- Настраиваем официальный шаблон PostgreSQL на Zabbix 4.4
- Подготовка шаблона
- Настройка шаблона для агента Zabbix
- Добавление шаблона на фронтенде Zabbix
- Шаблоны ZABBIX
- Шаблоны ZABBIX
- Мониторинг доступности службы linux с помощью Zabbix
- Введение
- Описание работы простых проверок (simple check)
- Мониторинг доступности сервиса по сети
- Мониторинг локальной службы в linux
- Заключение
Настраиваем официальный шаблон PostgreSQL на Zabbix 4.4
В Zabbix появился официальный Template DB PostgreSQL. В этой статье настроим его в Zabbix 4.4.

Если у вас все хорошо с английским, то рекомендую установить шаблон по официальному мануалу
Тем не менее в моей статье учтены нюансы, которых нет по этой ссылке.
Подготовка шаблона
1. Переходим в домашний каталог.
2. Скачиваем утилиту git и клонируем официальный репозиторий Zabbix, который находится на GitHub.
3. Переходим в каталог с шаблоном PostgreSQL.
Настройка шаблона для агента Zabbix
1. Подключимся к PostgreSQL.
2. Создадим пользователя zbx_monitor только для чтения с доступом к серверу PostgreSQL.
Для PostgreSQL версии 10 и выше:
Для PostgreSQL версии 9.6 и ниже:
3. Скопируем каталог postgresql/ в каталог /var/lib/zabbix/. Если у вас в /var/lib/ отсутствует каталог zabbix/, то создайте его. Каталог postgresql / содержит файлы, необходимые для получения метрик из PostgreSQL.
4. Затем скопируем файл template_db_postgresql.conf в каталог конфигурации агента Zabbix /etc/zabbix/zabbix_agentd.d/ и перезапустите агента Zabbix.
5. Теперь отредактируем файл pg_hba.conf, чтобы разрешить подключение к Zabbix. Подробнее о файле pg_hba.conf: https://www.postgresql.org/docs/current/auth-pg-hba-conf.html.
Добавьте одну из строк (Если не понимаете зачем это нужно, то добавьте только первую строку.):
Если PostgreSQL установлен из репозитория PGDG, добавьте путь к pg_isready в переменную среды PATH для пользователя zabbix.
* — так как у меня pgsql 12 версии, то у вас вместо pgsql-12 будет другой путь.
Если этого не сделать, то Status: Ping всегда будет в состоянии Down.
Добавление шаблона на фронтенде Zabbix
Считаю, что те, кому требуется снимать метрики с PostgreSQL итак знают как добавлять шаблоны. Поэтому опишу процесс кратко.
- Заходим на страницу Zabbix;
- Переходим на страницу «Configuration» => «Host«;
- Нажимаем на кнопку «Create host» или выбираем существующий хост;
- На странице создания/редактирования хоста выбираем вкладку «Templates» и и жмём на линк «Add«;
- В «Group» из списка выбираем «Templates/Databases», выбираем шаблон «Template DB PostgreSQL«, жмём кнопку «Select» и нажимаем кнопку «Update«;
Ждём некоторое время и наконец, переходим в «Monitoring» => «Latest data» => «Hosts» выбираем сервер с PostgreSQL => нажимаем «Apply«.
Enjoy!
Источник
Шаблоны ZABBIX
После установки ZABBIX и его настройки пришло время приступить к созданию шаблонов мониторинга. По умолчанию в системе доступно множество готовых к использованию шаблонов и в большинстве случаев они вполне способны решать многие задачи по наблюдению и выявлению неисправностей, а потому вам остается лишь добавить необходимые для наблюдения узлы или устройства, настроить хотя бы небольшую иерархию и логически сгруппировать объекты мониторинга. Интерфейс ZABBIX в принципе позволяет без чтения документации самостоятельно разобраться в настройках, но все же новичка будут сильно раздражать неочевидные моменты и огрехи в разработке интерфейса — надо признать, что он получился далеко не самым удобным, а многие основные элементы управления выглядят просто «слепо» и неопытный администратор не сразу обратит на них внимание. Однако все же стоит сказать большое спасибо разработчикам продукта хотя бы за то, что этот интерфейс все же есть и подавляющее большинство задач администрирования и настройки можно выполнить именно из него.
Если вам интересна тематика ZABBIX, рекомендую обратиться к основной статье — Система мониторинга ZABBIX, в ней вы найдете дополнительную информацию.
