- Мониторинг лог файла в Zabbix
- Введение
- Настройка мониторинга логов
- Создание триггера на событие из лога
- Заключение
- Блог белорусского сисадмина
- полезные записки
- Мониторинг логов в Zabbix и возврат триггера в OK
- Zabbix Documentation 4.0
- Sidebar
- Table of Contents
- 6 Log file monitoring
- Overview
- Configuration
- Important notes
- Extracting matching part of regular expression
- Using maxdelay parameter
- Actions if communication fails between agent and server
Мониторинг лог файла в Zabbix

Zabbix умет анализировать любой лог файл, сохранять его в свою базу, рассылать алерты по каким-то событиям. Я решил использовать эту возможность для анализа лог файла утилиты acpupsd для отправки оповещений об отключении электричества. Решается данная задача стандартным функционалом заббикса, описанного в документации.
Введение
Ранее я рассказывал об использовании утилиты управления упсами марки apc — apcupsd. Я показал, как установить apcupsd на hyper-v и xenserver для корректного завершения работы при отключении электричества. Рекомендую ознакомиться, если вас интересует этот вопрос. Его не всегда получается быстро и удобно решить. На помощь приходит apcupsd.
Указанные конфигурации у меня успешно работают, проверено годами. Я решил настроить отправку оповещений на почту через zabbix при пропадании электричества. Да и просто хочется хранить информацию об инцидентах в одном месте. Почтовые сообщения не всегда будут доставлены, нужно следить, чтобы на резервное питание были подключены все устройства, которые обеспечивают связь с интернетом. Частенько бывает, что при выключении электричества у провайдера так же выключается оборудование и связи нет. Либо ваш свитч, к которому подключен сервер, выключится и сообщение не будет доставлено.
Заранее позаботьтесь об этих вещах. Пишу об этом, потому что сам недавно на одном объекте все запитал от упсов, но забыл про свитч. В итоге об отключении электричества я узнал уже после того, как его вернули назад и сервера автоматически поднялись. Если у вас еще не настроен сервер мониторинга, рекомендую мою подробную статью с видео об установке и настройке zabbix на centos 9 или установка zabbix 3.4 на debian 9.
Настройка мониторинга логов
Для того, чтобы мониторить лог файл, на сервере должен быть установлен zabbix agent, а сам сервер добавлен в панель мониторинга. Я буду следить за логом программы apcupsd, который располагается по пути /var/log/apcupsd.events. Идем в веб интерфейс заббикса и добавляем новый итем к интересующему нас хосту. Если у вас таких будет несколько, то создавайте сразу шаблон. В моем случае у меня один сервер, поэтому я буду добавлять новый элемент сразу на него.
Создаем новый итем со следующими параметрами:
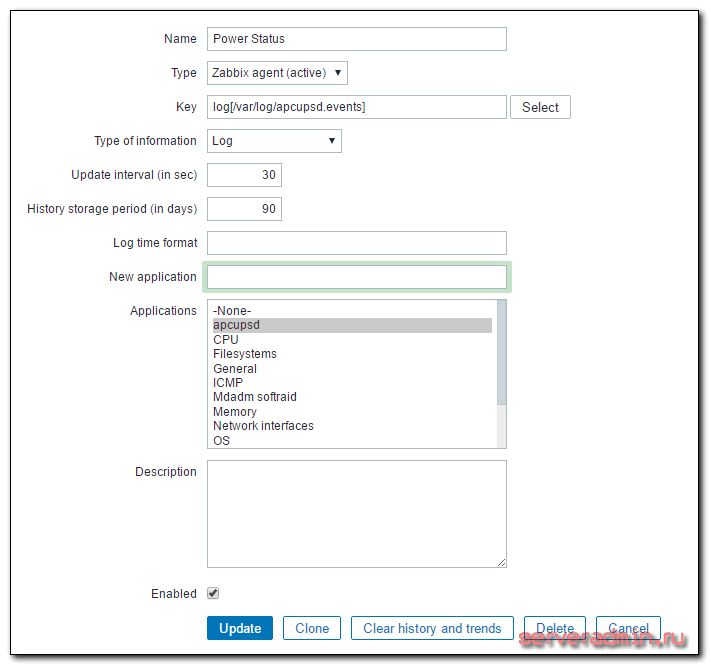
| Name | Имя нового итема. Можете указать любое название. |
| Type | Тип элемента. Обязательно выбираем Zabbix agent (active). По-умолчанию будет другой тип стоять. |
| Key | Ключ данных, log — тип, в квадратных скобках путь до лог файла. |
| Type of information | Указываем тип информации, поступающей в итем. |
Остальные параметры оставляете на свое усмотрение. Рекомендую время обновления итема ставить поменьше, чтобы оперативно получить информацию об инциденте. У меня стоит 30 секунд.
