- Мониторинг программы (процесса) Windows в Zabbix
- Zabbix: Мониторинг выборочного процесса (CPU, MEM) с защитой от ложных срабатываний
- 1. Создание нового шаблона Zabbix
- 2. Добавление макроса
- 3. Добавление элементов данных
- 4. Триггеры с гистерезисом
- 5. Конфигурация хоста
- Zabbix Documentation 5.2
- Sidebar
- Table of Contents
- 10 Заметки по выбору процессов в элементах данных proc.mem и proc.num
- Процессы, меняющие свои командную строку
- Потоки ядра Linux
- Мониторинг процесса Windows с помощью Zabbix?
- Zabbix Documentation 4.0
- Sidebar
- Table of Contents
- 9 Заметки о параметре типпамяти в элементах данных proc.mem
- Обзор
- FreeBSD
- Linux
- Solaris
Мониторинг программы (процесса) Windows в Zabbix

При очередной чистке записей, вышло так что забыл запустить программу назад в боевое состояние. Обнаружил только на следующий день, все бы ничего, но оплошность привела к анализу возможностей zabbix на предмет мониторинга состояния процесса программы. Оказалось в этом может помочь proc.num.
Так как у меня язык стоит русский в zabbix, прдполагаю что в 90% это будет у всех, поэтому следуем следующим маршрутом: Узлы сети — Выбираем свой узел сети (тот сервер на котором необходимо производить мониторинг процесса) — Элементы данных
Создаем новый элемент данных
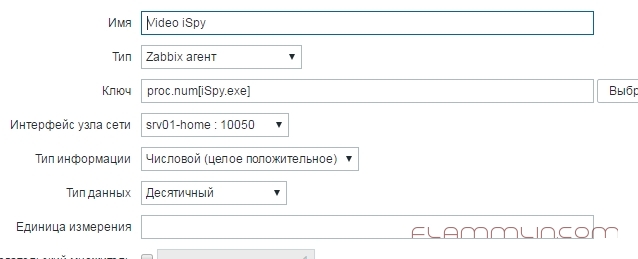
Ключ для нового элемента данных: proc.num[iSpy.exe] В скобках указан требуемый процесс мониторинга, в моем случае программа iSpy.exe. После настройки незабываем нажимать Добавить.
Дальше переходим в раздел триггеров и так же создаем новый триггер
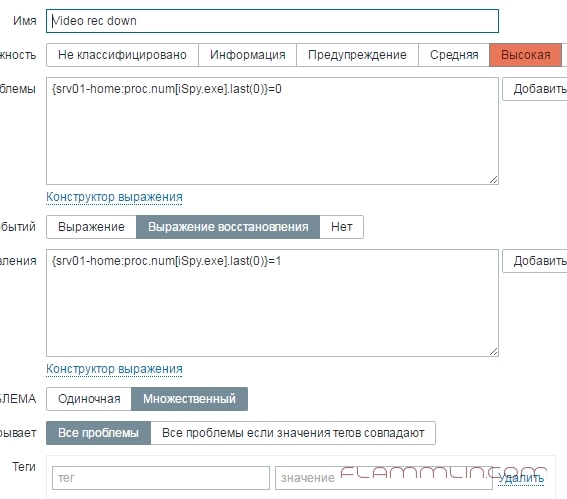
Соответственно, если процесс показал состояние 0 (значит программа закрыта и будет прислано уведомление), при значении 1 программа активна или произведен ее запуск.
В итоге если все правильно повторили за мной, то получите вот такую картинку при случае не запущенного приложения:
Zabbix: Мониторинг выборочного процесса (CPU, MEM) с защитой от ложных срабатываний
Как создать универсальный Zabbix шаблон для мониторинга Linux процесса, указанного по имени.
