- Zabbix: Мониторинг выборочного процесса (CPU, MEM) с защитой от ложных срабатываний
- 1. Создание нового шаблона Zabbix
- 2. Добавление макроса
- 3. Добавление элементов данных
- 4. Триггеры с гистерезисом
- 5. Конфигурация хоста
- Docs/Developer documentation
- Contents
- Developer notes
- Windows specific
- proc_info implementation
- proc.num implementation
- Executing scripts
- Zabbix frontend
- MVC-related
- Acknowledgements
- Timestamp handling
- Мониторинг доступности службы linux с помощью Zabbix
- Введение
- Описание работы простых проверок (simple check)
- Мониторинг доступности сервиса по сети
- Мониторинг локальной службы в linux
- Заключение
Zabbix: Мониторинг выборочного процесса (CPU, MEM) с защитой от ложных срабатываний
Как создать универсальный Zabbix шаблон для мониторинга Linux процесса, указанного по имени.
1. Создание нового шаблона Zabbix
Идем в Configuration -> Templates -> Create template и добавляем имя, группу и описание шаблона.
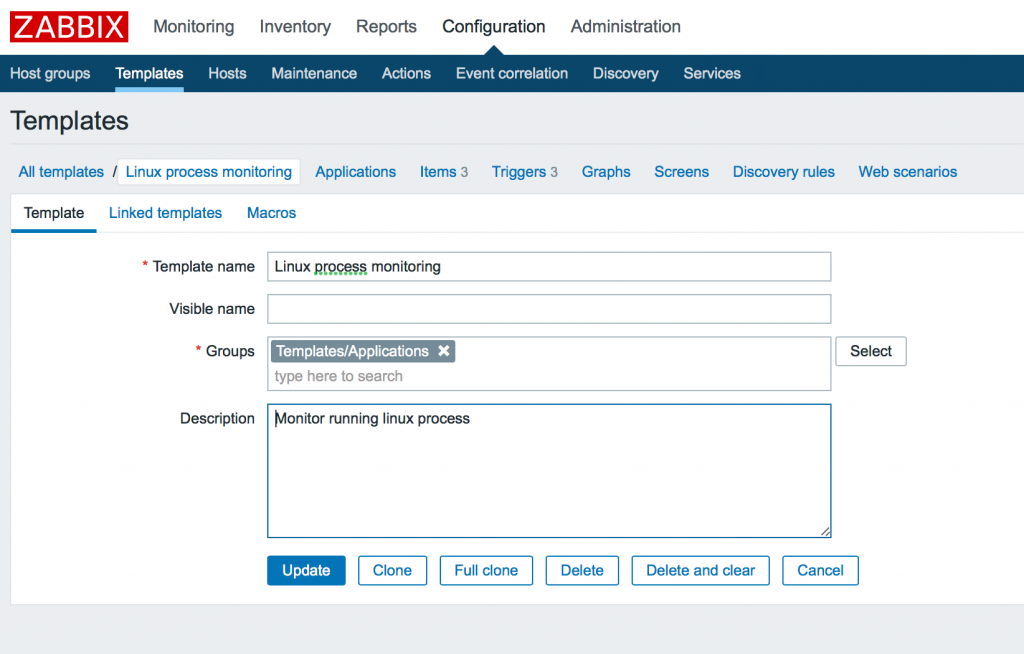
2. Добавление макроса
Мы хотим мониторить 3 параметра:
- количество процессов, с уведомлением о том, что процессов стало меньше (упали)
- использование памяти, с уведомлением о превышении
- использование процессора, с уведомлением о превышении
Давайте тут же определим значения по умолчанию. Для этого мы будем использовать макросы шаблона (вкладка Macros), чтобы потом была возможность заменить их для каждого хоста.
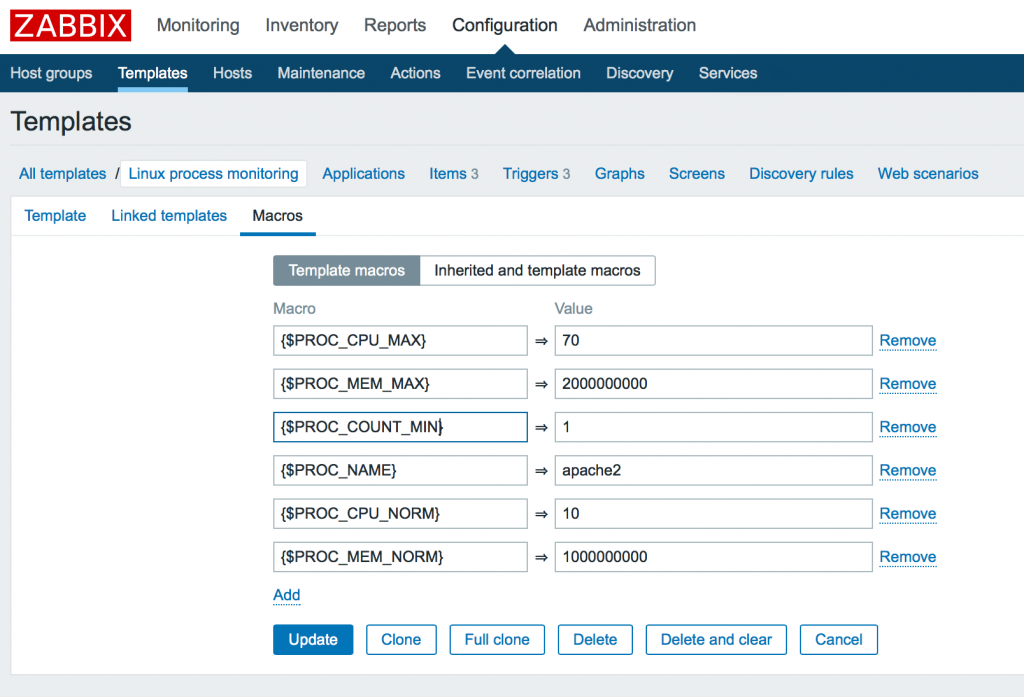
В этом примере мы создали 6 макросов.
