- Zabbix + Iostat: мониторинг дисковой подсистемы
- Мониторинг производительности дисковой подсистемы при помощи zabbix и block stat
- Небольшое отступление
- Мониторинг дисков в zabbix
- Утилизация дисковой подсистемы
- Время обработки запроса
- Пропускная способность
- Количество операций ввода-вывода в секунду
- Заключение
- Zabbix мониторинг hdd linux
Zabbix + Iostat: мониторинг дисковой подсистемы
Zabbix + Iostat: мониторинг дисковой подсистемы. 
Зачем?
Дисковая подсистема одна из важных подсистем сервера и от уровня нагрузки на дисковую подсистему зачастую зависит очень многое, например скорость отдачи контента или то как быстро будет отвечать база данных. Это в большей степени относится к почтовым или файловым серверам, серверам БД. Вобщем, показатели дисковой производительности отслеживать нужно. На основании графиков производительности дисковой подсистемы мы можем принять решение о необходимости наращивания мощностей задолго до того как петух клюнет. Да и вобще полезно поглядывать от релиза к релизу как работа разработчиков сказывается на уровне нагрузки.
Под катом, о мониторинге и о том как настроить.
Зависимости:
Мониторинг реализован через zabbix агента и две утилиты: awk и iostat (пакет sysstat). Если awk идет в дистрибутивах по умолчанию, то iostat требуется установить с пакетом sysstat (тут отдельное спасибо Sebastien Godard и сотоварищи).
Известные ограничения:
Для мониторинга нужен sysstat начиная с версии 9.1.2, т.к. там есть очень важное изменение: «Added r_await and w_await fields to iostat’s extended statistics». Так что следует быть внимательным, в некоторых дистрибутивах, например в CentOS немного «стабильная» и менее фичастая версия sysstat.
Если же отталкиваться от версии zabbix (2.0 или 2.2) то тут вопрос не принципиален, работает на обоих версиях. На 1.8 не заработает т.к. используется Low level discovery.
Возможности (чисто субъективно, по мере убывания полезности):
- Low level discovery (далее просто LLD) для автоматического обнаружения блочных устройств на наблюдаемом узле;
- утилизация блочного устройства в % — удобная метрика для отслеживания общей нагрузки на устройстве;
- latency или отзывчивость — доступна как общая отзывчивость, так и отзывчивость на операциях чтения/записи;
- величина очереди (в запросах) и средний размер запроса (в секторах) — позволяет оценить характер нагрузки и степень загруженности устройства;
- текущая скорость чтения/записи на устройство в человекопонятных килобайтах;
- количество запросов чтения/записи (в секунду) объединенных при постановке в очередь на выполнение;
- iops — величина операций чтения/записи в секунду;
- усредненное время обслуживания запросов (svctm). Вообще она deprecated, разработчики обещают ее давно спилить, но все никак руки не доходят.
Вобщем как видно, здесь доступны все те метрики которые есть в iostat (кто незнаком с этой утилитой настоятельно рекомендую заглянуть в man iostat).
Доступные графики:
Графики рисуются per-device, LLD обнаруживает устройства которые попадают под регулярное выражение «(xvd|sd|hd|vd)[a-z]», так что если ваши диски имеют другие имена, можно легко внести соответствующие изменения. Такая регулярка сделана чтобы обнаруживать устройства которые будут родительскими по отношению к прочим разделам, LVM томам, MDRAID массивам и т.п. Вобщем чтобы не собирать лишнего. Немного отвлеклись, итак список графиков:
- Disk await — отзывчивость устройства (r_await, w_await);
- Disk merges — операции слияния в очереди (rrqm/s, wrqm/s);
- Disk queue — состояние очереди (avgrq-sz, avgqu-sz);
- Disk read and write — текущие значения чтения/записи на устройство (rkB/s, wkB/s);
- Disk utilization — утилизация диска и значение IOPS (%util, r/s, w/s) — позволяет неплохо отслеживать скачки в утилизации и чем, чтением или записью они были вызваны.
