- Учимся применять оконные функции
- Принцип работы
- Синтаксис
- PARTITION BY
- ORDER BY
- ROWS или RANGE
- Виды функций
- Агрегатные функции
- Ранжирующие функции
- Функции смещения
- Аналитические функции
- Кейс. Модели атрибуции
- Первый клик
- С учетом давности взаимодействий
- Windows function in oracle
- 12.21.2В Window Function Concepts and Syntax
Учимся применять оконные функции

Оконные функции — это мощнейший инструмент аналитика, который с легкостью помогает решать множество задач.
Если вам нужно произвести вычисление над заданным набором строк, объединенных каким-то одним признаком, например идентификатором клиента, вам на помощь придут именно они.
Можно сравнить их с агрегатными функциями, но, в отличие от обычной агрегатной функции, при использовании оконной функции несколько строк не группируются в одну, а продолжают существовать отдельно. При этом результаты работы оконных функций просто добавляются к результирующей выборке как еще одно поле. Этот функционал очень полезен для построения аналитических отчетов, расчета скользящего среднего и нарастающих итогов, а также для расчетов различных моделей атрибуции.
Принцип работы
У вас может возникнуть вопрос – «Что значит оконные?»
При обычном запросе, все множество строк обрабатывается как бы единым «цельным куском», для которого считаются агрегаты. А при использовании оконных функций, запрос делится на части (окна) и уже для каждой из отдельных частей считаются свои агрегаты.
Синтаксис
Окно определяется с помощью обязательной инструкции OVER(). Давайте рассмотрим синтаксис этой инструкции:
Теперь разберем как поведет себя множество строк при использовании того или иного ключевого слова функции. А тренироваться будем на простой табличке содержащей дату, канал с которого пришел пользователь и количество конверсий:

Откроем окно при помощи OVER() и просуммируем столбец «Conversions»:

Мы использовали инструкцию OVER() без предложений. В таком варианте окном будет весь набор данных и никакая сортировка не применяется. Появился новый столбец «Sum» и для каждой строки выводится одно и то же значение 14. Это сквозная сумма всех значений колонки «Conversions».
PARTITION BY
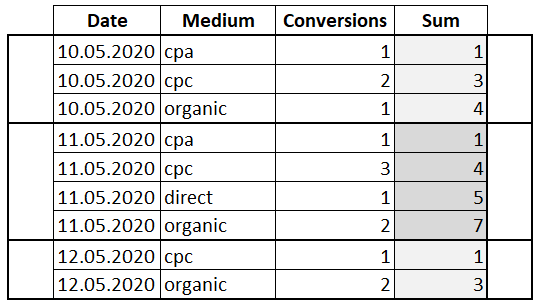
Теперь применим инструкцию PARTITION BY, которая определяет столбец, по которому будет производиться группировка и является ключевой в разделении набора строк на окна:

Инструкция PARTITION BY сгруппировала строки по полю «Date». Теперь для каждой группы рассчитывается своя сумма значений столбца «Conversions».
ORDER BY
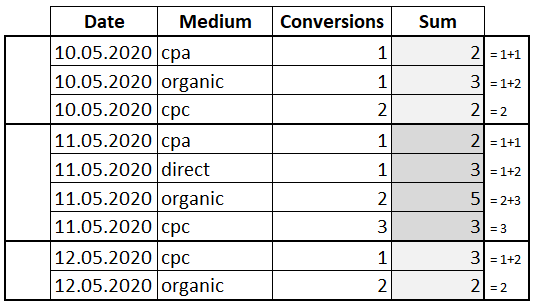
Попробуем отсортировать значения внутри окна при помощи ORDER BY:
К предложению PARTITION BY добавилось ORDER BY по полю «Medium». Таким образом мы указали, что хотим видеть сумму не всех значений в окне, а для каждого значения «Conversions» сумму со всеми предыдущими. То есть мы посчитали нарастающий итог.
ROWS или RANGE
Инструкция ROWS позволяет ограничить строки в окне, указывая фиксированное количество строк, предшествующих или следующих за текущей.
