- Мониторинг RAID в Zabbix
- Пример создания триггера в Zabbix
- Мониторинг программного рейда mdadm в zabbix
- Введение
- Настройка агента для мониторинга mdadm
- Настройка на сервере Zabbix
- Заключение
- Мониторинг Intel raid с помощью raidcfg и Zabbix
- Цели статьи
- Введение
- Скрипт для внешних проверок raid массивов
- Шаблон для мониторинга за intel raid
- Заключение
- Мониторинг программного RAID в Zabbix
- Шаг 1. Настройка Zabbix-client на наблюдаемом сервере
- Шаг 2. Настройка Zabbix-Server
- Аренда серверов.
- 1С:Предприятие “в облаке”.
- IP-телефония в офис.
Мониторинг RAID в Zabbix
Сегодня я расскажу как настроить мониторинг Raid — массива на серверах IBM с помощью системы мониторинга Zabbix.
IBM использует контроллеры LSI, у и них есть своя утилита для администрирования RAID-контроллера — MegaCli.
Для установки нужно добавить репозиторий в ваш sources.list:
открываем /etc/apt/sources.list и добавляем строку:
После чего устанавливаем как обычно:
Если вывод примерно такой, значит установка прошла успешно:
Теперь на клиентской машине, с установленным агентом zabbix в файл конфигурации /etc/zabbix/zabbix_agentd.conf добавляем строку:
Значения параметров:
custom.lsi.status — имя пользовательского параметра, его мы будем использовать в шаблоне при создании элемента данных (Item).
-LDInfo -Lall -aAll — отображаем все логические устройства всех контроллеров
grep State | grep -vc Optimal — выполняем подсчет всех массивов со статусом отличным от «Optimal».
Пример создания триггера в Zabbix
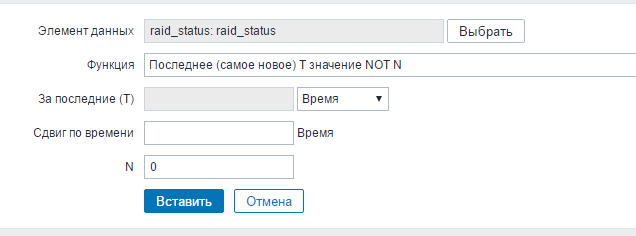
Создадим триггер отслеживания состояния массивов на примере LSI.
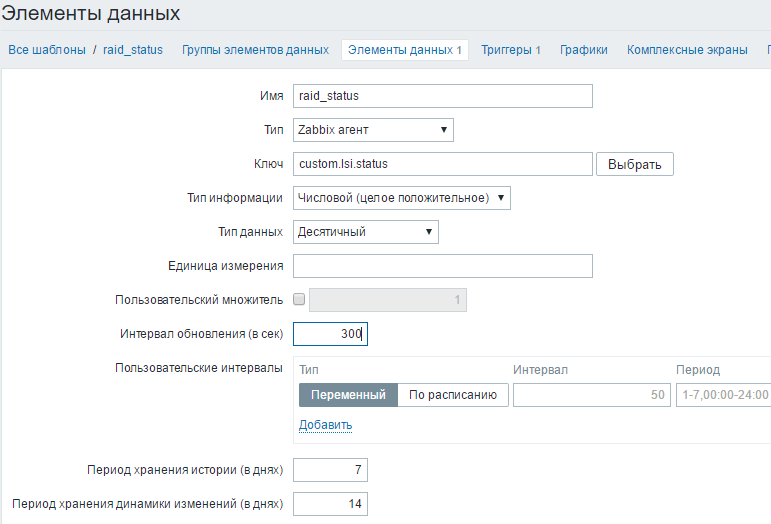
- Создаем шаблон Configuration → Templates → Create template, задаем имя и добавляем в группу Templates.
- В шаблоне открываем вкладку Items и создаем элемент. Указываем ключ(имя пользовательского параметра в zabbix-агенте — в нашем случае custom.lsi.status) и уменьшаем кол-во дней хранения значений:
Мониторинг программного рейда mdadm в zabbix

Мне довольно часто приходится работать с программным рейдом в linux — mdadm. Это эффективное бюджетное решение для обеспечения отказоустойчивости дисковой подсистемы сервера. Чтобы оперативно реагировать на проблемы с рейдом, необходимо получать информацию о его состоянии. С помощью системы мониторинга Zabbix очень легко настроить мониторинг mdadm.
