- Mohamed Houri’s Oracle Notes
- October 13, 2017
- Execution plans : blocking and non-blocking operations
- «Dense_rank()» vs «Max()» или расследование с неожиданным концом
- Читают сейчас
- Редакторский дайджест
- Похожие публикации
- DataLine запускает кластер для нагруженных баз данных Microsoft SQL в облаке
- Полный список флагов трассировки Microsoft SQL Server
- Обзор архитектуры и обеспечения высокой доступности в SQL Database (SQL Azure)
- Заказы
- Минуточку внимания
- Комментарии 15
Mohamed Houri’s Oracle Notes
October 13, 2017
Execution plans : blocking and non-blocking operations
Below are two 12cR2 row-source execution plans of the same query:
Forget the switch from a FULL TABLE scan to an INDEX FULL scan at line n° 3 and the switch from a SORT to a NOSORT operation at line n°2. What other remarkable difference we can still spot out there? Have you noticed that operation n°3 produced 1000 rows in the first execution plan and only 6 rows in the second one?
Here’s the model with which I obtained the above execution plans respectively:
What happened here so that an operation without a filter predicate produces 6 rows where it is supposed to generate the entire set of rows in the table i.e. 1,000 rows?
The explanation comes from the way Oracle handles blocking and non-blocking operations. A blocking operation requires receiving all rows from its child operation before a single row can be processed. A non-blocking operation consumes and produces rows at the same time.
Applied to the current situation, we see that the two previous execution plans have both a blocking operation at line n°2 which is the VIEW operation.
In fact, as magnificiently explained by Jonathan Lewis in this post, the blocking nature of the VIEW operation is function of its first child operation. If this one is a blocking operation then the VIEW is a blocking operation as well. If, however, the child operation is not blocking then its VIEW parent operation is a non-blocking operation that can consume and produce rows at the same time.
The first child of the two VIEW operations in the above execution plans is respectively:
The WINDOW SORT PUSHED RANK child operation of the VIEW is a sort operation. Sorts,as you know, are blocking operations. This is why the VIEW in the first execution plan is a blocking operation. Oracle has to retrieve all rows from table t1 (A-Rows = 1000) at operation n°3, sort them totally at operation n°2 before applying the filter predicate n°2 reducing as such the number of retrieved rows to only 5.
In the second execution plan the WINDOW NOSORT STOPKEY child operation of the VIEW is a non-blocking operation thanks to the ordered list of keys it receives from its INDEX FULL SCAN child operation. The VIEW asks for the first row from its first child operation which, at its turn, asks for the same row from its child operation the INDEX FULL SCAN at line 3. The index gives the first ordered key it has found to its parent operation, the WINDOW NOSORT STOPKEY,which feeds back again it parent operation, the VIEW, provided the index key survives the filter predicate n°2. The VIEW asks then for the second row, for the third row, and so on until the WINDOW NOSORT STOPKEYdeclares the end of the query. Indeed, the WINDOW NOSORT STOPKEY knows the upper bound it can’t go beyound. This is why when it receives the 6th row from the index full scan operation (A-Rows= 6) it realises that this row spans its upper bound and that it is now time to signal to the coordinator (select statement) the end of the query.
Here’s another example demonstrating that even with FULL segment scans Oracle is able to stop generating rows at the appropriate moment. All what it requires from the parent operation is to be a non-blocking operation able to consume and produce rows at the same time:
Summary
Sometimes we need to read and interpret execution plans not only in their order of operation using the “first child first, recursive descent” rule, but also in their order of data flow propagation (or row-source generation). In the latter case, knowing how to identify blocking and non-blocking operations is very important.
«Dense_rank()» vs «Max()» или расследование с неожиданным концом
Предыстория:
Так сложились звезды, что мне нужно сейчас искать работу. Перед каждым собеседованием я изучаю компанию, в которую меня пригласили, дабы понимать чем занимается компания, чему я научусь если мне сделают оффер и т.д. И вот, в один прекрасный момент, мне пришло приглашение на интервью, на позицию PL/SQL разработчика, от одной прекрасной компании. Прочитав о ней, мне показалось, что я влюблен и хочу там работать. Когда же я пришел на само интервью и в тот момент, когда все к интервью уже готово, а оно еще не началось просто потому что люди знакомятся, hr предлагает кофе и т.д., я уже понял, что хочу, очень хочу, тут работать.
За все интервью с тимлидом, мне один раз предложили написать простенький запрос, в остальном же все проходило в режиме: вопрос-ответ.
