- Zabbix: Мониторинг выборочного процесса (CPU, MEM) с защитой от ложных срабатываний
- 1. Создание нового шаблона Zabbix
- 2. Добавление макроса
- 3. Добавление элементов данных
- 4. Триггеры с гистерезисом
- 5. Конфигурация хоста
- Мониторинг списка запущенных процессов в Zabbix
- Введение
- Подготовка сервера к мониторингу процессов
- Настройка мониторинга за процессами
- Проверка отправки списка процессов
- Заключение
Zabbix: Мониторинг выборочного процесса (CPU, MEM) с защитой от ложных срабатываний
Как создать универсальный Zabbix шаблон для мониторинга Linux процесса, указанного по имени.
1. Создание нового шаблона Zabbix
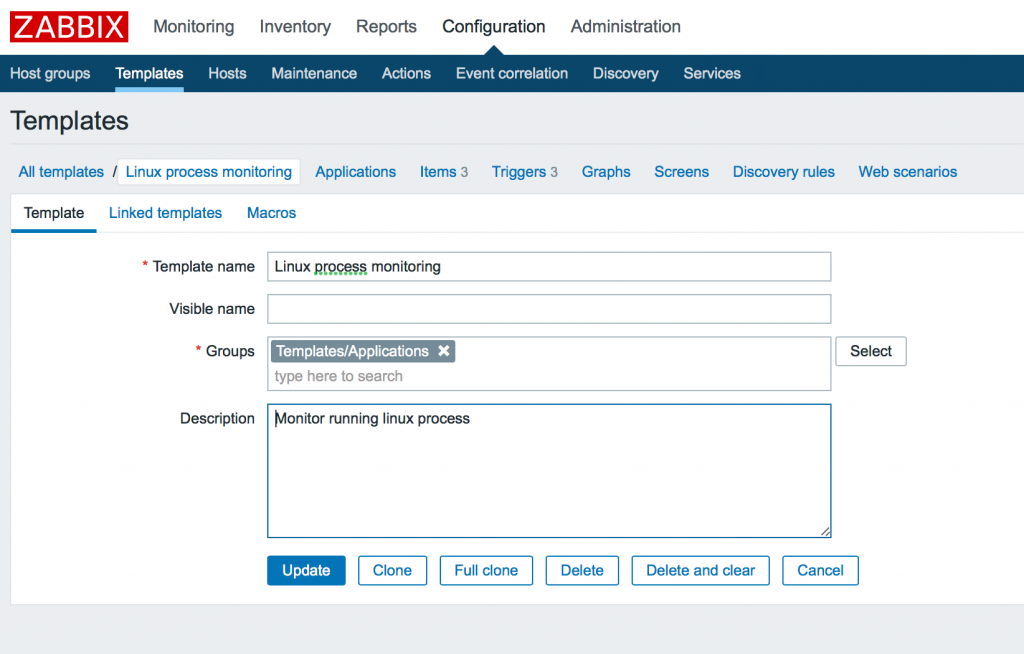
Идем в Configuration -> Templates -> Create template и добавляем имя, группу и описание шаблона.
2. Добавление макроса
Мы хотим мониторить 3 параметра:
- количество процессов, с уведомлением о том, что процессов стало меньше (упали)
- использование памяти, с уведомлением о превышении
- использование процессора, с уведомлением о превышении
Давайте тут же определим значения по умолчанию. Для этого мы будем использовать макросы шаблона (вкладка Macros), чтобы потом была возможность заменить их для каждого хоста.
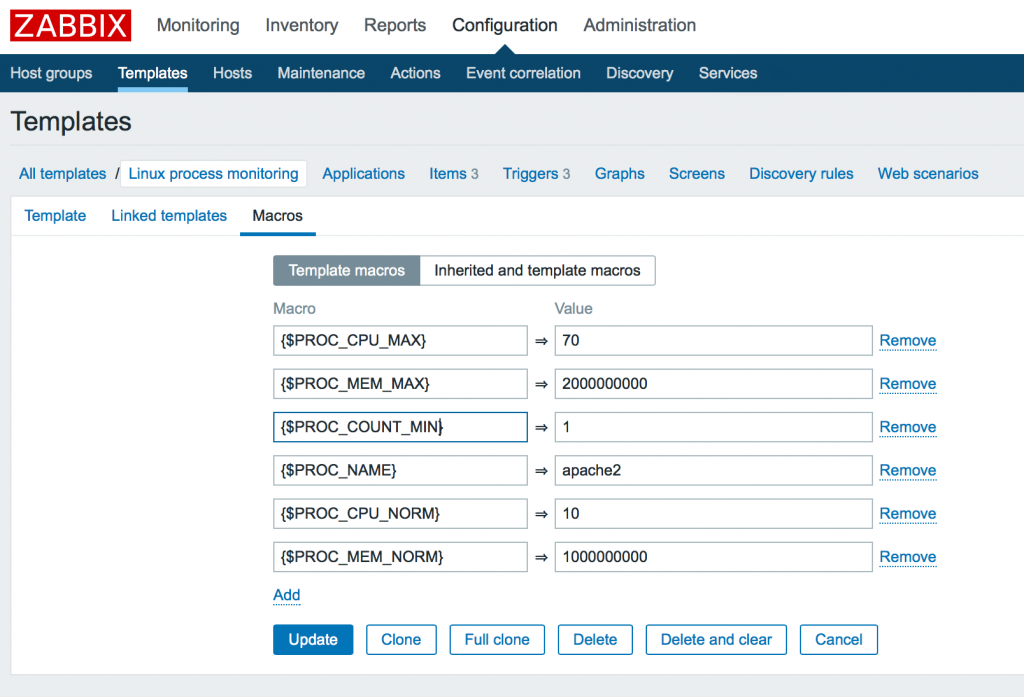
В этом примере мы создали 6 макросов.
