- Мониторинг Microsoft Windows на базе Zabbix
- Общая концепция
- Основные возможности
- Triggers
- Инвентаризация
- Графики
- Где скачать
- Мониторинг программы (процесса) Windows в Zabbix
- Мониторинг процесса Windows с помощью Zabbix?
- Мониторинг списка запущенных процессов в Zabbix
- Введение
- Подготовка сервера к мониторингу процессов
- Настройка мониторинга за процессами
- Проверка отправки списка процессов
- Заключение
Мониторинг Microsoft Windows на базе Zabbix
03.09.2019 Update
Кстати новые шаблоны уже доступны
Сегодня мы расскажем о том, как мы ведем мониторинг Windows систем (в скором времени планируем такой же обзор про Linux и как обычно с доступным шаблоном).
Наш путь начался, как часто бывает, со штатного шаблона Zabbix «Template OS Windows Active» для мониторинга Windows-клиентов (рабочие станции и сервера), но ровно через неделю активного использования поняли, в нем много чего не хватает.
Так мы и начали его кардинальную переделку, часть оставили и добавили много чего нового.
Общая концепция
1. Отдельные настройки шаблона в файле os_windows_active.conf
2. Отдельный скрипт PowerShell — os_windows_active.ps1 для работы шаблона, при этом скрипт должен быть универсальным и работать на большинстве операционных систем с минимумом внешних зависимостей.
3. Шаблон должен быть не зависимым от языка операционной системы, поэтому лучше всего снимать данные со счётчиков используя либо WMI, либо скрипт + zabbix trapper.
4. Шаблон должен давать максимум полезной информации по своему назначению, поэтому он объединяется как мониторинг физических параметров оборудования, так и операционной системы и даже инвентаризации.
Основные возможности
- логических дисков;
- физических дисков;
- сетевых адаптеров;
- системных сервисов.
Triggers
Мы включили и оттестировали, только самые критичные триггеры, которые реально показывают проблемы. Но добавили и некоторых других, для более детальной информации.
- Продолжительная нагрузка на процессор в течении часа.
Physical Memory
- Объём доступной физической памяти меньше заданного лимита;
- Объём Commited памяти больше физической.
Physical disk
- Скорость доступа к дискам на чтение и запись.
Logical disk
- Критический объём дисков с возможностью прогноза на 12 часов.
Network
- Смена MAC-адреса сетевого адаптера (для виртуальных машин очень актуально, если не поставили статический MAC-адрес);
- Отключение Link-а сетевого адаптера;
- Отброшенные пакеты на сетевом адаптере.
Operation system
- Дата последней установки обновлений Windows
- Изменение статуса Firewall
Инвентаризация
Так как клиенты имеют разные компьютеры, нам требуется получать краткую инвентаризацию по ним, поэтому мы добавили в шаблон сбор данных о компьютере, и этими данными заполняем стандартные поля Zabbix Inventory:
- OS
- tag
- Chassis
- Desktop
- Model
- HW architecture
- Vendor
- Host networks
Графики
Мы сделали несколько полезных общих графиков, чтобы наглядно видеть общее состояние клиента и отдельных его подсистем.



OS overview performance

OS detail performance
Где скачать
Данный шаблон и скрипт вы можете бесплатно скачать с GitHub, а также в Zabbix Share.
Наши шаблоны мы продолжим выкладываем в открытый доступ в наш репозитарий Zabbix.
Системное администрирование серверов и DevOps
Мониторинг программы (процесса) Windows в Zabbix

При очередной чистке записей, вышло так что забыл запустить программу назад в боевое состояние. Обнаружил только на следующий день, все бы ничего, но оплошность привела к анализу возможностей zabbix на предмет мониторинга состояния процесса программы. Оказалось в этом может помочь proc.num.
Так как у меня язык стоит русский в zabbix, прдполагаю что в 90% это будет у всех, поэтому следуем следующим маршрутом: Узлы сети — Выбираем свой узел сети (тот сервер на котором необходимо производить мониторинг процесса) — Элементы данных
Создаем новый элемент данных
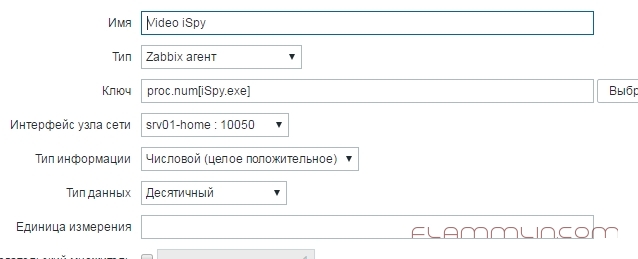
Ключ для нового элемента данных: proc.num[iSpy.exe] В скобках указан требуемый процесс мониторинга, в моем случае программа iSpy.exe. После настройки незабываем нажимать Добавить.
