- Backup and Restore of Data Deduplication-Enabled Volumes
- Optimized Backup
- Incremental Optimized Backup
- Full Volume Restore from Optimized Backup
- Selective Restore from Optimized Backup
- Selective Partial Volume Restore to Newly Formatted Volume
- Selective Restore from a Data Deduplication-Enabled Backup Store
- Recalling a File to Disk
- Nonoptimized Backup and Restore
- Incremental Nonoptimized Backup
- The Deduplication VSS Writer
- Windows backup with deduplication
- Что такое дедупликация данных?
- Плюсы и минусы дедупликации
- Плюсы:
- Минусы:
- Что нового в дедупликации Windows Server 2019
- Виды дедупликации
- Механизм работы дедупликации
- Эффективность дедупликации
- Инструменты управления дедупликацией
- Установка компонента дедупликации через «Диспетчер серверов»
- Установка компонента дедупликации через PowerShell
- Установка компонента дедупликации через Windows Admin Center
- Включение и настройка дедупликации из GUI интерфейса
- Включение и настройка дедупликации через PowerShell
- Как отключить дедупликацию Windows
Backup and Restore of Data Deduplication-Enabled Volumes
The data deduplication feature enables backup applications to perform optimized backup and restore of volumes that are enabled for data deduplication. There are also situations where it is preferable to perform nonoptimized backup and restore.
In addition to reading this documentation, you should also study the DedupBackupRestore sample, which is useful for understanding multiple restore scenarios.
Optimized Backup
In optimized backup, the backup application does the following:
- Uses a shadow copy of the optimized volume.
- Specifies the FILE_FLAG_OPEN_REPARSE_POINT flag when opening the data deduplication-optimized files.
- Copies the optimized files (reparse points) and chunk store container files as-is from the shadow copy to the backup store.
In many cases, such as a full volume backup (either block-level or file-level), performing an optimized backup will result in a smaller, faster backup than an unoptimized backup. In these cases the backup will be smaller, because the total size of the optimized files (reparse points), non-optimized files (not in-policy) and data deduplication store container files is significantly smaller than the full logical size of the volume. Optimized backups are faster, because there is less I/O (smaller backup) and because the optimized files are not «rehydrated» during the file copy operations. Selective backup, in which most of the volume is being backed up, may also benefit from using the optimized backup approach, if the logical size of the selected files is greater than the physical size of the selected files plus the chunk store files.
Incremental Optimized Backup
A backup application can perform an incremental optimized backup as follows:
- Back up only the changed user files, including reparse points that were created, modified, or deleted since the previous backup.
- Back up the changed chunk store container files. Remember that new chunks are appended to the current chunk store container. When its size reaches about 1 GB, that container file is sealed and a new container file is created. Therefore, the data deduplication optimization job usually results in incremental changes to the chunk store— most files are untouched, some are appended, and some new ones may be created.
- Because the data deduplication optimization job appends chunks to the chunk store container, backup applications may benefit from an incremental backup at the sub-file level, one that backs up new and modified file ranges instead of entire files.
Full Volume Restore from Optimized Backup
File-level full volume restore can and should be performed in an optimized manner by essentially reversing the procedure described in the Optimized Backup section. The complete set of data deduplication metadata and container files are restored, then the complete set of data deduplication reparse points are restored, followed by restore of all non-deduplicated files. Restoring volumes in this manner has the advantage of faster recovery time as compared to full-volume restore from a nonoptimized backup store because the amount of copied data is much smaller. Also, the size of the restored data in an optimized full volume restore is known to fit on a volume of the original size. On the other hand, restoring to the original or equivalently-sized volume from a nonoptimized backup will likely reach a disk-full condition because the files will be replaced at their full logical (non-deduplicated) size.
Block-level restore from an Optimized Backup is automatically an optimized restore because the restore occurs underneath data deduplication, which works at the file level.
It is recommended to always perform full volume restore to a freshly formatted volume of equivalent or greater size than the original volume. The target volume can be the original reformatted volume or a freshly created volume. The volume may contain files, but it might not contain a data deduplication chunk store. If the target volume already has a data deduplication chunk store, then you should follow the guidelines for selective restore below, or stage the restore by restoring to an alternate location that does not have a deduplication chunk store.
Note that full volume restore procedures do not need to use the Data Deduplication Backup/Restore API.
Selective Restore from Optimized Backup
Selective restore from an optimized backup can be done by using one of the following approaches.
- Selective partial volume restore to a newly formatted volume
- Selective restore from a data deduplication-enabled backup store
- Selective File Restore Using Data Deduplication Backup/Restore API
Selective Partial Volume Restore to Newly Formatted Volume
This approach is very similar to the file-level full volume restore described above where only a subset of the data deduplication reparse points are restored back to a freshly formatted volume. Note that this approach requires that all chunk store files be copied to the new volume. This approach is appropriate if most of the volume is being restored. The application can make a calculated decision about whether this is an appropriate technique by comparing the size of the data deduplication store files plus physical size of all the restored files to the total logical size of the target restore file set.
Selective Restore from a Data Deduplication-Enabled Backup Store
If the backup store is located on a volume enabled with data deduplication, both the backup store and the original volume are optimized. (Note that the backup server must be Windows ServerВ 2012 or later, and the backup volume must be an NTFS volume.) In this case, the backup application can simply copy the files as normal files back to the target volume. The files will be rehydrated in memory from the backup store, so the application will be subjected to increased I/O latency while reading the backup store. If the file on the target volume is missing, or has been fully recalled from the data deduplication store, there will be no increased latency on the target volume. However, to be sure, it is good practice to first delete the file, if it exists, from the target volume before restoring the file with this approach.
Recalling a File to Disk
To recall a file to disk programmatically, use one of the following methods:
- Open the file by creating a memory mapped writable section.
- Open the file inside a TxF transaction.
Nonoptimized Backup and Restore
In nonoptimized backup and restore, the backup application does not use the Data Deduplication Backup/Restore API.
The backup application opens the files and copies them without specifying the FILE_FLAG_OPEN_REPARSE_POINT flag.
The optimized files are copied to the backup volume as normal files, not as optimized files. The conversion from optimized file to normal file is performed transparently in memory by the data deduplication feature when the backup application copies the files.
Chunk store files should be excluded from the backup.
Restore from such a backup store is a normal file copy operation.
The size of the data in a nonoptimized backup is recommended to be much larger than the original optimized volume, because of the space savings from data deduplication. A full volume restore from a nonoptimized backup will usually not fit on the original or equivalently sized volume.
Nonoptimized backup is normally used only for the following:
- Selective backup of a small portion of the file on the volume, where the logical size of the selected files is smaller than the physical size of the optimized files plus the chunk store container files.
- To support restoring a Windows ServerВ 2012 or later backup to an earlier version of Windows.
- To support restoring a Windows ServerВ 2012 or later backup to a non-Windows computer.
Incremental Nonoptimized Backup
A backup application can perform an incremental optimized backup as follows:
- Back up any changed user files.
- Consider skipping reparse point changes. (These are marked with the USN_SOURCE_DATA_MANAGEMENT flag.)
- In unoptimized backup, the data deduplication chunk store is excluded, therefore changes to chunk store files can be ignored.
The Deduplication VSS Writer
The deduplication VSS writer reports two components for each volume that contains a deduplication chunk store:
| Component name | Component file location |
|---|---|
| «Chunk Store» | \System Volume Information\Dedup\ChunkStore\* |
| «Dedup Configuration» | \System Volume Information\Dedup\Settings\* |
Both components are marked as selectable-for-backup and selectable-for-restore. These components must be treated as follows in the backup:
- In an optimized volume backup, both components must be backed up.
- In a non-optimized volume backup, the «Chunk Store» component must be excluded.
Because deduplication is crash-consistent, the deduplication writer does not participate in Freeze events.
The deduplication writer does not participate in restore.
The deduplication schedules for the computer or cluster are reported by the Task Scheduler Writer, not the deduplication writer.
This writer is an in-box writer for Windows Server operating system versions; it does not ship in Windows Client.
The writer name string for this writer is «Dedup Writer».
The writer ID for the deduplication writer is 41DB4DBF-6046-470E-8AD5-D5081DFB1B70.
This writer’s usage type is VSS_UT_SYSTEMSERVICE, because deduplication’s ddpvssvc service is a system service.
Its backup schema includes the VSS_BS_INDEPENDENT_SYSTEM_STATE flag, because it doesn’t depend on system state.
Its backup schema also includes the VSS_BS_WRITER_SUPPORTS_NEW_TARGET flag, because it supports restoring to a different volume.
All components have the VSS_CF_NOT_SYSTEM_STATE flag set, because they are not part of system state.
All temporary and instance-related files are excluded from backup.
Windows backup with deduplication
 Добрый день! Дорогой читатель, я рад что ты вновь посетил один из крупнейших IT блогов рунета Pyatilistnik.org. Не так давно мы разобрали чистую установку Windows Server 2019, научились устанавливать в ней роли и компоненты. Время идет и ваш сервер может накопить большой объем данных, ресурсов на расширение может не быть, а выкручиваться как-то нужно, вот для таких ситуаций есть заумное слово дедупликация. В данном посте мы подробно разберем, что из себя представляет дедупликация данных в Windows Server 2019, что нового там появилось, ну и конечно, как все это настраивается и управляется. Уверен, что данный материал по самой новой серверной платформе будет многим полезен и актуален.
Добрый день! Дорогой читатель, я рад что ты вновь посетил один из крупнейших IT блогов рунета Pyatilistnik.org. Не так давно мы разобрали чистую установку Windows Server 2019, научились устанавливать в ней роли и компоненты. Время идет и ваш сервер может накопить большой объем данных, ресурсов на расширение может не быть, а выкручиваться как-то нужно, вот для таких ситуаций есть заумное слово дедупликация. В данном посте мы подробно разберем, что из себя представляет дедупликация данных в Windows Server 2019, что нового там появилось, ну и конечно, как все это настраивается и управляется. Уверен, что данный материал по самой новой серверной платформе будет многим полезен и актуален.