Тут вы можете увидеть максимально использование cpu 70%, использование памяти 2G, минимально 1 запущенный процесс, а так же имя процесса для примера: apache2. Так же мы должны задать нормальные значения наших параметров для построения гистерезиса в целях защиты от ложных срабатываний (описано ниже). По этому мы так же указываем как 10% и как 1G.
3. Добавление элементов данных
Теперь мы должны добавить элементы входных данных (items). Переходим в меню Items нашего шаблона и кликаем кнопку: Create item. Затем создаем 3 элемента:
- количество процессов
- использование cpu
- использование памяти
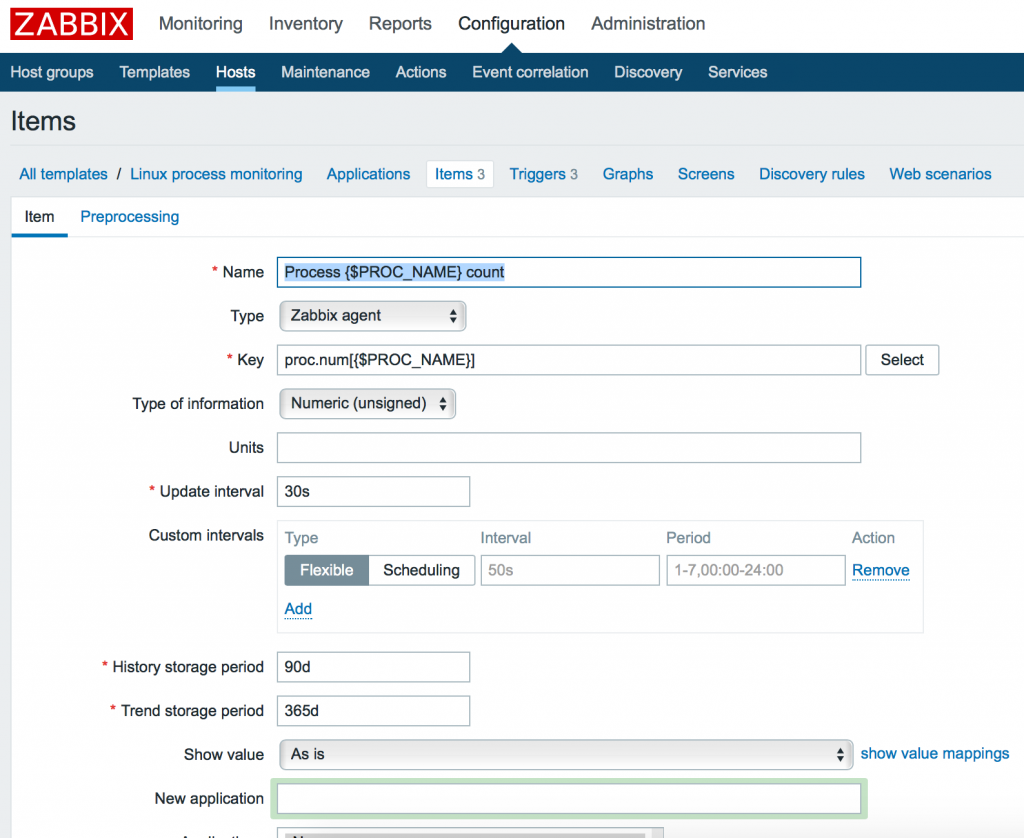
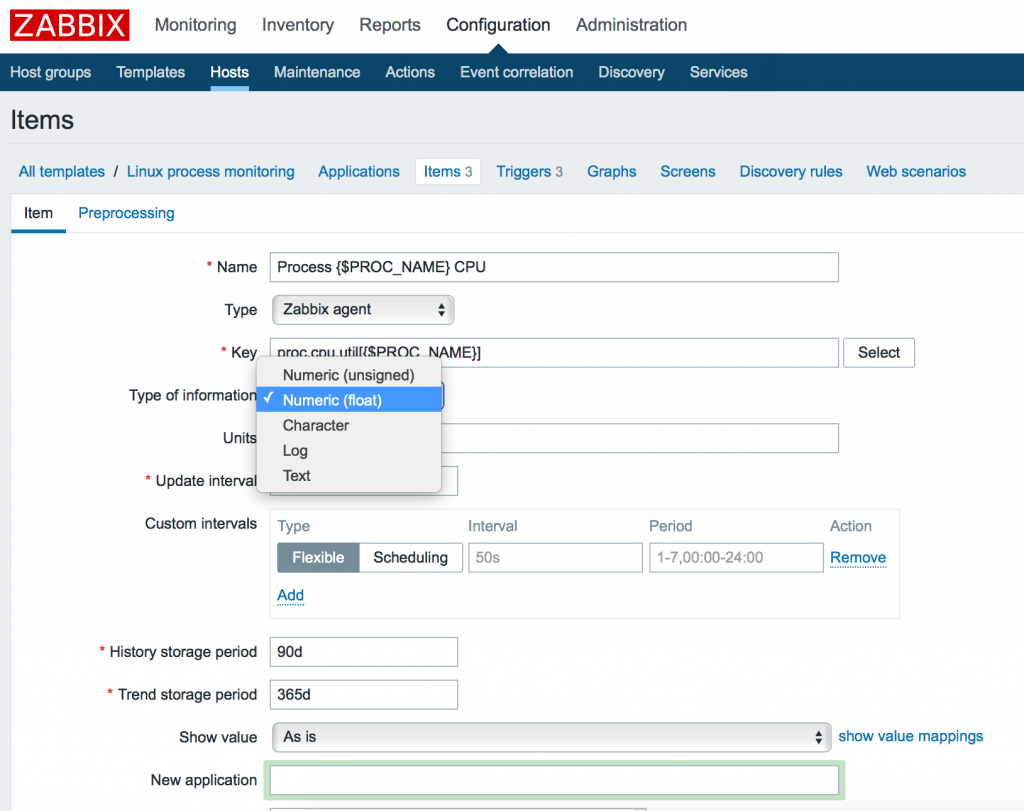
Мы можем использовать как макрос для задания конкретного имени процесса позже внутри конечной конфигурации хоста. Итак, добавляем 3 элемента с 3 ключами:
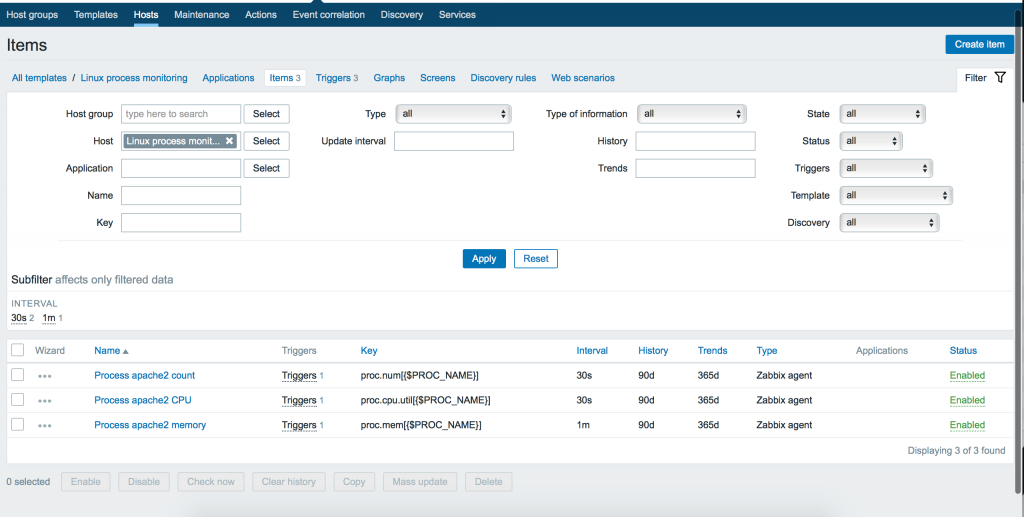