Задачка звучала так:
«У нас есть таблица операций, в ней 4 столбца: id операции, id клиента, дата операции, сумма операции. Нужно вывести последние операции по каждому клиенту с максимальной суммой за определенный период».
И я, конечно, начал лихорадочно соображать, как же написать так, чтобы было красиво и эффективно. А кроме оракла я еще работал с терадатой и в тот момент мой мозг выдал вот такой запрос:
На что мне был задан вопрос: «А почему была использована max(), а не dense_rank()?», не помню что я точно ответил, но звучало это приблизительно так: «max() я использовал чаще и могу, более-менее точно, представить, что он мне вернет, в отличии от dense_rank()». Дальше описывать интервью не буду, скажу только, что мне, конечно же, отказали. Позже, уже дома, в попытках проанализировать все и понять ошибки, я пришел к выводу, что слишком сильно хотел там работать и переволновался, иначе ту кашу, творившуюся у меня в голове во время интервью, я объяснить не могу. Это было нечто сродное с тем ощущением, когда школьник пытается поговорить с девочкой, которую он тайно любит еще с садика, но эти попытки все больше и больше ставят его в неловкое положение. Так же и я, стараясь выглядеть спокойным и адекватным, показал себя как никудышный специалист. В общем, я решил для себя выяснить, что лучше использовать dense_rank() или max() при решении такой задачи.
Исследование
Если вы хотите собственными глазами увидеть все, что я напишу и собственными руками это все потрогать — я подготовил набор скриптов создания данных для теста:
Итак, тестовые данные созданы, пора приступать к, собственно, самим запросам. Для того, чтобы не обрезать наши 20000 строк, мы не будем ограничивать нашу выборку каким-то определенным периодом, нам ведь важно понять какой метод лучше и эффективнее, а мы можем добавить и потом.
Предварительные планы для этих запросов (получено в pl/sql developer):
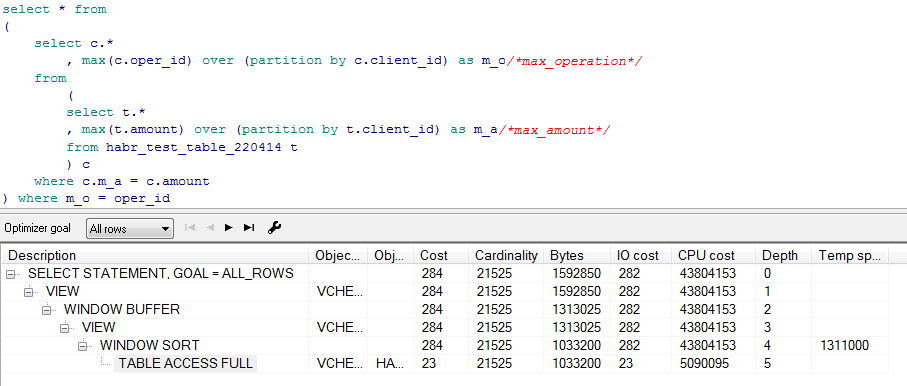
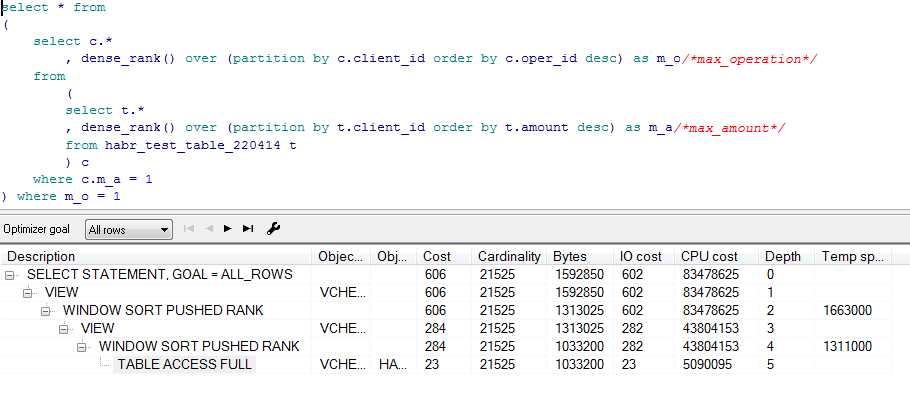
Но это предварительные планы, реальные получим при помощи утилиты SQLTUNE:
и выглядят эти реальные планы вот так:
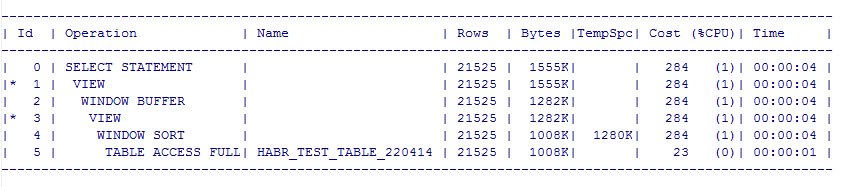
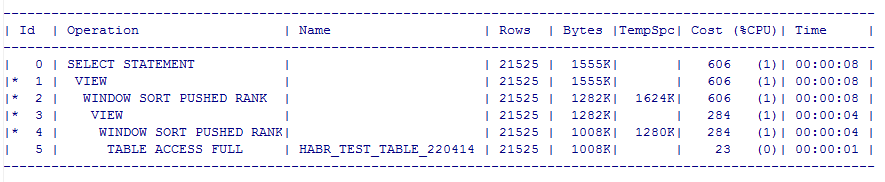
Помимо реального плана SQLTUNE также выдает рекомендации по оптимизации скрипта, в нашем случае он рекомендует собрать статистику, но так как табличка у нас одна, то и запросы находятся в одинаковых условиях.
