Windows tcp sliding window
I know everyone hates ads. But please understand that I am providing premium content for free that takes hundreds of hours of time to research and write. I don’t want to go to a pay-only model like some sites, but when more and more people block ads, I end up working for free. And I have a family to support, just like you. 🙂
If you like The TCP/IP Guide, please consider the download version. It’s priced very economically and you can read all of it in a convenient format without ads.
If you want to use this site for free, I’d be grateful if you could add the site to the whitelist for Adblock. To do so, just open the Adblock menu and select «Disable on tcpipguide.com». Or go to the Tools menu and select «Adblock Plus Preferences. «. Then click «Add Filter. » at the bottom, and add this string: «@@||tcpipguide.com^$document». Then just click OK.
Thanks for your understanding!
Sincerely, Charles Kozierok
Author and Publisher, The TCP/IP Guide

|
|
 The Book is Here. and Now On Sale!
The Book is Here. and Now On Sale!
|
|
|

 | The TCP/IP Guide 9 TCP/IP Lower-Layer (Interface, Internet and Transport) Protocols (OSI Layers 2, 3 and 4) 9 TCP/IP Transport Layer Protocols 9 Transmission Control Protocol (TCP) and User Datagram Protocol (UDP) 9 TCP/IP Transmission Control Protocol (TCP) 9 TCP Message Formatting and Data Transfer |
|





TCP Sliding Window Data Transfer and Acknowledgement Mechanics
(Page 5 of 6)
Example Illustration of TCP Sliding Window Mechanics
To see how all of this works, let’s consider the example of a client and server using a mythical file retrieval protocol. This protocol specifies that the client sends a request and receives an immediate response from the server. The server then sends the file requested when it is ready.
The two devices will of course first establish a connection and synchronize sequence numbers . For simplicity, let’s say the client uses an initial sequence number (ISN) of 0, and the server an ISN of 240. The server will send the client an ACK with an Acknowledgement Number of 1, indicating it is the sequence number it expects to receive next. Let’s say the server’s receive window size is set to 350, so this is the client’s send window size. The client will send its ACK with an Acknowledgment Number of 241. Let’s say its receive window size is 200 (and the server’s client window size is thus 200). Let’s assume that both devices maintain the same window size throughout the transaction. This won’t normally happen, especially if the devices are busy, but the example is complicated enough. Let’s also say the maximum segment size is 536 bytes in both directions. This means that the MSS wont affect the size of actual segments in this example (since the MSS is larger than the send window sizes for both devices.)
With the background for our example established, we can now follow a sample transaction to show in detail how the send and receive pointers are created and changed as messages are exchanged between client and server. Table 159 describes the process in detail, showing for each step what the send and receive pointers are for both devices. It is rather large, so beware. J The transaction is also graphically illustrated in two figures: Figure 221 and Figure 222 . Both illustrate the same exchange of messages, using the step numbers of Table 159 , but each from the perspective of one of the devices. Figure 221 shows the servers send pointers and clients receive pointers; Figure 222 shows the clients send pointers and servers receive pointers. (I would have put them all in one diagram but it wouldnt fit!)
Table 159: TCP Transaction Example With Send and Receive Pointers
Sliding Window at Transport and Data-Link layers [closed]
Why do we need sliding window mechanism at the Transport as well as Data Link Layers? TCP has its own sliding window mechanism for managing flows and errors. Also, data link layer has similar mechanisms. Isn’t this redundant?

1 Answer 1
TCP’s and UDP’s error control are a single checksum covering each packet. If it fails, the entire packet must be discarded, and then, when the receive fails to acknowledge receipt of the data after a timeout, the data must be resent. Even if data corruption was introduced on one data link between two routers along the network path, the data must be resent from the original sender and make the whole journey across multiple network hops again. This is quite expensive, so this kind of data integrity checking is suitable when the error rate is quite low and the cost of retransmitting is amortized over many successfully transmitted packets. Also, the simple checksum is not that robust and it will miss some errors.
Certain kinds of network links might be expected to have error rates that are too high for the IP transport protocols to deal with efficiently, and so they should provide their own layer of error detection (or even forward error correction) in order for IP to work well over them. Originally, (analog) modems are well known to have introduced this kind of integrity protection (e.g. V.42) as their speeds got higher and higher. I don’t know much about the details of the kinds of physical links that are popular these days, but I’d say it’s a good bet that one or more of DOCSIS, ADSL, wifi, and/or 3G/4G/LTE incorporate this kind of technology. I would also note that I consider all of this to be happening at the physical layer (Layer 1), not at the datalink layer (Layer 2), although debate is possible on that because the OSI layer model is never an exact fit for the real world of networking.