Инструкция RANGE, в отличие от ROWS, работает не со строками, а с диапазоном строк в инструкции ORDER BY. То есть под одной строкой для RANGE могут пониматься несколько физических строк одинаковых по рангу.
Обе инструкции ROWS и RANGE всегда используются вместе с ORDER BY.
В выражении для ограничения строк ROWS или RANGE также можно использовать следующие ключевые слова:
- UNBOUNDED PRECEDING — указывает, что окно начинается с первой строки группы;
- UNBOUNDED FOLLOWING – с помощью данной инструкции можно указать, что окно заканчивается на последней строке группы;
- CURRENT ROW – инструкция указывает, что окно начинается или заканчивается на текущей строке;
- BETWEEN«граница окна» AND «граница окна» — указывает нижнюю и верхнюю границу окна;
- «Значение»PRECEDING – определяет число строк перед текущей строкой (не допускается в предложении RANGE).;
- «Значение»FOLLOWING — определяет число строк после текущей строки (не допускается в предложении RANGE).
Разберем на примере:
В данном случае сумма рассчитывается по текущей и следующей ячейке в окне. А последняя строка в окне имеет то же значение, что и столбец «Conversions», потому что больше не с чем складывать.
Комбинируя ключевые слова, вы можете подогнать диапазон работы оконной функции под вашу специфическую задачу.
Виды функций
Оконные функции можно подразделить на следующие группы:
- Агрегатные функции;
- Ранжирующие функции;
- Функции смещения;
- Аналитические функции.
В одной инструкции SELECT с одним предложением FROM можно использовать сразу несколько оконных функций. Давайте подробно разберем каждую группу и пройдемся по основным функциям.
Агрегатные функции
Агрегатные функции – это функции, которые выполняют на наборе данных арифметические вычисления и возвращают итоговое значение.
- SUM – возвращает сумму значений в столбце;
- COUNT — вычисляет количество значений в столбце (значения NULL не учитываются);
- AVG — определяет среднее значение в столбце;
- MAX — определяет максимальное значение в столбце;
- MIN — определяет минимальное значение в столбце.
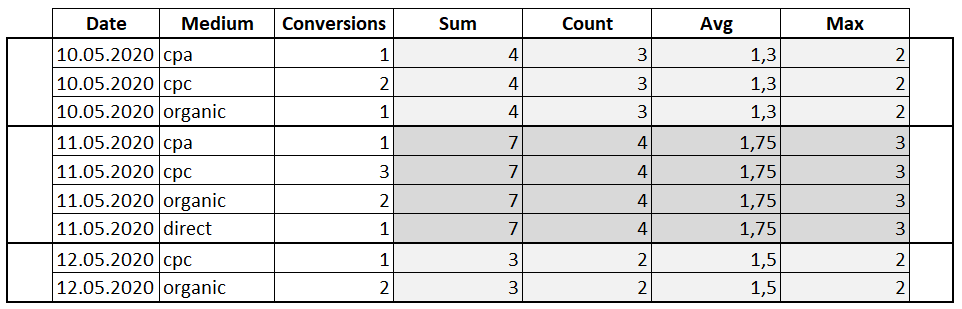
Пример использования агрегатных функций с оконной инструкцией OVER:
Ранжирующие функции
Ранжирующие функции – это функции, которые ранжируют значение для каждой строки в окне. Например, их можно использовать для того, чтобы присвоить порядковый номер строке или составить рейтинг.
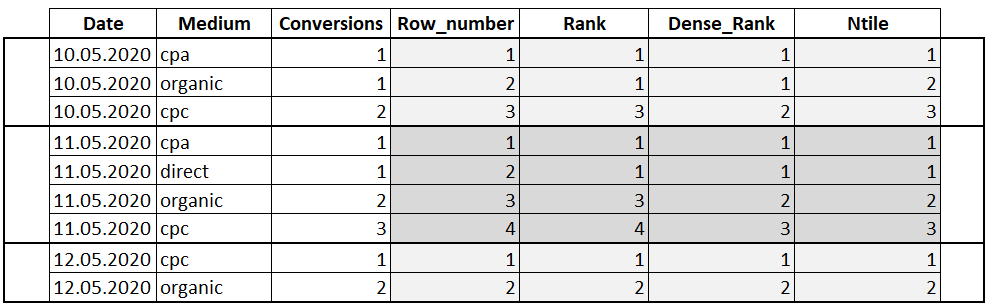
- ROW_NUMBER – функция возвращает номер строки и используется для нумерации;
- RANK — функция возвращает ранг каждой строки. В данном случае значения уже анализируются и, в случае нахождения одинаковых, возвращает одинаковый ранг с пропуском следующего значения;
- DENSE_RANK — функция возвращает ранг каждой строки. Но в отличие от функции RANK, она для одинаковых значений возвращает ранг, не пропуская следующий;
- NTILE – это функция, которая позволяет определить к какой группе относится текущая строка. Количество групп задается в скобках.
