- Блог белорусского сисадмина
- полезные записки
- Мониторинг логов в Zabbix и возврат триггера в OK
- Мониторинг лог файла в Zabbix
- Введение
- Настройка мониторинга логов
- Создание триггера на событие из лога
- Заключение
- Мониторинг событий информационной безопасности с помощью ZABBIX
- Подготовка
- Мониторинг событий безопасности MS Windows Server
- Мониторинг событий безопасности Unix систем
- Мониторинг событий ИБ на сетевых устройствах
Блог белорусского сисадмина
полезные записки
Мониторинг логов в Zabbix и возврат триггера в OK
Zabbix может многое. Главное — суметь это настроить 🙂 Одна из полезных возможностей — мониторинг лог-файлов на наличие определенных записей. Если вы хотите держать руку на пульсе событий при мониторинге серверов, то без мониторинга логов никак не обойтись: почти все серьезные ошибки пишутся в логи и во многих случаях гораздо эффективнее мониторить один-два лога, чем настраивать отслеживания статуса 50 сервисов, работоспособность которых не всегда легко проверить.
Собственно, в самой настройке мониторинга логов нет ничего сложного: добавляем соответствующий Item, пишем регулярное выражение для триггера и начинаем получать уведомления! Например, мы хотим отслеживать все ошибки из System лога на серверах под управлением OS Windows. Для этого, создаем следующий Item:
Параметры следующие: System — лог, который отслеживаем; второй параметр — регулярное выражение, которое ищем (пропущен, берем все записи); третий — «Error» — важность, согласно классификации ОС; четвертый — любой источник; пятый — @eventlog — макрос, который исключает события с идентификаторами ^(1111|36888|36887|36874)$; шестой — максимальное кол-во строк, которое мы отправляем серверу в секунду (неограниченное); последний параметр — skip — заставляет сервер читать только новые записи лога, а не перечитывать его весь.
В качестве триггера мы используем следующую строку:
Т.е. мы берем любую строку, которая попала в Item и высылаем уведомление.
После такой настройки мы получим первую ошибку из лога и триггер будет висеть в состоянии PROBLEM до скончания веков, т.к. нет события, которое его переводит в состояние OK. Для решения этой проблемы необходимо добавить к триггеру еще одно условие: наличие новых данных в течение промежутка времени, меньшего, чем время опроса Item. Т.е. если мы проверяем лог на ошибки раз в минуту, то нам надо поставить любой промежуток времени, меньший, чем минута. Итоговый триггер будет выглядеть как-то так:
Выглядеть это будет как «нашли что-то в Item» И «за последние 10 секунд были получены новые данные». При следующей проверке триггер перейдет в состояние OK, т.к. за последние 10 секунд новых данных получено не было. Других способов возврата триггера для лога в нормальное состояние в заббиксе версии 2 не предусмотрено.
Мониторинг лог файла в Zabbix

Zabbix умет анализировать любой лог файл, сохранять его в свою базу, рассылать алерты по каким-то событиям. Я решил использовать эту возможность для анализа лог файла утилиты acpupsd для отправки оповещений об отключении электричества. Решается данная задача стандартным функционалом заббикса, описанного в документации.
Введение
Ранее я рассказывал об использовании утилиты управления упсами марки apc — apcupsd. Я показал, как установить apcupsd на hyper-v и xenserver для корректного завершения работы при отключении электричества. Рекомендую ознакомиться, если вас интересует этот вопрос. Его не всегда получается быстро и удобно решить. На помощь приходит apcupsd.
Указанные конфигурации у меня успешно работают, проверено годами. Я решил настроить отправку оповещений на почту через zabbix при пропадании электричества. Да и просто хочется хранить информацию об инцидентах в одном месте. Почтовые сообщения не всегда будут доставлены, нужно следить, чтобы на резервное питание были подключены все устройства, которые обеспечивают связь с интернетом. Частенько бывает, что при выключении электричества у провайдера так же выключается оборудование и связи нет. Либо ваш свитч, к которому подключен сервер, выключится и сообщение не будет доставлено.
Заранее позаботьтесь об этих вещах. Пишу об этом, потому что сам недавно на одном объекте все запитал от упсов, но забыл про свитч. В итоге об отключении электричества я узнал уже после того, как его вернули назад и сервера автоматически поднялись. Если у вас еще не настроен сервер мониторинга, рекомендую мою подробную статью с видео об установке и настройке zabbix на centos 9 или установка zabbix 3.4 на debian 9.