Аналоги и отличия:
В заббиксе есть коробочные варианты для похожего мониторинга, это ключи vfs.dev.read и vfs.dev.write. Они хороши и прекрасно работают, но менее информативны чем iostat. Например в iostat есть такие метрики как latency и utilization.
Также есть аналогичный шаблон от Michael Noman на мой взгляд отличие только одно, она заточена на старые версии iostat, ну и + небольшие синтаксические изменения.
Где взять:
Итак, мониторинг состоит из файла конфигурации для агента, двух скриптов для сбора/получения данных и шаблон для веб-интерфейса. Все это доступно в репозитории на Github, поэтому любым доступным способом (git clone, wget, curl, etc. ) скачиваем их на машины которые хотим замониторить и переходим к следующему пункту.
Как настроить:
- iostat.conf — содержимое этого файла следует поместить в файл конфигурации zabbix агента, либо положить в каталог конфигурации который указан в Include опции основной конфигурации агента. Вобщем зависит от политики партии. Я использую второй вариант, для кастомных конфигов у меня отдельная директория.
- scripts/iostat-collect.sh и scripts/iostat-parse.sh — эта два рабочих скрипта следует скопировать в /usr/libexec/zabbix-extensions/scripts/. Тут также можно использовать удобное вам размещение, однако в таком случае не забудьте поправить пути в параметрах определенных в iostat.conf. Не забудьте проверить что они исполняемы (mode=755).
Теперь все готово, запускаем агента и переходим на сервер мониторинга и выполняем команду (не забываем подменить agent_ip):
Таким образом, проверяем с сервера мониторинга что iostat.conf подгрузился и отдает информацию, заодно смотрим что LLD работает. В качестве ответа вернется JSON с именами обнаруженных устройств. Если ответа не пришло, значит что-то сделали не так.
Также есть такой момент, что zabbix server не дожидается выполнения некоторых item’ов со стороны агентов (iostat.collect). Для этого следует увеличить значения Timeout.
Как настроить в web интейрфейс:
Теперь остался шаблон iostat-disk-utilization-template.xml. Через веб интерфейс импортируем его в раздел шаблонов и назначем на наш хост. Тут все просто. Теперь остается ждать примерно один час, такое время установлено в LLD правиле (тоже настраивается). Или можно поглядывать в Latest Data наблюдаемого хоста, в раздел Iostat. Как только там появились значения, можно перейти в раздел графиков и понаблюдать за первыми данными.
И напоследок тройка скринов графиков c локалхоста))):
Непосредственно данные в Latest Data: 
Графики отзывчивости (Latency):
График утилизации и IOPS:
Вот и собственно и все, спасибо за внимание.
Ну и по традиции, пользуясь случаем передаю привет Федорову Сергею (Алексеевичу) 🙂
Источник
Мониторинг производительности дисковой подсистемы при помощи zabbix и block stat
Вряд ли кто-то будет спорить, что наблюдение за производительностью дисковой подсистемы — чуть ли не важнейшая задача для всех высоконагруженных систем хранения и баз данных. Я изначально столкнулся с этим давным-давно, еще когда приходилось наблюдать за PostgreSQL. В последнее время вернулся к этому вопросу в связи с необходимостью тестирования различных хранилищ.
Сегодня хочу поделиться с сообществом своим текущим опытом на реальном примере zabbix и его связке с block stat.
Небольшое отступление
Я являюсь архитектором баз данных и систем хранения очень высокой производительности и больших объемов. Поэтому часто сталкиваюсь с задачами оценки, как те или иные параметры настройки системы влияют на работу СХД, какие железные конфигурации СХД лучше.
Да есть куча утилит, которая позволит протестировать диски, например тот же fio. Но ничто не сравнится с тестированием реальной нагрузкой.
Однако прежде чем подавать реальную и настоящую нагрузку, неплохо бы сначала протестировать на синтетике. А наблюдать за синтетикой лучше теми же средствами, что и за боевой системой, просто потому, что даже если ваши метрики не совсем верны методологически – они будут хотя бы те же самые и по ним можно будет делать выводы лучше/хуже.