Заметим, что параметры могут иметь различные типы данных. Так к примеру proc.num, proc.mem имеет тип данных: Numeric (int), а proc.cpu.util – Numeric (float). Вы можете удостовериться в правильности указания типа данных в меню Key -> Select или официальной документации Zabbix.
4. Триггеры с гистерезисом
Пришло время создать тригеры. Переходим в закладку Triggers нашего шаблона. Вы можете использовать встроенный конструктор выражений, нажав Problem expression -> Add, затем выбрав item и function. К примеру last (most recent) T value. Но это только одно последнее значение. Оно будет меняться каждый раз, что вызовет нестабильность в определении статуса. Чтобы определить жесткое (установившееся) значение статуса, это значение должно повториться несколько раз подряд. Для такого подсчета лучше использовать функцию count. Болле подробную информацию о функциях вы можете получить в официальной документации Zabbix.
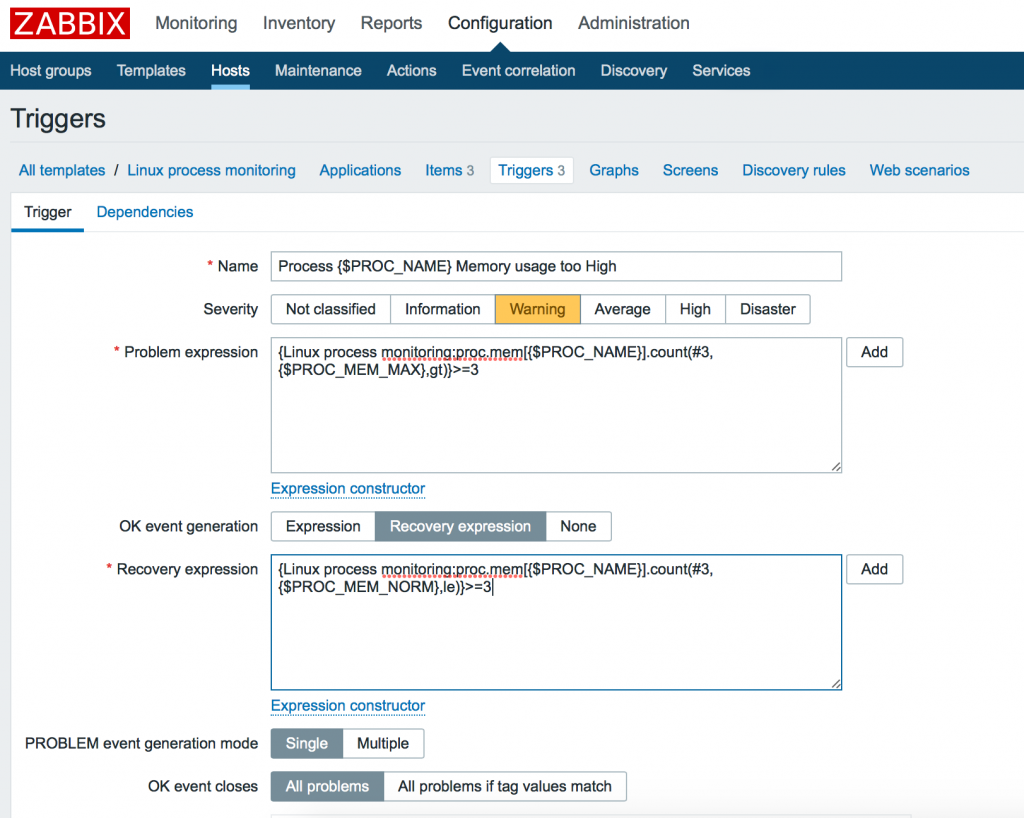
Итак, создаем триггер, который будет срабатывать при привышении потребления памяти больше чем <$PROC_MEM_MAX>3 раза подряд.
