- Настраиваем сбор логов Windows Server в ELK Stack
- Введение
- Сбор windows логов
- Dashboard в Kibana для Windows Server
- Сбор и анализ логов Windows Fileserver
- Заключение
- Централизованный Event Log в Windows 2008 Server
- Мониторинг производительности Windows Server, настройка оповещений счетчиков PerfMon
- Мониторинг производительности процессора с Perfomance Monitor
- Группы сборщиков данных в PerfMon
- Создание Alert для мониторинга загрузки CPU
Настраиваем сбор логов Windows Server в ELK Stack

Продолжаю цикл статей по настройке централизованной системы сбора логов ELK Stack. Сегодня расскажу, как собирать логи с Windows Server различных версий в elasticsearch. Данные предложенным способом можно будет собирать не только с серверных систем, но и со всех остальных, где используется журнал windows.
Введение
В своей статье я буду считать, что вы установили и настроили elk stack по моему материалу. Если это не так, то сами подредактируйте представленные конфиги под свои реалии. По большому счету, все самое основное по сбору логов windows серверов уже дано в указанной статье. Как минимум, там рассказано, как начать собирать логи с помощью winlogbeat. Дальше нам нужно их обработать и нарисовать функциональный дашборд для быстрого анализа поступающей информации.
Для того, чтобы оценить представленные мной графики и дашборды, рекомендую собирать логи сразу с нескольких серверов. Так можно будет оценить представленную информацию на практике. С одним сервером не так наглядно получится.
