- Кодировка в XML документе
- Символьная кодировка
- Юникод
- UTF-8 — Веб-стандарт
- Кодировка XML документа
- Ошибки XML
- Заключение
- Информационные технологии, интернет, веб программирование, IT, Hi-Tech, …
- Кодировка XML
- Ошибки Кодировки XML
- Блокнот Windows
- Выводы
- I. Коротко об XML¶
- Введение в XML¶
- Структура XML¶
- Правила синтаксиса (Валидность)¶
- Сущности¶
- Поиск информации в XML файлах (XPath)¶
- Кодировки¶
- XSD схема¶
- Как изменить кодировку сайта
- Что такое кодировка
- Типы кодировок
- Как определить кодировку на сайте
- Где и как изменить кодировку
- Смена кодировки базы данных
Кодировка в XML документе
XML документы могут содержать символы в различных международных кодировках.
Чтобы не возникало ошибок, необходимо указывать, какая кодировка используется в XML документе, либо сохранять файл в универсальной кодировке UTF-8.
Символьная кодировка
Символьная кодировка определяет уникальный бинарный код для различных символов, используемых в документе.
В компьютерных терминах символьную кодировку также называют символьным набором, символьной раскладкой, кодовым набором и кодом страницы.
Юникод
Юникод — это промышленный стандарт для символьной кодировки текстового документа. Он определяет (почти) все возможные международные символы по именам и числам.
Юникод имеет две разновидности: UTF-8 и UTF-16.
UTF = формат преобразования Юникода (анг. Unicode Transformation Format).
UTF-8 использует один байт (8 бит) для представления общепринятых символов и два (или три) байта для всех остальных символов.
UTF-16 использует два байта (16 бит) для большинства символов и три байта для всего остального.
UTF-8 — Веб-стандарт
UTF-8 — стандартная кодировка символов в сети Интернет.
UTF-8 считается кодировкой по умолчанию в HTML-5, CSS, JavaScript, PHP, SQL и XML.
Кодировка XML документа
Первая строка в XML документе называется прологом:
Пролог является необязательным и, как правило, содержит номер версии XML.
Кроме этого, он может содержать информацию о кодировке XML документа. Следующий пролог определяет кодировку UTF-8:
Стандартизация XML устанавливает, что все приложения XML должны понимать кодировки UTF-8 и UTF-16.
UTF-8 является кодировкой по умолчанию для XML документов без информации о кодировке.
Кроме этого, большинство систем приложений XML работают с такими кодировками, как ISO-8859-1, Windows-1252 и ASCII.
Ошибки XML
Очень часто XML документы создаются на одном компьютере, на сервер выгружается с другого, а в браузере отображаются на третьем компьютере.
Если кодировка некорректно интерпретируется всеми тремя компьютерами, то браузер отобразит бессмысленный набор символов, либо вообще выдаст сообщение об ошибке.
Наилучшим выбором в этом случае будет использование кодировки UTF-8. UTF-8 позволяет отображать практически все международные символы, и, кроме этого, она считается кодировкой по умолчанию, если не указана другая кодировка.
Заключение
Когда вы пишите XML документ:
- Используйте текстовый редактор, который позволяет изменять кодировку документа
- Убедитесь, что редактор настроен на использование нужной кодировки
- Опишите используемую кодировку в соответствующей декларации
- UTF-8 является самой безопасной кодировкой
- UTF-8 является стандартом в сети Интернет
Информационные технологии, интернет, веб программирование, IT, Hi-Tech, …
Кодировка XML
Здравствуйте, уважаемые посетители сайта okITgo.ru! Продолжаем рассматривать язык разметки XML.
XML документы могут содержать символы, не входящие в ASCII, например норвежские, или французские.
Чтобы избежать ошибок, указывайте кодировку XML, или сохраняйте XML файлы в формате Уникод.
Ошибки Кодировки XML
При загрузке XML документа, Вы можете получить две различные ошибки, указывающие на проблемы с кодировкой:
Неправильный символ был найден в текстовом содержимом.
Вы получаете эту ошибку, если ваш XML содержит символы, не входящие в ASCII, и файл был сохранен как однобайтовый ANSI (или ASCII) без указания кодировки.
Переключение из текущей кодировки в указанную кодировку не поддерживается.
