- Мониторинг доступности службы linux с помощью Zabbix
- Введение
- Описание работы простых проверок (simple check)
- Мониторинг доступности сервиса по сети
- Мониторинг локальной службы в linux
- Заключение
- Мониторинг списка запущенных процессов в Zabbix
- Введение
- Подготовка сервера к мониторингу процессов
- Настройка мониторинга за процессами
- Проверка отправки списка процессов
- Заключение
Мониторинг доступности службы linux с помощью Zabbix
Ранее я рассматривал различные конфигурации для мониторинга параметров и программ в windows и linux. Сейчас я хочу рассказать, как мониторить с помощью Zabbix произвольный сервис (службу), который работает либо локально на сервере, либо на внешнем tcp порту. Это может быть что угодно — ssh, ldap, smtp, ftp, http, pop, nntp, imap, tcp, https, telnet или любой другой сервис.
Введение
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
То же самое на Debian 10, если предпочитаете его:
В заббикс существуют различные способы получать данные для мониторинга. Наиболее распространенные источники информации:
- Zabbix агент. Устанавливается на наблюдаемую машину и отправляет данные на сервер мониторинга.
- SNMP агент. Чаще всего присутствует на устройстве, либо может быть установлен на сервер.
- Простые проверки — simple check. Выполняются непосредственно на сервере zabbix с помощью встроенных инструментов, не требуют дополнительных действий со стороны хоста.
- Внешние проверки — external checks. Как и простые проверки выполняются на сервере мониторинга, но не встроенными средствами, а внешними скриптами.
Есть и другие способы получения данных. Не буду их все перечислять, ознакомиться с ними можно в соответствующем разделе официальной документации. В нашем случае мы воспользуемся первыми двумя способами для мониторинга служб и сервисов в linux.
Тут можно пойти разными путями. Меня интересует мониторинг различных линукс служб, работающих как локально (samsdaemon, postgrey) в пределах конкретного сервера, так и для публичного доступа по сети, в частности squid, smtp, imap, http. Первое, что пришло в голову, это использовать итем с ключом service_state[]. Но как оказалось, этот тип данных снимает значения только с системных служб windows. Я не сразу это понял и некоторое время повозился в консоли, не понимая, почему при тестировании значения получаю сообщение, что данный item не поддерживается:
Дальше придумал через UserParameter запускать какой-нибудь скрипт, который будет проверять запущен ли сервис в системе или нет. Например с помощью ps ax | grep squid. В принципе, рабочий вариант, но мне казалось, что такую простую задачу можно решить проще и быстрее, без создания на каждом хосте скрипта и изменения файла конфигурации. И я не ошибся. Есть 2 различных способа мониторинга служб (сервисов) в linux с помощью zabbix. Рассмотрим первый из них.
Описание работы простых проверок (simple check)
Стал искать материал на эту тему и прочитал про simple check (простые проверки) в zabbix. Оказалось, это то, что нужно. Их можно использовать для безагентских проверок удаленных сервисов. При этом требуется минимум настроек и только на сервере. Можно создать шаблон и распространить на любое количество хостов.
Принцип работы простых проверок следующий. Вы создаете item, в нем указываете тип simple check, в качестве ключа выбираете net.tcp.service[сервис, , ], указываете соответствующие параметры в скобках и все. Сервер сам начинает опрашивать указанный сервис и возвращать в зависимости от его доступности 0 или 1. Устанавливать агент на хост не нужно. Мониторить можно любую сетевую службу, к которой есть доступ по tcp.
| 0 | сервис недоступен |
| 1 | сервис работает |
Всего в простых проверках доступны 5 ключей. Подробнее о них читайте в документации. В данном случае меня будет интересовать только ключ net.tcp.service. В нем предопределены алгоритмы проверок следующих служб: ssh, ntp, ldap, smtp, ftp, http, pop, nntp, imap, https, telnet. Детали реализации проверки каждой службы описаны тут. Если вы мониторите службу, которая не входит в указанный выше список, то происходит просто проверка возможности подключения, без отправки и получения каких-то данных.