Настройка мониторинга логов
Для того, чтобы мониторить лог файл, на сервере должен быть установлен zabbix agent, а сам сервер добавлен в панель мониторинга. Я буду следить за логом программы apcupsd, который располагается по пути /var/log/apcupsd.events. Идем в веб интерфейс заббикса и добавляем новый итем к интересующему нас хосту. Если у вас таких будет несколько, то создавайте сразу шаблон. В моем случае у меня один сервер, поэтому я буду добавлять новый элемент сразу на него.
Создаем новый итем со следующими параметрами:
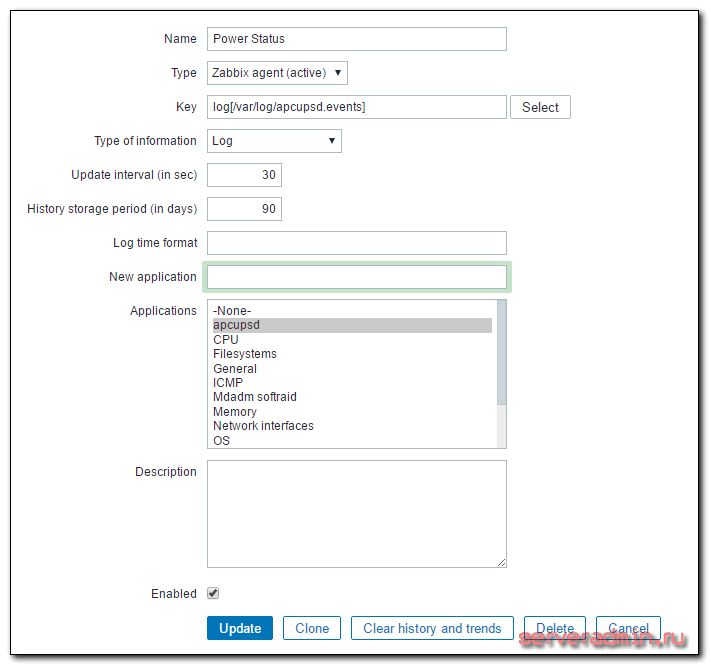
| Name | Имя нового итема. Можете указать любое название. |
| Type | Тип элемента. Обязательно выбираем Zabbix agent (active). По-умолчанию будет другой тип стоять. |
| Key | Ключ данных, log — тип, в квадратных скобках путь до лог файла. |
| Type of information | Указываем тип информации, поступающей в итем. |
Остальные параметры оставляете на свое усмотрение. Рекомендую время обновления итема ставить поменьше, чтобы оперативно получить информацию об инциденте. У меня стоит 30 секунд.
После того, как вы сохраните новый итем, через несколько минут начнут поступать данные. Проверять их как обычно в Latest data. В данной конфигурации будут сохраняться все строки из файла. В моем случае это не страшно, так как записей будет очень мало. Они создаются только по событиям в электро сети, а они случаются редко, поэтому я не стал делать фильтр по строкам или словам.
Но это только пол дела. Мы стали собирать логи, теперь нам нужно настроить отправку оповещения при пропадании электричества.
Создание триггера на событие из лога
Мы будем слать оповещение не только в момент отключения электричества, но и тогда, когда оно снова появится. Так что в триггере будут два условия:
- Условие активации события.
- И условие его прекращения.