Шаблоны ZABBIX
Дефолтные шаблоны ZABBIX покрывают достаточно большую область мониторинга, начиная от unix- и windows- систем, заканчивая сетевыми устройствами. Тем не менее перед системными администраторами часто встает задача ручного допиливания шаблонов, а иногда и вообще создания собственных с нуля. В этом вам помогут мои статьи, ну и конечно же официальная документация.
Найти информацию о шаблонах мониторинга в моем блоге вы сможете в следующих статьях:
- Мониторинг MySQL в ZABBIX — тюнинг СУБД всегда был важной задачей и без отслеживания ключевых показателей вы вряд ли добьетесь в этом деле успеха;
- Мониторинг Apache в ZABBIX — нельзя забывать про отслеживание показателей одного из самых популярных веб-сервисов;
- Мониторинг дисков ZABBIX — дефолтные шаблоны не предоставляют возможности для широкого мониторинга дисков unix-систем, эта статья призвана устранить этот недочет;
- Шаблоны Windows в ZABBIX — мониторинг Windows — это отдельная тематика, а потому я посветил ей целую статью и вероятнее всего на этом дело не кончится.
Тем не менее «затачивание» шаблонов под свои нужды представляет из себя далеко не самую простую задачу и сделать это можно не за один раз и не за короткий временной промежуток. Поскольку большинство системных администраторов вообще не используют системы мониторинга, следовательно каких-то больших сообществ и «клубов по интересам» касательно этих систем в интернете очень мало, либо нет вообще. Все это делает малодоступным свободное перенимание опыта со стороны новичков от их «видавших многое» коллег. И это особо актуально по отношению лучших практик мониторинга критически важных элементов серверов, сетевых устройств. Все это делает достаточно ценным ваши собственные шаблоны мониторинга, которые вы создавали, расширяли и совершенствовали на протяжении многих лет практики системного администрирования. Если кто-то пока не понимает о чем идет речь, то поясню: если единственная цель мониторинга сервера — понять включен он или выключен, то тут все просто и задача упирается во всего лишь один триггер, отвечающий за уведомление в случае отсутствия от сервера признаков жизни; однако если вы ставите целью понимание насколько аппаратное обеспечение сервера отвечает требованиям производительности со стороны ПО и когда может потребоваться сделать апгрейд, либо вашей задачей является тюнинг СУБД и выявление узких мест в работе системы, а может быть предмет вашего мониторинга — сложная система, состоящая из массы связанных друг с другом узлов с множеством служб (например, кластер), то в этих случаях вам придется самостоятельно «допиливать» шаблоны мониторинга под себя и никто с вами ничем не поделится и по-простому проскочить не получится.
Вот и у меня за годы использования ZABBIX накопились некоторые знания и навыки в администрировании этой системы и цель статьи этими знаниями поделиться. По мере изменений я буду выкладывать свои шаблоны ZABBIX и при необходимости их можно будет скачать. Пока основным и наиболее сложным моментом является анализ счетчиков производительности Windows, ведь их надо анализировать в комплексе и эту задачу я решаю следующим образом: по возможности в каждом ключе данных пишу комментарии как этот счетчик можно использовать и с какими другими показателями его надо анализировать. Что-то из этого — личный опыт, а что-то найдено в сети и источники я тоже буду стараться выкладывать.
Источник
Мониторинг доступности службы linux с помощью Zabbix
Ранее я рассматривал различные конфигурации для мониторинга параметров и программ в windows и linux. Сейчас я хочу рассказать, как мониторить с помощью Zabbix произвольный сервис (службу), который работает либо локально на сервере, либо на внешнем tcp порту. Это может быть что угодно — ssh, ldap, smtp, ftp, http, pop, nntp, imap, tcp, https, telnet или любой другой сервис.
Введение
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
То же самое на Debian 10, если предпочитаете его:
В заббикс существуют различные способы получать данные для мониторинга. Наиболее распространенные источники информации:
- Zabbix агент. Устанавливается на наблюдаемую машину и отправляет данные на сервер мониторинга.
- SNMP агент. Чаще всего присутствует на устройстве, либо может быть установлен на сервер.
- Простые проверки — simple check. Выполняются непосредственно на сервере zabbix с помощью встроенных инструментов, не требуют дополнительных действий со стороны хоста.
- Внешние проверки — external checks. Как и простые проверки выполняются на сервере мониторинга, но не встроенными средствами, а внешними скриптами.
Есть и другие способы получения данных. Не буду их все перечислять, ознакомиться с ними можно в соответствующем разделе официальной документации. В нашем случае мы воспользуемся первыми двумя способами для мониторинга служб и сервисов в linux.