Мониторинг доступности сервиса по сети
В качестве примера настроим мониторинг доступности прокси сервера squid. Он запущен на linux сервере и этот хост уже добавлен на сервер мониторинга. Данные поступают с помощью агента, но мы не будет его использовать. Просто создадим одиночный item для проверки доступности squid и trigger для отправки уведомления, если сервис не работает. В данном примере я рассмотрю настройку на примере конкретного хоста. Если у вас несколько серверов с squid, которые вы хотите мониторить, то все элементы лучше создать не отдельно на каждом хосте, а сразу сделать template и назначить его нужным хостам.
Итак, идем в Configuration -> Hosts и выбираем там хост, на котором установлен squid. Переходим в раздел Items и нажимаем Create item.
Заполняем необходимые параметры элемента.
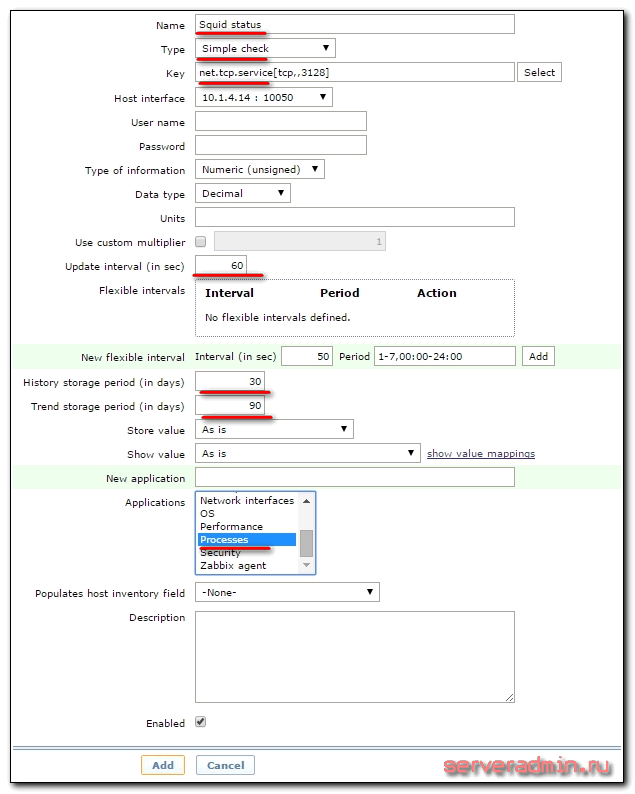
Обязательно заполнить первые 3, остальные на ваше усмотрение. Я считаю, что проверять каждые 30 секунд и хранить 90 дней информацию излишне, поэтому изменяю эти параметры в сторону увеличения.
| Squid status | Имя итема. |
| Simple check | Тип итема. |
| net.tcp.service[tcp,,3128] | Проверять tcp порт 3128 на указанном хосте. Если вы проверяете статус службы, расположенной не на том же хосте, к которому прикрепляете item, то после первой запятой можно указать необходимый адрес. |
Сразу создадим триггер, который в случае возврата в последних двух проверках значения итемом 0, будет отправлять уведомление о том, что служба недоступна. Для этого идем в раздел triggers и жмем Create trigger. Заполняем параметры элемента.
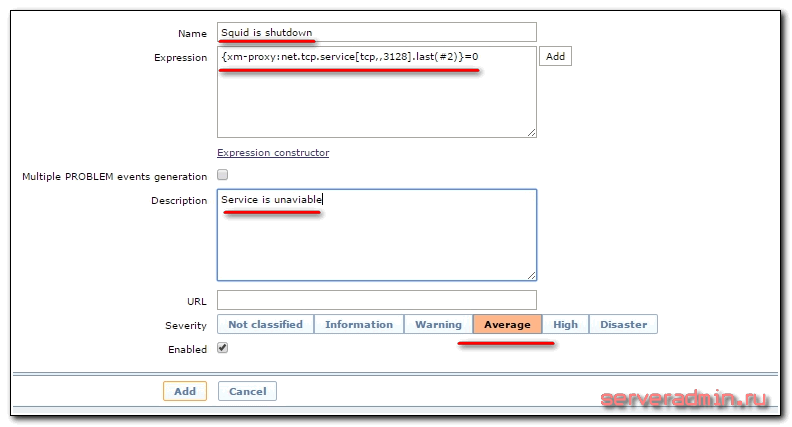
Выражение
Ждем пару минут и идем в Latest data проверять поступаемые значения.
