- Мониторинг времени отклика сайта в zabbix
- Введение
- Методика мониторинга времени ответа сервера
- Настройка мониторинга времени ответа сайта
- Заключение
- Мониторинг процесса Windows с помощью Zabbix?
- Zabbix: мониторим всё подряд (на примере Redis’а)
- Базовые понятия
- Сервер и агенты
- Параметры мониторинга
- События
- Действия и Оповещения
- Шаблоны
- Постановка задачи для плагина
- Начальное положение
- Создание собственного плагина
- Параметры мониторинга
- Основной элемент данных
- Зависимый элемент данных
- Вычисляемый элемент данных
- Триггеры
- Настройка агента
- Генерация JSON’а
- Файл userparameter_XXX.conf
- Резюме
Мониторинг времени отклика сайта в zabbix

Ранее я уже рассказывал о мониторинге web сайта в zabbix, принципиально с тех пор ничего не изменилось. Сегодня хочу подробнее остановиться на мониторинге конкретно времени отклика сайта. Последнее время этот параметр стал важным фактором ранжирования поисковых систем, поэтому ему уделяют повышенное внимание.
Введение
Как я уже сказал, статья с мониторингом web сайта актуальна и по сей день, хотя писалась для старой версии заббикса. Ни в одном из вышедших обновлений с тех пор модуль, отвечающий за мониторинг сайта, не менялся. Все осталось точно таким же, как и было. Сегодня я хочу дополнить статью некоторой информацией, плюс поделиться своими триггерами и советами по мониторингу времени отклика сайта.
Я обратил внимание на этот параметр не случайно. Последнее время поисковые системы стали внимательно относиться к времени отклика сервера с сайтом. Первым об этом заявил гугл еще несколько лет назад. В его инструменте PageSpeed Insights давно присутствует тест на время отклика сервера. Если он отвечает медленнее, чем 200 мс, то вы получаете предупреждение и рекомендации по устранению данного недостатка сервера. Некоторое время назад яндекс в вебмастере стал тоже указывать на высокое время отклика сайта, если таковое замечает.
Так что тема времени ответа сервера на сегодняшний день очень актуальна. Отдельно нужно рассматривать настройку веб сервера для уменьшения отклика. Возможно, я соберусь и напишу свои рекомендации на этот счет. А пока настроим мониторинг времени отклика сайта.
Методика мониторинга времени ответа сервера
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
То же самое на Debian 10, если предпочитаете его:
Принципиальной разницы где у вас работает сервер мониторинга zabbix нет. Я не буду останавливаться на этом моменте. Далее я считаю, что вы уже настроили мониторинг сайта по приведенной ранее статье. Дам некоторые рекомендации по ее поводу на основе последнего опыта:
- Лучше всего создавать шаблон web мониторинга, а не настраивать его на конкретном агенте. Совет этот универсальный для любых метрик, но именно для web мониторинга он более актуальный. Так вы сможете оперативно запускать проверки сайта с разных серверов, где установлены агенты забикса. Плюс, через экспорт шаблона вы легко сможете перенести мониторинг на другой сервер. Это очень важно, так как если у вас многоходовый мониторинга сайта, вручную его переносить на другой сервер очень хлопотно.
- У заббикса есть свои внутренние таймауты. Иногда я вижу в полученных данных значения, которые сильно выбиваются из общей картины. Например, у вас среднее время отклика сайта 200-300 мс. Иногда вы будете видеть на графике всплески до 1500 мс, 2500 мс, 3500 мс. Значения будут кратны одной секунде. Я не нашел подробной информации, как именно заббикс делает мониторинг сайта. Я думаю, что свыше какой-то задержки, он ждет секунду, пробует снова и так далее. Эти данные не стоит брать в расчет.
- Не стоит обращать внимание на абсолютные цифры. Все системы измеряют время отклика по-разному. В вебмастере яндекса вы увидите одно значение времени отклика сервера, в его же яндекс.метрике другое, гугл покажет третье, а заббикс четвертное. Отличаться эти значения могут существенно, в 2-3-4 раза. Я использую мониторинг времени отклика сайта в заббиксе для отслеживания динамики. К примеру, вы решили переехать на новый web сервер. Нужно как-то оценить его быстродействие. Вы сравниваете значения в мониторинге на старом сайта, потом на новом и делаете выводы.
По последнему пункту приведу простой пример из недавнего опыта. Я подготовил новый веб сервер. Нужно было оценить, насколько он быстрее работает на том же сайте, чем предыдущий. Я развернул сайт на новом сервере, поправил в файле hosts на сервере с заббикс агентом ip адрес сайта, направив запросы на новый web сервер. Получилась такая картинка.
