- Как использовать файловую систему ZFS в Linux
- Настройка ZFS
- Добавить диски в ZFS Zpool
- Удалить пул ZFS
- Проверить статус ZFS
- ZFS on Linux — не все так просто
- ZFS on Linux: вести с полей 2017
- Кратко о главных преимуществах ZFS для вашей системы.
- Структура.
- Типы массивов:
- ARC — умное кеширование в ZFS.
- Дополнительные возможности.
- Основные рекомендации (TL;DR):
- Важные моменты:
Как использовать файловую систему ZFS в Linux
Файловая система ZFS невероятно популярна.
В результате многие в предприятии клянутся им в верности и используют его для размещения триллионов байтов данных.
Несмотря на свою популярность, пользователи Linux не смогут наслаждаться этим из коробки.
Вместо этого те, кто хочет проверить это и использовать его в качестве основной файловой системы хранилища, должны будут установить его.
Установка ZFS немного отличается от других файловых систем, и в зависимости от того, что вы используете, может потребоваться небольшое ноу-хау.
Если вы новичок в этой файловой системе, лучше всего идти по маршруту Ubuntu.
Начиная с Ubuntu 16.04, Canonical упрощает работу с ZFS.
Еще лучше, Ubuntu – безусловно самая безопасная реализация ZFS в Linux, с простой настройкой и процессом сборки, который, как известно, очень надежный (в то время как другие дистрибутивы Linux имеют высокий риск нарушения ZFS).
Примечание. Хотя можно использовать ZFS для одного жесткого диска, это не очень хорошая идея, и вы, вероятно, пропустите все функции, которые делают эту файловую систему отличной.
Точкой файловой системы является создание избыточности, путем растяжения данных на нескольких жестких дисках.
Прежде чем продолжить, убедитесь, что у вас более 1 жесткого диска для ZFS.
Настройка ZFS
Файловая система ZFS работает, объединяя множество разных жестких дисков вместе, чтобы создать один большой центр хранения.
Это звучит слишком сложно, и это так. Тем не менее, результат – превосходное хранилище с большим пространством.
Создание новой файловой системы ZFS немного сложнее, чем просто открытие редактора разделов Gparted.
Вместо этого вам нужно будет взаимодействовать с ним на уровне командной строки. В
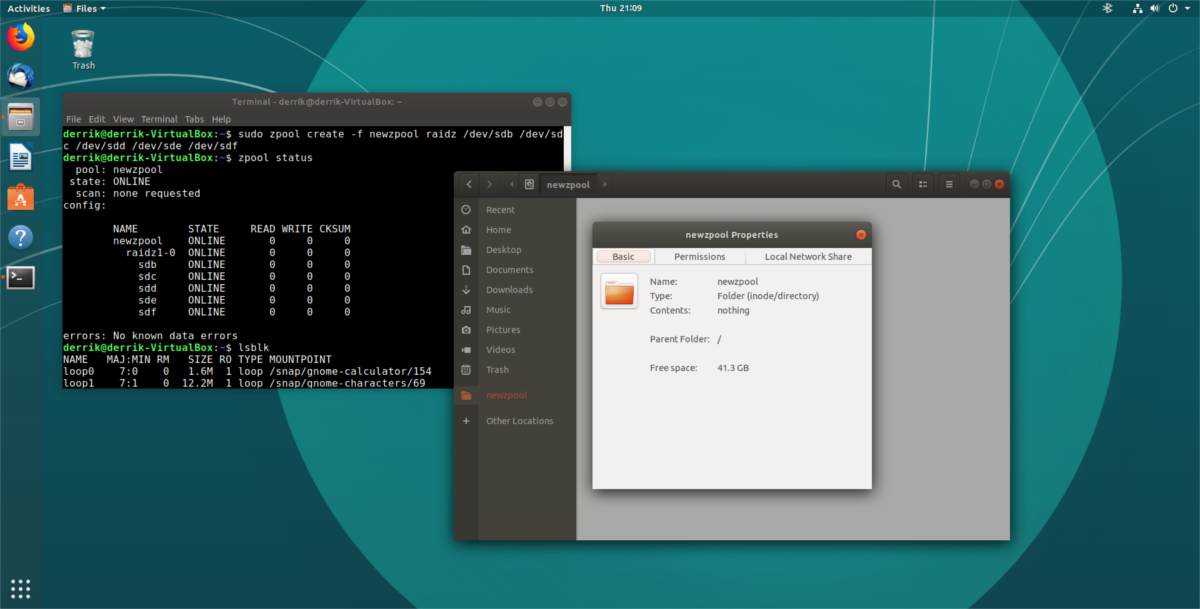
окне терминала запустите команду lsblk. Запуск команды «list block» выведет все накопители на вашем ПК Linux.