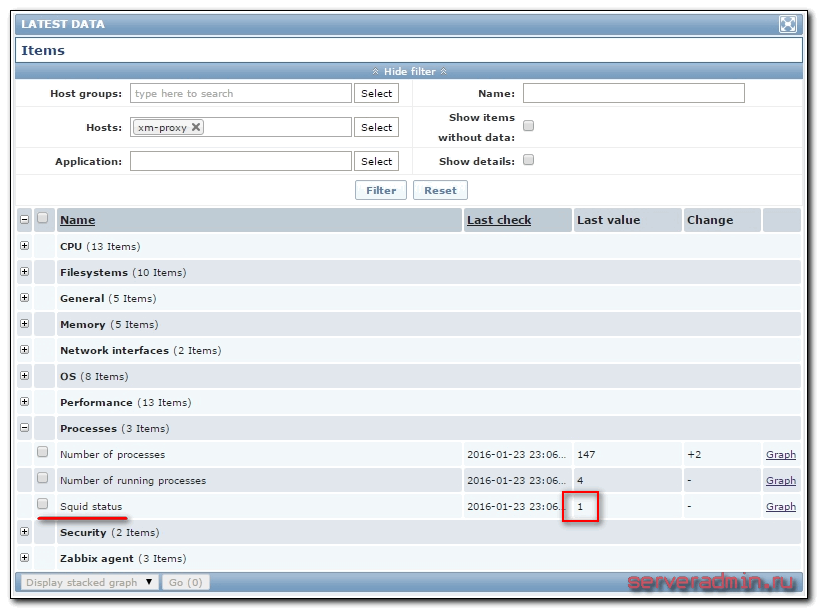
Чтобы проверить работу триггера, достаточно зайти на сервер и остановить squid. Если вы все сделали правильно, то после второй проверки, которая определит, что squid не отвечает по заданному адресу, вы получите уведомление на почту об этом. Если у вас не настроены или не работают уведомления на почту в zabbix, то читайте мою статью на эту тему.
Мониторинг локальной службы в linux
С мониторингом удаленного tcp сервиса разобрались, а что делать, если служба работает локально и к ней невозможно подключиться из вне. Тут уже не обойтись без установки zabbix агента. Если он установлен на хосте, то можно воспользоваться итемом с ключом proc.num. Этот ключ возвращает в качестве значения количество запущенных процессов. И если таких процессов больше одного, можно считать, что служба запущена.
Рассмотрим на примере мониторинга службы postgrey, реализующей greylist для борьбы со спамом. Она работает локально на почтовом сервере linux и является критическим сервисом, так как без него почтовый сервер postfix не будет принимать почту, выдавая временную ошибку почтовой системы. Проверим работу ключа proc.num:
Все в порядке, zabbix агент возвращает значение 1 при запущенном сервисе. Идем на сервер мониторинга, выбираем хост или шаблон и создаем новый item.
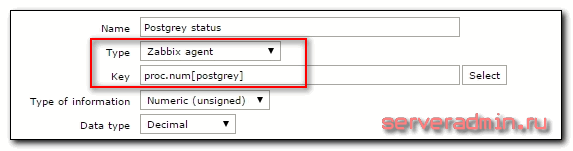
Показываю только основные параметры, остальные устанавливайте на свой вкус. Я лишь рекомендую не делать слишком частые проверки. В большинстве случаев в этом нет необходимости, а нагрузка на сервер постоянно растет при добавлении новых итемов.
Создаем триггер с оповещением о недоступности сервиса. При последних двух значениях равных 0 срабатываем.
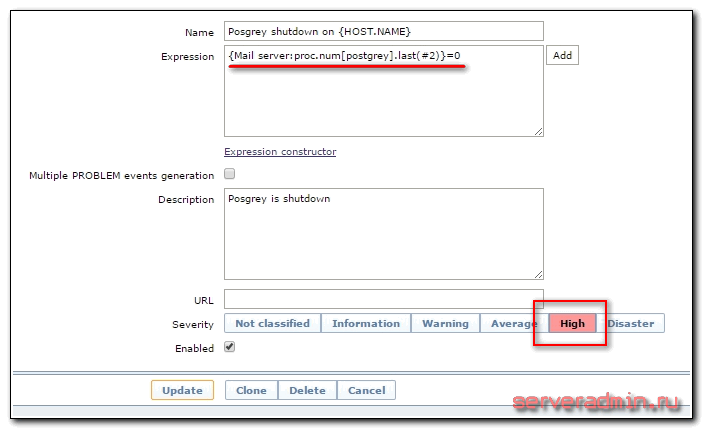
Я настраиваю триггер в шаблоне, поэтому сразу для удобства в названии триггера указываю маску для имени, чтобы было понятно в оповещении, на каком хосте сработал триггер. Как обычно, проверить поступаемые значения можно в Latest data.
