- Сбор данных с помощью сетевого монитора Collect data using Network Monitor
- Total Network Monitor 2
- Ваша корпоративная сеть под контролем
- Возможности программы
- Сканирование удаленных узлов
- Проверки и Мониторы
- Действия
- Карта сети
- Статистика
- 7 бесплатных программ для мониторинга сети и серверов
- Cacti
- Nagios
- Icinga
- Zabbix
- Observium
- Мониторинг сети своими руками
Сбор данных с помощью сетевого монитора Collect data using Network Monitor
В этом разделе вы узнаете, как использовать Microsoft Network Monitor 3.4, который является средством захвата сетевого трафика. In this topic, you will learn how to use Microsoft Network Monitor 3.4, which is a tool for capturing network traffic.
Network Monitor — это архивный анализатор протокола, который больше не находится в разработке. Network Monitor is the archived protocol analyzer and is no longer under development. Анализатор сообщений Майкрософт — это замена сетевого монитора. Microsoft Message Analyzer is the replacement for Network Monitor. Дополнительные сведения см. в руководстве по операционной работе анализатора сообщений Майкрософт. For more details, see Microsoft Message Analyzer Operating Guide.
Чтобы начать работу, скачайте средство Network Monitor. To get started, download Network Monitor tool. При установке сетевого монитора он устанавливает драйвер и подключает его к всем сетевым адаптерам, установленным на устройстве. When you install Network Monitor, it installs its driver and hooks it to all the network adapters installed on the device. На свойствах адаптеров можно увидеть то же самое, что и на следующем изображении: You can see the same on the adapter properties, as shown in the following image:
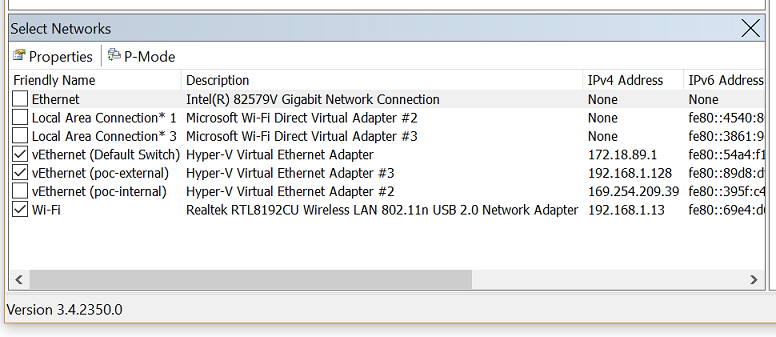
Когда во время установки драйвер подключается к карте сетевого интерфейса (NIC), NIC повторно получает новый интерфейс, что может вызвать кратковременный сбой в сети. When the driver gets hooked to the network interface card (NIC) during installation, the NIC is reinitialized, which might cause a brief network glitch.
Для захвата трафика To capture traffic
Запустите netmon в повышенном состоянии, выбрав run as Administrator. Run netmon in an elevated status by choosing Run as Administrator.
Сетевой монитор открывается со всеми сетевыми адаптерами. Network Monitor opens with all network adapters displayed. Выберите сетевые адаптеры, в которых необходимо захватить трафик, нажмите кнопку Новыйзахват и нажмите кнопку Начните. Select the network adapters where you want to capture traffic, click New Capture, and then click Start.

Воспроизведите проблему, и вы увидите, что Network Monitor захватывает пакеты на проводе. Reproduce the issue, and you will see that Network Monitor grabs the packets on the wire.

Выберите Стопи перейдите в файл > сохранить результаты. Select Stop, and go to File > Save as to save the results. По умолчанию файл будет сохранен в качестве файла «.cap». By default, the file will be saved as a «.cap» file.
Сохраненный файл запечатлел весь трафик, который пропускается в выбранные сетевые адаптеры на локальном компьютере и из него. The saved file has captured all the traffic that is flowing to and from the selected network adapters on the local computer. Однако вы заинтересованы только в том, чтобы посмотреть трафик/пакеты, связанные с конкретной проблемой подключения, с которой вы столкнулись. However, your interest is only to look into the traffic/packets that are related to the specific connectivity problem you are facing. Чтобы увидеть только связанный трафик, необходимо отфильтровать сетевой захват. So you will need to filter the network capture to see only the related traffic.