Тут вы можете увидеть максимально использование cpu 70%, использование памяти 2G, минимально 1 запущенный процесс, а так же имя процесса для примера: apache2. Так же мы должны задать нормальные значения наших параметров для построения гистерезиса в целях защиты от ложных срабатываний (описано ниже). По этому мы так же указываем как 10% и как 1G.
3. Добавление элементов данных
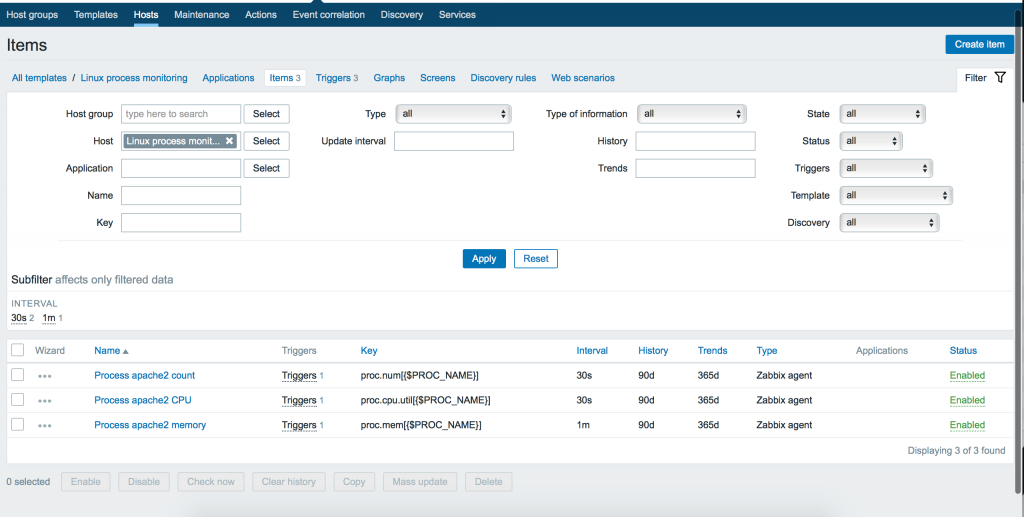
Теперь мы должны добавить элементы входных данных (items). Переходим в меню Items нашего шаблона и кликаем кнопку: Create item. Затем создаем 3 элемента:
- количество процессов
- использование cpu
- использование памяти
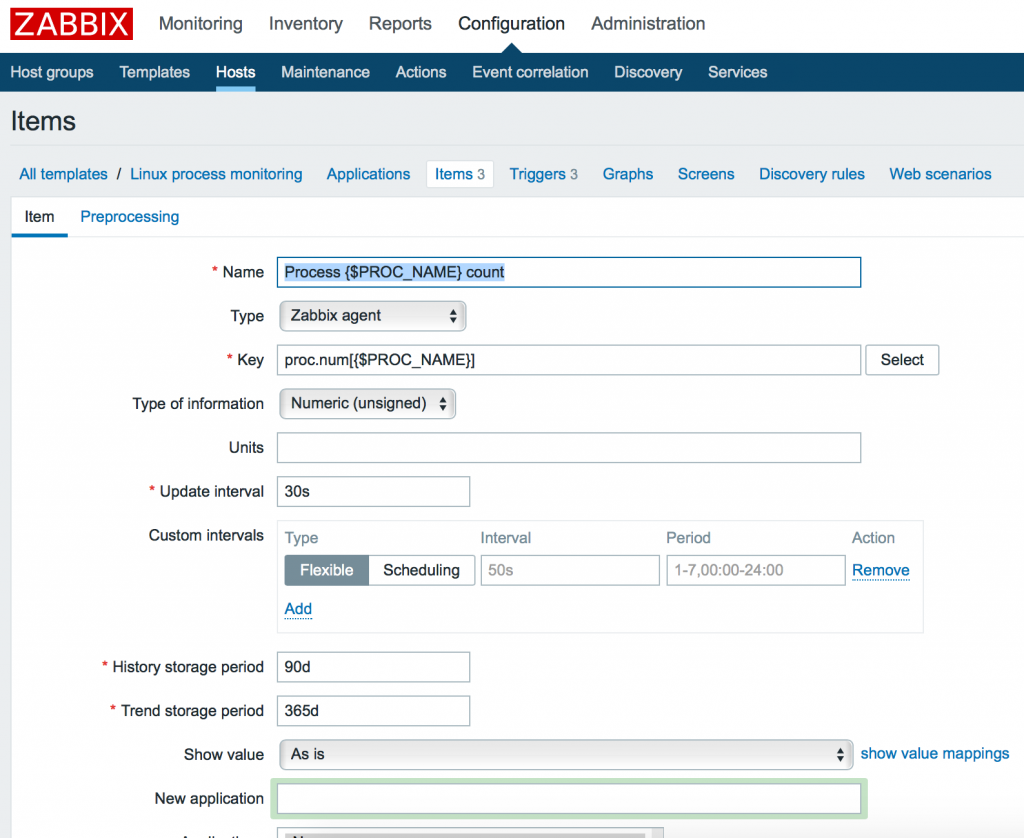
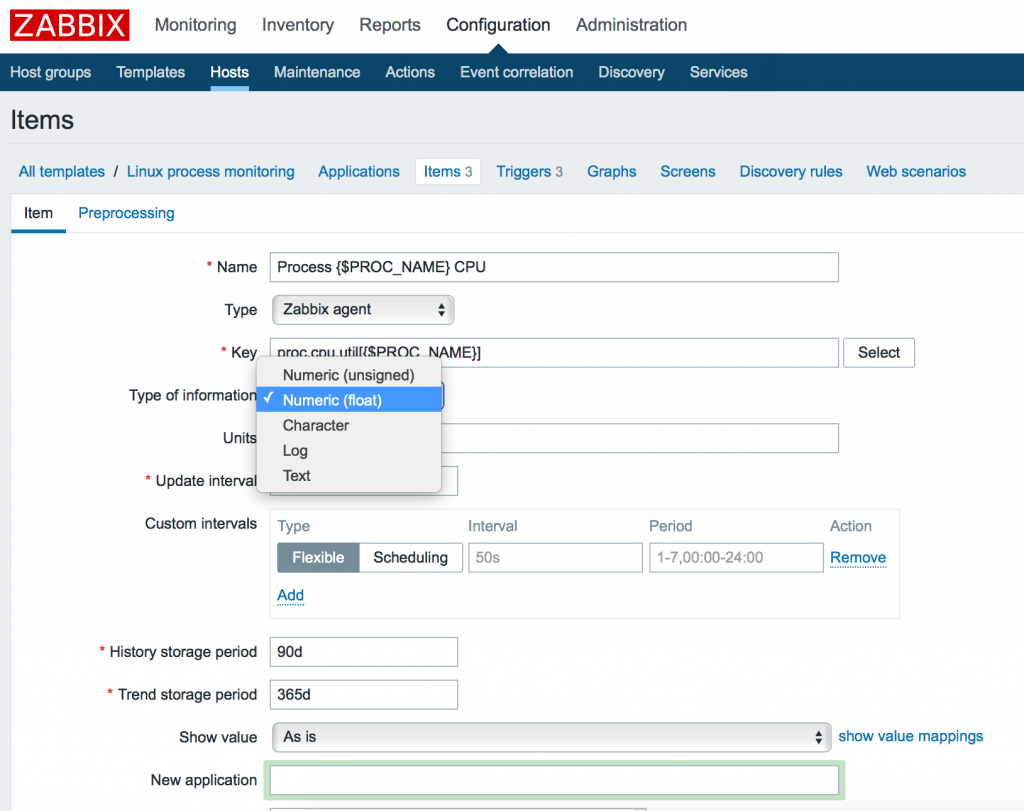
Мы можем использовать как макрос для задания конкретного имени процесса позже внутри конечной конфигурации хоста. Итак, добавляем 3 элемента с 3 ключами:
Заметим, что параметры могут иметь различные типы данных. Так к примеру proc.num, proc.mem имеет тип данных: Numeric (int), а proc.cpu.util – Numeric (float). Вы можете удостовериться в правильности указания типа данных в меню Key -> Select или официальной документации Zabbix.
4. Триггеры с гистерезисом
Пришло время создать тригеры. Переходим в закладку Triggers нашего шаблона. Вы можете использовать встроенный конструктор выражений, нажав Problem expression -> Add, затем выбрав item и function. К примеру last (most recent) T value. Но это только одно последнее значение. Оно будет меняться каждый раз, что вызовет нестабильность в определении статуса. Чтобы определить жесткое (установившееся) значение статуса, это значение должно повториться несколько раз подряд. Для такого подсчета лучше использовать функцию count. Болле подробную информацию о функциях вы можете получить в официальной документации Zabbix.
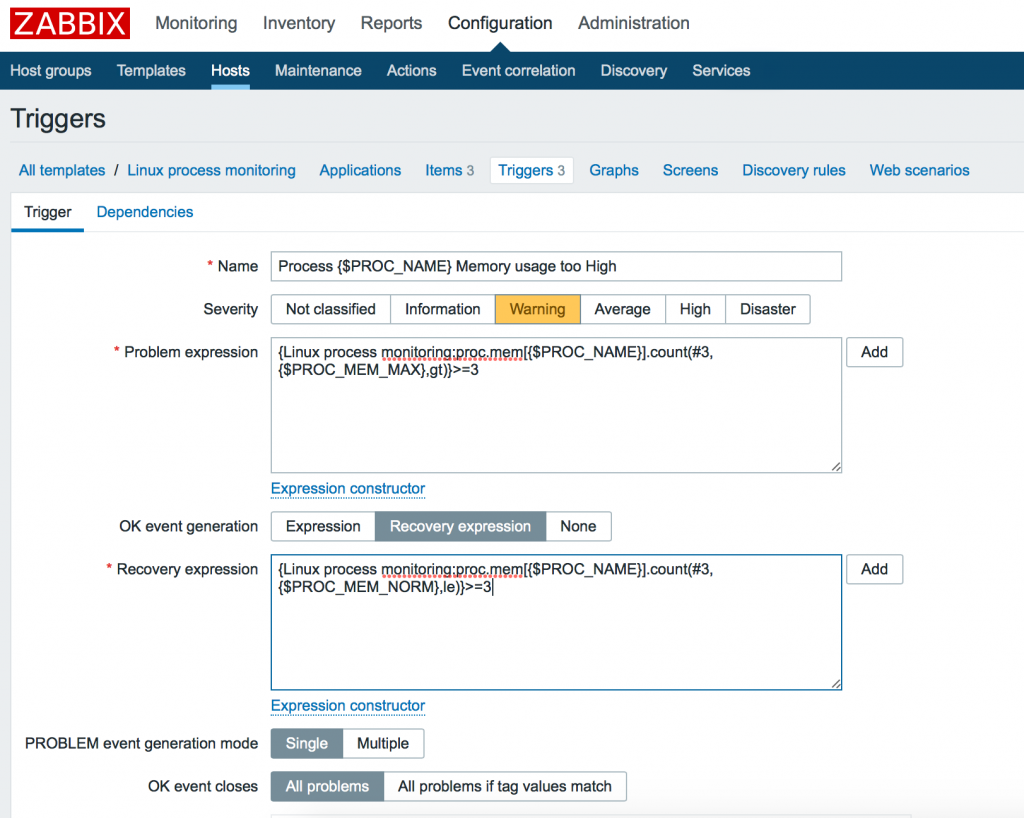
Итак, создаем триггер, который будет срабатывать при привышении потребления памяти больше чем <$PROC_MEM_MAX>3 раза подряд.
