- Активный и пассивный zabbix агент
- Отличие активного и пассивного агента
- Какой агент лучше использовать?
- Создание шаблона для активного агента
- Zabbix template os linux by zabbix agent
- Мониторинг доступности службы linux с помощью Zabbix
- Введение
- Описание работы простых проверок (simple check)
- Мониторинг доступности сервиса по сети
- Мониторинг локальной службы в linux
- Заключение
Активный и пассивный zabbix агент
У только начинающих администраторов zabbix часто возникает вопрос. В чем отличие между активным и пассивным агентом? И какой агент лучше использовать. В данной статье постараемся ответить на эти вопросы.
Отличие активного и пассивного агента
При использовании пассивного агента, zabbix сервер отправляет запросы на zabbix агент, в соответствии с настройками элементов данных (например загрузку cpu, памяти и т.д). А в ответ получает значения этих данных.
При активном агенте. Агент сначала запрашивает у zabbix сервера список элементов данных, частота этих запросов указана в параметре RefreshActiveChecks в настройках zabbix агента, обычно это не чаще одного раза в час, если у вас изменения в настройка узлов сети происходят редко, то можно указать обновление раз в сутки что бы меньше нагружать сервер. После получения элементов данных zabbix агент отправляет данные на сервер в соответствием с настройками этих данных.
Как следует из описанного выше. Основное отличие заключается в том, что при пассивном агенте данные запрашиваются сервером, а при активном данные отправляются самими агентами.
Какой агент лучше использовать?
Какой агент использовать это дело вкуса. По моему мнению если у вас небольшая сеть и в которую редко добавляются новые узлы, то можно использовать пассивный агент.
Если же у вас большая сеть и на сервере десятки или сотни тысяч активных элементов данных. А также если в сети постоянно появляются новые узлы. То в этом случае лучше, а также если узлы находятся за НАТом то необходимо использовать активный zabbix агенты.
преимущества пассивного агента
- Не работает если узел находится за NAT
- В отличие от активного агента больше нагрузка на сервер
Преимущества активного агента
- Меньшая нагрузка на сервер
- Возможность работы за NAT
- Авторегистрация узлов
- Необходимо создавать шаблоны, в стандартной установке все шаблоны для пассивной проверке.
Создание шаблона для активного агента
Создать шаблон для активного zabbix агента из уже существующего на самом деле очень просто. Рассмотрим на примере стандартного шаблона «Template OS Linux». Для этого открываем его на редактирование и смотрим какие еще шаблоны к нему присоединены, кликнув по вкладке «Присоединенные шаблоны»
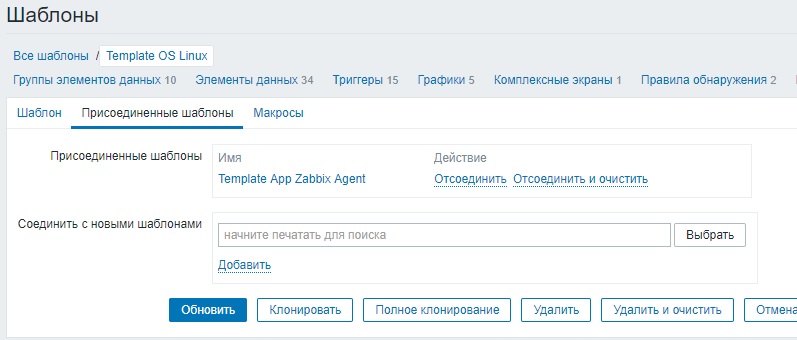
Прямо здесь кликаем по имени «Template App Zabbix Agent» и в открывшемся шаблоне нажимаем кнопку «Полное клонирование». Переименовываем новый шаблон например в «Template App Zabbix Agent_activ». И жмем добавить. Затем открываем созданный шаблон на редактирование, переходим на вкладку «элементы данных» и выделяем все элементы данных.