Часто используемые фильтры Commonly used filters
- Ipv4.address==»client ip» и ipv4.address==»server ip» Ipv4.address==»client ip» and ipv4.address==»server ip»
- Tcp.port== Tcp.port==
- Udp.port== Udp.port==
- Icmp Icmp
- Arp Arp
- Property.tcpretranmits Property.tcpretranmits
- Property.tcprequestfastretransmits Property.tcprequestfastretransmits
- Tcp.flags.syn==1 Tcp.flags.syn==1
Если вы хотите отфильтровать захват для определенного поля и не знать синтаксис для этого фильтра, щелкните правой кнопкой мыши это поле и выберите Добавить выбранное значение для **отображения фильтра ** **. If you want to filter the capture for a specific field and do not know the syntax for that filter, just right-click that field and select Add the selected value to Display Filter.
Сетевые трассировки, которые собираются с помощью команд netsh, встроенных в Windows, являются расширением «ETL». Network traces which are collected using the netsh commands built in to Windows are of the extension «ETL». Однако эти файлы ETL можно открыть с помощью сетевого монитора для дальнейшего анализа. However, these ETL files can be opened using Network Monitor for further analysis.
Total Network Monitor 2
Ваша корпоративная сеть под контролем
Хотите больше возможностей?
Инвентаризация сети
Мониторинг серверов

Разработка и распространение Total Network Monitor 2 полностью прекращены со 2 августа 2020 года. На смену ему пришел новый продукт —
Network Olympus, который по всем критериям превосходит своего предшественника, а также имеет больший потенциал к дальнейшему развитию.
Возможности программы
Сканирование удаленных узлов
Total Network Monitor помогает системным администраторам вести непрерывное наблюдение за работой локальной сети, постоянно проверяя статус отдельных компьютеров, сетевых и системных служб. Как только Total Network Monitor обнаружит неполадки, он сразу же оповестит вас, позволяя исправить их прежде чем они перерастут в серьёзные проблемы. Низкая нагрузка на сеть и малое потребление ресурсов системы, многопоточная работа и ведение подробных журналов делают Total Network Monitor идеальным решением для любых сетей.
Проверки и Мониторы

Total Network Monitor может гораздо больше чем просто проверять доступность серверов и оборудования с определённой периодичностью. Большой список проверок позволяет контролировать состояние различных компонентов в инфраструктуре вашей сети.
TCP/IP – проверка более высокого уровня; она позволяет проверять работоспособность вашего почтового, файлового или веб-сервера, посылая запрос на определённые TCP-порты.
Проверки Windows позволяют собирать информацию о текущем состоянии ваших серверных и клиентских Windows-систем. Доступна проверка производительности системы, ключей реестра, служб и журнала событий.
Действия
В современном мире корпоративные сети должны работать без сбоев 99% времени. Вовремя получив уведомление о неполадке, вы получаете возможность не дать ей перерасти в крупную аварию.
Когда Total Network Monitor обнаруживает неполадку, программа сразу же пытается предупредить системного администратора, выполнив одно из предварительно настроенных действий: издав звуковой сигнал, отобразив сообщение на текущем компьютере, отправив email с подробным описанием проблемы, отправив jabber-сообщение или связавшись с администратором через внешнее приложение.
Кроме того, Total Network Monitor может выполнять определённые действия, которые могут полностью или частично устранить возникшую проблему (запустив приложение, выполнив перезагрузку или перезапустив службу). Записи о любых возникших проблемах вносятся в журнал.
Карта сети
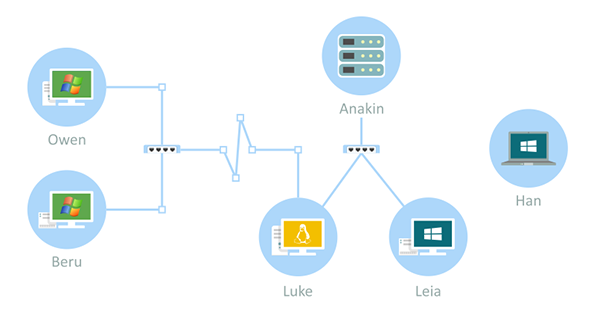
В Total Network Monitor присутствует возможность отображения наглядной карты вашей сети с индикацией состояния проверок всех устройств. На карте вы можете перемещать иконки, которые представляют ваши сетевые устройства и компьютеры, а также создавать связи между ними. Все устройства, которые требуют внимания, подсвечиваются красным, это позволит с первого взгляда обнаружить неполадки в сети.