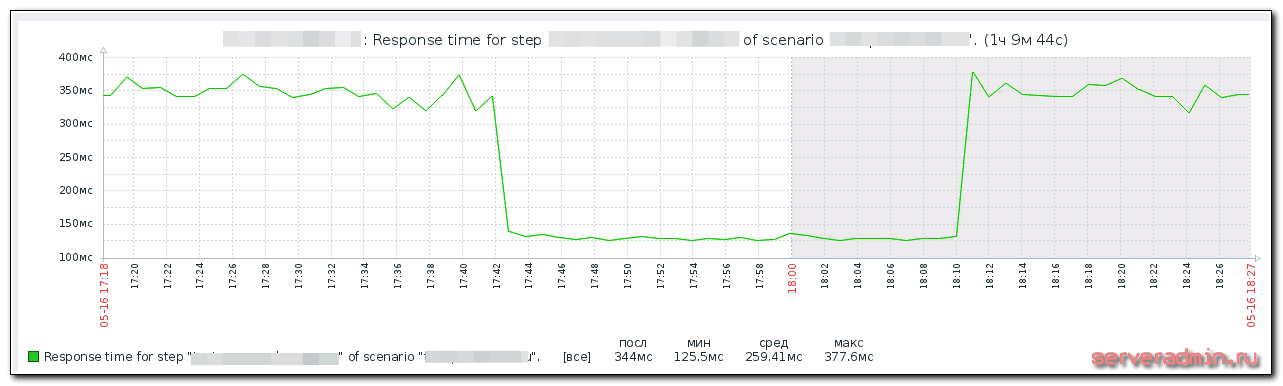
Сначала идет мониторинг реального сайта на текущем сервере, потом я переключаю запросы zabbix на новый сервер. Убедившись, что сайт на новом веб сервере отвечает быстрее, переключаю мониторинг обратно на старый сервер.
Понятно, что тест очень условный. Новый сервер стоит без нагрузки, отвечает стабильно, без пилы на графике. И тем не менее, я понимаю, что на нем будет лучше. Зачастую время отклика сайта зависит от факторов, которые вы не можете оценить заранее:
- Сетевую систему хостера
- Отклик жестких дисков
- Загруженность ноды виртуальных машин, если переезжаете на VDS.
Вы можете заказать сервер с хорошими параметрами по железу, но не получить быстрого отклика сайта по независящим от вас причинам. С этим столкнулся не так давно, когда пробовал использовать веб сервер у облачного провайдера. На словах все красиво — гибкая настройка параметров, отказоустойчивость, удобный бэкап и т.д. В общем, все то, чем хвалят облака. А на деле время отклика сайта было 300-400 мс при типовых настройках веб сервера. Использовался самый дорогой и быстрый тип диска. На выделенном бюджетном сервере при тех же настройках отклик был 100 мс.
Несмотря на всю условность подобного теста, он отвечает на поставленный вопрос — будет ли сайт после переезда на новый сервер отвечать быстрее. Я несколько раз проверял данную методику, в том числе и на своем сайта, не так давно переехав на новое место, так как старый виртуальный сервер стал работать заметно медленнее.
Настройка мониторинга времени ответа сайта
Выше я описал одно применение мониторинга времени отклика сервера, когда надо оценить эффективность переезда на другой сервер. Дальше я расскажу, как настроить мониторинг времени отклика сайта, с оповещением в случае снижения быстродействия, для контроля за работой сайта.
В принципе, ничего особенного делать не надо. Я просто поделюсь своим триггером, который я использую для адекватной реакции на замедление ответа сайта.
Итак, сначала мы настраиваем мониторинг сайта стандартным способом. Ждем некоторое время, чтобы накопились значения в итеме Response time. Возьму для примера свой сайт. Вот мой график ответа главной страницы сайта за последние 3 часа.