После того, как вы сохраните новый итем, через несколько минут начнут поступать данные. Проверять их как обычно в Latest data. В данной конфигурации будут сохраняться все строки из файла. В моем случае это не страшно, так как записей будет очень мало. Они создаются только по событиям в электро сети, а они случаются редко, поэтому я не стал делать фильтр по строкам или словам.
Но это только пол дела. Мы стали собирать логи, теперь нам нужно настроить отправку оповещения при пропадании электричества.
Создание триггера на событие из лога
Мы будем слать оповещение не только в момент отключения электричества, но и тогда, когда оно снова появится. Так что в триггере будут два условия:
- Условие активации события.
- И условие его прекращения.
Открываем вкладку с триггерами хоста и добавляем туда новый триггер со следующими параметрами:
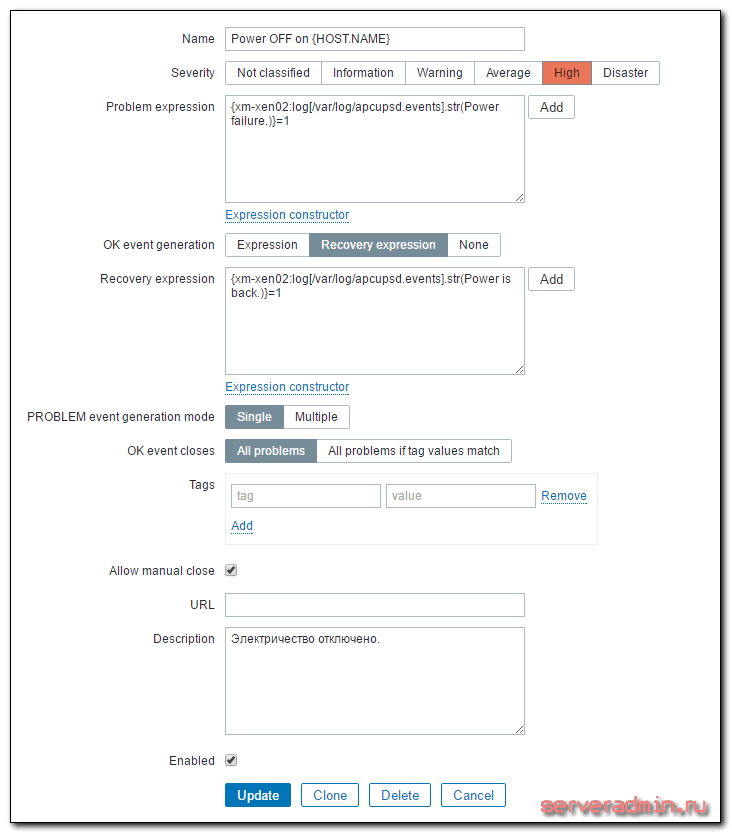
| Name | Имя триггера. Может быть любым. |
| Problem expression | |
| Recovery expression |
Рассказываю подробнее, что тут написано. xm-xen02 — имя сервера. Power failure. — строка в лог файле, которая появляется при отключении электричества. Когда оно возвращается, появляется запись Power is back. В общем виде лог выглядит примерно следующим образом:
Становится понятно, почему я взял именно эти строки. На этом все. После сохранения триггера он начнет работать и следить за итемом, который собирает строки из лога. Как только появятся строки, попадающие под условие, вы получите оповещение.
Заключение
Отладить работу оповещения об отключении электричества достаточно трудно, так как дергать по этому поводу шнур с питанием не хочется. Я пошел другим путем. Во время отладки использовал общий лог файл /var/log/messages и останавливал службу chronyd. Во время остановки, она пишет информацию об этом в лог файл, а при запуске так же сообщает, что запустилась. Я просто настроил итем и триггер на нужные строки и убедился, что все работает как надо. После этого уже сделал по аналогии итемы и триггеры для apcupsd. Рекомендую поступить похожим образом и потестировать функционал.