Статистика
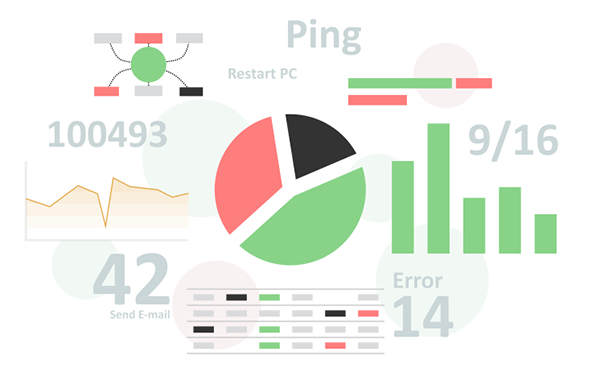
Total Network Monitor записывает состояние всех работающих мониторов в журнал, сохраняя полную информацию о состоянии вашей сети и доступности тех или иных служб. Данная информация может быть просмотрена непосредственно на панели статистики и в диаграмме активности, либо она может быть экспортирована для построения электронной или печатной версии отчёта.
В журналах доступна информация об общем времени работы сети и состоянии всех проверок, что позволяет просматривать полную историю всех возникших проблем или перебоев в работе. Отдельно доступен журнал по всем выполненным действиям. Количество информации, записываемой в журнал, может быть настроено, позволяя печатать как краткие сводки, так и отображать полный технический отчет о каждом событии.
7 бесплатных программ для мониторинга сети и серверов
Мантра мира недвижимости — Местоположение, Местоположение, Местоположение. Для мира системного администрирования этот священный текст должен звучать так: Видимость, Видимость и еще раз Видимость. Если каждую секунду на протяжении всего дня вы досконально не знаете, что делают ваша сеть и сервера, вы похожи на пилота, который летит вслепую. Вас неминуемо ждет катастрофа. К счастью для вас, на рынке сейчас доступно много хороших программ, как коммерческих, так и с открытым исходным кодом, способных наладить ваш сетевой мониторинг.

Поскольку хорошее и бесплатное всегда заманчивее хорошего и дорогого, предлагаем вам список программ с открытым исходным кодом, которые каждый день доказывают свою ценность в сетях любого размера. От обнаружения устройств, мониторинга сетевого оборудования и серверов до выявления тенденций в функционировании сети, графического представления результатов мониторинга и даже создания резервных копий конфигураций коммутаторов и маршрутизаторов — эти семь бесплатных утилит, скорее всего, смогут приятно удивить вас.
Cacti
Сначала был MRTG (Multi Router Traffic Grapher) — программа для организации сервиса мониторинга сети и измерения данных с течением времени. Еще в 1990-х, его автор Тобиас Отикер (Tobias Oetiker) счел нужным написать простой инструмент для построения графиков, использующий кольцевую базу данных, изначально используемый для отображения пропускной способности маршрутизатора в локальной сети. Так MRTG породил RRDTool, набор утилит для работы с RRD (Round-robin Database, кольцевой базой данных), позволяющий хранить, обрабатывать и графически отображать динамическую информацию, такую как сетевой трафик, загрузка процессора, температура и так далее. Сейчас RRDTool используется в огромном количестве инструментов с открытым исходным кодом. Cacti — это современный флагман среди программного обеспечения с открытым исходным кодом в области графического представления сети, и он выводит принципы MRTG на принципиально новый уровень.
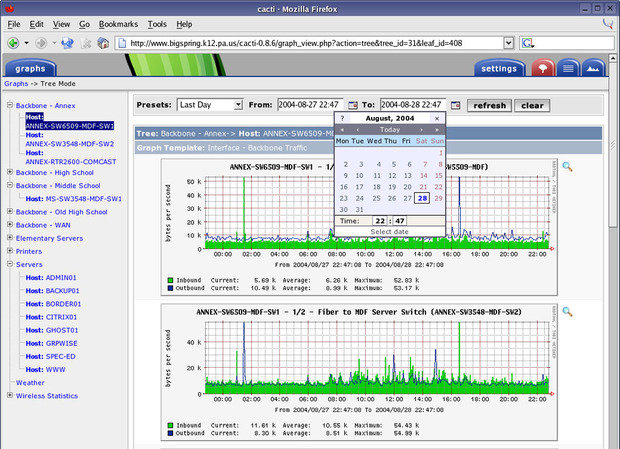
От использования диска до скорости вентилятора в источнике питания, если показатель можно отслеживать, Cacti сможет отобразить его и сделать эти данные легкодоступными.
