- Команда Tr в Linux с примерами
- Tr Command in Linux with Examples
- В этом руководстве мы покажем вам, как использовать tr команду, на практических примерах и подробных объяснениях наиболее распространенных вариантов.
- Как использовать tr команду
- Объединение вариантов
- Примеры команд Tr
- Преобразовать нижний регистр в верхний регистр
- Удалить все нечисловые символы
- Поместите каждое слово в новую строку
- Удалить пустые строки
- Печать $PATH каталогов на отдельной строке
- Вывод
- Замена символов строке linux
- Команда tr и ее синтаксис
- 1) Заменить все строчные буквы на заглавные
- 2) Удаление символов с помощью tr
- 3) Удаление ила змена символов НЕ в наборе
- 4) Замена пробелов на табуляцию
- 5) Удаление повторений символов
- 6) Заменить символы из набора на перенос строки
- 7) Генерируем список уникальных слов из файла
- 8) Кодируем символы с помошью ROT
- Вывод
- Найти и заменить текст в файле с помощью команд
- питон
- Основные приёмы обработки строк в bash
- Термины
- Сравнение строковых переменных
- Основные операторы сравнения
- Пример скрипта для сравнения двух строковых переменных
- Создание тестового файла
- Основы работы с grep
- Синтаксис команды
- Основные опции
- Практическое применение grep
- Поиск подстроки в строке
- Вывод нескольких строк
- Чтение строки из файла с использованием регулярных выражений
- Рекурсивный режим поиска
- Точное вхождение
- Поиск нескольких слов
- Количество строк в файле
- Вывод только имени файла
- Использование sed
- Синтаксис
- Распространенные конструкции с sed
- Замена слова
- Редактирование файла
- Удаление строк из файла
- Нумерация строк
- Удаление всех чисел из текста
- Замена символов
- Обработка указанной строки
- Работа с диапазоном строк
Команда Tr в Linux с примерами
Tr Command in Linux with Examples
В этом руководстве мы покажем вам, как использовать tr команду, на практических примерах и подробных объяснениях наиболее распространенных вариантов.
tr утилита командной строки в системах Linux и Unix, которая переводит, удаляет и сжимает символы из стандартного ввода и записывает результат в стандартный вывод.
Команда tr может выполнять такие операции, как удаление повторяющихся символов, преобразование прописных букв в строчные, а также замена и удаление основных символов. Как правило, он используется в сочетании с другими командами через трубопровод.
Как использовать tr команду
Синтаксис tr команды следующий:
tr принимает два набора символов, обычно одинаковой длины, и заменяет символы первого набора соответствующими символами из второго набора.
A SET — это в основном строка символов, включая специальные символы с обратной косой чертой.
В следующем примере tr будут заменены все символы из стандартного ввода (baksdev) путем сопоставления символов из первого набора с совпадающими символами из второго набора.
Каждое вхождение l заменяется на r , i с e и n на d :
Наборы символов также могут быть определены с использованием диапазонов символов. Например, вместо того, чтобы писать:
ты можешь использовать:
При использовании опции -c ( —complement ) tr заменяются все символы, которых нет в SET1.
В приведенном ниже примере все символы, кроме «li», будут заменены последними символами из второго набора:
Как вы могли заметить, вышеприведенный вывод имеет еще один видимый символ, чем ввод. Это связано с тем, что echo команда печатает невидимый символ новой строки, \n который также заменяется на y . Чтобы отобразить строку без новой строки, используйте -n параметр.
Опция -d ( —delete ) указывает tr на удаление символов, указанных в SET1. При удалении символов без сжатия указывайте только один набор.
Приведенная ниже команда удалит l , i и z символы:
Символ L не удаляется, потому что ввод включает в себя заглавные буквы, в L то время как l символы в наборе строчные.
Опция -s ( —squeeze-repeats ) заменяет последовательность повторяющихся вхождений набором символов в последнем SET.
В следующем примере tr удаляются повторяющиеся пробелы:
Когда используется SET2, последовательность символов, указанная в SET1, заменяется на SET2.
