- Windows 1251 или unicode
- Таблица кодов кириллицы в Unicode, UTF-8 и Windows-1251
- Что такое кодировка текста? Юникод и кодировки Utf-8, ANSI, Windows-1251
- Краткая история кодировок:
- Отличие utf-8 и windows 1251
- О разнице между двумя кодировками utf-8 и windows 1251
- О кодировках utf-8 и windows 1251
- Чем отличаются utf-8 и windows 1251
- Что такое кодировка windows 1251
- Что такое кодировка UTF-8
- Пример вывода текста в кодировках utf-8 латиницы
- Чем отличается текст в кодировках utf-8 и windows 1251
- Пример вывода текста в кодировках utf-8 кириллицы
- Пример отличия в кодировках utf-8 и windows 1251
- Что делать, если функция для кириллицы на utf-8 не работают?
Windows 1251 или unicode
БлогNot. Таблица кодов кириллицы в Unicode, UTF-8 и Windows-1251
Таблица кодов кириллицы в Unicode, UTF-8 и Windows-1251
Во-первых, напомню, что Юникод — не кодировка, а стандарт кодирования, кодировки — это UTF-8, UTF-16 и т.д., но, в силу инерции, разработчики и пользователи часто говорят о «кодировке Юникод», имея в виду распространённую именно в их деревне форму представления символов 🙂
Во-вторых, на самом деле кодирование там довольно замудрённое, возьмём, скажем русскую заглавную «Ж».
Представляемые в Юникоде символы кодируются целыми числами без знака, их можно называть «кодами символов Unicode».
Так, для буквы «Ж» Unicode = 104610 или 041616 или 10000 0101102. Unicode в двоичном виде разбивается на две части: пять левых бит и шесть правых. Левая часть в старших разрядах дополняется до байта признаком 110 двухбайтного кода UTF-8, получаем 11010000. К правой части в старших разрядах приписываются два бита 10 признака продолжения многобайтного кода, получаем 10010110. Окончательно код буквы «Ж» в UTF-8 будет иметь вид 11010000 100101102 или D0 9616.
Именно последний код мы увидим в любом 16-ричном вьюере файла, например, создав в текстовом редакторе файл со словом «Жора» и сохранив его в UTF-8 (только не из Блокнотика Windows, который добавит в начало файла 3-байтовую метку BOM):
То есть, каждая буква кодируется как бы дважды, сначала в 11-битный Unicode, затем в 16-битный UTF-8.
Ниже приведена таблица кодов кириллицы в Unicode, UTF-8 и однобайтовой кодировке Windows-1251.
| Символ | Unicode | UTF-8 | Windows-1251 | ||
|---|---|---|---|---|---|
| 16-ричн. | 10-тичн. | 16-ричн. | 10-тичн. | ||
| А | 0410 | 1040 | D090 | 208 144 | 192 |
| Б | 0411 | 1041 | D091 | 208 145 | 193 |
| В | 0412 | 1042 | D092 | 208 146 | 194 |
| Г | 0413 | 1043 | D093 | 208 147 | 195 |
| Д | 0414 | 1044 | D094 | 208 148 | 196 |
| Е | 0415 | 1045 | D095 | 208 149 | 197 |
| Ж | 0416 | 1046 | D096 | 208 150 | 198 |
| З | 0417 | 1047 | D097 | 208 151 | 199 |
| И | 0418 | 1048 | D098 | 208 152 | 200 |
| Й | 0419 | 1049 | D099 | 208 153 | 201 |
| К | 041A | 1050 | D09A | 208 154 | 202 |
| Л | 041B | 1051 | D09B | 208 155 | 203 |
| М | 041C | 1052 | D09C | 208 156 | 204 |
| Н | 041D | 1053 | D09D | 208 157 | 205 |
| О | 041E | 1054 | D09E | 208 158 | 206 |
| П | 041F | 1055 | D09F | 208 159 | 207 |
| Р | 0420 | 1056 | D0A0 | 208 160 | 208 |
| С | 0421 | 1057 | D0A1 | 208 161 | 209 |
| Т | 0422 | 1058 | D0A2 | 208 162 | 210 |
| У | 0423 | 1059 | D0A3 | 208 163 | 211 |
| Ф | 0424 | 1060 | D0A4 | 208 164 | 212 |
| Х | 0425 | 1061 | D0A5 | 208 165 | 213 |
| Ц | 0426 | 1062 | D0A6 | 208 166 | 214 |
| Ч | 0427 | 1063 | D0A7 | 208 167 | 215 |
| Ш | 0428 | 1064 | D0A8 | 208 168 | 216 |
| Щ | 0429 | 1065 | D0A9 | 208 169 | 217 |
| Ъ | 042A | 1066 | D0AA | 208 170 | 218 |
| Ы | 042B | 1067 | D0AB | 208 171 | 219 |
| Ь | 042C | 1068 | D0AC | 208 172 | 220 |
| Э | 042D | 1069 | D0AD | 208 173 | 221 |
| Ю | 042E | 1070 | D0AE | 208 174 | 222 |