Дальше переходим в раздел триггеров и так же создаем новый триггер
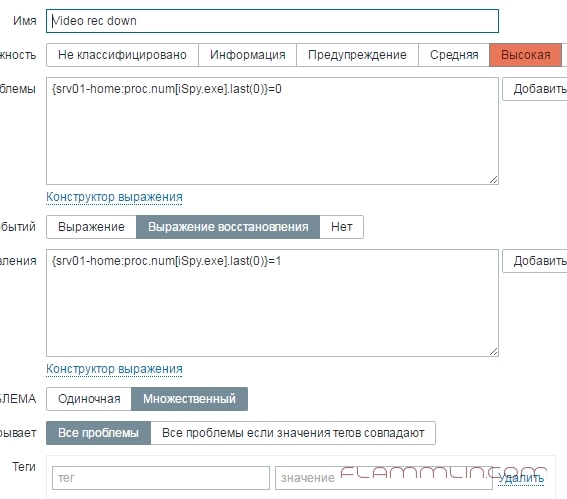
Соответственно, если процесс показал состояние 0 (значит программа закрыта и будет прислано уведомление), при значении 1 программа активна или произведен ее запуск.
В итоге если все правильно повторили за мной, то получите вот такую картинку при случае не запущенного приложения:
Мониторинг процесса Windows с помощью Zabbix?
Как организовать мониторинг процессов windows c помощью zabbix? Интересует способ узнать сколько процентов от общего ресурса процессора потребляет тот или иной процесс.
Версия Windows: Windows 10 pro 1909 x64
Версия zabbix сервера: 4.4.3
Способ снятия метрик: активный агент
- Вопрос задан более года назад
- 1210 просмотров
1.открываем perfmon.msc (не перепутайте с perfmon.exe — это немного другая программа.)
2.в «системном мониторе» (сейчас под рукой руссифицированная ось, поэтому ищите аналогичное на английском, благо монитор по умолчанию там один) нажимаем «добавить счетчики»
3. выбираем Process и ваш процесс, нужные метрики.
Все это только для понимания «что» вы будете мониторить.
теперь «как»: идем и внимательно читаем:
https://www.zabbix.com/documentation/4.2/ru/manual.
https://www.zabbix.com/documentation/4.2/ru/manual.
В последней статье ищем proc_info — это оно и есть
Если есть какие то перфкаунтеры которых вы не нашли в заббикс — в 1й статье в конце есть как добавить нужные через user parameters
Почему perfcounters а не WMI? Потому что обращение к WMI — довольно дорогая операция, часто не позапрашиваешь (а если залезть в глубины того что доступно через WMI — выяснится что там те же перфкаунтеры, облагороженные и обогащенные) — частое обращение довольно сильно жрет CPU
Почему не сторонняя программа? Потому что Win уже собирает данные процессов и основная задача — добраться до них
Мониторинг списка запущенных процессов в Zabbix

В стандартных шаблонах Zabbix есть триггеры на загрузку процессора, а так же на превышение максимально допустимого числа процессов. Триггеры эти практически бесполезны, если у вас плавающая нагрузка. Допустим, вы получаете уведомление о том, что у вас сильно нагружен процессор. Через 10 минут нагрузка прошла, а вы не успели зайти на сервер и посмотреть, чем он был нагружен в это время. Вот эту проблему я и решаю своим велосипедом, которым делюсь в статье.
Введение
Рассказываю подробно, что я хочу получить в конце статьи. В стандартном шаблоне Zabbix для Linux есть несколько триггеров. Они могут немного отличаться в названиях, в зависимости от версии шаблона, но смысл один и тот же:
- High CPU utilization
- Load average is too high
- Too many processes on hostname
Я хочу получить информацию о запущенных процессах на хосте в момент срабатывания триггера. Это позволит мне спокойно посмотреть, что создает нагрузку, когда у меня будет возможность. Мне не придется идти руками в консоль хоста и пытаться ловить момент, когда опять появится нагрузка.