Открываем вкладку с триггерами хоста и добавляем туда новый триггер со следующими параметрами:
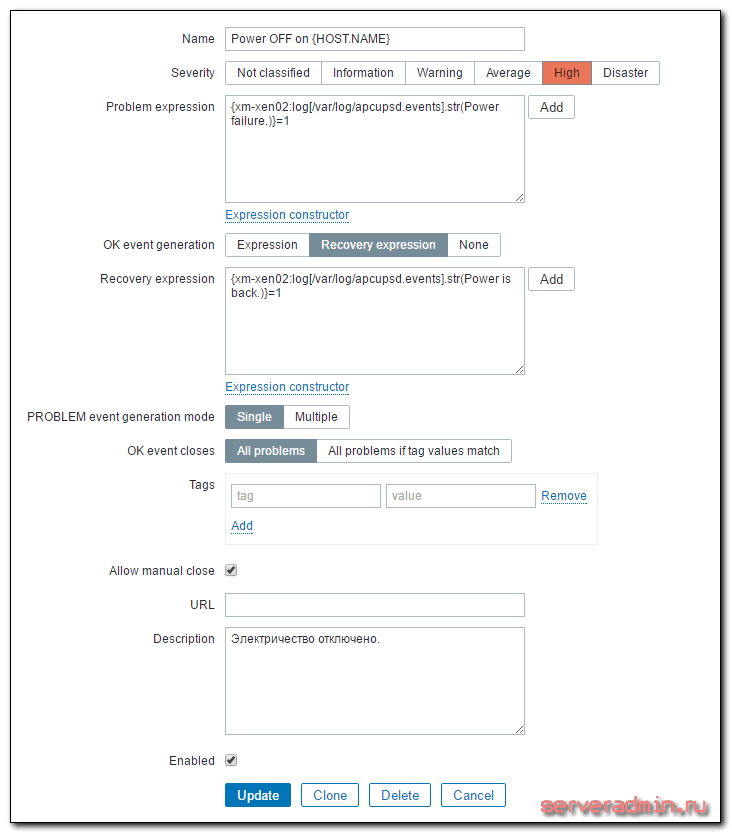
| Name | Имя триггера. Может быть любым. |
| Problem expression | |
| Recovery expression |
Рассказываю подробнее, что тут написано. xm-xen02 — имя сервера. Power failure. — строка в лог файле, которая появляется при отключении электричества. Когда оно возвращается, появляется запись Power is back. В общем виде лог выглядит примерно следующим образом:
Становится понятно, почему я взял именно эти строки. На этом все. После сохранения триггера он начнет работать и следить за итемом, который собирает строки из лога. Как только появятся строки, попадающие под условие, вы получите оповещение.
Заключение
Отладить работу оповещения об отключении электричества достаточно трудно, так как дергать по этому поводу шнур с питанием не хочется. Я пошел другим путем. Во время отладки использовал общий лог файл /var/log/messages и останавливал службу chronyd. Во время остановки, она пишет информацию об этом в лог файл, а при запуске так же сообщает, что запустилась. Я просто настроил итем и триггер на нужные строки и убедился, что все работает как надо. После этого уже сделал по аналогии итемы и триггеры для apcupsd. Рекомендую поступить похожим образом и потестировать функционал.
Мониторинг событий информационной безопасности с помощью ZABBIX

Некоторое время поработав с Zabbix, я подумал, почему бы не попробовать использовать его в качестве решения для мониторинга событий информационной безопасности. Как известно, в ИТ инфраструктуре предприятия множество самых разных систем, генерирующих такой поток событий информационной безопасности, что просмотреть их все просто невозможно. Сейчас в нашей корпоративной системе мониторинга сотни сервисов, которые мы наблюдаем с большой степенью детализации. В данной статье, я рассматриваю особенности использования Zabbix в качестве решения по мониторингу событий ИБ.
Что же позволяет Zabbix для решения нашей задачи? Примерно следующее:
- Максимальная автоматизация процессов инвентаризации ресурсов, управления уязвимостями, контроля соответствия политикам безопасности и изменений.
- Постоянная защита корпоративных ресурсов с помощью автоматического мониторинга информационной безопасности.
- Возможность получать максимально достоверную картину защищенности сети.
- Анализ широкого спектра сложных систем: сетевое оборудование, такое как Cisco, Juniper, платформы Windows, Linux, Unix, СУБД MSQL, Oracle, MySQL и т.д., сетевые приложения и веб-службы.
- Минимизация затрат на аудит и контроль защищенности.
В статье я не буду рассматривать всё выше перечисленное, затронем только наиболее распространённые и простые вопросы.
Подготовка
Итак, для начала я установил сервер мониторинга Zabbix. В качестве платформы мы будем использовать ОС FreeBSD. Думаю, что рассказывать в деталях о процессе установки и настройки нет необходимости, довольно подробная документация на русском языке есть на сайте разработчика, начиная от процесса установки до описания всех возможностей системы.
Мы будем считать что сервер установлен, настроен, а так же настроен web-frontend для работы с ним. На момент написания статьи система работает под управлением ОС FreeBSD 9.1, Zabbix 2.2.1.