С визуализацией данных из windows журналов проблем нет никаких. Winlogbeat из коробки умеет парсить логи и добавлять все необходимые метаданные. Со стороны logstash не нужны никакие фильтры. Принимаем все данные как есть с winlogbeat.
Сбор windows логов
Приступим к настройке. Устанавливаем последнюю версию winlogbeat на сервер, с которого мы будем отправлять логи в elk stack. Вот конфиг с тестового сервера, по которому пишу статью:
Теперь настраивает logstash на прием этих логов. Добавляем в конфиг:
Я формирую месячные индексы с логами windows серверов. Если у вас очень много логов или хотите более гибкое управление занимаемым объемом, то делайте индексы дневные, указав winsrv-%<+YYYY.MM.dd>.
Перезапускайте службы на серверах и ждите поступления данных в elasticsearch.
Dashboard в Kibana для Windows Server
После того, как данные из логов windows серверов начали поступать в elk stack, можно приступить к их визуализации. Я предлагаю такую информацию для Dashboard в kibana:
- Количество логов с разбивкой по серверам
- Количество записей в каждом журнале
- Разбивка по уровням критичности (поле level)
- Разбивка по ID событий в логах (поле event_id)
- Список имен компьютеров, фигурирующих в логах (поле event_data.Workstation)
- Список пользователей в логах (поле event_data.TargetUserName)
- Разбивка по IP адресам (поле event_data.IpAddress)
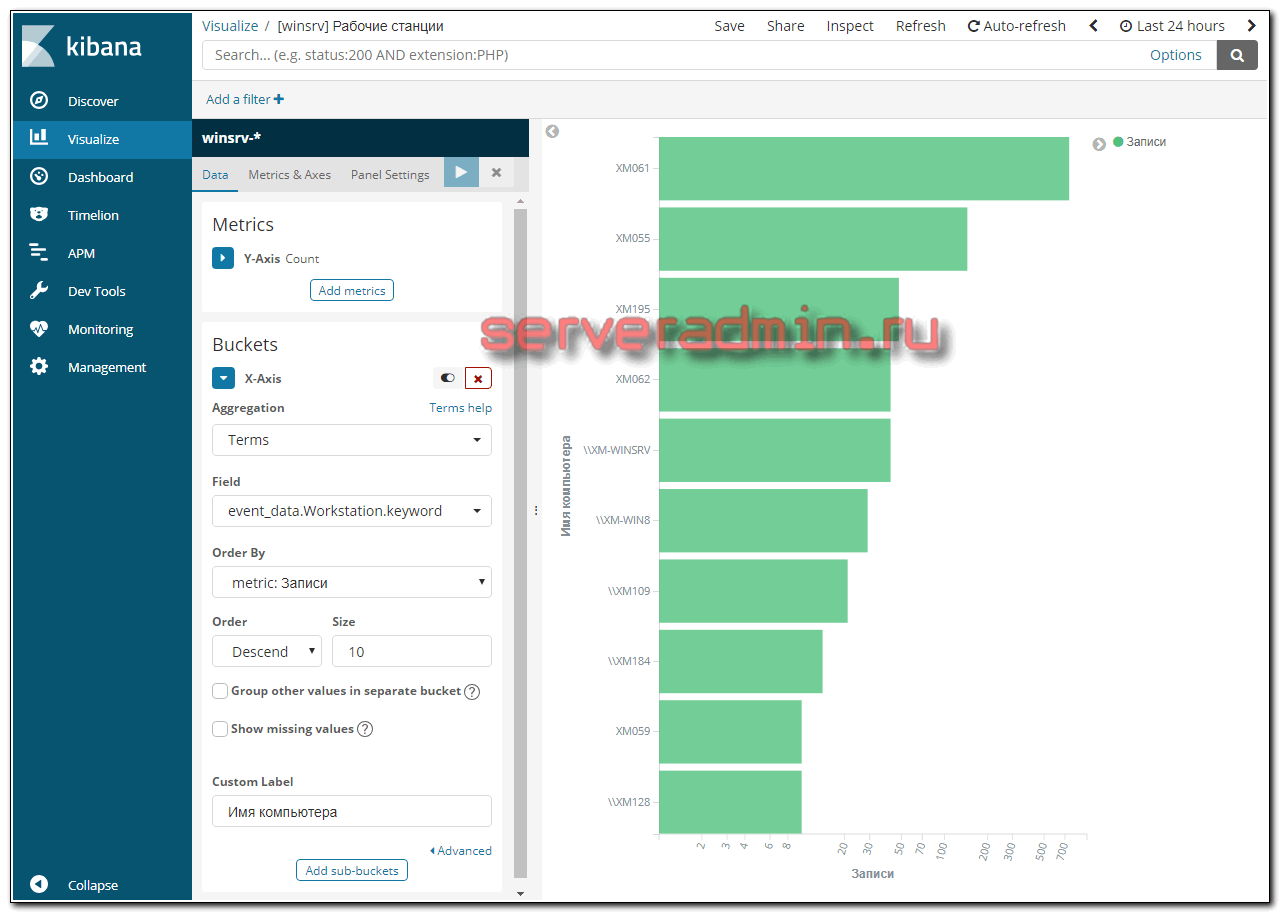
Визуализации создаются достаточно просто, плюс они все похожи друг на друга. Вот пример одной из них — разбивка по рабочим станциям:
А вот какой Dashbord у меня получился в итоге:
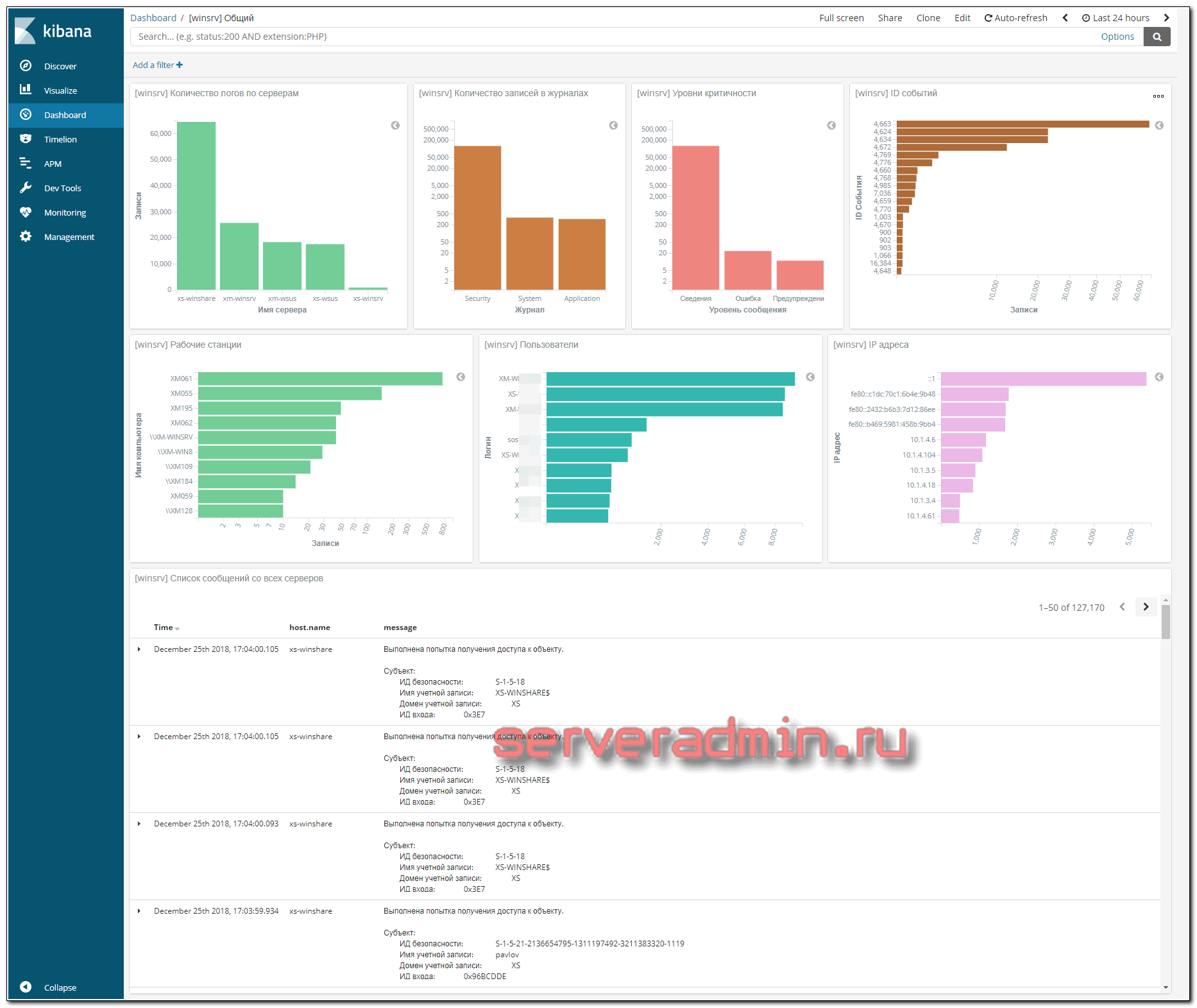
В самом низу идет список логов с сырым текстом события. Отдельно представляю дашборд для файлового сервера windows.