Вы получаете эту ошибку, если ваш XML файл был сохранен как двухбайтовый Уникод (или UTF-16) с указанной однобайтовой кодировкой (например, Windows-1251,
ISO-8859-1, UTF-8).
Вы также получаете эту ошибку, если ваш XML файл был сохранен как однобайтовый ANSI (или ASCII) с указанной двухбайтовой кодировкой (например, UTF-16).
Блокнот Windows
Блокнот Windows сохраняет файлы как однобайтовые ANSI (ASCII) по умолчанию.
Если Вы выберите «Сохранить как…», Вы можете указать двухбайтовый Уникод (UTF-16).
Сохраните XML файл ниже как Уникод (заметьте, что документ не содержит атрибута кодировки):
| Света |
Файл выше, note_encode_none_u.xml НЕ будет генерировать ошибку. Но если Вы укажете однобайтовую кодировку, то будет.
Кодировка (откройте файл), вызовет сообщение об ошибке:
Следующая кодировка (откройте файл), вызовет сообщение об ошибке:
Следующая кодировка (откройте файл), вызовет сообщение об ошибке:
Следующая кодировка (откройте файл), НЕ будет генерировать ошибку:
Выводы
- Всегда используйте атрибут кодировки XML
- Используйте редактор, который поддерживает кодировки
- Удостоверьтесь, что знаете, какую кодировку использует ваш редактор
- Используйте ту же самую кодировку в атрибуте кодировки
I. Коротко об XML¶
Введение в XML¶
XML ( англ. eXtensible Markup Language) — расширяемый язык разметки, предназначенный для хранения и передачи данных.
Простейший XML-документ выглядит следующим образом:
Первая строка — это XML декларация. Здесь определяется версия XML (1.0) и кодировка файла. На следующей строке описывается корневой элемент документа (открывающий тег). Следующие 4 строки описывают дочерние элементы корневого элемента ( title , author , year , price ). Последняя строка определяет конец корневого элемента (закрывающий тег).
Документ XML состоит из элементов (elements). Элемент начинается открывающим тегом (start-tag) в угловых скобках, затем идет содержимое (content) элемента, после него записывается закрывающий тег (end-teg) в угловых скобках.
Элементы могут содержать атрибуты, так, например, открывающий тег lang=»en»> имеет атрибут lang , который принимает значение en . Значения атрибутов заключаются в кавычки (двойные или ординарные).
Некоторые элементы, не содержащие значений, допустимо записывать без закрывающего тега. В таком случае символ / ставится в конце открывающего тега:
Структура XML¶
XML документ должен содержать корневой элемент. Этот элемент является «родительским» для всех других элементов.
Все элементы в XML документе формируют иерархическое дерево. Это дерево начинается с корневого элемента и разветвляется на более низкие уровни элементов.
Все элементы могут иметь подэлементы (дочерние элементы):
Правила синтаксиса (Валидность)¶
Структура XML документа должна соответствовать определенным правилам. XML документ отвечающий этим правилам называется валидным (англ. Valid — правильный) или синтаксически верным. Соответственно, если документ не отвечает правилам, он является невалидным .
Основные правила синтаксиса XML:
- Теги XML регистрозависимы — теги XML являются регистрозависимыми. Так, тег не то же самое, что тег .
Открывающий и закрывающий теги должны определяться в одном регистре:
- XML элементы должны соблюдать корректную вложенность:
- У XML документа должен быть корневой элемент — XML документ должен содержать один элемент, который будет родительским для всех других элементов. Он называется корневым элементом.
- Значения XML атрибутов должны заключаться в кавычки:
Сущности¶
Некоторые символы в XML имеют особые значения и являются служебными. Если вы поместите, например, символ внутри XML элемента, то будет сгенерирована ошибка, так как парсер интерпретирует его, как начало нового элемента.
В примере ниже будет сгенерирована ошибка, так как в значении «ООО » атрибута НаимОрг содержатся символы и > .
Также ошибка будет сгенерирована и в слудющем примере, если название организации взять в обычные кавычки (английские двойные):
Чтобы ошибки не возникали, нужно заменить символ на его сущность. В XML существует 5 предопределенных сущностей:
| Сущность | Символ | Значение |
|---|---|---|
| меньше, чем | ||
| > | > | больше, чем |
| & | & | амперсанд |
| ‘ | ‘ | апостроф |
| « | « | кавычки |
Только символы и & строго запрещены в XML. Символ > допустим, но лучше его всегда заменять на сущность.