Мониторинг событий безопасности MS Windows Server
С помощью системы мониторинга Zabbix можно собирать любую имеющуюся информацию из системных журналов Windows с произвольной степенью детализации. Это означает, что если Windows записывает какое-либо событие в журнал, Zabbix «видит» его, например по Event ID, текстовой, либо бинарной маске. Кроме того, используя Zabbix, мы можем видеть и собирать колоссальное количество интересных для мониторинга безопасности событий, например: запущенные процессы, открытые соединения, загруженные в ядро драйверы, используемые dll, залогиненных через консоль или удалённый доступ пользователей и многое другое.
Всё, что остаётся – определить события возникающие при реализации ожидаемых нами угроз.
Устанавливая решение по мониторингу событий ИБ в ИТ инфраструктуре следует учитывать необходимость выбора баланса между желанием отслеживать всё подряд, и возможностями по обработке огромного количества информации по событиям ИБ. Здесь Zabbix открывает большие возможности для выбора. Ключевые модули Zabbix написаны на C/C++, скорость записи из сети и обработки отслеживаемых событий составляет 10 тысяч новых значений в секунду на более менее обычном сервере с правильно настроенной СУБД.
Всё это даёт нам возможность отслеживать наиболее важные события безопасности на наблюдаемом узле сети под управлением ОС Windows.
Итак, для начала рассмотрим таблицу с Event ID, которые, на мой взгляд, очевидно, можно использовать для мониторинга событий ИБ:
События ИБ MS Windows Server Security Log
| Описание EventID | 2008 Server | 2003 Server |
| Очистка журнала аудита | 1102 | 517 |
| Вход с учётной записью выполнен успешно | 4624 | 528, 540 |
| Учётной записи не удалось выполнить вход в систему | 4625 | 529-535, 539 |
| Создана учётная запись пользователя | 4720 | 624 |
| Попытка сбросить пароль учётной записи | 4724 | 628 |
| Отключена учётная запись пользователя | 4725 | 629 |
| Удалена учётная запись пользователя | 4726 | 630 |
| Создана защищённая локальная группа безопасности | 4731 | 635 |
| Добавлен участник в защищённую локальную группу | 4732 | 636 |
| Удален участник из защищённой локальной группы | 4733 | 637 |
| Удалена защищённая локальная группа безопасности | 4734 | 638 |
| Изменена защищённая локальная группа безопасности | 4735 | 639 |
| Изменена учётная запись пользователя | 4738 | 642 |
| Заблокирована учётная запись пользователя | 4740 | 644 |
| Имя учётной записи было изменено | 4781 | 685 |
Я уделяю внимание локальным группам безопасности, но в более сложных схемах AD необходимо учитывать так же общие и глобальные группы.
Дабы не дублировать информацию, подробнее о критически важных событиях можно почитать в статье:
http://habrahabr.ru/company/netwrix/blog/148501/
Способы мониторинга событий ИБ MS Windows Server
Рассмотрим практическое применение данной задачи.
Для сбора данных необходимо создать новый элемент данных:
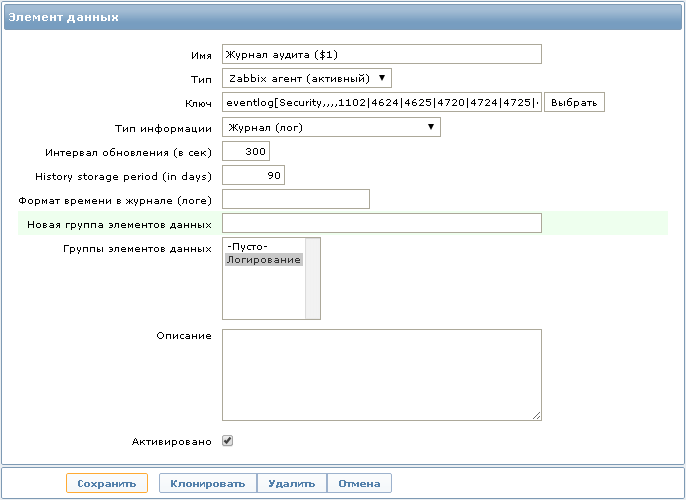
При желании для каждого Event ID можно создать по отдельному элементу данных, но я использую в одном ключе сразу несколько Event ID, чтобы хранить все полученные записи в одном месте, что позволяет быстрее производить поиск необходимой информации, не переключаясь между разными элементами данных.