Мы можем прочитать его так: “Количество (count) последних 3 значений (#3), которые были больше (gt) чем равно >= 3″. Что означает, что все последние 3 значения были были больше чем PROC_MEM_MAX. Это хороший способ определения устоявшегося значения.
Но что делать с возвратом в нормальное состояние? Если мы просто оставим так как есть, мы рискуем получить что-то на подобие этого:
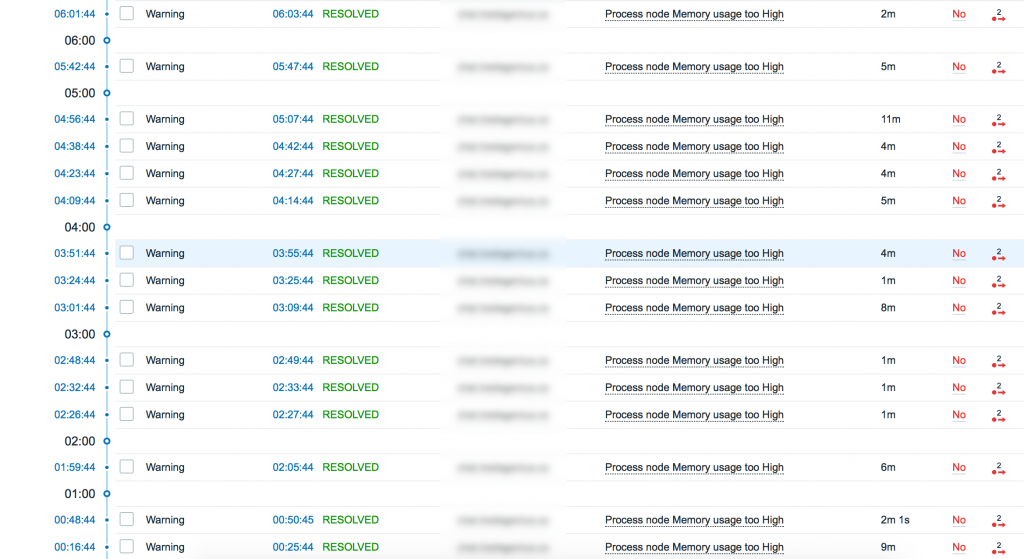
Каждые 5-10 минут статус меняет значение, колеблясь то выше, то ниже указанного порога. Он получает 3 подряд превышающих значения и триггер срабатывает, после чего он получает 3 нормальных значения и помечает проблему как RESOLVED (решена)! Что же делать? Нам поможет гистерезис с указанием не только максимального, но и нормального значения. Триггер будет в состоянии PROBLEM (проблема) до тех пор, пока значение нашего элемента не опустится до $
Итак, нажимаем OK event generation -> Recovery expression и добавляем выражение:
Его можно прочитать как: “Количество (count) последних трех (#3) значений элемента, которые были меньше или равны (le) числу было >= 3 раз. То есть установившееся в нормальном положении значение.
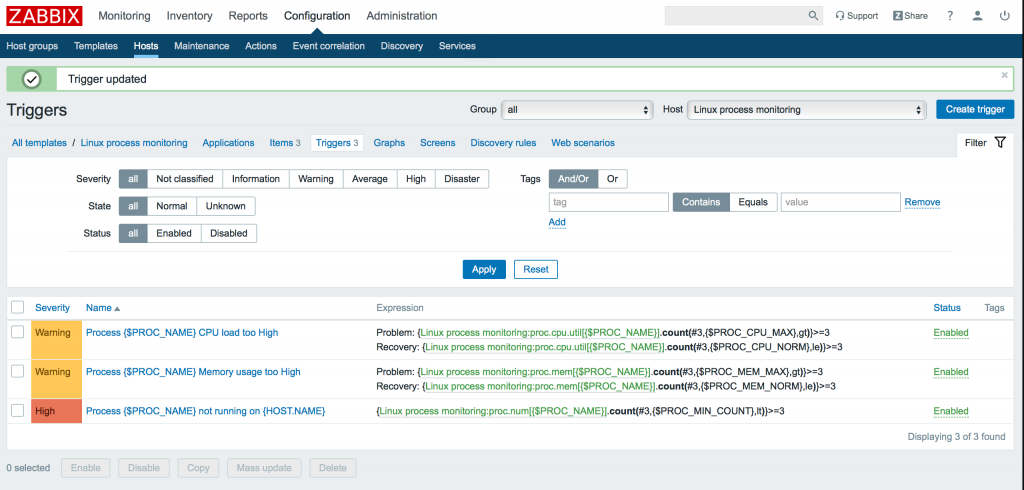
Подобным образом добавляем остальные тригеры (для использования процессора и количества процессов):
5. Конфигурация хоста
Теперь мы можем добавить наш шаблон к хосту. Идем в Configuration -> Hosts -> ваш сервер -> Templates. И добавляем только что созданный шаблон к серверу. Далее мы должны переопределись макросы.
