syslinux instead of GRUB. GRUB when used in conjunction with GPT requires an additional BIOS boot partition.
GRUB supports the default style of metadata currently created by mdadm (i.e. 1.2) when combined with an initramfs, which has replaced in Arch Linux with mkinitcpio. Syslinux only supports version 1.0, and therefore requires the —metadata=1.0 option.
Some boot loaders (e.g. GRUB Legacy, LILO) will not support any 1.x metadata versions, and instead require the older version, 0.90. If you would like to use one of those boot loaders make sure to add the option —metadata=0.90 to the /boot array during RAID installation.
Installation
Obtain the latest installation media and boot the Arch Linux installer as outlined in Getting and installing Arch.
Load kernel modules
Load the appropriate RAID (e.g. raid0 , raid1 , raid5 , raid6 , raid10 ) and LVM (i.e. dm-mod ) modules. The following example makes use of RAID1 and RAID5.
Prepare the hard drives
Each hard drive will have a 200 MiB /boot partition, 2048 MiB /swap partition, and a / partition that takes up the remainder of the disk.
The boot partition must be RAID1; i.e it cannot be striped (RAID0) or RAID5, RAID6, etc.. This is because GRUB does not have RAID drivers. Any other level will prevent your system from booting. Additionally, if there is a problem with one boot partition, the boot loader can boot normally from the other two partitions in the /boot array.
Partition hard drives
We will use gdisk to create three partitions on each of the three hard drives (i.e. /dev/sda , /dev/sdb , /dev/sdc ):
RAID installation
After creating the physical partitions, you are ready to setup the /boot, /swap, and / arrays with mdadm . It is an advanced tool for RAID management that will be used to create a /etc/mdadm.conf within the installation environment.
Create the / array at /dev/md0 :
Create the /swap array at /dev/md1 :
Create the /boot array at /dev/md2 :
Synchronization
After you create a RAID volume, it will synchronize the contents of the physical partitions within the array. You can monitor the progress by refreshing the output of /proc/mdstat ten times per second with:
Further information about the arrays is accessible with:
Once synchronization is complete the State line should read clean . Each device in the table at the bottom of the output should read spare or active sync in the State column. active sync means each device is actively in the array.
Scrubbing
It is good practice to regularly run data scrubbing to check for and fix errors.
To initiate a data scrub:
As with many tasks/items relating to mdadm, the status of the scrub can be queried:
To stop a currently running data scrub safely:
When the scrub is complete, admins may check how many blocks (if any) have been flagged as bad:
The check operation scans the drives for bad sectors and mismatches. Bad sectors are automatically repaired. If it finds mismatches, i.e., good sectors that contain bad data (the data in a sector does not agree with what the data from another disk indicates that it should be, for example the parity block + the other data blocks would cause us to think that this data block is incorrect), then no action is taken, but the event is logged (see below). This «do nothing» allows admins to inspect the data in the sector and the data that would be produced by rebuilding the sectors from redundant information and pick the correct data to keep.
General Notes on Scrubbing
It is a good idea to set up a cron job as root to schedule a periodic scrub. See raid-check AUR which can assist with this.
RAID1 and RAID10 Notes on Scrubbing
Due to the fact that RAID1 and RAID10 writes in the kernel are unbuffered, an array can have non-0 mismatch counts even when the array is healthy. These non-0 counts will only exist in transient data areas where they do not pose a problem. However, since we cannot tell the difference between a non-0 count that is just in transient data or a non-0 count that signifies a real problem. This fact is a source of false positives for RAID1 and RAID10 arrays. It is however recommended to still scrub to catch and correct any bad sectors there might be in the devices.
LVM installation
This section will convert the two RAIDs into physical volumes (PVs). Then combine those PVs into a volume group (VG). The VG will then be divided into logical volumes (LVs) that will act like physical partitions (e.g. / , /var , /home ). If you did not understand that make sure you read the LVM Introduction section.
Create physical volumes
Make the RAIDs accessible to LVM by converting them into physical volumes (PVs) using the following command. Repeat this action for each of the RAID arrays created above.