Что такое дедупликация данных?
Небольшое погружение в текущий цифровой мир. В 21 веке основной вызов перед цифровой экономикой, миром, это огромные объемы информации (Big Data), который генерируется каждую минуту. На одном только Youtube пользователи каждый день заливают сотни тысяч роликов, и на конец 2018 года, только на данном сервисе общий объем занимаемого дискового пространства занимает 11 петтабайт. Прибавьте к этому активно развивающиеся социальные сети, сервисы с просмотром онлайн видео, порно индустрия и многое другое. Компании активно переносят свои сервисы в облачные или виртуальные среды. Из всего этого видно, что объемы данных растут в геометрической прогрессии.
На текущий момент основные производители жестких дисков, технологически не успевают за нуждами людей, сервисов в необходимом объеме дисков и уперлись в жалкие 10-12 ТБ на один HDD.Если рассматривать малый и средний бизнес, то у них в большинстве случаев просто нет возможности в покупке новых серверов или систем хранения данных, которые помогли бы им увеличить объем своих дисковых массивов. Именно борясь с данной проблемой люди придумали концепцию дедупликации.

Дедупликация — это метод сокращения потребностей в хранении данных за счет устранения избыточных или дублирующих данных в вашей среде хранения. На носителе хранится только одна, уникальная копия данных, а избыточные или дублированные данные заменяются указателем на уникальную копию данных, если проще, то ссылкой на них.
Таким образом, он просматривает данные на уровне подфайлов (т.е. блоков) и пытается определить, есть ли данные уже. Если это не так, он хранит его. Если он видел его ранее, то он гарантирует, что он сохраняется только один раз, а все другие ссылки на эти дубликаты данных являются просто указателями.
По такому примеру построен дистрибутив всем известной операционной системы Windows 10, где на одном ISO Образе могут быть многие редакции: домашняя, профессиональная, максимальная, у каждой из них по сути одни и те же установочные файлы, а так как это так, то нет смысла хранить на дистрибутиве все эти версии одного и того же, в данном случае имеется только одна копия, и некоторое количество ссылок-указателей на него. Дедупликация делает все то же самое.
Еще очень распространенный пример, это сервис youtube, где есть одно оригинальное видео, которое лежит на дисковом пространстве, все остальные перезалитые ролики, просто ведут на оригинал по ссылке.
Плюсы и минусы дедупликации
Перед тем,как я опишу сам процесс дудупликации, я бы хотел отметить его положительные и отрицательные стороны.
Плюсы:
- Сжатие данных дает малым и средним предприятиям большую выгоду, поскольку они могут увеличить пространство на своих текущих устройствах хранения, удалив дублирующиеся данные.
- Меньшее количество данных может быть скопировано быстрее, что приводит к меньшим окнам резервного копирования, меньшим целевым точкам восстановления (RPO) и меньшим целевым показателям времени восстановления (RTO)
- Дедупликация данных ускоряет процессы резервного копирования, репликации и аварийного восстановления.
- Дедупликация может привести к значительной экономии времени, ресурсов и бюджета. Бюджет всегда стоял краеугольным камнем преткновения для бизнеса. В мелких конторах, где могут быть жадные и ушлые директора, вы лоб расшибете пока будите обосновывать необходимость покупки. Пока не потеряете данные из-за физического отказа железа и бизнесу не будет нанесен простой и урон, вам ничего не купят.
- К плюсам можно отнести тот факт, что данный компонент очень легко и просто устанавливается любым начинающим специалистом.
- Простота переноса данных. Предположим у вас есть сервер с Windows Server 2019, на котором включена функция дедупликации данных. путь на 50%, для примера это 1 ТБ. Вы хотите перенести данные файлы. Это легко можно сделать и в том же дуплицированном виде, если у вас на новом сервере уже будет настроен данный компонент и включен на нужном томе.
- Работает на файловой системе ReFS
- Работает на динамических томах, а так же на томах с BitLocker.
Минусы:
- Существует небольшая вероятность потери данных при дедупликации данных, поскольку система дедупликации хранит данные иначе, чем при их записи. Следовательно, достоверность данных зависит от системы дедупликации. Однако развитие технологий на протяжении многих лет уменьшило вероятность потери данных.
- При использовании встроенного метода дедупликации данные, которые не дедуплицируют хорошо, могут быть стерты, но это актуально в редких случаях на старых версиях ОС.
- Метод дедупликации может быть легко перегружен большими файлами, что может замедлить резервное копирование.
- Некоторые методы дедупликации, такие как постобработка, требуют более сложных конфигураций для правильной работы.
- Она не является заменой резервному копированию
- Не работает с файлами меньше 32 Кб, так же сюда попадают файлы с расширенными атрибутами (extended attributes)
Что нового в дедупликации Windows Server 2019
- Файловая система ReFS обычно используется для виртуализации, резервного копирования и Microsoft Exchange из-за своей отказоустойчивости, оптимизации уровней в реальном времени, более быстрых операций виртуальной машины и большой масштабируемости. Но до недавнего времени ReFS не поддерживала дедупликацию данных, которая была доступна только на томах, отформатированных в NTFS. Дедупликация данных может обеспечить значительную экономию затрат на хранение за счет использования технологии на уровне блоков, чтобы уменьшить объем занимаемых диском файлов.
- Увеличен объем поддерживаемого тома (Volume) до 64 ТБ.
- Максимальное количество томов до 64
- Поддерживаются файлы до 1ТБ
- Процесс дедуплицирования стал доступен с Nano Server редакцией
- Поддержка последовательного обновления кластерной ОС (Cluster OS Rolling Upgrade) — данная функция так же появилась в 2016. Смысл технологии в том, что вы могли обновить ваш Windows Server 2012 R2 до 2019, не останавливая вашего кластера. Там кластер начинал работать в смешанном режиме, это подразумевало нахождение общих данных на узлах кластера с разными версиями компонента дедупликации. Дедупликация в Windows Server 2019 поддерживает этот режим и обеспечивает доступ к дедуплицированным данным в процессе обновления кластера.
- Многопоточность — это наиглавнейшее нововведение, которое появилось еще в Windows Server 2016 и было усовершенствовано в 2019 версии. Лет 5 назад. когда флагманской операционной системой была Windows Server 2012 R2, то в ней процесс дедупликации происходил в один поток, это означало, что он не мог использовать все ядра центрального процессора для одного тома. Согласитесь, что это сильно ограничивало данную технологию и вызывало ограничение на размер тома в 10 ТБ, больше не могла обработать. Выглядит это вот так.
- Внедрена поддержка виртуализированных приложений резервного копирования. В том же 2012, имелся только один вид дедупликации, нацеленный на обычный файловый сервер, технология только развивалась. Представим себе работающую виртуальную машину, логично что ее файлы постоянно используются и открыты, дедупликация не умела с такими работать, тут дело было в неспособности поддерживать службу VSS. В 2012 R2, дедупликация с ней научилась дружить и тем самым работать с открытыми файлами виртуальных машин. В Windows Server 2019 данную технологию расширили и добавили поддержку виртуальных DPM.
- Интеграция с BranchCache
- Возможность исключать необходимые типы файлов от дедупликации, например avi или потоковое видео, так как их сложнее дедуплицировать.
- Поиск битых блоков — данный механизм в очередной раз оптимизировали и улучшили. Один раз в неделю запускается процесс, который ищет мусорные или сбойные блоки, и пытается их исправить. Вы можете его запускать вручную и на более глубоком уровне.
Виды дедупликации
На текущий момент существует три вида дедупликации:
- Файловая дедупликация — тут все просто есть первичные данные, а вторичные заменяются на ссылки ведущие на первые файлы. Данный подход, как я и писал выше применяется в дистрибутиве Microsoft Windows, MS Exchange, SCCM, DPM. Данный вид дедупликации можно назвать S.I.S. (Single Instance Storage). Это самый базовый уровень дедупликации.
- Блочная дедупликация — кто знаком с системами хранения данных, тот знает, что это более низкий уровень работы дисковым пространством. Данный механизм работает на субфайловом уровне, блоков. Тут сам процесс проходит уже не с файлами, а с блоками, я подробнее расскажу об этом чуть ниже. Очень актуально для виртуализованных сред, VDI сценарии. Тут будут обрабатываться блоки от 32 до 128 КБ.
- Битовая дедупликация — это самый продвинутый (Глубокий) тип дедупликации данных, у него самый высокий КПД эффективности. Но тут приходится расплачиваться повышенными затратами на обработку.
Механизм работы дедупликации
Технология дедупликации обычно разделяет данные на более мелкие порции, так называемые блоки и использует алгоритмы для назначения каждому блоку данных уникального хеш-идентификатора, называемого отпечатком. Чтобы создать отпечаток, он использует алгоритм, который вычисляет криптографическое значение хеша из блоков данных, независимо от типа данных. Эти слепки (хэши) хранятся в индексе.