Опция -t ( —truncate-set1 ) вынуждает tr обрезать SET1 до длины SET2 перед дальнейшей обработкой.
По умолчанию, если SET1 больше, чем SET2, tr будет повторно использоваться последний символ SET2. Вот пример:
Вывод показывает, что символ e из SET1 соответствует самому последнему символу из SET2, а именно 2 :
Теперь используйте ту же команду с -t опцией:
Вы можете видеть, что последние три символа SET1 удалены. SET1 становится ‘ab’, такой же длины, как SET2, и замена не производится.
Объединение вариантов
Команда tr также позволяет комбинировать ее параметры. Например, следующая команда первого заменяет все символы , кроме i с , 0 а затем сжимает повторяющиеся 0 символы:
Примеры команд Tr
В этом разделе мы рассмотрим несколько примеров общего использования tr команды.
Преобразовать нижний регистр в верхний регистр
Преобразование нижнего регистра в верхний или обратный является одним из типичных вариантов использования tr команды. [:lower:] соответствует всем символам в нижнем регистре и [:upper:] соответствует всем символам в верхнем регистре.
Вместо классов персонажей вы также можете использовать диапазоны:
Чтобы преобразовать верхний регистр в нижний регистр, просто поменяйте местами наборы.
Удалить все нечисловые символы
Следующая команда удаляет все нечисловые символы:
[:digit:] обозначает все цифры, и, используя -c опцию, команда удаляет все не цифры. Вывод будет выглядеть так:
Поместите каждое слово в новую строку
Чтобы поместить каждое слово в новую строку, нам нужно сопоставить все не алфавитно-цифровые символы и заменить их новой строкой:
Удалить пустые строки
Чтобы удалить пустые строки, просто сожмите повторяющиеся символы новой строки:
В команде выше мы используем символ перенаправления передать содержание file.txt в tr команде. Перенаправление > записывает вывод команды в new_file.txt .
Печать $PATH каталогов на отдельной строке
$PATH Переменная окружающей среды является двоеточиями список каталогов, сообщает оболочке , какие каталоги для поиска исполняемых файлов при вводе команды.
Чтобы напечатать каждый каталог в отдельной строке, нам нужно сопоставить двоеточие ( : ) и заменить его новой строкой:
Вывод
tr — команда для перевода или удаления символов
Хотя очень полезно, tr может работать только с одиночными символами. Для более сложного сопоставления с образцом и работы со строками, вы должны использовать sed или awk .
Источник
Замена символов строке linux

Команда tr (translate) используется в Linux в основном для преобразования и удаления символов. Она часто находит применение в скриптах обработки текста. Ее можно использовать для преобразования верхнего регистра в нижний, сжатия повторяющихся символов и удаления символов.
Команда tr требует два набора символов для преобразований, а также может использоваться с другими командами, использующими каналы (пайпы) Unix для расширенных преобразований.
В этой статье мы узнаем, как использовать команду tr в операционных системах Linux и рассмотрим некоторые примеры.
Команда tr и ее синтаксис
Ниже приведен синтаксис команды tr. Требуется, как минимум, два набора символов и опции.
SET1 и SET2 это группы символов. are a group of characters. Необходимо перечислить необходимые символы или указать последовательность.
\NNN -> восмеричные (OCT) символы NNN (1 до 3 цифр)
\\ -> обратный слеш (экранированный)
\n -> новая строка (new line)
\r -> перенос строки (return)
\t -> табуляция (horizontal tab)
[:alnum:] -> все буквы и цифры
[:alpha:] -> все буквы
[:blank:] -> все пробелы
[:cntrl:] -> все управляющие символы (control)
[:digit:] -> все цифры
[:lower:] -> все буквы в нижнем регистре (строчные)
[:upper:] -> все буквы в верхнем регистре (заглавные)
Примеры использования команды tr:
Вот некоторые опции:
-c , -C , —complement -> удалить все символы, кроме тех, что в первом наборе
-d , —delete -> удалить символы из первого набора
-s , —squeeze-repeats -> заменять набор символов, которые повторяются, из указанных в последнем наборе знаков
1) Заменить все строчные буквы на заглавные
Мы можем использовать tr для преобразования нижнего регистра в верхний или наоборот.