Мы можем прочитать его так: “Количество (count) последних 3 значений (#3), которые были больше (gt) чем равно >= 3″. Что означает, что все последние 3 значения были были больше чем PROC_MEM_MAX. Это хороший способ определения устоявшегося значения.
Но что делать с возвратом в нормальное состояние? Если мы просто оставим так как есть, мы рискуем получить что-то на подобие этого:
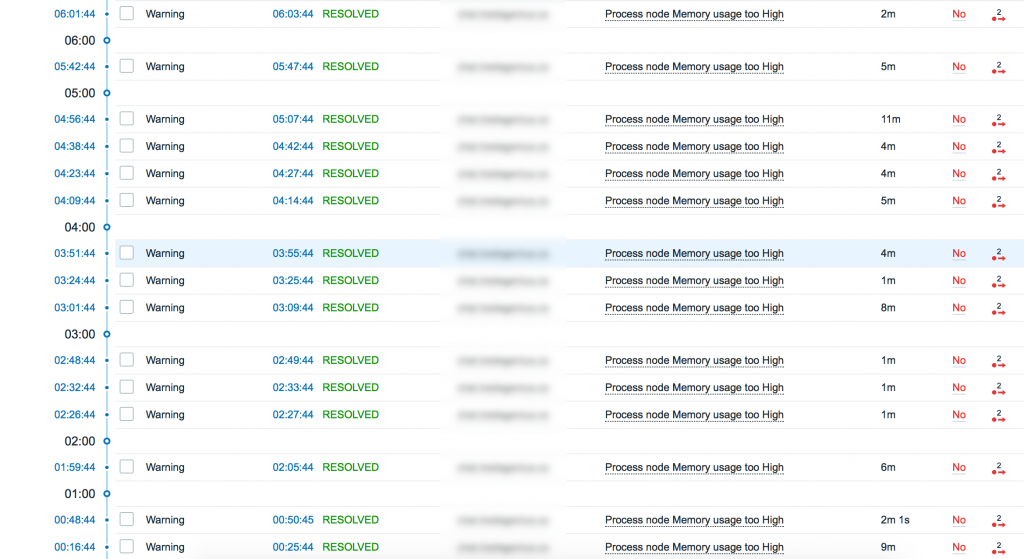
Каждые 5-10 минут статус меняет значение, колеблясь то выше, то ниже указанного порога. Он получает 3 подряд превышающих значения и триггер срабатывает, после чего он получает 3 нормальных значения и помечает проблему как RESOLVED (решена)! Что же делать? Нам поможет гистерезис с указанием не только максимального, но и нормального значения. Триггер будет в состоянии PROBLEM (проблема) до тех пор, пока значение нашего элемента не опустится до $
Итак, нажимаем OK event generation -> Recovery expression и добавляем выражение:
Его можно прочитать как: “Количество (count) последних трех (#3) значений элемента, которые были меньше или равны (le) числу было >= 3 раз. То есть установившееся в нормальном положении значение.
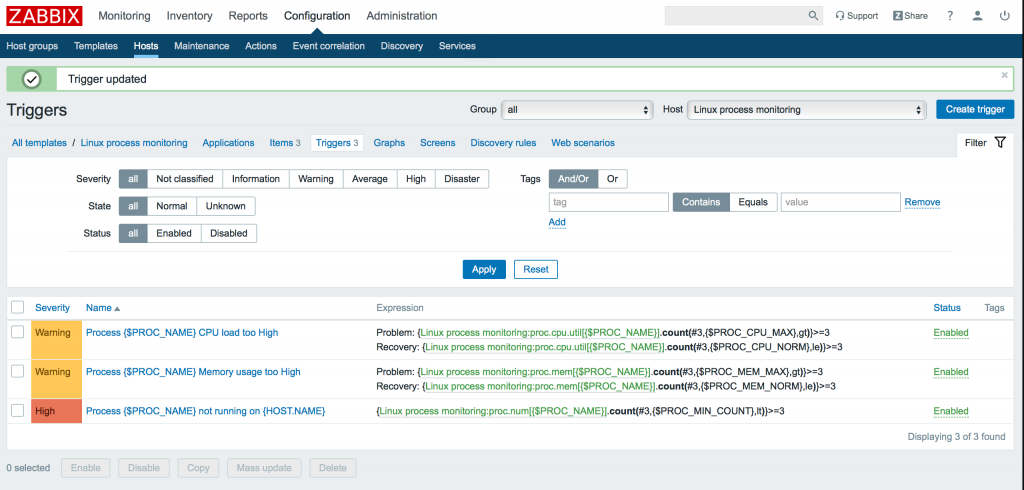
Подобным образом добавляем остальные тригеры (для использования процессора и количества процессов):
5. Конфигурация хоста
Теперь мы можем добавить наш шаблон к хосту. Идем в Configuration -> Hosts -> ваш сервер -> Templates. И добавляем только что созданный шаблон к серверу. Далее мы должны переопределись макросы.
