- Zabbix + Iostat: мониторинг дисковой подсистемы
- Мониторинг дискового пространства активным Zabbix-агентом
- Решение.
- Создаём шаблон.
- Назначаем шаблон компьютеру
- Аренда серверов.
- 1С:Предприятие “в облаке”.
- IP-телефония в офис.
- Мониторинг размера бэкапа в Zabbix
- Введение
- Скрипты по сбору информации о размере бэкапов
- Настраиваем zabbix агент
- Добавляем новый итем на сервер мониторинга zabbix
- Заключение
Zabbix + Iostat: мониторинг дисковой подсистемы
Zabbix + Iostat: мониторинг дисковой подсистемы. 
Зачем?
Дисковая подсистема одна из важных подсистем сервера и от уровня нагрузки на дисковую подсистему зачастую зависит очень многое, например скорость отдачи контента или то как быстро будет отвечать база данных. Это в большей степени относится к почтовым или файловым серверам, серверам БД. Вобщем, показатели дисковой производительности отслеживать нужно. На основании графиков производительности дисковой подсистемы мы можем принять решение о необходимости наращивания мощностей задолго до того как петух клюнет. Да и вобще полезно поглядывать от релиза к релизу как работа разработчиков сказывается на уровне нагрузки.
Под катом, о мониторинге и о том как настроить.
Зависимости:
Мониторинг реализован через zabbix агента и две утилиты: awk и iostat (пакет sysstat). Если awk идет в дистрибутивах по умолчанию, то iostat требуется установить с пакетом sysstat (тут отдельное спасибо Sebastien Godard и сотоварищи).
Известные ограничения:
Для мониторинга нужен sysstat начиная с версии 9.1.2, т.к. там есть очень важное изменение: «Added r_await and w_await fields to iostat’s extended statistics». Так что следует быть внимательным, в некоторых дистрибутивах, например в CentOS немного «стабильная» и менее фичастая версия sysstat.
Если же отталкиваться от версии zabbix (2.0 или 2.2) то тут вопрос не принципиален, работает на обоих версиях. На 1.8 не заработает т.к. используется Low level discovery.
Возможности (чисто субъективно, по мере убывания полезности):
- Low level discovery (далее просто LLD) для автоматического обнаружения блочных устройств на наблюдаемом узле;
- утилизация блочного устройства в % — удобная метрика для отслеживания общей нагрузки на устройстве;
- latency или отзывчивость — доступна как общая отзывчивость, так и отзывчивость на операциях чтения/записи;
- величина очереди (в запросах) и средний размер запроса (в секторах) — позволяет оценить характер нагрузки и степень загруженности устройства;
- текущая скорость чтения/записи на устройство в человекопонятных килобайтах;
- количество запросов чтения/записи (в секунду) объединенных при постановке в очередь на выполнение;
- iops — величина операций чтения/записи в секунду;
- усредненное время обслуживания запросов (svctm). Вообще она deprecated, разработчики обещают ее давно спилить, но все никак руки не доходят.
Вобщем как видно, здесь доступны все те метрики которые есть в iostat (кто незнаком с этой утилитой настоятельно рекомендую заглянуть в man iostat).
Доступные графики:
Графики рисуются per-device, LLD обнаруживает устройства которые попадают под регулярное выражение «(xvd|sd|hd|vd)[a-z]», так что если ваши диски имеют другие имена, можно легко внести соответствующие изменения. Такая регулярка сделана чтобы обнаруживать устройства которые будут родительскими по отношению к прочим разделам, LVM томам, MDRAID массивам и т.п. Вобщем чтобы не собирать лишнего. Немного отвлеклись, итак список графиков:
- Disk await — отзывчивость устройства (r_await, w_await);
- Disk merges — операции слияния в очереди (rrqm/s, wrqm/s);
- Disk queue — состояние очереди (avgrq-sz, avgqu-sz);
- Disk read and write — текущие значения чтения/записи на устройство (rkB/s, wkB/s);
- Disk utilization — утилизация диска и значение IOPS (%util, r/s, w/s) — позволяет неплохо отслеживать скачки в утилизации и чем, чтением или записью они были вызваны.
Аналоги и отличия:
В заббиксе есть коробочные варианты для похожего мониторинга, это ключи vfs.dev.read и vfs.dev.write. Они хороши и прекрасно работают, но менее информативны чем iostat. Например в iostat есть такие метрики как latency и utilization.