Сбор и анализ логов Windows Fileserver
Для файлового сервера настраиваем сбор логов в ELK Stack точно так же, как я показал выше. Для визуализации данных я настроил отдельный дашборд в Kibana со следующей информацией:
- Имена пользователей, которые обращаются к файлам (поле event_data.SubjectUserName)
- Типы запросов, которые выполняются (поле file_action)
- Список доступа к файлам (формируется из сохраненного фильтра поиска)
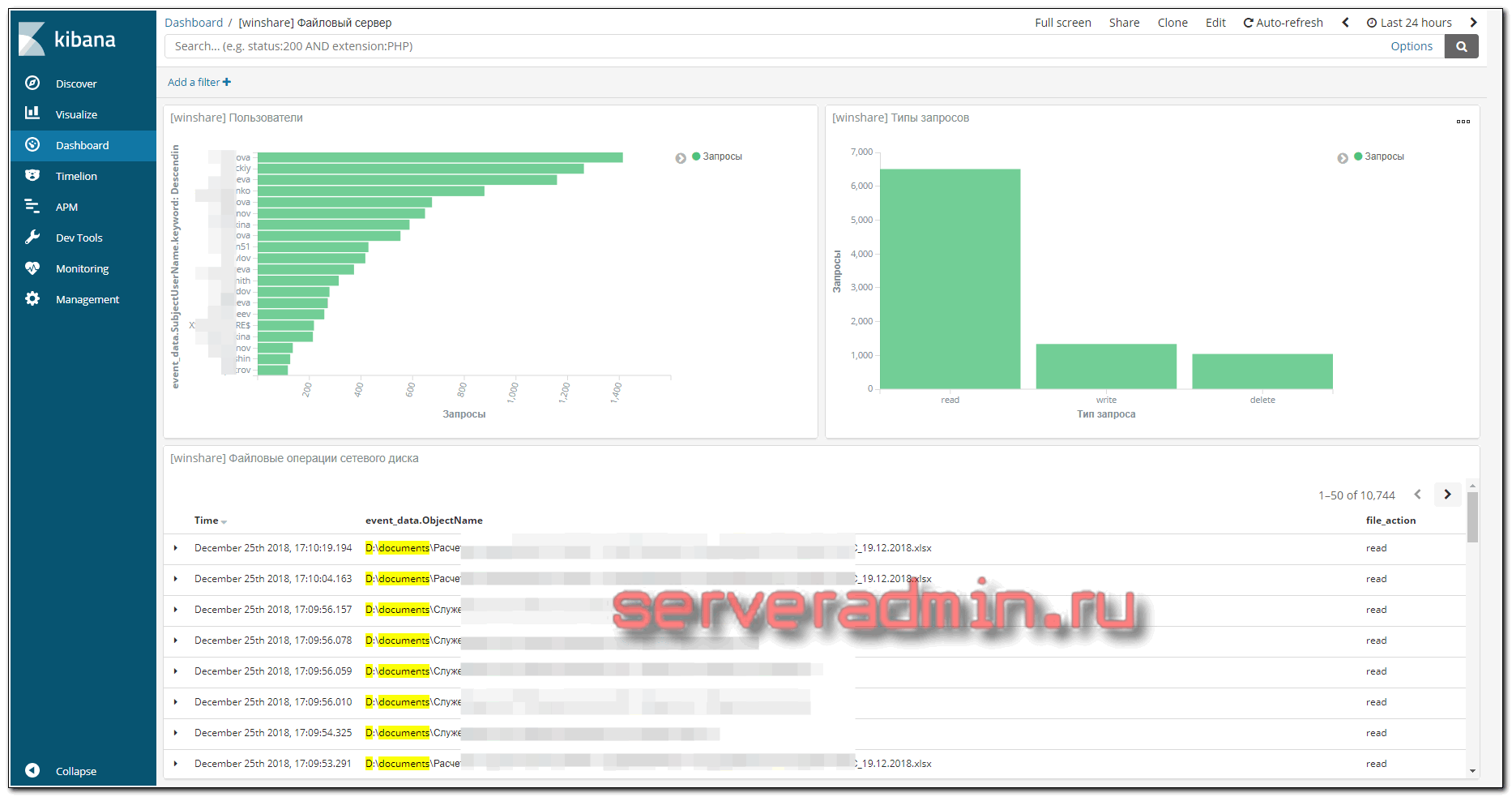
Возможно, кому-то будет актуально выводить на дашборд еще и информацию об именах файлов, к которым идет доступ. Информация об этом хранится в поле event_data.ObjectName. Лично я не увидел в этом необходимости.
Заключение
Материал написан исключительно на основании своего видения и небольшого опыта использования elk stack. Нигде не видел статей и мыслей на данную тему, так что буду рад предложениям, замечаниям. Ко всему прочему, я практически не администрирую windows сервера. Пишите обо всем в комментариях.
Централизованный Event Log в Windows 2008 Server
Мне очень понравилась новая возможность по работе с журналами событий в Windows 2008/7/Vista, называемая Event Log forwarding (subscription — или подписка), которая основана на технологии WinRM. Данная функция позволяет вам получить все события со всех журналов с множества серверов без использования сторонних продуктов и настраивается все это в течении всего пары минут. Возможно, именно эта технология позволит вам отказаться от столь любимых многими системными администраторами Kiwi Syslog Viewer и Splunk.