Введение
У нас имеется любой сервер Linux с настроенным рейдом mdadm. Я специально не останавливаюсь на каком-то конкретном дистрибутиве, потому что этот рецепт универсален и будет актуален в любом дистрибутиве. Узнать состояние рейда можно командой в консоли:
Заглавные буквы U означают, что все жесткие диски на месте, с рейдом все в порядке. Если какой-то из них выйдет из строя, то вместо буквы будет стоять знак _ . По этому значению мы и будем определять статус рейд массива mdadm — если знака _ нет, то все в порядке.
Воспользуемся простой командой для определения символа _ в выводе mdstat:
Если символа _ нет, то на выходе получаем значение 0. Если же это значение больше 1, то рейд считается поврежденным, zabbix отправляет уведомление. Отправлять полученные значения на сервер мониторинга будем с помощью UserParameter.
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
То же самое на Debian 10, если предпочитаете его:
Настройка агента для мониторинга mdadm
Идем на сервер с настроенным mdadm, который будем мониторить и добавляем в файл конфигурации агента zabbix новый параметр:
Перезапускаем агент той командой, которая актуальна для вашей системы. Скорее всего сгодится такая:
Проверим работу этого параметра:
Все в порядке. Рейд в нормальном состоянии, команда возвращает параметр 0. Для проверки правильности регулярного выражения можно направить вывод /proc/mdstat в текстовый файл, изменить там значение U на _ и прогнать egrep по этому файлу. Должно на выходе быть значение 1 или более, в зависимости от того, сколько вы подчеркиваний добавите. Например вот так:
Заменяем U на _ .
Все верно, команда отрабатывает правильно, значит мониторинг будет корректно работать.
Настройка на сервере Zabbix
Теперь идем на сервер мониторинга и настраиваем на нем все, что необходимо для мониторинга mdadm. Нам нужно будет создать шаблон, в нем один item и один trigger. Создаем шаблон: Configuration -> Templates -> Create template.
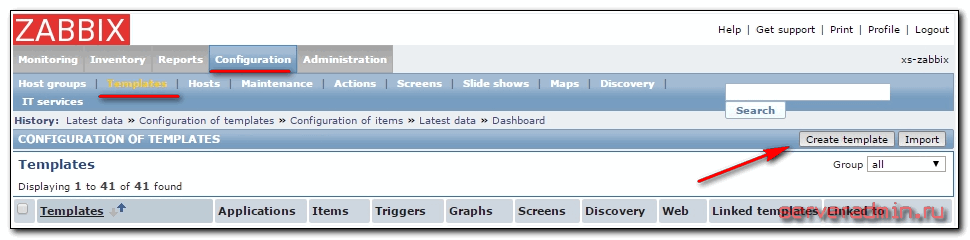
Пишем название, добавляем в группу и сохраняем. Открываем созданный шаблон, переходим в Items и создаем новый.

Заполняем параметры как у меня и жмем add.
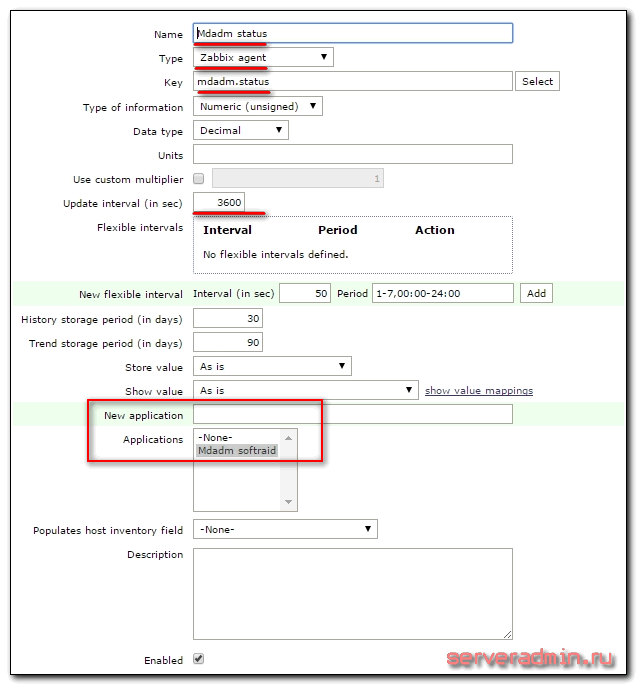
Я установил интервал обновления этого параметра в 3600 секунд, то есть раз в час. Не вижу смысла проверять его чаще. В этом нет практической пользы.