Cacti — это бесплатная программа, входящее в LAMP-набор серверного программного обеспечения, которое предоставляет стандартизированную программную платформу для построения графиков на основе практически любых статистических данных. Если какое-либо устройство или сервис возвращает числовые данные, то они, скорее всего, могут быть интегрированы в Cacti. Существуют шаблоны для мониторинга широкого спектра оборудования — от Linux- и Windows-серверов до маршрутизаторов и коммутаторов Cisco, — в основном все, что общается на SNMP (Simple Network Management Protocol, простой протокол сетевого управления). Существуют также коллекции шаблонов от сторонних разработчиков, которые еще больше расширяют и без того огромный список совместимых с Cacti аппаратных средств и программного обеспечения.
Несмотря на то, что стандартным методом сбора данных Cacti является протокол SNMP, также для этого могут быть использованы сценарии на Perl или PHP. Фреймворк программной системы умело разделяет на дискретные экземпляры сбор данных и их графическое отображение, что позволяет с легкостью повторно обрабатывать и реорганизовывать существующие данные для различных визуальных представлений. Кроме того, вы можете выбрать определенные временные рамки и отдельные части графиков просто кликнув на них и перетащив.
Так, например, вы можете быстро просмотреть данные за несколько прошлых лет, чтобы понять, является ли текущее поведение сетевого оборудования или сервера аномальным, или подобные показатели появляются регулярно. А используя Network Weathermap, PHP-плагин для Cacti, вы без чрезмерных усилий сможете создавать карты вашей сети в реальном времени, показывающие загруженность каналов связи между сетевыми устройствами, реализуемые с помощью графиков, которые появляются при наведении указателя мыши на изображение сетевого канала. Многие организации, использующие Cacti, выводят эти карты в круглосуточном режиме на 42-дюймовые ЖК-мониторы, установленные на стене, позволяя ИТ-специалистам мгновенно отслеживать информацию о загруженности сети и состоянии канала.
Таким образом, Cacti — это инструментарий с обширными возможностями для графического отображения и анализа тенденций производительности сети, который можно использовать для мониторинга практически любой контролируемой метрики, представляемой в виде графика. Данное решение также поддерживает практически безграничные возможности для настройки, что может сделать его чересчур сложным при определенных применениях.
Nagios
Nagios — это состоявшаяся программная система для мониторинга сети, которая уже многие годы находится в активной разработке. Написанная на языке C, она позволяет делать почти все, что может понадобится системным и сетевым администраторам от пакета прикладных программ для мониторинга. Веб-интерфейс этой программы является быстрым и интуитивно понятным, в то время его серверная часть — чрезвычайно надежной.
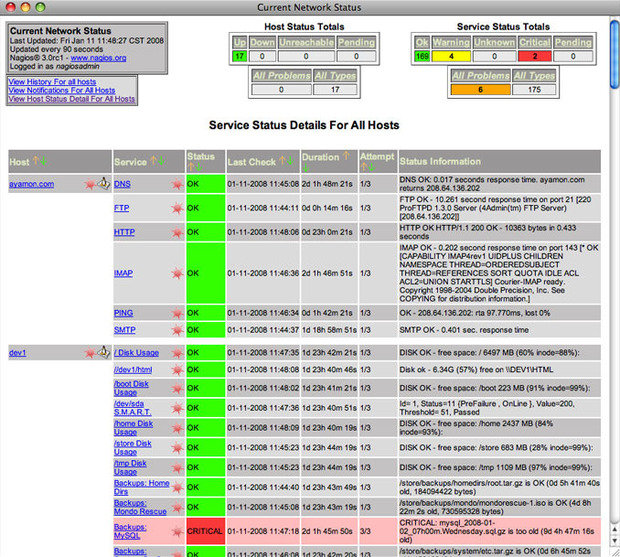
Nagios может стать проблемой для новичков, но довольно сложная конфигурация также является преимуществом этого инструмента, так как он может быть адаптирован практически к любой задаче мониторинга.