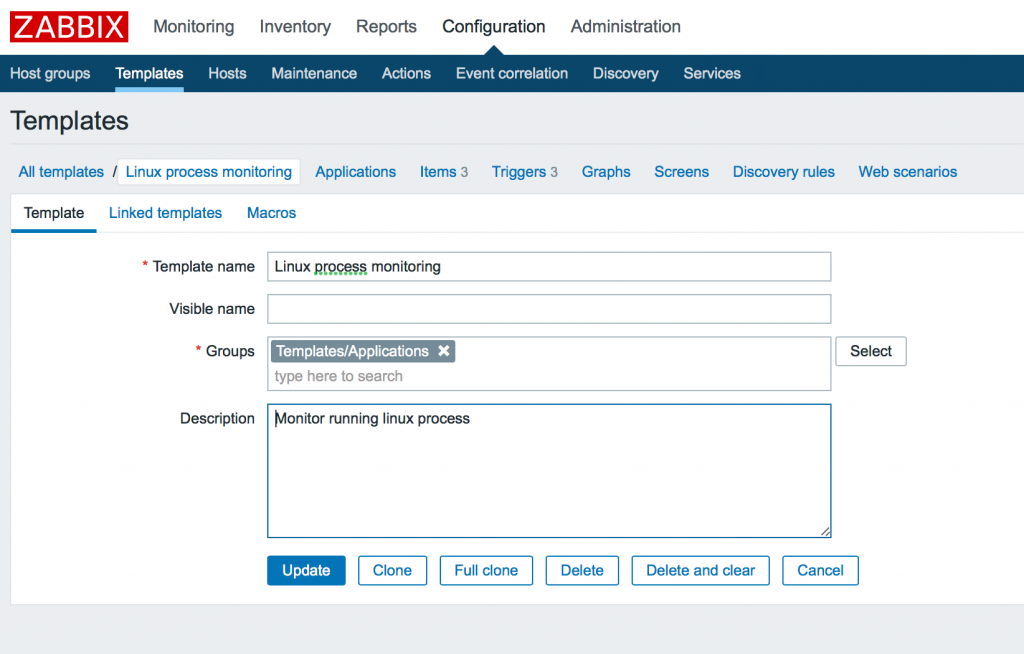
1. Создание нового шаблона Zabbix
Идем в Configuration -> Templates -> Create template и добавляем имя, группу и описание шаблона.
2. Добавление макроса
Мы хотим мониторить 3 параметра:
- количество процессов, с уведомлением о том, что процессов стало меньше (упали)
- использование памяти, с уведомлением о превышении
- использование процессора, с уведомлением о превышении
Давайте тут же определим значения по умолчанию. Для этого мы будем использовать макросы шаблона (вкладка Macros), чтобы потом была возможность заменить их для каждого хоста.
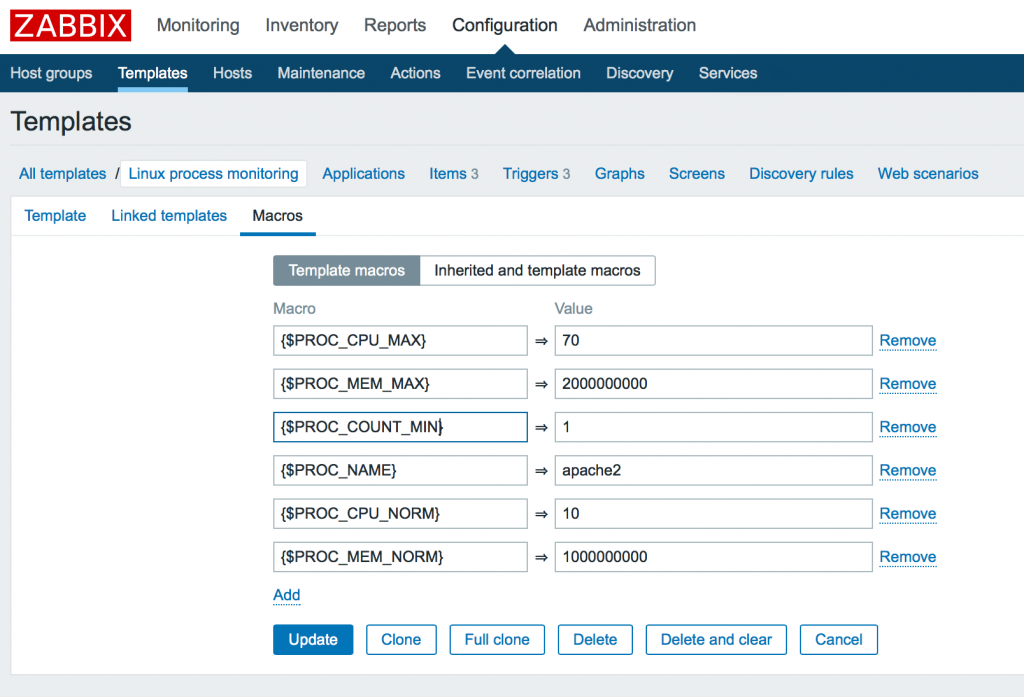
В этом примере мы создали 6 макросов.
Тут вы можете увидеть максимально использование cpu 70%, использование памяти 2G, минимально 1 запущенный процесс, а так же имя процесса для примера: apache2. Так же мы должны задать нормальные значения наших параметров для построения гистерезиса в целях защиты от ложных срабатываний (описано ниже). По этому мы так же указываем как 10% и как 1G.