This kind of error control doesn’t necessarily imply that the physical layer (or datalink layer, if you prefer) has any kind of sliding window. It might have in some of the more complex schemes designed for the most unreliable kinds of physical links, but all of the simplest kinds of error checking doesn’t: for example, the PPP and ethernet FCS. With an FCS, much like with a UDP checksum, a corrupted packet will simply be dropped, and the protocol has no memory or window from which to retransmit the failed frame, and it doesn’t acknowledge successfully received frames to the sender (which is necessary in any kind of sliding window protocol to advance the window).
All that being said, the transport layer error control mechanism remains essential because it is end to end. Only at this layer will errors other than errors introduced by the transmission medium be caught. The IP transport protocols’ checksums will catch corruption that occurred inside routers, errors introduced by physical media that doesn’t or can’t catch errors, or errors in host devices or device drivers.
That’s for error control. Some of the same can be said about flow control: although some complex schemes can exist to handle kinds of physical links that would be otherwise problematic for IP to work over, most be the simple schemes don’t involve any kind of sliding window. For example, when communicating over an RS-232 serial link, flow control is a simple binary control line: when it’s asserted, the other end sends data, and when it’s deasserted, the other end pauses. It doesn’t remember any previously transmitted data in a window and it doesn’t receive acknowledgements.
One final comment: UDP is an unreliable transport protocol. When using UDP, the application is responsible for managing timeouts and retransmissions. There is lots of variability in how well individual applications deal with it. Some to it pretty badly. Since (forward) error correction is at least provided by some of the most notoriously unreliable physical link layers, at least the situation is tolerable in that UDP, though unreliable, «usually» works. The same can be said about some non-TCP, non-UDP transport protocols.
В поисках утерянного гигабита или немного про окна в TCP
Поводом для написания этой статьи послужила лень, которая, как известно, двигатель прогресса и свидетель появления на свет невероятно облегчающих жизнь вещей.
В моём случае это была лень объяснять в тысячный раз клиенту, почему он арендовал канал точка-точка и в договоре чёрным по белому написано Ethernet 1Гбит/с, а он как ни измеряет, но чуть-чуть да меньше получается.
Где остальное? Почему недобор? Куда девался интернет из провода? А может его и вовсе страшно обманули?
Ну что ж, давайте искать, а заодно напишем заметку, которую будет не стыдно показать тысяче первому клиенту, у которого будет недосдача скорости.
Важно
Если вы сетевой инженер, то не читайте эту статью. Она оскорбит все ваши чувства т.к. написана максимально простым и доступным языком с множеством упущений.
История про окна. Мир до окон
Итак, чтобы понять, где скорость, нам придётся разобраться в том, как работает TCP в плане обеспечения надежности соединения.
Как нам всем известно, у ТСР есть финт последней надежды, когда все ухищрения доставить кадр до получателя не сработали, он просто заново отправляет испорченный или утерянный кадр.
Как это выглядит в простейшем случае:
- Кадр отправляется передатчиком. На передатчике включается таймер, в течении которого от получателя должно быть получено подтверждение АСК об успешном получении кадра или явное указание, что кадр был испорчен/утерян в пути — NACK
- Если по истечении таймера АСК не получен, пакет отправляется ещё раз
- Если приходит NACK, источник повторяет отправку кадра
- А если АСК получен, источник отправляет следующий кадр
Графически этот алгоритм легко представляется на временной шкале:
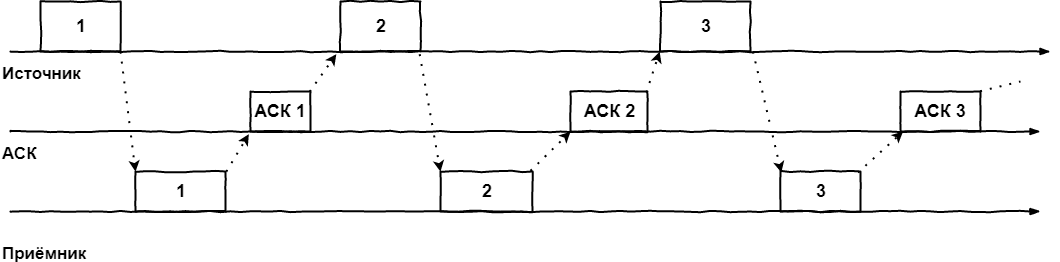
Называется этот алгоритм методом простоя источника, что сразу даёт нам понять его главный минус: катастрофически неэффективное использование канала связи. Технически, ничего не мешает передатчику сразу после отправки первого кадра отправлять второй, но мы принуждаем его ждать прихода ACK/NACK или истечения таймера.
