- Keep alive of TCP connection
- 1 ответ 1
- TCP keep-alive gets involved after TCP zero-window and closes the connection erroneously
- 4 Answers 4
- HTTP Keep Alive and TCP keep alive
- 4 Answers 4
- Tcp connection Keep alive
- 3 Answers 3
- Соединяй и властвуй. Нестандартный взгляд на keep-alive
- How it works
- Тридцать по одному или один по тридцать?
Keep alive of TCP connection
У нас на работе с коллегой возник спор по поводу keep alive TCP соединения с клиентом.
Read возвращает 0 только в том случае, если нет дополнительных данных в потоке и больше не ожидаются (например, сокет закрыт или достигнут конец файла)
Т.е. если мы выполняем await ReadAsync и постоянно получаем 0 байт, следовательно TCP клиент отвалился. Данный метод «keep alive» актуален при использовании ReadAsync и корректном дисконнекте клиента (чтобы на уровне TCP успел придти пакет о закрытии сокета).
Мой коллега утверждает:
Нельзя пологаться на этот метод. Единственный способ «keep alive» — это послать «heart bit» и удостовериться, что на том конце есть кому его принимать, иначе TCP клиент отвалился.
Хотелось бы узнать что думаете вы??
1 ответ 1
Нет смысла «постоянно получать 0 байт», первый же 0 означает закрытый на чтение сокет.
Однако, закрытым соединение становится только после прихода FIN или RST-пакета, причем пакет RST еще и имеет негарантированную доставку! Поэтому, если вас не устраивает системный тайм-аут в 2 часа для Keep-Alive (который к тому же по умолчанию для сокетов выключен) — обязательно нужно писать свою логику определения зависших соединений.
Тем не менее, не обязательно для этого отправлять heartbeat-сообщения. Если протокол подразумевает возможность повторного подключения — можно просто выставить тайм-аут на чтение и после тайм-аута закрывать соединение.
С другой стороны, надо помнить о NAT. Многие реализации PNAT имеют свои тайм-ауты для исходящих соединений — и могут разорвать неактивное соединение. Этот тайм-аут может быть очень небольшим, и угадать его заранее нельзя. Если важно чтобы соединение не рвалось само по себе — придется вводить в протокол клиентские keep-alive сообщения, с настраиваемым интервалом.
TCP keep-alive gets involved after TCP zero-window and closes the connection erroneously
We’re seeing this pattern happen a lot between two RHEL 6 boxes that are transferring data via a TCP connection. The client issues a TCP Window Full, 0.2s later the client sends TCP Keep-Alives, to which the server responds with what look like correctly shaped responses. The client is unsatisfied by this however and continues sending TCP Keep-Alives until it finally closes the connection with an RST nearly 9s later.
This is despite the RHEL boxes having the default TCP Keep-Alive configuration:
. which declares that this should only occur until 2hrs of silence. Am I reading my PCAP wrong (relevant packets available on request)?
Below is Wireshark screenshot of the pattern, with my own packet notes in the middle.



4 Answers 4
Actually, these «keep-alive» packets are not used for TCP keep-alive! They are used for window size updates detection.
Wireshark treats them as keep-alive packets just because these packets look like keep-alive packet.
A TCP keep-alive packet is simply an ACK with the sequence number set to one less than the current sequence number for the connection.
(We assume that ip 10.120.67.113 refers to host A, 10.120.67.132 refers to host B.) In packet No.249511, A acks seq 24507484. In next packet(No.249512), B send seq 24507483(24507484-1).

Why there are so many «keep-alive» packets, what are they used for?
A sends data to B, and B replies zero-window size to tell A that he temporarily can’t receive data anymore. In order to assure that A knows when B can receive data again, A send «keep-alive» packet to B again and again with persistence timer, B replies to A with his window size info (In our case, B’s window size has always been zero).
And the normal TCP exponential backoff is used when calculating the persist timer. So we can see that A send its first «keep-alive» packet after 0.2s, send its second packet after 0.4s, the third is sent after 0.8, the fouth is sent after 1.6s.
This phenomenon is related to TCP flow control.