Таким образом, корректными будут следующие формы записей:
В последнем примере английские двойные кавычки заменены на французские кавычки («ёлочки»), которые не являются служебными символами.
Поиск информации в XML файлах (XPath)¶
XPath ( англ. XML Path Language) — язык запросов к элементам XML-документа. XPath расширяет возможности работы с XML.
XML имеет древовидную структуру. В документе всегда имеется корневой элемент (инструкция version=”1.0”?> к дереву отношения не имеет). У элемента дерева всегда существуют потомки и предки, кроме корневого элемента, у которого предков нет, а также тупиковых элементов (листьев дерева), у которых нет потомков. Каждый элемент дерева находится на определенном уровне вложенности (далее — «уровень»). У элементов на одном уровне бывают предыдущие и следующие элементы.
Это очень похоже на организацию каталогов в файловой системе, и строки XPath, фактически, — пути к «файлам» — элементам. Рассмотрим пример списка книг:
XPath запрос /bookstore/book/price вернет следующий результат:
Сокращенная форма этого запроса выглядит так: //price .
С помощью XPath запросов можно искать информацию по атрибутам. Например, можно найти информацию о книге на итальянском языке: //title[@lang=»it»] вернет lang=»it»>Everyday Italian .
Чтобы получить больше информации, необходимо модифицировать запрос //book[title[@lang=»it»]] вернет:
В приведенной ниже таблице представлены некоторые выражения XPath и результат их работы:
| Выражение XPath | Результат |
|---|---|
| /bookstore/book[1] | Выбирает первый элемент book , который является потомком элемента bookstore |
| /bookstore/book[position() | Выбирает первые два элемента book , которые являются потомками элемента bookstore |
| //title[@lang] | Выбирает все элементы title с атрибутом lang |
| //title[@lang=’en’] | Выбирает все элементы title с атрибутом lang , который имеет значение en |
| /bookstore/book[price>35.00] | Выбирает все элементы book , которые являются потомками элемента bookstore и которые содержать элемент price со значением больше 35.00 |
| /bookstore/book[price>35.00]/title | Выбирает все элементы title элементов book элементов bookstore , которые содержать элемент price со значением больше 35.00 |
Кодировки¶
И еще один важный момент, который стоит рассмотреть — кодировки. Существует множество кодировок, о них подробнее можно прочитать в статье Набор символов.
Самыми распространенными кириллическими кодировками являются Windows-1251 и UTF-8 . Последняя является одним из стандартов, но большая часть ФНС отчетности имеет кодировку Windows-1251 .
В XML файле кодировка объявляется в декларации:
Часто можно столкнуться с ситуацией, когда текстовый редаткор некорректно распознает кодировку и отображает кракозябры. В такой случае, необходимо выбрать кодировку вручную, для этого выполните:
| Программа | Кодировка |
|---|---|
| Notepad++ | «Документ → Кодировка» |
| Geany | «Документ → Установить кодировку» |
| Firefox | «Вид → Кодировка» |
| Chrome | «Настройка → Дополнительные инструменты → Кодировка» |
В большинстве случаев при работе с русскоязычными файлами помогает переключение кодировки на Windows-1251 или UTF-8 . Если все равно не удается прочитать содержимое XML документа, стоит открыть его в Mozilla Firefox, он отлично распознает кодировки.
Если ничего не помогает, вполне возможно, что файл был поврежден.
XSD схема¶
XML Schema — язык описания структуры XML-документа, его также называют XSD. Как большинство языков описания XML, XML Schema была задумана для определения правил, которым должен подчиняться документ. Но, в отличие от других языков, XML Schema была разработана так, чтобы её можно было использовать в создании программного обеспечения для обработки документов XML.
После проверки документа на соответствие XML Schema читающая программа может создать модель данных документа, которая включает:
- словарь (названия элементов и атрибутов);
- модель содержания (отношения между элементами и атрибутами и их структура);
- типы данных.
Каждый элемент в этой модели ассоциируется с определённым типом данных, позволяя строить в памяти объект, соответствующий структуре XML-документа. Языкам объектно-ориентированного программирования гораздо легче иметь дело с таким объектом, чем с текстовым файлом.