Пройдите и решите, какие жесткие диски использовать для вашего Z-пула, и помните имена. В этом учебнике наши три диска в пуле ZFS: /dev/sdb, /dev/sdc и /dev/sdd.
Затем вам нужно полностью обнулить жесткие диски, выбранные для Z-пула, чтобы у них больше не было данных. Используя команду dd, перезапишите каждый из дисков. Это займет некоторое время.
Примечание: измените /dev/sdX с идентификатором диска, найденным с помощью команды lsblk (sdb и т. д.).
Когда dd закончит работу, запустите команду fdisk.
Запуск fdisk покажет много информации о жестких дисках, включая информацию о файловой системе для каждого.
Просмотрите показания и убедитесь, что ни один из дисков, которые вы удалили, не имеет файловой системы.
Этот шаг имеет решающее значение, поскольку ZFS не использует традиционный формат разбиения.
Если вывод fdisk выглядит хорошо, безопасно создайте новый Z-poll ZFS.
Для базовой настройки Z-пула выполните следующие действия:
Базовая установка позволит большинству пользователей удовлетворить свои потребности в хранилищах.
Однако те, которые ценят свои данные и нуждаются в защите, не должны идти по пути установки с такой базовой настройкой.
Вместо этого подумайте о создании пула ZFS с RaidZ.
Использование RaidZ в сочетании с вашим ZFS-пулом гарантирует, что ваши данные будут избыточными, с множеством резервных копий.
Чтобы создать пул ZFS с RaidZ, запустите:
Чтобы добавить файлы в новый пул хранения ZFS, откройте диспетчер файлов и перейдите в корень файловой системы.
Поместите файлы внутри папки с именем ZFS Zpool.
Добавить диски в ZFS Zpool
ZFS предназначен для хранения большого количества данных, но это не значит, что ваши оригинальные диски не будут заполняться.
Наступит время, когда потребуется больше места для хранения.
К счастью, поскольку ZFS не использует разделы, добавление большего количества хранилища в систему прост.
В этом примере мы добавим еще два диска в Zpool (/dev/sde и /dev/sdf).
Примечание: если ваша установка ZFS не использует RaidZ, удалите ее из команды.
Удалить пул ZFS
Зачастую объемы ZFS ломаются и становятся непригодными.
Когда это произойдет, вам может потребоваться удалить пул хранения.
Чтобы удалить пул хранения, откройте терминал и используйте команду zfs destroy.
Запуск zpool destroy занимает довольно много времени, в зависимости от того, сколько данных находится в вашем пуле хранения.
Вы узнаете, что Zpool полностью уничтожен, когда терминал снова будет доступен для использования.
Проверить статус ZFS
Быстрый способ проверить статус вашего Zpool с помощью команды zpool status.
С его помощью пользователи могут видеть базовое считывание тома ZFS, как он это делает и имеются ли какие-либо ошибки.
Чтобы проверить статус, выполните следующую команду:
Источник
ZFS on Linux — не все так просто
Прочитав статью «ZFS on Linux — легко и просто», решил поделиться своим скромным опытом использования этой ФС на паре Linux-серверов.