Поэтому важно понимать, что процессы отправки и получения ACKов могут идти независимо друг от друга. На этой идее и был рождён метод скользящего окна.
Окно первое. Скользящее. Теоретическое.
После осознания минусов предыдущего метода, в голову приходит идея разрешить источнику передавать пакеты в максимально возможном для него темпе, без ожидания подтверждения от приёмника. Но не бесконечное их количество, а ограниченное неким буфером, который называется окном, а его размер указывает на количество кадров которое разрешено передать без ожидания подтверждений.
Вернёмся к картинкам:
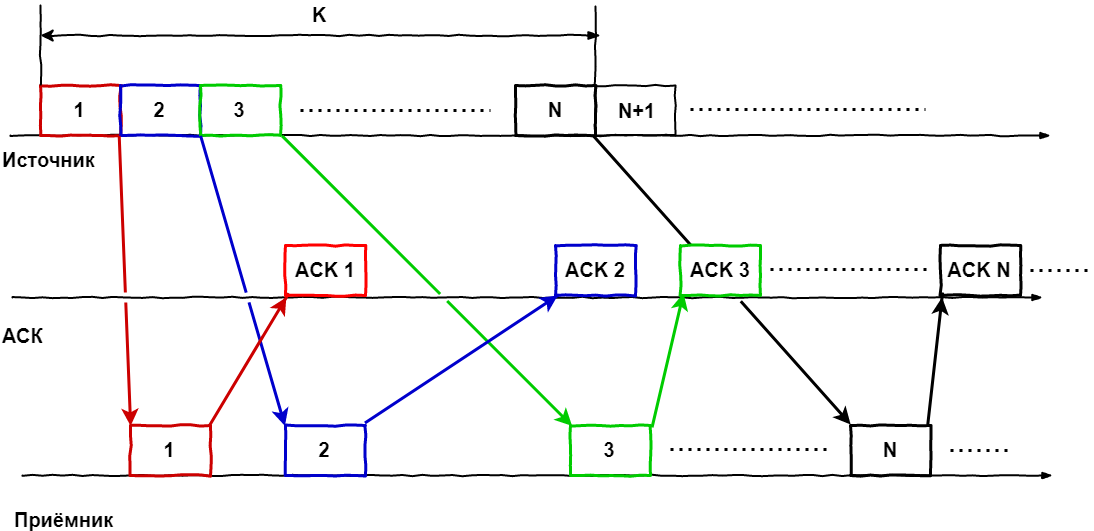
Для наглядности рассмотрим окно размером К кадров, в котором находятся пакеты (1. N) в некий момент времени, т.е. у нас была отправлена пачка кадров, каждый кадр по мере своей возможности достиг получателя, тот их обработал и отправил подтверждение для каждого.
Теперь усложняем ситуацию, включив время.
В момент прихода АСК на первый кадр, последний ещё не был даже отправлен, но поскольку мы знаем об успешности доставки, в окно можно добавить следующий по порядку кадр, т.е. окно сдвигается и теперь включает в себя кадры 2. N+1. Когда приходит ACK на 2-й кадр, окно снова сдвигается: 3. N+2. И так далее. Получается, что окно как-бы «скользит» по потоку пакетов. Или пакеты через него, тут кому как удобней представлять.
Таким образом, все кадры глобально делятся на три вида:
- Прошлое.Были отправлены, были получены подтверждения
- Суровое настоящее. Состоит из отправленных кадров, но без полученных подтверждений и тех, кто уже в окне, но стоит в очереди на отправку
- Светлое будущее. Кадры в очереди на попадание в окно.