Хочу заметить что в данном ключе в качестве имени мы используем журнал событий Security.
Теперь, когда элемент данных мы получили, следует настроить триггер. Триггер – это механизм Zabbix, позволяющий сигнализировать о том, что наступило какое-либо из отслеживаемых событий. В нашем случае – это событие из журнала сервера или рабочей станции MS Windows.
Теперь все что будет фиксировать журнал аудита с указанными Event ID будет передано на сервер мониторинга. Указание конкретных Event ID полезно тем, что мы получаем только необходимую информацию, и ничего лишнего.
Вот одно из выражений триггера:
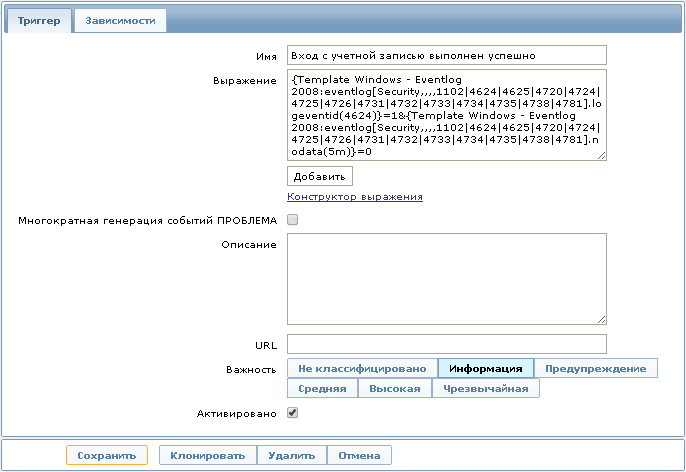
Данное выражение позволит отображать на Dashboard информацию о том что «Вход с учётной записью выполнен успешно», что соответствует Event ID 4624 для MS Windows Server 2008. Событие исчезнет спустя 5 минут, если в течение этого времени не был произведен повторный вход.
Если же необходимо отслеживать определенного пользователя, например “Администратор”, можно добавить к выражению триггера проверку по regexp:
Тогда триггер сработает только в том случае если будет осуществлён вход в систему именно под учетной записью с именем “Администратор”.
Мы рассматривали простейший пример, но так же можно использовать более сложные конструкции. Например с использованием типов входа в систему, кодов ошибок, регулярных выражений и других параметров.
Таким образом тонны сообщений, генерируемых системами Windows будет проверять Zabbix, а не наши глаза. Нам остаётся только смотреть на панель Zabbix Dashboard.
Дополнительно, у меня настроена отправка уведомлений на e-mail. Это позволяет оперативно реагировать на события, и не пропустить события произошедшие например в нерабочее время.
Мониторинг событий безопасности Unix систем
Система мониторинга Zabbix так же позволяет собирать информацию из лог-файлов ОС семейства Unix.
События ИБ в Unix системах, подходящие для всех
Такими проблемами безопасности систем семейства Unix являются всё те же попытки подбора паролей к учётным записям, а так же поиск уязвимостей в средствах аутентификации, например, таких как SSH, FTP и прочих.
Некоторые критически важные события в Unix системах
Исходя из вышеуказанного следует, что нам необходимо отслеживать действия, связанные с добавлением, изменением и удалением учётных записей пользователей в системе.
Так же немаловажным фактом будет отслеживание попыток входа в систему. Изменения ключевых файлов типа sudoers, passwd, etc/rc.conf, содержимое каталогов /usr/local/etc/rc.d наличие запущенных процессов и т.п.
Способы мониторинга ИБ в Unix системах
Рассмотрим следующий пример. Нужно отслеживать входы в систему, неудачные попытки входа, попытки подбора паролей в системе FreeBSD по протоколу SSH.
Вся информация об этом, содержится в лог-файле /var/log/auth.log.
По умолчанию права на данный файл — 600, и его можно просматривать только с привилегиями root. Придется немного пожертвовать локальной политикой безопасности, и разрешить читать данный файл группе пользователей zabbix:
Меняем права на файл:
Нам понадобится новый элемент данных со следующим ключом:
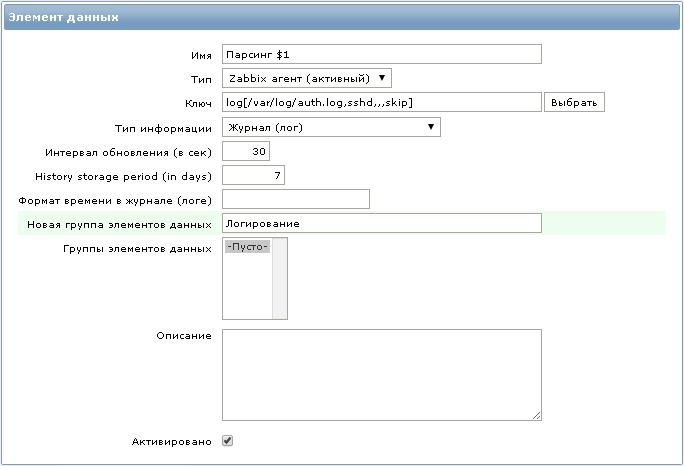
Все строки в файле /var/log/auth.log содержащие слово ”sshd” будут переданы агентом на сервер мониторинга.
Далее можно настроить триггер со следующим выражением:
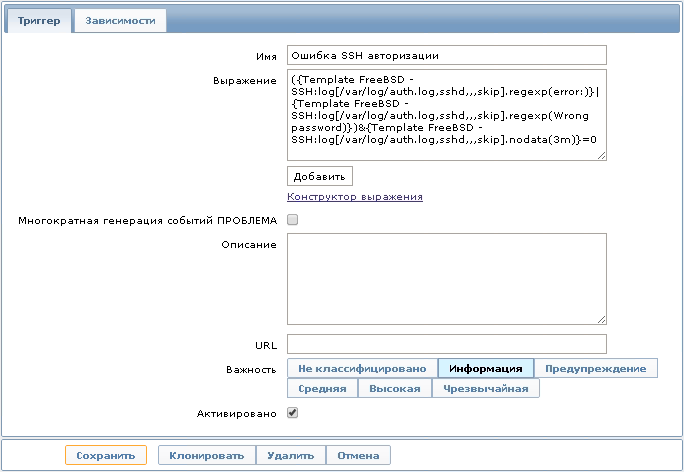
Это выражение определяется как проблема, когда в лог-файле появляются записи, отобранные по регулярному выражению “error:”. Открыв историю полученных данных, мы увидим ошибки, которые возникали при авторизации по протоколу SSH.
Вот пример последнего значения элемента данных, по которому срабатывает данный триггер:

Рассмотрим ещё один пример мониторинга безопасности в ОС FreeBSD:
С помощью агента Zabbix мы можем осуществлять проверку контрольной суммы файла /etc/passwd.
Ключ в данном случае будет следующий:
Это позволяет контролировать изменения учётных записей, включая смену пароля, добавление или удаление пользователей. В данном случае мы не узнаем, какая конкретная операция была произведена, но если к серверу кроме Вас доступ никто не имеет, то это повод для быстрого реагирования. Если необходимо более детально вести политику то можно использовать другие ключи, например пользовательские параметры.
Например, если мы хотим получать список пользователей, которые на данный момент заведены в системе, можно использовать такой пользовательский параметр:
И, например, настроить триггер на изменение в получаемом списке.
Или же можно использовать такой простой параметр:
Так мы увидим на Dashboard, кто на данный момент находится в системе:
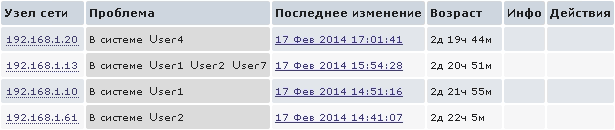
Мониторинг событий ИБ на сетевых устройствах
С помощью Zabbix можно так же очень эффективно отслеживать события ИБ на сетевых устройствах Cisco и Juniper, используя протокол SNMP. Передача данных с устройств осуществляется с помощью так называемых трапов (SNMP Trap).
С точки зрения ИБ можно выделить следующие события, которые необходимо отслеживать — изменения конфигураций оборудования, выполнение команд на коммутаторе/маршрутизаторе, успешную авторизацию, неудачные попытки входа и многое другое.
Способы мониторинга
Рассмотрим опять же пример с авторизацией:
В качестве стенда я буду использовать эмулятор GNS3 с маршрутизатором Cisco 3745. Думаю многим знакома данная схема.