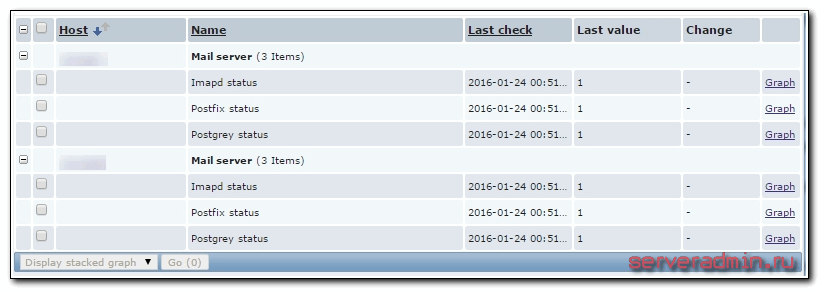
Вот и все. Мы настроили мониторинг локальных служб linux в заббиксе.
Заключение
В своем материале я рассмотрел два различных способа, с помощью которых можно мониторить любой удаленный сервис по протоколу tcp, либо локальную службу на сервере linux. Конкретно в моих примерах можно было воспользоваться вторым способом в обоих случаях. Я этого не сделал, потому что первым способом я не просто проверяю, что служба запущена, я еще и обращаюсь к ней по сети и проверяю ее корректную работу для удаленного пользователя.
Разница тут получается вот в чем. Допустим, сервер squid у вас запущен и работает на сервере. Проверка работы локальной службы показывает, что сервис работает и возвращает значение 1. Но к примеру, вы настраивали firewall и где-то ошиблись. Сервис стал недоступен по сети, пользователи не могут им пользоваться. При этом мониторинг будет показывать, что все в порядке, служба запущена, хотя реально она не может обслужить запросы пользователей. В таком случай только удаленная проверка покажет, что с доступностью сервиса проблемы и надо что-то делать.
Из этого можно сделать вывод, что система мониторинга zabbix предоставляет огромные возможности по мониторингу. Какой тип наблюдения и сбора данных подойдет в конкретном случае нужно решать на месте, исходя из сути сервиса, за которым вы наблюдаете.
Источник
Мониторинг списка запущенных процессов в Zabbix
В стандартных шаблонах Zabbix есть триггеры на загрузку процессора, а так же на превышение максимально допустимого числа процессов. Триггеры эти практически бесполезны, если у вас плавающая нагрузка. Допустим, вы получаете уведомление о том, что у вас сильно нагружен процессор. Через 10 минут нагрузка прошла, а вы не успели зайти на сервер и посмотреть, чем он был нагружен в это время. Вот эту проблему я и решаю своим велосипедом, которым делюсь в статье.
Введение
Рассказываю подробно, что я хочу получить в конце статьи. В стандартном шаблоне Zabbix для Linux есть несколько триггеров. Они могут немного отличаться в названиях, в зависимости от версии шаблона, но смысл один и тот же:
- High CPU utilization
- Load average is too high
- Too many processes on hostname
Я хочу получить информацию о запущенных процессах на хосте в момент срабатывания триггера. Это позволит мне спокойно посмотреть, что создает нагрузку, когда у меня будет возможность. Мне не придется идти руками в консоль хоста и пытаться ловить момент, когда опять появится нагрузка.
В дефолтной конфигурации у Zabbix нет готовых инструментов, чтобы реализовать желаемое. Вы можете настроить мониторинг процесса или группы процессов в Zabbix. Но это не то, что нужно. Можно настроить автообнаружение всех процессов и мониторить их. Чаще всего это тоже не нужно, а подобный мониторинг будет генерировать большую нагрузку и сохранять кучу данных в базу. Особенно если на сервере регулярно запущено несколько сотен процессов.
Моя задача посмотреть на список процессов именно в момент нагрузки. Более того, мне даже не нужны все процессы, достаточно первой десятки самых активных, нагружающих больше всего систему. Я буду реализовывать этот мониторинг следующим образом:
- Добавляю в стандартный шаблон новый айтем типа Zabbix Trapper.
