- Мониторим всё: расширение агентов Windows и Linux при помощи скриптов
- Немного матчасти
- Мониторинг SMART через UserParameter
- Мониторинг SMART через Flexible UserParameter
- Мониторинг SMART через Flexible UserParameter c Low-level Discovery
- Контроль за установкой новых программ на Windows
- В итоге
- ZABBIX — Настраиваем мониторинг служб
- ZABBIX — Настраиваем мониторинг служб.
- Создаём элемент данных.
- Мониторинг доступности службы linux с помощью Zabbix
- Введение
- Описание работы простых проверок (simple check)
- Мониторинг доступности сервиса по сети
- Мониторинг локальной службы в linux
- Заключение
Мониторим всё: расширение агентов Windows и Linux при помощи скриптов
Если нам нужно мониторить состояние серверов и прочих компьютеризированных рабочих мест при помощи Zabbix, то это можно сделать двумя способами.
Первый способ — это при помощи SNMP-запросов, с отправкой которых Zabbix замечательно справляется. Так можно вытащить и загрузку сетевых интерфейсов, и загрузку процессора, памяти. Поверх этого, производители сервера могут выдать нам по SNMP еще много информации о состоянии железа.
Второй заключается в использовании Zabbix агента, который мы будем запускать на наблюдаемой системе. Список наблюдаемых параметров включает в себя как и такие простые вещи, как загрузка процессора, использование памяти, так и более хитрые, такие как чтение текстовых лог-файлов с поддержкой ротации или отслеживание факта изменения любого файла. Можно даже в качестве параметра использовать вывод любой произвольной команды на системе. Возможности Zabbix агента растут от версии к версии.

Что делать, если того, что мы хотим контролировать через Zabbix нет в списке возможностей Zabbix агента? Ждать пока это имплементируют разработчики в следующем релизе? Не обязательно.
Нам оставили несколько стандартных интерфейсов для того, чтобы расширить возможности Заббикса по мониторингу серверов настолько, насколько позволит нам наша фантазия и наличие свободного времени на написание скриптов. Интерфейсы эти UserParameter и zabbix_sender. О первом и пойдет речь, а в качестве примеров будет показано как можно собирать состояние S.M.A.R.T жестких дисков и контролировать, когда кто-то удаляет или устанавливает новые программы на своей Windows-машине.
Немного матчасти
Если вы уже хоть раз настраивали Zabbix агент на сервере, то начать использовать UserParameter не составит труда. Чтобы добавить новый параметр нужно сделать несколько вещей:
- Добавить в конце конфигурационного файла zabbix_agentd.conf строчку вида
где:
— уникальное имя, которое мы придумываем сами. Будем его использовать при настройке элемента данных в Zabbix.
— команда, которую нужно выполнить на наблюдаемом узле сети.
А вот сразу очень простой пример, который лежит в каждом стандартном конфиге для Linux:
Итак, ключ здесь system.test, а выполняем команду who | wc -l, которая возвращает нам количество открытых сессий в системе. Добавляем (или раскомментируем данную строчку если уже есть), идем дальше.
- В Веб-консоли Zabbix создать новый элемент данных с ключом, который мы использовали, если брать пример выше, то это system.test.
Для этого нажимаем «Создать элемент данных»
и затем выставляем ключ такой же, как указали в конфиг-файле, а тип Zabbix агент:
- Перезагрузить Zabbix агента, чтобы изменения в конфиг-файле вступили в силу
Наблюдаем результат в последних данных:
Мониторинг SMART через UserParameter
Пример выше имеет мало практического применения, учитывая, что уже итак существует стандартный ключ system.users.num, который делает ровно тоже самое.
Так что теперь рассмотрим пример, который уже больше будет походить на реалистичный.
Если нам интересно мониторить момент, когда пора планово менять жесткие диски, то есть два варианта:
- Если диски за аппаратным RAID-контроллером, то, как правило, сами диски операционная система «не видит». Поэтому ищем способы как вытащить информацию о состоянии жестких дисков через утилиты или SNMP-сабагента, которые нам любезно предоставил(или не предоставил) производитель RAID-контроллера. Для каждой отдельной серии контроллеров свой путь до этой информации.