Также есть аналогичный шаблон от Michael Noman на мой взгляд отличие только одно, она заточена на старые версии iostat, ну и + небольшие синтаксические изменения.
Где взять:
Итак, мониторинг состоит из файла конфигурации для агента, двух скриптов для сбора/получения данных и шаблон для веб-интерфейса. Все это доступно в репозитории на Github, поэтому любым доступным способом (git clone, wget, curl, etc. ) скачиваем их на машины которые хотим замониторить и переходим к следующему пункту.
Как настроить:
- iostat.conf — содержимое этого файла следует поместить в файл конфигурации zabbix агента, либо положить в каталог конфигурации который указан в Include опции основной конфигурации агента. Вобщем зависит от политики партии. Я использую второй вариант, для кастомных конфигов у меня отдельная директория.
- scripts/iostat-collect.sh и scripts/iostat-parse.sh — эта два рабочих скрипта следует скопировать в /usr/libexec/zabbix-extensions/scripts/. Тут также можно использовать удобное вам размещение, однако в таком случае не забудьте поправить пути в параметрах определенных в iostat.conf. Не забудьте проверить что они исполняемы (mode=755).
Теперь все готово, запускаем агента и переходим на сервер мониторинга и выполняем команду (не забываем подменить agent_ip):
Таким образом, проверяем с сервера мониторинга что iostat.conf подгрузился и отдает информацию, заодно смотрим что LLD работает. В качестве ответа вернется JSON с именами обнаруженных устройств. Если ответа не пришло, значит что-то сделали не так.
Также есть такой момент, что zabbix server не дожидается выполнения некоторых item’ов со стороны агентов (iostat.collect). Для этого следует увеличить значения Timeout.
Как настроить в web интейрфейс:
Теперь остался шаблон iostat-disk-utilization-template.xml. Через веб интерфейс импортируем его в раздел шаблонов и назначем на наш хост. Тут все просто. Теперь остается ждать примерно один час, такое время установлено в LLD правиле (тоже настраивается). Или можно поглядывать в Latest Data наблюдаемого хоста, в раздел Iostat. Как только там появились значения, можно перейти в раздел графиков и понаблюдать за первыми данными.
И напоследок тройка скринов графиков c локалхоста))):
Непосредственно данные в Latest Data: 
Графики отзывчивости (Latency):
График утилизации и IOPS:
Вот и собственно и все, спасибо за внимание.
Ну и по традиции, пользуясь случаем передаю привет Федорову Сергею (Алексеевичу) 🙂
Источник
Мониторинг дискового пространства активным Zabbix-агентом
Для того, чтобы при помощи активного агента Zabbix следить за дисковым пространством компьютера, как оказалось, не нужно писать скриптов. Совсем. 🙂 Все уже умеет делать активный Zabbix-агент “из коробки”. Достаточно создать шаблон и назначить его компьютеру. Всё.
А теперь по порядку.
Сферический компьютер в вакууме. Нужно следить за заполненностью системного диска Windows. Предположим, что у нас всё стандартно, поэтому в качестве буквы системного диска используется “C:”.
Решение.
При помощи активного агента Zabbix будем собирать 4 параметра диска “C:”:
- общий размер диска
- размер занятого места
- размер свободного места
- процент свободного места.
На основании этих параметров создадим 4 триггера:
- Предупреждение. Свободно менее 20%
- Средняя важность. Свободно менее 10%
- Высокая важность. Свободно менее 1 Гб.
- Чрезвычайная важность. Свободно менее 100 Мб.
И создадим 2 графика:
- Размер свободного места
- Размер свободного места в процентах.
Создаём шаблон.
Имя шаблона: Active Computer – SystemDrive
Группа данных: Filesystems
Элементы данных:
- SystemDriveSizeFree – vfs.fs.size[“c:”,free]
- SystemDriveSizePFree – vfs.fs.size[“c:”,pfree]
- SystemDriveSizeTotal – vfs.fs.size[“c:”,total]
- SystemDriveSizeUsed – vfs.fs.size[“c:”,used]
Триггеры:
- Предупреждение. Меньше 20% свободно на системном диске компьютера













Назначаем шаблон компьютеру
И начинаем получать данные… 🙂

Аренда серверов.