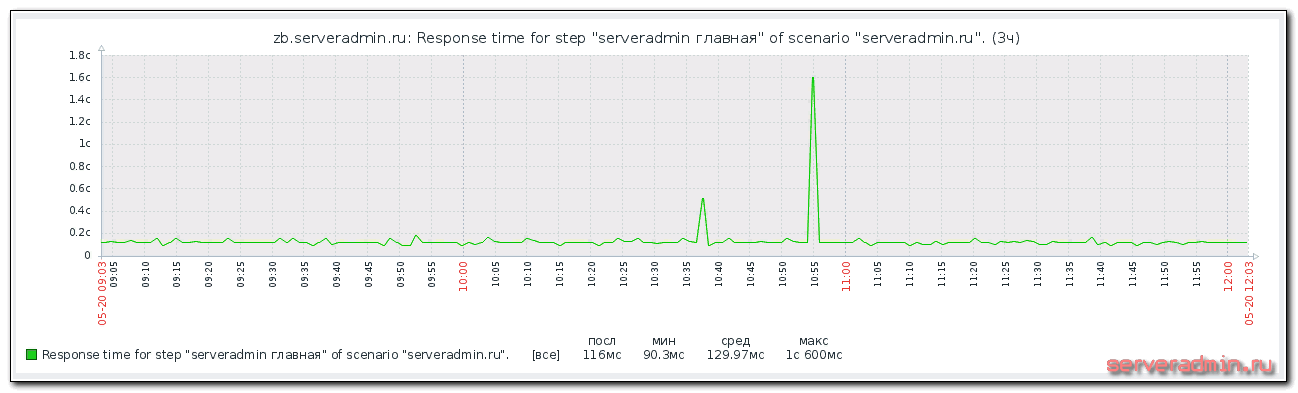
На графике хорошо видно всплеск, о которых я писал выше, с очень большим временем отклика. Не обращаем на него внимания. Я вижу, что мой сайт почти всегда отвечает быстрее 200 мс. Настроим триггер, который будет оповещать меня о том, что мой сайт стал работать медленнее. Я предлагаю такую настройку триггера.
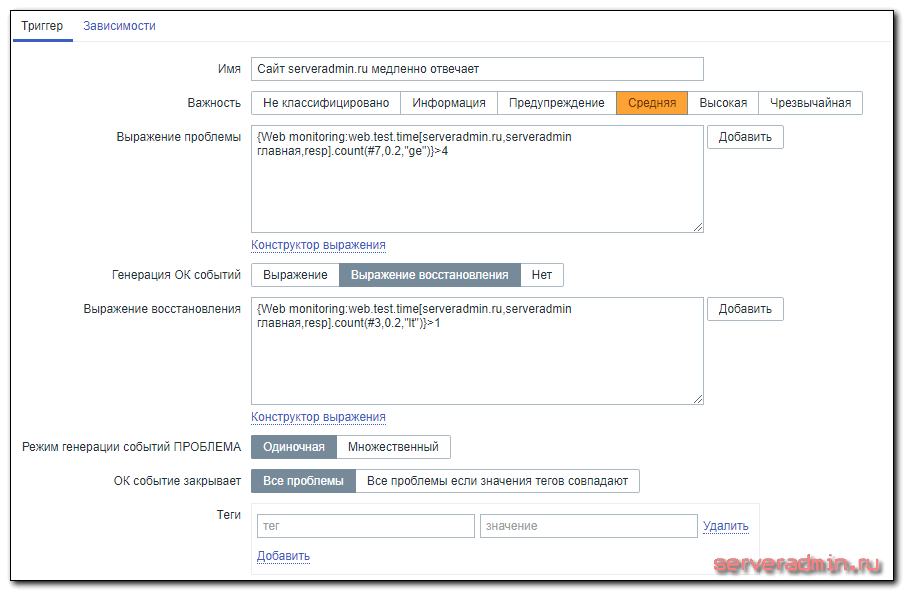
Для определения проблемы медленного отклика сайта я беру 7 последних значений из итема Response time for step, сравниваю их со значением 0.2 с. Если среди этих 7-ми значений более 4-х (5 и более) окажутся выше, чем 0.2, я считаю, что с быстродействием сайта проблемы и шлю оповещение.
После того, как в трех последних значениях, более одного будут ниже 0.2, проблемы нет. То есть, если в трех последних значениях, 2 будут ниже 200 мс, то все в порядке.
Цифры в триггере получены экспериментальным путем. Возможно, у вас имеет смысл использовать другие. Я их менял по мере калибровки системы. С другими цифрами было либо много ложных срабатываний, либо не замечал вовремя проблемы.
Не стоит забывать и то, что время отклика, которые вычисляет мониторинг заббикс, зависит напрямую от работы самого заббикса. Если у вас сервер с агентом тормозит или имеет сетевые проблемы, вы будете получать оповещения о медленной работе сайта, хотя с ним все в порядке. Если такие явления будут часты, то стоит переделать триггер, включив его срабатывание только если 2 и более агента получают высокие значения отклика сайта. Это не сложно, но я не привожу пример, так как сам его не использовал и не отлаживал.
Заключение
Настройка качественного мониторинга непростая задача. В том, что я описываю, есть много подводных камней, неточностей и неудобства. Я это прекрасно вижу и понимаю. Но так как у меня нет специализации только на мониторинге, не имею возможности все делать качественно и основательно. Для меня заббикс это вспомогательный инструмент, помогающий в работе.
Мониторинг, сделанный на основе стандартных шаблонов или с помощью небольших локальных изменений, помогает в основном, в самых простых случаях среагировать на нештатную ситуацию, либо потом с помощью сырых данных постфактум проанализировать ситуацию.
Для того, чтобы мониторинг работал четко, без ложных срабатываний, своевременно оповещал о проблемах, с ним нужно плотно и много работать. Насколько это оправданно, каждый решает для себя в конкретной ситуации.
Мониторинг процесса Windows с помощью Zabbix?
Как организовать мониторинг процессов windows c помощью zabbix? Интересует способ узнать сколько процентов от общего ресурса процессора потребляет тот или иной процесс.
Версия Windows: Windows 10 pro 1909 x64
Версия zabbix сервера: 4.4.3
Способ снятия метрик: активный агент
- Вопрос задан более года назад
- 1210 просмотров
1.открываем perfmon.msc (не перепутайте с perfmon.exe — это немного другая программа.)
2.в «системном мониторе» (сейчас под рукой руссифицированная ось, поэтому ищите аналогичное на английском, благо монитор по умолчанию там один) нажимаем «добавить счетчики»
3. выбираем Process и ваш процесс, нужные метрики.
Все это только для понимания «что» вы будете мониторить.
теперь «как»: идем и внимательно читаем:
https://www.zabbix.com/documentation/4.2/ru/manual.
https://www.zabbix.com/documentation/4.2/ru/manual.
В последней статье ищем proc_info — это оно и есть
Если есть какие то перфкаунтеры которых вы не нашли в заббикс — в 1й статье в конце есть как добавить нужные через user parameters
Почему perfcounters а не WMI? Потому что обращение к WMI — довольно дорогая операция, часто не позапрашиваешь (а если залезть в глубины того что доступно через WMI — выяснится что там те же перфкаунтеры, облагороженные и обогащенные) — частое обращение довольно сильно жрет CPU
Почему не сторонняя программа? Потому что Win уже собирает данные процессов и основная задача — добраться до них
Zabbix: мониторим всё подряд (на примере Redis’а)
Zabbix — замечательный продукт для администраторов крупных программно-аппаратных комплексов. Он настолько хорош, что может использоваться не только крупным бизнесом, но и средне-малым бизнесом, и даже в pet -проекте. В общем, у меня есть небольшой опыт работы с Zabbix’ом и я смело могу рекомендовать его к использованию.
Правда я не могу сказать, что понимаю «философию Zabbix’а«. Несмотря на обширную подробную документацию на русском языке, мне было сложно погружаться в мир Zabbix’а — создавалось ощущение, что мы с разработчиками одни и те же вещи называем разными именами. Возможно потому, что Zabbix создавался админами для админов, а я всё-таки больше разработчик и пользователь.
Тем не менее, для запуска Zabbix’а и для мониторинга основных параметров компьютерных систем (процессор, память и т.п.) навыков обычного linux-пользователя хватает. Есть большое количество плагинов от сторонних разработчиков, расширяющих возможности Zabbix’а. Для моих нужд мне потребовалось настроить мониторинг Redis-сервера. Я немного покопался в коде имеющихся плагинов и на их примере выяснил, что архитектура Zabbix’а позволяет достаточно просто подключать к мониторингу любые параметры информационных систем, которые могут быть выражены в числовом виде.
Под катом — пример Zabbix-плагина с моим пояснением по терминологии Zabbix’а. Кому-то этот пример покажется наивным, ну а кому-то поможет проще освоиться с понятиями. В любом случае, Zabbix достаточно велик для того, чтобы ощупать его с разных сторон.
Базовые понятия
Кратко о некоторых понятиях, которые используются в Zabbix’е: agents, items, triggers, actions, notifications, templates.
Сервер и агенты
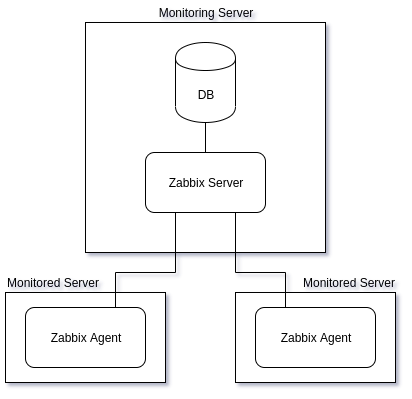
С точки зрения пользователя Zabbix делится на две большие части: сервер и агенты. Сервер располагается на одной машине, которая собирает и хранит статистические данные, а агенты — на тех машинах, данные с которых собираются:
Параметры мониторинга
Любая величина, которая может выражена в числовом или строковом виде, называется в терминологии Zabbix’а — элементом данных (item). Каждый элемент связывается с уникальным ключом (именем). Вот примеры элементов данных:
- system.cpu.load[percpu,avg1]: 0.1167
- system.uname: «Linux supru 4.15.0-50-generic #54-Ubuntu SMP Mon May 6 18:46:08 UTC 2019 x86_64»
Значения этих элементов данных (параметров мониторинга) привязываются ко времени, история значений параметров сохраняется в базе сервера.