Подробнее об XSD смотрите:
Примером использования XSD cхем может служить электронная отчетность:
Как изменить кодировку сайта
Иногда возникают случаи, когда при открытии сайта отображается не привычный нам контент, а сплошной набор нечитаемых символов. Это связано с тем, что кодировка ресурса не совпадает с той кодировкой, которая устанавливается сервером. Например, для чтения файлов используется Windows-1251, а требуется UTF-8.
Что такое кодировка сайта и как ее можно изменить – об этом и поговорим в сегодняшней статье.
Что такое кодировка
Кодировка – специальный метод, позволяющий отображать текст на экране таким образом, чтобы он был понятен каждому пользователю. Все символы, которые мы видим в интернете, – это буквы и цифры только для нас, компьютер их не понимает. Он воспринимает информацию в байтах, весь текст на экране монитора – это совокупность байтов. У каждого символа есть свое кодовое значение, которое компьютер использует при выводе слов и чисел на экран.
Вот наглядный пример того, как воспринимается компьютером латинский алфавит и прочие символы:
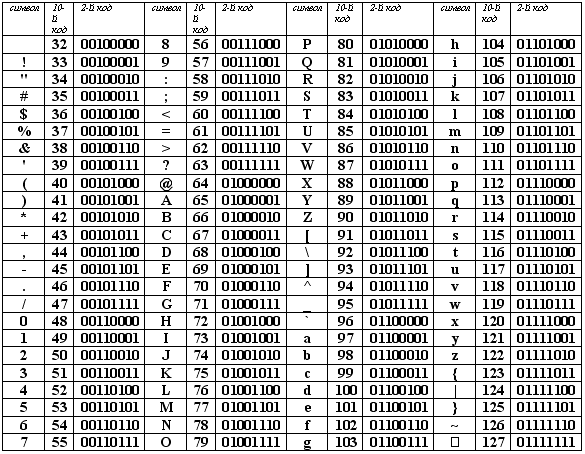
Если никакая кодировка не установлена, вместо символов мы увидим такие значения. Чтобы понять компьютер, необходимо установить нужную кодировку для расшифровки символов из этой таблицы.
Типы кодировок
Существует несколько типов кодировок:
- ASCII – первая кодировка, которая была признана Американским национальным институтом мировых стандартов. Для ее использования задействуется 7 бит, где первые 128 значений включают в себя весь английский алфавит, числа, знаки и символы. Такая кодировка ранее использовалась на англоязычных ресурсах.
- Кириллица – вариант российской кодировки, используемый на русскоязычных сайтах и блогах.
- КОИ8 (код обмена информацией 8-битный) – была разработана для кодирования букв кириллических алфавитов. Распространена в Unix-подобных ОС и электронной почте. Постепенно исчезает в связи с приходом Юникода.
- Windows 1250-1258 – 8-битные кодировки, зародившиеся после появления операционной системы Windows. Например, 1250 – все языки центральной Европы, 1251 – кириллица. В ней присутствуют все буквы русского алфавита, а также символы (за исключением знака ударения).
- UTF-8 – наиболее используемый тип кодировок, работающий практически со всеми языками мира. Символы занимают от 1 до 4 байт, что дает возможность создавать мультиязычные веб-сайты. Помимо UTF-8, есть такие варианты, как UTF-16 и UTF-32, однако предпочтение отдается первому типу.
Существуют и другие типы кодировок, но они используются в меньшей степени либо не используются вообще.
Как определить кодировку на сайте
Узнать кодировку своего или чужого сайта довольно просто, достаточно просмотреть исходный код страницы. Сделать это можно следующим образом:
- Открываем сайт, на котором необходимо посмотреть кодировку, и кликаем правой кнопкой мыши по любой области. В отобразившемся меню выбираем «Просмотр кода страницы». Также можно воспользоваться комбинацией клавиш «CTRL+U».

- В результате перед нами отобразится новое окно с кодом страницы – в нем воспользуемся комбинацией клавиш «CTRL+F» для поиска строки, отвечающей за кодировку веб-страницы. Вводим запрос «charset» и смотрим результат.