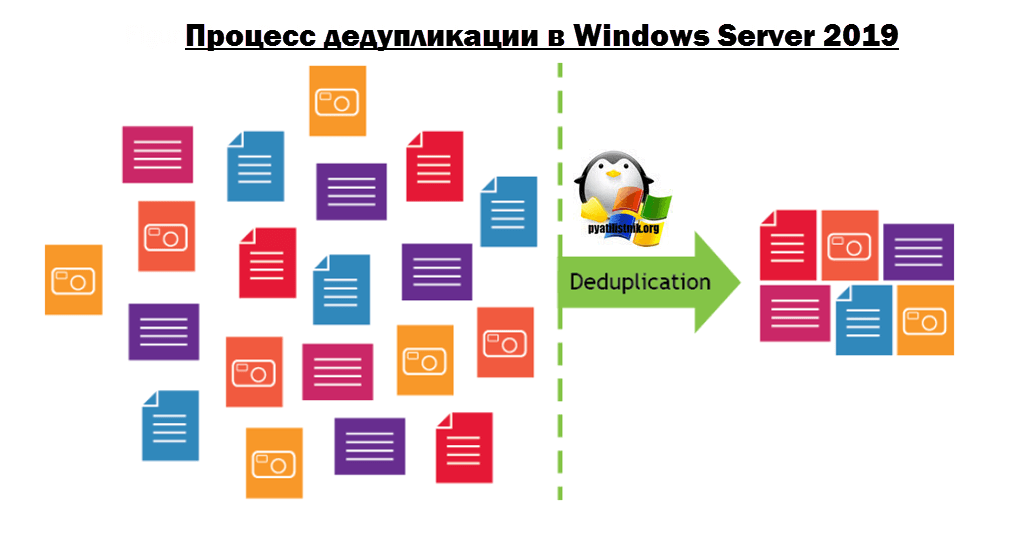
Алгоритм дедупликации сравнивает отпечатки фрагмента данных с теми, которые уже есть в индексе. Если в индексе присутствует отпечаток, блока данных, то блок заменяется указателем на блок данных (ссылкой). Если отпечаток не существует, данные записываются на диск как новый уникальный блок данных.
Более наглядно можно посмотреть на сайте Microsoft (https://docs.microsoft.com/ru-ru/windows-server/storage/data-deduplication/understand)
Эффективность дедупликации
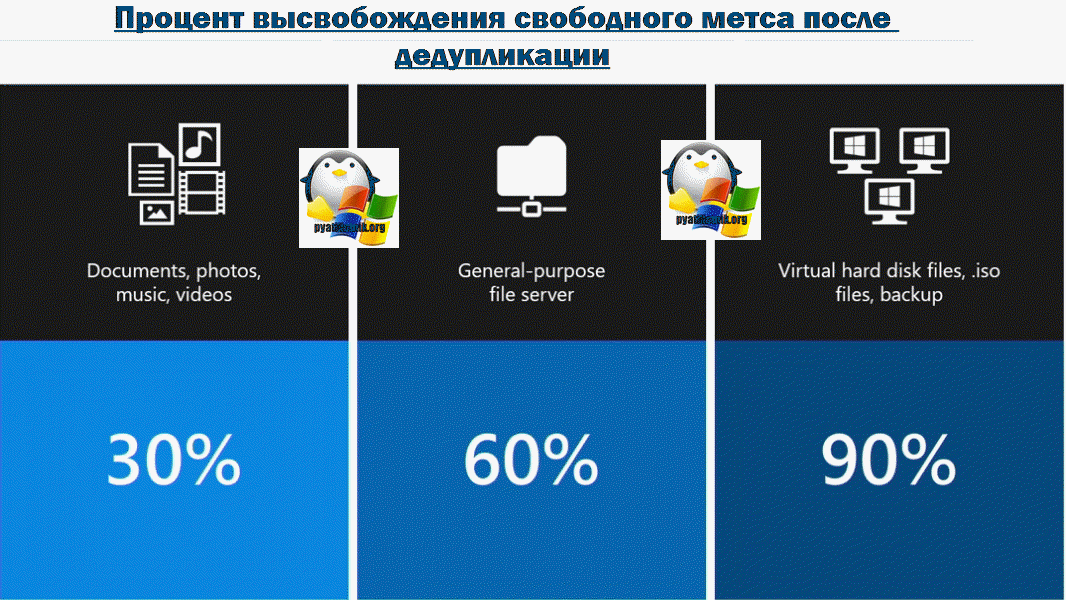
Тут бы я хотел привести среднестатистические цифры, так сказать сколько можно выиграть в попугаях по разным типам данных:
- Видео, музыка, фотографии — тут можно ожидать 30-35% от работы дедупликации данных
- Различные документы и офисные данные — до 60%
- Файлы виртуальных машин в библиотеке шаблонов, например, ISO диски — можно получить до 90%. Для виртуальных сред
Инструменты управления дедупликацией
Существует три инструмента, которые вам помогут отслеживать и управлять процессом дедупликации данных в Windows Server 2019:
Установка компонента дедупликации через «Диспетчер серверов»
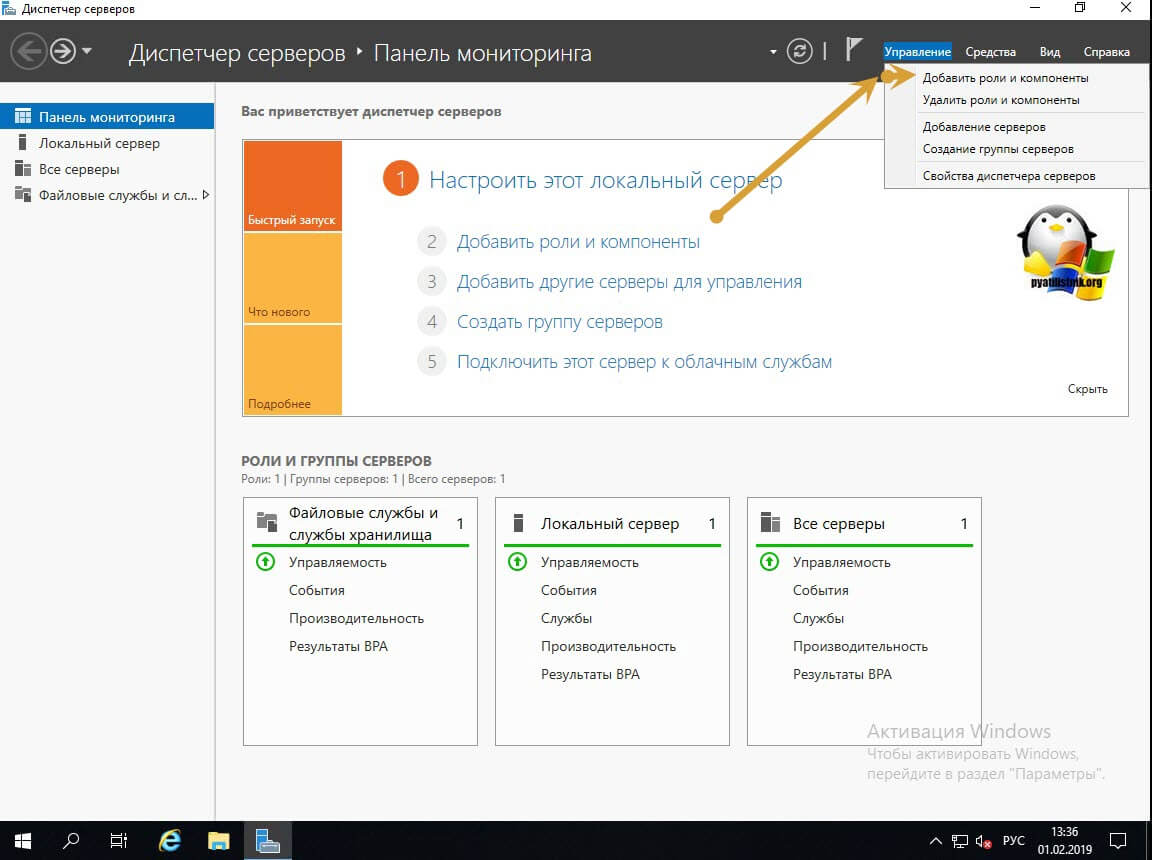
Открываем оснастку «Диспетчер серверов». В правом верхнем углу выберите пункт «правление — Добавить роли и компоненты».
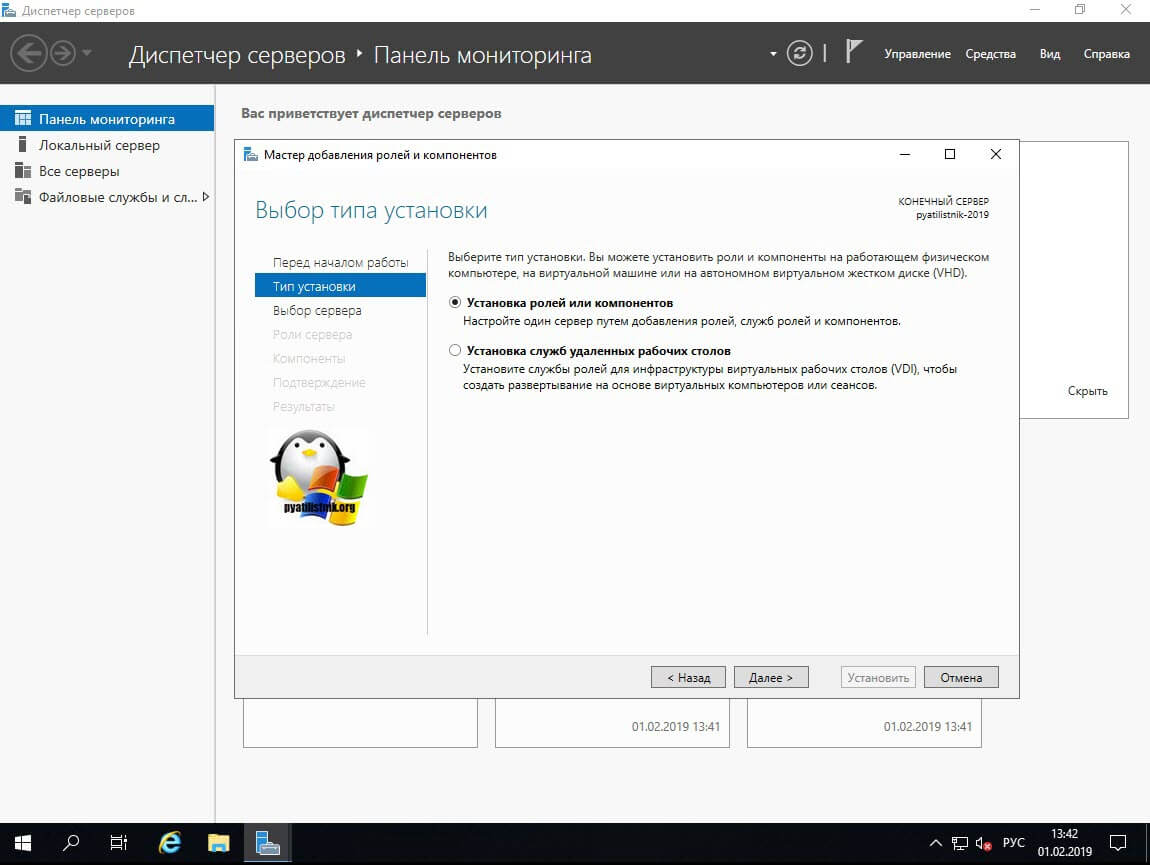
Оставляем пункт «Установка ролей или компонентов» и нажимаем далее.