Теперь добавим триггер, который будет срабатывать, если с рейдом проблемы. Переходим на список триггеров, жмем Create trigger и заполняем значения.
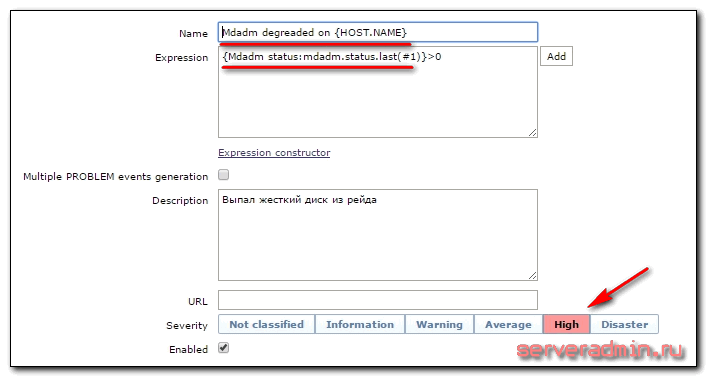
Добавляем триггер. На этом настройка шаблона закончена. Можно назначить шаблон всем хостам, на которых мы добавили UserParameter и ждать, когда в Last Data появятся первые значения. Я на момент отладки на всякий случай поставил сбор данных каждые 60 секунд. Когда убедился, что все работает, изменил это значение обратно на 3600.
Заключение
Вот так легко и просто настроить необходимый мониторинг в Zabbix. Пользовательские параметры предоставляют широкие возможности по настройке. Можно мониторить все, что угодно. Даже в данном случае можно придумать целую кучу всевозможных команд, с помощью которых можно собирать данные по mdadm. Можно сохранять не только состояние рейда, но и подробную информацию о нем. Для этого нужно просто полный вывод сделать и передавать его на сервер.
Мониторинг Intel raid с помощью raidcfg и Zabbix

У меня есть группа серверов с настроенным intel raid и установленными поверх Windows Hyper-V Server. Возникло больше желание с помощью zabbix наблюдать за состоянием массивов и предупреждать в случае проблем. Готового решения нигде не нашел, поэтому пораскинул мозгами и придумал свое, чем и хочу поделиться с вами.
Цели статьи
- Настроить передачу в zabbix состояния рейд массивов, настроенных с помощью встроенной в материнскую плату технологии intel raid.
- При настройке совершать минимум действий на целевых серверах, а максимум на zabbix сервере.
- Настроить триггеры и уведомления на случай, если состояние рейда отличается от рабочего Normal.
Введение
На серверах уже настроен мониторинг состояния SMART дисков. При использовании встроенного intel raid, состояние дисков с целевой системы нормально наблюдается. В принципе, мне этого хватало, но подумал, почему бы и состояние массивов не замониторить, ведь массив может развалиться и при нормальных показателях смарта дисков.
В первую очередь погуглил и не нашел практически ничего, что помогло бы настроить мониторинг интел рейдов в zabbix. На целевых системах установлена интеловская утилита raidcfg, с помощью которой можно посмотреть на состояние массивов и дисков. Например, с ключом /st получается вот такой вывод.
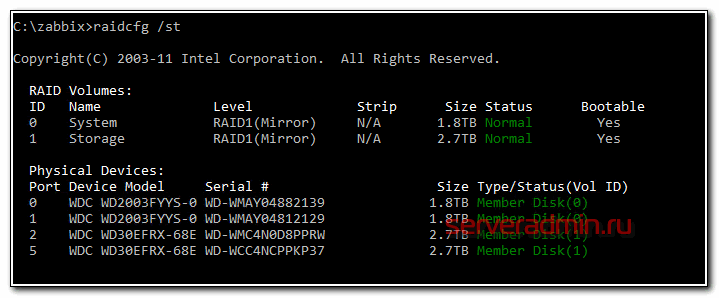
Красиво и наглядно, но для автоматизации не очень подходит. Лучше подойдет ключ /stv.

С такими данными уже можно работать. В целом, ничего сложного, нужно распарсить вывод любым удобным способом и передать на сервер мониторинга информацию о статуте рейд массива. Как можно с помощью батников парсить различные текстовые файлы я показывал на нескольких примерах в отдельной статье — Мониторинг значений из текстового файла в Zabbix.