The source and destination IP addresses in the packets originating from client do not match the destination and source IP addresses in the response packets, which indicates that there is some device in between the boxes doing NAT. It is also important to understand where the packets have been captured. Probably a packet capture on the client itself will help understand the issue.
Please note that the client can generate TCP keepalive if it does not receive a data packet for two hours or more. As per RFC 1122, the client retries keepalive if it does not receive a keepalive response from the peer. It eventually disconnects after continuous retry failure.
The NAT devices typically implement connection caches to maintain the state of ongoing connections. If the size of the connection reaches limit, the NAT devices drops old connections in order to service the new connections. This could also lead to such a scenario.
The given packet capture indicates that there is a high probability that packets are not reaching the client, so it will be helpful to capture packets on client machine.
HTTP Keep Alive and TCP keep alive
How is HTTP Keep Alive implemented? Does it internally use TCP Keep Alive? If not, how does the server detect if the client is dead or alive?
4 Answers 4
HTTP Keep-Alive is a feature of HTTP protocol. The web-server, implementing Keep-Alive Feature, has to check the connection/socket periodically (for incoming HTTP request) for the time span since it sent the last HTTP response (in case there was corresponding HTTP Request). If no HTTP request is received by the time of the configured keep-alive time (seconds) the web server closes the connection. No further HTTP request will be possible after the ‘close’ done by Web Server. On the other hand, TCP Keep-Alive is managed by OS in the TCP layer. HTTP Keep-Alive and TCP Keep-Alive is totally unrelated things.
I know this is an old question, but still:
HTTP Keep-Alive is a feature that allows HTTP client (usually browser) and server (webserver) to send multiple request/response pairs over the same TCP connection. This decreases latency for 2nd, 3rd. HTTP request, decreases network traffic and similar.
TCP keepalive is a totally different beast. It keeps TCP connection opened by sending small packets. Additionally, when the packet is sent this serves as a check so the sender is notified as soon as connection drops (note that this is NOT the case otherwise — until we try to communicate through TCP connection we have no idea if it is ok or not).
To answer your questions about HTTP Keep-Alive:
To put it simply, the HTTP server doesn’t close the TCP connection after each response but waits some time if some other HTTP request will come over it too. After some timeout it closes it anyway.
No, at least I see no point in it.
It doesn’t — it doesn’t need to. If a client sends a request, it will get the response. If the client doesn’t send anything over TCP connection (maybe because the connection is dead) then a timeout will close the connection; client will of course notice this and will send request through another TCP connection if needed.
Tcp connection Keep alive
i am creating a client server application. the server is already design and in place waiting for connection from the client. Now in the client section i would like to keep the connection alive throughout th life of the application and the connection only closes when the main client application close’s or shutdown or the server closes it.
Currently every 10 seconds Server closes the TCP connection.I tried with
but it doesn’t work for me.. Below is my code block
and in the handler I have:

3 Answers 3
In the call to SetSocketOption() , KeepAlive is not valid at the SocketOptionLevel.Tcp level, instead use SocketOptionLevel.Socket .
SetSocketOption( SocketOptionLevel.Socket, SocketOptionName.KeepAlive, true ) ;
The comments and answer above are valid — sounds like a bad design choice to have a socket opened for the entire lifetime of the app AND expect things to work properly — you should build some sort of failsafe mechanism in case the connection gets dropped.
Back to keep-alives: You need them on both ends — server and client so check how the sockets are set up on both sides. I think that the default value for keep alives is 2 hours — that’s a long time to wait for a keep-alive packet but it can be changed. Check Socket.IOControl method and use IOControlCode.KeepAliveValues with a structure that looks like this (unmanaged) http://msdn.microsoft.com/en-us/library/ms741621.aspx. More about control codes here: http://msdn.microsoft.com/en-us/library/system.net.sockets.iocontrolcode.aspx
The comment («whrn there is no datapacket means no TCP connection») in your code is placed where you receive a disconnect (0 bytes) packet from the other side. There is no way to keep that connection alive because the other side choses to close it.
If the connection is being closed due to network issues, you would either get an exception, or it would seem as if the connection is valid but quiet.
Keep-alive mechanisms always work alongside with timeouts — the timeout enforces «if no data was received for x seconds, close the connection» where the keep-alive simply sends a dummy data packet to keep the timeout from occurring.
By implementing a protocol yourself (you’re operating on the TCP/IP level) you only need to implement a keep-alive if you already have a timeout implemented on the other side.
Соединяй и властвуй. Нестандартный взгляд на keep-alive