Как и Cacti, очень активное сообщество поддерживает Nagios, поэтому различные плагины существуют для огромного количества аппаратных средств и программного обеспечения. От простейших ping-проверок до интеграции со сложными программными решениями, такими как, например, написанным на Perl бесплатным программным инструментарием WebInject для тестирования веб-приложений и веб сервисов. Nagios позволяет осуществлять постоянный мониторинг состояния серверов, сервисов, сетевых каналов и всего остального, что понимает протокол сетевого уровня IP. К примеру, вы можете контролировать использование дискового пространства на сервере, загруженность ОЗУ и ЦП, использования лицензии FLEXlm, температуру воздуха на выходе сервера, задержки в WAN и Интеренет-канале и многое другое.
Очевидно, что любая система мониторинга серверов и сети не будет полноценной без уведомлений. У Nagios с этим все в порядке: программная платформа предлагает настраиваемый механизм уведомлений по электронной почте, через СМС и мгновенные сообщения большинства популярных Интернет-мессенджеров, а также схему эскалации, которая может быть использована для принятия разумных решений о том, кто, как и при каких обстоятельствах должен быть уведомлен, что при правильной настройке поможет вам обеспечить многие часы спокойного сна. А веб-интерфейс может быть использован для временной приостановки получения уведомлений или подтверждения случившейся проблемы, а также внесения заметок администраторами.
Кроме того, функция отображения демонстрирует все контролируемые устройства в логическом представлении их размещения в сети, с цветовым кодированием, что позволяет показать проблемы по мере их возникновения.
Недостатком Nagios является конфигурация, так как ее лучше всего выполнять через командную строку, что значительно усложняет обучение новичков. Хотя люди, знакомые со стандартными файлами конфигурации Linux/Unix, особых проблем испытать не должны.
Возможности Nagios огромны, но усилия по использованию некоторых из них не всегда могут стоить затраченных на это усилий. Но не позволяйте сложностям запугать вас: преимущества системы раннего предупреждения, предоставляемые этим инструментом для столь многих аспектов сети, сложно переоценить.
Icinga
Icinga начиналась как ответвление от системы мониторинга Nagios, но недавно была переписана в самостоятельное решение, известное как Icinga 2. На данный момент обе версии программы находятся в активной разработке и доступны к использованию, при этом Icinga 1.x совместима с большим количеством плагинами и конфигурацией Nagios. Icinga 2 разрабатывалась менее громоздкой, с ориентацией на производительность, и более удобной в использовании. Она предлагает модульную архитектуру и многопоточный дизайн, которых нет ни в Nagios, ни в Icinga 1.
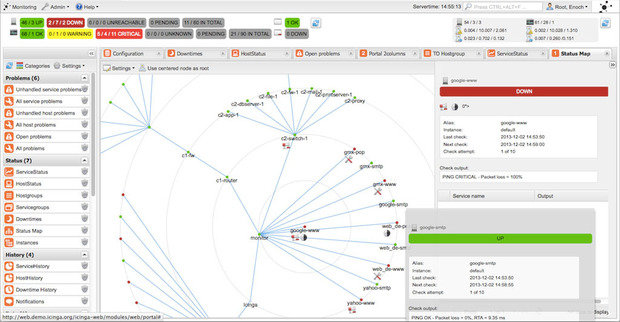
Icinga предлагает полноценную программную платформу для мониторинга и системы оповещения, которая разработана такой же открытой и расширяемой, как и Nagios, но с некоторыми отличиями в веб-интерфейсе.
Как и Nagios, Icinga может быть использована для мониторинга всего, что говорит на языке IP, настолько глубоко, насколько вы можете использовать SNMP, а также настраиваемые плагины и дополнения.
Существует несколько вариаций веб-интерфейса для Icinga, но главным отличием этого программного решения для мониторинга от Nagios является конфигурация, которая может быть выполнена через веб-интерфейс, а не через файлы конфигурации. Для тех, кто предпочитает управлять своей конфигурацией вне командной строки, эта функциональность станет настоящим подарком.
Icinga интегрируется со множеством программных пакетов для мониторинга и графического отображения, таких как PNP4Nagios, inGraph и Graphite, обеспечивая надежную визуализацию вашей сети. Кроме того, Icinga имеет расширенные возможности отчетности.
Если вам когда-либо приходилось для поиска устройств в вашей сети подключаться через протокол Telnet к коммутаторам и выполнять поиск по MAC-адресу, или вы просто хотите, чтобы у вас была возможность определить физическое местоположение определенного оборудования (или, что, возможно, еще более важно, где оно было расположено ранее), тогда вам будет интересно взглянуть на NeDi.