Confirm that LVM has added the PVs with:
Create the volume group
Next step is to create a volume group (VG) on the PVs.
Create a volume group (VG) with the first PV:
Confirm that LVM has added the VG with:
Create logical volumes
In this example we will create separate / , /var , /swap , /home LVs. The LVs will be accessible as /dev/VolGroupArray/ .
Create a /var LV:
Create a /home LV that takes up the remainder of space in the VG:
Confirm that LVM has created the LVs with:
Update RAID configuration
Since the installer builds the initrd using /etc/mdadm.conf in the target system, you should update that file with your RAID configuration. The original file can simply be deleted because it contains comments on how to fill it correctly, and that is something mdadm can do automatically for you. So let us delete the original and have mdadm create you a new one with the current setup:
Prepare hard drive
Follow the directions outlined the in #Installation section until you reach the Prepare Hard Drive section. Skip the first two steps and navigate to the Manually Configure block devices, filesystems and mountpoints page. Remember to only configure the PVs (e.g. /dev/VolGroupArray/lvhome ) and not the actual disks (e.g. /dev/sda1 ).
Configure system
mkinitcpio.conf
mkinitcpio can use a hook to assemble the arrays on boot. For more information see mkinitcpio Using RAID. Add the mdadm_udev and lvm2 hooks to the HOOKS array in /etc/mkinitcpio.conf after udev .
Conclusion
Once it is complete you can safely reboot your machine:
Install the bootloader on the Alternate Boot Drives
Once you have successfully booted your new system for the first time, you will want to install the bootloader onto the other two disks (or on the other disk if you have only 2 HDDs) so that, in the event of disk failure, the system can be booted from any of the remaining drives (e.g. by switching the boot order in the BIOS). The method depends on the bootloader system you are using:
Syslinux
Log in to your new system as root and do:
Syslinux will deal with installing the bootloader to the MBR on each of the members of the RAID array:
GRUB legacy
Log in to your new system as root and do:
Archive your filesystem partition scheme
Now that you are done, it is worth taking a second to archive off the partition state of each of your drives. This guarantees that it will be trivially easy to replace/rebuild a disk in the event that one fails. See fdisk#Backup and restore partition table.
Management
For further information on how to maintain your software RAID or LVM review the RAID and LVM aritcles.
Источник
Записки IT специалиста
Технический блог специалистов ООО»Интерфейс»
- Главная
- LVM для начинающих. Часть 1. Общие вопросы
LVM для начинающих. Часть 1. Общие вопросы
 Современные системы хранения предъявляют повышенные требования к гибкости управления дисковым пространством и классических дисковых устройств с размещенными на них разделами становится недостаточно. Это привело к созданию многих высокоуровневых инструментов, одним из которых является Менеджер логических томов (Logical volume management) — LVM в Linux. Это простой и мощный инструмент, позволяющий управлять пространством хранения абстрагировавшись от физических устройств и в данной статье мы начнем знакомство с ним.
Современные системы хранения предъявляют повышенные требования к гибкости управления дисковым пространством и классических дисковых устройств с размещенными на них разделами становится недостаточно. Это привело к созданию многих высокоуровневых инструментов, одним из которых является Менеджер логических томов (Logical volume management) — LVM в Linux. Это простой и мощный инструмент, позволяющий управлять пространством хранения абстрагировавшись от физических устройств и в данной статье мы начнем знакомство с ним.
Что такое LVM и для чего он нужен
Давайте начнем с самого начала и посмотрим, как устроена классическая дисковая система, в ее основе лежат физические устройства хранения: жесткие диски, SSD, RAID-массивы и т.д. Каждое физическое устройство содержит логическую разметку — разделы. Каждый раздел может содержать либо файловую систему, либо вложенные разделы. В любом случае общая емкость разделов ограничена емкостью физического устройства. Ниже показана классическая схема такой разметки.