Итак схема такая, у нас есть сервер Windows 2008, запущенный в качестве коллектора логов с одного или нескольких источников. В качестве подготовительной работы нужно выполнить следующие 3 шага:
На коллекторе логов в командной строке с правами администратора запустите следующую команду, которая запустит службу Windows Event Collector Service, измените тип ее запуска в автоматический (Automatically — Delayed Start) и включите канал ForwardedEvents, если он был отключен.
wecutil qc
На каждом из источников нужно активировать WinRM:
winrm quickconfig
По умолчанию сервер-коллектор логов не может просто собирать информацию из журналов событий источников, вам придется добавить учетную запись компьютера-коллектора в локальные администраторы на все сервера-источники логов (в том случае, если сервер-источник работает под управлением 2008 R2, то достаточно добавить учетку коллектора в группу Event Log Readers)
Теперь мы должны создать подписки (Subscriptions) на сервер коллектор. Для чего зайдите на него, откройте консоль MMC Event Viewer, щелкните правой кнопкой мыши по Subscriptions и выберите Create Subscription:
Здесь вы можете выбрать несколько различных настроек.
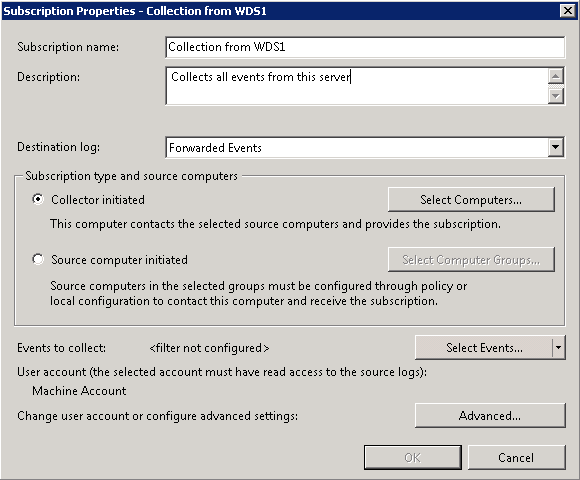
При каждом добавлении коллектора, неплохо было бы проверить подключение:
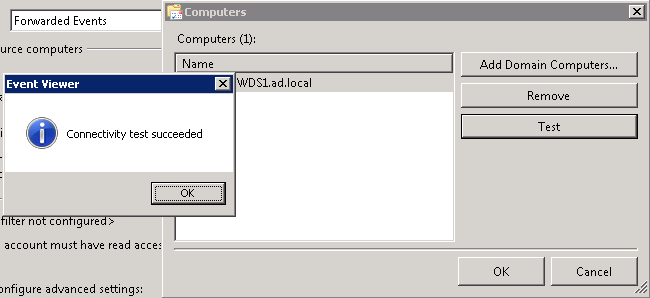
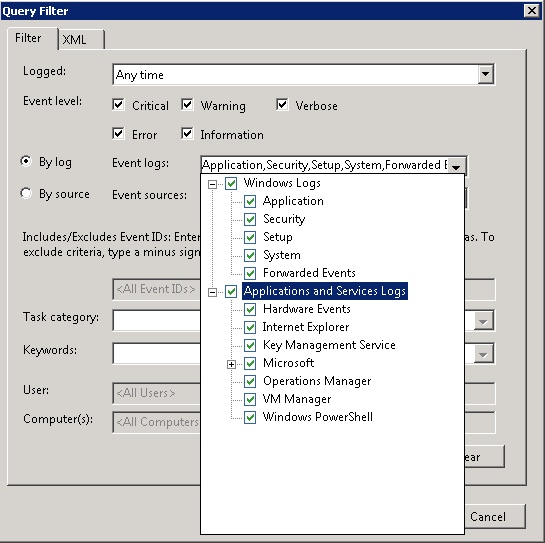
Далее вы должны настроить фильтр, указав какие типы событий вы хотите получать (например, Errors и Warnings), также можно собирать события по конкретным номерам Event ID или по словам в описании события. Есть один нюанс: не выбирайте слишком много типов событий в одну подписку, анализировать этот журнал можно будет бесконечно :).
Расширенные настройки (Advanced settings) могут понадобиться, если вы хотите использовать нестандартный порт для WinRM, или захотите работать по протоколу HTTPS, или же оптимизировать сьор логов по медленным каналам WAN.
После нажатия OK подписка будет создана. Здесь вы можете щелкнуть правой кнопкой мыши по подписке и получить статус выполнения (Runtime Status), или перезапустить ее (Retry) если предыдущий запуск был неудачным. Обратите внимание, что даже если ваша подписка имеет зеленый значок, в процедуре сбора логов могут быть ошибки. Поэтому всегда проверяйте Runtime Status.
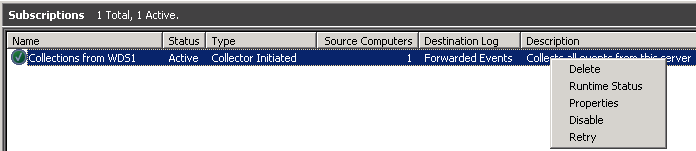
После начала работы подписки, вы сможете просматривать перенаправленные события. Имейте в виду, что если журналы очень большие, то их первичный сбор может занять некоторое время.