NeDi постоянно просматривает сетевую инфраструктуру и каталогизирует устройства, отслеживая все, что обнаружит.
NeDi — это бесплатное программное обеспечение, относящее к LAMP, которое регулярно просматривает MAC-адреса и таблицы ARP в коммутаторах вашей сети, каталогизируя каждое обнаруженное устройство в локальной базе данных. Данный проект не является столь хорошо известным, как некоторые другие, но он может стать очень удобным инструментом при работе с корпоративными сетями, где устройства постоянно меняются и перемещаются.
Вы можете через веб-интерфейс NeDi задать поиск для определения коммутатора, порта коммутатора, точки доступа или любого другого устройства по MAC-адресу, IP-адресу или DNS-имени. NeDi собирает всю информацию, которую только может, с каждого сетевого устройства, с которым сталкивается, вытягивая с них серийные номера, версии прошивки и программного обеспечения, текущие временные параметры, конфигурации модулей и т. д. Вы даже можете использовать NeDi для отмечания MAC-адресов устройств, которые были потеряны или украдены. Если они снова появятся в сети, NeDi сообщит вам об этом.
Обнаружение запускается процессом cron с заданными интервалами. Конфигурация простая, с единственным конфигурационным файлом, который позволяет значительно повысить количество настроек, в том числе возможность пропускать устройства на основе регулярных выражений или заданных границ сети. NeDi, обычно, использует протоколы Cisco Discovery Protocol или Link Layer Discovery Protocol для обнаружения новых коммутаторов и маршрутизаторов, а затем подключается к ним для сбора их информации. Как только начальная конфигурация будет установлена, обнаружение устройств будет происходить довольно быстро.
До определенного уровня NeDi может интегрироваться с Cacti, поэтому существует возможность связать обнаружение устройств с соответствующими графиками Cacti.
Проект Ntop — сейчас для «нового поколения» более известный как Ntopng — прошел долгий путь развития за последнее десятилетие. Но назовите его как хотите — Ntop или Ntopng, — в результате вы получите первоклассный инструмент для мониторинга сетевого траффика в паре с быстрым и простым веб-интерфейсом. Он написан на C и полностью самодостаточный. Вы запускаете один процесс, настроенный на определенный сетевой интерфейс, и это все, что ему нужно.
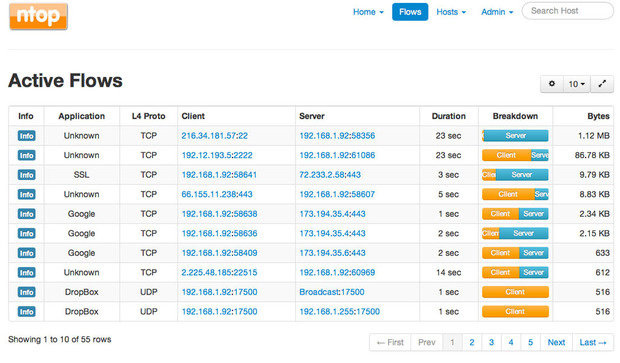
Ntop — это инструмент для анализа пакетов с легким веб-интерфейсом, который показывает данные в реальном времени о сетевом трафике. Информация о потоке данных через хост и о соединении с хостом также доступны в режиме реального времени.
Ntop предоставляет легко усваиваемые графики и таблицы, показывающие текущий и прошлый сетевой трафик, включая протокол, источник, назначение и историю конкретных транзакций, а также хосты с обоих концов. Кроме того, вы найдете впечатляющий набор графиков, диаграмм и карт использования сети в реальном времени, а также модульную архитектуру для огромного количества надстроек, таких как добавление мониторов NetFlow и sFlow. Здесь вы даже сможете обнаружить Nbox — аппаратный монитор, который встраивает в Ntop.
Кроме того, Ntop включает API-интерфейс для скриптового языка программирования Lua, который может быть использован для поддержки расширений. Ntop также может хранить данные хоста в файлах RRD для осуществления постоянного сбора данных.
Одним из самых полезных применений Ntopng является контроль трафика в конкретном месте. К примеру, когда на вашей карте сети часть сетевых каналов подсвечены красным, но вы не знаете почему, вы можете с помощью Ntopng получить поминутный отчет о проблемном сегменте сети и сразу узнать, какие хосты ответственны за проблему.