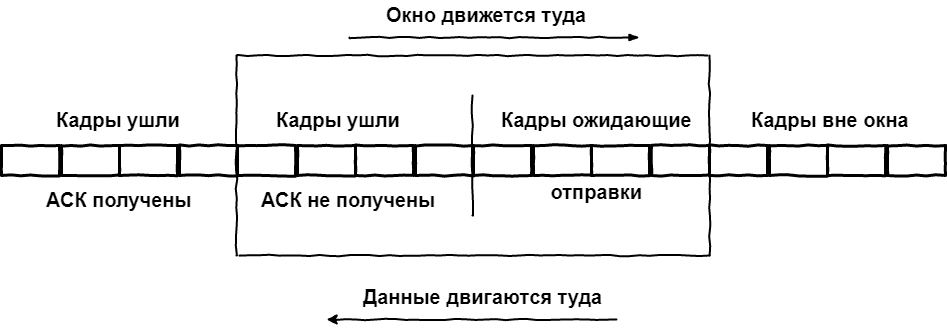
И как это влияет на скорость связи? – спросите вы.
Как мы видим из графика, необходимым условием для максимальной утилизации канала связи является регулярное поступление подтверждений в рамках действия окна. АСК не обязаны приходить в чётком порядке, главное чтобы АСК на первый кадр в окне пришёл раньше, чем будет отправлен последний кадр, иначе сработает таймер неответа, кадр будет отправлен заново, а движение окна прекратится.
Также, стоит отметить, что в большинстве реализаций алгоритма скользящего окна, подтверждения приходят не на каждый пакет, а сразу на всю принятую пачку (называется Selective Ack). Это позволяет ещё больше увеличить эффективную утилизацию канала за счёт снижения объёма служебной информации.
Итак, что же мы имеем в сухом остатке? Какие параметры имеют существенное влияние на эффективность передачи данных между двумя точками?
- Размер окна, который выбирается меньшим из двух: окно, объявленное получателем (размер его буфера) или CWND — размер, определяемый отправителем на основе RTT
- Само RTT: время приёма-передачи, равное времени, затраченному на отправку сигнала, плюс время необходимое для подтверждения о приёме.
И мы не должны передать больше, чем готов принять получатель или пропустить сеть.
Давайте представим, что у нас супер надёжная сеть, где пакеты практически никогда не теряются и не бьются. В такой сети нам выгодно иметь окно максимально возможного размера, что позволит нам минимизировать паузы между отправкой кадров.
В плохой же сети ситуация обратная — при частых потерях и большом количестве битых пакетов нам важно доставить каждый из них в целости и сохранности, поэтому мы уменьшаем окно так, чтобы трафик как можно меньше терялся и мы избежали фатальных переотправок. Жертвовать в этом случае приходится скоростью.
И как нам всем известно, реальность — это смесь двух крайних случаев, поэтому в реальной сети размер окна величина переменная. Причём он может быть изменён, как в одностороннем порядке на любой стороне, так и по согласованию.
Промежуточное резюме. Как мы видим, даже без привязки к конкретным протоколам, чисто технически крайне сложно утилизировать канал на все 100%, т.к. хотим мы того или нет, но даже в лабораторных условиях между кадрами будут минимальные, но задержки, которые и не дадут нам достичь заветных 100% утилизации полосы пропускания.
А что уж говорить про реальные сети? Вот во второй части мы и рассмотрим одну из реализаций на примере TCP.
Окно второе. Реализация в TCP
Чем замечателен ТСР? На основе ненадёжных дейтаграмм IP, он позволяет обеспечить надежную доставку сообщений.
При установлении логического соединения модули ТСР обмениваются между собой следующими параметрами:
- Размер буфера получателя — это верхнее ограничение размера окна
- Начальный порядковый номер байта, с которого начнётся отсчёт потока данных в рамках этой сессии
Сразу запоминаем важную особенность — в ТСР окно оперирует не количеством кадров, а количеством байт. Это значит, что окно представляет из себя множество нумерованных байт неструктурированного потока данных от верхних протоколов. Звучит громоздко, но проще написать не получается.
Итак, ТСР протокол дуплексный, а значит каждая сторона в любой момент времени выступает и как отправитель, и как получатель. Следовательно с каждой стороны должен быть буфер для приёма сегментов и буфер для ещё не отправленных сегментов. Но кроме того, должен быть ещё и буфер для копий уже отправленных сегментов, на которые ещё не получили подтверждения о приёме.
Кстати, отсюда следует упускаемая многими особенность: в двух направлениях условия сети могут быть разными, а значит разный размер окон и разная пропускная способность.
В такой ситуации пляска ведётся от возможностей получателя. При установлении соединения, обе стороны высылают друг другу окна приёма. Получатель запоминает его размер и понимает сколько байт можно отправить, не дожидаясь АСК.