Далее вы выбираете сервер из пула или же виртуальный жесткий диск.
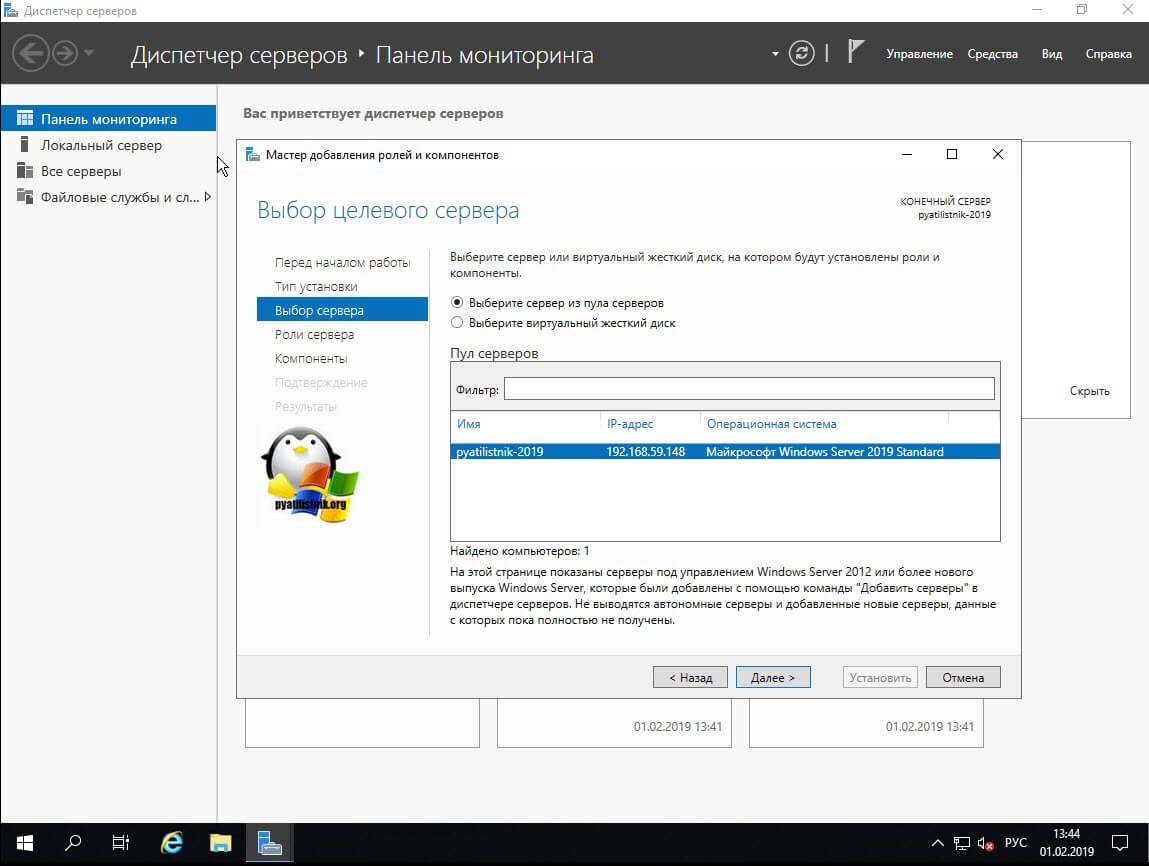
В списке ролей находите пункт «Файловые службы и службы хранилища — Файловые службы и службы iSCSI — Дедупликация данный (Data Deduplication)», ставите на против нее галку и продолжаете установку.
Пропускаем окно с компонентами Windows Server 2019.
После установки компонента у вас в системе по пути C:\Windows\system32\ появится файл ddpeval.exe. ddpeval — это Deduplication Data Evaluation Tool, она позволяет проверить эффективность возможной дедупликации. Что удобно ее можно спокойно копировать на флешку или другие компьютеры и запускать.
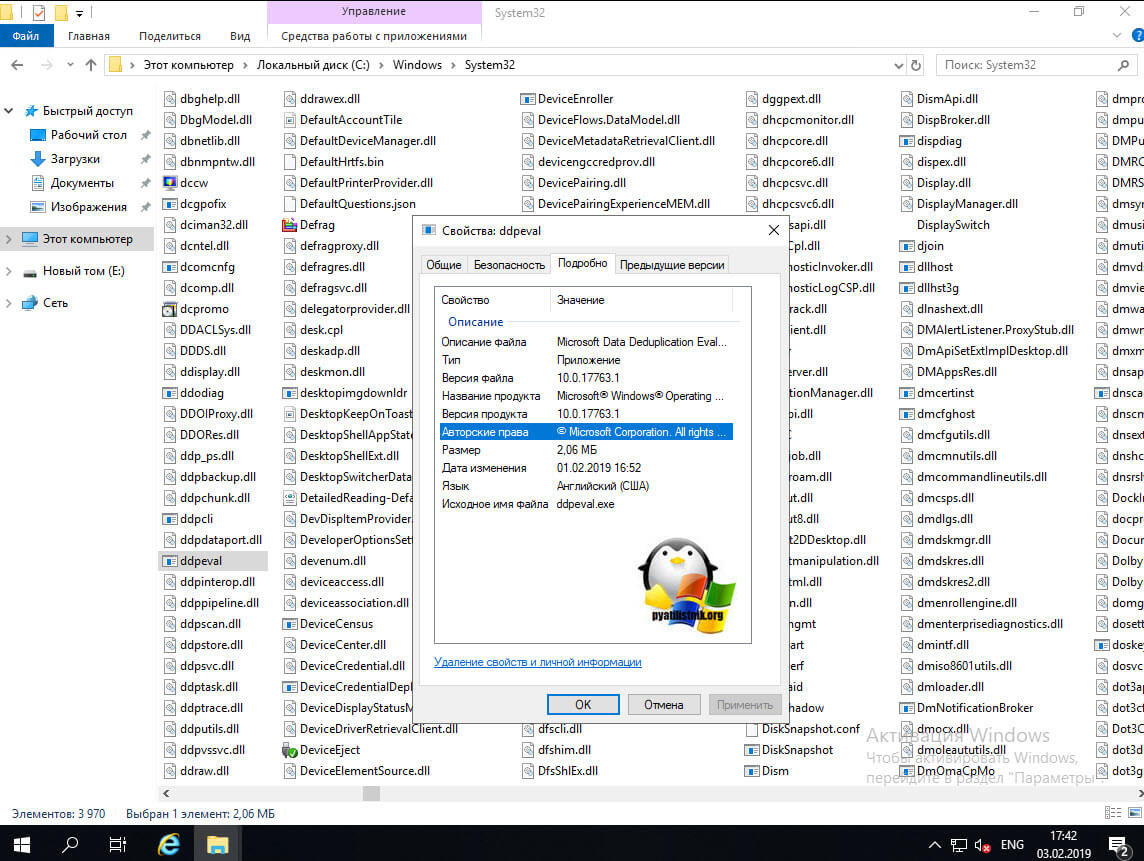
Для примера я запустил утилиту Deduplication Data Evaluation Tool в Windows 10 1809, через командную строку:
Учтите, что утилита ddpeval.exe не работает на системном диске. где установлена система. В моем примере, после того, как программка ddpeval.exe провела сбор данных, я вижу, что их можно оптимизировать за счет дедупликации на 27%, что для SSD-диска, с его не очень большим объемом, отличный результат.
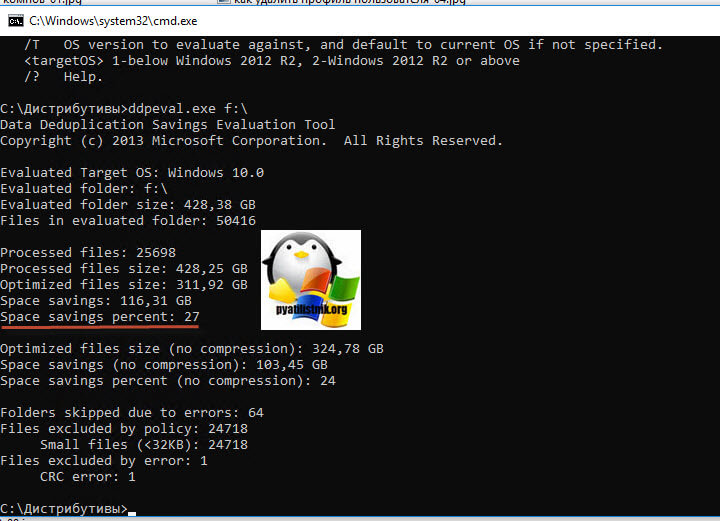
Установка компонента дедупликации через PowerShell
Данный метод куда быстрее, чем графический. Я вам уже подробно рассказывал, о процессе установки ролей и компонентов в Windows Server 2019, тут приведу лишь выдержку из нескольких команд. Открываем оснастку PowerShell и вводим вот такую команду:
У вас появится ползунок с процессом инсталляции.