| Я | 042F | 1071 | D0AF | 208 175 | 223 |
| а | 0430 | 1072 | D0B0 | 208 176 | 224 |
| б | 0431 | 1073 | D0B1 | 208 177 | 225 |
| в | 0432 | 1074 | D0B2 | 208 178 | 226 |
| г | 0433 | 1075 | D0B3 | 208 179 | 227 |
| д | 0434 | 1076 | D0B4 | 208 180 | 228 |
| е | 0435 | 1077 | D0B5 | 208 181 | 229 |
| ж | 0436 | 1078 | D0B6 | 208 182 | 230 |
| з | 0437 | 1079 | D0B7 | 208 183 | 231 |
| и | 0438 | 1080 | D0B8 | 208 184 | 232 |
| й | 0439 | 1081 | D0B9 | 208 185 | 233 |
| к | 043A | 1082 | D0BA | 208 186 | 234 |
| л | 043B | 1083 | D0BB | 208 187 | 235 |
| м | 043C | 1084 | D0BC | 208 188 | 236 |
| н | 043D | 1085 | D0BD | 208 189 | 237 |
| о | 043E | 1086 | D0BE | 208 190 | 238 |
| п | 043F | 1087 | D0BF | 208 191 | 239 |
| р | 0440 | 1088 | D180 | 209 128 | 240 |
| с | 0441 | 1089 | D181 | 209 129 | 241 |
| т | 0442 | 1090 | D182 | 209 130 | 242 |
| у | 0443 | 1091 | D183 | 209 131 | 243 |
| ф | 0444 | 1092 | D184 | 209 132 | 244 |
| х | 0445 | 1093 | D185 | 209 133 | 245 |
| ц | 0446 | 1094 | D186 | 209 134 | 246 |
| ч | 0447 | 1095 | D187 | 209 135 | 247 |
| ш | 0448 | 1096 | D188 | 209 136 | 248 |
| щ | 0449 | 1097 | D189 | 209 137 | 249 |
| ъ | 044A | 1098 | D18A | 209 138 | 250 |
| ы | 044B | 1099 | D18B | 209 139 | 251 |
| ь | 044C | 1100 | D18C | 209 140 | 252 |
| э | 044D | 1101 | D18D | 209 141 | 253 |
| ю | 044E | 1102 | D18E | 209 142 | 254 |
| я | 044F | 1103 | D18F | 209 143 | 255 |
| Символы вне общего правила | |||||
| Ё | 0401 | 1025 | D081 | 208 129 | 168 |
| ё | 0451 | 1105 | D191 | 209 145 | 184 |
23.09.2018, 12:37; рейтинг: 43095
Что такое кодировка текста? Юникод и кодировки Utf-8, ANSI, Windows-1251

Часто в веб-программировании и вёрстке html-страниц приходится думать о кодировке редактируемого файла — ведь если кодировка выбрана неверная, то есть вероятность, что браузер не сможет автоматически её определить и в результате пользователь увидит т.н. «кракозябры».
Возможно, вы сами видели на некоторых сайтах вместо нормального текста непонятные символы и знаки вопроса. Всё это возникает тогда, когда кодировка html-страницы и кодировка самого файла этой страницы не совпадают.
Вообще, что такое кодировка текста? Это просто набор символов, по-английски «charset » (character set). Нужна она для того, чтобы текстовую информацию преобразовывать в биты данных и передавать, например, через Интернет.
Собственно, основные параметры, которыми различаются кодировки — это количество байтов и набор спец.символов, в которые преобразуется каждый символ исходного текста.
Краткая история кодировок:
Одной из первых для передачи цифровой информации стало появление кодировки ASCII — American Standard Code for Information Interchange — Американская стандартная кодировочная таблица, принятая Американским национальным институтом стандартов — American National Standards Institute (ANSI).
В этих аббревиатурах можно запутаться Для практики же важно понимать, что исходная кодировка создаваемых текстовых файлов может не поддерживать все символы некоторых алфавитов (к примеру, иероглифы), потому идёт тенденция к переходу к т.н. стандарту Юникод (Unicode), который поддерживает универсальные кодировки — Utf-8, Utf-16, Utf-32 и др.
Самая популярная из кодировок Юникода — кодировка Utf-8. Обычно в ней сейчас верстаются страницы сайтов и пишутся разные скрипты. Она позволяет без проблем отображать различные иероглифы, греческие буквы и прочие мыслимые и немыслимые символы (размер символа до 4-х байт). В частности, все файлы WordPress и Joomla пишутся именно в этой кодировке. А также некоторые веб-технологии (в частности, AJAX) способны нормально обрабатывать только символы utf-8.