В этот раз мне не захотелось такие костыли городить на каждом сервере. Я в итоге решил поступить по-другому. На zabbix сервере сделать скрипт для внешних проверок. Этот скрипт будет на целевом сервере с помощью zabbix_get забирать вывод команды raidcfg.exe /stv, запущенной через system.run. Дальше вывод команды в исходном виде поступает на zabbix сервер. Его можно парсить каким-то образом, но я решил этого не делать. Вывод и так короткий, много места не занимает. Проверка на наличие тревожных слов будет уже в триггере с помощью regexp.
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
То же самое на Debian 10, если предпочитаете его:
Скрипт для внешних проверок raid массивов
В директорию на zabbix сервере /usr/lib/zabbix/externalscripts кладем скрипт intelraid.sh для внешних проверок.
Скрипт, как вы видите, очень простой. Для того, чтобы он работал, вам обязательно нужно на каждом агенте разрешить выполнение внешних команд. По-умолчанию они отключены. Добавляем в агенте параметр:
И перезапускаем агент. Это все, что надо делать на целевых серверах. Теперь можно проверить работу скрипта. Для этого выбираете любой сервер и передаем его ip адрес в качестве параметра скрипту.
Если получаете результат работы утилиты raidcfg, значит все в порядке. Можно переходить в web интерфейс сервера мониторинга.
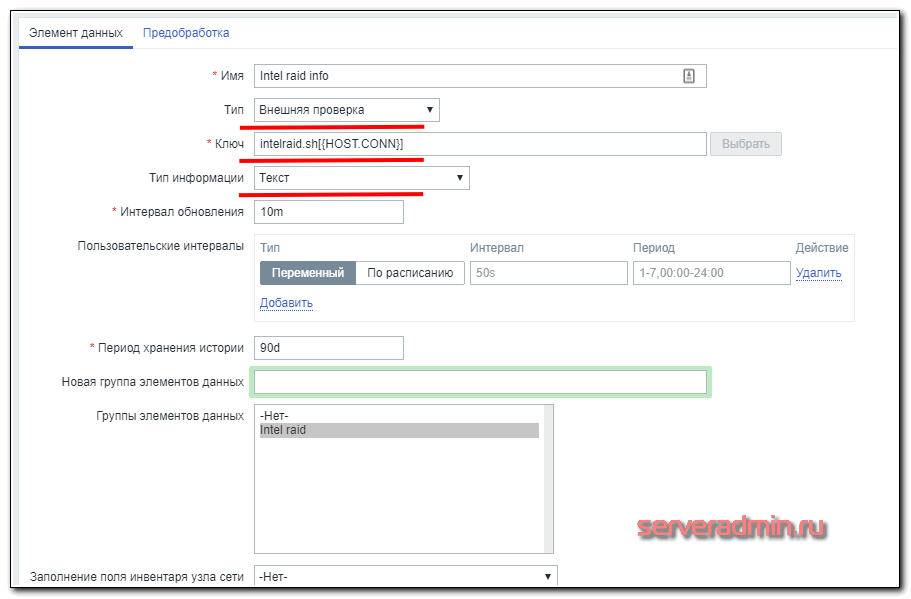
Шаблон для мониторинга за intel raid
Шаблон очень простой — один элемент и один триггер, поэтому экспорт шаблона делать не буду, лучше создать вручную, чтобы точно работало на всех версиях Zabbix. Вот элемент данных.
А вот триггер к нему.