Вначале — лирическое отступление. ZFS — это круто. Это настолько круто, что перекрывает все недостатки ФС, портированной с идеологически другой платформы. Ядро Solaris работает с иными примитивами, нежели Linux, поэтому, чтобы сделать возможным перенос ZFS с использованием кода Solaris, разработчики создали слой совместимости SPL — Solaris Porting Layer. Прослойка эта работает вроде бы нормально, но она — дополнительный код в режиме ядра, который вполне может быть источником сбоев.
ZFS не до конца совместима с Linux VFS. Например, нельзя управлять списками контроля доступа через POSIX API и команды getfacl/setfacl, что очень не нравится Samba, которая хранит в ACL разрешения NTFS. Поэтому выставить нормальные права на Samba-папки и файлы не получится. Samba, теоретически, поддерживает ZFS ACL, но этот модуль под Linux еще собрать надо… А вот расширенные атрибуты ФС в ZFS on Linux присутствуют и работают отлично.
Кроме того, Solaris в 32-х битной редакции использует иной механизм распределения памяти, нежели Linux. Поэтому, если вы решились попробовать ZFS on Linux на архитектуре x86, а не x86_64 — готовьтесь к глюкам. Вас ждет стопроцентная загрузка процессора на элементарных операция и километры ошибок в dmesg. Как пишут разработчики ZFS on Linux: «You are strongly encouraged to use a 64-bit kernel. At the moment zfs will build in a 32-bit environment but will not run stably».
ZFS — это своеобразная «вещь в себе», и она хранит в метаданных такие параметры, которые нетипичны для Linux. Например — имя точки монтирования ФС задается в ее настройках, а сама ФС монтируется командой zfs mount, что автоматически делает ее несовместимой с /etc/fstab и прочими способами монтирования ФС в Linux. Можно, конечно, выставить mountpoint=legacy и все-таки воспользоваться mount, но это, согласитесь, неизящно. В Ubuntu проблема решается пакетом mountall, который содержит специфичные для ZFS скрипты монтирования и пропатченную команду mount.
Следующая проблема — мгновенные снимки системы, так называемые снэпшоты. Вообще, ZFS содержит очень эффективную реализацию снэпшотов, которая позволяет создавать «машину времени» — комплект снимков, скажем, за месяц, с разрешением 1 снимок в 15 минут. Мейнтейнеры Ubuntu конечно, включили эту возможность в пакет zfs-auto-snapshot, который и создает комплект снимков, правда, более разряженный по времени. Проблема в том, что каждый снимок отображается в каталоге /dev в виде блочного устройства. Цикличность создания снэпшотов такова, что за месяц мы получим 4+24+4+31+1=64 блочных устройста на каждый том пула. Тоесть, если у нас, скажем, 20 томов (вполне нормальное значение, если мы используем сервер для виртуализации), мы получим 64*20=1280 устройств за месяц. Когда же мы захотим перезагрузиться, нас будет ждать большой сюрприз — загрузка очень сильно затянется. Причина — при загрузке выполняется утилита blkid, опрашивающая все блочные устройства на предмет наличия файловых систем. То ли механизм определения ФС в ней реализован криво, то ли блочные устройства открываются медленно, но так или иначе процесс blkid убивается ядром через 120 секунд по таймауту. Надо ли говорить, что blkid и все основанные на ней скрипты не работают и после завершения загрузки?
oneric1, ОС — Debian Sid x86_64
Допустим, мы победили все эти проблемы, и хотим отдать свежесозданный раздел другим машинам по iSCSI, FC или как-нибудь еще через систему LIO-Target, встроенную в ядро. Не тут то было! Модуль zfs при загрузке использует основной номер 230 для создания блочных устройств в каталоге /dev. LIO-Target (точнее, утилита targetcli) без последних патчей не считает устройство с таким номером готовым для экспортирования. Решение — исправить одну строчку в файле /usr/lib/python2.7/dist-packages/rtslib/utils.py, или добавить параметр загрузки модуля zfs в файл /etc/modprobe.d/zfs.conf:
И в завершение: как известно, включить модуль zfs в ядро мешает несовместимость CDDL, под которой выпущена ZFS, и GPL v2 в ядре. Поэтому каждый раз при обновлении ядра модуль пересобирается через DKMS. Иногда у модуля это получается, иногда (когда ядро уж слишком новое) — нет. Следовательно, самые свежие фишки (и багфиксы KVM и LIO-Target) из последних ядер вы будете получать с некоторой задержкой.