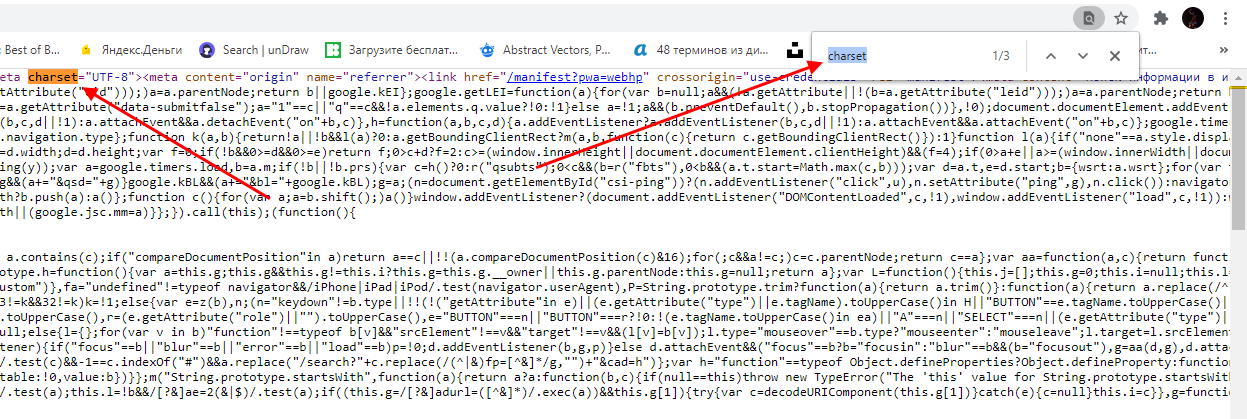
После charset указано значение UTF-8 – это означает, что данная кодировка используется на рассматриваемом сайте. Если вы увидели, что на вашем сайте указана некорректная кодировка, то это можно исправить. Подробнее о том, как это сделать, поговорим далее.
Где и как изменить кодировку
Все зависит от сайта. Способ установки кодировки может различаться: если используется одностаничник, то достаточно в HTML-файле прописать мета-тег в блоке :
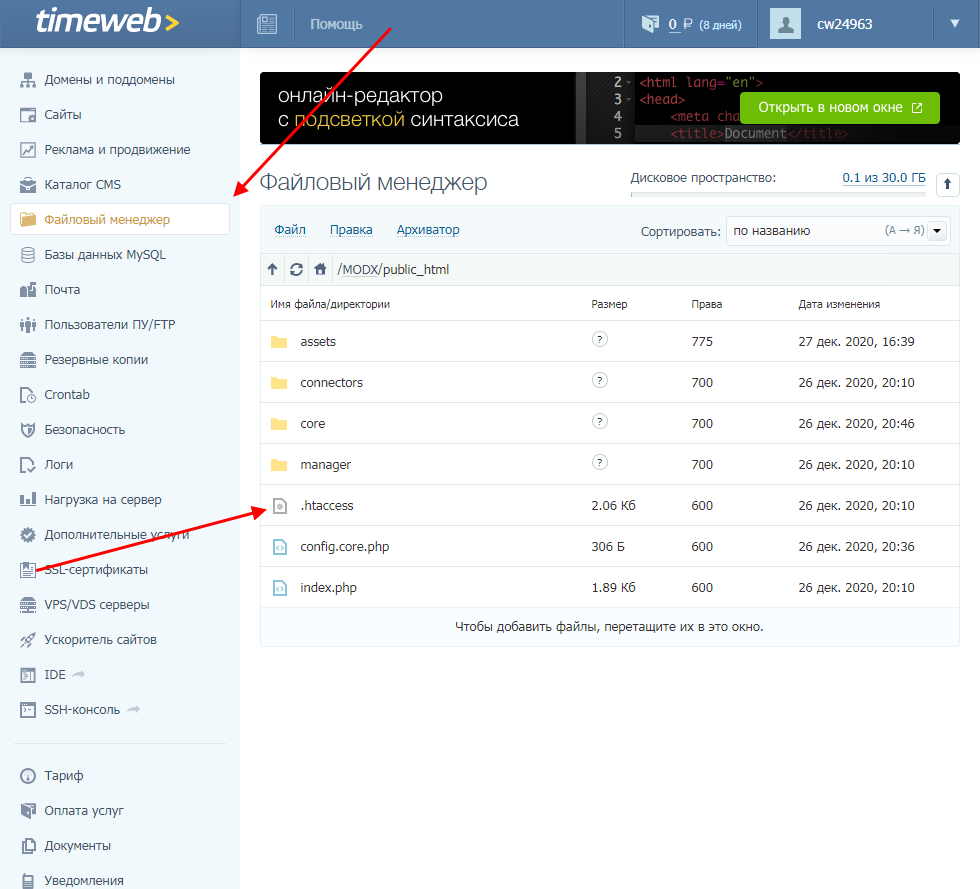
В противном случае нам потребуется отредактировать файл .htaccess. Рассмотрим на примере хостинга Timeweb, как это можно сделать.
- Открываем личный кабинет и переходим в раздел «Файловый менеджер». В нем перемещаемся в директорию с сайтом и находим в корне файл .htaccess – открываем его двойным кликом мыши.
- В начало файла необходимо добавить следующий код:
Открываем свой сайт и видим, что ничего не изменилось – так и должно быть. Чтобы внести изменения, очищаем кэш с помощью комбинации клавиш «CTRL+F5» и смотрим результат.
Как видите, сменить кодировку на своем сайте легко. Аналогичным образом мы можем изменить кодировку и на всем сервере – для этого необходимо выполнить следующее (актуально для веб-сервера Apache):
- Находим файл httpd.conf, который расположен по адресу: «/usr/local/apache/conf/», и открываем его.
- Если нужно поменять Windows-1251 на UTF-8, то меняем строку «AddDefaultCharset windows-1251» на «AddDefaultCharset utf-8».
Если вы поменяете кодировку по умолчанию, то она будет изменена для всех ресурсов, находящихся на данном сервере.
Смена кодировки базы данных
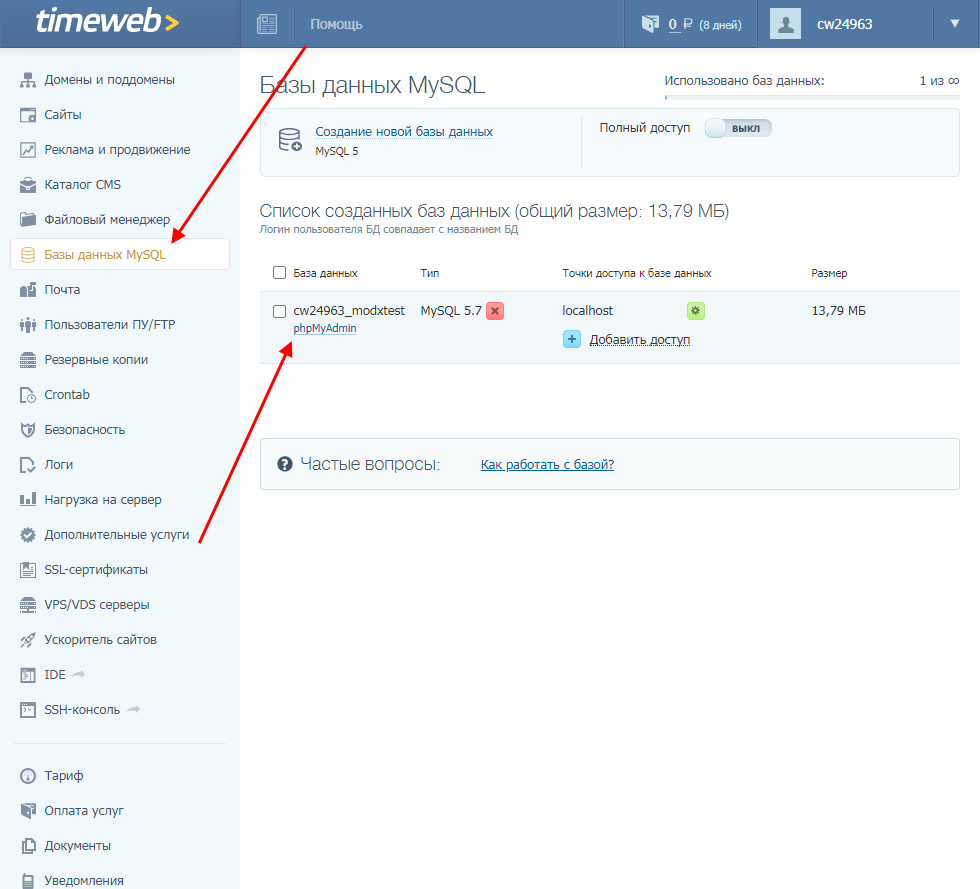
В данном случае нам потребуется открыть базу данных через личный кабинет хостинга и изменить значение кодировки в разделе «Операции». Давайте рассмотрим, как это можно сделать через админку Timeweb.
- Переходим в свой аккаунт и открываем раздел «Базы данных MySQL» – в нем находим нужную базу данных и кликаем по кнопке «phpMyAdmin».
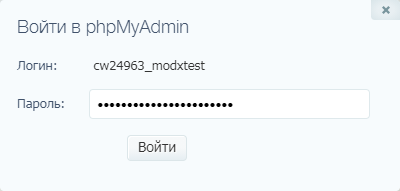
- В отобразившемся окне вводим пароль и следуем далее.
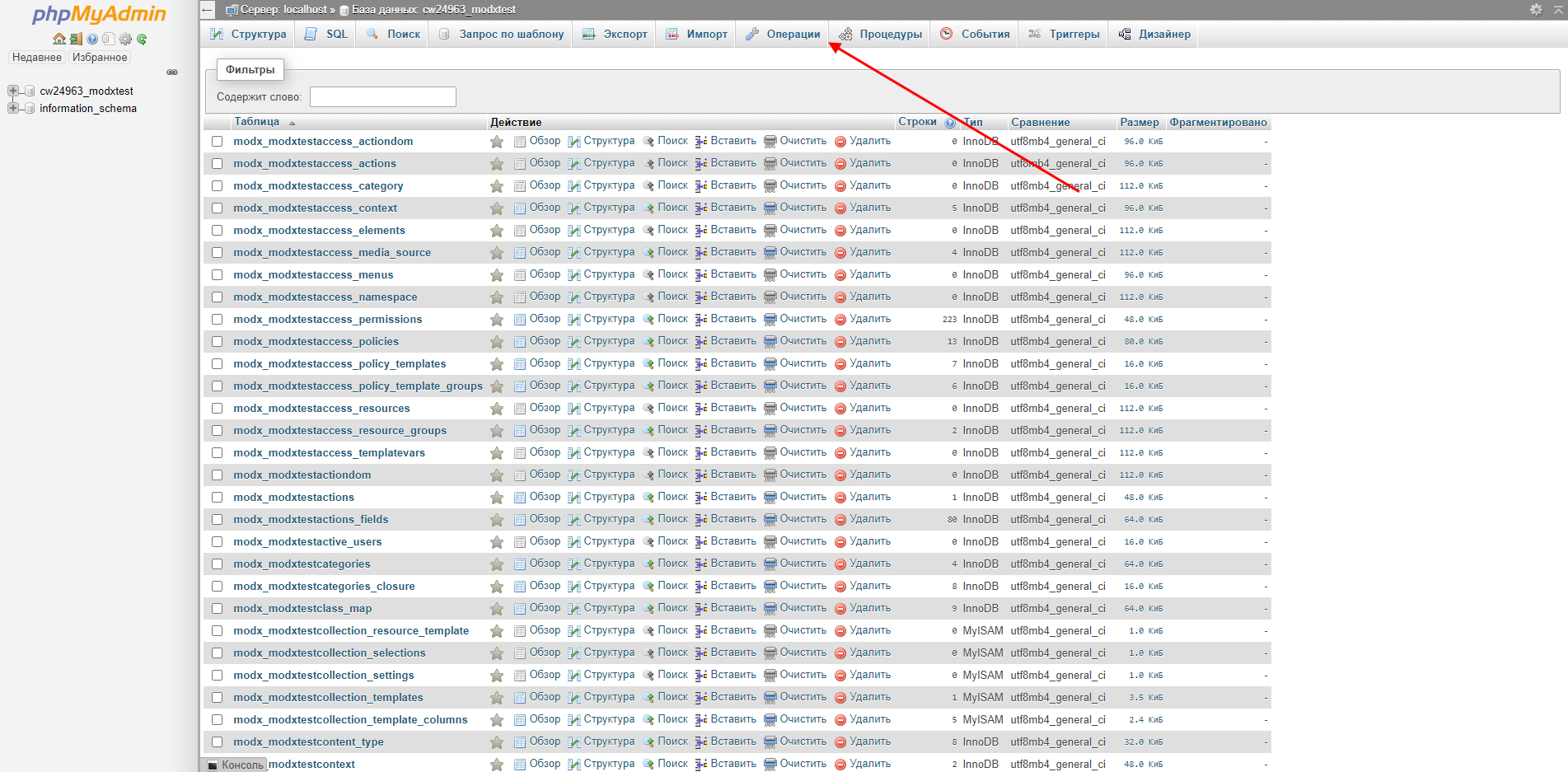
- Переходим к нужной базе данных и в верхнем меню выбираем «Операции».