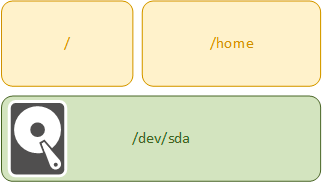 Все это просто, понятно и хорошо работает ровно до тех пор, пока дискового пространства физического диска достаточно. Если же его станет не хватать, то возникнут первые проблемы. Самым простым решением будет добавить еще один физический диск и перенести на него какой-нибудь из разделов, скажем /home, но при этом на первом физическом диске останется свободная область, которую мы уже не сможем использовать для размещения файлов домашней директории.
Все это просто, понятно и хорошо работает ровно до тех пор, пока дискового пространства физического диска достаточно. Если же его станет не хватать, то возникнут первые проблемы. Самым простым решением будет добавить еще один физический диск и перенести на него какой-нибудь из разделов, скажем /home, но при этом на первом физическом диске останется свободная область, которую мы уже не сможем использовать для размещения файлов домашней директории.
Точнее сможем, если смонтируем этот раздел в какую-нибудь вложенную папку, скажем /home/video, но это не решает проблемы, а только добавляет неудобства. Вместо единого дискового пространства мы получаем набор разрозненных сегментов.
Также вы можете столкнуться с ситуацией, когда каждого диска в отдельности не хватает для размещения раздела, хотя их суммарной емкости будет достаточно. Можно, конечно, попробовать объединить их в RAID массив, но это резко снизит гибкость модернизации такой системы, просто так добавить еще один диск к емкости массива уже не получится.
Во всех этих случаях нам на помощь приходит LVM, которая вводит новые уровни абстракции и позволяет работать с логическими томами, не оглядываясь на реальную конфигурацию физических устройств. В LVM существует три уровня абстракции:
- PV, Physical volume, физический том — это физический диск, либо раздел на диске, если мы не можем использовать его целиком.
- VG, Volume group, группа томов — группа томов объединяет в себя физические тома и является следующим уровнем абстракции, представляя собой единое пространство хранения, которое может быть размечено на логические разделы. Эквивалентен обычному диску в классической системе.
- LV, Logical volume, логический том — логический раздел в группе томов, аналогичен обычном разделу, представляет из себя блочное устройство и может содержать файловую систему.
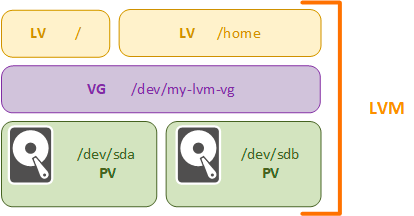 Если говорить упрощенно, то между физическими носителями и логическими разделами у нас появилась дополнительная прослойка в виде группы томов, которая объединяет пространства физических дисков в одно логическое, эквивалентное одному большому диску.
Если говорить упрощенно, то между физическими носителями и логическими разделами у нас появилась дополнительная прослойка в виде группы томов, которая объединяет пространства физических дисков в одно логическое, эквивалентное одному большому диску.
При этом объединять в группу томов мы можем совершенно разные диски, не испытывая ограничений ни по размеру, ни по скорости. При этом мы можем спокойно добавлять в группу томов новые физические устройства, удалять старые, изменять размеры и расположение логических томов и все это в онлайн-режиме.
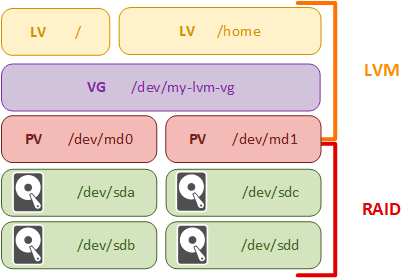
LVM и RAID
Теперь о том, чем LVM не является. Как следует из названия, LVM — это менеджер логических томов, т.е. разметки верхнего уровня, максимально абстрагированной от физических устройств. RAID — это избыточный массив независимых дисков, задача которого — обеспечить избыточность и тем самым обеспечить защиту от отказа одного или нескольких физических дисков. О логической разметке RAID не имеет никакого представления, работая исключительно с физическими устройствами или разделами на них.
Можно ли с помощью LVM реализовать некоторые функции RAID? Можно, но в этом случае либо будут использоваться собственные решения, серьезно уступающие программному RAID Linux (mdraid), либо вызовы будут передаваться модулю md, т.е. тому же самому mdraid.