Для примера на нашем сервере необходимо мониторить процесс node (node.js). Давайте посмотрим один из моих графиков данного процесса:
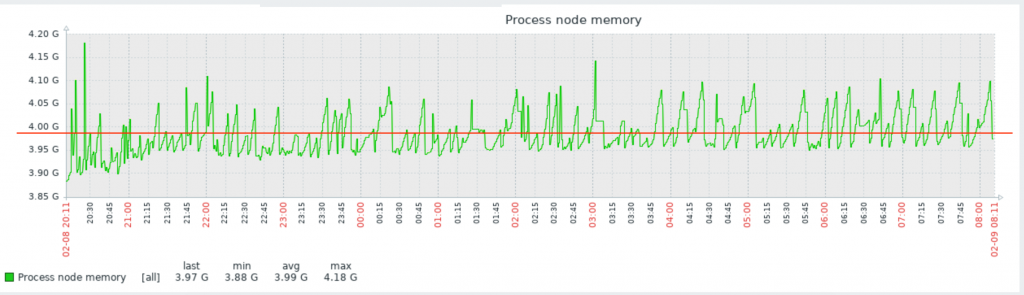
Вы видите, что у меня он потребляет порядка 4Gb RAM. Это нормальное состояние для моего сервиса. Так же вы видите колебание в районе красной линии. Без гистерезиса Zabbix нас просто заспамил бы сообщениями об изменении статуса в районе этой линии. В моем примере нормальное значение потребления памяти для указания в гистерезисе это 4G, а максимальное – больше чем 4.20G, пусть будет 4,5G. Добавим эти значения, а так же имя нашего процесса как макросы для данного хоста:
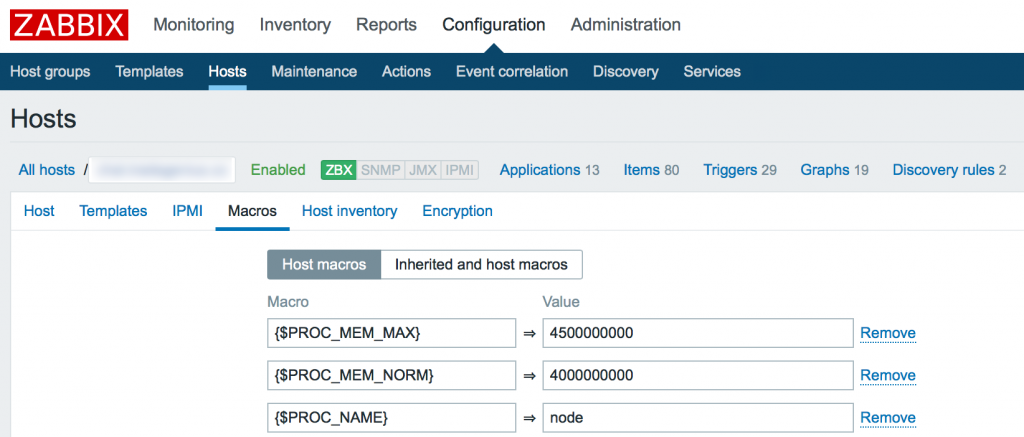
Итак, мой триггер перейдет в состоянии PROBLEM только когда значение потребляемой памяти будет больше чем 4,5Gb 3 раза подряд. А вернется он в нормальное состояние только тогда, когда потребление снизится ниже 4Г 3 раза подряд.
Готово! Позравляю! Теперь можно проверить последние данные в разделе Monitoring -> Latest data.
Источник
Docs/Developer documentation
Contents
Developer notes
This page is intended to collect notes on what a new developer might be interested in.
Windows specific
proc_info implementation
Requesting information on a process is done on a process handle. A process handle is requested from operating system with desired access rights. Starting with Windows Vista (major version 6) Microsoft introduced new access right called PROCESS_QUERY_LIMITED_INFORMATION and since then that must be used in order to retrieve information supported by proc_info item.
- before: OpenProcess() was always called with PROCESS_QUERY_INFORMATION desired access, which caused «access denied» on newer versions of Windows
- since Zabbix 2.2.9, 2.4.4: OpenProcess() is called with PROCESS_QUERY_INFORMATION on older versions of Windows (up to, including Windows XP and Server 2003) and PROCESS_QUERY_LIMITED_INFORMATION on newer versions
proc.num implementation
Before Zabbix 2.2.9, 2.4.4 Zabbix agent used method EnumProcesses () to get a list of running process IDs. If there was a process name filter, OpenProcess () call was issued on each process ID to get process handle. After that process name (executable) would be requested from that handle. A handle maybe requested with different access level. We were requesting a handle with PROCESS_QUERY_INFORMATION and PROCESS_VM_READ access rights. This was actually not needed and resulted in «access denied» in many cases and incorrect number of running processes reported by Zabbix agent.
In Zabbix 2.2.9, 2.4.4 we decided to use another method of getting a list of running processes, CreateToolhelp32Snapshot () . This method allows getting the list of all running processes along with process names (executables). This in turn allows skipping unnecessary calls to OpenProcess () , which gave errors before.