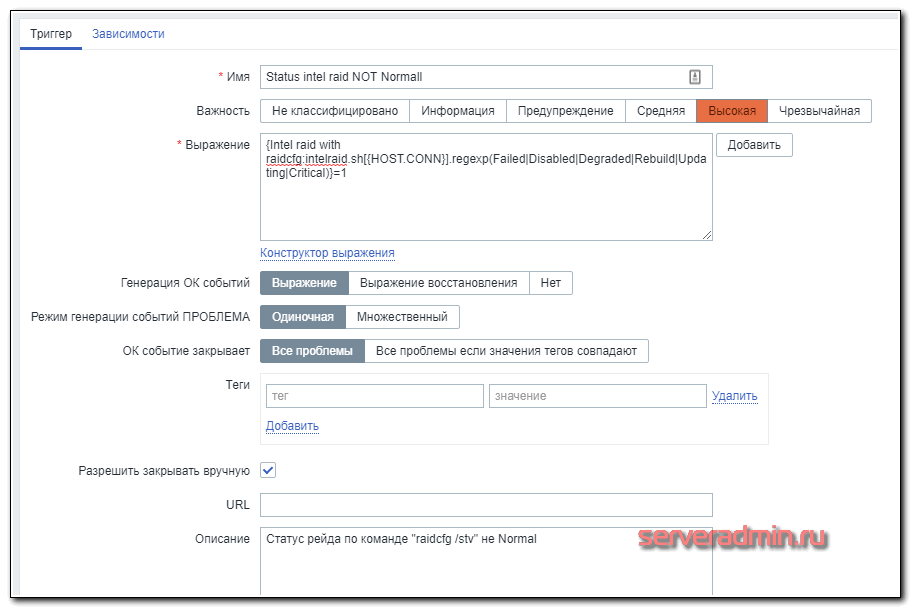
Если в строке будет найдено одно из слов Failed|Disabled|Degraded|Rebuild|Updating|Critical, то он сработает. Я на практике не проверял работу триггера, так как не хотелось рейд ломать. А потестил следующим образом. Добавил в проверочную строку название одного из массивов, к примеру, Storage, который встречается не на всех серверах. В итоге, триггер сработал только там, где было такое название. Так что в теории, проверка должна работать корректно.
Теперь можно добавлять шаблон к необходимым хостам и ждать поступление данных. В Latest Data должны увидеть следующее содержимое итема.
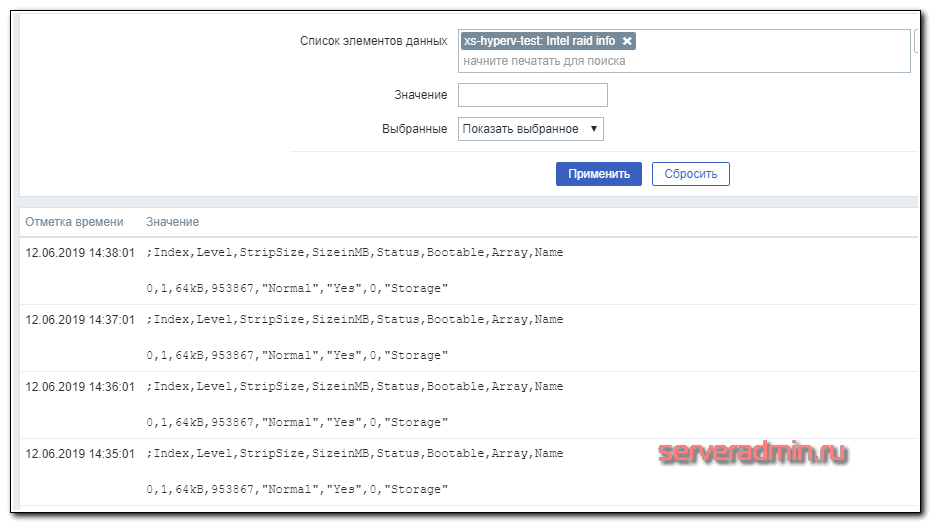
Вот и все. Теперь все intel raid массивы подключены к мониторингу.
Заключение
Так быстро и просто решается прикладная задача по мониторингу с помощью Zabbix. Сел, прикинул и сразу сделал. Вариантов решения обычно несколько, выбирай на свой вкус. Можно было на клиенте распарсить вывод и передавать в Zabbix сразу состояние массива в одно слово. А можно было просто True/False или 1/0.
Я последнее время стараюсь максимально выполнять на сервере и минимально на клиенте, благо в заббиксе появилась куча средств для этого — пост обработка данных, зависимые элементы и т.д. Буду рад замечаниям и предложениям по теме в комментариях. Если вам интересен Zabbix, читайте мои остальные статьи по нему.
Мониторинг программного RAID в Zabbix
Достаточно часто использую программные RAID-массивы на Windows-серверах: удобно, дёшево, сердито. 🙂
Однако, за программным RAID-массивом, как и за любым другим, нужно следить. Хотя бы чуть-чуть.
Есть отличная статья, которая описывает, как следить за программным RAID-массивом в Linux: https://serveradmin.ru/monitoring-programmnogo-reyda-mdadm-v-zabbix/
И тут я подумал: “А чем Windows хуже?”. Сказано, – сделано. 🙂
Шаг 1. Настройка Zabbix-client на наблюдаемом сервере
Вояем простенький скрипт, который выводит “0”, если с массивом всё хорошо, и “1”, если есть проблемы. Сразу замечу, что скрипт писался с расчётом на то, что Windows Server у вас использует по умолчанию русский язык. Если же у вас используется другой язык, рекомендую от имени администратора выполнить команду “echo list volume | diskpart” и посмотреть, что выводится в том случае, если какой-то RAID-массив имеет проблемы.