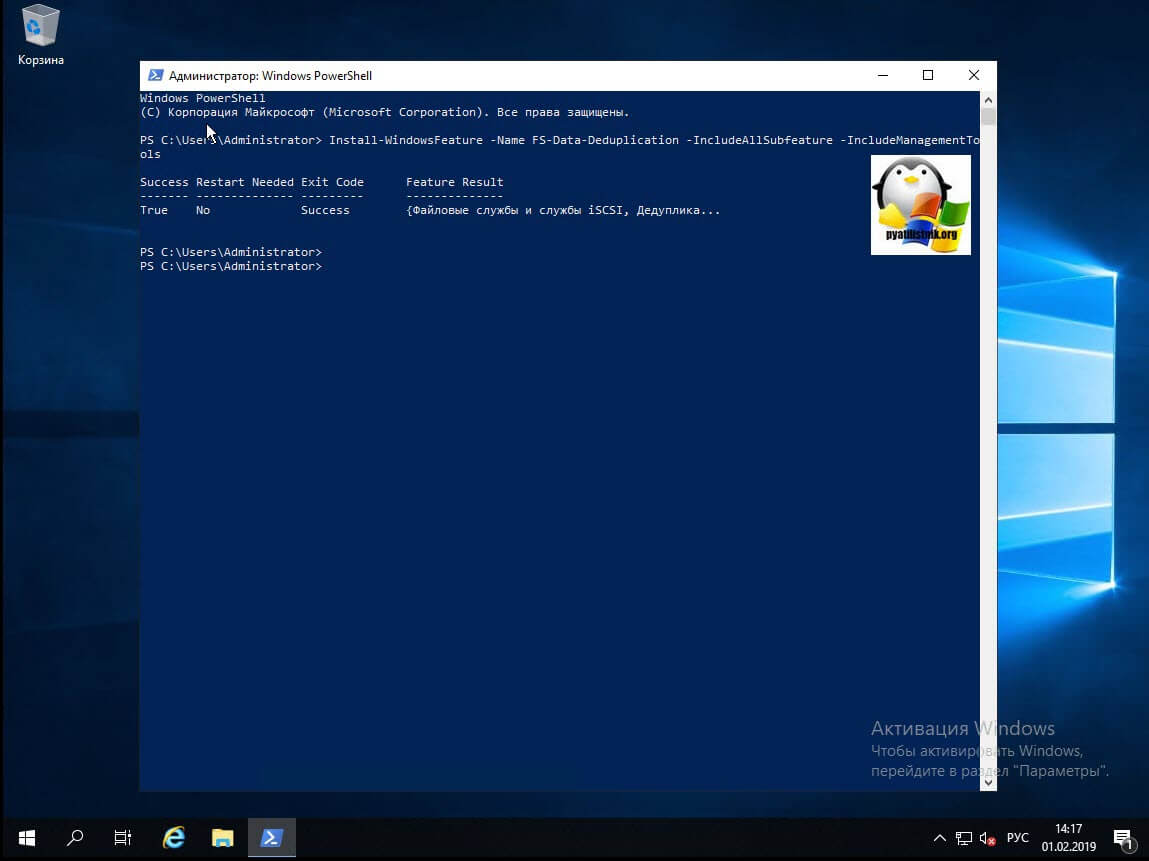
Буквально в течении секунд 20-30 ваш компонент будет присутствовать в вашей Windows Server 2019.
Установка компонента дедупликации через Windows Admin Center
Открываете ваш браузер и подключаетесь к Windows Admin Center. Переходите в пункт «Роли и компоненты», где ставите галку на против дедупликации и нажимаете установить.
Будет произведен поиск зависимостей, по окончании которого вам нужно нажать»Да».
В области уведомления будет отображаться процесс установки.
Включение и настройка дедупликации из GUI интерфейса
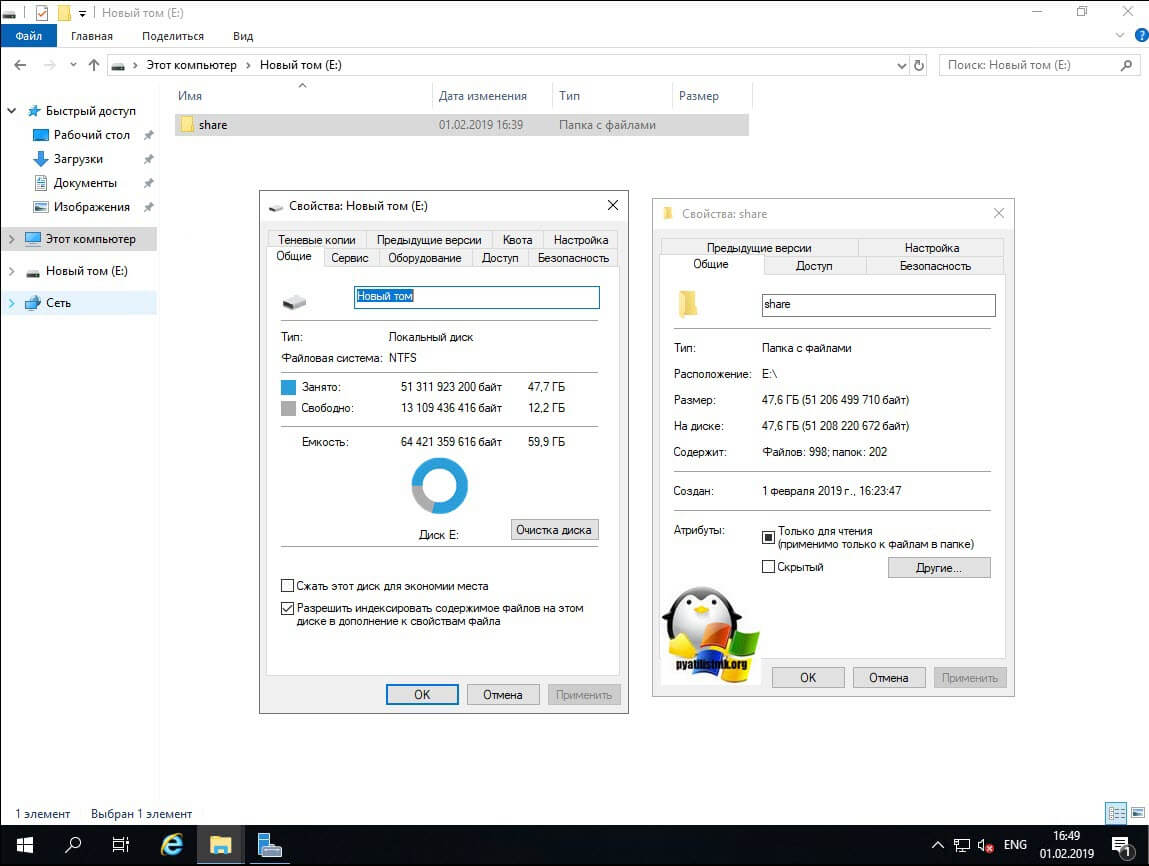
И так компонент мы установили, теперь осталось его включить и настроить под свои нужды. Делать мы это будем разными методами, графическими и из командной строки PowerShell. Как я показывал выше через утилиту Deduplication Data Evaluation Tool вы можете оценить степень дедупликации. Если она вас устраивает, то можно ее применять.Еще один момент, перед процедурой я сделал контрольный замер свободного места на диске D.
Теперь открываем оснастку «Диспетчер серверов — Файловые службы и службы хранилища».

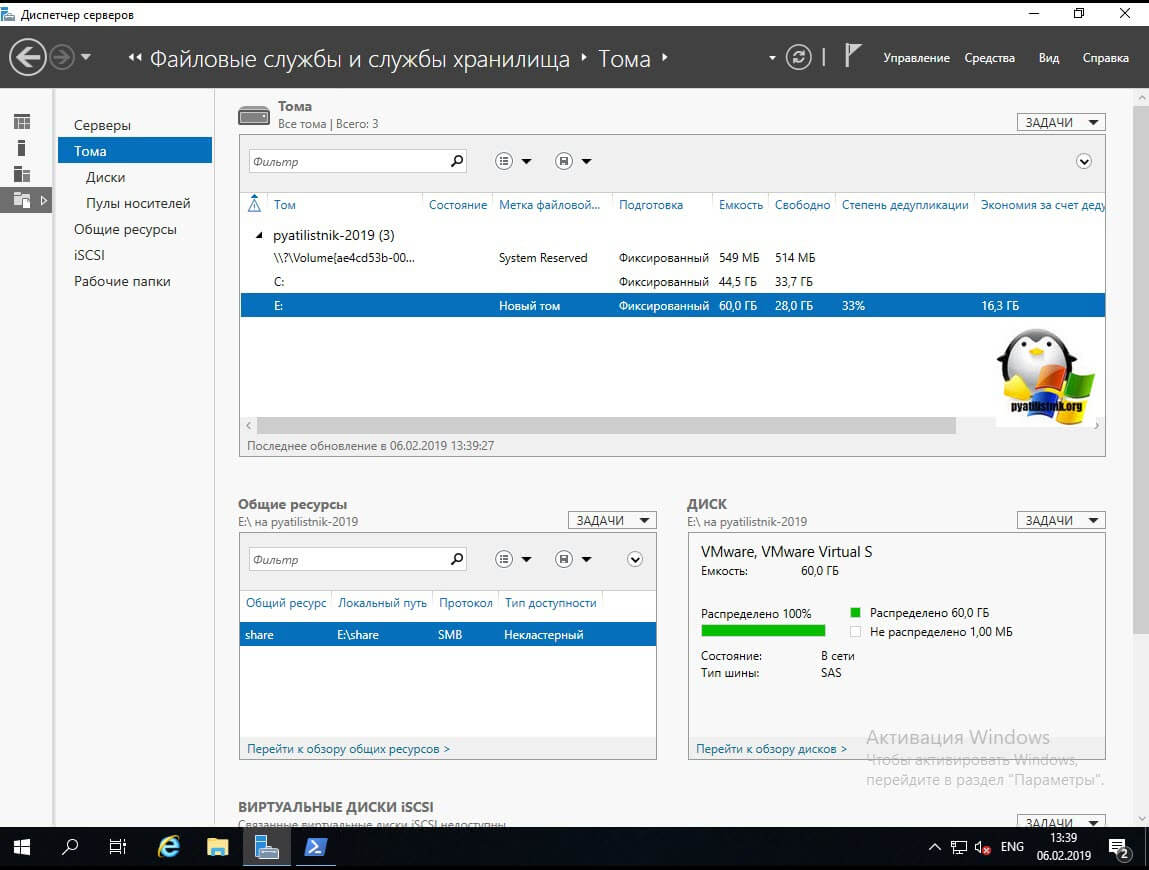
Находим пункт «Тома (Volumes)». Напоминаю, что дедупликация может работать только с ними. У меня в примере есть том с буквой E: именно его я и хочу оптимизировать по распределению дискового пространства. Щелкаем по нему правым кликом и из меню выбираем пункт «Настройка дедупликации данных (Configure Data Deduplication)».