При этом достаточно сильно пострадает простота и прозрачность управления массивами, что может поставить вас в затруднительное (если не хуже) положение в нештатных ситуациях, особенно если вы не обладаете достаточным опытом работы с LVM.
Поэтому, в строгом соответствии с философией UNIX, мы считаем, что каждый должен выполнять свою задачу и делать это хорошо. Поэтому для создания избыточных дисковых массивов мы будем продолжать использовать программный RAID, а предоставляемые им md-устройства использовать в качестве физических томов LVM.
 Экстенты и способы их отображения
Экстенты и способы их отображения
 Экстенты и способы их отображения
Экстенты и способы их отображенияЕдиницей организации дискового пространства в LVM является экстент — некоторая минимальная область данных, которая может быть организована в составе логического тома. Выделить объем менее одного экстента LVM не может. Размер экстента определяется группой томов и зависит от ее объема, минимальный размер экстента 4 МБ, впоследствии это значение остается постоянным для группы томов на всем протяжении ее существования.
Все входящие в группу томов физические тома разделяются на физические экстенты, логические тома в свою очередь содержат логические экстенты, размеры физических и логических экстентов равны.
При создании логического тома ему выделяется некоторый непрерывный диапазон экстентов, каждому логическому экстенту соответствует физический экстент одного из физических томов. При этом не обязательно все логические экстенты должны соответствовать экстентам одного физического тома либо идти подряд, одному логическому тому могут соответствовать различные наборы физических экстентов с различных физических томов.
Если снова упростить ситуацию, то LVM можно рассматривать как некую таблицу соответствия, в которой записано какой логический экстент относится к какому физическому. Таким образом мы можем иметь логический том, фактически располагающийся на нескольких физических томах, при этом система будет видеть его как одно непрерывное пространство.
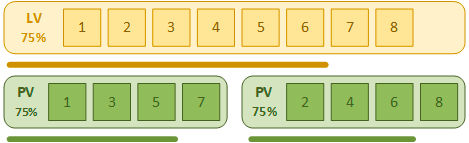
Размещение логических экстентов на физических томах называют отображением и существуют разные алгоритмы для этого. Наиболее простым является линейное отображение, при котором логические экстенты последовательно отображаются на свободные физические. Если физических экстентов одного физического тома не хватает для отображения всех логических экстентов, то начинают использоваться экстенты следующего физического тома.
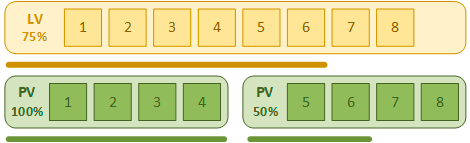 Казалось бы, все понятно, но есть одна особенность. Давайте еще раз посмотрим на схему выше. У нас есть условный логический том содержащий 8 экстентов и два физических, по четыре экстента в каждом. При линейном отображении экстенты распределены между физическими томами последовательно и при заполнении логического тома на 75% мы получим полностью заполненный первый физический том и наполовину заполненный второй.
Казалось бы, все понятно, но есть одна особенность. Давайте еще раз посмотрим на схему выше. У нас есть условный логический том содержащий 8 экстентов и два физических, по четыре экстента в каждом. При линейном отображении экстенты распределены между физическими томами последовательно и при заполнении логического тома на 75% мы получим полностью заполненный первый физический том и наполовину заполненный второй.
Чтение и запись при линейном отображении выполняются последовательно, со скоростью того физического диска, на котором расположен физический экстент. Если в составе группы томов используются диски с разной скоростью доступа, то скорость работы с логическим томом будет меняться, в зависимости от того, на какой диск отображен логический экстент.
Линейное отображение является наиболее простым и удобным в работе, так для расширения логического тома нам достаточно добавить в группу один или несколько физических томов, а затем добавить в логический том дополнительные экстенты, отобразив их на свободные физические экстенты новых дисков. Этого вопроса мы еще коснемся позднее.