Функции смещения
Функции смещения – это функции, которые позволяют перемещаться и обращаться к разным строкам в окне, относительно текущей строки, а также обращаться к значениям в начале или в конце окна.
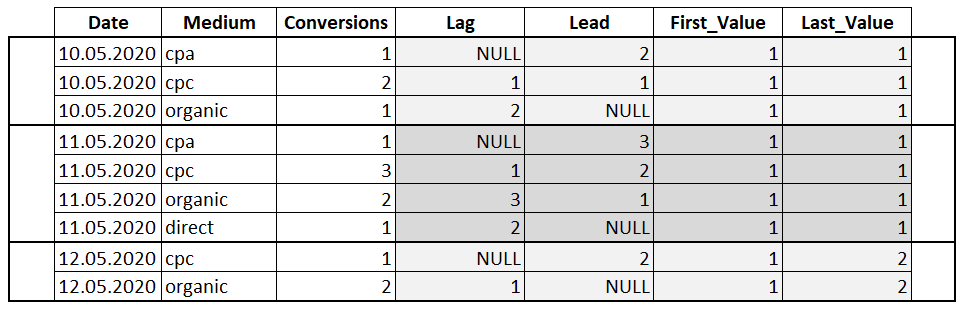
- LAG илиLEAD – функция LAG обращается к данным из предыдущей строки окна, а LEAD к данным из следующей строки. Функцию можно использовать для того, чтобы сравнивать текущее значение строки с предыдущим или следующим. Имеет три параметра: столбец, значение которого необходимо вернуть, количество строк для смещения (по умолчанию 1), значение, которое необходимо вернуть если после смещения возвращается значение NULL;
- FIRST_VALUE или LAST_VALUE — с помощью функции можно получить первое и последнее значение в окне. В качестве параметра принимает столбец, значение которого необходимо вернуть.
Аналитические функции
Аналитические функции — это функции которые возвращают информацию о распределении данных и используются для статистического анализа.
- CUME_DIST — вычисляет интегральное распределение (относительное положение) значений в окне;
- PERCENT_RANK — вычисляет относительный ранг строки в окне;
- PERCENTILE_CONT — вычисляет процентиль на основе постоянного распределения значения столбца. В качестве параметра принимает процентиль, который необходимо вычислить (в этой статье я рассказываю как посчитать медиану, благодаря этой функции);
- PERCENTILE_DISC — вычисляет определенный процентиль для отсортированных значений в наборе данных. В качестве параметра принимает процентиль, который необходимо вычислить.
Важно! У функций PERCENTILE_CONT и PERCENTILE_DISC, столбец, по которому будет происходить сортировка, указывается с помощью ключевого слова WITHIN GROUP.

Кейс. Модели атрибуции
Благодаря модели атрибуции можно обоснованно оценить вклад каждого канала в достижение конверсии. Давайте попробуем посчитать две разных модели атрибуции с помощью оконных функций.
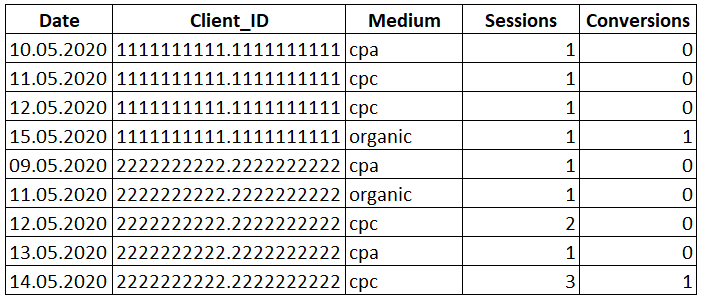
У нас есть таблица с id посетителя (им может быть Client ID, номер телефона и тп.), датами и количеством посещений сайта, а также с информацией о достигнутых конверсиях.