OpenProcess () is still called if a user name is specified in proc.num , e. g. proc.num[zabbix_agentd.exe,administrator] .
Executing scripts
Zabbix can execute scripts/commands in the following locations:
- External checks
- Alert scripts
- User parameters
- Remote commands ( system.run )
- Global scripts
Zabbix frontend
MVC-related
Setting a new filter to be used in the system . view widget since Zabbix 3.0.
Acknowledgements
Acknowledgements can be disabled in the Administration -> General -> GUI section. This affects the following places:
- Monitoring -> Dashboard , Last 20 issues widget -> Ack column
- Monitoring -> Dashboard -> Last 20 issues widget -> Issue column (on hover in popup another Ack column)
- Monitoring -> Dashboard -> System status widget -> on problem hover popup column Ack
- Monitoring -> Dashboard configuration -> Problem display
- Monitoring -> Overview -> Data -> cell
- Monitoring -> Overview -> Triggers -> cell
- Monitoring -> Triggers -> Filter -> Acknowledge status
- Monitoring -> Triggers -> Filter -> Events -> Show unacknowledged (7 days)
- Monitoring -> Triggers -> Ack column
- Monitoring -> Events -> Ack column
- Monitoring -> Event details -> Ack widget
- Monitoring -> Event details -> Event list [previous 20] -> Ack column
- Monitoring/Configuration -> Screens -> Screen element -> Data overview -> cell
- Monitoring/Configuration -> Screens -> Screen element -> Triggers overview -> cell
- Monitoring/Configuration -> Screens -> Screen element -> Host group issues -> Ack column
- Monitoring/Configuration -> Screens -> Screen element -> Host group issues -> Issue column (on hover in popup another Ack column)
- Monitoring/Configuration -> Screens -> Screen element -> Host issues -> Ack column
- Monitoring/Configuration -> Screens -> Screen element -> Host issues -> Issue column (on hover in popup another Ack column)
- Configuration -> Maps -> Problem display
Disabling acknowledgements does not affect the following places:
- Configuration -> Actions -> Operations -> Action operations -> Conditions -> Operation condition
- Monitoring -> Triggers -> Alarm acknowledgements page
Timestamp handling
Zabbix handles and assigns timestamps between agent/server/proxy/sender in a specific manner. The full description should be probably moved here, until then see this issue comment. Starting with version 4.0 server and proxy will no longer adjust the timestamps of received values, the mechanism of assigning them hasn’t changed.
Источник
Мониторинг доступности службы linux с помощью Zabbix
Ранее я рассматривал различные конфигурации для мониторинга параметров и программ в windows и linux. Сейчас я хочу рассказать, как мониторить с помощью Zabbix произвольный сервис (службу), который работает либо локально на сервере, либо на внешнем tcp порту. Это может быть что угодно — ssh, ldap, smtp, ftp, http, pop, nntp, imap, tcp, https, telnet или любой другой сервис.
Введение
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
То же самое на Debian 10, если предпочитаете его:
В заббикс существуют различные способы получать данные для мониторинга. Наиболее распространенные источники информации:
- Zabbix агент. Устанавливается на наблюдаемую машину и отправляет данные на сервер мониторинга.
- SNMP агент. Чаще всего присутствует на устройстве, либо может быть установлен на сервер.
- Простые проверки — simple check. Выполняются непосредственно на сервере zabbix с помощью встроенных инструментов, не требуют дополнительных действий со стороны хоста.
- Внешние проверки — external checks. Как и простые проверки выполняются на сервере мониторинга, но не встроенными средствами, а внешними скриптами.
Есть и другие способы получения данных. Не буду их все перечислять, ознакомиться с ними можно в соответствующем разделе официальной документации. В нашем случае мы воспользуемся первыми двумя способами для мониторинга служб и сервисов в linux.
Тут можно пойти разными путями. Меня интересует мониторинг различных линукс служб, работающих как локально (samsdaemon, postgrey) в пределах конкретного сервера, так и для публичного доступа по сети, в частности squid, smtp, imap, http. Первое, что пришло в голову, это использовать итем с ключом service_state[]. Но как оказалось, этот тип данных снимает значения только с системных служб windows. Я не сразу это понял и некоторое время повозился в консоли, не понимая, почему при тестировании значения получаю сообщение, что данный item не поддерживается:
Дальше придумал через UserParameter запускать какой-нибудь скрипт, который будет проверять запущен ли сервис в системе или нет. Например с помощью ps ax | grep squid. В принципе, рабочий вариант, но мне казалось, что такую простую задачу можно решить проще и быстрее, без создания на каждом хосте скрипта и изменения файла конфигурации. И я не ошибся. Есть 2 различных способа мониторинга служб (сервисов) в linux с помощью zabbix. Рассмотрим первый из них.
Описание работы простых проверок (simple check)
Стал искать материал на эту тему и прочитал про simple check (простые проверки) в zabbix. Оказалось, это то, что нужно. Их можно использовать для безагентских проверок удаленных сервисов. При этом требуется минимум настроек и только на сервере. Можно создать шаблон и распространить на любое количество хостов.