Каков же вывод? Использовать ZFS в продакшене надо с осторожностью. Возможно, те конфигурации, которые без проблем работали на других ФС, работать не будут, а те команды, которые вы без опаски выполняли на LVM, будут вызывать взаимоблокировки.
Зато в продакшене под Linux вам теперь доступны все фишки ZFS vol. 28 — дедупликация, он-лайи компрессия, устойчивость к сбоям, гибкий менеджер томов (его, кстати, можно использовать отдельно) и т. д. В общем удачи и успехов вам!
Источник
ZFS on Linux: вести с полей 2017

Проект ZFS on Linux изначально был создан для портирования существующего кода из Solaris. После закрытия его исходного кода совместно с сообществом OpenZFS проект продолжил разработку ZFS для Linux. Код может быть собран как в составе ядра, так и в виде модуля.
Сейчас пользователь может создать пул с последней совместимой с Solaris версией 28, а также с приоритетной для OpenZFS версией 5000, после которого началось применение feature flags (функциональные флаги). Они позволяют создавать пулы, которые будут поддерживаться в FreeBSD, пост-Sun Solaris ОС, Linux и OSX вне зависимости от различий реализаций.
В 2016 году был преодолён последний рубеж, сдерживавший ZFS на Linux — многие дистрибутивы включили его в штатные репозитории, а проект Proxmox уже включает его в базовую поставку. Ура, товарищи!
Рассмотрим как наиболее важные отличия, так и подводные камни, которые есть в настоящее время в версии ZFS on Linux 0.6.5.10.
Начинать знакомство с ZFS стоит с изучения особенностей CopyOnWrite (CoW) файловых систем — при изменении блока данных старый блок не изменяется, а создается новый. Переводя на русский — происходит копирование при записи. Данный подход накладывает отпечаток на производительности, зато даёт возможность хранить всю историю изменения данных.
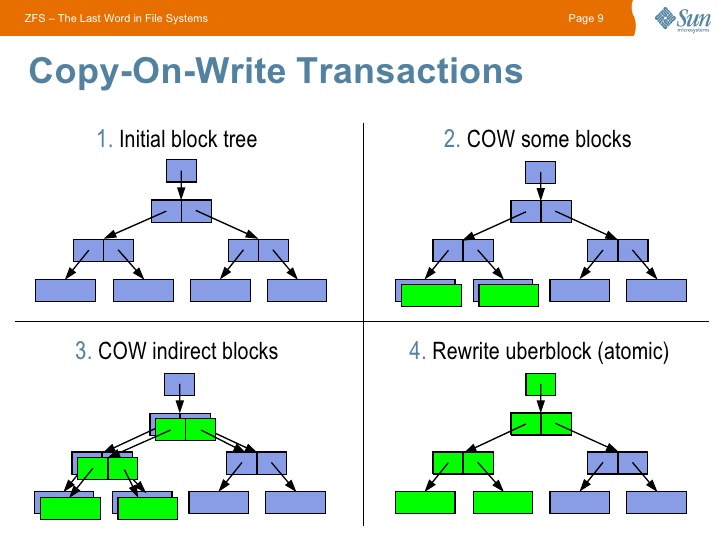
CoW подход в ZFS даёт огромные возможности: эта ФС не может иметь некорректного состояния, т.к. в случае проблем с последней транзакцией (например при отключении питания) будет использована последняя корректная.