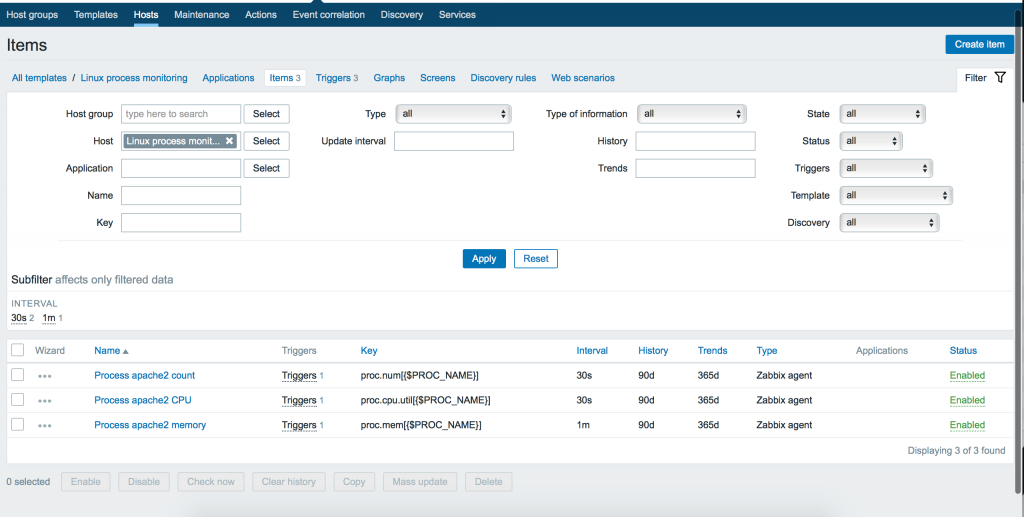
3. Добавление элементов данных
Теперь мы должны добавить элементы входных данных (items). Переходим в меню Items нашего шаблона и кликаем кнопку: Create item. Затем создаем 3 элемента:
- количество процессов
- использование cpu
- использование памяти
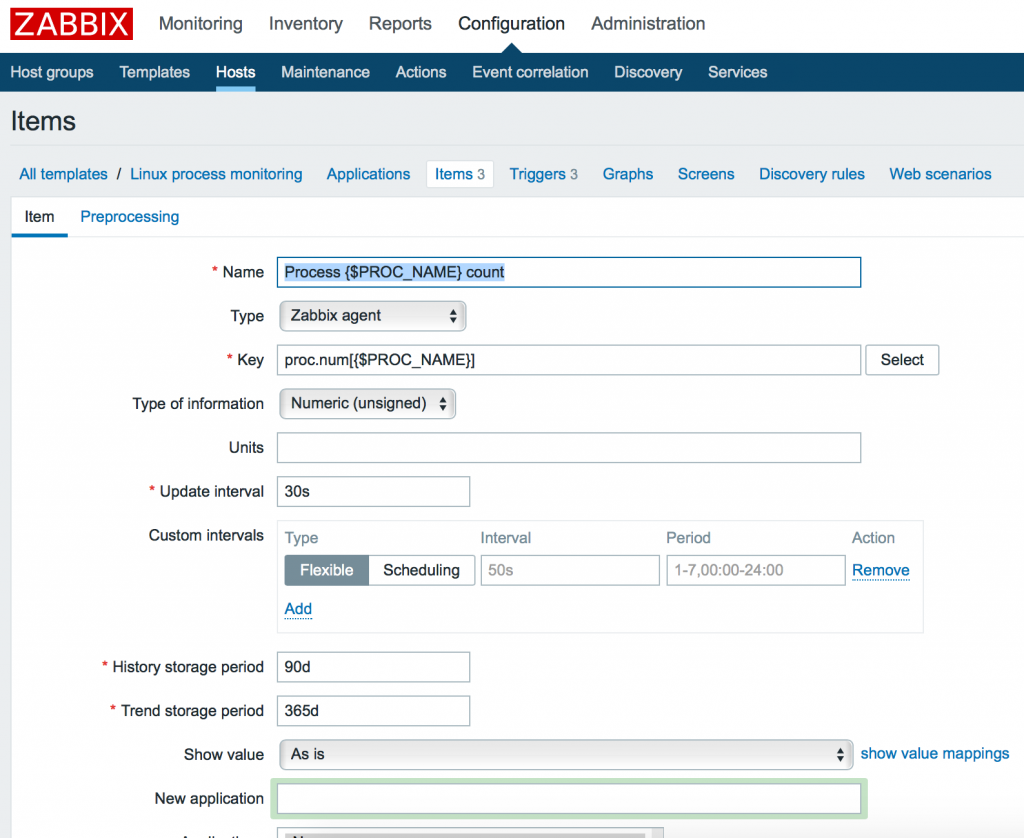
Мы можем использовать как макрос для задания конкретного имени процесса позже внутри конечной конфигурации хоста. Итак, добавляем 3 элемента с 3 ключами:
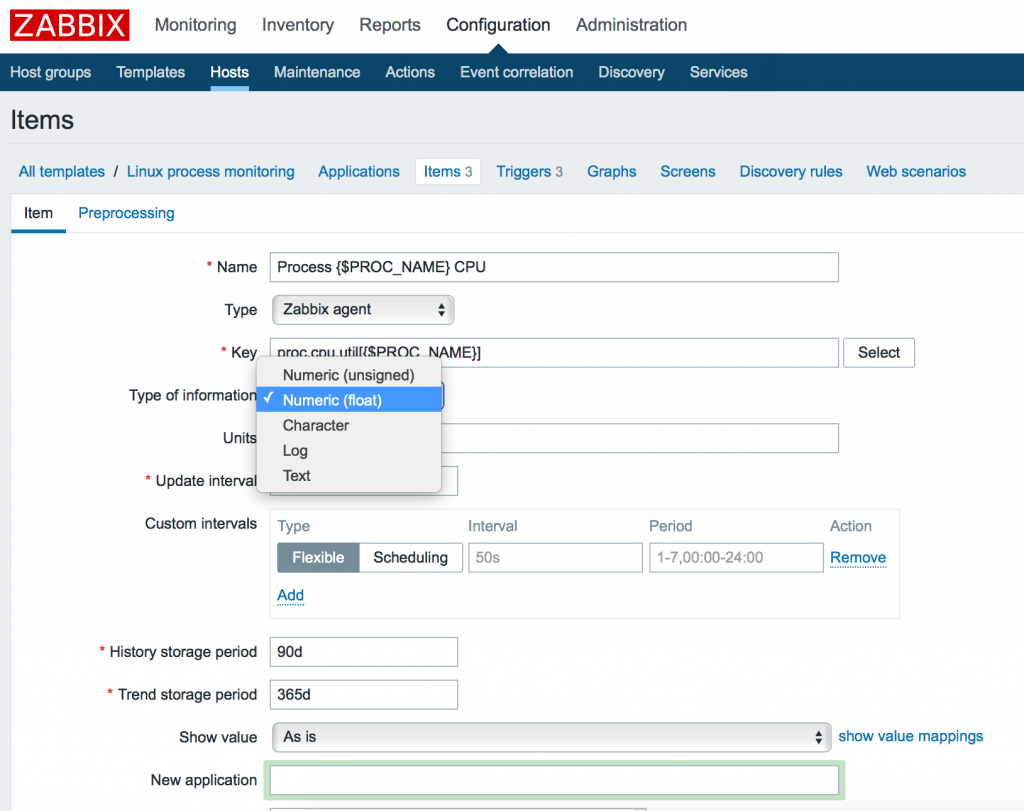
Заметим, что параметры могут иметь различные типы данных. Так к примеру proc.num, proc.mem имеет тип данных: Numeric (int), а proc.cpu.util – Numeric (float). Вы можете удостовериться в правильности указания типа данных в меню Key -> Select или официальной документации Zabbix.
4. Триггеры с гистерезисом
Пришло время создать тригеры. Переходим в закладку Triggers нашего шаблона. Вы можете использовать встроенный конструктор выражений, нажав Problem expression -> Add, затем выбрав item и function. К примеру last (most recent) T value. Но это только одно последнее значение. Оно будет меняться каждый раз, что вызовет нестабильность в определении статуса. Чтобы определить жесткое (установившееся) значение статуса, это значение должно повториться несколько раз подряд. Для такого подсчета лучше использовать функцию count. Болле подробную информацию о функциях вы можете получить в официальной документации Zabbix.