Принцип работы простых проверок следующий. Вы создаете item, в нем указываете тип simple check, в качестве ключа выбираете net.tcp.service[сервис, , ], указываете соответствующие параметры в скобках и все. Сервер сам начинает опрашивать указанный сервис и возвращать в зависимости от его доступности 0 или 1. Устанавливать агент на хост не нужно. Мониторить можно любую сетевую службу, к которой есть доступ по tcp.
| 0 | сервис недоступен |
| 1 | сервис работает |
Всего в простых проверках доступны 5 ключей. Подробнее о них читайте в документации. В данном случае меня будет интересовать только ключ net.tcp.service. В нем предопределены алгоритмы проверок следующих служб: ssh, ntp, ldap, smtp, ftp, http, pop, nntp, imap, https, telnet. Детали реализации проверки каждой службы описаны тут. Если вы мониторите службу, которая не входит в указанный выше список, то происходит просто проверка возможности подключения, без отправки и получения каких-то данных.
Мониторинг доступности сервиса по сети
В качестве примера настроим мониторинг доступности прокси сервера squid. Он запущен на linux сервере и этот хост уже добавлен на сервер мониторинга. Данные поступают с помощью агента, но мы не будет его использовать. Просто создадим одиночный item для проверки доступности squid и trigger для отправки уведомления, если сервис не работает. В данном примере я рассмотрю настройку на примере конкретного хоста. Если у вас несколько серверов с squid, которые вы хотите мониторить, то все элементы лучше создать не отдельно на каждом хосте, а сразу сделать template и назначить его нужным хостам.
Итак, идем в Configuration -> Hosts и выбираем там хост, на котором установлен squid. Переходим в раздел Items и нажимаем Create item.
Заполняем необходимые параметры элемента.
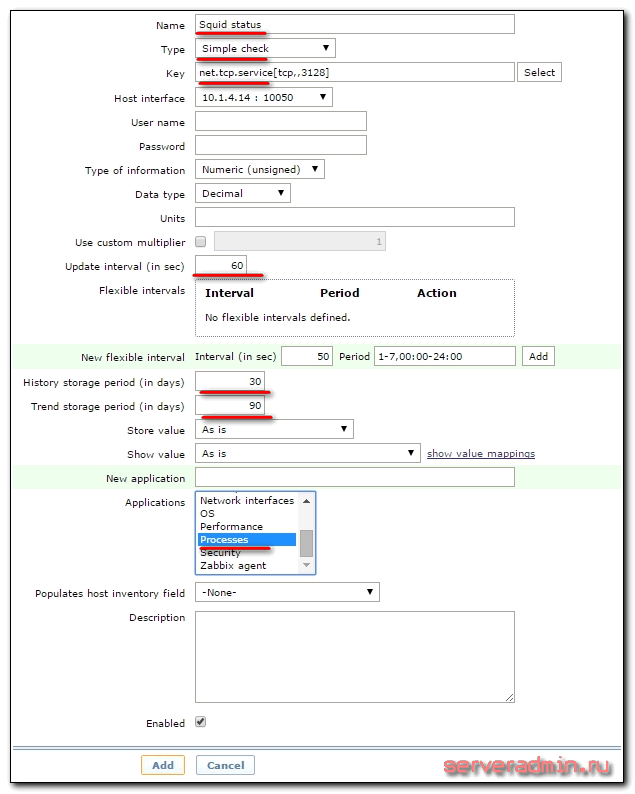
Обязательно заполнить первые 3, остальные на ваше усмотрение. Я считаю, что проверять каждые 30 секунд и хранить 90 дней информацию излишне, поэтому изменяю эти параметры в сторону увеличения.
| Squid status | Имя итема. |
| Simple check | Тип итема. |
| net.tcp.service[tcp,,3128] | Проверять tcp порт 3128 на указанном хосте. Если вы проверяете статус службы, расположенной не на том же хосте, к которому прикрепляете item, то после первой запятой можно указать необходимый адрес. |
Сразу создадим триггер, который в случае возврата в последних двух проверках значения итемом 0, будет отправлять уведомление о том, что служба недоступна. Для этого идем в раздел triggers и жмем Create trigger. Заполняем параметры элемента.
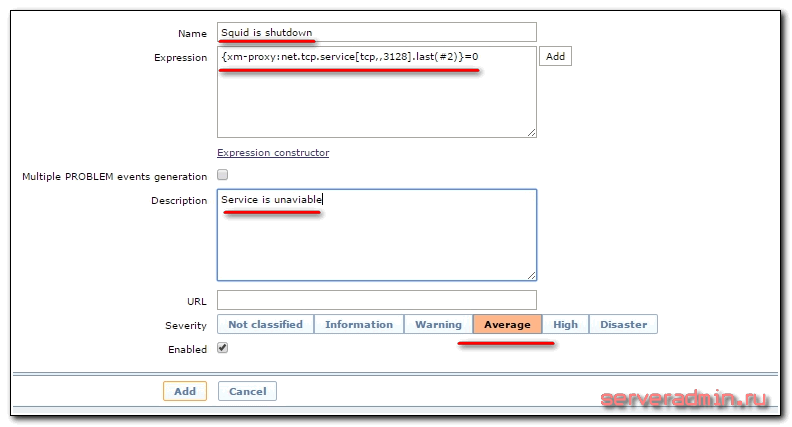
Выражение
Ждем пару минут и идем в Latest data проверять поступаемые значения.