Тут можно пойти разными путями. Меня интересует мониторинг различных линукс служб, работающих как локально (samsdaemon, postgrey) в пределах конкретного сервера, так и для публичного доступа по сети, в частности squid, smtp, imap, http. Первое, что пришло в голову, это использовать итем с ключом service_state[]. Но как оказалось, этот тип данных снимает значения только с системных служб windows. Я не сразу это понял и некоторое время повозился в консоли, не понимая, почему при тестировании значения получаю сообщение, что данный item не поддерживается:
Дальше придумал через UserParameter запускать какой-нибудь скрипт, который будет проверять запущен ли сервис в системе или нет. Например с помощью ps ax | grep squid. В принципе, рабочий вариант, но мне казалось, что такую простую задачу можно решить проще и быстрее, без создания на каждом хосте скрипта и изменения файла конфигурации. И я не ошибся. Есть 2 различных способа мониторинга служб (сервисов) в linux с помощью zabbix. Рассмотрим первый из них.
Описание работы простых проверок (simple check)
Стал искать материал на эту тему и прочитал про simple check (простые проверки) в zabbix. Оказалось, это то, что нужно. Их можно использовать для безагентских проверок удаленных сервисов. При этом требуется минимум настроек и только на сервере. Можно создать шаблон и распространить на любое количество хостов.
Принцип работы простых проверок следующий. Вы создаете item, в нем указываете тип simple check, в качестве ключа выбираете net.tcp.service[сервис, , ], указываете соответствующие параметры в скобках и все. Сервер сам начинает опрашивать указанный сервис и возвращать в зависимости от его доступности 0 или 1. Устанавливать агент на хост не нужно. Мониторить можно любую сетевую службу, к которой есть доступ по tcp.
| 0 | сервис недоступен |
| 1 | сервис работает |
Всего в простых проверках доступны 5 ключей. Подробнее о них читайте в документации. В данном случае меня будет интересовать только ключ net.tcp.service. В нем предопределены алгоритмы проверок следующих служб: ssh, ntp, ldap, smtp, ftp, http, pop, nntp, imap, https, telnet. Детали реализации проверки каждой службы описаны тут. Если вы мониторите службу, которая не входит в указанный выше список, то происходит просто проверка возможности подключения, без отправки и получения каких-то данных.
Мониторинг доступности сервиса по сети
В качестве примера настроим мониторинг доступности прокси сервера squid. Он запущен на linux сервере и этот хост уже добавлен на сервер мониторинга. Данные поступают с помощью агента, но мы не будет его использовать. Просто создадим одиночный item для проверки доступности squid и trigger для отправки уведомления, если сервис не работает. В данном примере я рассмотрю настройку на примере конкретного хоста. Если у вас несколько серверов с squid, которые вы хотите мониторить, то все элементы лучше создать не отдельно на каждом хосте, а сразу сделать template и назначить его нужным хостам.
Итак, идем в Configuration -> Hosts и выбираем там хост, на котором установлен squid. Переходим в раздел Items и нажимаем Create item.
Заполняем необходимые параметры элемента.
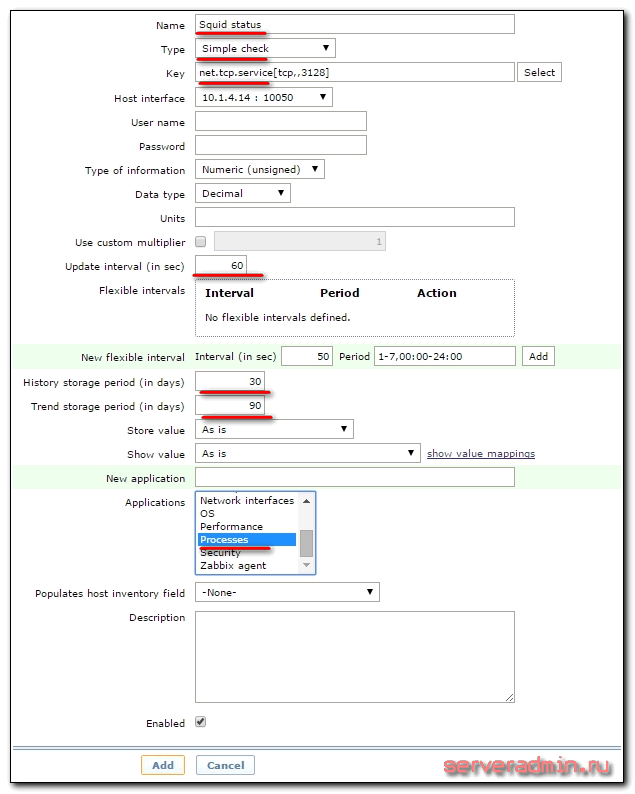
Обязательно заполнить первые 3, остальные на ваше усмотрение. Я считаю, что проверять каждые 30 секунд и хранить 90 дней информацию излишне, поэтому изменяю эти параметры в сторону увеличения.