Большинство современных серверов поддерживает соединения keep-alive. Если на страницах много медиаконтента, то такое соединение поможет существенно ускорить их загрузку. Но мы попробуем использовать keep-alive для куда менее очевидных задач.
How it works
Прежде чем переходить к нестандартным способам применения, расскажу, как работает keep-alive. Процесс на самом деле прост донельзя — вместо одного запроса в соединении посылается несколько, а от сервера приходит несколько ответов. Плюсы очевидны: тратится меньше времени на установку соединения, меньше нагрузка на CPU и память. Количество запросов в одном соединении, как правило, ограничено настройками сервера (в большинстве случаев их не менее нескольких десятков). Схема установки соединения универсальна:
1. В случае с протоколом HTTP/1.0 первый запрос должен содержать заголовок **Connection: keep-alive**.
Если используется HTTP/1.1, то такого заголовка может не быть вовсе, но некоторые серверы будут автоматически закрывать соединения, не объявленные постоянными. Также, к примеру, может помешать заголовок **Expect: 100-continue**. Так что рекомендуется принудительно добавлять keep-alive к каждому запросу — это поможет избежать ошибок.
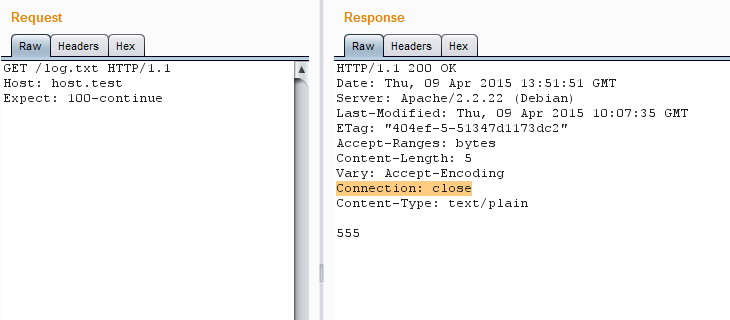
Expect принудительно закрывает соединение
2. Когда указано соединение keep-alive, сервер будет искать конец первого запроса. Если в запросе не содержится данных, то концом считается удвоенный CRLF (это управляющие символы \r\n, но зачастую срабатывает просто два \n). Запрос считается пустым, если у него нет заголовков Content-Length,Transfer-Encoding, а также в том случае, если у этих заголовков нулевое или некорректное содержание. Если они есть и имеют корректное значение, то конец запроса — это последний байт контента объявленной длины.
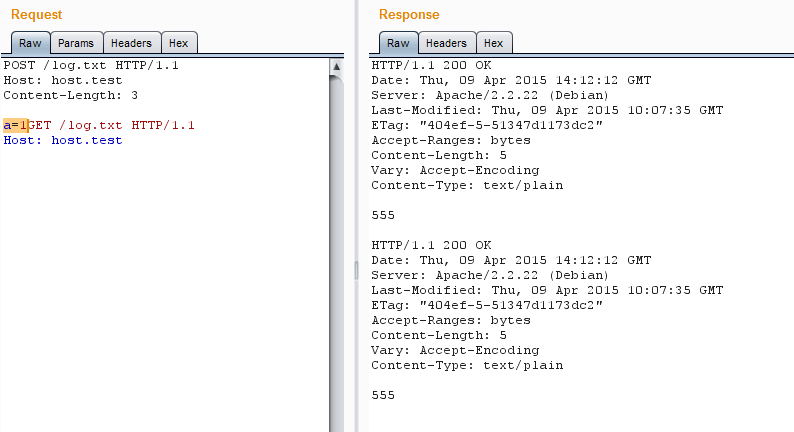
За последним байтом объявленного контента может сразу идти следующий запрос
3. Если после первого запроса присутствуют дополнительные данные, то для них повторяются соответствующие шаги 1 и 2, и так до тех пор, пока не закончатся правильно сформированные запросы.
Иногда даже после корректного завершения запроса схема keep-alive не отрабатывает из-за неопределенных магических особенностей сервера и сценария, к которому обращен запрос. В таком случае может помочь принудительная инициализация соединения путем передачи в первом запросе HEAD.
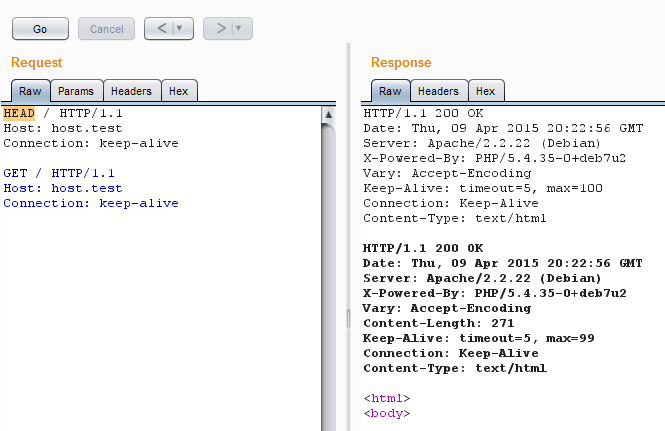
Запрос HEAD запускает последовательность keep-alive
Тридцать по одному или один по тридцать?
Как бы забавно это ни звучало, но первый и самый очевидный профит — это возможность ускориться при некоторых видах сканирования веб-приложений. Разберем простой пример: нам нужно проверить определенный XSS-вектор в приложении, состоящем из десяти сценариев. Каждый сценарий принимает по три параметра.
Я накодил небольшой скрипт на Python, который пробежится по всем страницам и проверит все параметры по одному, а после выведет уязвимые сценарии или параметры (сделаем четыре уязвимые точки) и время, затраченное на сканирование.