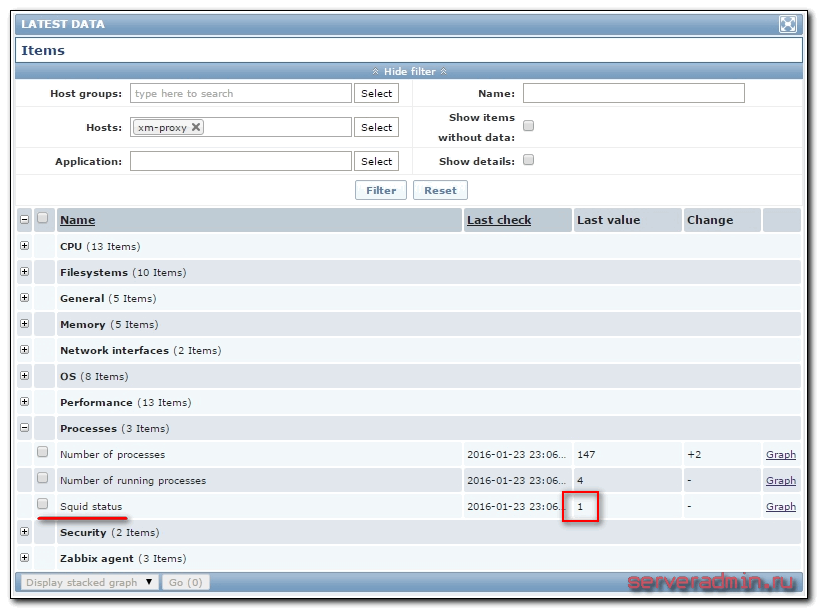
Чтобы проверить работу триггера, достаточно зайти на сервер и остановить squid. Если вы все сделали правильно, то после второй проверки, которая определит, что squid не отвечает по заданному адресу, вы получите уведомление на почту об этом. Если у вас не настроены или не работают уведомления на почту в zabbix, то читайте мою статью на эту тему.
Мониторинг локальной службы в linux
С мониторингом удаленного tcp сервиса разобрались, а что делать, если служба работает локально и к ней невозможно подключиться из вне. Тут уже не обойтись без установки zabbix агента. Если он установлен на хосте, то можно воспользоваться итемом с ключом proc.num. Этот ключ возвращает в качестве значения количество запущенных процессов. И если таких процессов больше одного, можно считать, что служба запущена.
Рассмотрим на примере мониторинга службы postgrey, реализующей greylist для борьбы со спамом. Она работает локально на почтовом сервере linux и является критическим сервисом, так как без него почтовый сервер postfix не будет принимать почту, выдавая временную ошибку почтовой системы. Проверим работу ключа proc.num:
Все в порядке, zabbix агент возвращает значение 1 при запущенном сервисе. Идем на сервер мониторинга, выбираем хост или шаблон и создаем новый item.
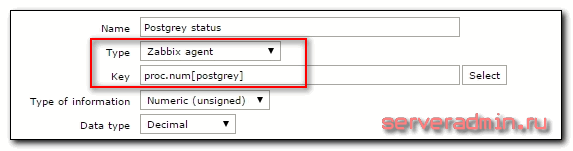
Показываю только основные параметры, остальные устанавливайте на свой вкус. Я лишь рекомендую не делать слишком частые проверки. В большинстве случаев в этом нет необходимости, а нагрузка на сервер постоянно растет при добавлении новых итемов.
Создаем триггер с оповещением о недоступности сервиса. При последних двух значениях равных 0 срабатываем.
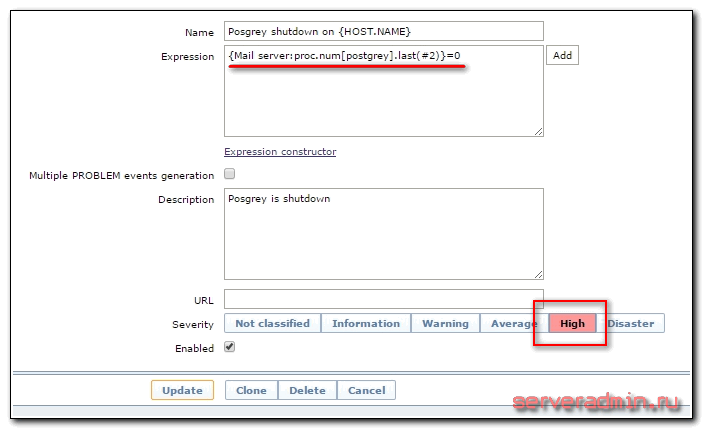
Я настраиваю триггер в шаблоне, поэтому сразу для удобства в названии триггера указываю маску для имени, чтобы было понятно в оповещении, на каком хосте сработал триггер. Как обычно, проверить поступаемые значения можно в Latest data.
Вот и все. Мы настроили мониторинг локальных служб linux в заббиксе.
Заключение
В своем материале я рассмотрел два различных способа, с помощью которых можно мониторить любой удаленный сервис по протоколу tcp, либо локальную службу на сервере linux. Конкретно в моих примерах можно было воспользоваться вторым способом в обоих случаях. Я этого не сделал, потому что первым способом я не просто проверяю, что служба запущена, я еще и обращаюсь к ней по сети и проверяю ее корректную работу для удаленного пользователя.
Разница тут получается вот в чем. Допустим, сервер squid у вас запущен и работает на сервере. Проверка работы локальной службы показывает, что сервис работает и возвращает значение 1. Но к примеру, вы настраивали firewall и где-то ошиблись. Сервис стал недоступен по сети, пользователи не могут им пользоваться. При этом мониторинг будет показывать, что все в порядке, служба запущена, хотя реально она не может обслужить запросы пользователей. В таком случай только удаленная проверка покажет, что с доступностью сервиса проблемы и надо что-то делать.
Из этого можно сделать вывод, что система мониторинга zabbix предоставляет огромные возможности по мониторингу. Какой тип наблюдения и сбора данных подойдет в конкретном случае нужно решать на месте, исходя из сути сервиса, за которым вы наблюдаете.
Источник



