Практикум по теме «Кодирование текста»
Продолжение. См. № 7/2009
Выполняя лабораторную работу (см. № 7/2009), учащиеся получили кодовую таблицу для Windows —
CP-1251. Следующие этапы практикума — познакомиться с существованием множества кодовых таблиц, самостоятельно получить другие кодовые таблицы с символами кириллицы и, наконец, написать программу перекодировки текста (все программирование в этом варианте курса информатики — на Лого).
Учебные материалы и задания для учащихся
Наверное, вам приходилось сталкиваться с ситуацией, когда текст на экране компьютера выглядит, как нарочно зашифрованный. Например, так:

Происходят такие неприятности в результате существования не одной-единственной, а нескольких таблиц кодировки. Почему так получилось?
Американский стандартный код для обмена информацией (ASCII) первоначально был разработан для передачи текстов по телеграфу, причем в то время он был 7-битовым, то есть для кодирования символов английского языка, служебных и управляющих символов использовались только 128 семибитовых комбинаций. При этом первые 32 кода служили для кодирования управляющих сигналов (начало текста, конец строки, перевод каретки, звонок, конец текста и т.д.). При разработке первых компьютеров фирмы IBM этот код был использован для представления символов в компьютере. На кодирование каждого символа был отведен байт, а поскольку в исходном коде ASCII было всего 128 символов, для их кодирования хватило половины восьмибайтовых кодов.
Оставшуюся вторую половину кодов стали использовать для представления символов псевдографики, математических знаков и некоторых символов из языков, отличных от английского (греческих букв, немецких умляутов, французских диакритических знаков и т.п.).
Когда стали приспосабливать компьютеры для других стран и языков, фирма IBM ввела в употребление несколько кодовых таблиц, ориентированных на конкретные страны. Так, для скандинавских стран была предложена таблица CP-865 (Nordic), для арабских стран — таблица CP-864 (Arabic), для Израиля — таблица CP-862 (Israel) и так далее. В этих таблицах часть кодов из второй половины кодовой таблицы использовалась для представления символов национальных алфавитов.
С русским языком ситуация развивалась особым образом. Появилось несколько разных таблиц с символами кириллицы: KOI8-R, CP-866, CP-1251 (именно ее вы получили в лабораторной работе), ISO-8551-5.
Одна из причин в том, что таблица кодировки связана с операционной системой (операционная система управляет компьютером и осуществляет операции ввода-вывода информации).

Программы для работы с текстами — текстовые редакторы, браузеры — “умеют” перекодировать текст в соответствии с указанной таблицей кодировки.
Кодировка на web-странице
Грамотно сделанный HTML-документ обязательно должен содержать специальный тег с указанием использованной в нем таблицы кодировки. Если вы попали в Интернете на “нечитаемую” страницу, то скорее всего в HTML-коде нет тега с кодировкой. Но браузер поможет вам прочесть страницу. Для этого в браузерах есть специальное меню.
Например, в браузере Internet Explorer зайдите в пункт меню View/Encoding (Вид/Кодировка). Вы увидите меню, в котором можно выбрать таблицу кодировки. Попробуйте изменить кодировку этой страницы.
Но даже наличие множества различных национальных таблиц кодировки не может решить всех проблем с кодированием текстов. Для таких языков, как китайский или японский, вообще 256 символов недостаточно. Кроме того, всегда существует проблема вывода или сохранения в одном файле одновременно текстов на разных языках (например, при цитировании).
Поэтому была разработана универсальная кодовая таблица UNICODE, содержащая символы, применяемые в языках всех народов мира, а также различные служебные и вспомогательные символы (знаки препинания, математические и технические символы, стрелки, диакритические знаки и т.д.).
Очевидно, что одного байта недостаточно для кодирования такого большого количества символов в одной таблице. Поэтому в UNICODE используются 16-битовые (двухбайтовые) коды. К настоящему времени задействовано около 49 000 кодов, время от времени в таблицу добавляются новые знаки. Например, в сентябре 1998 г. в таблицу был внесен символ валюты EURO.
Сейчас в компьютерном мире сосуществуют однобайтовые и двухбайтовые таблицы кодировки, но постепенно будет полностью осуществлен переход на UNICODE.
1. Подберите с помощью браузера кодировку для следующих страниц.
Примечание для читателя “Информатики”: учитель создает для этого задания две-три web-страницы с текстом в разных кодировках и тэг с указанием кодовой страницы удаляет.
Запишите, какие таблицы кодировки использованы в этих документах.
2. Вы обратили внимание на то, что при любых изменениях кодировки английские слова прекрасно читаются? Объясните, почему так получается.
3. Рассчитайте, сколько всего различных текстовых символов можно закодировать двоичным кодом при двухбайтовой системе кодирования.
Получение разных кодовых таблиц
Выполняя лабораторную работу, вы получили шестнадцатеричную кодовую таблицу CP-1251. Ведь именно с этой таблицей работает русифицированная операционная среда Windows.
Для получения таблицы вы написали программу на Лого. А таблицу поместили и оформили в документе MS Word. Если эту таблицу поместить на web-страницу (то есть в документ HTML), то можно с помощью браузера получить и другие таблицы кодировки.
1. Получение web-страницы с таблицей кодировки
Помните, какие тэги нужны для создания таблицы на web-странице? Вот пример HTML-кода для таблицы, состоящей из четырех ячеек (двух столбцов и двух строк):