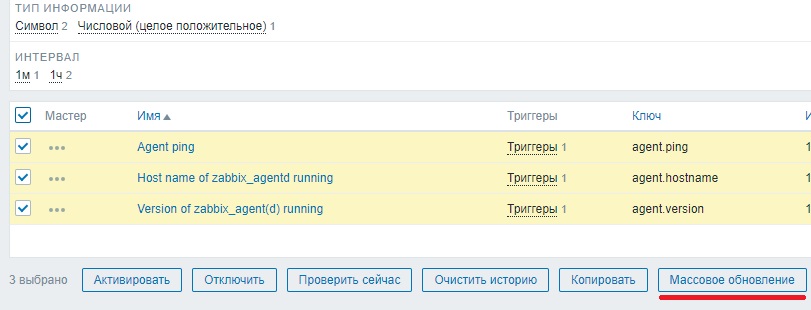
После чего жмем «Массовое обновление». Выбираем тип «Zabbix агент (активный)»

И нажимаем «обновить»
Снова открываем шаблон «Template OS Linux» и здесь нажимаем кнопку «Полное клонирование». И создаем новый шаблон «Template OS Linux_activ». Открываем шаблон «Template OS Linux_activ» на редактирование и переходим на вкладку «Присоединенные шаблоны». Здесь отсоединяем шаблон «Template App Zabbix Agent» и присоединяем «Template App Zabbix Agent_activ».
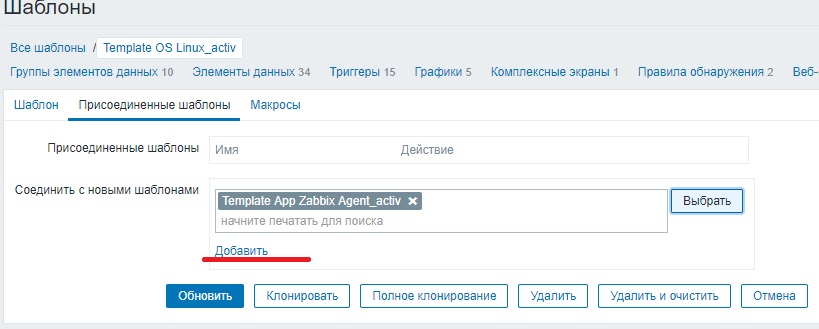
Затем переходим в элементы данных и также с помощью кнопки «Массовое обновление» меняем тип на «Zabbix агент (активный)». Еще нам нужно изменить тип в правилах обнаружения. Для этого переходим на вкладку «Правила обнаружения» и нажимаем в каждом правиле на ссылку «Прототипы элементов данных». К сожалению здесь массовое обновление не работает. Поэтому проходимся по каждому элементу вручную и меняем тип. Теперь у нас есть новый шаблон «Template OS Linux_activ», который работает с активным zabbix агентами. И уже его мы можем навешивать на хосты.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Источник
Zabbix template os linux by zabbix agent
Monitor ZFS on Linux on Zabbix
This template is a modified version of the original work done by pbergdolt and posted on the zabbix forum a while ago here: https://www.zabbix.com/forum/zabbix-cookbook/35336-zabbix-zfs-discovery-monitoring?t=43347 . Also the original home of this variant was on https://share.zabbix.com/zfs-on-linux .
I have maintained and modified this template over the years and the different versions of ZoL on a large number of servers so I’m pretty confident that it works 😉
Thanks to external contributors, this template was extended and is now more complete than ever. However, if you find a metric that you need and is missing, don’t hesitate to open a ticket or even better, to create a PR!
Tested Zabbix server version include 4.0, 4.4, 5.0 and 5.2 . The template shipped here is in 4.0 format to allow import to all those versions.
This template will give you screens and graphs for memory usage, zpool usage and performance, dataset usage, etc. It includes triggers for low disk space (customizable via Zabbix own macros), disks errors, etc.