Но есть одна серьезная проблема и связана она с SSD, во-первых, твердотельные диски не следует заполнять на 100%, так как это приводит к ухудшению работы сборщика мусора и деградации производительности. Во-вторых, при использовании в составе группы томов нескольких SSD мы получим неравномерную нагрузку на диски и, как следствие, повышенный износ некоторых из них.
Решить эту проблему можно при чередующемся способе отображения (stripe, «полосатое»). В этом случае логические экстенты отображаются между физическими томами в порядке чередования, количество полос чередования определяет количество физических томов, которые будут для этого использоваться. По понятным причинам количество полос не может превышать количество физических томов.
 Чередующееся отображение обеспечивает равномерную нагрузку и заполнение физических дисков, поэтому для твердотельных накопителей следует использовать именно его. Также нетрудно заметить, что такая схема чем-то похожа на RAID 0. Это действительно так и операции чтения-записи можно производить параллельно, достигая более высоких скоростей дисковых операций. По этой причине чередующееся отображение может быть использовано и вместе с HDD в целях повышения производительности тома. Чем больше число полос, тем выше производительность.
Чередующееся отображение обеспечивает равномерную нагрузку и заполнение физических дисков, поэтому для твердотельных накопителей следует использовать именно его. Также нетрудно заметить, что такая схема чем-то похожа на RAID 0. Это действительно так и операции чтения-записи можно производить параллельно, достигая более высоких скоростей дисковых операций. По этой причине чередующееся отображение может быть использовано и вместе с HDD в целях повышения производительности тома. Чем больше число полос, тем выше производительность.
Однако данный способ накладывает свои ограничения, для расширения тома мы должны использовать количество дисков кратное числу полос. Кроме того, чередование будет производиться только внутри группы дисков, для лучшего понимания этого момента обратите внимание на схему:
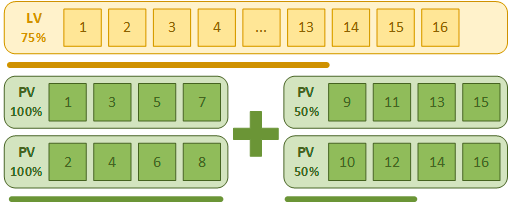 Мы расширили существующий логический том с 8 до 16 экстентов. При этом первые 8 экстентов как чередовались между первыми двумя физическими томами, так и продолжили чередоваться. А следующие 8 экстентов стали чередоваться между двумя добавленными физическими томами. Таким образом при заполнении логического тома сначала будут заполнены первые два физических диска, а только затем начнет заполняться вторая пара. Кроме того, если речь идет о твердотельниках, первая пара дополнительно будет испытывать повышенную нагрузку.
Мы расширили существующий логический том с 8 до 16 экстентов. При этом первые 8 экстентов как чередовались между первыми двумя физическими томами, так и продолжили чередоваться. А следующие 8 экстентов стали чередоваться между двумя добавленными физическими томами. Таким образом при заполнении логического тома сначала будут заполнены первые два физических диска, а только затем начнет заполняться вторая пара. Кроме того, если речь идет о твердотельниках, первая пара дополнительно будет испытывать повышенную нагрузку.
Фактически мы получили линейное отображение на две пары физических дисков. Поэтому расширять чередующиеся массивы на твердотельных накопителях не следует. Правильным решением будет создание нового тома с большим числом полос.
 Несомненным достоинством LVM является то, что при должном опыте и знаниях том можно расширить и с изменением числа полос полностью в онлайн-режиме, т.е. не останавливая работы хранилища.
Несомненным достоинством LVM является то, что при должном опыте и знаниях том можно расширить и с изменением числа полос полностью в онлайн-режиме, т.е. не останавливая работы хранилища.
Управление томами в LVM
Как мы уже говорили, LVM позволяет гибко управлять дисковым пространством без привязки к физическим накопителям, это позволяет добавлять, удалять или менять физические диски без перерыва в работе хранилища, разве что на время физической замены оборудования. Рассмотрим несколько примеров.
Начнем с наиболее распространенного сценария — расширения. Количество данных обычно только растет и свободного места начинает не хватать. В классической дисковой системе нам потребуется либо заменить текущий диск диском большего объема, либо перенести часть данных на другой раздел.