События
При наступлении некоторого события в Zabbix’е срабатывает триггер. Например,
По сути, триггеры — это формулы, в которых переменными выступают параметры мониторинга (текущие и сохранённые), и которые на выходе дают true / false .
Действия и Оповещения
В случае наступления события (срабатывания тригера) сервер может выполнить действие. Например, отправить оповещение по email’у на заданный адрес («Problem: host is unreachable for 5 minutes«). Также действие может быть выполнено в случае возвращения триггера в исходное состояние («Resolved: host is unreachable for 5 minutes«). Все события (переключения триггера) логируются на стороне сервера.
Шаблоны
Zabbix даёт возможность как настроить правила мониторинга для отдельного хоста, так и создать шаблон правил (template), который можно применять к различным хостам:
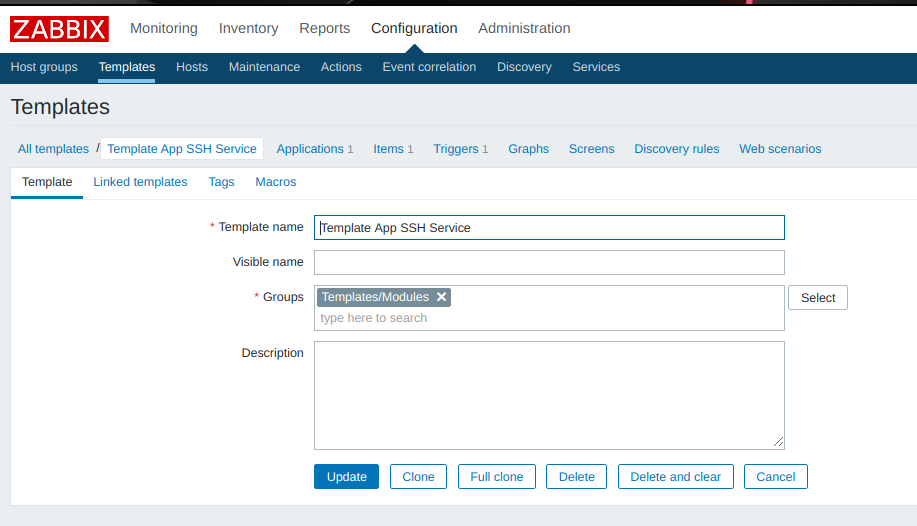
На примере видно, что шаблон «Template App SSH Service» описывает одно приложение (Applications), один параметр мониторинга (Items), один триггер (Triggers). Также доступны описания для графиков, экранов, правил обнаружения и web-сценариев.
Постановка задачи для плагина
Начальное положение
Сам Zabbix предлагает свой собственный плагин для мониторинга состояния Redis’а, но на моей версии сервера (4.2.8) мне не удалось его задействовать (плагин для версии 4.4 и выше). Также предлагаются решения от третьих лиц (около десятка вариантов под различные версии Zabbix’а, на картинке только первых три):

Каждый из них обладал своими плюсами-минусами, пришлось заглянуть внутрь, чтобы выбрать. Лучшим, на мой взгляд, оказался плагин Shakeeljaveed/zabbix-redis-userparamaters, состоявший из двух файлов:
Немножко пришлось поработать «ручками», но зато на его примере стало чуть понятнее, как данные от агента попадают на сервер. По предложению автора Javeed Shakeel состояние Redis’а каждые 2 минуты сбрасывалось кроном в файл /tmp/redismetric :
А затем каждый параметр мониторинга извлекался агентом из файла /tmp/redismetric при помощи средств самой операционной системы. Инструкции для этого размещались в конфигурации Zabbix-агента /etc/zabbix/zabbix_agent.conf.d/userparameter_redis.conf . Например, вот так выглядят инструкция для извлечения параметра used_memory (использование памяти Redis-сервером):
То есть, в файле /tmp/redismetric с выводом redis-cli INFO по ключу used_memory ищется строка ( grep -w . )
которая затем разбивается на столбцы по разделителю «:» ( cut -d: -f2 ). На выходе агент получает число 7153216 и присваивает его параметру used_memory .
Остаётся через web-интерфейс настроить сервер, чтобы он периодически отправлял запросы агенту на получение данных по параметру used_memory , после чего данные начинают литься на сервер, сохраняться в базе, по ним можно строить графики и создавать триггера, реагирующие на изменения этого параметра.