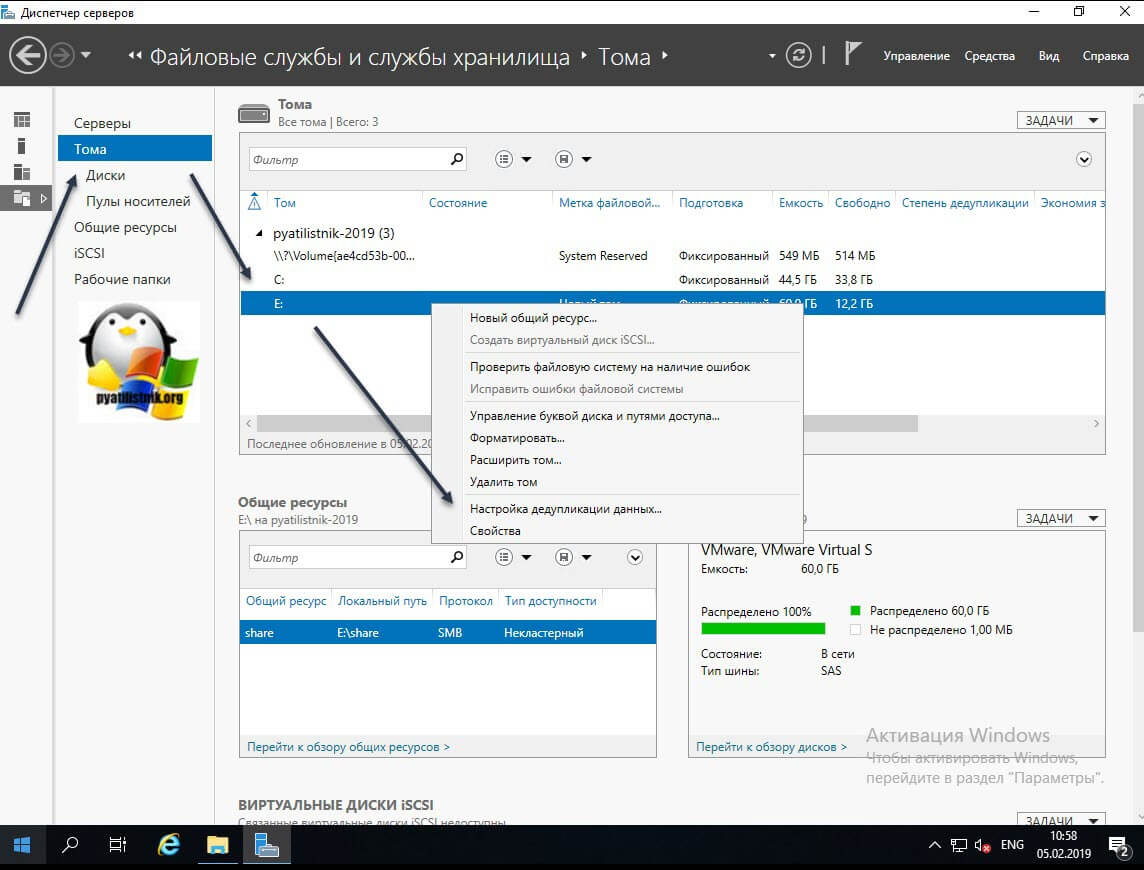
У вас откроется окно «Параметры дедупликации (Deduplication Settings)». По умолчанию дедупликия отключена, в выпадающем окне у вас будет три режима его работы:
- Файловый сервер общего назначения (General puprose file server) — это самый базовый вариант, который используется в подавляющем большинстве случаев.
- Сервер инфраструктуры виртуальных рабочих столов (VDI) (Virtual Desktop infrastructure VDI server), тут думаю понятно из названия.
- Виртуализированный резервный сервер (Virtualized Backup Server), для виртуального DPM
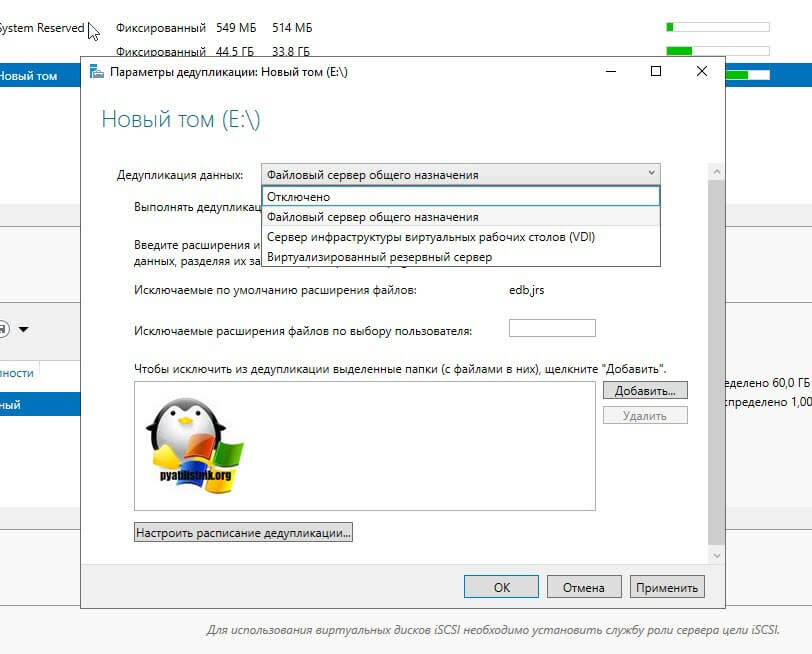
Оставляем выбраным пункт «Файловый сервер общего назначения». Далее вам необходимо определиться с возрастом файлов, которые будут подлежать процессу дедупликации. По умолчанию выставлено значение в 3 дня. Логика в этом есть, это сделано, чтобы отсеять временные файлы, мусорные. Старайтесь не ставить слишком маленькие значения, если у вас очень часто изменяются данные. На практике этого достаточно, но если вам необходимо сделать все сейчас, то установите это значение на единицу.
Далее вы можете определиться с форматами файлов, которые вы не хотели бы дедуплицировать. Тут уже каждый решает для себя сам. Вот вам список самых распространенных форматов файлов, которые вы могли бы исключить.
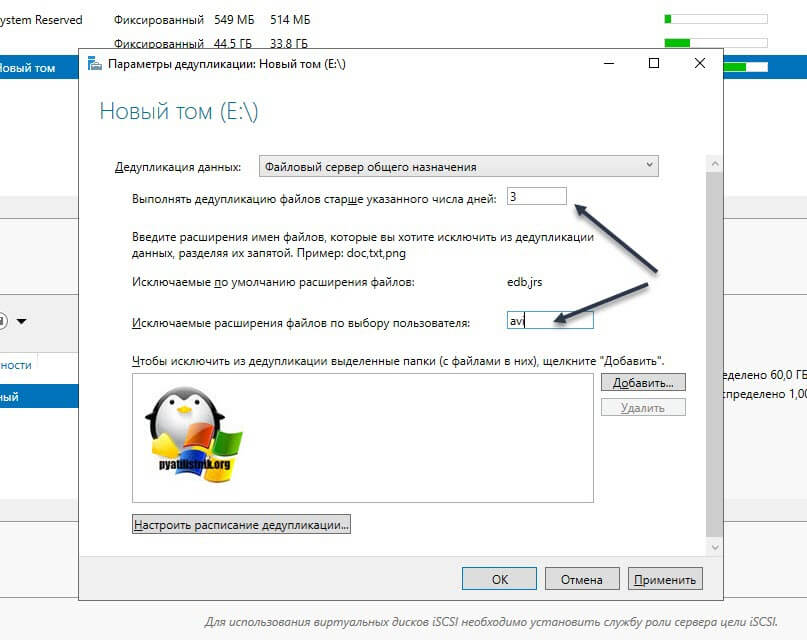
Так же есть возможность исключения нужных вам папок из задания. Для примера я исключу у себя папку с TotalCommander. Для этого нажмите кнопку «Добавить» и используя проводник укажите целевую папку.