Пользу от такой видимости сети сложно переоценить, а получить ее очень легко. По сути, вы можете запустить Ntopng на любом интерфейсе, который был настроен на уровне коммутатора, для мониторинга другого порта или VLAN. Вот и все.
Zabbix
Zabbix — это полномасштабный инструмент для сетевого и системного мониторинга сети, который объединяет несколько функций в одной веб-консоли. Он может быть сконфигурирован для мониторинга и сбора данных с самых разных серверов и сетевых устройств, обеспечивая обслуживание и мониторинг производительности каждого объекта.
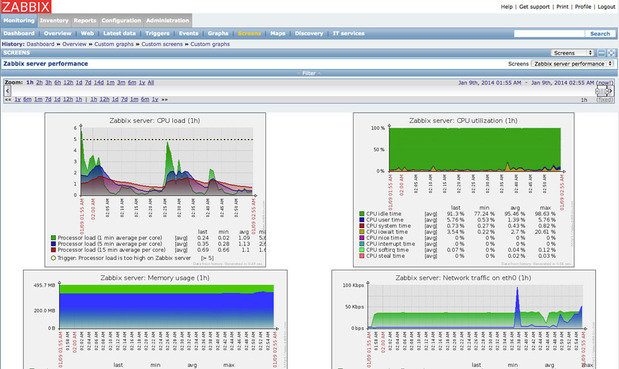
Zabbix позволяет производить мониторинг серверов и сетей с помощью широкого набора инструментов, включая мониторинг гипервизоров виртуализации и стеков веб-приложений.
В основном, Zabbix работает с программными агентами, запущенными на контролируемых системах. Но это решение также может работать и без агентов, используя протокол SNMP или другие возможности для осуществления мониторинга. Zabbix поддерживает VMware и другие гипервизоры виртуализации, предоставляя подробные данные о производительности гипервизора и его активности. Особое внимание также уделяется мониторингу серверов приложений Java, веб-сервисов и баз данных.
Хосты могут добавляться вручную или через процесс автоматического обнаружения. Широкий набор шаблонов по умолчанию применяется к наиболее распространенным вариантам использования, таким как Linux, FreeBSD и Windows-сервера; широко-используемые службы, такие как SMTP и HTTP, а также ICMP и IPMI для подробного мониторинга аппаратной части сети. Кроме того, пользовательские проверки, написанные на Perl, Python или почти на любом другом языке, могут быть интегрированы в Zabbix.
Zabbix позволяет настраивать панели мониторинга и веб-интерфейс, чтобы сфокусировать внимание на наиболее важных компонентах сети. Уведомления и эскалации проблем могут основываться на настраиваемых действиях, которые применяются к хостам или группам хостов. Действия могут даже настраиваться для запуска удаленных команд, поэтому некий ваш сценарий может запускаться на контролируемом хосте, если наблюдаются определенные критерии событий.
Программа отображает в виде графиков данные о производительности, такие как пропускная способность сети и загрузка процессора, а также собирает их для настраиваемых систем отображения. Кроме того, Zabbix поддерживает настраиваемые карты, экраны и даже слайд-шоу, отображающие текущий статус контролируемых устройств.
Zabbix может быть сложным для реализации на начальном этапе, но разумное использование автоматического обнаружения и различных шаблонов может частично облегчить трудности с интеграцией. В дополнение к устанавливаемому пакету, Zabbix доступен как виртуальное устройство для нескольких популярных гипервизоров.
Observium
Observium — это программа для мониторинга сетевого оборудования и серверов, которое имеет огромный список поддерживаемых устройств, использующих протокол SNMP. Как программное обеспечение, относящееся к LAMP, Observium относительно легко устанавливается и настраивается, требуя обычных установок Apache, PHP и MySQL, создания базы данных, конфигурации Apache и тому подобного. Он устанавливается как собственный сервер с выделенным URL-адресом.