Просто используем наборы [:lower:] [:upper:] или «a-z» «A-Z» для замены всех символов.
Вот пример, как преобразовать в Linux с помощью команды tr все строчные буквы в заглавные:
А сейчас сделаем замену из файла input.txt
Как мы видим, в файле ничего не изменилось, осталось все строчными буквами. Чтобы изменения были в файле, на необходимо перевести вывод в новый файл. Например, в output.txt
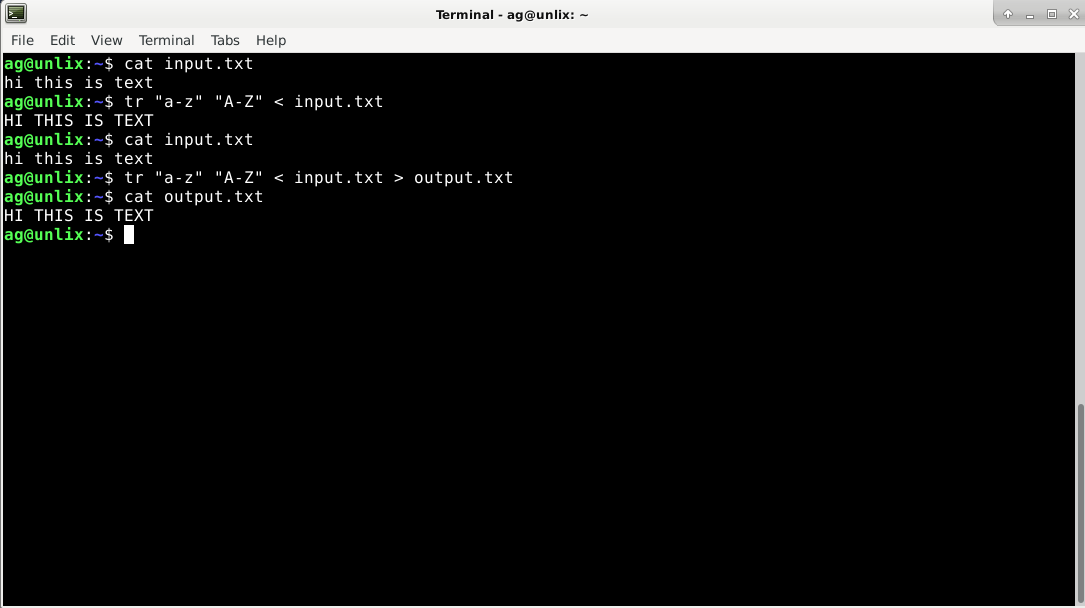
Кстати, в команде sed есть опция y которая делает то же самое (sed ‘y/SET1/SET2’)
2) Удаление символов с помощью tr
Опция -d используется для удаления всех символов, которые указаны в наборе символов.
Следующая команда удалит все символы из этого набора ‘aei’.
Следующая команда удалит все цифры в тексте. Будем использовать набор [:digit:] , чтобы определить все цифры.
А вот пример команд, которыми можно удалить переносы на новые строки
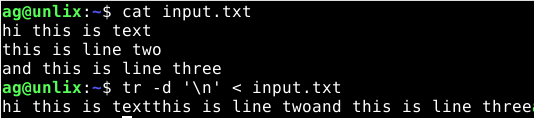
3) Удаление ила змена символов НЕ в наборе
С помощью параметра -c Вы можете сказать tr заменить все символы, которые Вы не указали в наборе. Приведем пример.
А вот пример удаления, просто укажем опцию -d и только один набор (символы которого удалять НЕ надо, а остальные удалить)

4) Замена пробелов на табуляцию
Для указания пробелов используем — [:space:] , а для табуляции — \t.
5) Удаление повторений символов
Это делает параметр -s . Рассмотрим пример удаления повторов знаков.
Или заменим повторения на символ решетки
6) Заменить символы из набора на перенос строки
Сделаем так, чтобы все буквы были заменены на перенос новой строки:
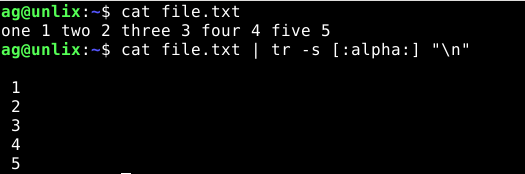
7) Генерируем список уникальных слов из файла
Это иногда очень полезная команда, когда необходимо определить количество повторений и вывести уникальные слова из файла:
8) Кодируем символы с помошью ROT
ROT (Caesar Cipher) — это тип криптографии, в котором кодирование выполняется путем перемещения букв в алфавите к его следующей букве.
Давайте проверим, как использовать tr для шифрования.
В следующем примере каждый символ в первом наборе будет заменен соответствующим символом во втором наборе.
Первый набор [a-z] (это значит abcdefghijklmnopqrstuvwxyz). Второй набор [n-za-m] (который содержит pqrstuvwxyzabcdefghijklmn).
Простая команда для демонстрации вышеуказанной теории:
Полезно при шифровании электронных адресов:
Вывод
tr — это очень мощная команда линукс при использовании пайпов Unix и очень часто используется в скриптах. Дополнительную информацию об этой утилите всегда можно найти в man.
Если у Вас есть какие-либо дополнения, не стесняйтесь пишите в комментариях.
Источник
Найти и заменить текст в файле с помощью команд
Как я могу найти и заменить определенные слова в текстовом файле, используя командную строку?
- sed = Stream EDitor
- -i = на месте (т.е. сохранить обратно в исходный файл)
- s = команда замены
- original = регулярное выражение, описывающее слово для замены (или только само слово)
- new = текст для замены
- g = глобальный (т.е. заменить все, а не только первое вхождение)
file.txt = имя файла
Есть несколько разных способов сделать это. Один использует sed и Regex. SED — это потоковый редактор для фильтрации и преобразования текста. Один пример выглядит следующим образом:
Другой способ , который может иметь больше смысла , чем и > strout является с трубами!
Есть множество способов достичь этого. В зависимости от сложности того, чего можно достичь с помощью замены строки, и в зависимости от инструментов, с которыми пользователь знаком, некоторые методы могут быть предпочтительнее других.
В этом ответе я использую простой input.txt файл, который вы можете использовать для проверки всех примеров, представленных здесь. Содержимое файла:
Bash на самом деле не предназначен для обработки текста, но простые замены могут быть выполнены с помощью расширения параметров , в частности, здесь мы можем использовать простую структуру $
Этот небольшой скрипт не выполняет замену на месте, это означает, что вам придется сохранить новый текст в новый файл и избавиться от старого файла, или mv new.txt old.txt
Примечание: если вам интересно, почему while IFS= read -r ; do . done он используется, то в основном это способ чтения файла строка за строкой. Смотрите это для справки.
AWK, будучи утилитой обработки текста, вполне подходит для такой задачи. Он может делать простые замены и намного более сложные, основанные на регулярных выражениях . Он обеспечивает две функции: sub() и gsub() . Первый из них заменяет только первое вхождение, а второй — заменяет вхождения во всей строке. Например, если у нас есть строка one potato two potato , это будет результат:
AWK может принять входной файл в качестве аргумента, поэтому input.txt было бы легко сделать то же самое с :
В зависимости от версии AWK, которая у вас есть, она может иметь или не иметь редактирование на месте, поэтому обычная практика — сохранять и заменять новый текст. Например что-то вроде этого:
Sed — это редактор строк. Он также использует регулярные выражения, но для простых замен достаточно сделать:
Что хорошо в этом инструменте, так это то, что он имеет редактирование на месте, которое вы можете включить с -i флагом.
Perl — это еще один инструмент, который часто используется для обработки текста, но это язык общего назначения, который используется в сетях, системном администрировании, настольных приложениях и во многих других местах. Он заимствовал много концепций / функций из других языков, таких как C, sed, awk и другие. Простую замену можно сделать так:
Как и у sed, у perl также есть флаг -i.