В дефолтной конфигурации у Zabbix нет готовых инструментов, чтобы реализовать желаемое. Вы можете настроить мониторинг процесса или группы процессов в Zabbix. Но это не то, что нужно. Можно настроить автообнаружение всех процессов и мониторить их. Чаще всего это тоже не нужно, а подобный мониторинг будет генерировать большую нагрузку и сохранять кучу данных в базу. Особенно если на сервере регулярно запущено несколько сотен процессов.
Моя задача посмотреть на список процессов именно в момент нагрузки. Более того, мне даже не нужны все процессы, достаточно первой десятки самых активных, нагружающих больше всего систему. Я буду реализовывать этот мониторинг следующим образом:
- Добавляю в стандартный шаблон новый айтем типа Zabbix Trapper.
- Разрешаю на zabbix agent запуск внешних команд.
- Настраиваю на Zabbix Server действие при срабатывании одного из нужных мне триггеров. В действии указываю выполнение команды на целевом сервере, которая сформирует список процессов и отправит его на сервер мониторинга с помощью zabbix-sender.
Приступаем к реализации задуманного. Я буду настраивать описанную схему на Zabbix Server версии 5.2. Если у вас его нет, читайте мою статью по установке и настройке zabbix. В качестве подопытной системы будет выступать Centos. Так же предлагаю мои статьи по ее установке и предварительной настройке.
Подготовка сервера к мониторингу процессов
Первым делом идем на целевой сервер и изменяем конфигурацию zabbix-agent. Нам надо активировать следующую опцию:
Не забудьте после этого перезапустить агента.
Предупреждаю, что подобная настройка — огромная дыра в безопасности сервера. Используйте на свой страх и риск. Чтобы у вас не было проблем с этим, настоятельно рекомендую ограничивать доступ к порту агента на сервере на уровне firewall только с сервера мониторинга. Так же в обязательном порядке использовать шифрованное соединение между сервером и агентом. Вообще, это универсальное правило при настройке мониторинга. В идеале, так надо делать всегда. Я стараюсь все это настраивать при работе мониторинга через интернет. Если проигнорировать данное предупреждение и оставить все в открытом доступе, то через разрешенные удаленные команды вам могут залить на сервер зловред.
Далее проверим команду, которая будет формировать список процессов для отправки на сервер мониторинга. Я предлагаю использовать вот такую конструкцию, но вы можете придумать что-то свое.
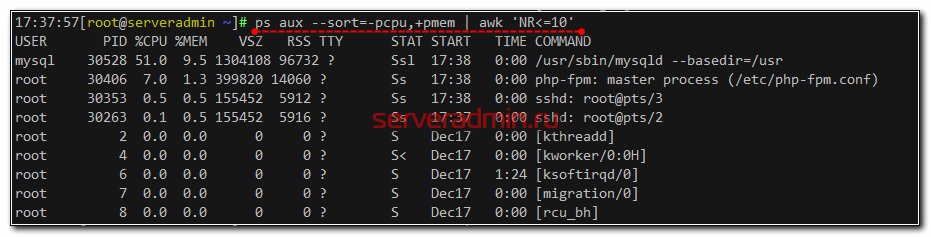
Получаем список запущенных процессов, отсортированный по потреблению cpu и ограниченный первыми десятью строками. В данный момент на сервере с агентом нам делать нечего. Перемещаемся в web интерфейс Zabbix Server.
Настройка мониторинга за процессами
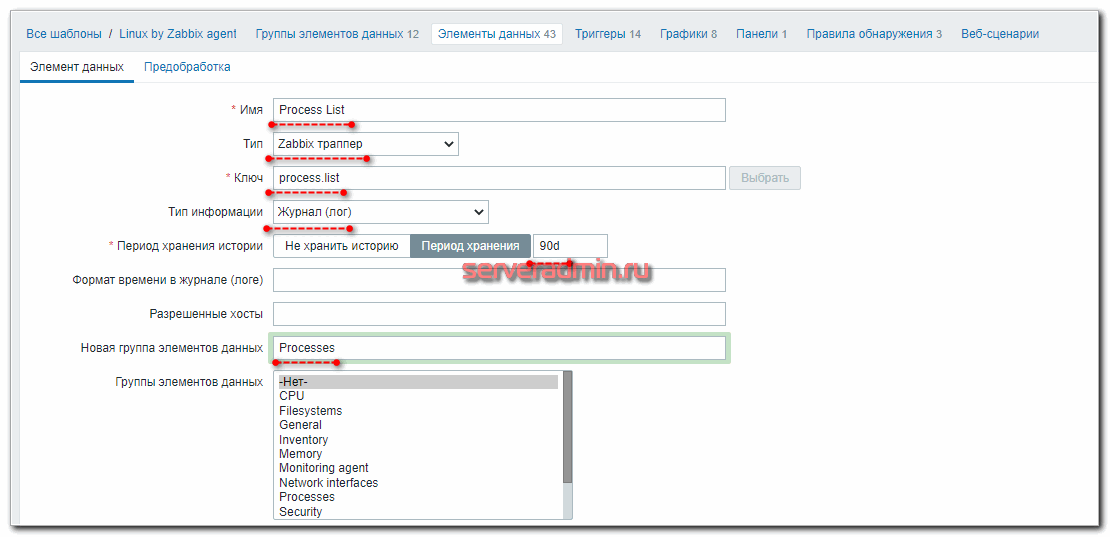
На Zabbix сервере идем в стандартный шаблон Linux и добавляем туда 2 новых айтема:
- Process List — список процессов, ограниченный десятью с самой высокой нагрузкой на cpu. Сюда будем записывать информацию о процессах на сервере при срабатывании триггеров на повышенную нагрузку CPU.