Надёжные сервера с Pro-бегом
У ВАС В ОФИСЕ!
1С:Предприятие “в облаке”.

Безопасный доступ к своей 1С из офиса, командировки и т.п.!
IP-телефония в офис.

IP-телефония давно перестала быть роскошью в офисах.
Хотите себе в офис цифровую АТС — обращайтесь. !
Источник
Мониторинг размера бэкапа в Zabbix
Ранее я уже рассказывал, как мониторить бэкапы с помощью zabbix. Захотелось собирать информацию о размере бэкапа, чтобы смотреть тренды по его увеличению или уменьшению. Немного пораскинул мозгами и придумал решение задачи по мониторингу размера бэкапов с помощью уже привычного инструмента UserParameter.
Введение
Я уже много раз использовал внешние скрипты и UserParameter для мониторинга в zabbix. Не буду подробно на этом останавливаться. Приведу список своих материалов по этой теме:
Использовать будем такой же подход. У нас будет 2 скрипта. Первый будет собирать информацию о размерах папок с файлами, второй будет передавать сформированные данные в заббикс. Делать все будем раз в сутки, чаще нет смысла, так как у меня бэкапы выполняются с суточным интервалом. Сами бэкапы представляют из себя не отдельные файлы-архивы, а папки. Настроено все примерно так же, как в статье про настройку backup с помощью rsync.
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
То же самое на Debian 10, если предпочитаете его:
Скрипты по сбору информации о размере бэкапов
Первый скрипт будет проверять размер каталогов и записывать результат в текстовый файл. Сначала я собирал размер в байтах, потом решил скриптом преобразовывать в гигабайты, но через некоторое время нашел способ в заббиксе преобразовывать размер из байтов в гигабайты и снова стал в заббикс передавать только байты. Так оказалось удобнее всего. Создаем папку для скриптов и кладем туда сам скрипт:
Если у вас несколько папок с бэкапами, добавляете их все в скрипт. Можно автоматизировать этот процесс, задать переменные с названиями папок с бэкапами и в цикле их перебирать, но у меня это не получилось, так как пути сильно разные. Пришлось все в ручную добавлять. Я привожу пример с одной папкой. Остальные по аналогии добавляете, не забывая изменять имена переменных, в которые передается размер директории.
Результатом работы скрипта будет файл следующего содержания:
| 1с | имя бэкапа |
| размер бэкапа в байтах |
Необходимо добавить этот скрипт в крон и выполнять раз в сутки. Находите конфиг крона в вашей системе и добавляете туда:
Время выбираете на свое усмотрение. В данном случае у меня отдельный сервер для бэкапов, его можно днем напрячь, когда он простаивает.
Дальше рисуем скрипт, который будет передавать данные в заббикс:
Проверяем его работу следующим образом:
На выходе просто цифра с размером, которая уходит на сервер заббикса. То, что нужно. Важно не забыть один момент, иначе ничего не зааработает. Скрипту нужно назначить владельца zabbix, чтобы агент мог его запускать:
Если этого не сделать, получите ошибку в логе агента:
Настраиваем zabbix агент
Делаем все как обычно. Идем в папку /etc/zabbix/zabbix_agentd.conf.d и создаем файл с пользовательскими параметрами:
Сохраняем файл. Перезапускаем агента и проверяем в консоли, что улетит на сервер:
Все в порядке, агент настроили. Осталось добавить новый итем на сервер.