Задачей мониторинга состояния любой системы явлется не только сбор статистики, но и предупреждение о возникновении ситуаций, требующих вмешательства человека. Так как с Redis’ом я работаю на уровне очень начинающего пользователя, то пришлось поискать информацию, на какие параметры «здоровья» обращать внимание и что они значат. Наиболее достойной показалась статья «6 Crucial Redis Monitoring Metrics You Need To Watch». Проанализировав её, я пришёл к выводу, что «для полного счастья» мне нужно собирать данные для обнаружения следующих событий:
- Memory fragmentation: used_memory_rss / used_memory > 1.5
- Low cache hit ratio: (keyspace_hits)/ (keyspace_hits + keyspace_misses) 0
- Evicted keys: evicted_keys > 0
Также я хотел собирать статистику по дополнительным параметрам (версия Redis’а, uptime и т.п.). В общем, имея общее представление о том, каким образом данные собираются агентом и передаются на сервер, «хотелки» можно сильно не ограничивать. В итоге получился список параметров для мониторинга из 12 позиций.
Создание собственного плагина
Параметры мониторинга
Плагин, который я анализировал, предполагал выполнение отдельной команды для получения отдельного параметра (элемента данных, item’а):
Т.е., для получения данных по 12 параметрам агент должен будет 12 раз выполнить различные наборы команд. А если мне нужно мониторить параметры, которые сложно извлечь цепочкой команд и нужно будет писать отдельный shell-скрипт или полноценную программу? Для таких «хотелок» Zabbix предлагает вариант с зависимыми элементами данных. Суть его в том, что на стороне агента скриптом формируется набор данных (например, в формате JSON), который передаётся на сервер в виде строкового параметра. Затем на стороне сервера происходит разбор полученных данных и вычленение из них отдельных элементарных параметров.
Основной элемент данных
Я описал основной элемент данных redis.info строкового типа с периодом обновления в 1 мин., без сохранения истории изменений:
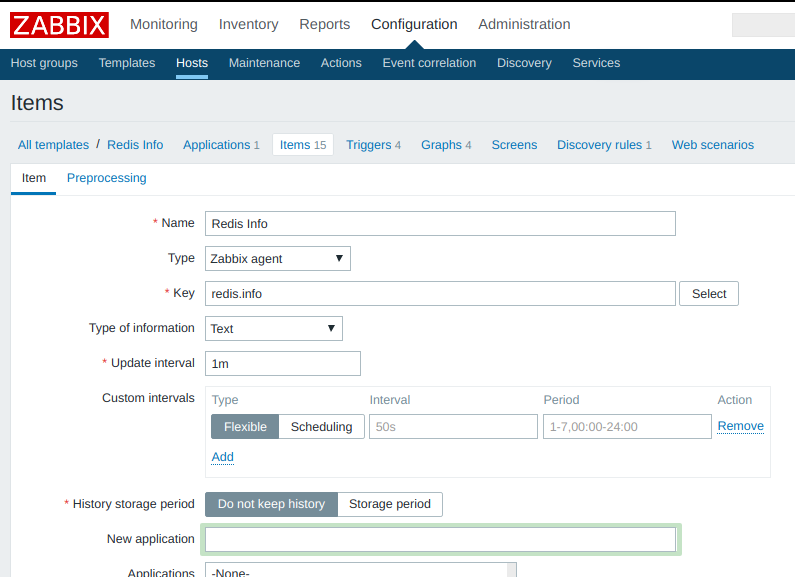
Предположительно, на стороне агента должен генерироваться такой JSON:
после чего этот текст должен попадать на сервер в виде элемента данных redis.info , но не сохраняться, а служить базой для других элементов данных (параметров мониторинга).