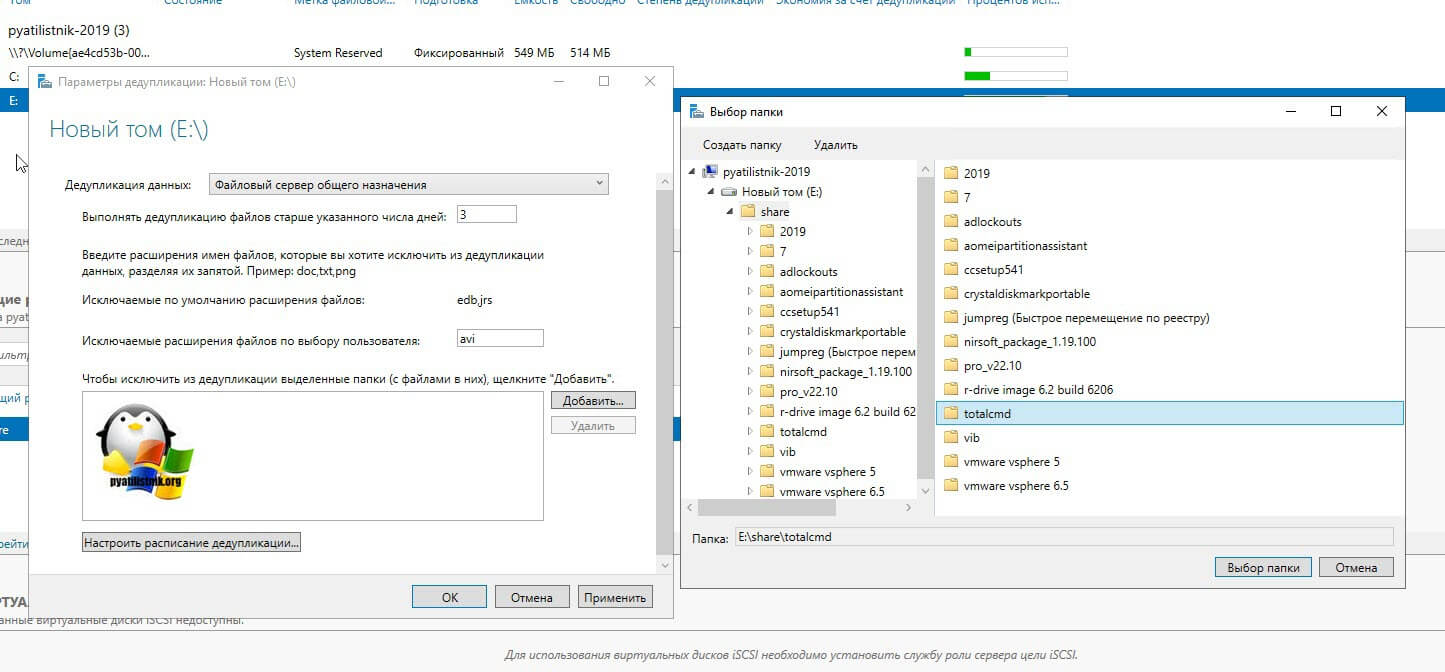
В списке исключения у вас будет выбранная папка. Чуть ниже будет очень полезная настройка, которая позволит вам управлять расписанием. Нажмите кнопку «Настроить расписание дедупликации (Set Deduplication Schedule)»
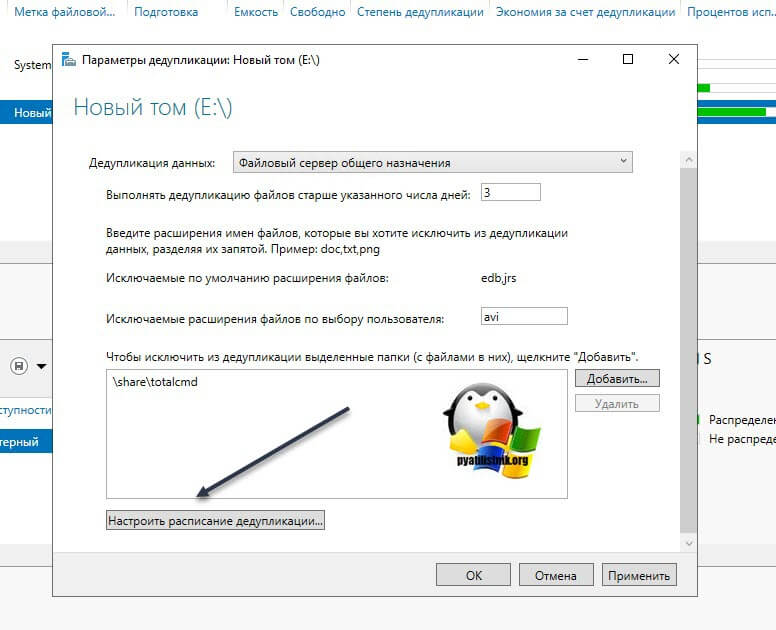
На выбор у вас есть возможность создавать два расписания, которые будут выполняться в фоновом режиме. Включаем галку «Включить фоновую оптимизацию (background optimization)». Далее, чтобы иметь возможность выбирать конкретные дни и время, вам необходимо выставить галку «Включить оптимизацию пропускной способности (Enable throughput optimization)». Первое задание у меня будет запускаться в 23-00 и выполняться до 9 утра. суммарно я на это выделил 10 часов, у вас эти цифры могут отличаться, тут нужно исходить от ваших условий.
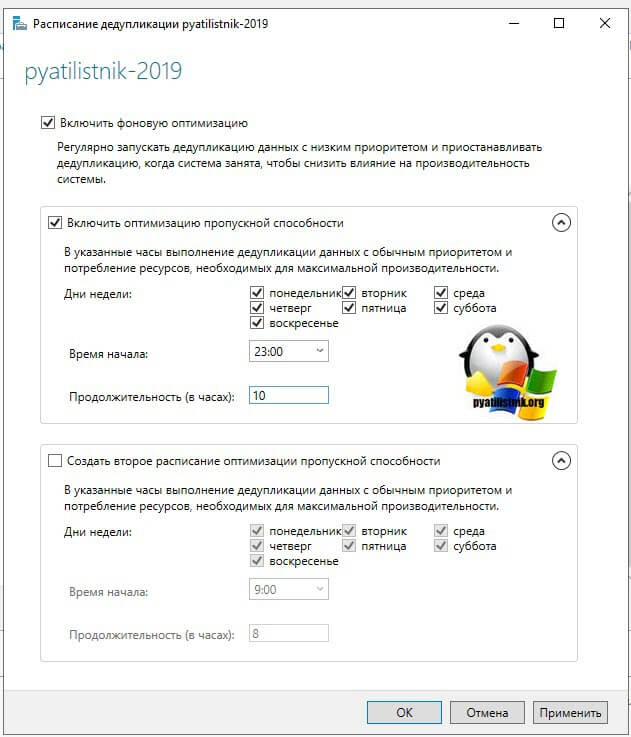
Так же хочу отметить, что по данным компании Microsoft усредненная скорость дедупликации данных в Windows Server 2019 25 мб/с, это приблизительно 87 ГБ в час, это нужно учитывать на больших объемах данных. Так же если у вас в качестве томов выступают ISCSI ,то вам еще нужно учесть нагрузку на сеть.
Если вам необходимо запустить процедуру сразу, то тут вам в помощь PowerShell. Откройте оболочку повершела.
Start-DedupJob -Volume E: -Type Optimization
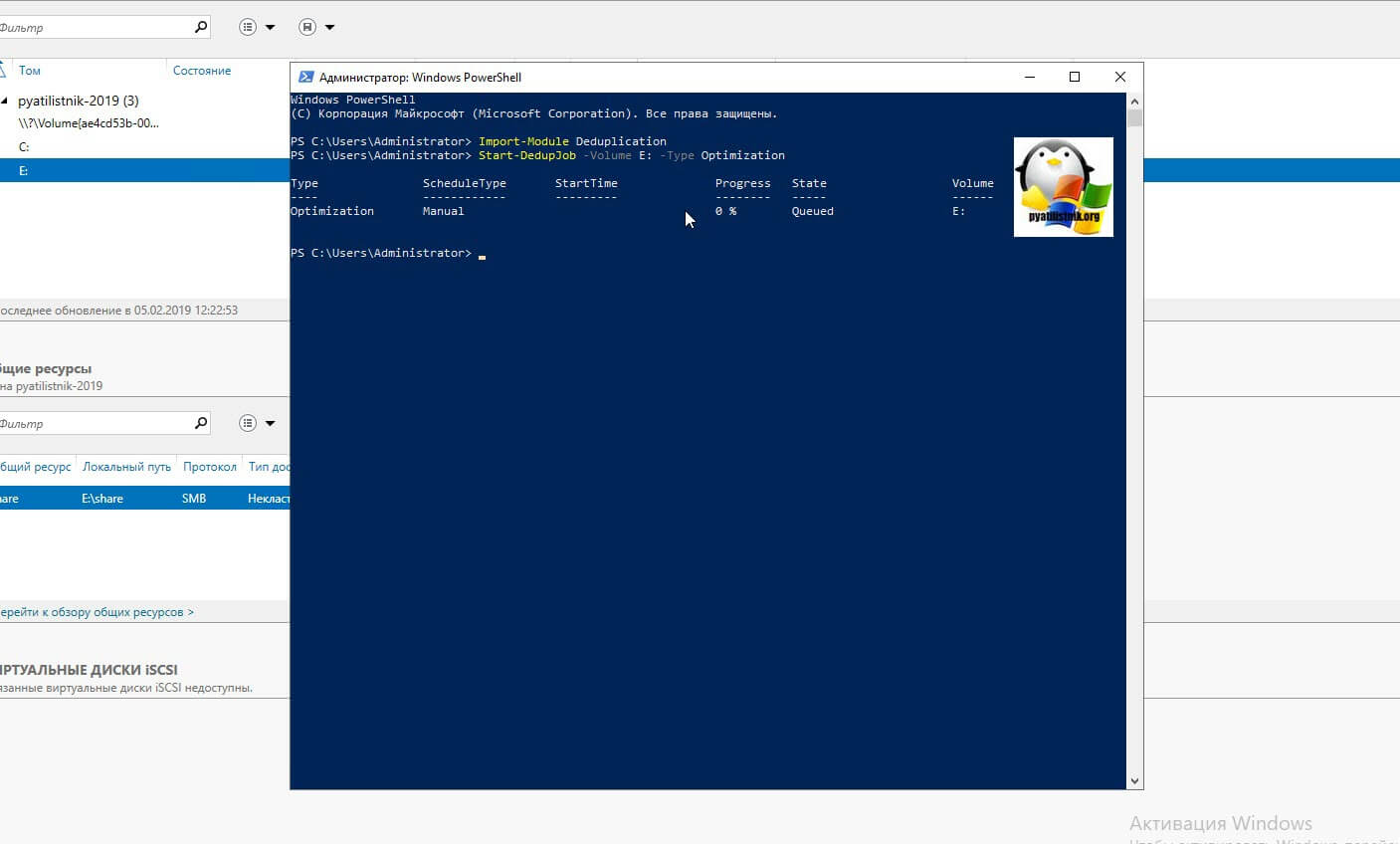 Первая команда импортирует нужный модуль, который содержит необходимые командлеты, вторая запустит немедленно дедупликацию на томе E:\. Посмотреть статус выполнения хода дедупликации, вы сможете с помощью вот такой команды:
Первая команда импортирует нужный модуль, который содержит необходимые командлеты, вторая запустит немедленно дедупликацию на томе E:\. Посмотреть статус выполнения хода дедупликации, вы сможете с помощью вот такой команды:
У вас будут столбы, где вы увидите, что тип задания «Manual (Запущенный вручную)», сам прогресс бар в процентах, статус и на каком томе выполняется задание.