- Разрешаю на zabbix agent запуск внешних команд.
- Настраиваю на Zabbix Server действие при срабатывании одного из нужных мне триггеров. В действии указываю выполнение команды на целевом сервере, которая сформирует список процессов и отправит его на сервер мониторинга с помощью zabbix-sender.
Приступаем к реализации задуманного. Я буду настраивать описанную схему на Zabbix Server версии 5.2. Если у вас его нет, читайте мою статью по установке и настройке zabbix. В качестве подопытной системы будет выступать Centos. Так же предлагаю мои статьи по ее установке и предварительной настройке.
Подготовка сервера к мониторингу процессов
Первым делом идем на целевой сервер и изменяем конфигурацию zabbix-agent. Нам надо активировать следующую опцию:
Не забудьте после этого перезапустить агента.
Предупреждаю, что подобная настройка — огромная дыра в безопасности сервера. Используйте на свой страх и риск. Чтобы у вас не было проблем с этим, настоятельно рекомендую ограничивать доступ к порту агента на сервере на уровне firewall только с сервера мониторинга. Так же в обязательном порядке использовать шифрованное соединение между сервером и агентом. Вообще, это универсальное правило при настройке мониторинга. В идеале, так надо делать всегда. Я стараюсь все это настраивать при работе мониторинга через интернет. Если проигнорировать данное предупреждение и оставить все в открытом доступе, то через разрешенные удаленные команды вам могут залить на сервер зловред.
Далее проверим команду, которая будет формировать список процессов для отправки на сервер мониторинга. Я предлагаю использовать вот такую конструкцию, но вы можете придумать что-то свое.
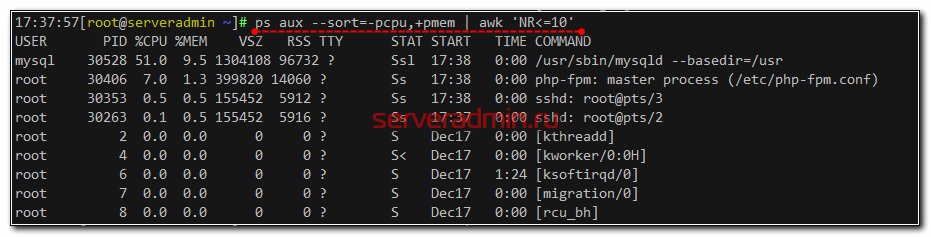
Получаем список запущенных процессов, отсортированный по потреблению cpu и ограниченный первыми десятью строками. В данный момент на сервере с агентом нам делать нечего. Перемещаемся в web интерфейс Zabbix Server.
Настройка мониторинга за процессами
На Zabbix сервере идем в стандартный шаблон Linux и добавляем туда 2 новых айтема:
- Process List — список процессов, ограниченный десятью с самой высокой нагрузкой на cpu. Сюда будем записывать информацию о процессах на сервере при срабатывании триггеров на повышенную нагрузку CPU.
- Full Process List — полный список всех процессов. Сюда запишем полный список всех процессов, когда сработает триггер на превышение максимально допустимого количества запущенных процессов на сервере.
Так выглядит первый айтем. Второй сделайте по аналогии.
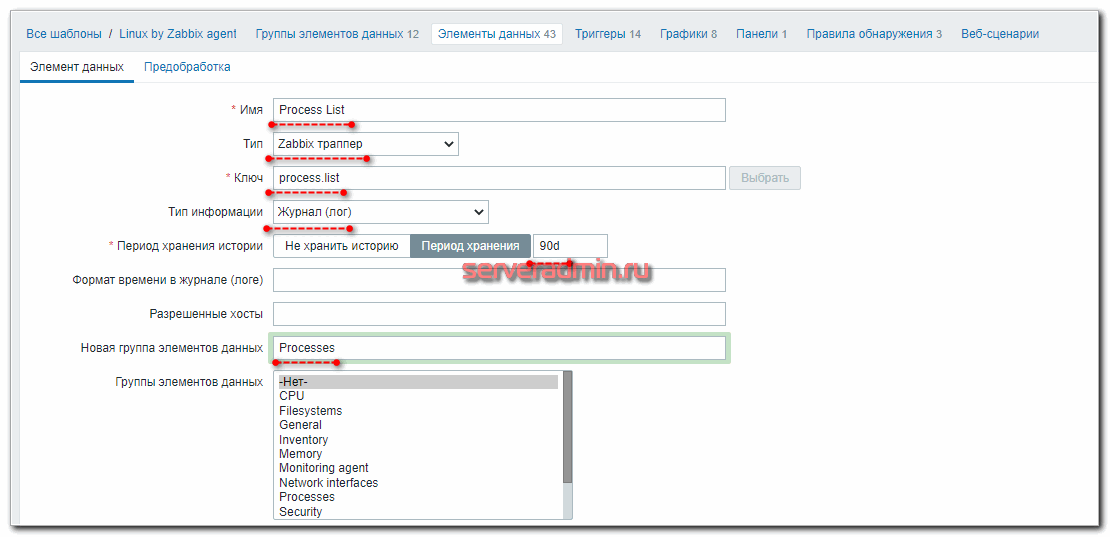
Теперь идем на сервер с агентом и пробуем отправку данных в данный айтем. Для этого нам нужен будет zabbix_sender. Если у вас его нет, то установите.