- Full Process List — полный список всех процессов. Сюда запишем полный список всех процессов, когда сработает триггер на превышение максимально допустимого количества запущенных процессов на сервере.
Так выглядит первый айтем. Второй сделайте по аналогии.
Теперь идем на сервер с агентом и пробуем отправку данных в данный айтем. Для этого нам нужен будет zabbix_sender. Если у вас его нет, то установите.
Отправку данных проверяем следующим образом:
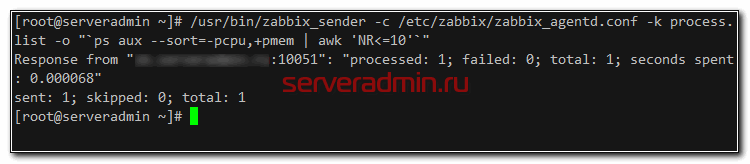
Я не буду подробно останавливаться на формате запросов с помощью zabbix_sender. Все это хорошо описано в документации. Теперь идем в веб интерфейс сервера и в разделе Последние данные смотрим на список процессов, который нам пришел с целевого сервера.
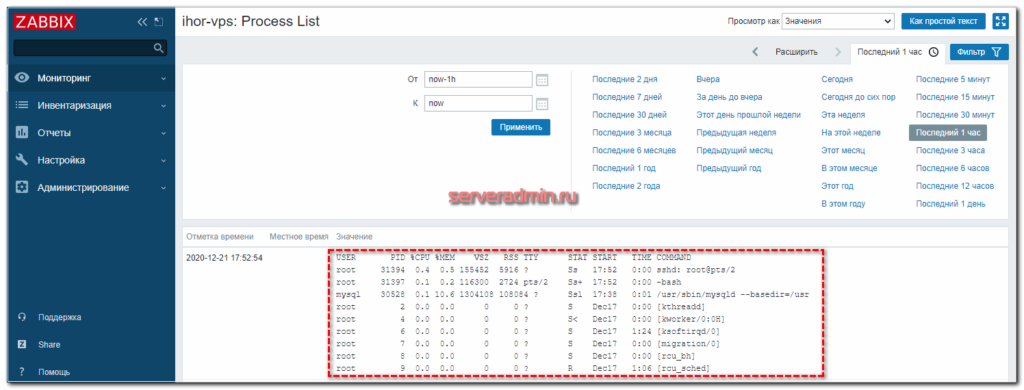
Ровно то, что нам было нужно. То же самое можно проверить с айтемом Full Process List, убрав в команде | awk ‘NR Настройка -> Действия и добавляем новое.