Когда то давным-давно для этих целей использовал iostat, лютый парсер к нему и gnuplot, и даже написал статейку habr.com/post/165855. Скажу я вам – это жутко неудобно.
Куда как удобнее натравить на систему zabbix и мониторить. А к zabbix можно прикрутить модную Grafana и мониторить красиво. Сразу скажу – выбор zabbix скорее исторический: «потому что он уже был».
Мониторинг дисков в zabbix
Справедливости ради скажу, что в zabbix уже есть встроенные ключи vfs.dev.*, но увы очень мало: скорость чтения и записи, объем.
А что нужно нам?
Практика показывает что ключевые метрики по которым можно оценивать дисковую подсистему это:
- Количество операций в секунду (ops)
- Пропускная способность (throughput)
- Время обработки запроса (latency или правильней svctime)
- Утилизация дисковой подсистемы (utilization)
Так как эти метрики очень зависят друг от друга, то не зная все нельзя сделать правильные выводы.
Все эти метрики есть в iostat. Но как их положить в zabbix?
Легкое гугление приводит нас к различным парсерам iostat, в том числе и здесь.
Но мне по душе другой вариант, а именно парсинг вывода /sys/class/block/*/stat
- это первоисточник данных — iostat так же использует эти данные
- для разбора показателей можно ограничиться только однострочником в UserParameter без дополнительных скриптов.
Но есть и недостатки:
- Некоторые параметры необходимо вычислять делением дельты одного на дельту другого, причем не простой, а временной (скорости). В zabbix это сделать можно, но это будут не одновременные запросы, как если бы это делал сложный скрипт, а отношение последних значений, что в принципе не совсем верно, но в нашем случае довольно точно.
Итак, кроме самого zabbix и zabbix-agent на наблюдаемой машине нам потребуется awk. Мы используем дистрибутив CentOS 7.4 и zabbix 3.4
Данные в zabbix мы будем собирать при помощи zabbix-agent, создав пользовательские ключи. Для этого в /etc/zabbix/zabbix_agentd.d нужно создать файлик userparameter_custom.vfs.conf примерно со следующим содержимым:
UserParameter=custom.vfs.dev.io.ms[*],cat /sys/class/block/$1/stat | awk ‘
Тут все просто — создаем пользовательский ключ custom.vfs.dev.io.ms, в качестве параметра передаем туда имя блочного устройства, значением параметра будет 10 колонка файлика stat.
В этом файлике статистики всего 11 колонок, посмотреть их описание можно вот тут.
Колонка №10 это io_tics — количество миллисекунд затраченным устройством на ввод вывод. Как почти все параметры — эта цифра является аккумулятором и постоянно возрастает. Как же получить из них привычные метрики.
Утилизация дисковой подсистемы
Эта метрика аналогична значению поля utils команды iostat -x. Характеризует загрузку дисковой подсистемы. По сути это сколько процентов реального времени система затратила на операции ввода-вывода за интервал между опросами. Как правило при приближении к 100% система начинает все больше простаивать в ожидании когда диски обработают ваши запросы.
Чтобы получить эту цифру — надо взять значение 10 колонки файла статистики и запомнить его в zabbix как скорость изменения в секунду, не забыв умножить на 0.1 так как значение в статистике в миллисекундах, а нам нужны проценты.
Аналогичным образом можно посчитать нагрузку записью/чтением (колонки write_ticks / read_ticks).
Время обработки запроса
Эта метрика аналогична r_svctime и w_svctime для записи и чтения соответственно. По сути это усредненное время обработки запросов за интервал между опросами.
Данная метрика чуть посложнее. Рассмотрим на примере запросов на запись.
Для этого нам понадобится создать три ключа:
- write utils — количество времени потраченное на запись — колонка №8 write_ticks сохраненная, как скорость изменения в секунду между опросами. По сути значение ключа в zabbix будет утилизация записью.