Для примера на нашем сервере необходимо мониторить процесс node (node.js). Давайте посмотрим один из моих графиков данного процесса:
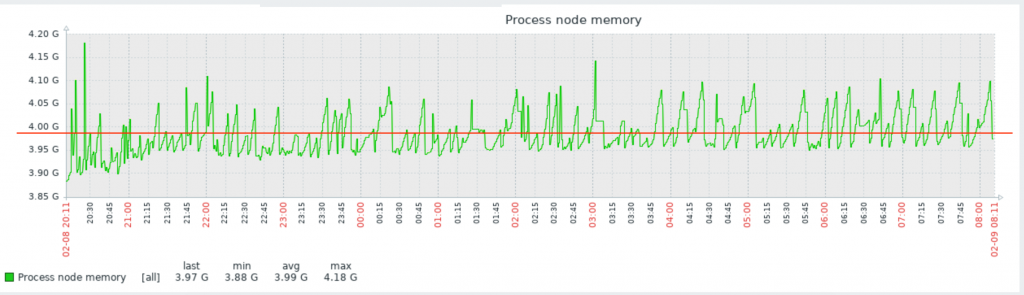
Вы видите, что у меня он потребляет порядка 4Gb RAM. Это нормальное состояние для моего сервиса. Так же вы видите колебание в районе красной линии. Без гистерезиса Zabbix нас просто заспамил бы сообщениями об изменении статуса в районе этой линии. В моем примере нормальное значение потребления памяти для указания в гистерезисе это 4G, а максимальное – больше чем 4.20G, пусть будет 4,5G. Добавим эти значения, а так же имя нашего процесса как макросы для данного хоста:
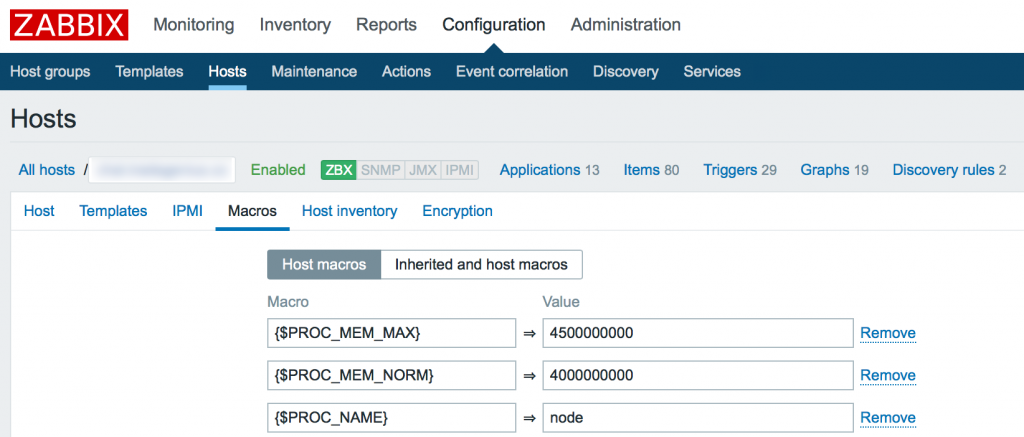
Итак, мой триггер перейдет в состоянии PROBLEM только когда значение потребляемой памяти будет больше чем 4,5Gb 3 раза подряд. А вернется он в нормальное состояние только тогда, когда потребление снизится ниже 4Г 3 раза подряд.
Готово! Позравляю! Теперь можно проверить последние данные в разделе Monitoring -> Latest data.
Источник
Мониторинг списка запущенных процессов в Zabbix
В стандартных шаблонах Zabbix есть триггеры на загрузку процессора, а так же на превышение максимально допустимого числа процессов. Триггеры эти практически бесполезны, если у вас плавающая нагрузка. Допустим, вы получаете уведомление о том, что у вас сильно нагружен процессор. Через 10 минут нагрузка прошла, а вы не успели зайти на сервер и посмотреть, чем он был нагружен в это время. Вот эту проблему я и решаю своим велосипедом, которым делюсь в статье.
Введение
Рассказываю подробно, что я хочу получить в конце статьи. В стандартном шаблоне Zabbix для Linux есть несколько триггеров. Они могут немного отличаться в названиях, в зависимости от версии шаблона, но смысл один и тот же:
- High CPU utilization
- Load average is too high
- Too many processes on hostname
Я хочу получить информацию о запущенных процессах на хосте в момент срабатывания триггера. Это позволит мне спокойно посмотреть, что создает нагрузку, когда у меня будет возможность. Мне не придется идти руками в консоль хоста и пытаться ловить момент, когда опять появится нагрузка.
В дефолтной конфигурации у Zabbix нет готовых инструментов, чтобы реализовать желаемое. Вы можете настроить мониторинг процесса или группы процессов в Zabbix. Но это не то, что нужно. Можно настроить автообнаружение всех процессов и мониторить их. Чаще всего это тоже не нужно, а подобный мониторинг будет генерировать большую нагрузку и сохранять кучу данных в базу. Особенно если на сервере регулярно запущено несколько сотен процессов.
Моя задача посмотреть на список процессов именно в момент нагрузки. Более того, мне даже не нужны все процессы, достаточно первой десятки самых активных, нагружающих больше всего систему. Я буду реализовывать этот мониторинг следующим образом:
- Добавляю в стандартный шаблон новый айтем типа Zabbix Trapper.
- Разрешаю на zabbix agent запуск внешних команд.
- Настраиваю на Zabbix Server действие при срабатывании одного из нужных мне триггеров. В действии указываю выполнение команды на целевом сервере, которая сформирует список процессов и отправит его на сервер мониторинга с помощью zabbix-sender.