Блог белорусского сисадмина
полезные записки
Мониторинг логов в Zabbix и возврат триггера в OK
Zabbix может многое. Главное — суметь это настроить 🙂 Одна из полезных возможностей — мониторинг лог-файлов на наличие определенных записей. Если вы хотите держать руку на пульсе событий при мониторинге серверов, то без мониторинга логов никак не обойтись: почти все серьезные ошибки пишутся в логи и во многих случаях гораздо эффективнее мониторить один-два лога, чем настраивать отслеживания статуса 50 сервисов, работоспособность которых не всегда легко проверить.
Собственно, в самой настройке мониторинга логов нет ничего сложного: добавляем соответствующий Item, пишем регулярное выражение для триггера и начинаем получать уведомления! Например, мы хотим отслеживать все ошибки из System лога на серверах под управлением OS Windows. Для этого, создаем следующий Item:
Параметры следующие: System — лог, который отслеживаем; второй параметр — регулярное выражение, которое ищем (пропущен, берем все записи); третий — «Error» — важность, согласно классификации ОС; четвертый — любой источник; пятый — @eventlog — макрос, который исключает события с идентификаторами ^(1111|36888|36887|36874)$; шестой — максимальное кол-во строк, которое мы отправляем серверу в секунду (неограниченное); последний параметр — skip — заставляет сервер читать только новые записи лога, а не перечитывать его весь.
В качестве триггера мы используем следующую строку:
Т.е. мы берем любую строку, которая попала в Item и высылаем уведомление.
После такой настройки мы получим первую ошибку из лога и триггер будет висеть в состоянии PROBLEM до скончания веков, т.к. нет события, которое его переводит в состояние OK. Для решения этой проблемы необходимо добавить к триггеру еще одно условие: наличие новых данных в течение промежутка времени, меньшего, чем время опроса Item. Т.е. если мы проверяем лог на ошибки раз в минуту, то нам надо поставить любой промежуток времени, меньший, чем минута. Итоговый триггер будет выглядеть как-то так:
Выглядеть это будет как «нашли что-то в Item» И «за последние 10 секунд были получены новые данные». При следующей проверке триггер перейдет в состояние OK, т.к. за последние 10 секунд новых данных получено не было. Других способов возврата триггера для лога в нормальное состояние в заббиксе версии 2 не предусмотрено.
Zabbix Documentation 4.0
Sidebar
Table of Contents
6 Log file monitoring
Overview
Zabbix can be used for centralized monitoring and analysis of log files with/without log rotation support.
Notifications can be used to warn users when a log file contains certain strings or string patterns.
To monitor a log file you must have:
Configuration
Verify agent parameters
Item configuration
Configure a log monitoring item.

All mandatory input fields are marked with a red asterisk.
Specifically for log monitoring items you enter:
| Type | Select Zabbix agent (active) here. |
| Key | Use one of the following item keys: log[] or logrt[]: These two item keys allow to monitor logs and filter log entries by the content regexp, if present. For example: log[/var/log/syslog,error] . Make sure that the file has read permissions for the ‘zabbix’ user otherwise the item status will be set to ‘unsupported’. log.count[] or logrt.count[]: These two item keys allow to return the number of matching lines only. See supported Zabbix agent item key section for details on using these item keys and their parameters. |
| Type of information | Select: For log[] or logrt[] items — Log ; For log.count[] or logrt.count[] items — Numeric (unsigned) . If optionally using the output parameter, you may select the appropriate type of information other than Log . Note that choosing a non-Log type of information will lead to the loss of local timestamp. |
| Update interval (in sec) | The parameter defines how often Zabbix agent will check for any changes in the log file. Setting it to 1 second will make sure that you get new records as soon as possible. |
| Log time format | In this field you may optionally specify the pattern for parsing the log line timestamp. If left blank the timestamp will not be parsed. Supported placeholders: * y: Year (0001-9999) * M: Month (01-12) * d: Day (01-31) * h: Hour (00-23) * m: Minute (00-59) * s: Second (00-59) For example, consider the following line from the Zabbix agent log file: “ 23480:20100328:154718.045 Zabbix agent started. Zabbix 1.8.2 (revision 11211).” It begins with six character positions for PID, followed by date, time, and the rest of the line. Log time format for this line would be “pppppp:yyyyMMdd:hhmmss”. Note that “p” and “:” chars are just placeholders and can be anything but “yMdhms”. |
Important notes
Extracting matching part of regular expression
Sometimes we may want to extract only the interesting value from a target file instead of returning the whole line when a regular expression match is found.