Абсолютно также считается время обработки запросов на чтение, только используя колонки №1 read I/Os и №4 read_ticks.
Пропускная способность
Метрика показывающая с какой скоростью данные были записаны или прочитаны
Для этой метрики используются колонки №3 read sectors и №5 write sectors. Значение сколько было прочитано или записано «секторов». Точно так же в zabbix сохраняем как изменение за секунду.
Единственный ньюанс — значение в файле указанно «в попугаях-секторах», причем размер этого «сектора» фиксирован 512 байт и не зависит от реальных значений ни физического ни логического сектора устройства (проверял на нескольких устройствах с реальным размером физического сектора 4к). Так что чтобы пересчитать в байты — не забудьте умножить на 512.
Количество операций ввода-вывода в секунду
Эта метрика — те самые пресловутые IOPS
Самая простая метрика — мы ее уже записывали для подсчета svc time это значение колонок №5 write I/Os и №1 read I/Os также сохраненные как скорость в секунду.
Заключение
Этих метрик мне как правило достаточно для того чтобы я мог делать обоснованные выводы. Конечно это не все цифры которые можно получить из файла статистики. Например там есть и число текущих обрабатываемых запросов, и количество запросов которые были объеденены. Но полагаю при необходимости вам не составит труда добавить их по аналогии с описанным.
И да не претендую на авторство — сам метод был когда-то давно загуглен, но за давностью лет ссылки конечно затерялись.
Увы NDA заставляет кое-что подчистить из них, но надеюсь на работоспособность шаблона это не повлияет.
А в шапке скриншот из Grafana прикрученной поверх zabbix — демонстрирующий реальные цифры с одной из тестовых инсталляций.
Источник
Zabbix мониторинг hdd linux
So, мониторинг параметров SMART жёстких дисков на Zabbix для машин на Linux. Для машин на windows в этой зарисовке.
Для этого, на компьютере который мы будем мониторить, должен быть установлен Zabbix-agent и набор для работы со SMART параметрами жёсткого диска. Как установить zabbix-agent можно посмотреть в в этой статье или найти материалы интернете. Установка ПО для работы со SMART.
Переходим к редактированию конфигурации zabbix-agent. В конце файла конфигурации нужно добавить несколько сток:
Как можно понять это запуск того самого smartctl, который мы установили в самом начале. Работоспосбность проверяем на сервере Zabbix:
Если работает, то в ответ получаем числовое значение. Если ответ пусто или другого рода ошибка, вероятнее всего не хватает прав на выполнение команд zabbix-агентом. Для этого идём в sudoers и разрешаем выполнение smartctl без пароля root. Добавляем в конец файла:
Далее переходим к настройке Zabbix через web-интерфейс.
Идём в Настройка — Шаблоны — Template OS Linux — Группы элементов данных . Создаём группу элементов данных, на пример SMART. После создания группы заходим в раздел Элементы данных . И тут мы создаём элементы, необходимые для мониторинга.
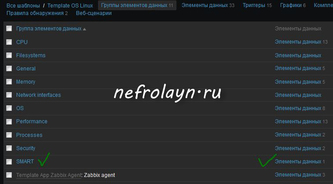
Список всех доступных параметров можно посмотреть, выполнив
Я добавил только те параметры, которые говорят о здоровье диска. Получиться должно что-то вроде:
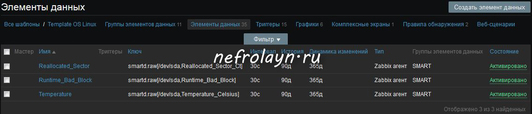
Самое время создать графики. В том же разделе заходим по ссылке Графики и создаём график с именем, на пример SMART.
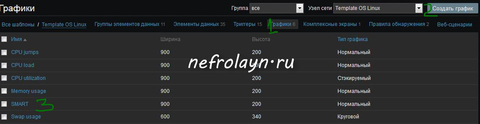
После создания заходим в этот график на добавляем наши элементы данных. Должно получиться что-то вроде этого:
Источник