| Squid status | Имя итема. |
| Simple check | Тип итема. |
| net.tcp.service[tcp,,3128] | Проверять tcp порт 3128 на указанном хосте. Если вы проверяете статус службы, расположенной не на том же хосте, к которому прикрепляете item, то после первой запятой можно указать необходимый адрес. |
Сразу создадим триггер, который в случае возврата в последних двух проверках значения итемом 0, будет отправлять уведомление о том, что служба недоступна. Для этого идем в раздел triggers и жмем Create trigger. Заполняем параметры элемента.
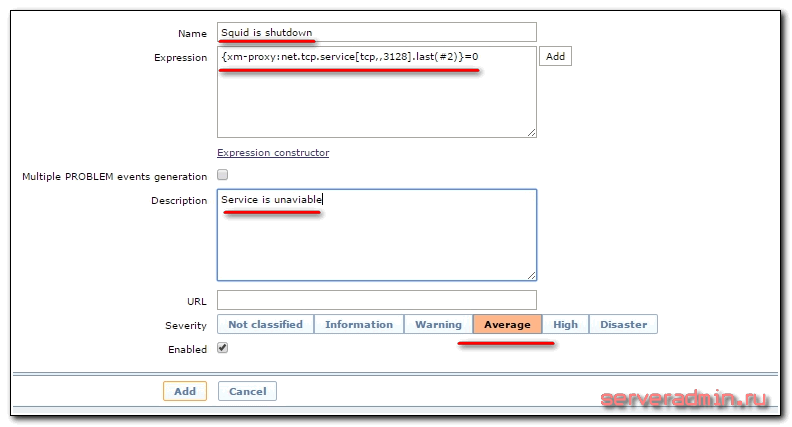
Выражение
Ждем пару минут и идем в Latest data проверять поступаемые значения.
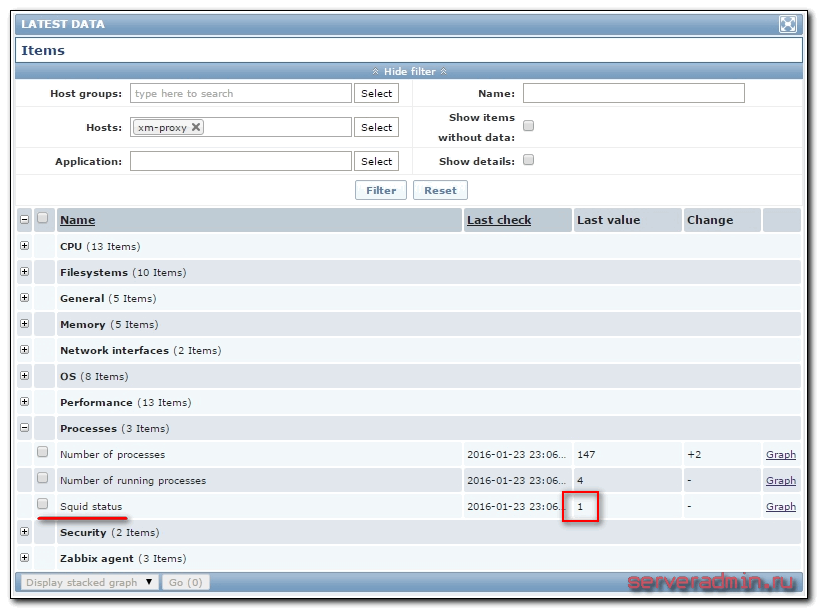
Чтобы проверить работу триггера, достаточно зайти на сервер и остановить squid. Если вы все сделали правильно, то после второй проверки, которая определит, что squid не отвечает по заданному адресу, вы получите уведомление на почту об этом. Если у вас не настроены или не работают уведомления на почту в zabbix, то читайте мою статью на эту тему.
Мониторинг локальной службы в linux
С мониторингом удаленного tcp сервиса разобрались, а что делать, если служба работает локально и к ней невозможно подключиться из вне. Тут уже не обойтись без установки zabbix агента. Если он установлен на хосте, то можно воспользоваться итемом с ключом proc.num. Этот ключ возвращает в качестве значения количество запущенных процессов. И если таких процессов больше одного, можно считать, что служба запущена.