Example of graphs:
- Arc memory usage and hit rate:

- Complete breakdown of META and DATA usage:
- Dataset usage, with available space, and breakdown of used space with directly used space, space used by snapshots and space used by children:
- Zpool IO throughput:




Supported OS and ZoL version
Any Linux variant should work, tested version by myself include:
- Debian 8, 9, 10
- Ubuntu 16.04, 18.04 and 20.04
- CentOS 6 and 7
About the ZoL version, this template is intended to be used by ZoL version 0.7.0 or superior but still works on the 0.6.x branch.
Installation on Zabbix server
To use this template, follow those steps:
Create the Value mapping «ZFS zpool scrub status»
- Administration
- General
- Value mapping
Then create a new value map named ZFS zpool scrub status with the following mappings:
| Value | Mapped to |
|---|---|
| 0 | Scrub in progress |
| 1 | No scrub in progress |

Import the template
Import the template that is in the «template» directory of this repository or download it directly with this link:
Installation on the server you want to monitor
The server needs to have some very basic tools to run the user parameters:
Usually, they are already installed and you don’t have to install them.
Add the userparameters file on the servers you want to monitor
There are 2 different userparameters files in the «userparameters» directory of this repository.
One uses sudo to run and thus you must give zabbix the correct rights and the other doesn’t use sudo.
On recent ZFS on Linux versions (eg version 0.7.0+), you don’t need sudo to run zpool list or zfs list so just install the file and you are done.
For older ZFS on Linux versions (eg version 0.6.x), you will need to add some sudo rights with the file . On some distribution, ZoL already includes a file with all the necessary rights at /etc/sudoers.d/zfs but its content is commented, just remove the comments and any user will be able to list zfs datasets and pools. For convenience, here is the content of the file commented out:
If you don’t know where your «userparameters» directory is, this is usually the /etc/zabbix/zabbix_agentd.d folder. If in doubt, just look at your zabbix_agentd.conf file for the line begining by Include= , it will show where it is.
Restart zabbix agent
Once you have added the template, restart zabbix-agent so that it will load the new userparameters.
Customization of alert level by server
This template includes macros to define when the «low disk spaces» type triggers will fire.
By default, you will find them on the macro page of this template: 
If you change them here, they will apply to every hosts linked to this template, which may not be such a good idea. Prefer to change the macros on specific servers if needed.
You can see how the macros are used by looking at the discovery rules, then «Trigger prototypes»: 
Important note about Zabbix active items
This template uses Zabbix items of type Zabbix agent (active) (= active items). By default, most template uses Zabbix agent items (= passive items).
If you want, you can convert all the items to Zabbix agent and everything will work, but you should really uses active items because those are way more scalable. The official documentation doesn’t really make this point clear (https://www.zabbix.com/documentation/4.0/manual/appendix/items/activepassive) but active items are optimized: the agent asks the server for the list of items that the server wants, then send them by batch periodically.
On the other hand, for passive items, the zabbix server must establish a connection for each items and ask for them, then wait for the anwser: this results in more CPU, memory and network consumption used by both the server and the agent.
To make an active item work, you must ensure that you have a ServerActive=your_zabbix_server_fqdn_or_ip line in your agent config file (usually /etc/zabbix/zabbix_agentd.conf ).
You also need to configure the «Host Name» on the zabbix UI to be the same as the server output of the hostname command (you can always adjust the «Visible name» in the Zabbix UI to anything you want if needed) because the zabbix agent sends this information to the zabbix server. It basically tells the server «Hello, I am $(hostname), which items do you need from me?» so if there is a mismatch here, the server will most likely answer «I don’t know you!» 😉
Beyond a certain point, depending on your hardware, you will have to use active items.
Источник
Мониторинг доступности службы linux с помощью Zabbix
Ранее я рассматривал различные конфигурации для мониторинга параметров и программ в windows и linux. Сейчас я хочу рассказать, как мониторить с помощью Zabbix произвольный сервис (службу), который работает либо локально на сервере, либо на внешнем tcp порту. Это может быть что угодно — ssh, ldap, smtp, ftp, http, pop, nntp, imap, tcp, https, telnet или любой другой сервис.