Добавляем новый итем на сервер мониторинга zabbix
Кратко расскажу, что делать на сервере. Раньше я уже неоднократно рассматривал этот момент, поэтому не буду на нем подробно останавливаться. Больше информации можете получить в предыдущих статьях, которые я привел в самом начале. Идем в веб интерфейс. Выбираем хост, на котором мы только что настраивали агент, заходим в список итемов и добавляем новый:
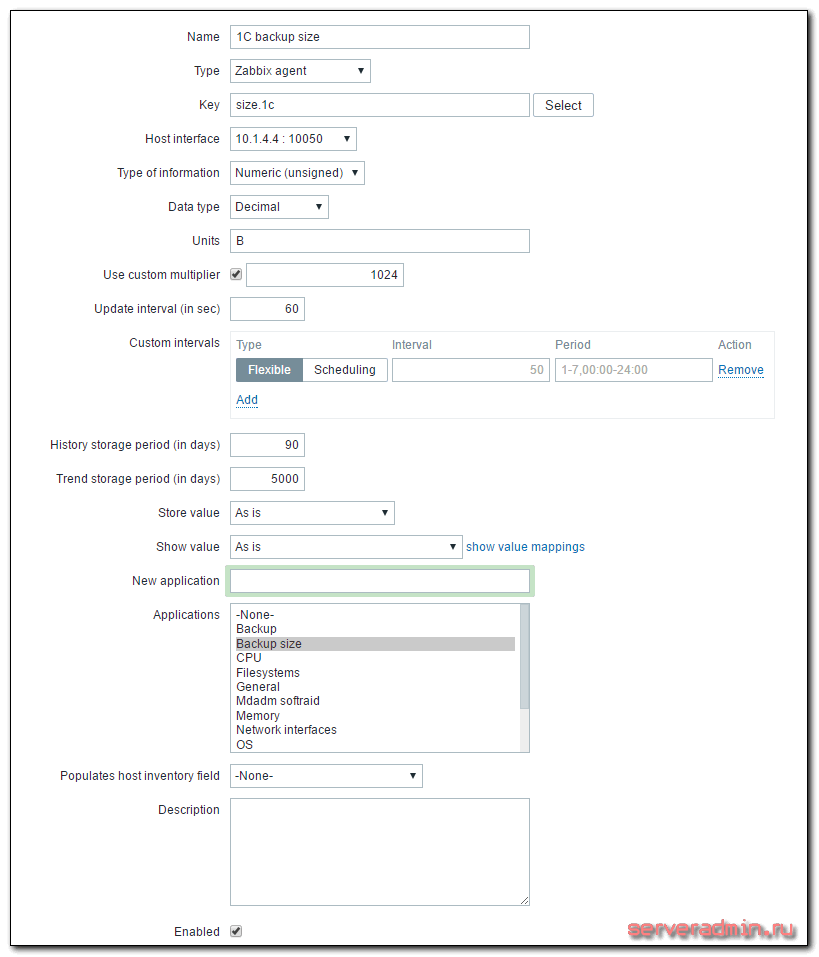
| Name | Произвольное имя итема. |
| Key | Название ключа, должно быть точно таким же, как в UserParameter в агенте. |
| Update interval | Время обновления, в данном случае раз в минуту для отладки, потом рекомендую ставить раз в сутки. |
| Units | Единица измерения, в данном случае байты. |
| Use custom multiplier | Пользовательский множитель для корректного перевода в гигабайты |
Сохраняем новый итем и ждем поступления данных. В случае указания большого интервала обновления, к примеру, раз в сутки, я не знаю, когда заббикс первый раз проведет опрос. Будет здорово, если кто-нибудь подскажет. Меня всегда интересовал этот момент. Во время отладки я ставлю маленький интервал обновления, например минуту или две. После того, как убеждаюсь, что все работает корректно, изменяют интервал на необходимый.
Смотреть результат следует, как обычно, в Latest data. Там же можно и график посмотреть, когда накопятся данные для него. Для более наглядных и красивых графиков, необходимо будет их вручную создать в конструкторе графиков конкретного хоста. Лично мне достатчно информации из последних данных.

Заключение
С помощью внешних скриптов настроили еще один тип мониторинга для бэкапов. Если у кого-то есть мысли на тему того, что нужно мониторить у резервных копий, высказывайте пожелания, попробую реализовать. Я очень внимательно отношусь к бэкапам и помимо автоматических проверок стараюсь время от времени заходить и глазами проверять все ли в порядке, на месте ли данные и можно ли их восстановить.
На своем опыте убедился в необходимости таких проверок. Приходилось сталкиваться с отказами различных систем, в том числе и коммерческих. Сервис может тупо зависнуть или выключиться, а ты надеешься на оповещения об ошибках, а раз не получаешь их, думаешь, что все в порядке, а на самом деле у тебя нет резервных копий. Еще вариант, с которым приходилось сталкиваться, это когда вроде все в порядке, никаких ошибок нет, а во время восстановления получаешь ошибку чтения данных.
Было бы неплохо автоматизировать восстановление данных и сравнение их с оригиналом для стопроцентной уверенности в том, что у тебя живые копии. Но для этого нужны дополнительные ресурсы.
Источник