- Если речь идет о просто рабочих станциях, серверах с софтовом RAID и т.д., то тогда к дискам есть доступ из операционной системы, и мы вольны использовать различные утилиты для чтения их статуса. В случае Zabbix нам подходит утилита smartctl, из пакета SMARTMONTOOLS.
В Debian установка SMARTMONTOOLS сводится к:
и утилита готова к использованию.
Для каждого диска, который есть в системе сначала проверим, что SMART включен:
если вдруг SMART поддерживается диском, но выключен, то активируем его:
Теперь мы можем проверять статус SMART командой:
Именно эту команду мы и запишем в наш zabbix_agentd.conf:
где uHDD.health — ключ.
Мониторинг SMART через Flexible UserParameter
Тут возникает резонный вопрос, как быть если дисков два. Легче всего решить эту проблему поможет способность UserParameter передавать параметры агенту, про которую мы еще не упоминали. Но делается все очень просто, сразу пример:
В веб-интерфейсе Zabbix в ключе мы будем подставлять параметры в квадратные скобки вместо *. Например, для одного элемента данных мы напишем sda, а для другого sdb. В команде этот параметр найдет отражение там, где стоит переменная $1.
Создадим для второго диска элемент данных:
И через некоторое время сможем наблюдать результат в последних данных:
Мониторинг SMART через Flexible UserParameter c Low-level Discovery
Все получилось. Но тут возникает резонный вопрос, как быть если дисков не два, а двадцать два. И тут нам пригодится замечательная возможность низкоуровнего обнаружения (LLD), про которую мы уже говорили.
Низкоуровневое обнаружение позволяет системе мониторинга обнаруживать какое количество однотипных элементов присутствует на узле сети и динамически по шаблону создавать необходимые элементы данных, триггеры и графики для этих элементов. «Из коробки» системе доступна возможность находить файловые системы, сетевые интерфейсы и SNMP OID’ы. Однако, и здесь разработчики оставили возможность дополнить стандартные возможности, нужно просто передать в систему информацию о том, какие элементы обнаружены в формате JSON. Этим и воспользуемся.
Создадим маленький скрипт на perl, smartctl-disks-discovery.pl. Он будет находить все диски в системе и выводить эту информацию в JSON, передавая также информацию, включен ли у диска SMART или нет, а также попытается сам включить SMART, если он выключен:
При запуске скрипт выдает:
Теперь, для того чтобы скрипт автоматически запускался Zabbix’ом, просто добавим еще один UserParameter в zabbix_agentd.conf:
Покончив с настройкой конфига, переходим в веб-интерфейс, где создаем новое правило обнаружения для smartctl:
Обратите внимание на ключ и на фильтр, (<#SMART_ENABLED>=1) благодаря последнему будут добавляться только те обнаруженные диски, которые поддерживают SMART. Теперь мы можем переписать два наших элемента данных для дисков sda и sdb в один прототип элементов данных, просто заменив имя диска на макрос <#DISKNAME>:
Последнее, перед тем, как Zabbix сможет запускать команды, которые мы прописали в zabbix_agentd.conf из-под root и мониторить SMART, нужно добавить разрешения для его пользователя запускать эту команду без ввода пароля, для этого добавим в /etc/sudoers строчку:
Готовый шаблон для мониторинга SMART с остальными элементами данных, триггерами прикладываю, так же как и настроенный под него конфиг.
Контроль за установкой новых программ на Windows
Zabbix агент, установленный на Windows, точно также может быть расширен через UserParameter, только команды будут уже другие. Хотя, например, smartctl — кроссплатформенная утилита, и точно также можно ее использовать для контроля за жесткими дисками в Windows.
Кратко рассмотрим еще другой пример. Задача получать уведомление каждый раз, когда пользователь самостоятельно удаляет или устанавливает программы.