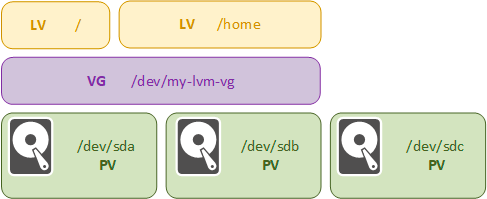
LVM позволяет добавить один или несколько дисков меньшей емкости, расширив логический том за счет их пространства. Прежде всего нам следует добавить новые физические диски — физические тома по терминологии LVM — в группу томов. Таким образом у нас появятся дополнительные свободные физические экстенты. После мы просто добавим в логический том нужное количество экстентов, которые LVM отобразит на физические экстенты новых дисков, тем самым увеличив размер тома. Останется только увеличить размер файловой системы.
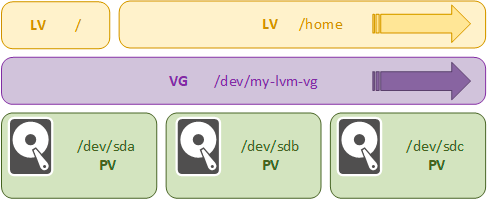 Другой довольно распространенный сценарий — замена оборудования. При большом объеме хранящихся данных это может быть не простой задачей. Но LVM снова придет на помощь. Точно также добавляем новые физические тома в группу томов и запускаем специальную операцию по переносу физических экстентов с одного физического тома на другие. Единственное условие — группа томов должна содержать нужное количество свободных экстентов, количество и размер новых дисков роли не играют.
Другой довольно распространенный сценарий — замена оборудования. При большом объеме хранящихся данных это может быть не простой задачей. Но LVM снова придет на помощь. Точно также добавляем новые физические тома в группу томов и запускаем специальную операцию по переносу физических экстентов с одного физического тома на другие. Единственное условие — группа томов должна содержать нужное количество свободных экстентов, количество и размер новых дисков роли не играют.
Перемещение может занять длительное время, но хранилище при этом остается доступным, разве что несколько снизится производительность. По окончанию переноса экстентов просто выводим нужный физический том из группы томов и удаляем из LVM, теперь его можно физически изъять из сервера в любое подходящее для этого время.
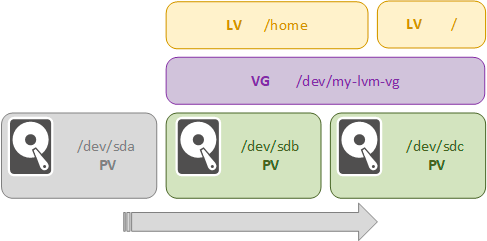 Обратите внимание, что в отличие от дисковых утилит, которые работают на уровне разделов, LVM перемещает именно физические экстенты и изменяет сопоставление отображения для логических томов. Таким образом если на диске sda (по схеме) у нас находился корневой раздел и часть /home, то именно эти части и будут перенесены на новый диск, перемещать раздел полностью нет никакой необходимости, даже если перемещаемые экстенты отображены куда-нибудь в середину логического тома.
Обратите внимание, что в отличие от дисковых утилит, которые работают на уровне разделов, LVM перемещает именно физические экстенты и изменяет сопоставление отображения для логических томов. Таким образом если на диске sda (по схеме) у нас находился корневой раздел и часть /home, то именно эти части и будут перенесены на новый диск, перемещать раздел полностью нет никакой необходимости, даже если перемещаемые экстенты отображены куда-нибудь в середину логического тома.
Данный материал является обзорным и предназначен для формирования общего понимания структуры LVM и принципов его работы. Поэтому мы сознательно оставили за кадром многие иные возможности LVM, такие как снимки или тонкие тома. В дальнейших материалах мы будем рассматривать практическую работу с LVM также от простого к сложному, потому как решаемые задачи не должны опережать имеющиеся навыки и знания, особенно в такой ответственной области как системы хранения.
Помогла статья? Поддержи автора и новые статьи будут выходить чаще:

Или подпишись на наш Телеграм-канал: 
Источник