(начало первой строки)
содержимое ячейки 1
содержимое ячейки 2
(конец первой строки)
(начало второй строки)
содержимое ячейки 3
содержимое ячейки 4
(конец второй строки)
Откройте вашу программу получения таблицы кодировки. Внесите в программу изменения: в текстовое окно должны попасть теперь еще и тэги для строк и ячеек. Не забудьте добавить тэги структуры HTML-документа. В результате в текстовом окне должен появиться HTML-код web-страницы, содержащей кодовую таблицу.
Сохраните текст в файле. Не забудьте про расширение имени файла!
Просмотрите получившуюся страницу в браузере. Если с таблицей все в порядке, можно начинать эксперименты.
Попробуйте менять кодировку страницы — вид таблицы должен меняться. Таким образом можно получить все кодовые таблицы, имеющиеся в браузере (только однобайтовые, конечно!).
Сформулируйте, что именно меняется в таблице при переходе от одной кодировки к другой.
2. Добавление десятичного номера
Для вашей следующей работы (создания программы-перекодировщика) нужно, чтобы в таблице были еще и десятичные номера символов. Например, так, как на этой картинке:

Усовершенствуйте вашу программу так, чтобы на web-странице появились и номера. Сделайте скриншоты кодовых таблиц с кириллицей: Windows-1251, KOI8-R, CP-866, MacCyrillic. Сохраните скриншоты в отдельных файлах в формате GIF.
Время на выполнение этой части практикума — 3 урока.
repeat 14 [строчка :n pr [] make «n :n + 16]
repeat 16 [insert char :n insert char 32
Результат — 14 строк по 16 символов в каждой.
Программа, создающая HTML-код (без десятичных номеров):
Практическая работа №4 Представление и сжатие текстов

Цель урока: практическое закрепление знаний о представлении в компьютере текстовых данных.
Задачи урока:
• закрепить у учащихся знания о представлении в компьютере текстовых данных;
• познакомить с методом сжатия Хаффмана и деревом Хаффмана;
• научить работать с кодировочными таблицами;
• научить решать задачи на шифровку и дешифровку текстов;
• развивать мышление (умение сравнивать, анализировать, обобщать);
• учить ставить и разрешать проблемы, делать выводы;
• воспитывать информационную культуру учащихся, внимательность, аккуратность, дисциплинированность, уважительное отношение к мнению других.
Просмотр содержимого документа
«Практическая работа №4 Представление и сжатие текстов»
Работа 1.4. Представление текстов. Сжатие текстов
Цель работы: практическое закрепление знаний о представлении в компьютере текстовых данных.
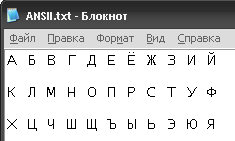
Определить, какие символы кодировочной таблицы ASCII (DOS) соответствуют всем прописным буквам русского алфавита в кодировочной таблице ANSI (Windows). Для выполнения задания создать текст с русским алфавитом в Блокноте, а затем открыть его в режиме просмотра (клавиша F3) в любом файловом менеджере (Windows Commander, Far, Total Commander, Norton Commander) и преобразовать в другую кодировку. После выполнения задания заполнить таблицу.
1. Используем готовый текстовый файл ANSI.txt..
2. Далее открывает Unreal Commander (Free Commander) и ищем в нём наш файл.
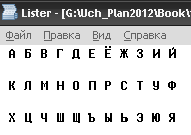
4. Затем нажимаем на режим просмотра F3. Там отобразится содержимое файла в изначальной кодировке (ANSI) и там же есть возможность, просмотреть это же содержимое в разных кодировках.
В нашем случае нужно найти значение кодировки ASCII (DOS).
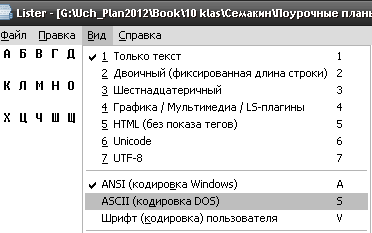
5. Получаем результат:
Ответ: Таких символов нет. Вместо них на экране в режиме просмотра появляются символы псевдографики.
Закодировать текст с помощью кодировочной таблицы ASCII.
Happy Birthday to you!
Записать двоичное и шестиадцатеричное представления кода (для записи шестнадцатеричного кода использовать средство для просмотра файлов любого файлового менеджера).
в 16-ричной СС (используем кодовую таблицу в текстовом файле ASCII.docx)
48 61 70 70 79 20 42 69
72 74 68 64 61 79 20 74
6F 20 79 6F 75 21 21
в двоичной СС (4816=100 10002 где 1000 — код цифру 8, а 100 — код цифры 4)
1001000 1100001 1110000 1110000 1111001 0100000 1000010 1101001
1110010 1110100 1101000 1100100 1100001 1111001 0100000 1110100
1101111 0100000 1111001 1101111 1110101 0100001 0100001
Декодировать текст, записанный в международной кодировочной таблице ASCII (дано десятичное представление).
72 101 108 108 111 44 32 109 121 32 102 114 105 101 110 100 33
Для раскодирования используем таблицу в файле «Коды символов ASCII.mht»
где Dec — десятизначный код
Пользуясь таблицей кодировки ASCII, расшифровать текст, представленный в виде двоичных кодов символов.
01010000 01100101 01110010 01101110 00100000 01010101 01101110 01101001 01110110 01100101 01110010 01110011 01101001 01110100 01111001
Переведем в 16-ричный код отделяя группу двоичных разрядов, справа налево, по 4 бита:
Используя кодовую таблицу из файла Коды символов ASCII.mht по найденному Hex коду (50) определим первый символ латинского текста «P»
50 65 72 6E 20 55 6D 69 76
65 72 73 69 74 79
Пользуясь кодовой страницей Windows-1251 таблицы кодировки ASCII, получить шестнадцатеричный код слова ИНФОРМАТИЗАЦИЯ.
Используем кодовую таблицу в файле «Таблица Windows-1251.mht»
Согласно этой таблицы русская заглавная буква «И» (в колонке Hex)
имеет 16-ричный код — C8
Ответ: C8 CD D4 CE D0 CC C0 D2 C8 C7 C0 D6 C8 DF
Во сколько раз увеличится объем памяти, необходимый для хранения текста, если его преобразовать из кодировки KOI8-R в кодировку Unicode?
Для кодирования одного символа в кодировке KOI-8 используется 1 байт, а в кодировке UNICODE — 2 байта, следовательно, информационный объем страницы текста увеличится в 2 раза
С помощью табличного процессора Excel построить кодировочную таблицу ASCII, в которой символы будут автоматически отображаться на экране в соответствии с их заданным десятичным номером (использовать соответствующую текстовую функцию).
Введите ускоренным методом числа от 33 до 254 (по 25 в каждой строке через столбец:
А, С, E, … , Q)