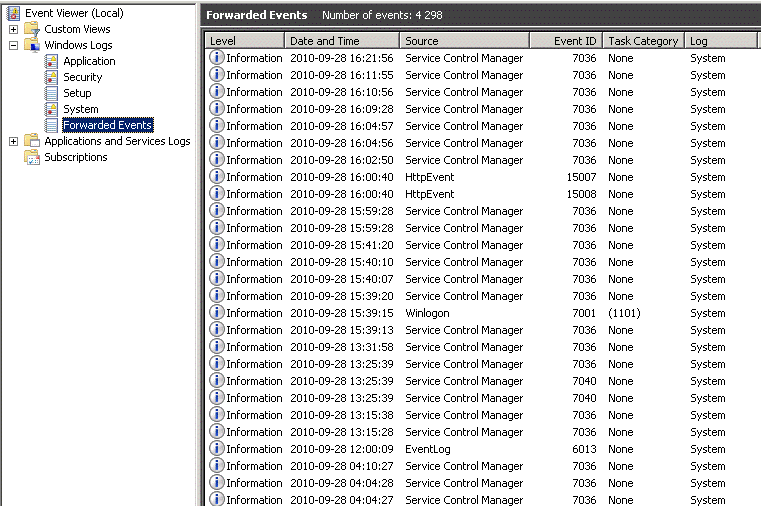
Конфигурацию можно посмотреть на вкладке Properties -> Subscriptions.
В том случае, если сбор логов не работает, сначала на сервере-источнике логов удостоверьтесь, что локальный файрвол настроен корректно и разрешает трафик WinRM.
Один раз, когда я добавил учетную запись сервера-коллектора в группу Event Log Readers, но не добавил ее локальные админы, была такая ошибка;
[WDS1.ad.local] – Error – Last retry time: 2010-09-28 16:46:22. Code (0×5): Windows Event Forward Plugin failed to read events. Next retry time: 2010-09-28 16:51:22.
Я попробовал добавить учетку сервера в группу локальных админов, в результате появилась такая ошибка:
[WDS1.ad.local] – Error – Last retry time: 2010-09-28 16:43:18. Code (0×7A): The data area passed to a system call is too small. Next retry time: 2010-09-28 16:48:18.
Оказывается, я выбрал в фильтре слишком много журналов для сбора. Поправив фильтры так, чтобы они собирали чуть меньше информации, я победил эту ошибку.
Мониторинг производительности Windows Server, настройка оповещений счетчиков PerfMon
В этой статье мы рассмотрим особенности использования встроенных счетчиков производительности Performance Monitor для мониторинга состояния Windows Server. Счетчики PerfMon можно использовать для отслеживания изменений определенных параметров производительности сервера (алертов) и оповещать администратора в случае возникновения высокой загрузки или других нештатных состояниях.
Чаще всего для мониторинга работоспособности, доступности, загруженности серверов используются сторонние продукты. Если вам нужно получать информацию о производительности приложений либо железа только с одного-двух Windows-серверов, либо когда это нужно на непостоянной основе, либо возник более сложный случай, требующий глубокого траблшутинга производительности, то можно воспользоваться встроенным функционалом Windows Performance Monitor.
Основные возможности Performance Monitor, которые можно использовать отдельно или совместно с другими сторонними системами мониторинга (типа Zabbix, Nagios, Cacti и другие):
- cистема мониторинга при выводе информации о производительности сначала обращается к Performance Monitor;
- главной задачей системы мониторинга является оповещение о наступлении тревожного момента, аварии, а у Performance Monitor – собрать и предоставить диагностические данные.
Текущие значения производительности Windows можно получить из Task Manager, но Performance Monitor умеет несколько больше:
- Task Manager работает только в реальном времени и только на конкретном (локальном) хосте;
- в Performance Monitor можно подключать счётчики с разных серверов, вести наблюдение длительное время и собранную информацию сохранять в файл;
- в Task Manager очень мало показателей производительности.
Мониторинг производительности процессора с Perfomance Monitor
Для снятия данных о производительности процессора воспользуемся несколькими основными счётчиками:
- \Processor\% Processor Time— определяет уровень загрузки ЦП, и отслеживает время, которое ЦП затрачивает на работу процесса. Уровень загрузки ЦП в диапазоне в пределах 80-90 % может указывать на необходимость добавления процессорной мощности.
- \Processor\%Privileged Time — соответствует проценту процессорного времени, затраченного на выполнение команд ядра операционной системы Windows, таких как обработка запросов ввода-вывода SQL Server. Если значение этого счетчика постоянно высокое, и счетчики для объекта Физический диск также имеют высокие значения, то необходимо рассмотреть вопрос об установке более быстрой и более эффективной дисковой подсистемы (см. более подробную статью об анализе производительности дисков с помощью PerfMon).
- \Processor\%User Time — соответствует проценту времени работы CPU, которое он затрачивает на выполнение пользовательских приложений.
Запустите Performance Monitor с помощью команды perfmon. В разделе Performance Monitor отображается загрузкой CPU в реальном времени с помощью графика (параметр Line), с помощью цифр (параметр Report), с помощью столбчатой гистограммы (параметр Histogram bar) (вид выбирается в панели инструментов). Чтобы добавить счетчики, нажмите кнопку “+” (Add Counters).