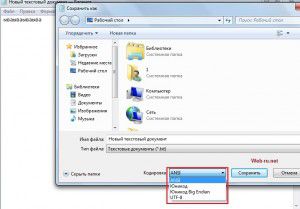
Установка кодировок текстового файла при создании его обычным блокнотом. Кликабельно
В Рунете же ещё можно встретить сайты, написанные с расчётом на кодировку Windows-1251 (или cp-1251). Это специальная кодировка, предназначенная специально для кириллицы.
Почему вообще необходимо иметь представление о разных кодировках? Дело в том, что нередко на том же WordPress можно встретить, например, в Footer’е знаки вопроса вместо нормального текста. Это просто говорит о том, что php-файл Footer’а сохранён в одной кодировке, а в заголовке html-страницы указана совсем другая кодировка. Прочитайте — как сменить кодировку файла и что в этом поможет.
Отличие utf-8 и windows 1251
Поддержи проект. 
Отличие utf-8 и windows 1251. Рассмотрим, чем отличаются две кодировки «utf-8 и windows 1251» в теории и на практике. И как победить некоторые проблемы для кириллицы в utf-8!?
О разнице между двумя кодировками utf-8 и windows 1251
О кодировках utf-8 и windows 1251
Самое главное. что нас интересует, как и меня — в чем же отличие кодировок utf-8 и windows 1251. И отличается только кириллица!
Чем отличаются utf-8 и windows 1251
UTF-8 — это много-байтовая кодировка, а Windows- 1251 однобайтовая. И более того, отличие только в кириллице.
Количество байтов кириллицы в UTF-8 будет в 2 раза больше, чем 1). латиницы в UTF-8 и 2). латиницы + кириллицы в Windows- 1251 → пример
Главное отличие кодировок – это используемый набор символов. В UTF-8 гораздо больше количество символов возможно представить, чем в Windows- 1251. Кодировка Windows- 1251 однобайтовая, т.е. представить в ней можно только 255 символов. Для кириллицы, впрочем, этого вполне достаточно, именно поэтому однобайтовые кодировки до сих пор так массово применяются.
Что такое кодировка windows 1251
Windows-1251 – набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста; она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
Что такое кодировка UTF-8
UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (©), то вам не нужно искать особый шрифт или же изображать символов в графическом формате.
Пример вывода текста в кодировках utf-8 латиницы
А если вы еще и поняли о чем идет речь, то вы вообще Эйнштейн!  , то и смысла особого вам читать дальше нет.
, то и смысла особого вам читать дальше нет.
А для всех остальных продолжим.
Чем отличается текст в кодировках utf-8 и windows 1251
Теория — это конечно классно и круто, но как обстоит дело на практике!
Как показать отличие двух кодировок!?
У нас на сайте основная кодировка utf-8, и мы не напрягаясь можем посмотреть, что творится с текстом в этой кодировке!
Нам понадобится какой-то текст на латинице:
И. нам нужно такое слово, чтобы имело одинаковое количество букв в слове, ну пусть это будет моё имя.
Пусть это будет слово — «Marat!»
Далее нам потребуется функция var_dump.
И выведем прямо здесь вот такую конструкцию :
Что мы здесь можем прочитать!?
Что это строка, и что в ней 5 элементов.
Пример вывода текста в кодировках utf-8 кириллицы
Теперь, проделаем тоже самое со строкой на кириллице:
У нас все таже кодировка utf-8.
Но теперь нам понадобится текст на кириллице:
Пусть это будет слово — «Марат!»
И выведем прямо здесь вот такую конструкцию :
И что мы здесь видим!?
Что количество элементов в строке 10. Если вы читали теорию внимательно, то вот вам показатель того, что одна буква состоит из двух символов, а латиницы это не касается.
Поэтому, и возникают проблемы с текстов в кодировке utf-8 кириллицы, множество функций тупо не работают.
Как пример. как-то я задолбался со strtolower в utf-8 для кириллицы, что решил написать собственную функцию strtolower, чтобы каждый раз не городить этажерку из нескольких функций.
Пример отличия в кодировках utf-8 и windows 1251
Если вы поленились прочитать два верхних пункта, то ещё раз выведем результаты вывода текста на латинице и на кириллице с одним количеством букв.
Результат вывода var_dump(‘Marat’); :
string(5) «Marat»
Результат var_dump(‘Марат’); :
string(10) «Марат»
Что делать, если функция для кириллицы на utf-8 не работают?
Поскольку я давно занимаюсь сайтами, то могу сказать, что на самом деле таких случаев не так много, когда нужна какая-то специальная функция для обработки кириллицы на utf-8.
Но если уж она возникала, то есть несколько вариантов решения!
Это функции с приставкой «mb_», естественно надо проверять, работает ли она у вас на хостинге.
Второй вариант, это написать собственную функцию, которая будет работать и для латиницы и кириллицы? как это я показал на функции strtolower
Пусть это будет функция str_split и её аналог mb_str_split