@echo off
echo list volume | diskpart | findstr /i ошибка > %TEMP%\mdadm.txt
set /p a= nul
If %Errorlevel%==0 (echo 1) else (echo 0)
Открываем “блокнот”, в новый документ вставляем указанный выше текст и записываем всё это в bat-файл. У меня Zabbix-Client на серверах обычно установлен в папку с именем “C:\zabbix”, поэтому полный путь до файла со скриптом будет таким: “C:\zabbix\raid_status.bat”
Теперь открываем файл с конфигурацией Zabbix-клиента, который у меня расположен по адресу “C:\zabbix\zabbix_agentd.win.conf”, и в самый конец файла дописываем новую строку
После того, как сохранили конфигурацию, перезапускаем службу агента. Я обычно это делаю при помощи оснастки “Управление компьютером”.
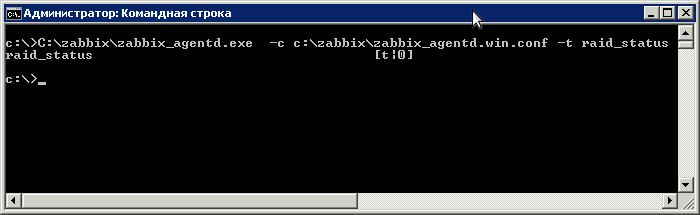
Теперь нужно проверить, всё ли правильно мы сделали. Открываем “От имени администратора” консоль (CMD) и подаём команду
C:\zabbix\zabbix_agentd.exe -c c:\zabbix\zabbix_agentd.win.conf -t raid_status
Если будет выведено “raid_status [t|0]”, значит вы всё настроили правильно.
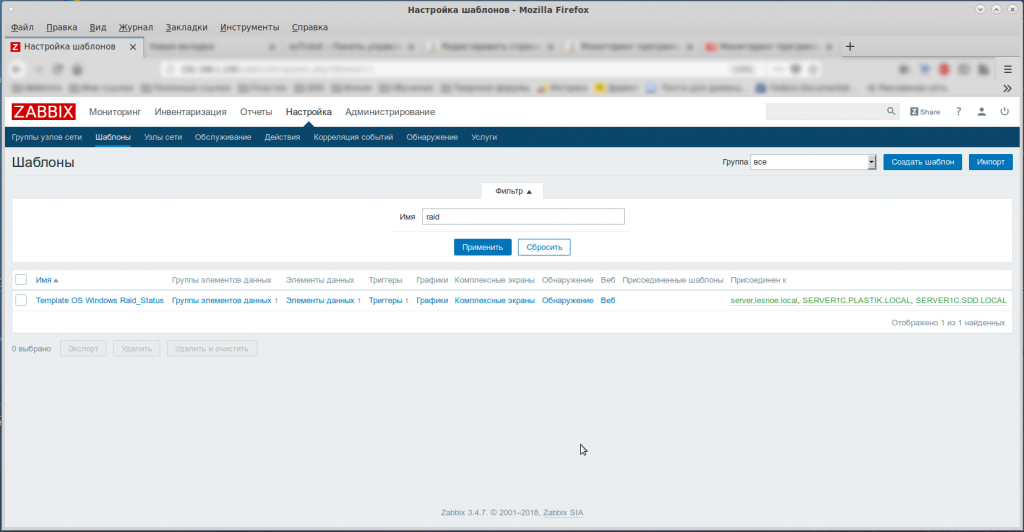
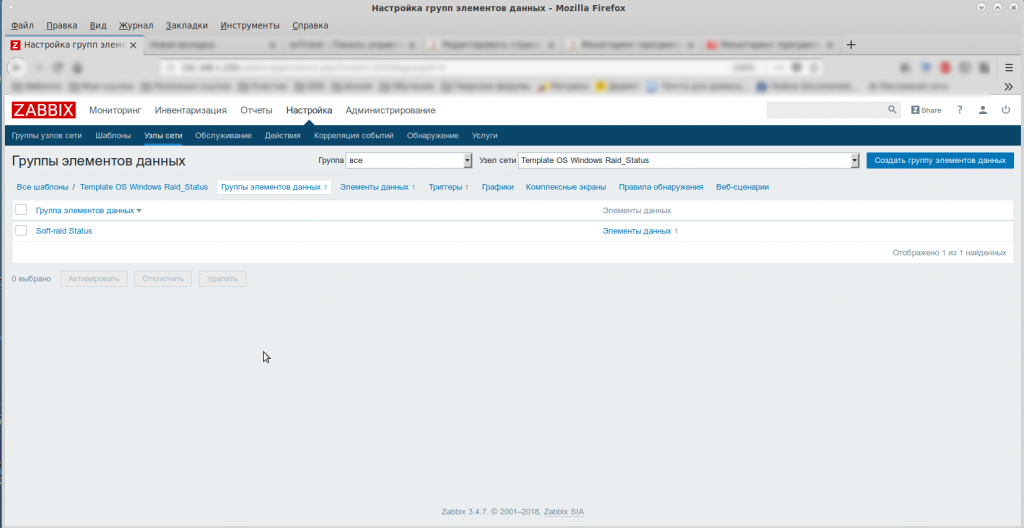
Шаг 2. Настройка Zabbix-Server
Только всегда нужно делать “поправку на ветер”. Ну, например, я использую элемента данных “raid_status”, а в статье используется “mdadm.status”.