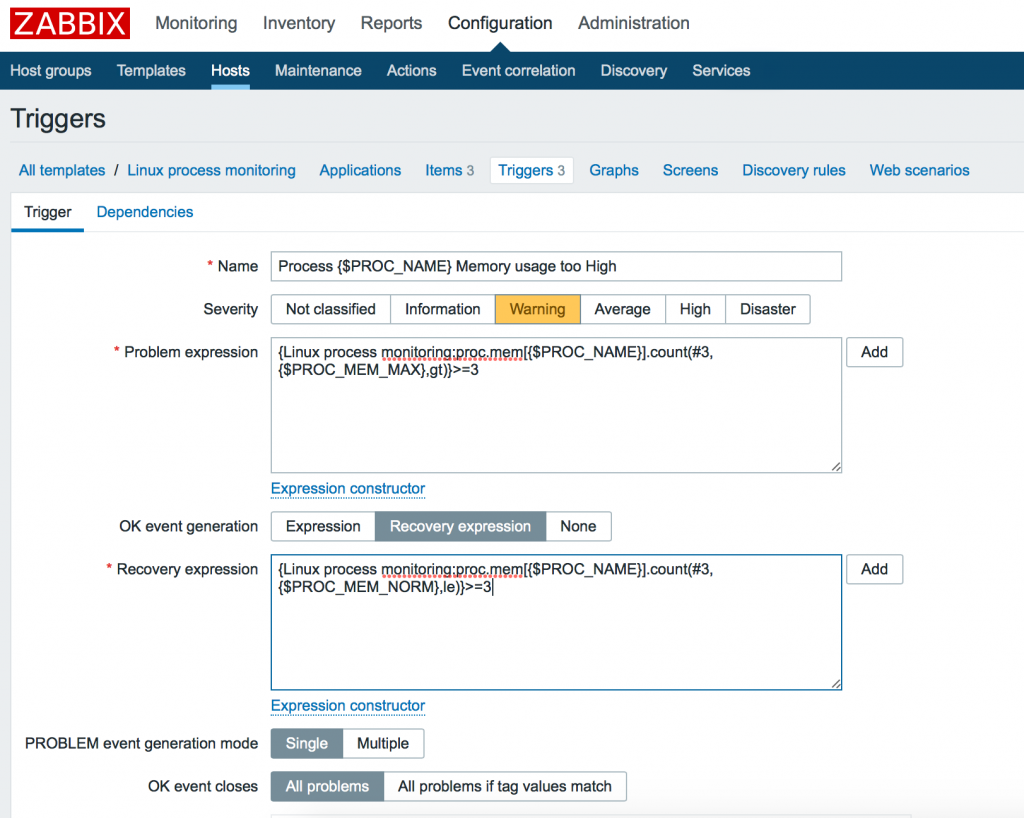
Итак, создаем триггер, который будет срабатывать при привышении потребления памяти больше чем <$PROC_MEM_MAX>3 раза подряд.
Мы можем прочитать его так: “Количество (count) последних 3 значений (#3), которые были больше (gt) чем равно >= 3″. Что означает, что все последние 3 значения были были больше чем PROC_MEM_MAX. Это хороший способ определения устоявшегося значения.
Но что делать с возвратом в нормальное состояние? Если мы просто оставим так как есть, мы рискуем получить что-то на подобие этого:
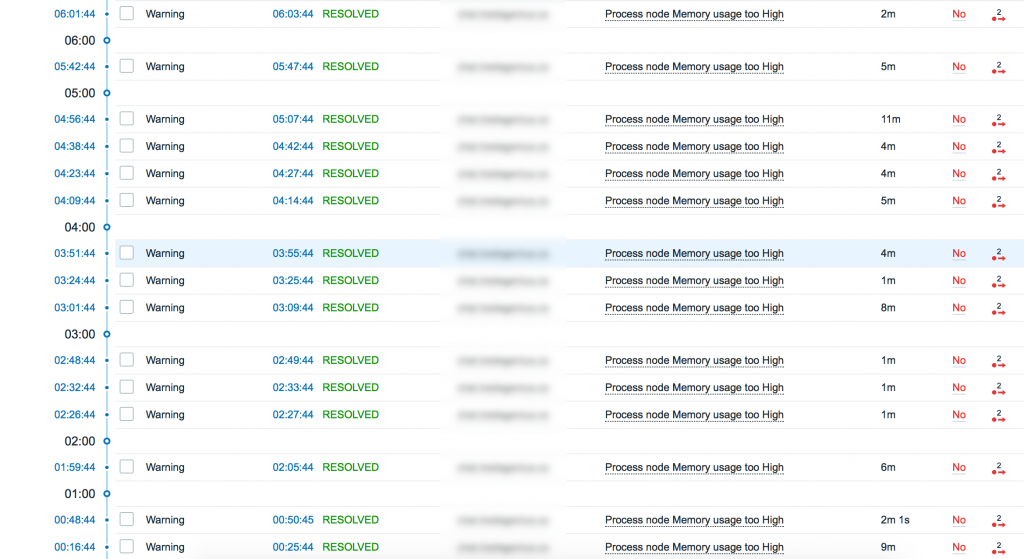
Каждые 5-10 минут статус меняет значение, колеблясь то выше, то ниже указанного порога. Он получает 3 подряд превышающих значения и триггер срабатывает, после чего он получает 3 нормальных значения и помечает проблему как RESOLVED (решена)! Что же делать? Нам поможет гистерезис с указанием не только максимального, но и нормального значения. Триггер будет в состоянии PROBLEM (проблема) до тех пор, пока значение нашего элемента не опустится до $
Итак, нажимаем OK event generation -> Recovery expression и добавляем выражение:
Его можно прочитать как: “Количество (count) последних трех (#3) значений элемента, которые были меньше или равны (le) числу было >= 3 раз. То есть установившееся в нормальном положении значение.