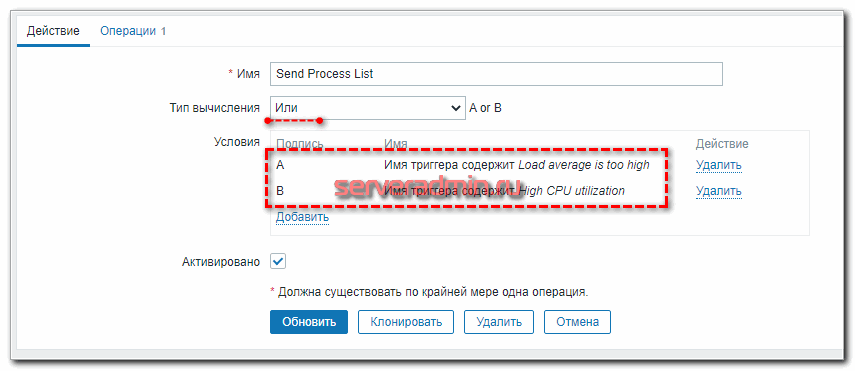
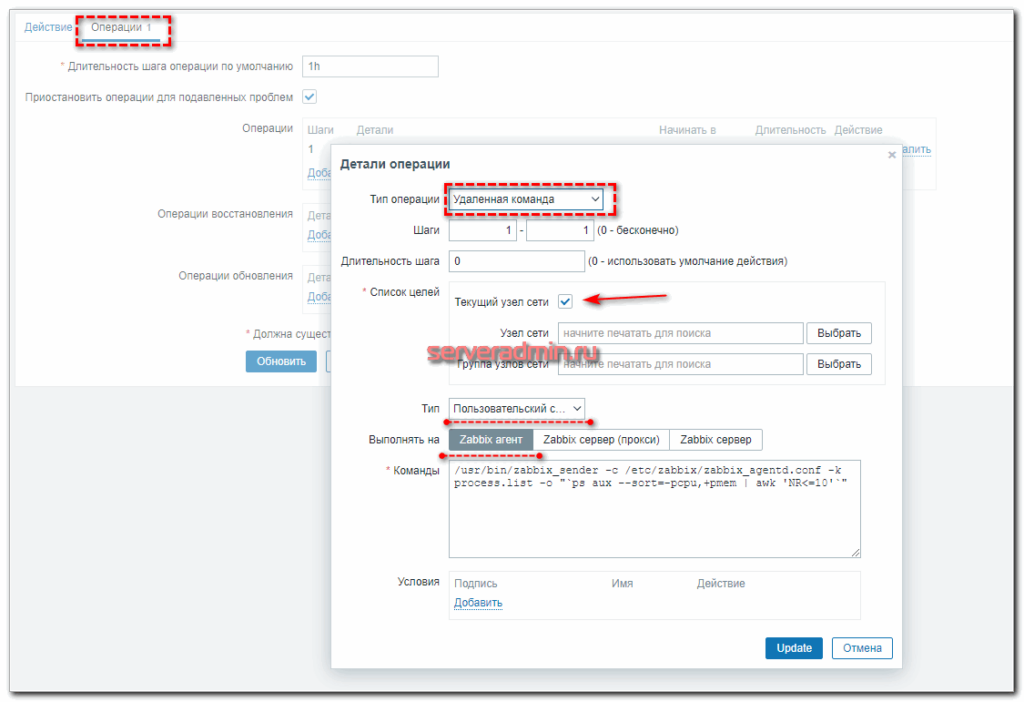
Сохраняйте действие и можно проверять.
Проверка отправки списка процессов
Теперь проверим, как все это будет работать. Для этого идем на целевой сервер и нагружаем его чем-нибудь. Я для примера запустил в двух разных консолях по команде:
Они достаточно быстро нагрузили единственное ядро тестового сервера, так что оставалось только подождать активации триггера. Через 5 минут это случилось.
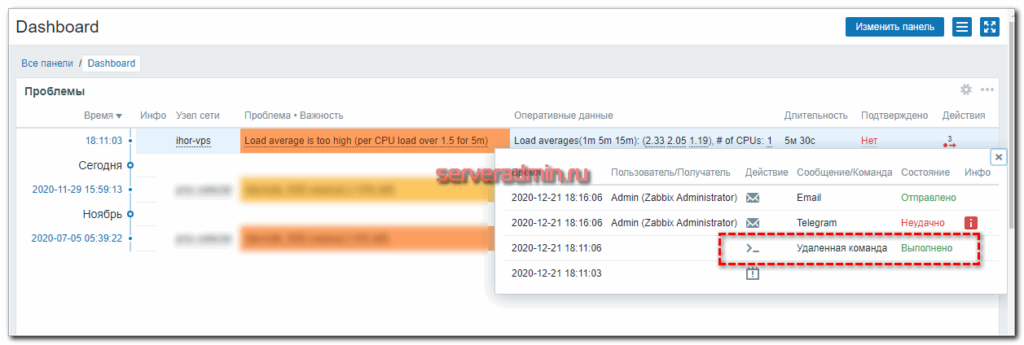
Иду в раздел Последние данные и вижу там список процессов, которые нагрузили мой сервер.