Для начала нам необходимо настроить отправку SNMP трапов с маршрутизатора на сервер мониторинга. В моём случае это будет выглядеть так:
Будем отправлять события из Syslog и трапы аутентификации. Замечу, что удачные и неудачные попытки авторизации пишутся именно в Syslog.
Далее необходимо настроить прием нужных нам SNMP трапов на сервере мониторинга.
Добавляем следующие строки в snmptt.conf:
В нашем примере будем ловить трапы Syslog.
Теперь необходимо настроить элемент данных для сбора статистики со следующим ключом:
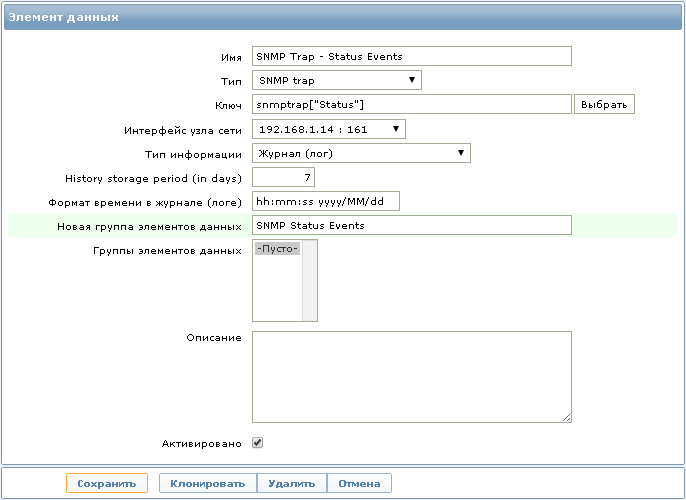
Если трап не настроен на сервере мониторинга, то в логе сервера будут примерно такие записи:
В результате в полученном логе будет отражаться информация о попытках входа с детализированной информацией (user, source, localport и reason в случае неудачи):

Ну и можно настроить триггер для отображения события на Dashboard:
В сочетании с предыдущим пунктом у нас на Dashboard будет информация вот такого плана:
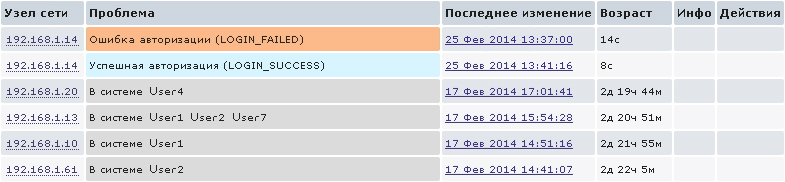
Аналогично вышеописанному примеру можно осуществлять мониторинг большого количества событий, происходящих на маршрутизаторах Cisco, для описания которых одной статьей явно не обойтись.
Хочу заметить что приведённый пример не будет работать на продуктах Cisco ASA и PIX, так как там несколько иначе организована работа с логированием авторизации.
Juniper и Syslog
Ещё одним примером мы разберем мониторинг авторизации в JunOS 12.1 для устройств Juniper.
Тут мы не сможем воспользоваться трапами SNMP, потому как нет поддержки отправки трапов из Syslog сообщений. Нам понадобится Syslog сервер на базе Unix, в нашем случае им будет тот же сервер мониторинга.
На маршрутизаторе нам необходимо настроить отправку Syslog на сервер хранения:
Теперь все сообщения об авторизации будут отправляться на Syslog сервер, можно конечно отправлять все сообщения (any any), но переизбыток информации нам не нужен, отправляем только необходимое.
Далее переходим к Syslog серверу
Смотрим tcpdump, приходят ли сообщения:
По умолчанию в настройках syslog.conf все что приходит с auth.info должно записываться в /var/log/auth.log. Далее делаем все аналогично примеру с мониторингом входов в Unix.
Вот пример строки из лога:

Остается только настроить триггер на данное событие так же как это было рассмотрено в примере с авторизацией на Unix сервере.
Таким способом можно отслеживать множество событий, среди которых такие как: сохранение конфигурации устройства (commit), вход и выход из режима редактирования конфигурации (edit).
Так же хочу заметить, что аналогичным способом можно осуществлять мониторинг и на устройствах Cisco, но способ с SNMP трапами мне кажется более быстрым и удобным, и исключается необходимость в промежуточном Syslog сервере.