Подобным образом добавляем остальные тригеры (для использования процессора и количества процессов):
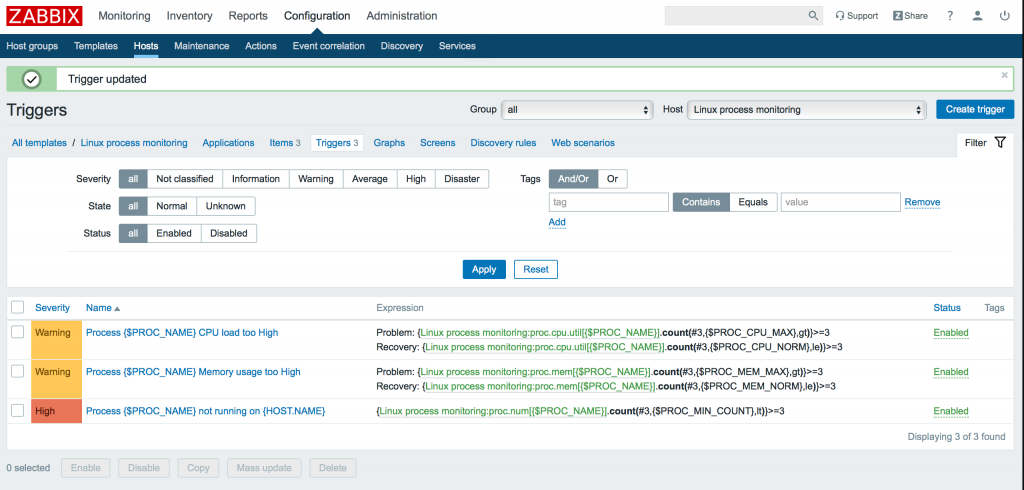
5. Конфигурация хоста
Теперь мы можем добавить наш шаблон к хосту. Идем в Configuration -> Hosts -> ваш сервер -> Templates. И добавляем только что созданный шаблон к серверу. Далее мы должны переопределись макросы.
Для примера на нашем сервере необходимо мониторить процесс node (node.js). Давайте посмотрим один из моих графиков данного процесса:
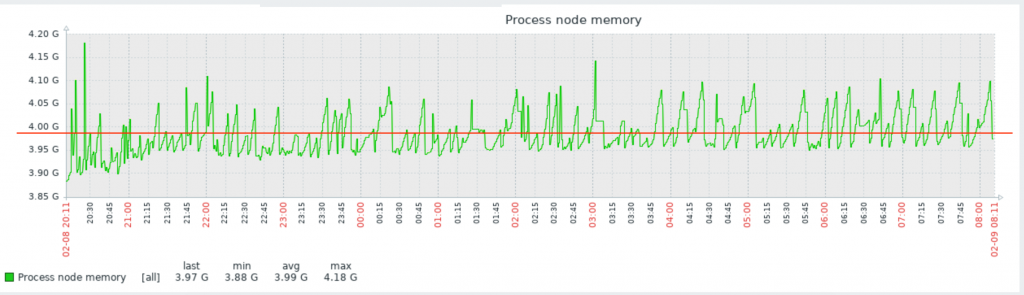
Вы видите, что у меня он потребляет порядка 4Gb RAM. Это нормальное состояние для моего сервиса. Так же вы видите колебание в районе красной линии. Без гистерезиса Zabbix нас просто заспамил бы сообщениями об изменении статуса в районе этой линии. В моем примере нормальное значение потребления памяти для указания в гистерезисе это 4G, а максимальное – больше чем 4.20G, пусть будет 4,5G. Добавим эти значения, а так же имя нашего процесса как макросы для данного хоста:
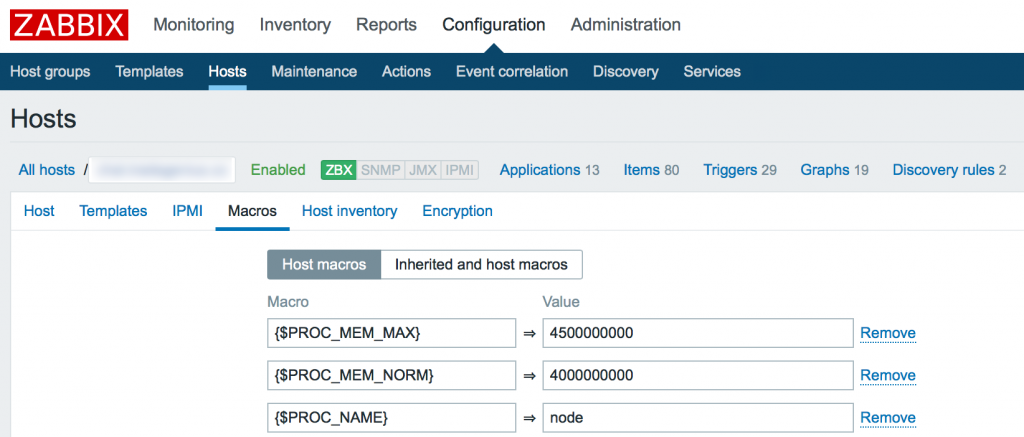
Итак, мой триггер перейдет в состоянии PROBLEM только когда значение потребляемой памяти будет больше чем 4,5Gb 3 раза подряд. А вернется он в нормальное состояние только тогда, когда потребление снизится ниже 4Г 3 раза подряд.
Готово! Позравляю! Теперь можно проверить последние данные в разделе Monitoring -> Latest data.
Zabbix Documentation 5.2
Sidebar
Table of Contents
10 Заметки по выбору процессов в элементах данных proc.mem и proc.num
Процессы, меняющие свои командную строку
Некоторые программы используют изменение своих командных стро как метод отображения своей текущей активности. Пользователь может просматривать эту активность при выполнении команд ps и top . Примеры таких программ включают PostgreSQL, Sendmail, Zabbix.
Давайте рассмотрим пример с Linux. Давайте предположим, что мы хотим наблюдать количество процессов Zabbix агента.
Команда ps отобразит интересующие процессы
Выбор процессов по имени и пользователю делает свое дело:
Теперь, давайте переименуем исполняемый файл zabbix_agentd на zabbix_agentd_30 и перезапустим его.
ps теперь отображает
Теперь выбор процессов по имени и пользователю выдает неправильный результат:
Почему простое переименование исполняемого файла на более длинное имя приводит к совершенно другому результату ?
Zabbix агент при запуске проверяет имя процесса. Открывает файл /proc/
/status и проверяет строку с Name . В нашем случае строками с Name являются:
Имя процесса в файле status обрезается до 15 символов.
Подобный результат можно увидеть при помощи команды ps :
Очевидно, что этот вывод не идентичен нашему proc.num[] значению zabbix_agentd_30 параметра имя . Будучи не в состоянии найти совпадение имени процесса в файле status Zabbix агент обращается к файлу /proc/
Как агент просматривает файл “cmdline” проиллюстрировано при помощи выполнения команды
В нашем случае файлы /proc/
/cmdline содержат невидимые, непечатаемые нулевые байты, которые используются для завершения строки в языке C. В этом примере нулевые байты отображаются как “ ”.
Zabbix агент проверяет “cmdline” основного процесса и берет zabbix_agentd_30 , которое соответствует значению zabbix_agentd_30 нашего параметра имя . Таким образом, основной процесс засчитывается элементом данных proc.num[zabbix_agentd_30,zabbix] .
При проверке следующего процесса, агент берет zabbix_agentd_30: collector [idle 1 sec] из файла cmdline и оно не соответствует нашему zabbix_agentd_30 параметра имя . То есть, засчитывается только основной процесс, который не меняет свою командную строку. Другие процессы агента модифицируют свои командные строки и они игнорируются.
Этот пример показывает, что в этом случае параметр имя нельзя использовать в proc.mem[] и proc.num[] для выбора процессов.
Использование параметра cmdline с надлежащим регулярным выражением даст правильный результат:
Будьте осторожны в использовании элементов данных proc.mem[] и proc.num[] при наблюдении за программами, которые модифицируют свои командные строки.
Перед тем как поместить параметры имя и cmdline в элементах данных proc.mem[] и proc.num[] , вы мозможно захотите протестировать эти параметры, используя элемент данных proc.num[] и команду ps .
Потоки ядра Linux
Нельзя выбрать потоки при помощи »cmdline» параметров в элементах данных »proc.mem[]» и »proc.num[]»
Давайте возьмем в качестве примера один из потоков ядра:
Его можно выбрать при помощи параметра имя :
Но выбор при помощи параметра cmdline не работает:
Причина такого поведения кроется в том, что Zabbix агент берет регулярное выражение, которое указано в параметре cmdline , и применяет его к содержимому процесса /proc/
/cmdline . В случае потоков ядра, их файлы /proc/
/cmdline пустые. Таким образом, параметр cmdline никогда не совпадет.