Приступаем к реализации задуманного. Я буду настраивать описанную схему на Zabbix Server версии 5.2. Если у вас его нет, читайте мою статью по установке и настройке zabbix. В качестве подопытной системы будет выступать Centos. Так же предлагаю мои статьи по ее установке и предварительной настройке.
Подготовка сервера к мониторингу процессов
Первым делом идем на целевой сервер и изменяем конфигурацию zabbix-agent. Нам надо активировать следующую опцию:
Не забудьте после этого перезапустить агента.
Предупреждаю, что подобная настройка — огромная дыра в безопасности сервера. Используйте на свой страх и риск. Чтобы у вас не было проблем с этим, настоятельно рекомендую ограничивать доступ к порту агента на сервере на уровне firewall только с сервера мониторинга. Так же в обязательном порядке использовать шифрованное соединение между сервером и агентом. Вообще, это универсальное правило при настройке мониторинга. В идеале, так надо делать всегда. Я стараюсь все это настраивать при работе мониторинга через интернет. Если проигнорировать данное предупреждение и оставить все в открытом доступе, то через разрешенные удаленные команды вам могут залить на сервер зловред.
Далее проверим команду, которая будет формировать список процессов для отправки на сервер мониторинга. Я предлагаю использовать вот такую конструкцию, но вы можете придумать что-то свое.
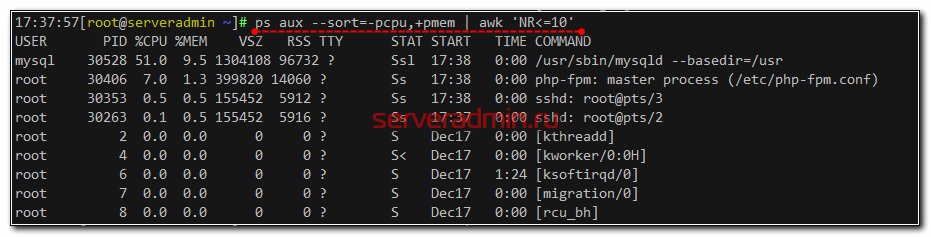
Получаем список запущенных процессов, отсортированный по потреблению cpu и ограниченный первыми десятью строками. В данный момент на сервере с агентом нам делать нечего. Перемещаемся в web интерфейс Zabbix Server.
Настройка мониторинга за процессами
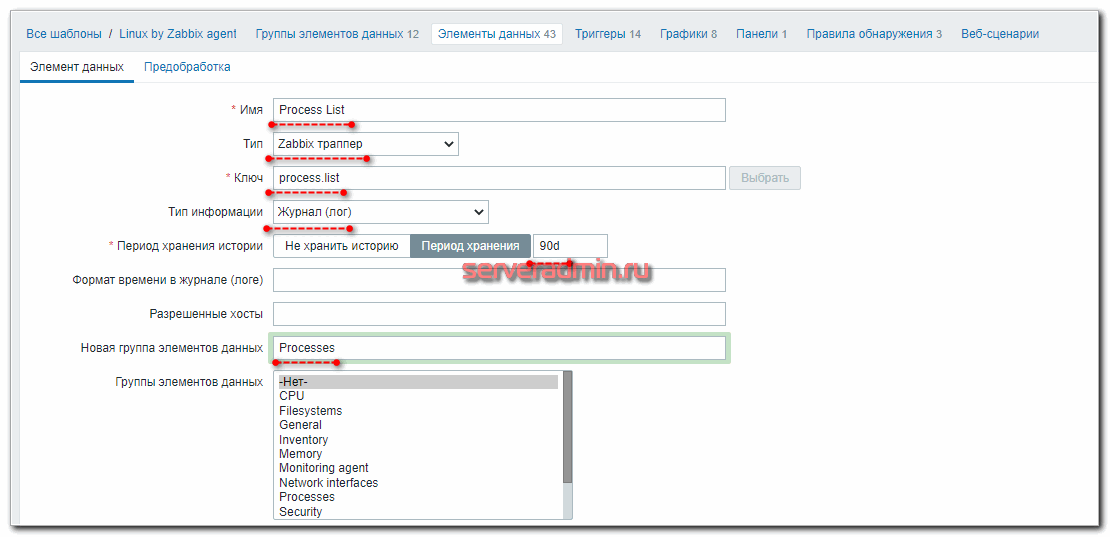
На Zabbix сервере идем в стандартный шаблон Linux и добавляем туда 2 новых айтема:
- Process List — список процессов, ограниченный десятью с самой высокой нагрузкой на cpu. Сюда будем записывать информацию о процессах на сервере при срабатывании триггеров на повышенную нагрузку CPU.
- Full Process List — полный список всех процессов. Сюда запишем полный список всех процессов, когда сработает триггер на превышение максимально допустимого количества запущенных процессов на сервере.
Так выглядит первый айтем. Второй сделайте по аналогии.
Теперь идем на сервер с агентом и пробуем отправку данных в данный айтем. Для этого нам нужен будет zabbix_sender. Если у вас его нет, то установите.
Отправку данных проверяем следующим образом:
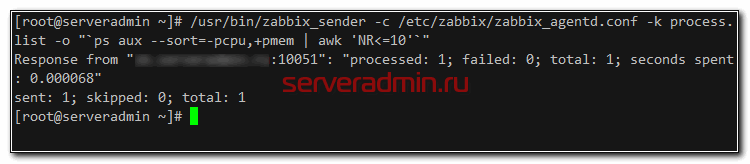
Я не буду подробно останавливаться на формате запросов с помощью zabbix_sender. Все это хорошо описано в документации. Теперь идем в веб интерфейс сервера и в разделе Последние данные смотрим на список процессов, который нам пришел с целевого сервера.
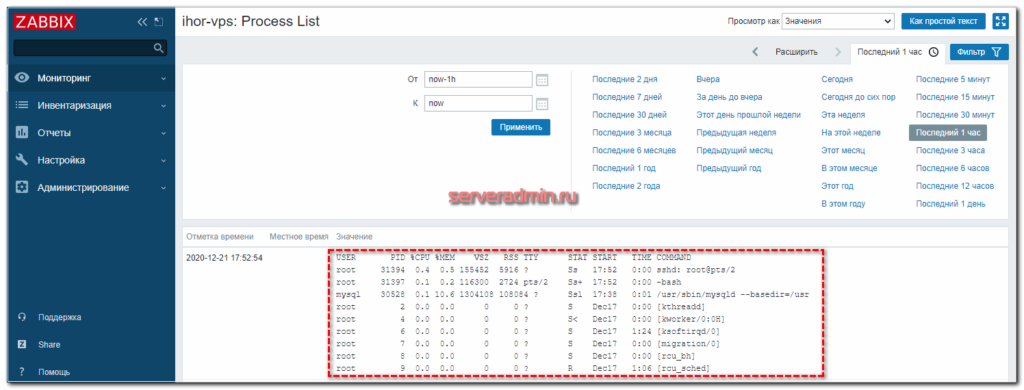
Ровно то, что нам было нужно. То же самое можно проверить с айтемом Full Process List, убрав в команде | awk ‘NR Настройка -> Действия и добавляем новое.
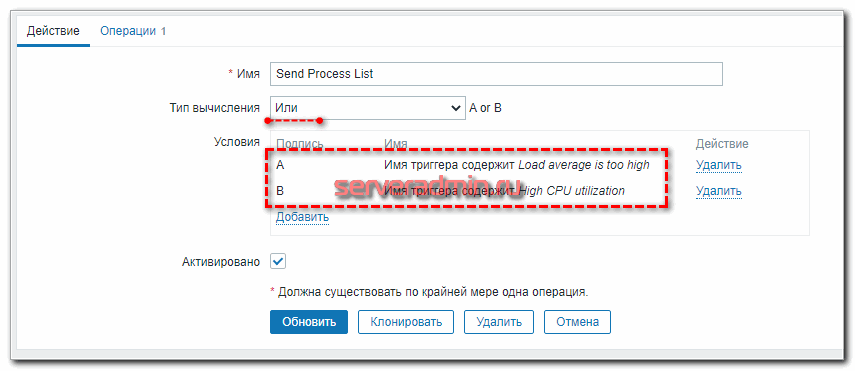
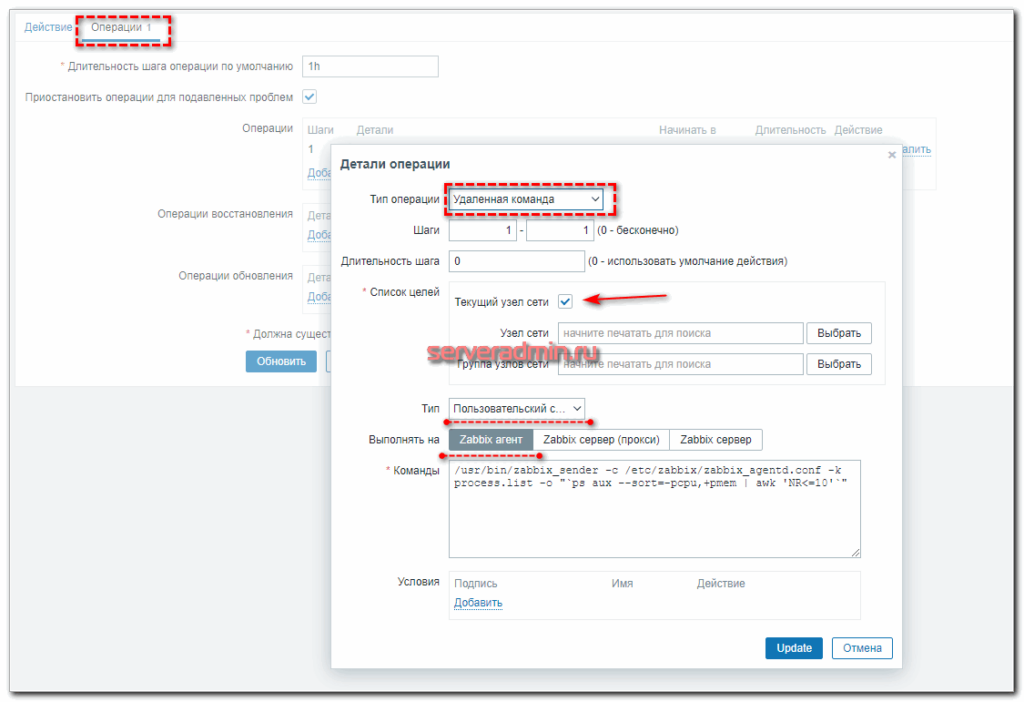
Сохраняйте действие и можно проверять.
Проверка отправки списка процессов
Теперь проверим, как все это будет работать. Для этого идем на целевой сервер и нагружаем его чем-нибудь. Я для примера запустил в двух разных консолях по команде:
Они достаточно быстро нагрузили единственное ядро тестового сервера, так что оставалось только подождать активации триггера. Через 5 минут это случилось.
