How to Change File Type in Windows 10
With our increasing use of computers in our daily life, it may get necessary even for a simple user to change the file type of a file from one format to another. Each file format has their own properties. For example a ‘.txt’ file will probably get opened by the text editor while an ‘html’ file will get launched in your default browser.
 File format analogy
File format analogy
Even though the contents inside the files might be the same, the file type matters a lot. The process of changing file type is quite simple and straightforward. However, there are some cases whereby changing the file type, the file becomes unusable. Hence it is recommended that you know exactly what you’re doing and also make an additional copy of the file.
Showing file extensions and changing the file format
By default, Windows doesn’t have the file format displayed alongside every file. For example, if a file is a text file, its name wouldn’t display ‘ap puals.txt’. Instead, it will only display ‘appuals’. First, we will enable the file extensions and then through basic rename, we will change the file extension. You can also choose to rename files in bulk if there are a lot of files that you need to change the type for.
- Press Windows + E, click View from the top-most ribbon. Now click Options and select the option Change folder and search options.
 Change folder and search options – Windows Explorer
Change folder and search options – Windows Explorer
- Now uncheck the option Hide extensions for known file types. Now all the files will have their file extensions displayed alongside their names.
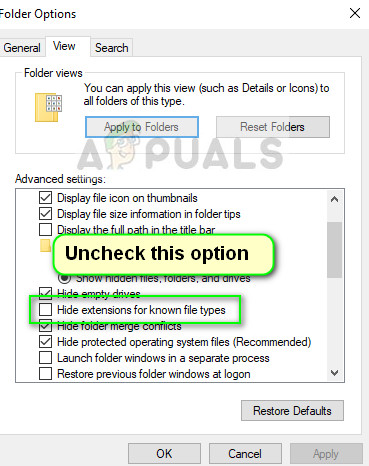 Enabling File Extensions – Windows Explorer
Enabling File Extensions – Windows Explorer
- Now navigate to the file for which you want to change the file format. Right-click on it and select Rename.
- Now change the file’s extension to the extension of the type which you want to change into. In this example, we change a ‘text’ file to a ‘python’ file. The extensions for a text file are ‘txt’ and for python ‘py’.
 Process of changing a file type
Process of changing a file type
Here is a list of common file extensions used in the world of computing. We have listed them according to their type.
Code Pages
Most applications written today handle character data primarily as Unicode, using the UTF-16 encoding. However, many legacy applications continue to use character sets based on code pages. Even new applications sometimes have to work with code pages, often for one of the following reasons:
- To communicate with legacy applications.
- To communicate with older mail and news servers, which might not always support Unicode.
- To communicate with the Windows Console.
New Windows applications should use Unicode to avoid the inconsistencies of varied code pages and for ease of localization.
Each code page is represented by a code page identifier, for example, 1252, and is handled by the Unicode and character set API functions. For a list of supported code page identifiers, see Code Page Identifiers. The «Code Pages» reference on the Microsoft Go Global Developer Center gives full descriptions of many code pages.
Windows code pages, commonly called «ANSI code pages», are code pages for which non-ASCII values (values greater than 127) represent international characters. These code pages are used natively in Windows Me, and are also available on Windows NT and later.
Originally, Windows code page 1252, the code page commonly used for English and other Western European languages, was based on an American National Standards Institute (ANSI) draft. That draft eventually became ISO 8859-1, but Windows code page 1252 was implemented before the standard became final, and is not exactly the same as ISO 8859-1.
Many Windows API functions have «A» (ANSI) and «W» (wide, Unicode) versions. The «A» version handles text based on Windows code pages, while the «W» version handles Unicode text. See Windows Data Types for Strings and Conventions for Function Prototypes.
Windows code pages are also sometimes referred to as «active code pages» or «system active code pages». A Windows operating system always has one currently active Windows code page. All ANSI versions of API functions use the currently active code page.
Original equipment manufacturer (OEM) code pages are code pages for which non-ASCII values represent line drawing and punctuation characters. These code pages were originally used for MS-DOS and are still used for console applications. They are also used for the non-extended file names in the FAT12, FAT16, and FAT32 file systems, as described in Character Sets Used in File Names. The usual OEM code page for English is code page 437.
For both Windows code pages and OEM code pages, the code values 0x00 through 0x7F correspond to the 7-bit ASCII character set. Code values 0x00 through 0x19 and 0x7F always represent standardized control characters and 0x20 through 0x7E represent standardized displayable characters. Characters represented by the remaining codes, 0x80 through 0xff, vary among character sets. Each character set includes different special characters, typically customized for a language or group of languages. Windows code page 1252 and OEM code page 437 are generally used in the United States.