Дальше включаются механизмы описанные в первой главе. Отправка сегментов, ожидание подтверждение, повторная отправка в случае необходимости и т.д. Важное отличие от теоретических изысканий — это комбинирование различных методик. Так например, получение нескольких сегментов, пришедших по порядку, происходит автоматически, прерываясь, только если сбивается очередность поступления. Это одна из функций буфера получателя — восстановить порядок сегментов. И то, если в потоке обнаруживается разрыв, ТСР модуль может повторить запрос потерянного сегмента.
Пара слов про буфер копий на отправителе. У всех сегментов, лежащих в этом буфере, работает таймер. Если за время таймера приходит соответствующий АСК, сегмент удаляется. Если нет — отправляется заново. Возможна такая ситуация, что по таймеру сегмент будет отправлен ещё раз до того, как придёт АСК, но в этом случае повторный сегмент просто будет отброшен получателем.
И вот от этого тайм-аута на ожидание и зависит производительность ТСР. Будет слишком короткий — появятся избыточные переотправки пакетов. Слишком длинный — получим простои из-за ожидания несуществующих АСК.
На самом деле ТСР определяет размер тайм-аута по сложному адаптивному алгоритму, где учитываются скорость, надежность, протяжённость линии и множество других факторов. Но в общих чертах он таков:
- При отправке каждого сегмента замеряется время до прихода АСК.
- Получаемые значения усредняются с весовыми коэффициентами, возрастающими от прошлого к будущему. Это позволяет более новым данным оказывать большее влияние на итоговый результат.
- Затем считается среднее значение от усреднений на предыдущем шаге и получается величина таймаута.Но если разброс величин очень велик, то учитывается ещё и дисперсия.
Но что-то мы всё больше про окно отправки, хотя окно приёма представляет из себя более интересную сущность. На разных концах соединения окна, обычно, имеют разный размер. В мире победивших клиент-серверных технологий, не приходится ожидать, что клиент будет готов оперировать окном того же размера, который может обрабатывать сервер.
Точно так же размер его может меняться динамически, в зависимости от состояния сети, но здесь неправильный выбор подразумевает уже “двойную” ответственность. В случае получения данных бОльших, чем может обработать ТСР модуль, они будут отброшены, на источнике сработает таймер, он переотправит данные, они опять не попадут в размер окна и т.д.
С другой стороны, установка слишком маленького окна приведёт к использованию канала на скорости равной скорости передачи одного сегмента.Поэтому разработчики ТСР предложили схему, в которой при установлении соединения размер окна устанавливается относительно большим и в случае проблем начинает сокращаться в два раза за шаг. Это действительно выглядит странно, поэтому были созданы реализации ТСР повторяющие привычную нам логику: начать с малого окна и, если сеть справляется, то начать его увеличивать.
Но на размер окна приёма может влиять не только принимающая сторона, но и отправитель данных. Если мы видим, что АСК регулярно приходят позже таймеров, что приходится часто переотправлять сегменты, то источник может выставить своё значение окна приёма и будет действовать правило наименьшего — будет принято самое маленькое значение, кто бы его ни назначил.
Остаётся рассмотреть ещё один вариант развития событий, а именно перегрузку ТСР-соединения. Это состояние сети характеризуется тем, что на на промежуточных и оконечных узлах возникают очереди пакетов. В данном случае у приёмника есть два варианта:
- Уменьшить размер окна.
- Совсем отказаться от приёма, установив размер окна, равный нулю.
Хотя полностью закрыть соединение таким образом нельзя. Существует специальный указатель срочности, который принуждает порт принять сегмент данных, даже если для этого придётся очистить существующий буфер. А принявший нулевой размер окна отправитель не теряет надежды и периодически отправляет контрольные запросы на приёмник и, если тот уже готов для принятия новых данных, то в ответ он получит новый, не нулевой, размер окна.
Итого
Капитан подсказывает — если одна TCP сессия в принципе не может обеспечивать 100% утилизацию канала, то используй две. Если мы говорим про клиента, который взял в аренду канал точка-точка и поднял в нём GRE туннель, то пусть поднимет второй. Дабы они не дрались за полосу, заворачиваем в первый важный трафик, во второй — всякую ерунду и страшно зарезаем ему скорость. Этого как раз хватит на то, чтобы выбрать остатки полосы, которую первая сессия не может взять чисто технически.