Предварительный итог
После всех этих манипуляций мне, как я надеюсь и вам, ясно что при решении этой задачи max() отрабатывает быстрее чем dense_rank() в 2 раза и съедает вдвое меньше процессорного времени. Ну оно то понятно итак, без планов и прочего, ведь max() это всего лишь поиск наибольшего, в то время как dense_rank() — это, в первую очередь сортировка, а уже потом нумерование.
Но не это побудило меня писать статью.
Внезапно
В процессе первоначального заполнения таблицы для теста, это я ведь для статьи сообразил скрипты, а в первый раз все происходило практически в ручном режиме, и для проверки состояния подопытной таблицы я использовал запрос с order by .
Позже я написал «запрос с dense_rank()» и начал сравнивать планы, но заметив этот злополучный order by в запросе с max(), удалил order by , но cost его я уже увидел и запомнил. И когда увидел cost в запросе с max() без order by сильно удивился, ведь:

Да и вообще, сказать что я сильно удивился — ничего не сказать… Как так получилось? Почему order by ускорил запрос в 10 раз? Решил найти ответ в трассировке. Не буду писать как именно снимать трассу в оракле, ибо это тема для отдельной статьи, да и статьи с описанием сего процесса легко найти во всемирной паутине. Предоставлю только набор скриптов, которыми я проводил трассировку и ссылку на такую статью, нашел я ее довольно давно, с тех пор она меня выручает:
Итоги
Отсюда видим, что и предварительный, и реальный планы не ошибочны, никакого подвоха вроде бы как нет и можно радоваться десятикратному ускорению. А так ли это?
P.S. Я так и не смог ответить на этот вопрос и все еще не верю в то, что запрос реально ускорить в разы при помощи order by. Буду и дальше пытаться выяснить этот момент, к чему и вас призываю. И да откроются перед нами сокрытые тайны оракла!
P.P.S. Благодарю всех за внимание! Если вы вместе со мной проводили тест — не забываем чистить за собой базу, особенно если это прод какого нибудь банка.
Читают сейчас
Редакторский дайджест
Присылаем лучшие статьи раз в месяц
Скоро на этот адрес придет письмо. Подтвердите подписку, если всё в силе.
Похожие публикации
DataLine запускает кластер для нагруженных баз данных Microsoft SQL в облаке
Полный список флагов трассировки Microsoft SQL Server
Обзор архитектуры и обеспечения высокой доступности в SQL Database (SQL Azure)
Заказы
AdBlock похитил этот баннер, но баннеры не зубы — отрастут
Минуточку внимания
Комментарии 15

Что-то очень сумбурно: собеседование, ваши впечатления, вопрос, процесс решения, измерение производительности, планы запросов и все это в одной статье. Тяжело удерживать фокус.
А ключ похоже содержится в самом вопросе: «Нужно вывести последние операции по каждому клиенту». Операции — множественное число. Max всегда возвращает 1 строку. Если клиент совершил 3 операции на миллион долларов, в выводе будет отображена только одна из них, случайная операция из этих трех максимальных. Dense_rank выведет их все. И эффективность тут непричем.
Постараюсь ответить по порядку:
Собеседование: в реальной жизни у меня не было времени и желания сравнивать функции, если решение удовлетворяет требованиям по производительности — никто ничего не меняет. Работает, устраивает заказчика — задача выполнена, у вас не так?