Для этого будем использовать наш vbs-скрипт:
Для его интеграции с Zabbix добавим UserParameter в конфиг-файл:
Добавим элемент данных в шаблон для Windows:
Добавим триггер:
и действие, которое будет отправлять e-mail уведомление:
Весь процесс мониторинга выглядит так: каждый час запускается скрипт Zabbix агентом, который сравнивает два списка программ: текущий и предыдущий. Затем скрипт выписывает все изменения в отдельный файл. Если же изменений нет, то в файл пишется 0x0
Содержимое файла уходит на Zabbix сервер, где поднимается триггер в случае, если значение элемента данных uDiffProgramms отлично от 0x0. Затем отдельное действие отправляет по почте уведомление со списком того, что было установлено или удалено на данном компьютере:
В итоге
UserParameter — отличная и простая возможность расширить функционал системы самостоятельно. Стоит упомянуть и альтернативы: zabbix_sender, который, например, подойдет для тех случаев, когда нужно отправлять данные в Zabbix не по расписанию, (как это делает UserParameter), а по какому-то событию; и system.run[], который похож на UserParameter, но удобнее тем, что не нужно вносить изменения во все конфиги агентов, достаточно просто добавить этот элемент данных в шаблон. Более того, в следующем крупном релизе Zabbix 2.2 нас ожидает еще один новый способ расширить возможности агента- это подключаемые модули. Ждем с нетерпением!