питон
Этот язык очень универсален и также используется в самых разных приложениях. Он имеет много функций для работы со строками, среди которых есть replace() , так что если у вас есть переменная, как var=»Hello World» , вы могли бы сделать var.replace(«Hello»,»Good Morning»)
Простой способ прочитать файл и заменить строку в нем будет так:
Однако в Python вам также нужно выводить в новый файл, что вы также можете сделать из самого скрипта. Например, вот простой:
Источник
Основные приёмы обработки строк в bash
Работа со строками в bash осуществляется при помощи встроенных в оболочку команд.
Термины
- Консольные окружения — интерфейсы, в которых работа выполняется в текстовом режиме.
- Интерфейс — механизм взаимодействия пользователя с аппаратной частью компьютера.
- Оператор — элемент, задающий законченное действие над каким-либо объектом операционной системы (файлом, папкой, текстовой строкой и т. д.).
- Текстовые массивы данных — совокупность строк, записанных в переменную или файл.
- Переменная — поименованная область памяти, позволяющая осуществлять запись и чтение данных, которые в нее записываются. Она может принимать любые значения: числовые, строковые и т. д.
- Потоковый текстовый редактор — программа, поддерживающая потоковую обработку текстовой информации в консольном режиме.
- Регулярные выражения — формальный язык поиска части кода или фрагмента текста (в том числе строки) для дальнейших манипуляций над найденными объектами.
- Bash-скрипты — файл с набором инструкций для выполнения каких-либо манипуляций над строкой, текстом или другими объектами операционной системы.
Сравнение строковых переменных
Для выполнения операций сопоставления 2 строк (str1 и str2) в ОС на основе UNIX применяются операторы сравнения.
Основные операторы сравнения
- Равенство « = »: оператор возвращает значение «истина» («TRUE»), если количество символов в строке соответствует количеству во второй.
- Сравнение строк на эквивалентность « == »: возвращается «TRUE», если первая строка эквивалентна второй ( дом == дом ).
- Неравенство «str1 != str2»: «TRUE», если одна строковая переменная не равна другой по количеству символов.
- Неэквивалентность «str1 !== str2»: «TRUE», если одна строковая переменная не равна другой по смысловому значению ( дерево !== огонь ).
- Первая строка больше второй «str1 > str2»: «TRUE», когда str1 больше str2 по алфавитному порядку. Например, « дерево > огонь » , поскольку литера «д» находится ближе к алфавитному ряду, чем «о».
- Первая строка меньше второй «str1 str2»: «TRUE», когда str1 меньше str2 по алфавитному порядку. Например, « огонь », поскольку «о» находится дальше к началу алфавитного ряда, чем «д».
- Длина строки равна 0 « -z str2»: при выполнении этого условия возвращается «TRUE».
- Длина строки отлична от нулевого значения « -n str2»: «TRUE», если условие выполняется.
Пример скрипта для сравнения двух строковых переменных
- Чтобы сравнить две строки, нужно написать bash-скрипт с именем test .

- Далее необходимо открыть терминал и запустить test на выполнение командой:
- Предварительно необходимо дать файлу право на исполнение командой:
- После указания пароля скрипт выдаст сообщение на введение первого и второго слова. Затем требуется нажать клавишу «Enter» для получения результата сравнения.


Создание тестового файла
Обработка строк не является единственной особенностью консольных окружений Ubuntu. В них можно обрабатывать текстовые массивы данных.
- Для практического изучения команд, с помощью которых выполняется работа с текстом в интерпретаторе bash, необходимо создать текстовый файл txt .
- После этого нужно наполнить его произвольным текстом, разделив его на строки. Новая строка не должна сливаться с другими элементами.
- Далее нужно перейти в директорию, в которой находится файл, и запустить терминал с помощью сочетания клавиш — Ctrl+Alt+T.
Основы работы с grep
Поиск строки в файле операционной системы Linux Ubuntu осуществляется посредством специальной утилиты — grep . Она позволяет также отфильтровать вывод информации в консоли. Например, вывести все ошибки из log-файла утилиты ps или найти PID определенного процесса в ее отчете.
Команда grep работает с шаблонами и регулярными выражениями. Кроме того, она применяется с другими командами интерпретатора bash.
Синтаксис команды
Для работы с утилитой grep необходимо придерживаться определенного синтаксиса
- grep [options] pattern [file_name1 file_name2 file_nameN] (где «options» — дополнительные параметры для указания настроек поиска и вывода результата; «pattern» — шаблон, представляющий строку поиска или регулярное выражение, по которым будет осуществляться поиск; «file_name1 file_name2 file_nameN» — имя одного или нескольких файлов, в которых производится поиск).
- instruction | grep [options] pattern (где «instruction» — команда интерпретатора bash, «options» — дополнительные параметры для указания настроек поиска и вывода результата, «pattern» — шаблон, представляющий строку поиска или регулярное выражение, по которым будет производиться поиск).
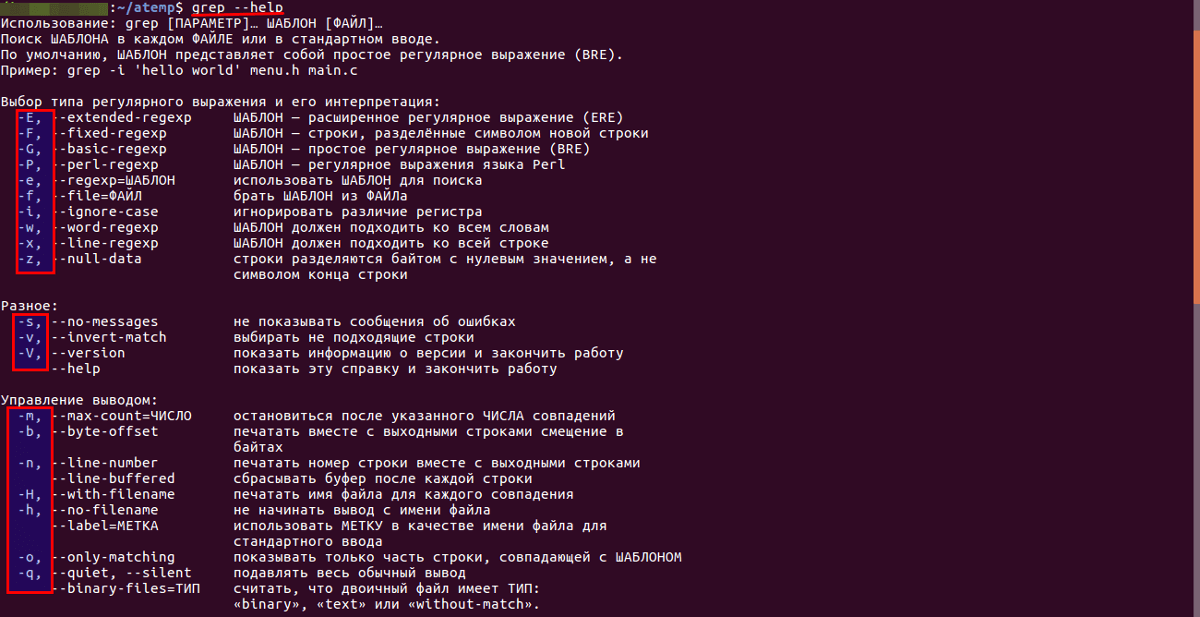
Основные опции
- Отобразить в консоли номер блока перед строкой — -b .
- Число вхождений шаблона строки — -с .
- Не выводить имя файла в результатах поиска — -h .
- Без учета регистра — -i .
- Отобразить только имена файлов с совпадением строки — -l .
- Показать номер строки — -n .
- Игнорировать сообщения об ошибках — -s .
- Инверсия поиска (отображение всех строк, в которых не найден шаблон) — -v .
- Слово, окруженное пробелами, — -w .
- Включить регулярные выражения при поиске — -e .
- Отобразить вхождение и N строк до и после него — -An и -Bn соответственно.