Отправку данных проверяем следующим образом:
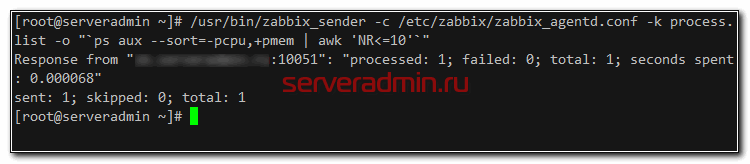
Я не буду подробно останавливаться на формате запросов с помощью zabbix_sender. Все это хорошо описано в документации. Теперь идем в веб интерфейс сервера и в разделе Последние данные смотрим на список процессов, который нам пришел с целевого сервера.
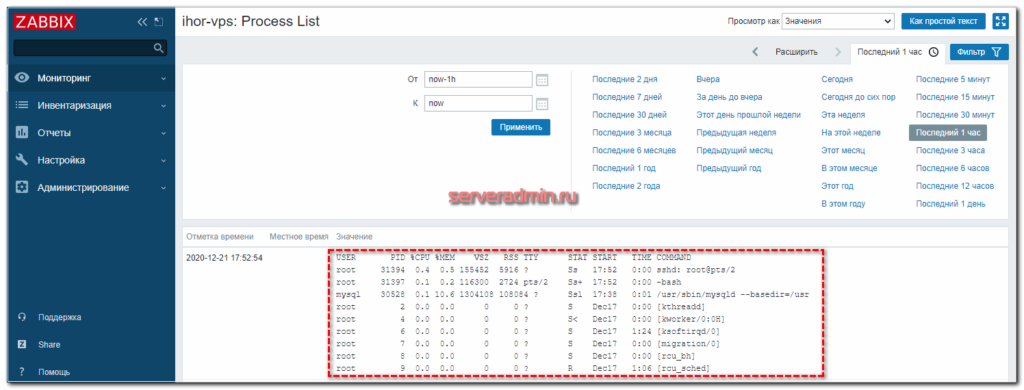
Ровно то, что нам было нужно. То же самое можно проверить с айтемом Full Process List, убрав в команде | awk ‘NR Настройка -> Действия и добавляем новое.