In addition to Windows and OEM code pages, your applications can use non-native code pages. Examples are EBCDIC and Macintosh code pages.
Two encodings of Unicode (UTF-7 and UTF-8) are implemented as code pages. Like other code pages, each page is known by a numeric identifier and can be handled with many of the same Unicode and character set API functions.
Code pages can be either single-byte character set (SBCS) pages or double-byte character set (DBCS) pages. In SBCS pages, each byte directly encodes a single character, so that it is possible to represent exactly 256 distinct characters (including control characters, letters, digits, punctuation, symbols, and the like). DBCS code pages are used for languages such as Japanese and Chinese. In such a code page, some characters have two-byte encodings with certain byte values (always values greater than 127) serving as «lead bytes». Instead of encoding characters in their own right, lead bytes can be mapped to a character only in conjunction with a «trail byte».
Some legacy protocols require the use of SBCS and DBCS code pages. Each SBCS/DBCS code page supports different characters, but no code page supports the full breadth of characters provided by Unicode. Each SBCS/DBCS code page supports a different subset, differently encoded.
Data converted from one SBCS or DBCS code page to another is subject to corruption, because the same data value on different code pages can encode a different character. Data converted from Unicode to SBCS or DBCS is subject to data loss, because a given code page might not be able to represent every character used in that particular Unicode data.
In addition to SBCS and DBCS code pages, your applications have available the multibyte character set code pages 52936, 54936, 51949, and 5022x, which use an approach similar to that for a DBCS. A multibyte character set code page goes beyond two-byte encodings of some characters, however. UTF-7 and UTF-8 use a similar approach to encode Unicode based on a 7-bit and 8-bit bytes, respectively. For more information, see Unicode.
Several Unicode and character set functions allow your applications to handle code pages. An application can use the GetCPInfo and GetCPInfoEx functions to obtain information about a code page. This information includes the default character used when a character in a converted string has no corresponding entry in the code page.
An application can use the MultiByteToWideChar and WideCharToMultiByte functions to convert between strings based on Windows code pages and Unicode strings. Although their names refer to «MultiByte», these functions work equally well with SBCS, DBCS, and multibyte character set code pages.
WideCharToMultiByte can lose some data if the supplied code page cannot represent all characters in a Unicode string.
Your application can convert between Windows code pages and OEM code pages using the standard C runtime library functions. However, use of these functions presents a risk of data loss because the characters that can be represented by each code page do not match exactly.
Your applications can also call the GetACP function. This function retrieves the identifier of the current Windows (ANSI) code page.
Change Console Code Page in Windows C++
I’m trying to output UTF8 characters in the Windows command line. I can’t seem to get the function, setConsoleOutputCP to work. I also heard that you had to change the font to «Lucida Grande» for it to work but I can’t get that working either. Can someone please provide me with a short example of how to use these functions to correctly output UTF-8 characters to the console?
Also I heard that those functions don’t work in Windows XP, is there a better alternative to those functions which will work in Windows XP?
4 Answers 4
Windows console doesn’t play nice with UNICODE and particularly with UTF-8.
Setting a console code page to utf-8 won’t work.
One approach is to use WideCharToMultiByte() (or something else) to convert the text to UTF-16, then MultiByteToWideChar() (or something else) to convert to a localised ISO encoding. The set the console code page to the ISO code page.
Its ugly, but it sort of works.
[I know this question is old and was about Windows XP, but it still seemed like a good place to drop this information so I (and maybe others) can find it again in the future.]
Support for Unicode in CMD windows has improved in newer versions of Windows. This program will work on Windows 10.
I made an RAII class to ensure the code page is restored because it would be rude to leave the code page changed if the user had purposely selected a specific one. All the Windows-specific code (SetConsoleOutputCP) is contained within that class. The definition of the use_utf8 variable in main changes the code page to UTF-8, and that code page will stay in effect until the variable is destructed at the end of the scope.
Note that I used the u8 prefix on the string literal, which is a newer feature of C++ to ensure that the string is encoded using UTF-8 regardless of the encoding used for the source file. You don’t have to use that feature if you have another way to make a string of valid UTF-8 text.
You still have to be sure that the CMD window is using a font that supports the glyphs you need. I don’t think there’s a way to get font linking automatically. But this will at least show a the replacement character if the font is missing the glyph. For example, on my window, the ¡Olé! looks right but the CJK glyph is shown approximately like � . If the user copies that replacement character, the clipboard will receive the original glyph, so they can paste it into other programs without any loss of fidelity.