- Показать строки до и после вхождения — -Cn .
Практическое применение grep
Поиск подстроки в строке

В окне терминала выводятся все строки, содержащие подстроку. Найденные совпадения подсвечиваются другим цветом.
- С учетом регистра:
- Без учета регистра:
Вывод нескольких строк
- Строка с вхождением и две после нее:
- Строка с вхождением и три до нее:
- Строка, содержащая вхождение, и одну до и после нее:
Чтение строки из файла с использованием регулярных выражений
Регулярные выражения расширяют возможности поиска и позволяют выполнить разбор строки на отдельные элементы. Они активируются при помощи ключа -e.
- Вывод строки, в начале которой встречается слово «Фамилия».
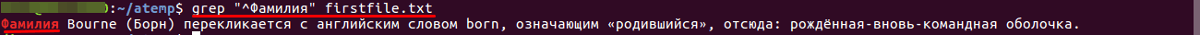 В регулярных выражения для обозначения начала строки используется специальный символ «^».
В регулярных выражения для обозначения начала строки используется специальный символ «^». Чтобы вывести первый символ строки, нужно воспользоваться конструкцией
grep «оболочка$» firstfile.txt Если требуется вывести символ конца строки, то следует применять конструкцию
grep «а.$» firstfile.txt . В этом случае будут выведены все строки, заканчивающиеся на литеру «а».

Если воспользоваться числовыми интервалами, то можно вывести все строки, в которых встречаются числа:
Рекурсивный режим поиска
- Чтобы найти строку или слово в нескольких файлах, расположенных в одной папке, нужно использовать рекурсивный режим поиска:
- Если нет необходимости выводить имена файлов, содержащих искомую строку, то можно воспользоваться ключом-параметром деактивации отображения имен:
Точное вхождение
При поиске союза «и» grep будет выводить все строки, в которых он содержится. Чтобы этого избежать, требуется использовать специальный ключ « w »:
Поиск нескольких слов
Утилита «w» позволяет искать не только одно слово, но и несколько одновременно
Количество строк в файле
При помощи grep можно определить число вхождений строки или подстроки в текстовом файле и вывести ее номер.

- Число вхождений:
- Номера строк с совпадениями:
Инверсия
Если в тексте требуется найти определенные строки, которые не содержат какого-либо слова или подстроки, то рекомендуется использовать инверсионный режим поиска.
Вывод только имени файла
Чтобы не выводить все строки с совпадением, а вывести только имя файла, нужно воспользоваться конструкцией:
Использование sed
Потоковый текстовый редактор « sed » встроен в bash Linux Ubuntu. Он использует построчное чтение, а также позволяет выполнить фильтрацию и преобразование текста.
Синтаксис
Для работы с потоковым текстовым редактором sed используется следующий синтаксис:
sed [options] instructions [file_name] (где «options» — ключи-опции для указания метода обработки текста, «instructions» — команда, совершаемая над найденным фрагментом текста, «file_name» — имя файла, над которым совершаются действия).