Рассмотрим на примере мониторинга службы postgrey, реализующей greylist для борьбы со спамом. Она работает локально на почтовом сервере linux и является критическим сервисом, так как без него почтовый сервер postfix не будет принимать почту, выдавая временную ошибку почтовой системы. Проверим работу ключа proc.num:
Все в порядке, zabbix агент возвращает значение 1 при запущенном сервисе. Идем на сервер мониторинга, выбираем хост или шаблон и создаем новый item.
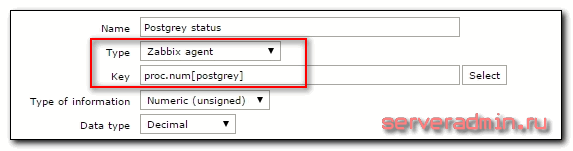
Показываю только основные параметры, остальные устанавливайте на свой вкус. Я лишь рекомендую не делать слишком частые проверки. В большинстве случаев в этом нет необходимости, а нагрузка на сервер постоянно растет при добавлении новых итемов.
Создаем триггер с оповещением о недоступности сервиса. При последних двух значениях равных 0 срабатываем.
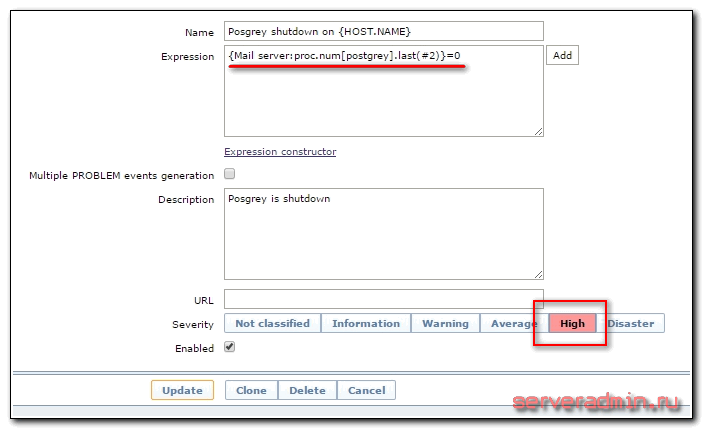
Я настраиваю триггер в шаблоне, поэтому сразу для удобства в названии триггера указываю маску для имени, чтобы было понятно в оповещении, на каком хосте сработал триггер. Как обычно, проверить поступаемые значения можно в Latest data.
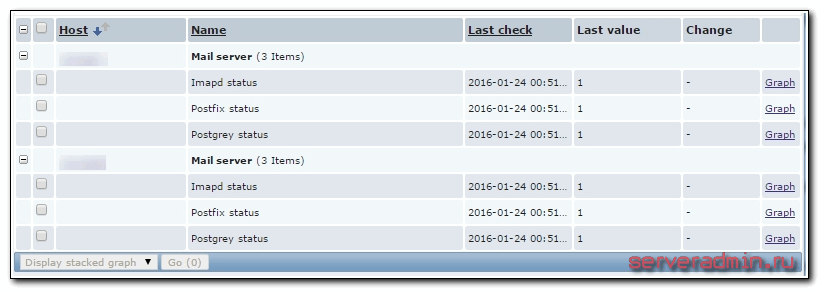
Вот и все. Мы настроили мониторинг локальных служб linux в заббиксе.
Заключение
В своем материале я рассмотрел два различных способа, с помощью которых можно мониторить любой удаленный сервис по протоколу tcp, либо локальную службу на сервере linux. Конкретно в моих примерах можно было воспользоваться вторым способом в обоих случаях. Я этого не сделал, потому что первым способом я не просто проверяю, что служба запущена, я еще и обращаюсь к ней по сети и проверяю ее корректную работу для удаленного пользователя.
Разница тут получается вот в чем. Допустим, сервер squid у вас запущен и работает на сервере. Проверка работы локальной службы показывает, что сервис работает и возвращает значение 1. Но к примеру, вы настраивали firewall и где-то ошиблись. Сервис стал недоступен по сети, пользователи не могут им пользоваться. При этом мониторинг будет показывать, что все в порядке, служба запущена, хотя реально она не может обслужить запросы пользователей. В таком случай только удаленная проверка покажет, что с доступностью сервиса проблемы и надо что-то делать.
Из этого можно сделать вывод, что система мониторинга zabbix предоставляет огромные возможности по мониторингу. Какой тип наблюдения и сбора данных подойдет в конкретном случае нужно решать на месте, исходя из сути сервиса, за которым вы наблюдаете.
Источник