Первый клик
В Google Analytics стандартной моделью атрибуции является последний непрямой клик. И в данном случае 100% ценности конверсии присваивается последнему каналу в цепочке взаимодействий.
Попробуем посчитать модель по первому взаимодействию, когда 100% ценности конверсии присваивается первому каналу в цепочке при помощи функции FIRST_VALUE.
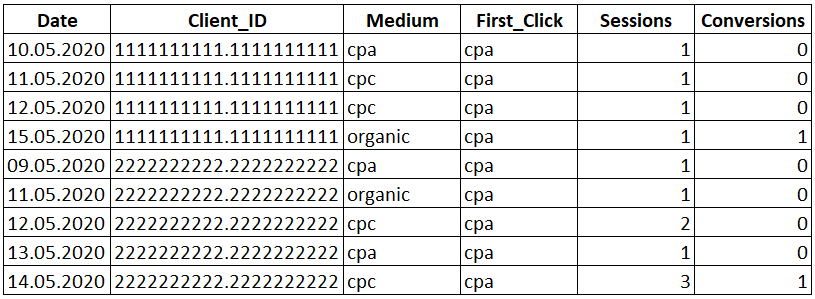
Рядом со столбцом «Medium» появился новый столбец «First_Click», в котором указан канал в первый раз приведший посетителя к нам на сайт и вся ценность зачтена данному каналу.
Произведем агрегацию и получим отчет.

С учетом давности взаимодействий
В этом случае работает правило: чем ближе к конверсии находится точка взаимодействия, тем более ценной она считается. Попробуем рассчитать эту модель при помощи функции DENSE_RANK.
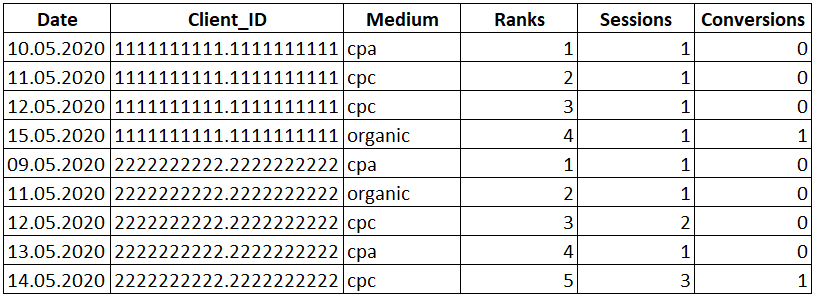
Рядом со столбцом «Medium» появился новый столбец «Ranks», в котором указан ранг каждой строки в зависимости от близости к дате конверсии.
Теперь используем этот запрос для того, чтобы распределить ценность равную 1 (100%) по всем точкам на пути к конверсии.

Рядом со столбцом «Medium» появился новый столбец «Time_Decay» с распределенной ценностью.
И теперь, если сделать агрегацию, можно увидеть как распределилась ценность по каналам.
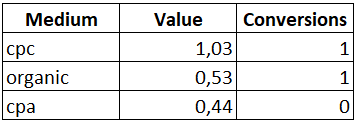
Из получившегося отчета видно, что самым весомым каналом является канал «cpc», а канал «cpa», который был бы исключен при применении стандартной модели атрибуции, тоже получил свою долю при распределении ценности.
Windows function in oracle
MySQL 8.0 Reference Manual Including MySQL NDB Cluster 8.0
12.21.2В Window Function Concepts and Syntax
This section describes how to use window functions. Examples use the same sales information data set as found in the discussion of the GROUPING() function in Section 12.20.2, “GROUP BY Modifiers”:
A window function performs an aggregate-like operation on a set of query rows. However, whereas an aggregate operation groups query rows into a single result row, a window function produces a result for each query row:
The row for which function evaluation occurs is called the current row.