Также сразу стоит отметить, что для всех данных считается контрольная сумма, что также оставляет свой отпечаток на производительности, но даёт гарантию целостности данных.
Кратко о главных преимуществах ZFS для вашей системы.
- контрольные суммы — гарантия корректности данных;
- возможность резервирования как на уровне создания зеркал и аналогов RAID массивов, так и на уровне отдельного диска (параметр copies );
- в отличие от многих файловых систем с их fsck на уровне журнала, ZFS проверяет все данные по контрольным суммам и умеет проводить их автоматическое восстановление по команде scrub (если в пуле есть живая копия битых данных);
- первая ФС, разработчики которой честно признались во всех возможных рисках при хранении — везде при упоминании ZFS можно встретить требование оперативной памяти с поддержкой ECC (любая ФС имеет риск повреждения при отсутствии ECC памяти, просто все, кроме ZFS, предпочитают не задумываться об этом);
- ZFS создавалась с учетом ненадёжности дисков, просто помните это и перестаньте волноваться о вашем
WD GreenSeagateetc(только, если рядом трудится ещё один выживший диск).
Максимальная гибкость вашего хранилища:
- закончилось место? Замените диск на более объёмный, и ваш покорный ZFS сам займёт новоотведённое ему место (по параметру autoexpand);
- лучшая реализация снапшотов среди файловых систем для Linux. На это подсаживаешься. Инкрементально по сети, в архив,
/dev/null, да хоть раздвойте личность вашего дорогого Linux в реальном времени (clone); - нужно больше
золотаместа? 256 зебибайт хватит всем!
Структура.
В ZFS структура хранилища выглядит следующим образом:
В пуле может быть неограниченное количество vdev, что позволяет создать пул из двух и более mirror, RAID-Z или других сочетаний. Также доступны классические RAID10 и т.д.
Типы массивов:
Stripe — обычный RAID0.
Mirror — RAID1 на манер ZFS — реплицируются только занятые блоки, забудьте о синхронизации пустого места.
RAID-Z — создавался как замена RAID5-6, но имеет большие отличия:
— каждый блок данных — аналог отдельного массива (с динамической длинной);
— отсутствует проблема write hole;
— при ребилде создаются только данные (т.е. риск сбоя в этот момент уменьшается). Также в тестовой ветке уже находятся улучшения, которые дополнительно ускорят этот процесс.
Рекомендуется использовать RAID-Z2 (аналог RAID6). При создании RAID-Z стоит обязательно изучить эту статью, основные нюансы:
— IOPS равен самому медленному диску (создавайте RAID-Z с наименьшим количеством дисков);
— эффективность утилизации места увеличивается при бОльшем количестве дисков в массиве (требуется задать корректный recordsize, см. ссылку выше);
— в существующий массив RAID-Z нельзя добавить ещё один диск (пока), но можно заменить диски на более ёмкие. Эта проблема решается созданием нескольких массивов в рамках одного vdev.
dRAID (в разработке) — базируется на наработках RAID-Z, но при сбое позволяет задействовать на чтение-запись все диски массива.
ARC — умное кеширование в ZFS.
CoW ухудшает производительность. Для сглаживания ситуации был создан adaptive replacement cache (ARC). Его основная особенность в проработанных эвристиках для исключения вымывания кеша, в то время как обычный page cache в Linux к этому очень чувствителен.
Бонусом к ARC существует возможность создать быстрый носитель со следующим уровнем кеша — L2ARC. При необходимости он подключается на быстрые SSD и позволяет заметно улучшить IOPS HDD дисков. L2ARC является аналогом bcache со своими особенностями.
L2ARC стоит использовать только после увеличения ОЗУ на максимально возможный объём.
Также существует возможность вынести запись журнала — ZIL, что позволит значительно ускорить операции записи.
Дополнительные возможности.
Компрессия — с появлением LZ4 позволяет увеличить скорость IO за счёт небольшой нагрузки на процессор. Нагрузка настолько мала, что включение данной опции уже является повсеместной рекомендацией. Также есть возможность воспользоваться другими алгоритмами (для бекапов прекрасно подходит gzip).
Дедупликация — особенности: процесс дедупликации производится синхронно при записи, не требует дополнительной нагрузки, основное требование —
320 байт ОЗУ на каждый блок данных (Используйте команду zdb -S название_пула для симуляции на существующем пуле) или
5гб на каждый 1 тб. В ОЗУ хранится т.н. Dedup table (DDT), при недостатке ОЗУ каждая операция записи будет упираться в IO носителя (DDT будет читаться каждый раз с него).
Рекомендуется использовать только на часто повторяющихся данных. В большинстве случаев накладные расходы не оправданы, лучше включить LZ4 компрессию.
Снапшоты — в силу архитектуры ZFS абсолютно не влияют на производительность, в рамках данной статьи на них останавливаться не будем. Отмечу только прекрасную утилиту zfs-auto-snapshot, которая создаёт их автоматически в заданные интервалы времени. На производительности не отражается.
Шифрование (в разработке) — будет встроенным, разрабатывается с учётом всех недостатков реализации от Oracle, а также позволит штатными send/receive и scrub отправлять и проверять данные на целостность без ключа.
Основные рекомендации (TL;DR):
— Заранее продумайте геометрию массива, в настоящий момент ZFS не умеет уменьшаться, а также расширять существующие массивы (можно добавлять новые или менять диски на более объёмные);
— используйте сжатие:
compression=lz4
— храните расширенные атрибуты правильно, по умолчанию хранятся в виде скрытых файлов (только для Linux):
xattr=sa
— отключайте atime:
atime=off
— выставляйте нужный размер блока (recordsize), файлы меньше recordsize будут записываться в уменьшенный блок, файлы больше recordsize будут записывать конец файла в блок с размером recordsize (при recordsize=1M файл размером 1.5мб будет записан как 2 блока по 1мб, в то время как файл 0.5мб будет записан в блок размером 0.5мб). Больше — лучше для компрессии:
recordsize=128K
— ограничьте максимальный размер ARC (для исключения проблем с количеством ОЗУ):
echo «options zfs zfs_arc_max=половина_ОЗУ_в_байтах» >> /etc/modprobe.d/zfs.conf
echo половина_ОЗУ_в_байтах >> /sys/module/zfs/parameters/zfs_arc_max
— дедупликацию используйте только по явной необходимости;
— по возможности используйте ECC память;
— большинство SSD врёт системе о размере блока, для перестраховки контролируйте его (параметр ashift). Ссылка на список исключений для SSD в коде ZFS.
Важные моменты:
— многие свойства действуют только на новые данные, к примеру при включении сжатия оно не применится к уже существующим данным. В дальнейшем возможно создание программы, применяющей свойства автоматически. Обходится простым копированием.
— консольные команды ZFS не запрашивают подтверждение, при выполнении destroy будьте бдительны!
— ZFS не любит заполнение пула на 100%, как и все другие CoW ФС, после 80% возможно замедление работы без должной настройки.
— требуется правильно выставлять размер блока, иначе производительность приложений может быть неоптимальна (примеры — Mysql, PostrgeSQL, torrents).
— делайте бекапы на любой ФС!
В настоящий момент ZFS on Linux уже является стабильным продуктом, но плотная интеграция в существующие дистрибутивы будет проходить ещё некоторое время.
ZFS — прекрасная система, от которой очень сложно отказаться после знакомства. Она не является универсальным средством, но в нише программных RAID массивов уже заняла своё место.
Я, gmelikov, состою в проекте ZFS on Linux и готов с радостью ответить на любые вопросы!
Отдельно хочу пригласить к участию, всегда рады issues и PR, а также готовы помочь вам в наших mailing lists.
Update (12.02.2018): Добавлена информация про ashift SSD дисков.
Источник