В статье написано всё очень подробно. Я просто приведу свои скриншоты. 🙂
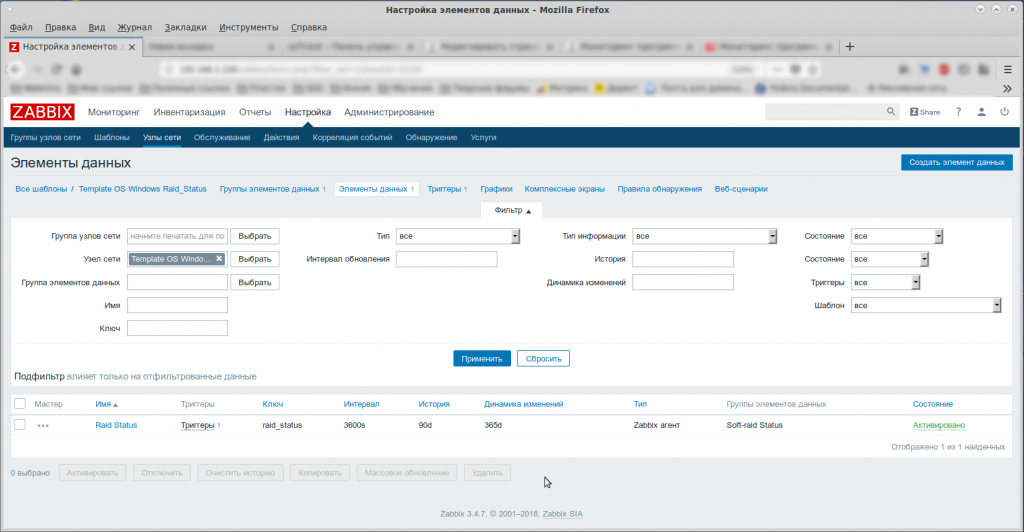
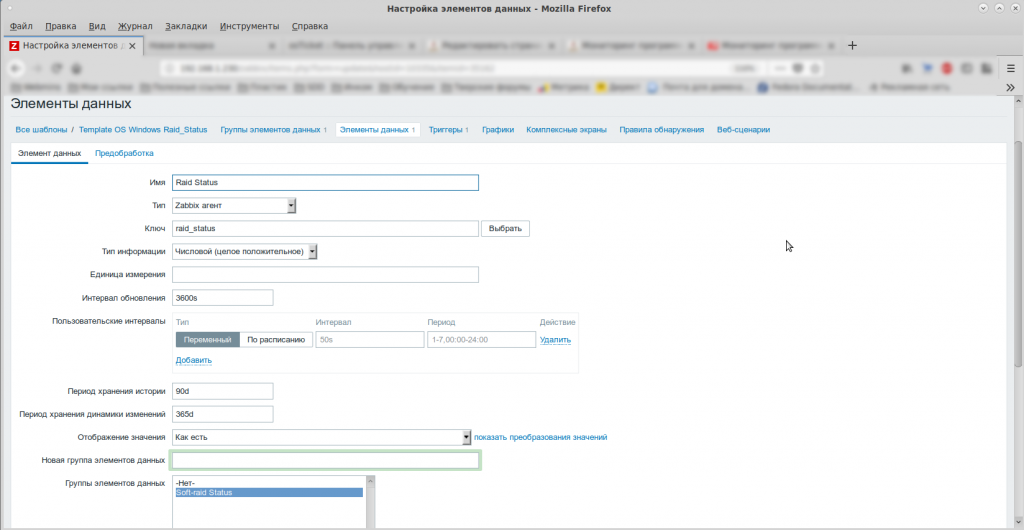
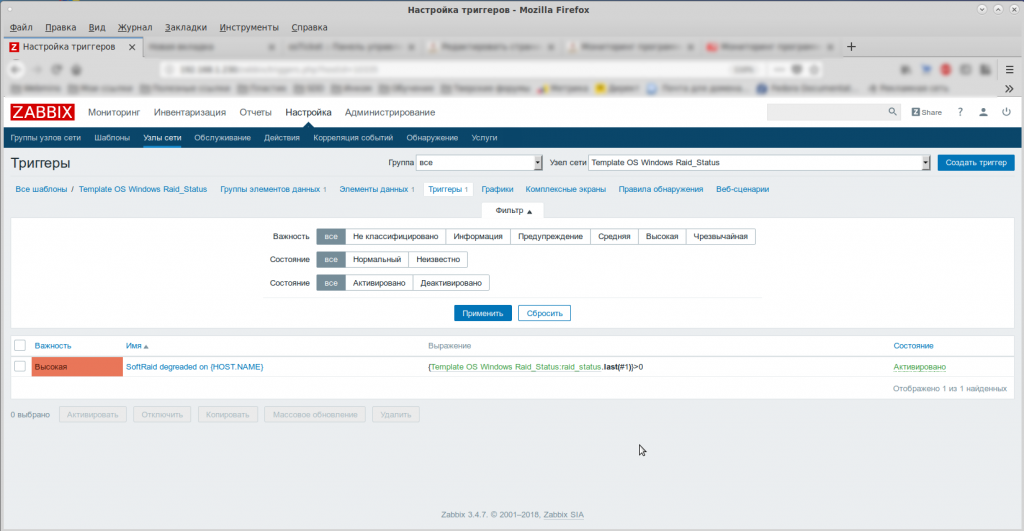
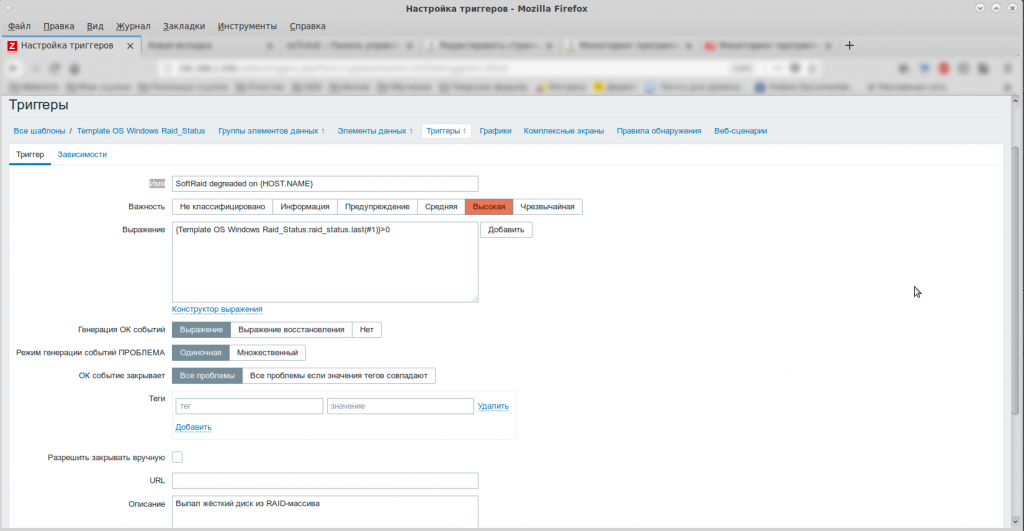
Аренда серверов.

Надёжные сервера с Pro-бегом
У ВАС В ОФИСЕ!
1С:Предприятие “в облаке”.

Безопасный доступ к своей 1С из офиса, командировки и т.п.!
IP-телефония в офис.

IP-телефония давно перестала быть роскошью в офисах.
Хотите себе в офис цифровую АТС — обращайтесь. !