Для вывода всех опций потокового текстового редактора нужно воспользоваться командой:
Распространенные конструкции с sed
Замена слова
Например, если требуется заменить строку в файле или слово с «команды» на «инструкции». Для этого нужно воспользоваться следующими конструкциями:
- Для первого вхождения:
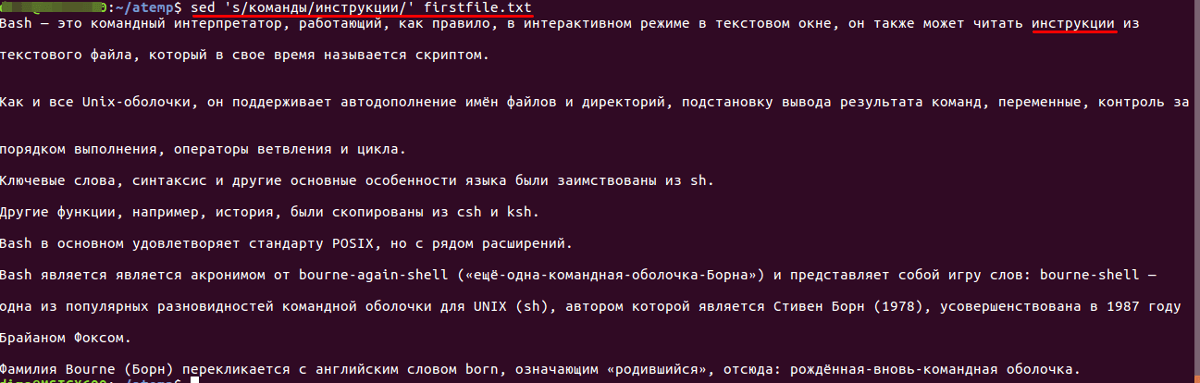
Произвести замену только в строках, которые заканчиваются на«Bash»:
Редактирование файла
Чтобы записать строку в файл, нужно указать параметр замены одной строки на другую, воспользовавшись ключом — -i :
После выполнения команды произойдет замена слова «команды» на «инструкции» с последующим сохранением файла.
Удаление строк из файла
- Удалить первую строку из файла:
- Удалить строку из файла, содержащую слово«окне»:
После выполнения команды будет удалена первая строка, поскольку она содержит указанное слово.
Нумерация строк
Строки в файле будут пронумерованы следующим образом: первая строка — 1, вторая — 2 и т. д.
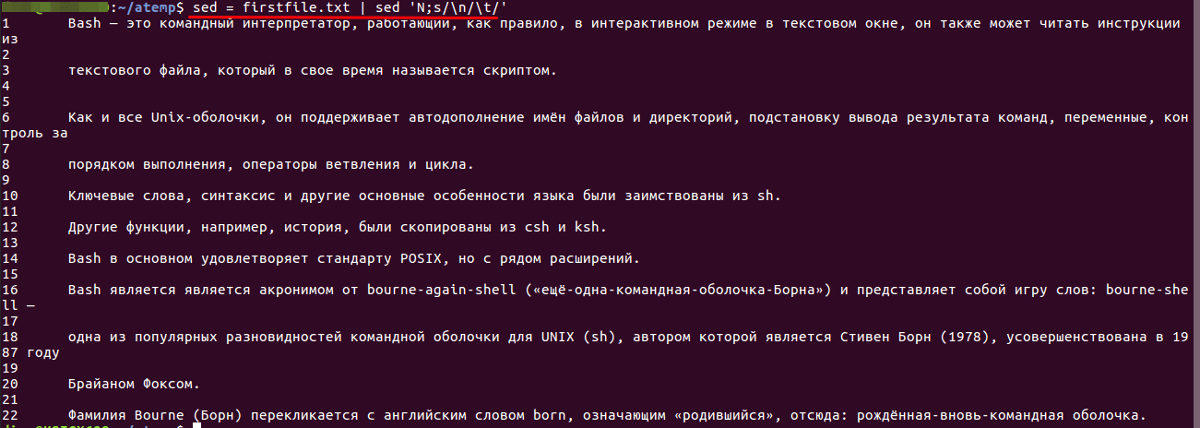
Следует обратить внимание, что нумерация начинается не с «0», как в языках программирования.
Удаление всех чисел из текста
Замена символов
Чтобы заменить набор символов, нужно воспользоваться инструкцией, содержащей команду « y »:
Обработка указанной строки
Утилита производит манипуляции не только с текстом, но и со строкой, указанной в правиле шаблона (3 строка):
Работа с диапазоном строк
Для выполнения замены только в 3 и 4 строках нужно использовать конструкцию:
Вставка содержимого файла после строки
Иногда требуется вставить содержимое одного файла (input_file.txt) после определенной строки другого (firstfile.txt). Для этой цели используется команда:
sed ‘5r input_file.txt’ firstfile.txt (где «5r» — 5 строка, «input_file.txt» — исходный файл и «firstfile.txt» — файл, в который требуется вставить массив текста).
Начни экономить на хостинге сейчас — 14 дней бесплатно!
Источник