Введение
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
То же самое на Debian 10, если предпочитаете его:
В заббикс существуют различные способы получать данные для мониторинга. Наиболее распространенные источники информации:
- Zabbix агент. Устанавливается на наблюдаемую машину и отправляет данные на сервер мониторинга.
- SNMP агент. Чаще всего присутствует на устройстве, либо может быть установлен на сервер.
- Простые проверки — simple check. Выполняются непосредственно на сервере zabbix с помощью встроенных инструментов, не требуют дополнительных действий со стороны хоста.
- Внешние проверки — external checks. Как и простые проверки выполняются на сервере мониторинга, но не встроенными средствами, а внешними скриптами.
Есть и другие способы получения данных. Не буду их все перечислять, ознакомиться с ними можно в соответствующем разделе официальной документации. В нашем случае мы воспользуемся первыми двумя способами для мониторинга служб и сервисов в linux.
Тут можно пойти разными путями. Меня интересует мониторинг различных линукс служб, работающих как локально (samsdaemon, postgrey) в пределах конкретного сервера, так и для публичного доступа по сети, в частности squid, smtp, imap, http. Первое, что пришло в голову, это использовать итем с ключом service_state[]. Но как оказалось, этот тип данных снимает значения только с системных служб windows. Я не сразу это понял и некоторое время повозился в консоли, не понимая, почему при тестировании значения получаю сообщение, что данный item не поддерживается:
Дальше придумал через UserParameter запускать какой-нибудь скрипт, который будет проверять запущен ли сервис в системе или нет. Например с помощью ps ax | grep squid. В принципе, рабочий вариант, но мне казалось, что такую простую задачу можно решить проще и быстрее, без создания на каждом хосте скрипта и изменения файла конфигурации. И я не ошибся. Есть 2 различных способа мониторинга служб (сервисов) в linux с помощью zabbix. Рассмотрим первый из них.
Описание работы простых проверок (simple check)
Стал искать материал на эту тему и прочитал про simple check (простые проверки) в zabbix. Оказалось, это то, что нужно. Их можно использовать для безагентских проверок удаленных сервисов. При этом требуется минимум настроек и только на сервере. Можно создать шаблон и распространить на любое количество хостов.
Принцип работы простых проверок следующий. Вы создаете item, в нем указываете тип simple check, в качестве ключа выбираете net.tcp.service[сервис, , ], указываете соответствующие параметры в скобках и все. Сервер сам начинает опрашивать указанный сервис и возвращать в зависимости от его доступности 0 или 1. Устанавливать агент на хост не нужно. Мониторить можно любую сетевую службу, к которой есть доступ по tcp.
| 0 | сервис недоступен |
| 1 | сервис работает |
Всего в простых проверках доступны 5 ключей. Подробнее о них читайте в документации. В данном случае меня будет интересовать только ключ net.tcp.service. В нем предопределены алгоритмы проверок следующих служб: ssh, ntp, ldap, smtp, ftp, http, pop, nntp, imap, https, telnet. Детали реализации проверки каждой службы описаны тут. Если вы мониторите службу, которая не входит в указанный выше список, то происходит просто проверка возможности подключения, без отправки и получения каких-то данных.
Мониторинг доступности сервиса по сети
В качестве примера настроим мониторинг доступности прокси сервера squid. Он запущен на linux сервере и этот хост уже добавлен на сервер мониторинга. Данные поступают с помощью агента, но мы не будет его использовать. Просто создадим одиночный item для проверки доступности squid и trigger для отправки уведомления, если сервис не работает. В данном примере я рассмотрю настройку на примере конкретного хоста. Если у вас несколько серверов с squid, которые вы хотите мониторить, то все элементы лучше создать не отдельно на каждом хосте, а сразу сделать template и назначить его нужным хостам.