Вот так, считайте, что если вы можете узнать что-то о системе скриптом или командой, значит, вы всегда можете передать это в Zabbix.
Источник
ZABBIX — Настраиваем мониторинг служб
 Всем привет, часто возникает необходимость настроить мониторинг различные службы и всегда знать если что-то упало. В данной статье расскажу о том как настроить мониторинг служб по средствам Zabbix.
Всем привет, часто возникает необходимость настроить мониторинг различные службы и всегда знать если что-то упало. В данной статье расскажу о том как настроить мониторинг служб по средствам Zabbix.
ZABBIX — Настраиваем мониторинг служб.
Создаём элемент данных.
Для начала необходимо выбрать наш шаблон, к которому привязан интересующий нас узел сети, если его нет создаём, о том как создать шаблон можете прочитать тут: ZABBIX — Новый шаблон. В нашем случае шаблон у нас уже есть с привязанным к нему узлом сети. Переходим в “Настройка” -> “Шаблоны” -> Выбираем наш шаблон ->Выбираем “Элементы данных” и нажимаем кнопку “Создать элемент данных”
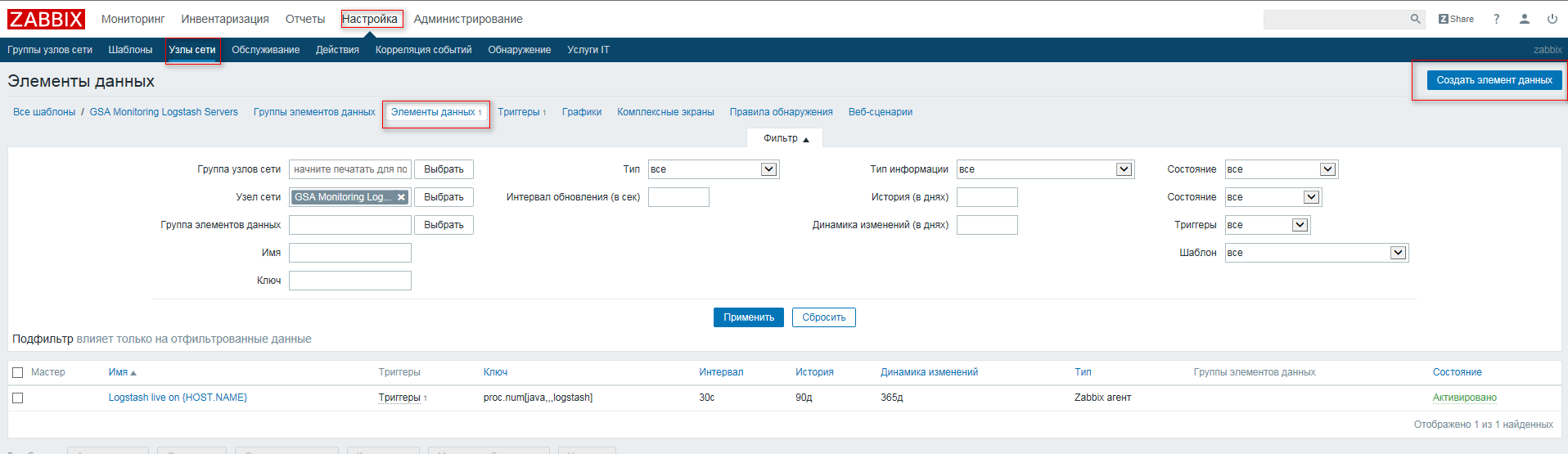
Zabbix-создаём элементы данных
Дальше необходимо вписать наши условия, оставляем все пункты по умолчанию, кроме “Имя” и “Ключ”. Вписываем любое угодное нам имя и в поле ключ нажимаем “Выбрать”
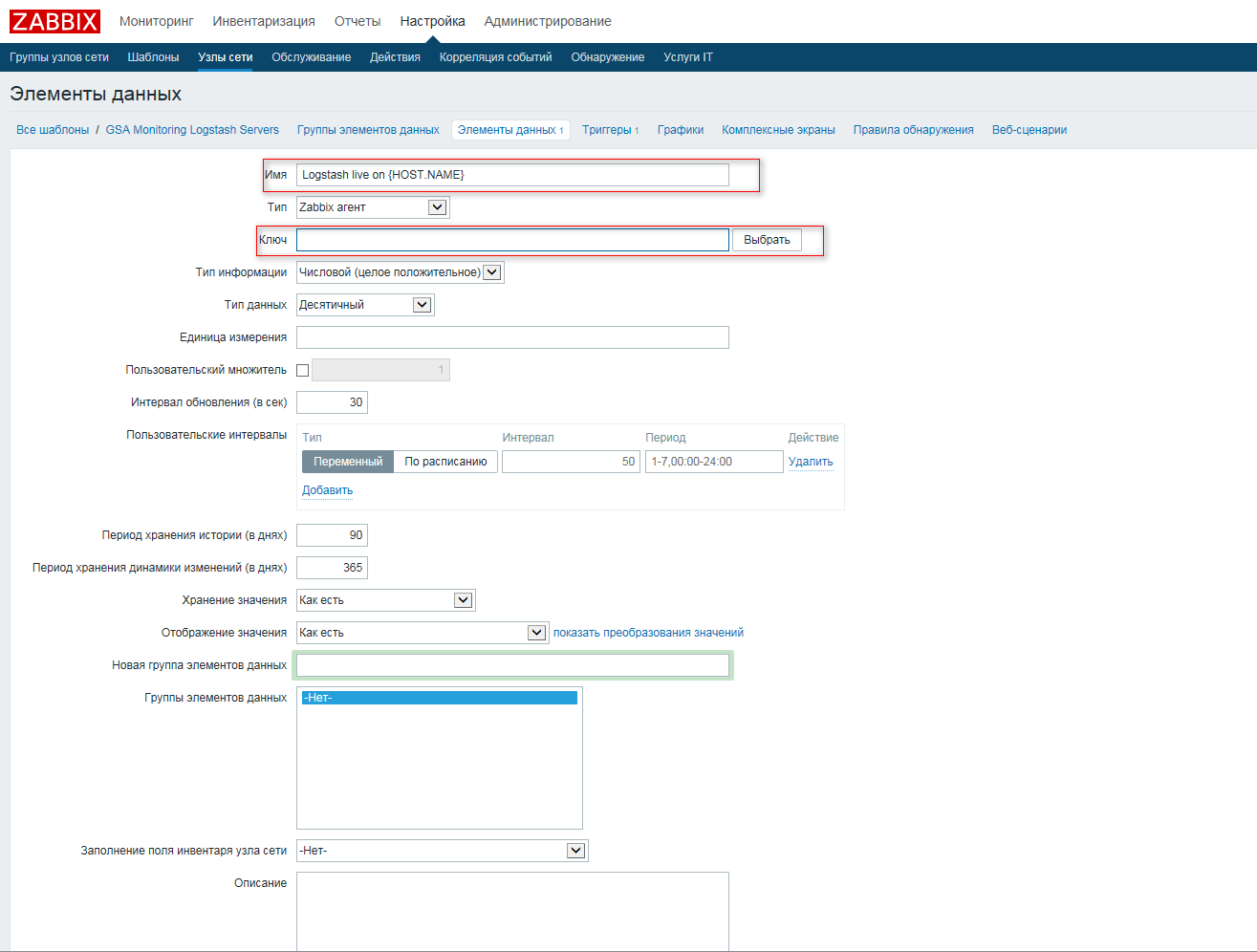
Ищем в списке ключ “proc.num[ , , , ]”, выбираем его.
Вот что про данный ключ пишут в документации Zabbix-а:
| proc.num[ , , , ] | ||||
|---|---|---|---|---|
| Количество процессов. | Целое число | имя – имя процесса (по умолчанию “все процессы”) пользователь – имя пользователя (по умолчанию “все пользователи”) состояние – возможные значения: all (по умолчанию), run, sleep, zomb cmdline – фильтр по командной строке (является регулярным выражением) | Примеры ключей: ⇒ proc.num[,mysql] – количество процессов выполняемых под пользователем mysql ⇒ proc.num[apache2,www-data] – количество процессов apache2 выполняемых под пользователем www-data ⇒ proc.num[,oracle,sleep,oracleZABBIX] – количество процессов в спящем состоянии выполняемых под oracle и имеющих oracleZABBIX в содержимом командной строкиСмотрите заметки по выбору процессов с параметрами имя и cmdline (специфика для Linux).В Windows, поддерживаются только параметры имя и пользователь. | |
Затем нам необходимо указать необходимые параметры для ключа. К примеру мы хотим настроить мониторинг демона под названием “sendsms”, тогда ключ у нас будет таким:
Источник
Мониторинг доступности службы linux с помощью Zabbix
Ранее я рассматривал различные конфигурации для мониторинга параметров и программ в windows и linux. Сейчас я хочу рассказать, как мониторить с помощью Zabbix произвольный сервис (службу), который работает либо локально на сервере, либо на внешнем tcp порту. Это может быть что угодно — ssh, ldap, smtp, ftp, http, pop, nntp, imap, tcp, https, telnet или любой другой сервис.
Введение
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
То же самое на Debian 10, если предпочитаете его:
В заббикс существуют различные способы получать данные для мониторинга. Наиболее распространенные источники информации:
- Zabbix агент. Устанавливается на наблюдаемую машину и отправляет данные на сервер мониторинга.
- SNMP агент. Чаще всего присутствует на устройстве, либо может быть установлен на сервер.
- Простые проверки — simple check. Выполняются непосредственно на сервере zabbix с помощью встроенных инструментов, не требуют дополнительных действий со стороны хоста.
- Внешние проверки — external checks. Как и простые проверки выполняются на сервере мониторинга, но не встроенными средствами, а внешними скриптами.
Есть и другие способы получения данных. Не буду их все перечислять, ознакомиться с ними можно в соответствующем разделе официальной документации. В нашем случае мы воспользуемся первыми двумя способами для мониторинга служб и сервисов в linux.
Тут можно пойти разными путями. Меня интересует мониторинг различных линукс служб, работающих как локально (samsdaemon, postgrey) в пределах конкретного сервера, так и для публичного доступа по сети, в частности squid, smtp, imap, http. Первое, что пришло в голову, это использовать итем с ключом service_state[]. Но как оказалось, этот тип данных снимает значения только с системных служб windows. Я не сразу это понял и некоторое время повозился в консоли, не понимая, почему при тестировании значения получаю сообщение, что данный item не поддерживается:
Дальше придумал через UserParameter запускать какой-нибудь скрипт, который будет проверять запущен ли сервис в системе или нет. Например с помощью ps ax | grep squid. В принципе, рабочий вариант, но мне казалось, что такую простую задачу можно решить проще и быстрее, без создания на каждом хосте скрипта и изменения файла конфигурации. И я не ошибся. Есть 2 различных способа мониторинга служб (сервисов) в linux с помощью zabbix. Рассмотрим первый из них.
Описание работы простых проверок (simple check)
Стал искать материал на эту тему и прочитал про simple check (простые проверки) в zabbix. Оказалось, это то, что нужно. Их можно использовать для безагентских проверок удаленных сервисов. При этом требуется минимум настроек и только на сервере. Можно создать шаблон и распространить на любое количество хостов.
Принцип работы простых проверок следующий. Вы создаете item, в нем указываете тип simple check, в качестве ключа выбираете net.tcp.service[сервис, , ], указываете соответствующие параметры в скобках и все. Сервер сам начинает опрашивать указанный сервис и возвращать в зависимости от его доступности 0 или 1. Устанавливать агент на хост не нужно. Мониторить можно любую сетевую службу, к которой есть доступ по tcp.
| 0 | сервис недоступен |
| 1 | сервис работает |
Всего в простых проверках доступны 5 ключей. Подробнее о них читайте в документации. В данном случае меня будет интересовать только ключ net.tcp.service. В нем предопределены алгоритмы проверок следующих служб: ssh, ntp, ldap, smtp, ftp, http, pop, nntp, imap, https, telnet. Детали реализации проверки каждой службы описаны тут. Если вы мониторите службу, которая не входит в указанный выше список, то происходит просто проверка возможности подключения, без отправки и получения каких-то данных.
Мониторинг доступности сервиса по сети
В качестве примера настроим мониторинг доступности прокси сервера squid. Он запущен на linux сервере и этот хост уже добавлен на сервер мониторинга. Данные поступают с помощью агента, но мы не будет его использовать. Просто создадим одиночный item для проверки доступности squid и trigger для отправки уведомления, если сервис не работает. В данном примере я рассмотрю настройку на примере конкретного хоста. Если у вас несколько серверов с squid, которые вы хотите мониторить, то все элементы лучше создать не отдельно на каждом хосте, а сразу сделать template и назначить его нужным хостам.
Итак, идем в Configuration -> Hosts и выбираем там хост, на котором установлен squid. Переходим в раздел Items и нажимаем Create item.
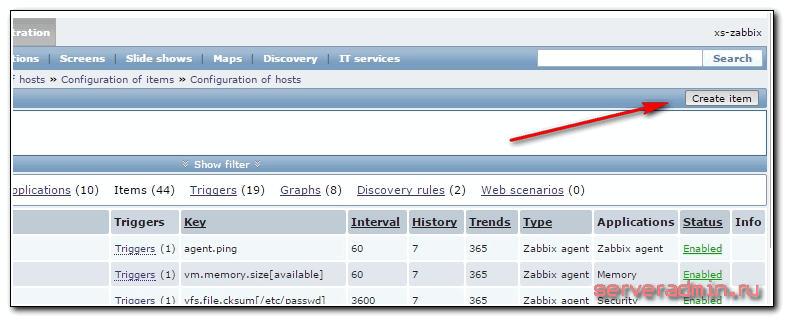
Заполняем необходимые параметры элемента.
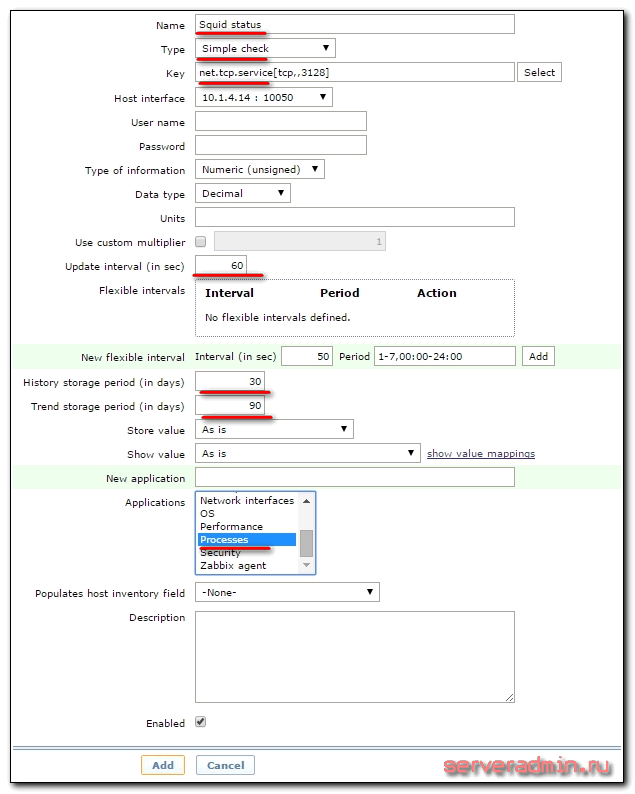
Обязательно заполнить первые 3, остальные на ваше усмотрение. Я считаю, что проверять каждые 30 секунд и хранить 90 дней информацию излишне, поэтому изменяю эти параметры в сторону увеличения.
| Squid status | Имя итема. |
| Simple check | Тип итема. |
| net.tcp.service[tcp,,3128] | Проверять tcp порт 3128 на указанном хосте. Если вы проверяете статус службы, расположенной не на том же хосте, к которому прикрепляете item, то после первой запятой можно указать необходимый адрес. |
Сразу создадим триггер, который в случае возврата в последних двух проверках значения итемом 0, будет отправлять уведомление о том, что служба недоступна. Для этого идем в раздел triggers и жмем Create trigger. Заполняем параметры элемента.
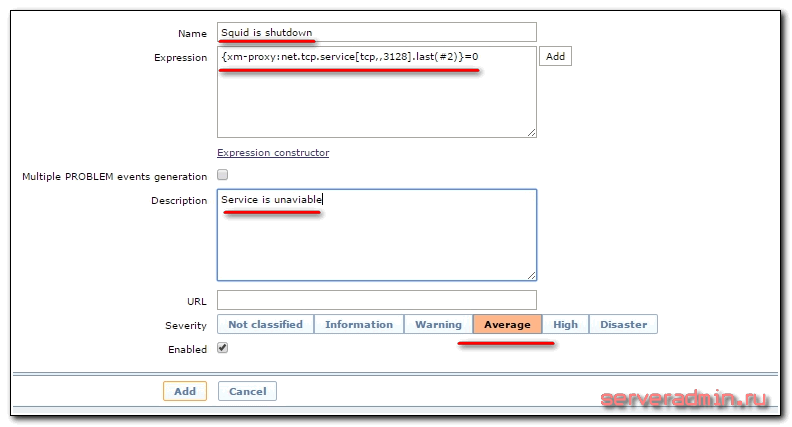
Выражение
Ждем пару минут и идем в Latest data проверять поступаемые значения.
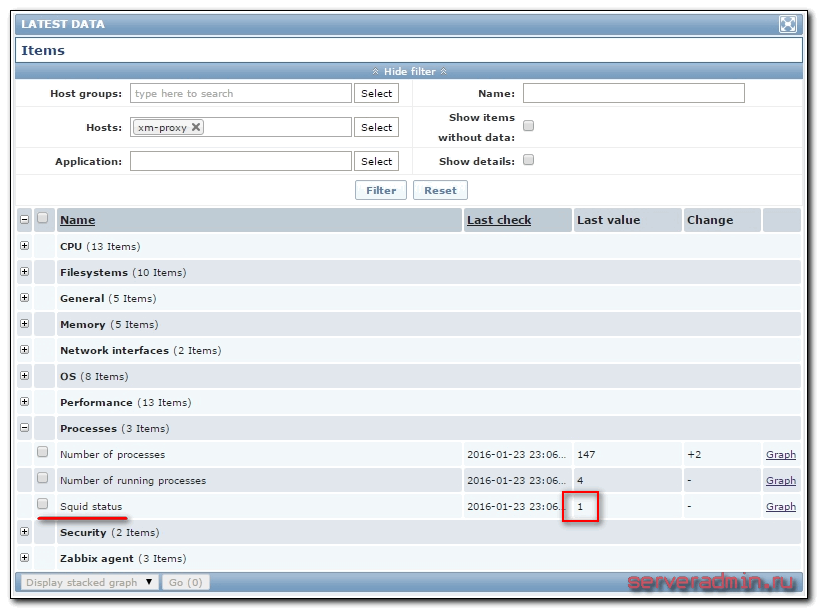
Чтобы проверить работу триггера, достаточно зайти на сервер и остановить squid. Если вы все сделали правильно, то после второй проверки, которая определит, что squid не отвечает по заданному адресу, вы получите уведомление на почту об этом. Если у вас не настроены или не работают уведомления на почту в zabbix, то читайте мою статью на эту тему.
Мониторинг локальной службы в linux
С мониторингом удаленного tcp сервиса разобрались, а что делать, если служба работает локально и к ней невозможно подключиться из вне. Тут уже не обойтись без установки zabbix агента. Если он установлен на хосте, то можно воспользоваться итемом с ключом proc.num. Этот ключ возвращает в качестве значения количество запущенных процессов. И если таких процессов больше одного, можно считать, что служба запущена.
Рассмотрим на примере мониторинга службы postgrey, реализующей greylist для борьбы со спамом. Она работает локально на почтовом сервере linux и является критическим сервисом, так как без него почтовый сервер postfix не будет принимать почту, выдавая временную ошибку почтовой системы. Проверим работу ключа proc.num:
Все в порядке, zabbix агент возвращает значение 1 при запущенном сервисе. Идем на сервер мониторинга, выбираем хост или шаблон и создаем новый item.
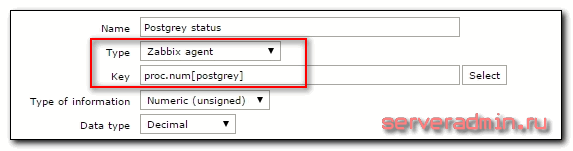
Показываю только основные параметры, остальные устанавливайте на свой вкус. Я лишь рекомендую не делать слишком частые проверки. В большинстве случаев в этом нет необходимости, а нагрузка на сервер постоянно растет при добавлении новых итемов.
Создаем триггер с оповещением о недоступности сервиса. При последних двух значениях равных 0 срабатываем.
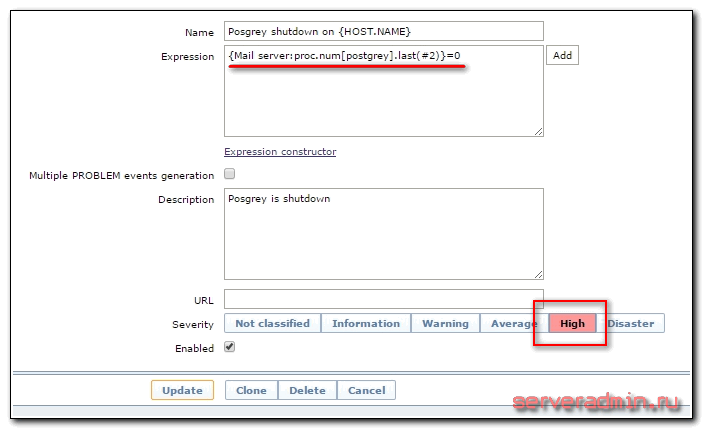
Я настраиваю триггер в шаблоне, поэтому сразу для удобства в названии триггера указываю маску для имени, чтобы было понятно в оповещении, на каком хосте сработал триггер. Как обычно, проверить поступаемые значения можно в Latest data.
Вот и все. Мы настроили мониторинг локальных служб linux в заббиксе.
Заключение
В своем материале я рассмотрел два различных способа, с помощью которых можно мониторить любой удаленный сервис по протоколу tcp, либо локальную службу на сервере linux. Конкретно в моих примерах можно было воспользоваться вторым способом в обоих случаях. Я этого не сделал, потому что первым способом я не просто проверяю, что служба запущена, я еще и обращаюсь к ней по сети и проверяю ее корректную работу для удаленного пользователя.
Разница тут получается вот в чем. Допустим, сервер squid у вас запущен и работает на сервере. Проверка работы локальной службы показывает, что сервис работает и возвращает значение 1. Но к примеру, вы настраивали firewall и где-то ошиблись. Сервис стал недоступен по сети, пользователи не могут им пользоваться. При этом мониторинг будет показывать, что все в порядке, служба запущена, хотя реально она не может обслужить запросы пользователей. В таком случай только удаленная проверка покажет, что с доступностью сервиса проблемы и надо что-то делать.
Из этого можно сделать вывод, что система мониторинга zabbix предоставляет огромные возможности по мониторингу. Какой тип наблюдения и сбора данных подойдет в конкретном случае нужно решать на месте, исходя из сути сервиса, за которым вы наблюдаете.
Источник