В ячейку B1 введите формулу =СИМВОЛ(A1) и далее используя ускоренный метод, скопируйте ее в остальные ячейки столбцов: B, D, F,…, R.

Справка:
Алгоритм Хаффмана. Сжатием информации в памяти компьютера называют такое ее преобразование, которое ведет к сокращению объема занимаемой памяти при сохранении закодированного содержания. Рассмотрим один из способов сжатия текстовой информации — алгоритм Хаффмана. С помощью этого алгоритма строится двоичное дерево, которое позволяет однозначно декодировать двоичный код, состоящий из символьных кодов различной длины. Двоичным называется дерево, из каждой вершины которого выходят две ветви. На рисунке приведен пример такого дерева, построенного для алфавита английского языка с учетом частоты встречаемости его букв.
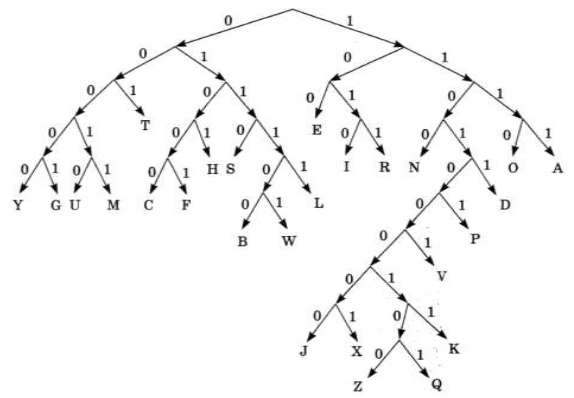
Закодируем с помощью данного дерева слово «hello»: 0101 100 01111 01111 1110
При размещении этого кода в памяти побитно он примет вид: 01011000 11110111 11110
Таким образом, текст, занимающий в кодировке ASCII 5 байтов, в кодировке Хаффмана займет только 3 байта.
Используя метод сжатия Хаффмана, закодируйте следующие слова:
а) administrator 1111 11011 00011 1010 1100 1010 0110 001 1011 1111 001 1110 1011
(11111101 10001110 10110010 10011000 11011111 10011110 1011)
б) revolution 1011 100 1101001 1110 01111 00010 001 1010 1110 1100
(10111001 10100111 10011110 00100011 01011101 100)
в) economy 100 01000 1110 1100 1110 00011 00000 (10001000 11101100 11100001 100000)
г) department 11011 100 110101 1111 1011 001 00011 100 1100 001
(11011100 11010111 11101100 10001110 01100001)
Используя дерево Хаффмана, декодируйте следующие слова:
а) 01110011 11001001 10010110 10010111 100000
(011100 1111 001 001 100 1011 01001 01111 00000) BATTERFLY
б) 00010110 01010110 10011001 01101101 01000100 000
(00010 1100 1010 1101001 100 1011 0110 1010 001 00000) UNIVERSITY