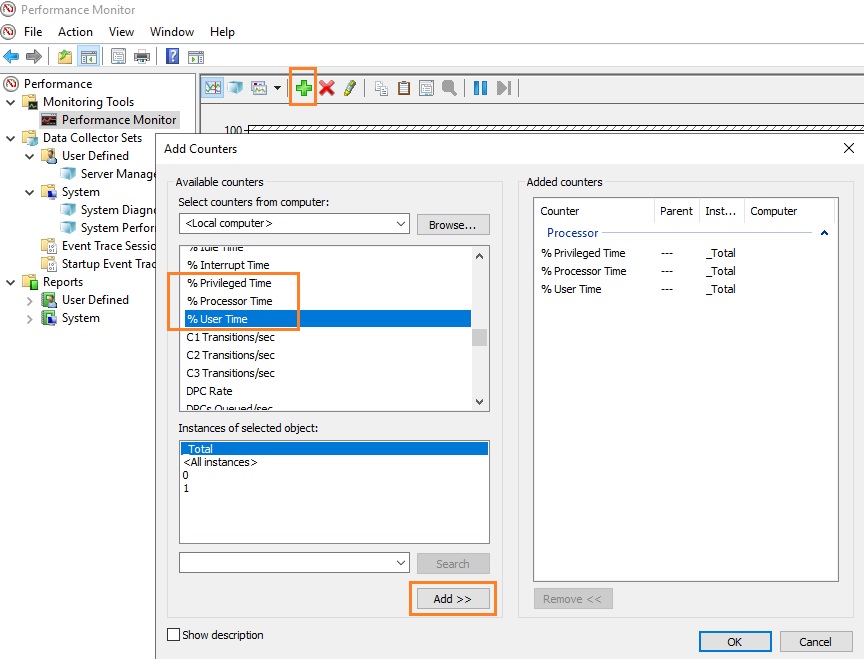
Слева направо двигается линия в реальном времени и отображает график загрузки процессора, на котором можно увидеть, как всплески, так и постоянную нагрузку.
Например, вам нужно посмотреть загрузку процессора виртуальными машинами и самим Hyper-V. Выберите группу счетчиков Hyper-V Hypervisor Logical Processor, выберите счетчик % Total Run Time. Вы можете показывать нагрузку по всем ядрам CPU (Total), либо по конкретным (HV LP №), либо всё сразу (All Instances). Выберем Total и All Instances.
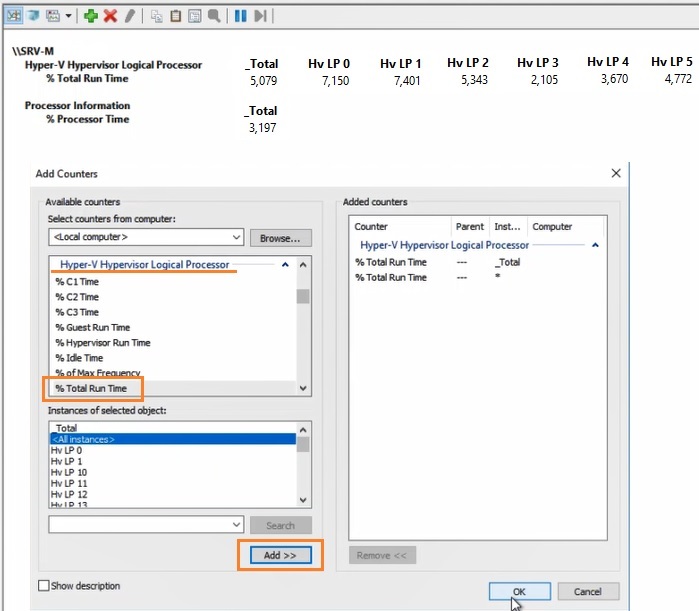
Группы сборщиков данных в PerfMon
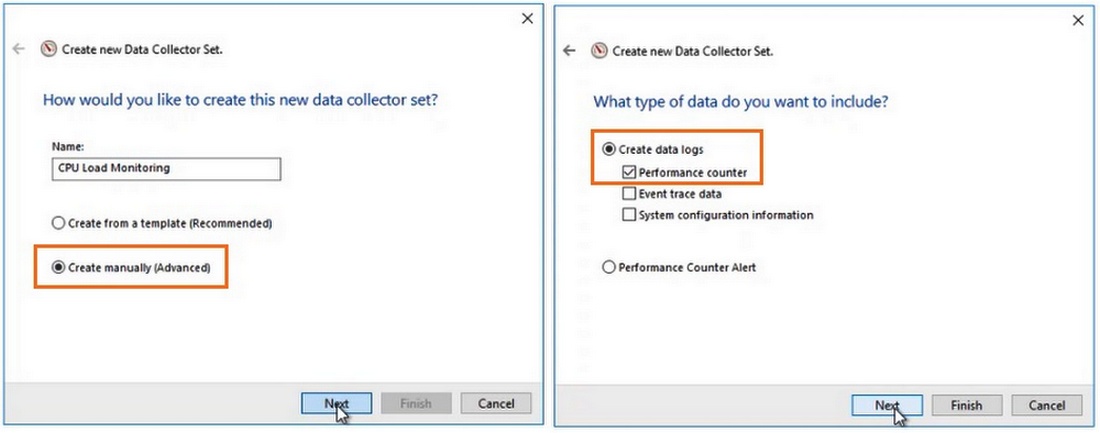
Чтобы не сидеть целый за наблюдением движения линии, создаются группы сбор данных (Data Collector Set), задаются для них параметры и периодически просматриваются.