Итак, идем в Configuration -> Hosts и выбираем там хост, на котором установлен squid. Переходим в раздел Items и нажимаем Create item.
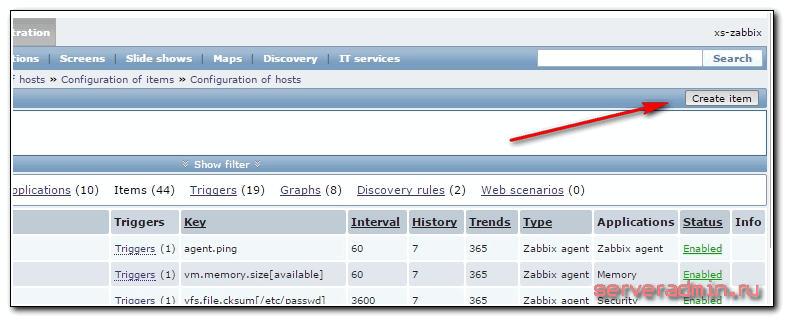
Заполняем необходимые параметры элемента.
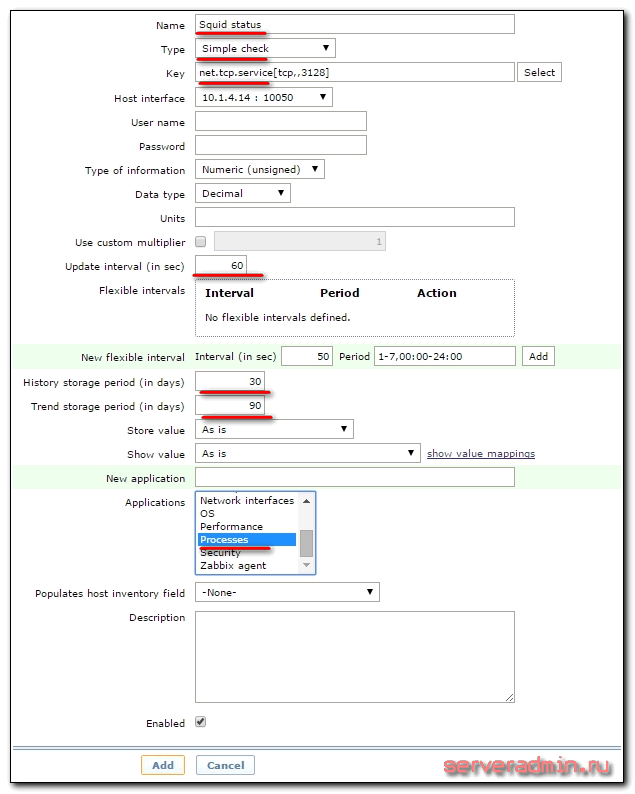
Обязательно заполнить первые 3, остальные на ваше усмотрение. Я считаю, что проверять каждые 30 секунд и хранить 90 дней информацию излишне, поэтому изменяю эти параметры в сторону увеличения.
| Squid status | Имя итема. |
| Simple check | Тип итема. |
| net.tcp.service[tcp,,3128] | Проверять tcp порт 3128 на указанном хосте. Если вы проверяете статус службы, расположенной не на том же хосте, к которому прикрепляете item, то после первой запятой можно указать необходимый адрес. |
Сразу создадим триггер, который в случае возврата в последних двух проверках значения итемом 0, будет отправлять уведомление о том, что служба недоступна. Для этого идем в раздел triggers и жмем Create trigger. Заполняем параметры элемента.