Зависимый элемент данных
Тестовый параметр redis.info.version зависит от redis.info и сохраняет свои значения в базе в течение 90 дней. Периодичность мониторинга параметра зависит от базового элемента ( redis.info ):
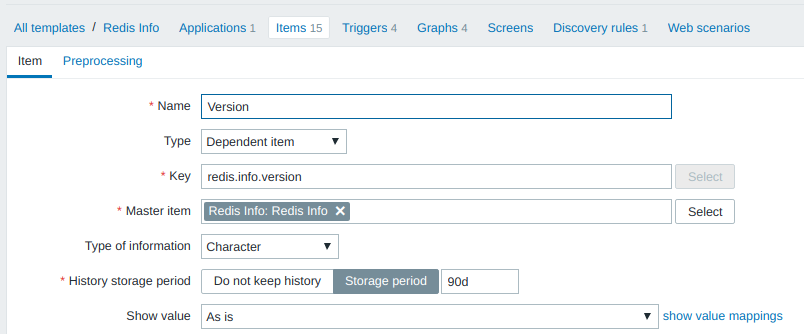
Значение параметра redis.info.version извлекается из значения redis.info при помощи инструкций JSONPath:
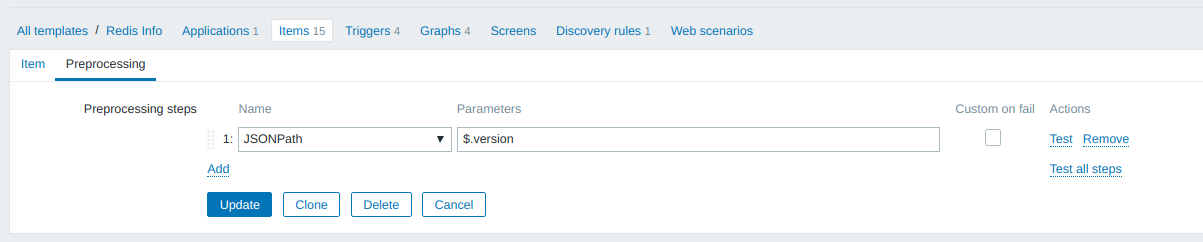
По аналогичной схеме описываются остальные зависимые элементы данных (параметры мониторинга), которые передаются в виде JSON’а. Вот пример описания числового параметра redis.info.used_memory :
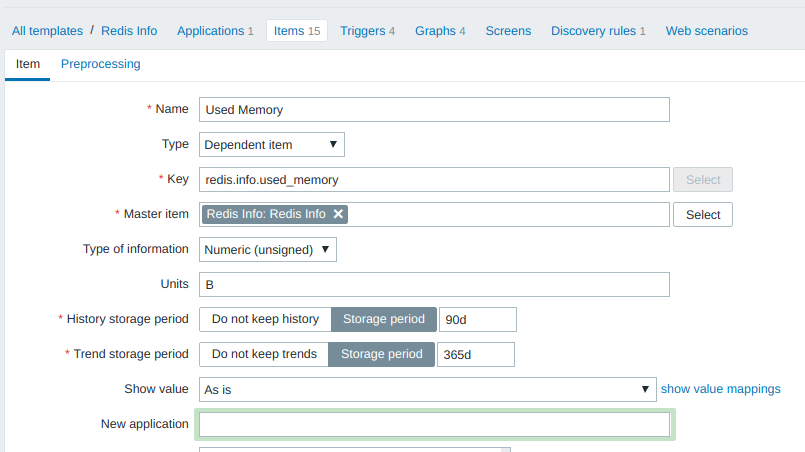
Всё достаточно прозрачно, за исключением Units и Trend storage period . Со вторым пунктом я не разбирался, оставил по-умолчанию, а единицы измерения объяснены в документации. В данном случае значение redis.info.used_memory измеряется в байтах и в web-интерфейсе сворачивается до кило/мега/гига/. -байт.
Формула для извлечения значения из JSON’а: JSONPath = $.used_memory
Вычисляемый элемент данных
Для вычисления фрагментации памяти используется отношение used_memory_rss / used_memory и на его базе определяется триггер, срабатывающий при превышении отношением значения 1.5. В Zabbix’е есть вычисляемый тип элементов данных:
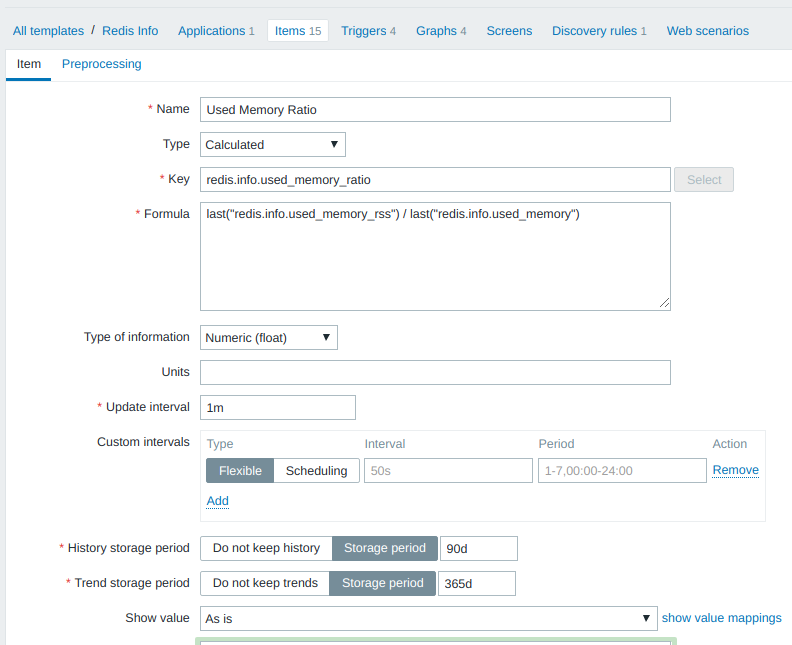
Значение для параметра redis.info.used_memory_ratio вычисляется каждую минуту на основании последних значений двух других параметров ( redis.info.used_memory_rss и redis.info.used_memory ), сохраняется в базе в течение 90 дней и т.д.