Since Zabbix 2.2.0, log items have the ability to extract desired values from matched lines. This is accomplished by the additional output parameter in log and logrt items.
Using the ‘output’ parameter allows to indicate the subgroup of the match that we may be interested in.
should allow returning the entry count as found in the content of:
The reason why Zabbix will return only the number is because ‘output’ here is defined by \1 referring to the first and only subgroup of interest: (5+)
And, with the ability to extract and return a number, the value can be used to define triggers.
Using maxdelay parameter
The ‘maxdelay’ parameter in log items allows ignoring some older lines from log files in order to get the most recent lines analyzed within the ‘maxdelay’ seconds.
By default items for log monitoring follow all new lines appearing in the log files. However, there are applications which in some situations start writing an enormous number of messages in their log files. For example, if a database or a DNS server is unavailable, such applications flood log files with thousands of nearly identical error messages until normal operation is restored. By default, all those messages will be dutifully analyzed and matching lines sent to server as configured in log and logrt items.
Built-in protection against overload consists of a configurable ‘maxlines’ parameter (protects server from too many incoming matching log lines) and a 4*’maxlines’ limit (protects host CPU and I/O from overloading by agent in one check). Still, there are 2 problems with the built-in protection. First, a large number of potentially not-so-informative messages are reported to server and consume space in the database. Second, due to the limited number of lines analyzed per second the agent may lag behind the newest log records for hours. Quite likely, you might prefer to be sooner informed about the current situation in the log files instead of crawling through old records for hours.
The solution to both problems is using the ‘maxdelay’ parameter. If ‘maxdelay’ > 0 is specified, during each check the number of processed bytes, the number of remaining bytes and processing time is measured. From these numbers the agent calculates an estimated delay — how many seconds it would take to analyze all remaining records in a log file.
If the delay does not exceed ‘maxdelay’ then the agent proceeds with analyzing the log file as usual.
If the delay is greater than ‘maxdelay’ then the agent ignores a chunk of a log file by “jumping” over it to a new estimated position so that the remaining lines could be analyzed within ‘maxdelay’ seconds.
Note that agent does not even read ignored lines into buffer, but calculates an approximate position to jump to in a file.
The fact of skipping log file lines is logged in the agent log file like this:
The “to byte” number is approximate because after the “jump” the agent adjusts the position in the file to the beginning of a log line which may be further in the file or earlier.
Depending on how the speed of growing compares with the speed of analyzing the log file you may see no “jumps”, rare or often “jumps”, large or small “jumps”, or even a small “jump” in every check. Fluctuations in the system load and network latency also affect the calculation of delay and hence, “jumping” ahead to keep up with the “maxdelay” parameter.
Setting ‘maxdelay’ logrt with the copytruncate option assumes that different log files have different records (at least their timestamps are different), therefore MD5 sums of initial blocks (up to the first 512 bytes) will be different. Two files with the same MD5 sums of initial blocks means that one of them is the original, another — a copy.
logrt with the copytruncate option makes effort to correctly process log file copies without reporting duplicates. However, things like producing multiple log file copies with the same timestamp, log file rotation more often than logrt[] item update interval, frequent restarting of agent are not recommended. The agent tries to handle all these situations reasonably well, but good results cannot be guaranteed in all circumstances.
Actions if communication fails between agent and server
Each matching line from log[] and logrt[] item and a result of each log.count[] and logrt.count[] item check requires a free slot in the designated 50% area in the agent send buffer. The buffer elements are regularly sent to server (or proxy) and the buffer slots are free again.
While there are free slots in the designated log area in the agent send buffer and communication fails between agent and server (or proxy) the log monitoring results are accumulated in the send buffer. This helps to mitigate short communication failures.
During longer communication failures all log slots get occupied and the following actions are taken:



