- Русские Блоги
- Zabbix CPU load、CPU utlization、CPU jumps
- Во-первых, загрузка ЦП
- Два, загрузка процессора
- Интеллектуальная рекомендация
- Используйте Maven для создания собственного архетипа скелета проекта (4)
- Станция интерпретации больших данных B пользуется популярностью среди гигантов района «призрачные животные» Цай Сюкуня.
- Вопрос A: Алгоритм 7-15: алгоритм кратчайшего пути Дейкстры
- Учебный дневник — перелистывание страниц
- Нулевое основание для отдыха-клиента
- Вам также может понравиться
- Подробно объясните, как новички используют sqlmap для выполнения инъекционных атак на базы данных mysql.
- Vue заметки сортируют, пусть вам начать с Vue.js:. 04_3 Сетевое приложение: AXIOS плюс Вью
- Шаблон алгоритма конной повозки
- 35 Line Code, чтобы получить метод исследования событий (ON)
- Образ докера: gitlab
- Мониторинг использования CPU в Zabbix
- Мониторим ядра CPU в Zabbix и создаем произвольные счетчики в Low-level discovery
Русские Блоги
Zabbix CPU load、CPU utlization、CPU jumps
Во-первых, загрузка ЦП

Используйте Zabbix, чтобы проверить загрузку ЦП, будут следующие значения:
- Время простоя ЦП: отношение времени простоя ЦП [для краткости id]
- Пользовательское время ЦП: время ЦП, используемое в пользовательском режиме [именуемое нами]
- Системное время ЦП: соотношение времени ЦП, используемое в системном режиме [сокращенно sy]
- CPU iowait time: CPU ожидает времени завершения записи на диск [wa]
- Хорошее время ЦП: соотношение времени ЦП в пользовательском режиме, используемое в качестве хорошо взвешенного распределения процесса [обозначается как ni]
- Время прерывания ЦП: время использования аппаратного прерывания [привет]
- CPU softirq time: время использования жесткого прерывания [si]
- Время кражи ЦП: время кражи виртуальной машины [именуемое st]
Фактически, эти данные получаются с помощью команды top в системе Linux: 
Два, загрузка процессора

Загрузка процессора обеспечивает 1 минуту, 5 минут и 15 минут одноядерной загрузки процессора.
Мы обнаружим, что данные, предоставляемые Zabbix, сильно отличаются от данных средней нагрузки, выводимых командой top, потому что top подсчитывает общее количество ядер.
Кроме того, Zabbix настроен с двумя триггерами
Интеллектуальная рекомендация

Используйте Maven для создания собственного архетипа скелета проекта (4)
Один, базовое введение в Maven Во-вторых, скачайте и настройте Maven Три, настроить домашнее зеркало на Али В-четвертых, создайте содержимое скелета архетипа В-пятых, создайте проект через архетип 6. .

Станция интерпретации больших данных B пользуется популярностью среди гигантов района «призрачные животные» Цай Сюкуня.
Автор | Сюй Линь Ответственный редактор | Ху Вэйвэй Предисловие Недавно Цай Сюкунь отправил письмо юриста на станцию B. Содержание письма юриста показало, что «на станции B имеется большое кол.

Вопрос A: Алгоритм 7-15: алгоритм кратчайшего пути Дейкстры
Название Описание Во взвешенном ориентированном графе G для исходной точки v задача о кратчайшем пути от v до оставшихся вершин в G называется задачей кратчайшего пути с одной исходной точкой. Среди ш.
Учебный дневник — перелистывание страниц
Используйте плагин Layui.

Нулевое основание для отдыха-клиента
Предисловие: статья, обобщенная, когда я только что связался с тестом API, в дополнение к остальному клиенту этот инструмент сам, некоторые из мелких пониманий API, я надеюсь помочь тому же белую белу.
Вам также может понравиться

Подробно объясните, как новички используют sqlmap для выполнения инъекционных атак на базы данных mysql.
Шаг 1. Откройте для себя инъекцию Со мной все было нормально, когда я был свободен, я случайно нажал на чужой блог и обнаружил, что ссылка заканчивается на id, поэтому я проверил его вручную. Результа.

Vue заметки сортируют, пусть вам начать с Vue.js:. 04_3 Сетевое приложение: AXIOS плюс Вью
В предыдущем разделе мы ввели основное использование AXIOS, по сравнению с нативным Ajax, который при условии, что способ является более простым и, а сетевые данные теперь в состоянии получить его ров.

Шаблон алгоритма конной повозки
Блог гангстеров Тележки, запряженные лошадьми, используются для решения проблемы самой длинной подстроки палиндрома. Основное внимание уделяется подстрокам, а не подпоследовательностям. Если вы хотите.

35 Line Code, чтобы получить метод исследования событий (ON)
Об авторе: Чжу Сяою,Личный публичный номер: языковой класс большой кошки Эта проблема научит вас этой большой классе Cat.Как написать наиболее эффективное метод исследования событий с 35 Line R Code C.
Образ докера: gitlab
GitLab Docker images Both GitLab CE and EE are in Docker Hub: GitLab CE Docker image GitLab EE Docker image The GitLab Docker images are monolithic images of GitLab running all the necessary services .
Источник
Мониторинг использования CPU в Zabbix
Приведу пример мониторинга использования каждого ядра процессора используя Zabbix.
Допустим на высоконагруженном NAT сервере основная нагрузка от softirq, присутствует один процессор с 8 ядрами, а также на сервере установлен Zabbix агент.
И чтобы увидеть равномерно ли распределены прерывания сетевого адаптера по ядрам процессора, создадим элементы данных на Zabbix сервере, в которых укажем:
Тип: Zabbix агент
Тип информации: Числовой (с плавающей точкой)
Единица измерения: %
А также ключ:
Где 0 — номер процессора, softirq — тип нагрузки, avg5 — средняя нагрузка за 5 минут. Аналогично создадим элементы данных для других ядер процессора с ключами, а также добавим их на один график:
Вместо softirq можно указать idle, nice, user (по умолчанию для Linux), system (по умолчанию для Windows), iowait, interrupt, softirq, steal, guest, guest_nice.
А вместо avg5 можно указать: avg1 (среднее за одну минуту, по умолчанию) или avg15 (среднее за 15 минут).
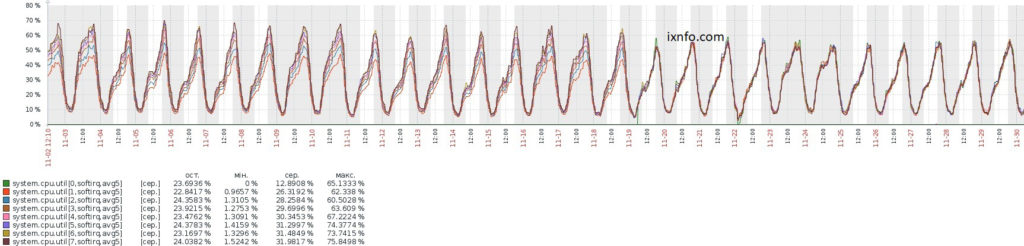
Чтобы не указывать ядра процессоров вручную, можно создать правило обнаружения:
И указать в нем элемент данных, например:
Также можно создать триггер, чтобы узнать когда значение будет больше 90:
Ниже приведу примеры элементов данных, которые отображают различную информацию о CPU, кстати эти элементы данных по умолчанию присутствуют в шаблоне «Template OS Linux».
Источник
Мониторим ядра CPU в Zabbix и создаем произвольные счетчики в Low-level discovery
Не так давно тут проходила статья про LLD. Мне она показалась скучной т.к. описывает примерно то же, что есть и в документации. Я решил пойти дальше и с помощью LLD мониторить те параметры, которые раньше нельзя было мониторить автоматически, либо это было достаточно сложно. Разберем работу LLD на примере логических процессоров в Windows: 
Изначально интересовал расширенный монтиринг помимо ядрер CPU и нагрузка на физические диски. До того как обнаружение было введено, эти задачи частично решались ручным добавлением. Я добавлял условные диски в файл конфигурации zabbix_agent и вообще по-разному извращался. В результате это было очень неудобно, добавлялось много неприятной ручной работы и вообще неправильно в общем как-то было 🙂
В итоге получается схема, которая автоматически определяет ядра в системе, а также физические диски, установленные в системе и добавляет необходимые элементы сбора данных. Для того, чтобы узнать как это реализовать у себя, добро пожаловать под кат. Я попытаюсь более-менее подробно расписать работу на примере CPU и то как сделать тоже самое, но для физических дисков.
Тип отправляемых данных
Для начала стоит отослать к документации, где расписывается что такое LLD и с чем его едят. Помимо стандартных шаблонов нас будет интересовать 4-ый раздел с описание JSON формата обнаружения. То есть мы будем создавать свой собственный метод обнаружения. По сути все сводится к вызову скрипта, который формирует в нужном формате нужные данные.
Создаем скрипт.
Для скрипта я выбрал powershell. Его я знаю немного лучше других скриптовых языков, да и учитывая, что все будет крутиться во круг WMI, сделать его можно было бы и на VBS.
Итак, скрипт.
Задача скрипта состоит в том, чтобы определить число логических процессоров с помощью WMI и вывести в консоль эти данные в формате JSON. Передавать мы будем переменную с именем , а также ее значения. Формат вывода будет примерно таким, в зависимости от количества логических процессоров:
Скрипт формирования данных
Сам скрипт выглядит так:
Сейчас мы получаем, что при запуске скрипта он узнает сколько ядер и формирует пакет для отправки.
Что же мы делаем дальше? Нужно создать Discovery rule.
Добавялем низкоуровневое обнаружение в настройках zabbix сервера
Для этого заходим в нужный шаблон, который добавлен к интересующим нас хостам, в раздел Discovery и нажимаем кнопку Create discovery rule.
Тут мы видим непонятное значение поля key: PSScript[proc.ps1]. Это UserParameter. Этот пункт создан для удобства, теперь в каждом новом объекте мы можем просто вписывать параметр в виде имени PS скрипта и он будет искать его в заранее оговоренном месте. Сам параметр прописывается в файле конфигурации клиента (обычно называется zabbix_agentd.conf) и выглядит так:
Мы создали новое правило обнаружения с пользовательским сбором данных. Запрос на изменение информации задан как 1 час. Пожалуй, для таких статических данных, как количество процессоров, это слишком часто :), но каждый волен поставить свое значение. Для первоначального сбора данных и отладки лучше это значение уменьшить до совсем небольших значений, чтобы не ждать часами выполнение скрипта.
Настройка прототипов данных
Хорошо. Данные о количестве процессоров мы начали собирать. Но в результате нам нужны не эти данные, а новый item в мониторинге. Именно item может собирать данные, а не наш скрипт, наш скрипт служит только для обнаружения самих элементов для сбора данных.
А для того что бы создать новый элемент сбора данных, полученный на основании LLD, в том же разделе Discovery мы создаем новый прототип. Для этого заходим в item prototypes и нажимаем create item prototype. Я создал вот такой элемент сбора:
Для сбора данных используется стандартный счетчик производительности. В zabbix для сбора этих данных есть ключ perf_counter. Вместо номера логического ядра мы вставляем полученное значение в виде переменной из раздела Discovery.
Теперь все готово. Или почти все…
С этого момента, когда скрипт discovery обнаружит логические процессоры, для этого хоста будут созданы элементы сбора данных созданных точно для этого количества процессоров.
И теперь если мы зайдем в items для хоста, низкоуровневое обнаружение для которого уже отработало, то мы увидим, что появились новые элементы:
Эти элементы нельзя удалить стандартным способом, т.к. они созданы автоматически, они выделены особенным префиксом с названием правила низкоуровневого обнаружения. На скриншоте кажется, что написана какая-то фигня в имени :), на самом деле все просто, я использую трехзначный код в каждом имени для сортировки. То есть 100 это только лишь сортировочный номер. Следующая цифра от 0 до 11 это номер логического процессора. А дальше уже «% загруженности процессора». А то сначала может показаться, что это 0% загруженности процессора и я пытаюсь это значение собрать 🙂
Единственный недостаток всего этого метода в том, что график, такой как в заголовке этого поста, нельзя создать с помощью механизма низкоуровневого обнаружения. То есть мы можем, конечно, создать не только item, но и graph объект для каждого логического процессора, но создать один суммарный график автоматически со всеми обнаруженными логическими процессорами не получится. По крайней мере я не видел как это можно было бы сделать, на форуме zabbix мне также не смогли подсказать. Это, конечно, не особенно серьезный недостаток, но если у вас 200 хостов, это может стать проблемой :). Ведь график для каждого хоста нужно будет создавать вручную.
Мониторим производительность каждого физического диска в системе
В вышеприведённом способе лучше разобраться и тогда это открывает достаточно широкие возможности для мониторинга объектов в системе, количество которых либо отличается от хоста к хосту либо их количество во все изменяется во время работы.
Например, часто случается, что нужно определить, не происходил ли недостаток в ресурсах физического диска, установленного в сервере. Чаще всего эти данные сложно уловить в реалтайме и хочется иметь их собранными постфактум. Для этого я ввел аналогичное обнаружение и для физических дисков для сбора обширной статистики по ним. И, в отличии от процессоров, элементов сбора данных я создал их с избытком.
Тут, конечно, надо быть внимательным и если mysql у вас стоит на каком-нибудь стареньком забитом компе, то подобное количество достаточно быстро унесет вашу базу данных в небеса. Т.к. в приведенном примере для каждого хоста создается для каждого физического диска 20 новых элементов, которые будут создавать одного новое значение в минуту. В масштабе пары десятков серверов с кучами разных дисков это выливается в более-менее весомое количество данных. Но тут каждый волен выбирать свой путь самурая 🙂
Скрипт для LLD физических дисков выглядит так:
Добавляем новое правило обнаружения по аналогии с CPU. Точно также мы создаем нужные элементы в discovery.
Вообще, конечно, этот механизм дает довольно большие возможности по определению различных элементов для мониторинга. Таким же способом можно, например, добавить мониторинг сетевых интерфейсов, процессов в системе, служб и любых других элементов, имя которых и количество заранее неизвестно.
Надеюсь эта статья кому-нибудь поможет разобраться с LLD. С удовольствием отвечу на возникшие вопросы.
Источник