Чтобы создать группу сбора данных, нужно нажать на разделе User Defined правой кнопкой мыши, в меню выбрать New -> Data Collector Set. Выберите Create manually (Advanced) -> Create Data Logs и включите опцию Performance Counter. Нажмите Add и добавите счётчики. В нашем примере % Total Run Time из группы Hyper-V Hypervisor Logical Processor и Available MBytes из Memory. Установите интервал опроса счётчиков в 3 секунды.
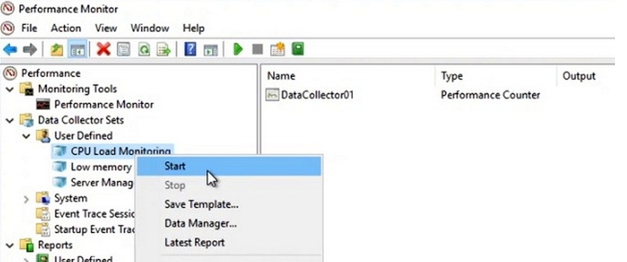
Далее вручную запустите созданный Data Collector Set, нажав на нём правой кнопкой мыши и выбрав в меню пункт Start.
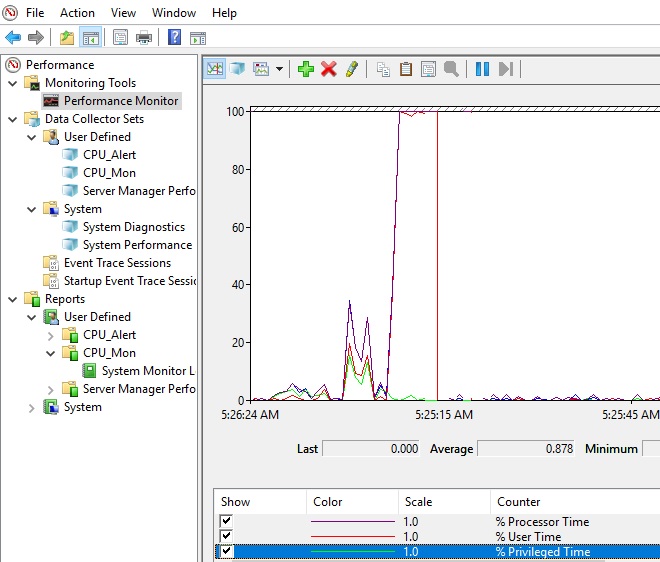
Через некоторое время можно просмотреть отчёт. Для этого в контекстном меню группы сбора данных нужно выбрать пункт Latest Report. Вы можете посмотреть и проанализировать отчёт производительности в виде графика. Отчёт можно скопировать и переслать. Он хранится в C:\PerfLogs\Admin\CPU_Mon и имеет расширение .blg.
Если нужно на другом сервере запустить такой же набор счётчиков, как на первом, то их можно переносить экспортом. Для этого в контекстном меню группы сбора данных выберите пункт Save Template, укажите имя файла (расширение .xml). Скопируйте xml файл на другой сервер, создайте новую группу сбора данных, выберите пункт Create from a template и укажите готовый шаблон.
Создание Alert для мониторинга загрузки CPU
В определённый критический момент в Performance Monitor могут срабатывать алерты, которые помогают ИТ-специалисту прояснить суть проблемы. В первом случае алерт может отправить оповещение, а во втором – запустить другую группу сбора данных.
Чтобы создать алерт в PerfMon, нужно создать ещё один Data Collector Set. Укажите его имя CPU_Alert, выберите опцию Create manually (Advanced), а затем — Performance Counter Alert. Добавьте счётчик % Total Run Time из Hyper-V Hypervisor Logical Processor, укажите границу загрузки 50 %, при превышении которой будет срабатывать алерт, установите интервал опроса счётчика в 3 секунды.