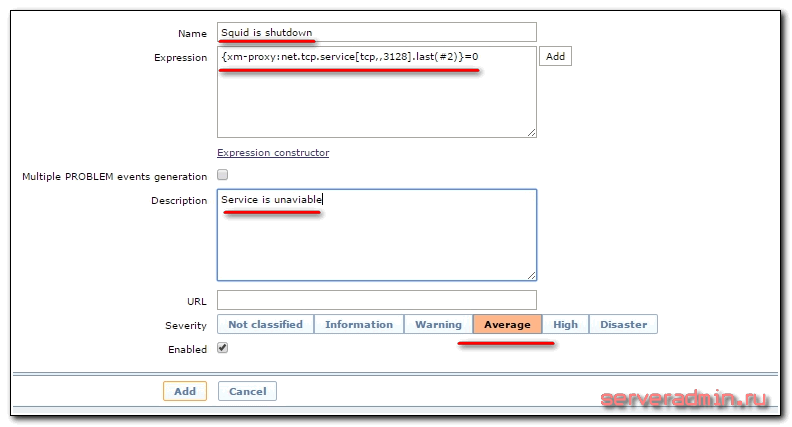
Выражение
Ждем пару минут и идем в Latest data проверять поступаемые значения.
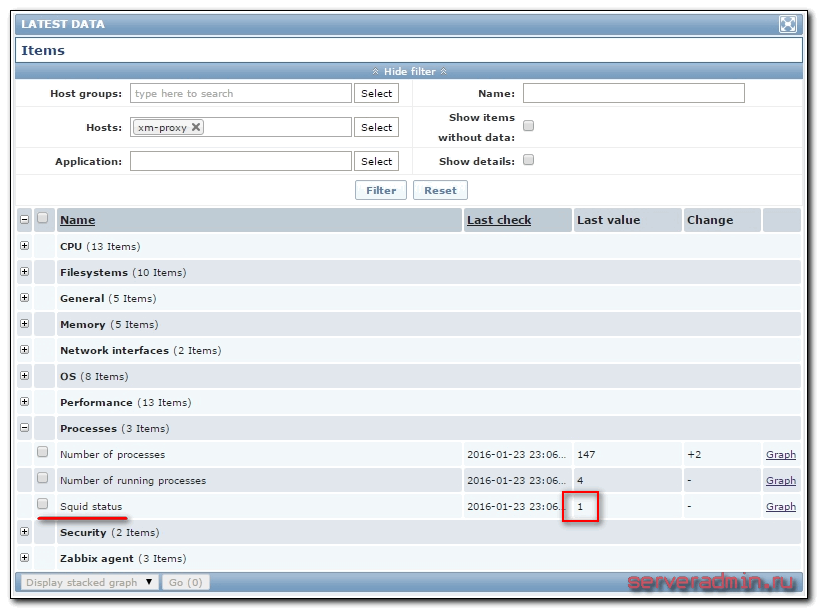
Чтобы проверить работу триггера, достаточно зайти на сервер и остановить squid. Если вы все сделали правильно, то после второй проверки, которая определит, что squid не отвечает по заданному адресу, вы получите уведомление на почту об этом. Если у вас не настроены или не работают уведомления на почту в zabbix, то читайте мою статью на эту тему.
Мониторинг локальной службы в linux
С мониторингом удаленного tcp сервиса разобрались, а что делать, если служба работает локально и к ней невозможно подключиться из вне. Тут уже не обойтись без установки zabbix агента. Если он установлен на хосте, то можно воспользоваться итемом с ключом proc.num. Этот ключ возвращает в качестве значения количество запущенных процессов. И если таких процессов больше одного, можно считать, что служба запущена.
Рассмотрим на примере мониторинга службы postgrey, реализующей greylist для борьбы со спамом. Она работает локально на почтовом сервере linux и является критическим сервисом, так как без него почтовый сервер postfix не будет принимать почту, выдавая временную ошибку почтовой системы. Проверим работу ключа proc.num:
Все в порядке, zabbix агент возвращает значение 1 при запущенном сервисе. Идем на сервер мониторинга, выбираем хост или шаблон и создаем новый item.