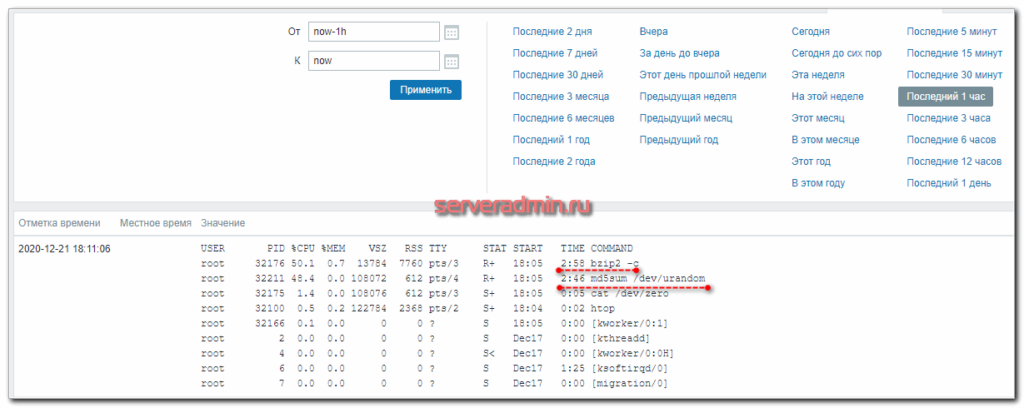
Что мне в итоге и требовалось. Теперь нет нужды каким-то образом проверять, что конкретно нагружает сервер. В момент пиковой нагрузки я получу список запущенных процессов в отдельный айтем. Для полного списка процессов все делается по аналогии.
Заключение
Вот такую реализацию я придумал, когда потребовалось решить задачу. Один сервер постоянно донимал оповещениями по ночам. Нужно было понять, что его дергает в это время. Жаль, что у Zabbix из коробки нет реализации подобного информирования. Помню лет 5 назад был бесплатный тариф у мониторинга NewRelic. Можно было поставить агент мониторинга на сервер и потом смотреть очень удобные отчеты в веб интерфейсе. Никаких настроек не нужно было, все работало из коробки. Там были отражены все запущенные процессы на сервере на временном ряду со всеми остальными метриками. Это было очень удобно. Я нигде в бесплатном софте не видел такой реализации. Это примерно вот так выглядело.
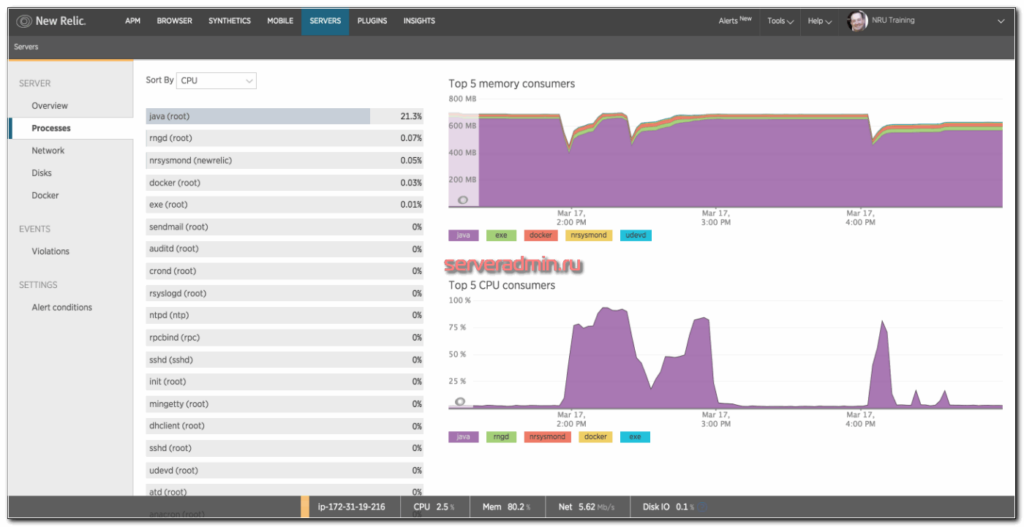
Кстати, в первоначальной версии действия я просто отправлял список процессов на почту. Мне показалось это удобным. Можно было сразу же в почте, в соседнем письме с триггером, посмотреть список процессов. Но потом решил, что удобнее все же хранить историю в одном месте на сервере и настроил сбор данных туда. Хотя можно делать и то, и другое. Например, в действии можно указать другую команду к исполнению:
И вам на почту придет список запущенных процессов после активации триггера.