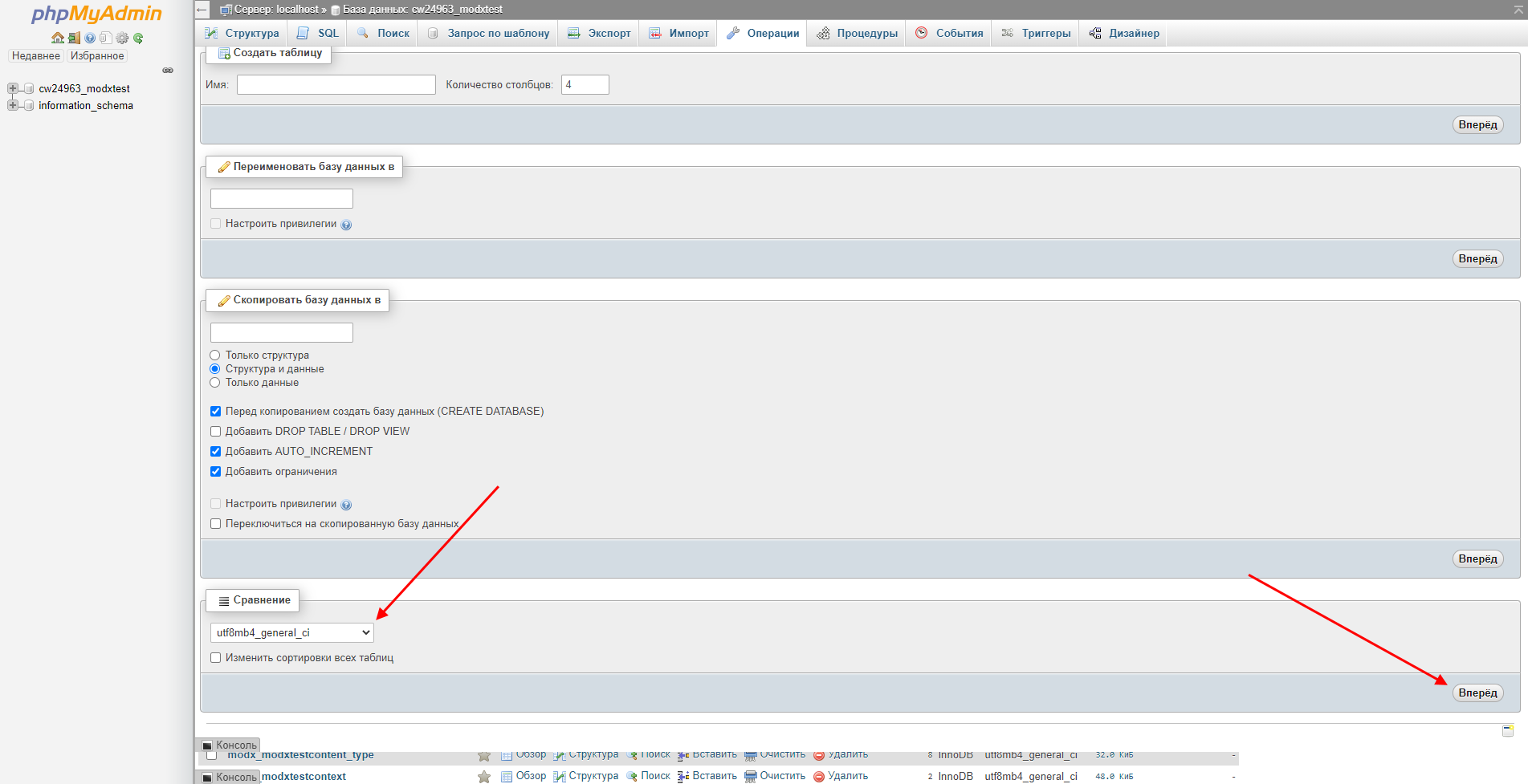
- Указываем в нижнем блоке значение «utf8mb4_general_ci» и в правой части жмем на кнопку «Вперед».
- Готово! Теперь база данных использует кодировку UTF-8.
На этом статья подходит к концу. Теперь вы знаете больше о кодировке сайта и можете легко ее изменить в случае необходимости. Спасибо за внимание!