В данном случае я хотел описать причину такого интереса к этим функциям.
Мои впечатления: — это попытка оправдаться перед сообществом и перед самим собой за сорванное интервью, а также описать свои чувства и меру своего желания разобраться в данном вопросе. Что является еще одним мотиватором для детального изучения вопроса.
Вопрос, решение задачи, измерение производительности, планы запросов — все это все касается решения задачи.
Главный акцент в статье — это странное поведение оракла при использовании order by, вот собственно и все, что я хотел рассказать, но без остального картинка не была бы полной.
Желание разобраться и провести работу над ошибками похвально.
>если решение удовлетворяет требованиям по производительности
Прежде всего, решение должно удовлетворять условию задачи (правильно работать), и только потом уже требованиям производительности. У вас же запросы с max и dense_rank дают разный результат!
Сортировка очень помогает группировке. И максимальное значение на отсортированных данных найти элементарно. Вот и получилось, что проще один раз явно отсортировать данные и использовать их в следующем подзапросе, чем неявно вызывать ее при группировке и поиске максимального значения по-отдельности. А на cost акцентировать внимание не стоит. Иногда при переписывании запроса cost увеличивается в сотни раз, а время выполнения уменьшается.
У вас же запросы с max и dense_rank дают разный результат!
Да ну неужели, правда что ль? Может сами проверите. Я, конечно, могу скинуть скрин, но не думаю что вы ему поверите.

Честно говоря, вам еще учиться и учиться. Советую читать почаще оракловые форумы, например OTN и SQL.RU. Там вы научитесь делать правильные и удобные тест-кейсы и, самое главное, правильно их анализировать.
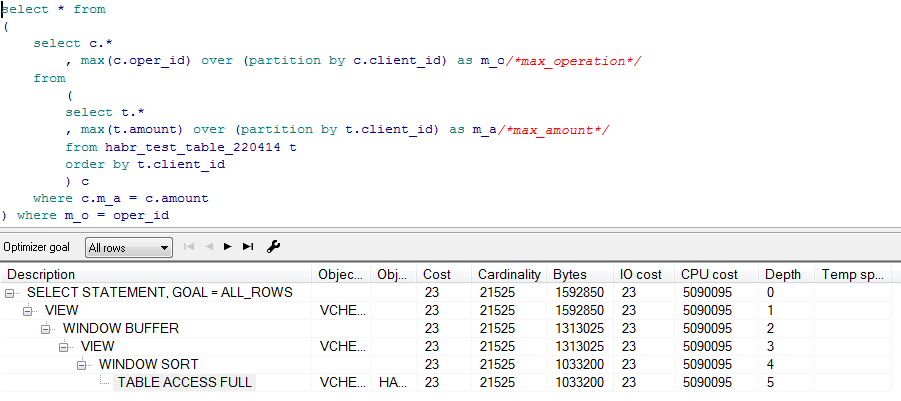
Полный разбор сейчас делать мне некогда, поэтому пробегусь бегло по некоторым наиболее важным вещам. Потом если захотите задать какие-либо вопросы — можете написать мне на почту.
1. Старайтесь избегать создания лишних объектов (а триггеры вообще старайтесь никогда не создавать) и максимально упрощать тест-кейс.
Например, можно было бы сделать так:
2. Собирайте всегда статистику, чтобы на выполнение запросов не влиял dynamic_sampling.
3. Реальные планы не надо показывать через DBMS_SQLTUNE.REPORT_TUNING_TASK. Лучше показывать через dbms_xplan.display_cursor с параметром ‘allstats last’, или отчет dbms_sqltune.report_sql_monitor, ну или трассировку(что немного более геморройно). И лучше в текстовом виде.
А в идеале, готовить тестовый скрипт для sql*plus(командное окно PL/SQL developer`а в принципе это тоже умеет).
Например:
4. У вас сомнительные данные с сомнительными выводами. Вообще для такого типа запросов очень важен объем данных. Например, на 100 тысячах записей нет никакой 10-кратной разницы.
Вот кусок вывода того скрипта, что я привел выше:
Все отклонения в пределах нормы. Советую еще протрассировать с ивентом 10032 — это sort trace. Там вы увидите разницу в кол-ве сравнений и используемой для этого памяти.
5. На самом деле, достаточно было одной аналитической функции, а так как у вас еще и уникальный oper_id, то лучше вообще row_number(в моем скрипте это пример №4)