Триггеры
Вот пример триггера, срабатывающего при излишней фрагментации памяти:
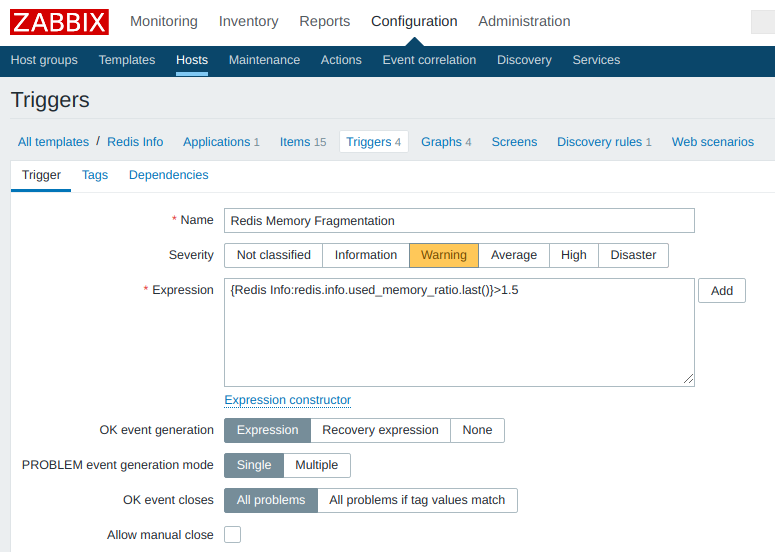
Ничего необычного, за исключением формата выражений, используемого в формуле изменения состояния триггера. В Zabbix’е есть конструктор форм, можно воспользоваться им или обратиться к документации/примерам (список триггеров доступен через web-интерфейс по адресу «Configuration / Templates / $
Триггер может базироваться на любых элементах данных (item’ах) вне зависимости от их типа (основной, зависимый, вычисляемый).
Настройка агента
Генерация JSON’а
Для получения значений параметров мониторинга и формирования JSON’а я использую вот такой shell-скрипт:
Этот скрипт я поместил в файл /var/lib/zabbix/user_parameter/redis/get_info.sh на сервере с Redis’ом, на котором уже установлен агент Zabbix’а. Пользователь, под которым запускается Zabbix-агент (обычно zabbix ) должен иметь права на выполнение файла get_info.sh .
Файл userparameter_XXX.conf
На стороне агента дополнительные параметры мониторинга прописываются в файлах userparameter_*.conf в каталоге /etc/zabbix/zabbix_agentd.d . Поэтому для того, чтобы агент узнал о том, каким образом ему нужно собирать данные по параметру redis.info , я создал файл /etc/zabbix/zabbix_agentd.d/userparameter_redis.conf с таким содержимым:
Т.е., для получения данных по параметру redis.info агент должен запустить скрипт /var/lib/zabbix/user_parameter/redis/get_info.sh и передать на сервер результат выполнения.
После рестарта Zabbix-агента ( sudo service zabbix-agent restart ) у него появляется возможность собирать данные для параметра redis.info и отправлять их на сервер.
UPDATE: коллега banzayats обратил внимание, что текстовые данные с хоста можно получить без создания промежуточного скрипта userparameter_*.conf — при помощи параметра » system.run » и проводить постпроцессинг уже на стороне zabbix-сервера.
Резюме
Понимание Zabbix’а ко мне приходило (и всё ещё приходит) достаточно тяжело. Тем не менее я считаю его прекрасным инструментом, особенно после того, как для меня открылась простота добавления собственных параметров мониторинга (элементов данных). По большому счёту, достаточно добавить один файл на сервер с агентом ( userparameter_XXX.conf ) с shell-командой для сбора данных и настроить Zabbix-сервер на получение этих данных через web-интерфейс. И всё — можно накапливать данные, строить графики, анализировать изменения и создавать триггера, реагирующие на эти изменения.
Код шаблона, файла userparameter_redis.conf и скрипта get_info.sh можно посмотреть в проекте flancer32/zabbix_plugin_redis.
Спасибо всем, кто дочитал до конца, а особенно тем, кто нашёл в публикации что-то полезное для себя.