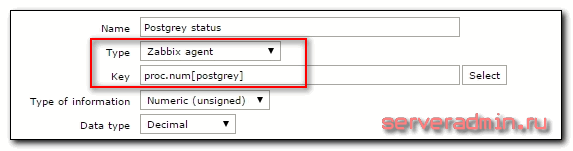
Показываю только основные параметры, остальные устанавливайте на свой вкус. Я лишь рекомендую не делать слишком частые проверки. В большинстве случаев в этом нет необходимости, а нагрузка на сервер постоянно растет при добавлении новых итемов.
Создаем триггер с оповещением о недоступности сервиса. При последних двух значениях равных 0 срабатываем.
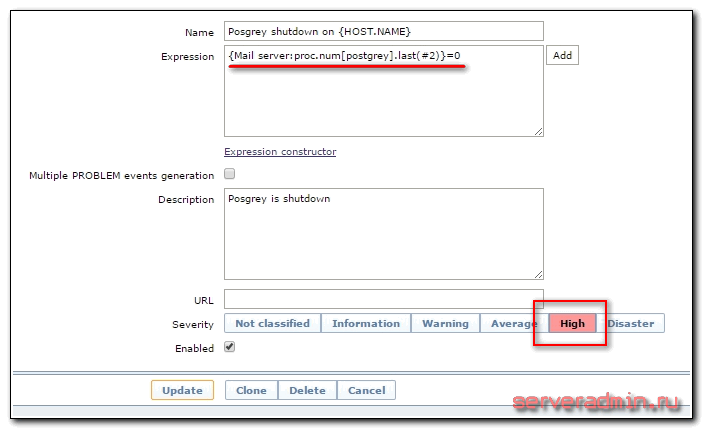
Я настраиваю триггер в шаблоне, поэтому сразу для удобства в названии триггера указываю маску для имени, чтобы было понятно в оповещении, на каком хосте сработал триггер. Как обычно, проверить поступаемые значения можно в Latest data.
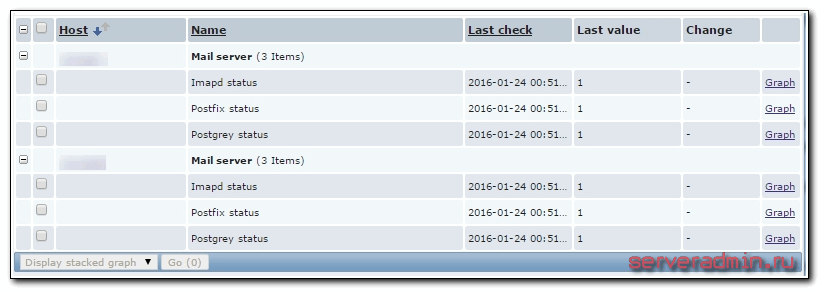
Вот и все. Мы настроили мониторинг локальных служб linux в заббиксе.
Заключение
В своем материале я рассмотрел два различных способа, с помощью которых можно мониторить любой удаленный сервис по протоколу tcp, либо локальную службу на сервере linux. Конкретно в моих примерах можно было воспользоваться вторым способом в обоих случаях. Я этого не сделал, потому что первым способом я не просто проверяю, что служба запущена, я еще и обращаюсь к ней по сети и проверяю ее корректную работу для удаленного пользователя.
Разница тут получается вот в чем. Допустим, сервер squid у вас запущен и работает на сервере. Проверка работы локальной службы показывает, что сервис работает и возвращает значение 1. Но к примеру, вы настраивали firewall и где-то ошиблись. Сервис стал недоступен по сети, пользователи не могут им пользоваться. При этом мониторинг будет показывать, что все в порядке, служба запущена, хотя реально она не может обслужить запросы пользователей. В таком случай только удаленная проверка покажет, что с доступностью сервиса проблемы и надо что-то делать.
Из этого можно сделать вывод, что система мониторинга zabbix предоставляет огромные возможности по мониторингу. Какой тип наблюдения и сбора данных подойдет в конкретном случае нужно решать на месте, исходя из сути сервиса, за которым вы наблюдаете.
Источник