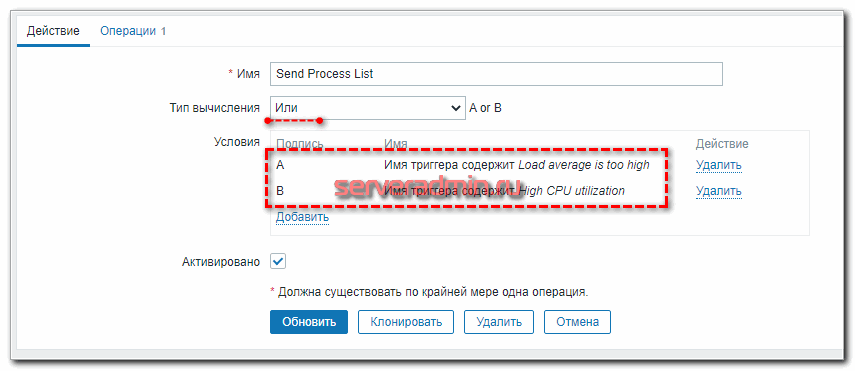
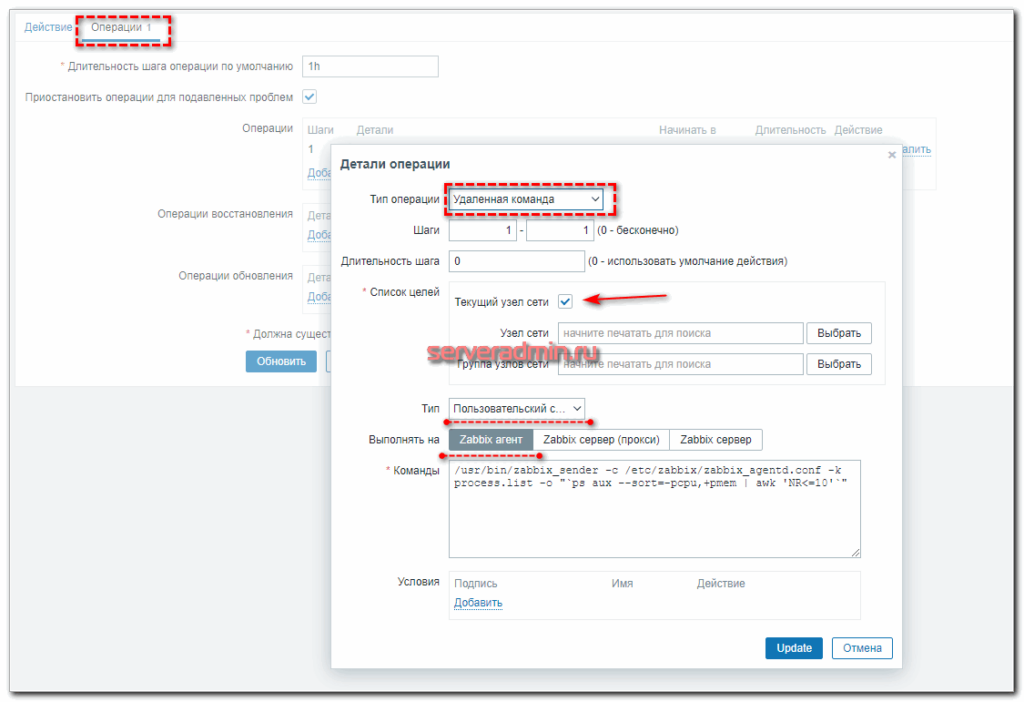
Сохраняйте действие и можно проверять.
Проверка отправки списка процессов
Теперь проверим, как все это будет работать. Для этого идем на целевой сервер и нагружаем его чем-нибудь. Я для примера запустил в двух разных консолях по команде:
Они достаточно быстро нагрузили единственное ядро тестового сервера, так что оставалось только подождать активации триггера. Через 5 минут это случилось.
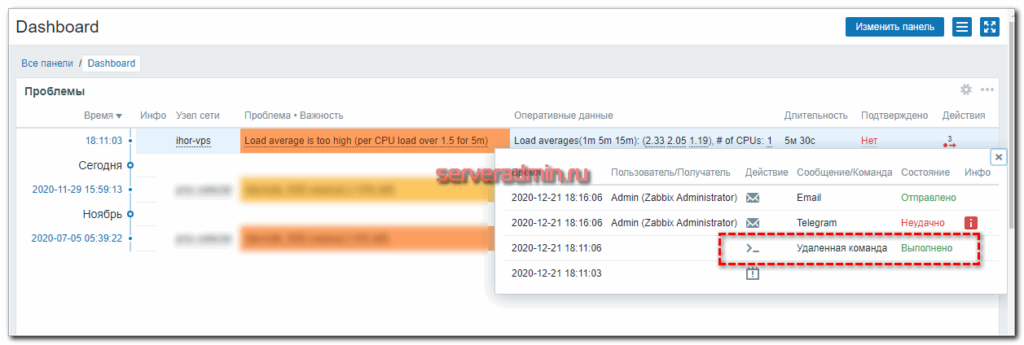
Иду в раздел Последние данные и вижу там список процессов, которые нагрузили мой сервер.