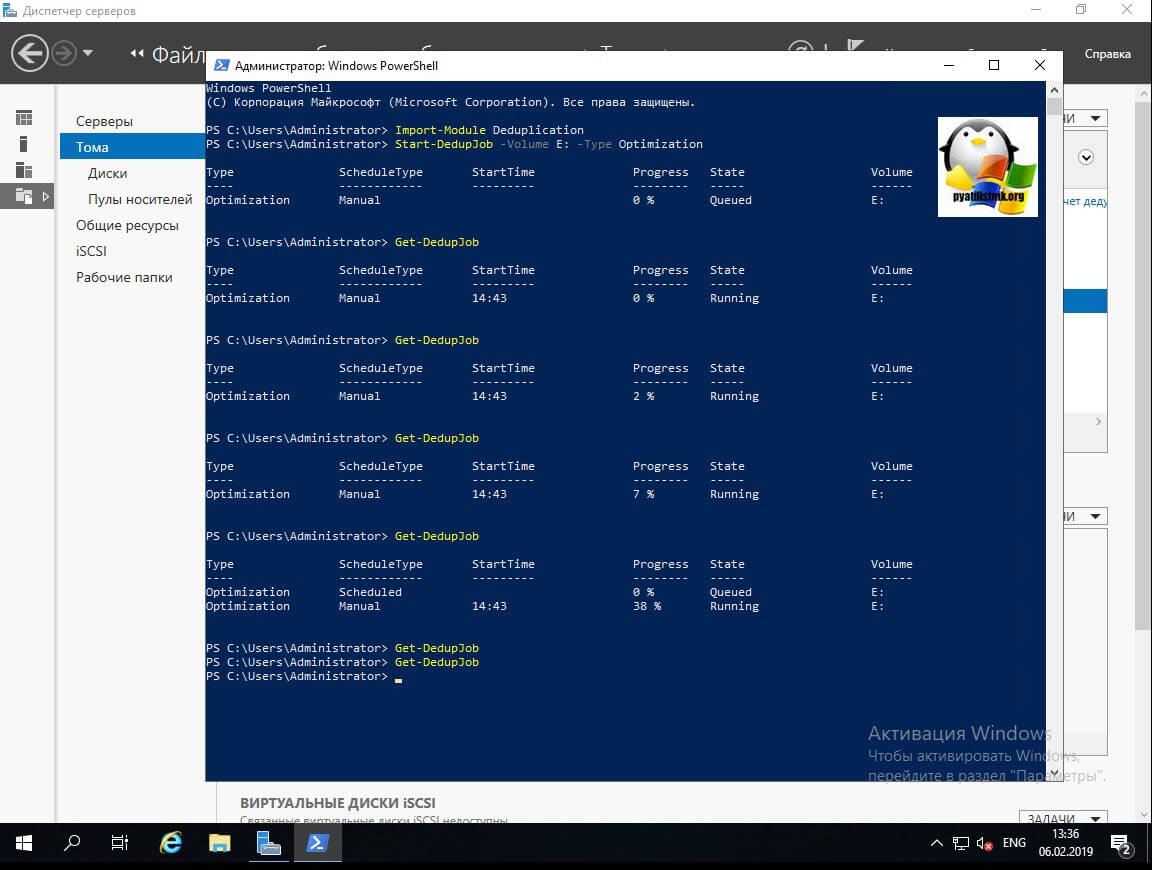
Теперь если посмотреть в оснастке диспетчера серверов степень дедупликации данных, то в моем случая я получил 33%, что весьма прилично.
Включение и настройка дедупликации через PowerShell
Графический метод, это хорошо, но все же большую свободу действий и возможностей нам компания Microsoft предоставляет, через использования сильного языка и его командлетов. Откройте оснастку Powershell. Первым делом импортируем модуль для нужных команд.
Первым делом нужно включить саму дедупликацию и выбрать один из ее типов. Сделать, это можно командой:
В результате на томе E: будет активированная дедупликация со стандартным типом «Файловый сервер общего назначения». Если нужно задать другие типы, то можно воспользоваться ключами:
- -UsageType HyperV — аналогично режиму «Сервер инфраструктуры виртуальных рабочих столов (VDI) (Virtual Desktop infrastructure VDI server)»
- Backup — Виртуализированный резервный сервер (Virtualized Backup Server), для виртуального DPM
- Default — Файловый сервер общего назначения (General puprose file server)
Если в нужно явно задать режим работы, то сделайте командой:
Так же можно выполнить сразу для нескольких томов в Windows Server 2019:
Так же если у вас нет букв томов и вы знаете только GUID, то его так же можно использовать в командах:
Как отключить дедупликацию Windows
Простая задача, необходимо выключить и затем удалить роль дедупликации в Windows Server 2019. Если вы отключите дедупликацию данных с помощью графического интерфейса или Powershell, это на самом деле не отменит выполненную работу и дедуплицированные данные на текущий момент останутся. Хуже того, если вы отключили сервис, то вы не можете запустить команду очистки мусора (которая очищает данные, созданные с помощью технологии дедупликации).
Поэтому важно, чтобы вы оставили дедупликацию данных включенной, но сначала ИСКЛЮЧИЛИ весь диск. Затем выполните следующие две команды (которые будут выполняться в зависимости от количества имеющихся у вас данных). Первая команда исключает из процесса дедупликации раздел D:
Ключ -Full указывает, что задания по сборке мусора освобождают все удаленные или не связанные данные на томе. Если этот параметр не указан, задания по сборке мусора освобождают пространство после превышения системного порога удаления данных.

Далее мониторим его статус, пока задание не будет выполнено:
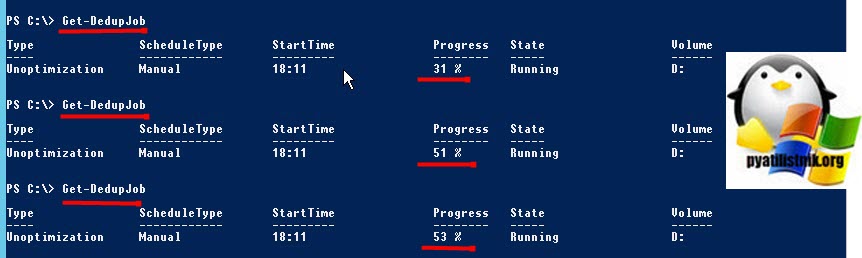
Поскольку задание по сбору мусора еще нужно запустить, нам нужно довольно нелогично включить дедупликацию для тома с помощью следующей команды
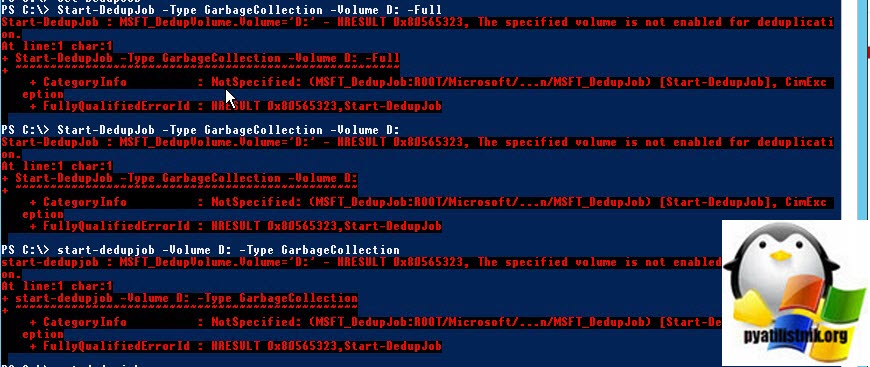
В противном случае вы будите получать ошибку:
+ CategoryInfo : NotSpecified: (MSFT_DedupJob:ROOT/Microsoft/. n/MSFT_DedupJob) [Start-DedupJob], CimExc
eption
+ FullyQualifiedErrorId : HRESULT 0x80565323,Start-DedupJob
Как только это будет сделано, следующим шагом будет запуск следующей команды, чтобы запустить сборку мусора на томе
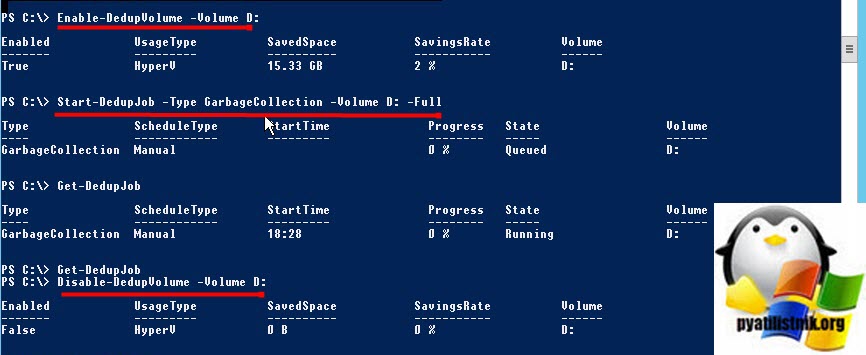
Наконец, после этого последний шаг — отключить дедупликацию тома с помощью следующей команды