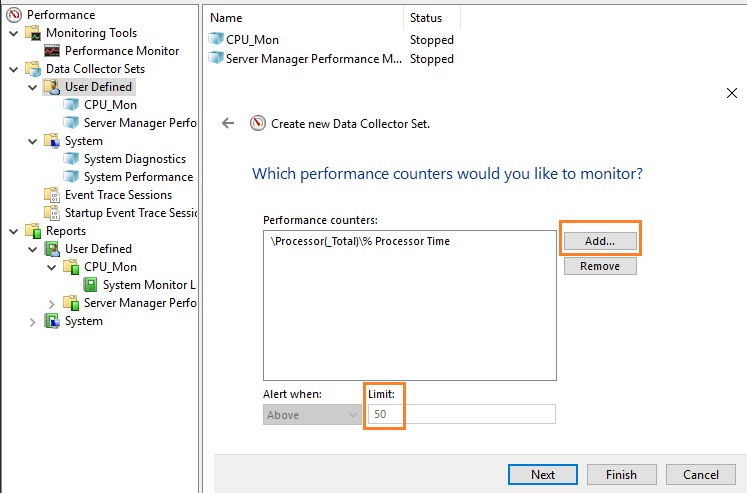
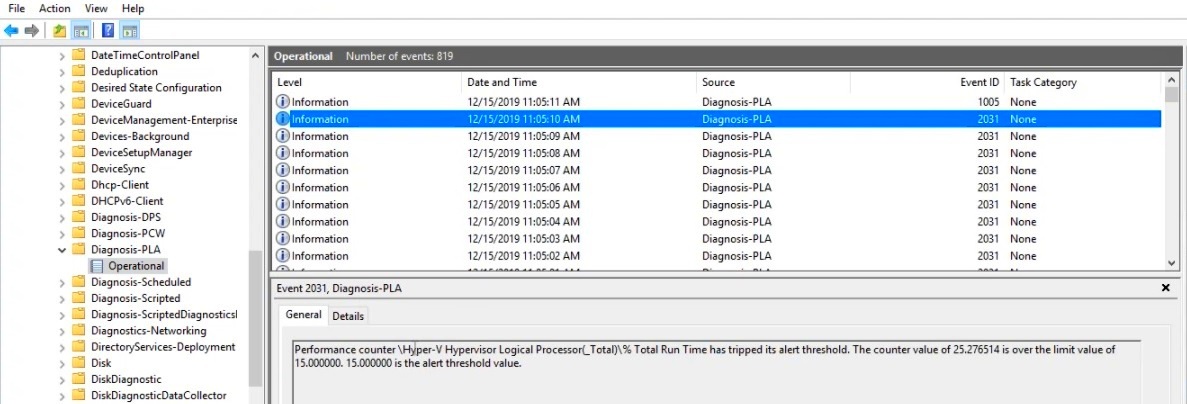
Далее нужно зайти в свойства данной группы сбора информации, перейти на вкладку Alert Action, включить опцию Log an entry in the application event log и запустить группу сбора данных. Когда сработает алерт, в журнале (в консоли Event Viewer в разделе Applications and Services Logs\Microsoft\Windows\Diagnosis-PLA\Operational) появится запись:
“Performance counter \Processor(_Total)\% Processor Time has tripped its alert threshold. The counter value of 100.000000 is over the limit value of 50.000000. 50.000000 is the alert threshold value”.
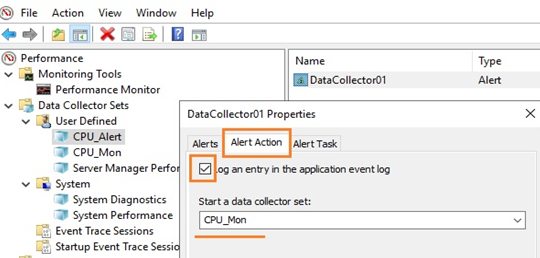
Здесь же рассмотрим и второй случай, когда нужно запустить другую группу сбора данных. Например, алерт срабатывает при достижении высокой загрузки CPU, делает запись в лог, но вы хотите включить сбор данных с других счётчиков для получения дополнительной информации. Для этого необходимо в свойствах алерта в меню Alert Action в выпадающем списке Start a data collector set выбрать ранее созданную группу сбора, например, CPU_Mon. Рядом находится вкладка Alert Task, в которой можно указать разные аргументы либо подключить готовую задачу из консоли Task Scheduler, указав её имя в поле Run this task when an alert is triggered. Будем использовать второй вариант.
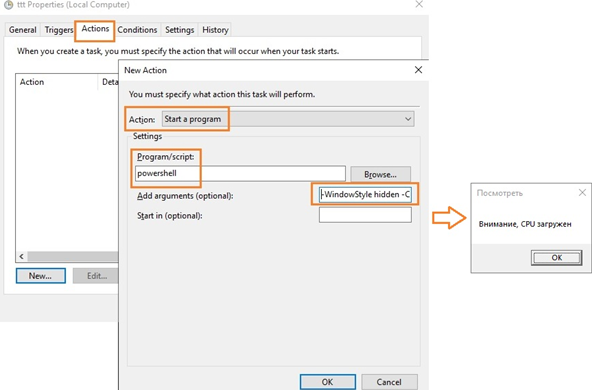
С помощью Task Scheduler можно выполнить какие-то действия: выполнить команду, отправить письмо или вывести сообщение на экран (сейчас последниед ве функции не поддерживаются, считаются устаревшими (deprecated)). Для вывода на уведомления на экран можно использовать скриптом PowerShell. Для этого в консоли Task Scheduler создайте новую задачу, на вкладке Triggers выберите One time, на вкладке Actions в выпадающем поле Action выбирите параметр Start a program, в поле Program/Script укажите powershell.exe, а в поле Add arguments (optional) следующий код:
-WindowStyle hidden -Command «& <[System.Reflection.Assembly]::LoadWithPartialName('System.Windows.Forms'); [System.Windows.Forms.MessageBox]::Show('Внимание, CPU загружен', 'Посмотреть')>«
Для отправки письма вы можете воспользоваться командлетом PowerShell Send-MailMessage или стороннюю утилиту mailsend.exe.. Для этого создайте аналогичное задание в Task Scheduler, в поле Program/Script укажите полный путь к утилите (у нас C:\Scripts\Mail\mailsend.exe), а в поле Add arguments (optional) через параметры нужно передать значения: электронный адрес, адрес и номер порта SMTP-сервера, текст письма и заголовка, пароль:
-to dep.it@ddd.com -from dep.it@ddd.com -ssl -port 465 -auth -smtp smtp.ddd.com -sub Alarm -v -user dep.it@ddd.com +cc +bc -M «Alarm, CPU, Alarm» -pass «it12345»
где +cc означает не запрашивать копию письма, +bc — не запрашивать скрытую копию письма.