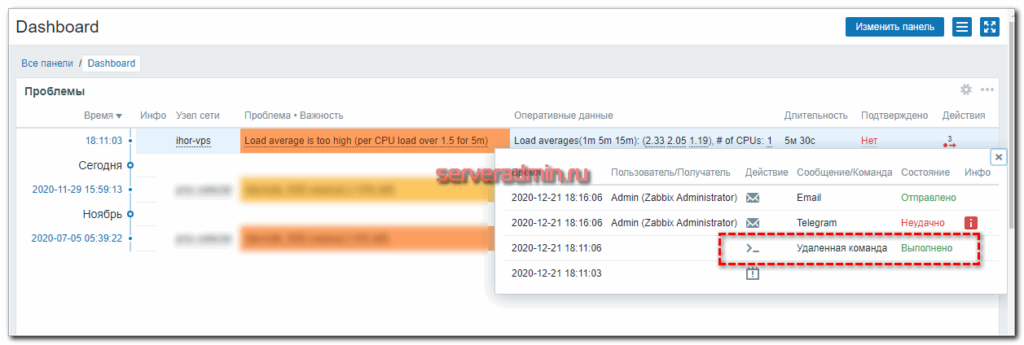
Иду в раздел Последние данные и вижу там список процессов, которые нагрузили мой сервер.
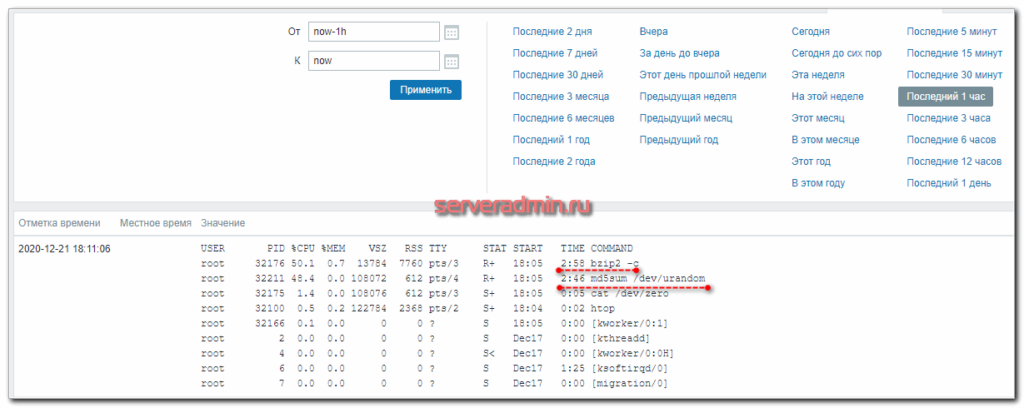
Что мне в итоге и требовалось. Теперь нет нужды каким-то образом проверять, что конкретно нагружает сервер. В момент пиковой нагрузки я получу список запущенных процессов в отдельный айтем. Для полного списка процессов все делается по аналогии.
Заключение
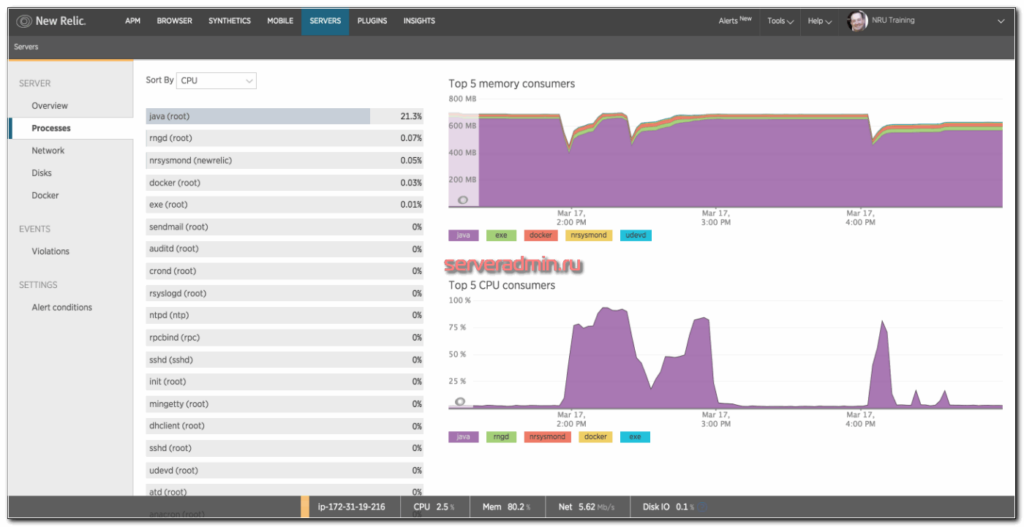
Вот такую реализацию я придумал, когда потребовалось решить задачу. Один сервер постоянно донимал оповещениями по ночам. Нужно было понять, что его дергает в это время. Жаль, что у Zabbix из коробки нет реализации подобного информирования. Помню лет 5 назад был бесплатный тариф у мониторинга NewRelic. Можно было поставить агент мониторинга на сервер и потом смотреть очень удобные отчеты в веб интерфейсе. Никаких настроек не нужно было, все работало из коробки. Там были отражены все запущенные процессы на сервере на временном ряду со всеми остальными метриками. Это было очень удобно. Я нигде в бесплатном софте не видел такой реализации. Это примерно вот так выглядело.
Кстати, в первоначальной версии действия я просто отправлял список процессов на почту. Мне показалось это удобным. Можно было сразу же в почте, в соседнем письме с триггером, посмотреть список процессов. Но потом решил, что удобнее все же хранить историю в одном месте на сервере и настроил сбор данных туда. Хотя можно делать и то, и другое. Например, в действии можно указать другую команду к исполнению:
И вам на почту придет список запущенных процессов после активации триггера.
Источник