The query rows related to the current row over which function evaluation occurs comprise the window for the current row.
For example, using the sales information table, these two queries perform aggregate operations that produce a single global sum for all rows taken as a group, and sums grouped per country:
By contrast, window operations do not collapse groups of query rows to a single output row. Instead, they produce a result for each row. Like the preceding queries, the following query uses SUM() , but this time as a window function:
Each window operation in the query is signified by inclusion of an OVER clause that specifies how to partition query rows into groups for processing by the window function:
The first OVER clause is empty, which treats the entire set of query rows as a single partition. The window function thus produces a global sum, but does so for each row.
The second OVER clause partitions rows by country, producing a sum per partition (per country). The function produces this sum for each partition row.
Window functions are permitted only in the select list and ORDER BY clause. Query result rows are determined from the FROM clause, after WHERE , GROUP BY , and HAVING processing, and windowing execution occurs before ORDER BY , LIMIT , and SELECT DISTINCT .
The OVER clause is permitted for many aggregate functions, which therefore can be used as window or nonwindow functions, depending on whether the OVER clause is present or absent:
MySQL also supports nonaggregate functions that are used only as window functions. For these, the OVER clause is mandatory:
As an example of one of those nonaggregate window functions, this query uses ROW_NUMBER() , which produces the row number of each row within its partition. In this case, rows are numbered per country. By default, partition rows are unordered and row numbering is nondeterministic. To sort partition rows, include an ORDER BY clause within the window definition. The query uses unordered and ordered partitions (the row_num1 and row_num2 columns) to illustrate the difference between omitting and including ORDER BY :
As mentioned previously, to use a window function (or treat an aggregate function as a window function), include an OVER clause following the function call. The OVER clause has two forms:
Both forms define how the window function should process query rows. They differ in whether the window is defined directly in the OVER clause, or supplied by a reference to a named window defined elsewhere in the query:
In the first case, the window specification appears directly in the OVER clause, between the parentheses.
In the second case, window_name is the name for a window specification defined by a WINDOW clause elsewhere in the query. For details, see Section 12.21.4, “Named Windows”.
For OVER ( window_spec ) syntax, the window specification has several parts, all optional:
If OVER() is empty, the window consists of all query rows and the window function computes a result using all rows. Otherwise, the clauses present within the parentheses determine which query rows are used to compute the function result and how they are partitioned and ordered:
window_name : The name of a window defined by a WINDOW clause elsewhere in the query. If window_name appears by itself within the OVER clause, it completely defines the window. If partitioning, ordering, or framing clauses are also given, they modify interpretation of the named window. For details, see Section 12.21.4, “Named Windows”.
partition_clause : A PARTITION BY clause indicates how to divide the query rows into groups. The window function result for a given row is based on the rows of the partition that contains the row. If PARTITION BY is omitted, there is a single partition consisting of all query rows.
Partitioning for window functions differs from table partitioning. For information about table partitioning, see ChapterВ 24, Partitioning.
partition_clause has this syntax:
Standard SQL requires PARTITION BY to be followed by column names only. A MySQL extension is to permit expressions, not just column names. For example, if a table contains a TIMESTAMP column named ts , standard SQL permits PARTITION BY ts but not PARTITION BY HOUR(ts) , whereas MySQL permits both.
order_clause : An ORDER BY clause indicates how to sort rows in each partition. Partition rows that are equal according to the ORDER BY clause are considered peers. If ORDER BY is omitted, partition rows are unordered, with no processing order implied, and all partition rows are peers.
order_clause has this syntax:
Each ORDER BY expression optionally can be followed by ASC or DESC to indicate sort direction. The default is ASC if no direction is specified. NULL values sort first for ascending sorts, last for descending sorts.
An ORDER BY in a window definition applies within individual partitions. To sort the result set as a whole, include an ORDER BY at the query top level.
frame_clause : A frame is a subset of the current partition and the frame clause specifies how to define the subset. The frame clause has many subclauses of its own. For details, see Section 12.21.3, “Window Function Frame Specification”.