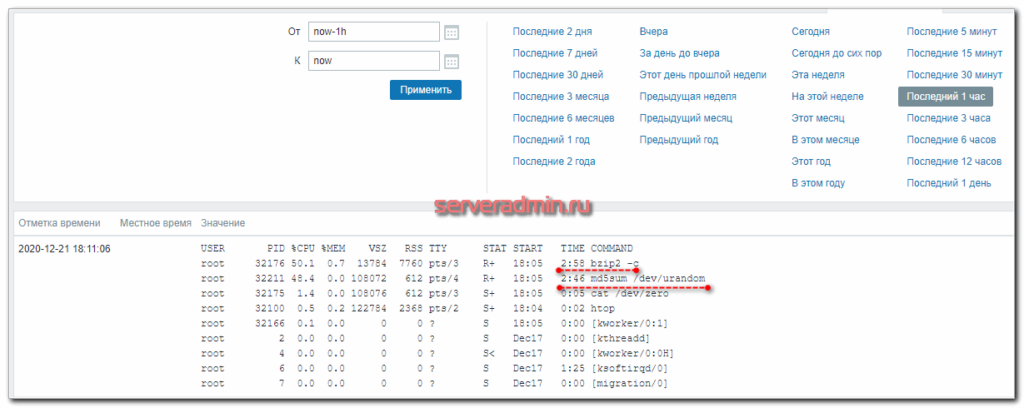
Что мне в итоге и требовалось. Теперь нет нужды каким-то образом проверять, что конкретно нагружает сервер. В момент пиковой нагрузки я получу список запущенных процессов в отдельный айтем. Для полного списка процессов все делается по аналогии.
Заключение
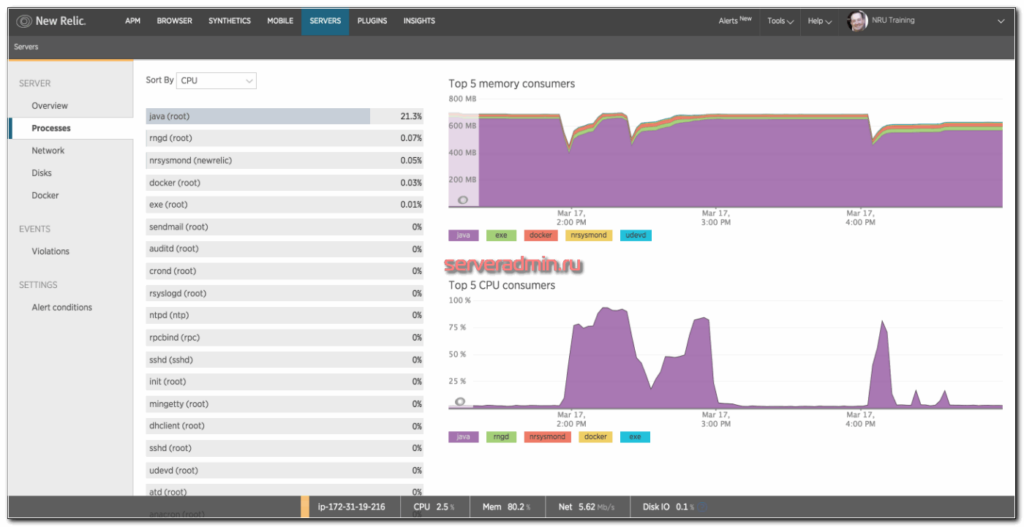
Вот такую реализацию я придумал, когда потребовалось решить задачу. Один сервер постоянно донимал оповещениями по ночам. Нужно было понять, что его дергает в это время. Жаль, что у Zabbix из коробки нет реализации подобного информирования. Помню лет 5 назад был бесплатный тариф у мониторинга NewRelic. Можно было поставить агент мониторинга на сервер и потом смотреть очень удобные отчеты в веб интерфейсе. Никаких настроек не нужно было, все работало из коробки. Там были отражены все запущенные процессы на сервере на временном ряду со всеми остальными метриками. Это было очень удобно. Я нигде в бесплатном софте не видел такой реализации. Это примерно вот так выглядело.
Кстати, в первоначальной версии действия я просто отправлял список процессов на почту. Мне показалось это удобным. Можно было сразу же в почте, в соседнем письме с триггером, посмотреть список процессов. Но потом решил, что удобнее все же хранить историю в одном месте на сервере и настроил сбор данных туда. Хотя можно делать и то, и другое. Например, в действии можно указать другую команду к исполнению:
И вам на почту придет список запущенных процессов после активации триггера.
Источник