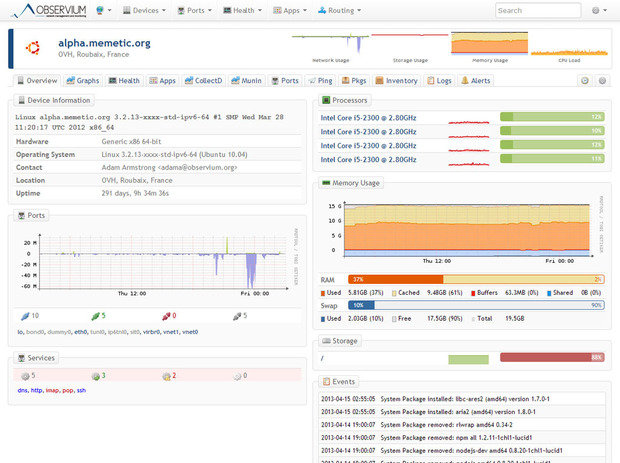
Observium сочетает в себе мониторинг систем и сетей с анализом тенденций производительности. Он может быть настроен для отслеживания практически любых показателей.
Вы можете войти в графический интерфейс и начать добавлять хосты и сети, а также задать диапазоны для автоматического обнаружения и данные SNMP, чтобы Observium мог исследовать окружающие его сети и собирать данные по каждой обнаруженной системе. Observium также может обнаруживать сетевые устройства через протоколы CDP, LLDP или FDP, а удаленные агенты хоста могут быть развернуты на Linux-системах, чтобы помочь в сборе данных.
Все эта собранная информация доступна через легкий в использовании пользовательский интерфейс, который предоставляет продвинутые возможности для статистического отображения данных, а также в виде диаграмм и графиков. Вы можете получить что угодно: от времени отклика ping и SNMP до графиков пропускной способности, фрагментации, количества IP-пакетов и т. д. В зависимости от устройства, эти данные могут быть доступны вплоть для каждого обнаруженного порта.
Что касается серверов, то для них Observium может отобразить информацию о состоянии центрального процессора, оперативной памяти, хранилища данных, свопа, температуры и т. д. из журнала событий. Вы также можете включить сбор данных и графическое отображение производительности для различных сервисов, включая Apache, MySQL, BIND, Memcached, Postfix и другие.
Observium отлично работает как виртуальная машина, поэтому может быстро стать основным инструментом для получения информации о состоянии серверов и сетей. Это отличный способ добавить автоматическое обнаружение и графическое представление в сеть любого размера.
Мониторинг сети своими руками
Слишком часто ИТ-администраторы считают, что они ограничены в своих возможностях. Независимо от того, имеем ли мы дело с пользовательским программным приложением или «неподдерживаемой» частью аппаратного обеспечения, многие из нас считают, что если система мониторинга не сможет сразу же справиться с ним, то получить в этой ситуации необходимые данные невозможно. Это, конечно же, не так. Приложив немного усилий, вы сможете почти все сделать более видимым, учтенным и контролируемым.

В качестве примера можно привести пользовательское приложение с базой данных на серверной части, например, интернет-магазин. Ваш менеджмент хочет увидеть красивые графики и диаграммы, оформленные то в одном виде, то в другом. Если вы уже используете, скажем, Cacti, у вас есть несколько возможностей вывести собранные данные в требуемом формате. Вы можете, к примеру, написать простой скрипт на Perl или PHP для запуска запросов в базе данных и передачи этих расчетов в Cacti либо же использовать SNMP-вызов к серверу базы данных, используя частный MIB (Management Information Base, база управляющей информации). Так или иначе, но задача может быть выполнена, и выполнена легко, если у вас есть необходимый для этого инструментарий.
Получить доступ к большинству из приведенных в данной статье бесплатных утилит для мониторинга сетевого оборудования не должно быть сложно. У них есть пакетные версии, доступные для загрузки для наиболее популярных дистрибутивов Linux, если только они изначально в него не входят. В некоторых случаях они могут быть предварительно сконфигурированы как виртуальный сервер. В зависимости от размера вашей инфраструктуры, конфигурирование и настройка этих инструментов может занять довольно много времени, но как только они заработают, они станут надежной опорой для вас. В крайнем случае, стоит хотя бы протестировать их.
Независимо от того, какую из этих вышеперечисленных систем вы используете, чтобы следить за своей инфраструктурой и оборудованием, она предоставит вам как минимум функциональные возможности еще одного системного администратора. Она хоть не может ничего исправить, но будет следить буквально за всем в вашей сети круглые сутки и семь дней в неделю. Предварительно потраченное время на установку и настройку окупятся с лихвой. Кроме того, обязательно запустите небольшой набор автономных средств мониторинга на другом сервере, чтобы наблюдать за основным средством мониторинга. Это то случай, когда всегда лучше следить за наблюдателем.
Появились вопросы или нужна консультация? Обращайтесь!