Вычисление потоков в элементах данных »proc.mem[]» и »proc.num[]»
Потоки ядра Linux вычисляются при помощи элемента данных proc.num[] , но не сообщают информацию о памяти в элементе данных proc.mem[] . Например:
Но что случится, если имеется пользовательский процесс с таким же именем как и у потока ядра? Такой вариант будет выглядеть примерно следующим образом:
Мониторинг процесса Windows с помощью Zabbix?
Как организовать мониторинг процессов windows c помощью zabbix? Интересует способ узнать сколько процентов от общего ресурса процессора потребляет тот или иной процесс.
Версия Windows: Windows 10 pro 1909 x64
Версия zabbix сервера: 4.4.3
Способ снятия метрик: активный агент
- Вопрос задан более года назад
- 1215 просмотров
1.открываем perfmon.msc (не перепутайте с perfmon.exe — это немного другая программа.)
2.в «системном мониторе» (сейчас под рукой руссифицированная ось, поэтому ищите аналогичное на английском, благо монитор по умолчанию там один) нажимаем «добавить счетчики»
3. выбираем Process и ваш процесс, нужные метрики.
Все это только для понимания «что» вы будете мониторить.
теперь «как»: идем и внимательно читаем:
https://www.zabbix.com/documentation/4.2/ru/manual.
https://www.zabbix.com/documentation/4.2/ru/manual.
В последней статье ищем proc_info — это оно и есть
Если есть какие то перфкаунтеры которых вы не нашли в заббикс — в 1й статье в конце есть как добавить нужные через user parameters
Почему perfcounters а не WMI? Потому что обращение к WMI — довольно дорогая операция, часто не позапрашиваешь (а если залезть в глубины того что доступно через WMI — выяснится что там те же перфкаунтеры, облагороженные и обогащенные) — частое обращение довольно сильно жрет CPU
Почему не сторонняя программа? Потому что Win уже собирает данные процессов и основная задача — добраться до них
Zabbix Documentation 4.0
Sidebar
Table of Contents
9 Заметки о параметре типпамяти в элементах данных proc.mem
Обзор
Параметр типпамяти поддерживается на платформах Linux, AIX, FreeBSD, и Solaris.
Три общих значения ‘типапамяти’ поддерживаются на всех этих платформах: pmem , rss и vsize . Кроме того, также поддерживаются специфичные значения ‘типапамяти’ на некоторых платформах.
Смотри в таблице значения поддерживаемые параметром ‘типпамяти’ на AIX.
| Поддерживаемое значение | Описание | Источник в структуре procentry64 | Пытается быть совместимым с |
|---|---|---|---|
| vsize 1) | Размер виртуальной памяти | pi_size | |
| pmem | Процент физической памяти | pi_prm | ps -o pmem |
| rss | Резидентный размер набора | pi_trss + pi_drss | ps -o rssize |
| size | Размер процесса (код + данные) | pi_dvm | “ps gvw” колонка SIZE |
| dsize | Размер данных | pi_dsize | |
| tsize | Размер текста (кода) | pi_tsize | “ps gvw” колонка TSIZ |
| sdsize | Размер данных из разделяемой библиотеки | pi_sdsize | |
| drss | Резидентный размер набора данных | pi_drss | |
| trss | Резидентный размер набора текста | pi_trss |
FreeBSD
Смотри в таблице значения поддерживаемые параметром ‘типпамяти’ на FreeBSD.
| Поддерживаемое значение | Описание | Источник в структуре kinfo_proc | Пытается быть совместимым с |
|---|---|---|---|
| vsize | Размер виртуальной памяти | kp_eproc.e_vm.vm_map.size или ki_size | ps -o vsz |
| pmem | Процент физической памяти | вычисляется из rss | ps -o pmem |
| rss | Резидентный размер набора | kp_eproc.e_vm.vm_rssize или ki_rssize | ps -o rss |
| size 2) | Размер процесса (код + данные + стэк) | tsize + dsize + ssize | |
| tsize | Размер текста (кода) | kp_eproc.e_vm.vm_tsize или ki_tsize | ps -o tsiz |
| dsize | Размер данных | kp_eproc.e_vm.vm_dsize или ki_dsize | ps -o dsiz |
| ssize | Размер стэка | kp_eproc.e_vm.vm_ssize или ki_ssize | ps -o ssiz |
Linux
Смотри в таблице значения поддерживаемые параметром ‘типпамяти’ на Linux.
| Поддерживаемое значение | Описание | Источник из /proc/ |
|---|
/status файла
Заметки для Linux:
/status. Во время самостоятельного измерения сегмент данных агента увеличивается на 4 КБ и затем возвращается к предыдущему значению.
Solaris
Смотри в таблице значения поддерживаемые параметром ‘типпамяти’ на Solaris.