Note that command line parameters you get from main ‘s argv will be in the original code page. One way to work around this is to get the unconverted «wide» command line with GetCommandLineW, convert it to UTF-8 with WideToMultibyte, and then parse it yourself. Alternatively, you can pass the result of GetCommandLineW to CommandLineToArgvW, which will parse it, and then you’d convert each argument to UTF-8.
Finally, note that changing the code page affects only the output. If you input text from the user, it arrives encoded using the original code page (often called the OEM code page).
TODO: Figure out input. SetConsoleCP isn’t doing what I think the documentation says it should do.
Changing codepage in .bat file (Win7 vs Win Vista)
I have a strange issue while trying to change the codepage in a .bat file.
When I execute the following .bat file in Windows 7 it executes fine.
The codepage gets changed and program.exe get executed.
However when I start the .bat file from Windows Vista the codepage gets changed and after that the batch file is exited.
So program.exe never gets executed.
However when I run the two commands manually from the commandline it does work.
Any idea how to get this working under Windows Vista from .bat file?

4 Answers 4
It’s new to me that this works with Win7, in Vista and XP it’s normal that batch files aren’t work if the codepage is changed to 65001.
But you can use a workaraound
This works, as the complete block is cached while the codepage is changed.
In your case (with german umlauts) you could better use the codepage 1252
Have you checked return code of chcp ( chcp 65001 & echo %ERRORLEVEL% )?
Anyway, try chcp 65001 & «D:\program.exe» /opt ÄiÜ & chcp 850 .
I’ve found a (very dirty) solution which works for me.
By the looks of it it just isn’t possible what I want to do.
What I’ve done to make it work is the following:
- Instead of trying to create a batchfile I create a .txt file (with the same contents as the batchfile).
- I’ve written a very simple C# program which reads the .txt file and executes the content.
As I said it’s pretty dirty but it works for me.
If other answer are added here I’ll try those as well.
A less ugly solution, I use it when I need to use filenames with special characters as parameters in batch files:
Change default code page of Windows console to UTF-8
Currently I’m running Windows 7 x64 and usually I want all console tools to work with UTF-8 rather than with default code page 850.
Running chcp 65001 in the command prompt prior to use of any tools helps but is there any way to set is as default code page?
Update:
Changing HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage\OEMCP value to 65001 appear to make the system unable to boot in my case.
Proposed change of HKEY_LOCAL_MACHINE\Software\Microsoft\Command Processor\Autorun to @chcp 65001>nul served just well for my purpose. (thanks to Ole_Brun)
8 Answers 8
To change the codepage for the console only, do the following:
- Start -> Run -> regedit
- Go to [HKEY_LOCAL_MACHINE\Software\Microsoft\Command Processor\Autorun]
- Change the value to @chcp 65001>nul
If Autorun is not present, you can add a New String
Personally, I don’t like changing the registry. This can cause a lot of problems. I created a batch file:
I saved at C:\Windows\System32 as switch.bat.
I created a link for cmd.exe on the Desktop.
In the properties of the cmd shortcut, changed the destination to: C:\Windows\System32\cmd.exe /k switch
Voilá, when I need to type in UTF-8, I use this link.
Edit the Registry:
Then restart. With this fix, if you are using Consolas font, it seems to lock PowerShell into a small font size. cmd.exe still works fine. As a workaround, you can use Lucida Console, or I switched to Cascadia Mono:
In the 1809 build of Windows 10 I’ve managed to permanently solve this by going to the system’s Language settings , selecting Administrative language settings , clicking Change system locale. and checking the Beta: Use Unicode UTF-8 for worldwide language support box and then restarting my pc.
This way it applies to all applications, even those ones that I don’t start from a command prompt!
(Which was necessary for me, since I was trying to edit Agda code from Atom.)

This can be done by creating a PowerShell profile and adding the command «chcp 65001 >$null» to it:
This doesn’t require editing the registry and, unlike editing a shortcut, will work if PowerShell is started in a specific folder using the Windows Explorer context menu.
The command to change the codepage is chcp . Example: chcp 1252 . You should type it in a Powershell window. To avoid the hassle of typing it everytime (if you always have to change the codepage), you may append it to the program’s command line. To do so, follow these steps:
- Right-click the Powershell icon on Start menu and choose «More» > «Open file Location».
- Right-click the Powershell shortcut and select «Properties».
- Add the following to the end of the «Target» command line: -NoExit -Command «chcp 1252»
Be happy. Don’t fuss with Windows Registry unless you have no other option.



